参考&转载自:
介绍Google推出的大一统模型—T5_谷歌大模型_深度之眼的博客-CSDN博客
T5 和 mT5-CSDN博客
T5:Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer(万字长文略解T5)_t5论文_hithithithithit的博客-CSDN博客
nlp发展

Google推出大一统模型——T5模型简介
博主在学习的过程中看到了下面这段,要笑死了

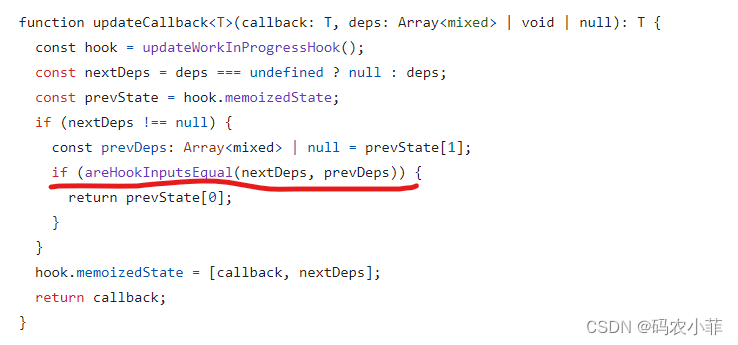
T5 (Transfer Text-to-Text Transformer)提出一个统一的模型框架,将各种NLP任务都视为Text-to-Text任务,也就是输入为Text,输出也为Text的任务,从而使得这些任务在训练(pre-train和fine-tune)时能够使用相同的目标函数等。具体来说,就是使用了最大似然目标(teacher forcing )来进行训练而不管任务类型。为了让模型认识不同的任务,我们使用了文本前缀来标明不同类型任务输入
