在transformer中存在add&norm操作,add操作很简单,就是把注意力矩阵和原来的矩阵相加,也就是残差链接,可以有效减少梯度消失。
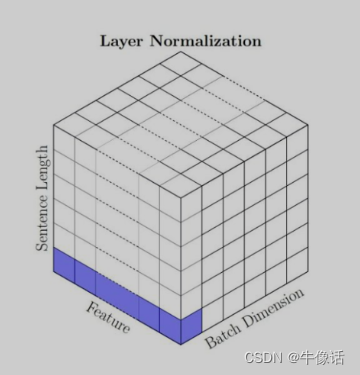
下图为layer norm的解释图,可以看出layer norm是针对一个token来做的归一化操作。
具体的实现,我们来看下面这段代码,我们的目标就是使用torch中的LN去计算一个EM,然后我们再自己手动计算一个EM,看看LN到底是不是针对token来求的平均,其中注释我已经写的很清楚了,仔细看注释就会理解了!!!:
import torch# 1.使用torch的layer norm来进行操作,然后看一下ln后的矩阵是什么样子
# 创建了一个2*3*4的随机矩阵
batch_size, seq_size, dim = 2, 3, 4
embedding = torch.randn(batch_size, seq_size, dim)
print("embedding:", embedding)
# 创建一个LayerNorm层
layer_norm = torch.nn.LayerNorm(dim, elementwise_affine=False)
# 进行LayerNorm操作
print("layer_norm: ", layer_norm(embedding))# 2.自己手动来对最后一个维度进行计算,如果和上面的结果一样,说明layernorm的计算和我们的计算是一样的
eps: float = 0.00001# 计算了embedding张量在最后一个维度上的均值,并将结果存储在变量mean中。
# dim=(-1):这个参数指定了要在哪个维度上计算均值。在这里,-1表示最后一个维度,所以这个函数会计算embedding张量在最后一个维度上的均值。
mean = torch.mean(embedding[:, :, :], dim=(-1), keepdim=True)
print("mean:", mean)# 计算了embedding张量在最后一个维度上的方差,并将结果存储在变量var中
var = torch.square(embedding[:, :, :] - mean).mean(dim=(-1), keepdim=True)
print("var", var)# 对嵌入张量embedding进行标准化(或称为归一化)的操作
# torch.sqrt(var + eps),这部分代码首先计算了方差张量var的平方根,然后加上一个非常小的常数eps(通常用于防止除以零的错误)。这个操作是缩放的一部分,它根据数据的方差来调整数据的大小
print("y_custom: ", (embedding[:, :, :] - mean) / torch.sqrt(var + eps))通过上面的代码,我们可以看到下面的打印内容:
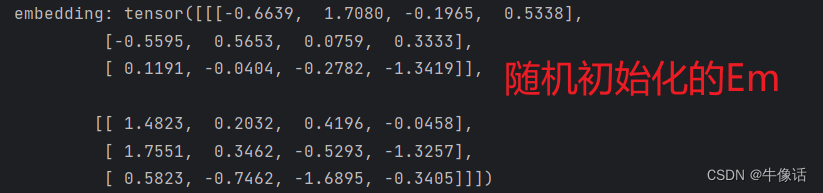
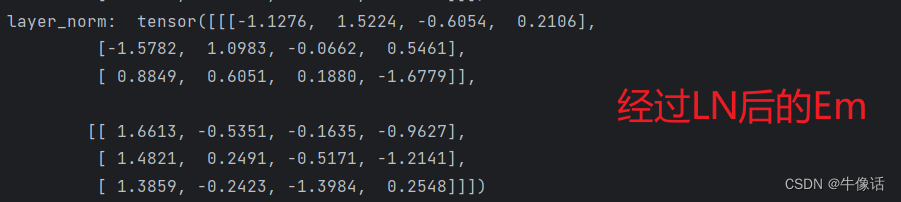

通过输出上的对比我们发现了,使用torch来LN后的EM和我们手动来对Token进行LN的数值一样,说明了LN就是对Token来进行归一会操作的。