- 翻译前缀translate English to German:
- 分类前缀cola sentence:
- 摘要前缀summarize:
这里每个任务前缀的选择可以认为是一种超参,即人为设计前缀样式。作者发现不同的前缀对模型的影响有限,因此没有做大量实验比较选择不同前缀的结果。
在T5之前的几乎所有预训练语言模型,在下游任务微调过程中都需要添加非线性层,将模型的输出转化为任务指定的输出格式。T5不需要添加任何非线性层,只需要提供下游任务的微调数据,并在输入数据前加上任务声明前缀.
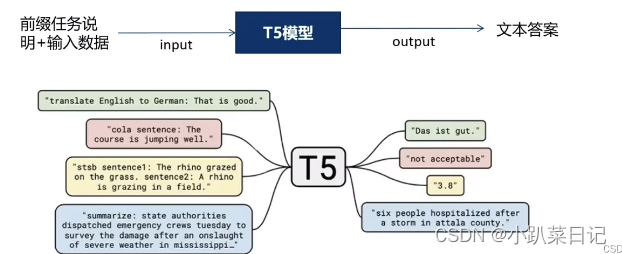
T5将任务指令设定在输入文本中,就不需要针对每类任务单独设置特定的FC输出层,所有任务都输出text。对于生成任务(例如机器翻译或文本摘要)很自然,但对于分类任务这是很不寻常的,其中训练T5输出 文本label (例如,用于情感分析的“正”或“负”)而不是类别索引。上图中黄色例子,对于需要输出连续值的 STS-B(文本语义相似度任务),以每 0.2 为间隔,从 1 到 5 分之间分成 21 个值作为输出分类任务。通过训练T5模型可以被训练成生成与目标相似度相关的文本输出,而不是直接输出一个标量值。
T5模型结构
T5模型采用Transformer的encoder-decoder结构,T5模型和原始的Transformer结构基本一致,除了做了如下两点改动:
1.去除了层标准化(Layer Norm)的偏置项
这里使用的layer normalization仅用于缩放,没有偏置,且Layer normalization被应用于每个子模块输入的前面。在layer normalization之后,一个残差跳过连接被用于将每个子模块的输入和输出相加
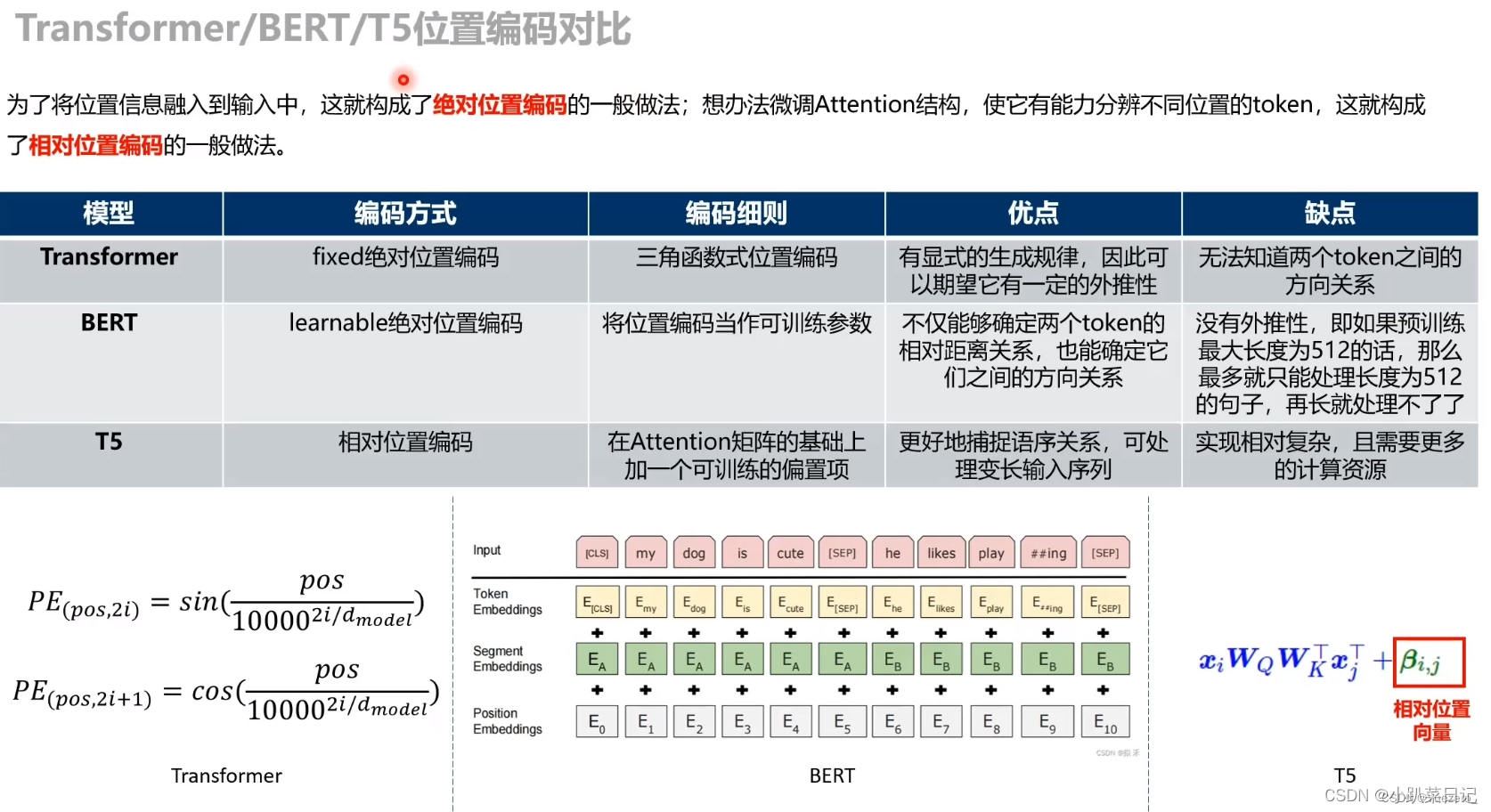
2.使用不同的位置嵌入
本文使用了相对位置编码,每个位置嵌入都只是一个标量,它被添加到用于计算注意力权重的相应logit中。为了提高效率,我们还在模型中的所有层中共享位置嵌入参数,尽管在给定的层中,每个注意头使用不同的学习位置嵌入。
transformer中使用绝对位置编码,T5中使用相对位置编码

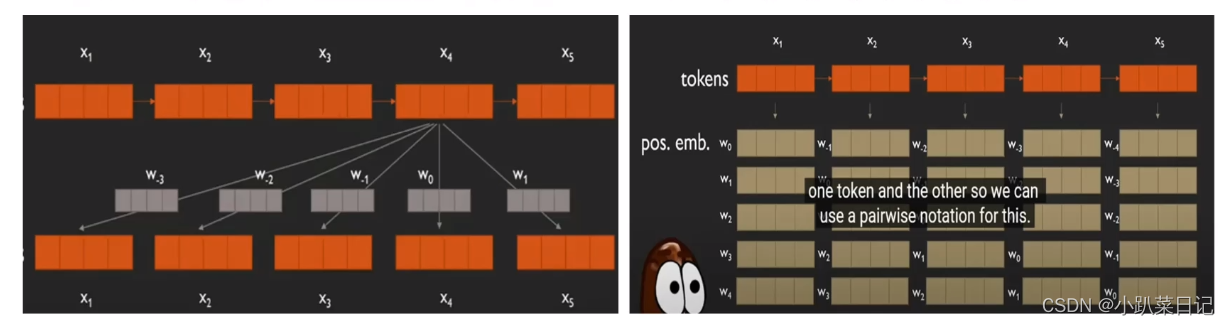 朴素思想解决位置远距离位置编码:为了防止输入序列过长导致位置编码无限增大,设置阈值k限制位置编码增长(类似梯度裁剪)
朴素思想解决位置远距离位置编码:为了防止输入序列过长导致位置编码无限增大,设置阈值k限制位置编码增长(类似梯度裁剪)

T5的 Position Embedding:

T5的 Position Embedding 在 self-attention 的 QK 乘积之后进行: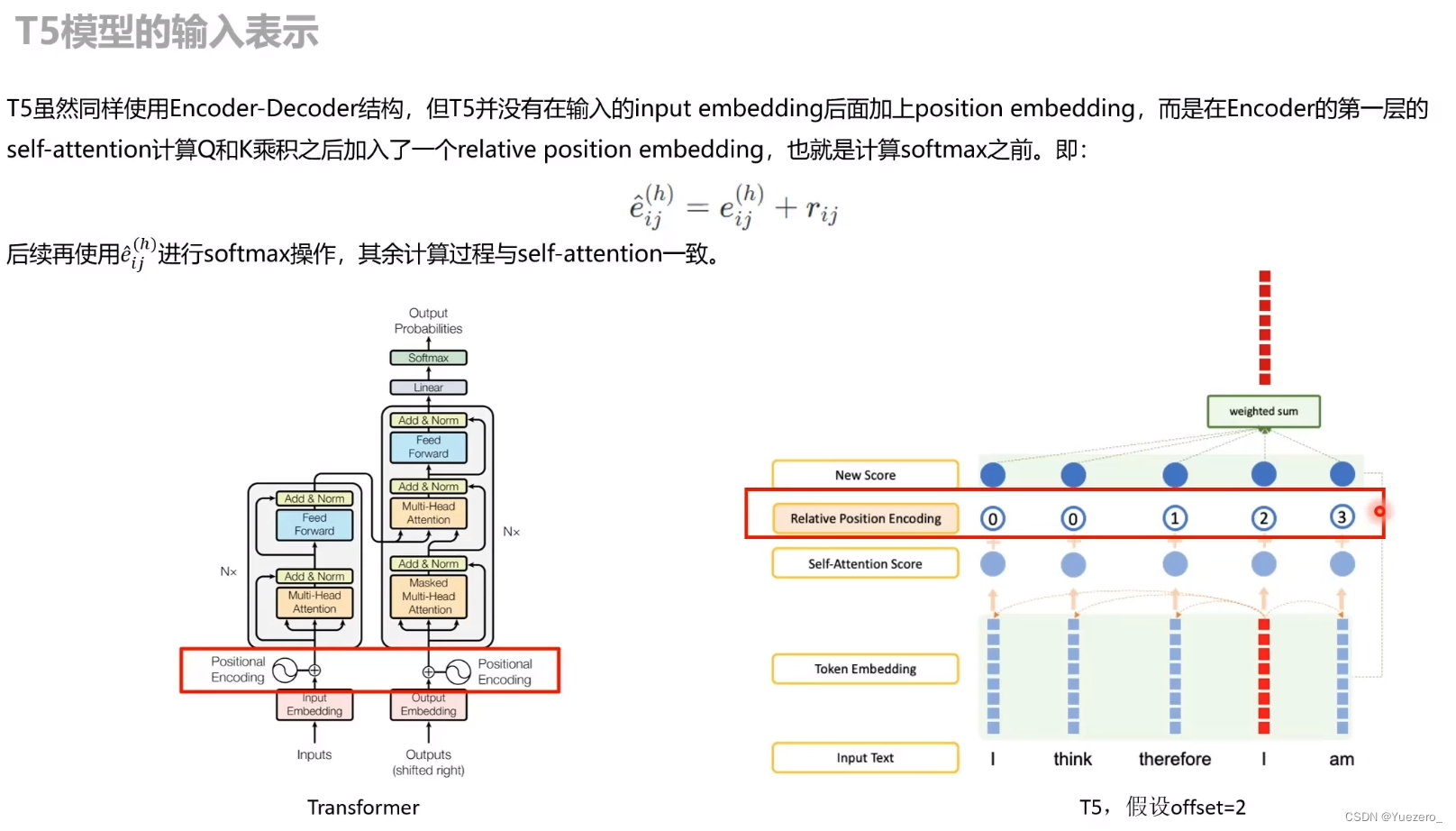
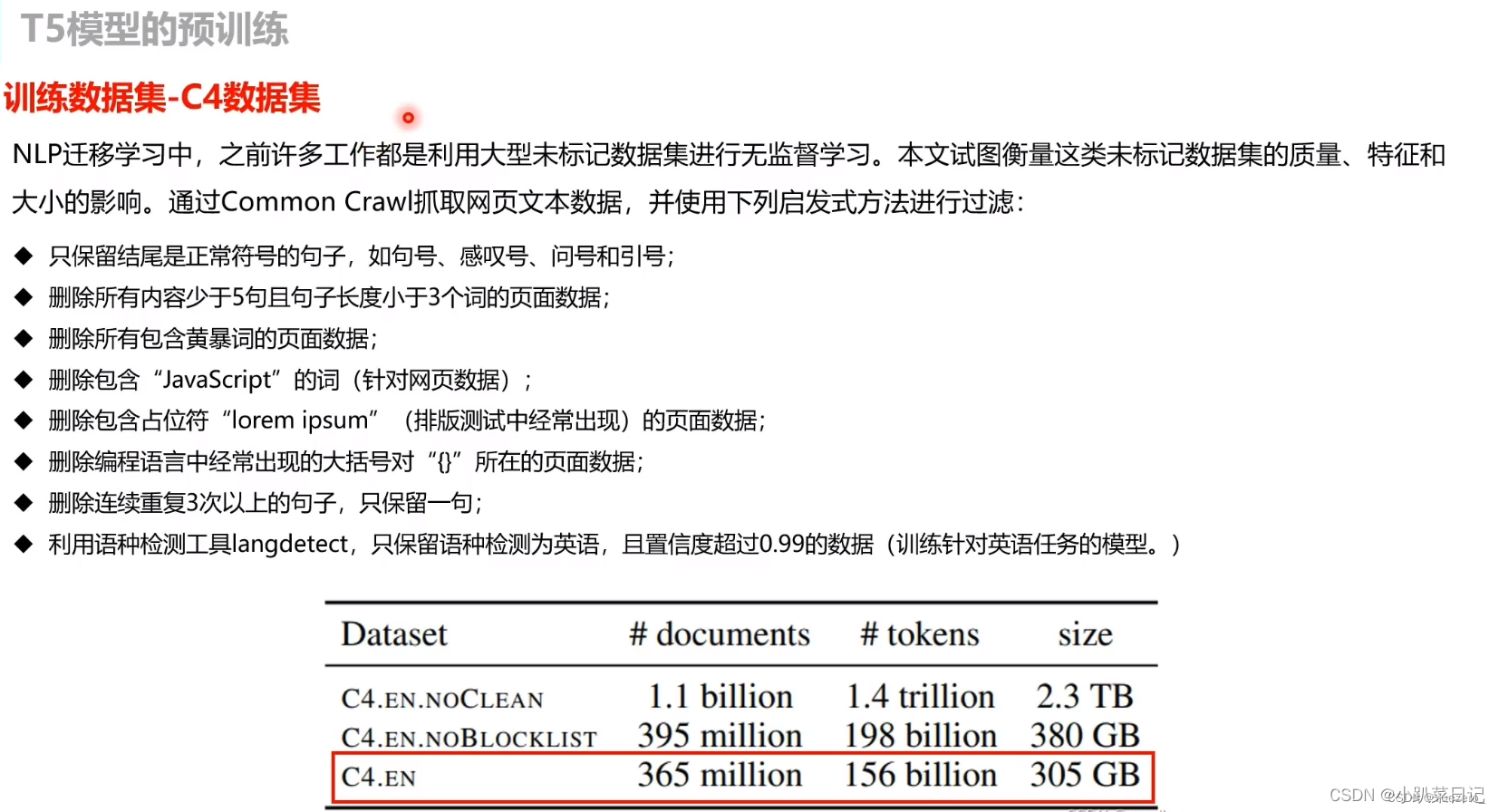
数据集C4
作者对公开爬取的网页数据集Common Crawl进行了过滤,去掉一些重复的、低质量的,看着像代码的文本等,并且最后只保留英文文本,得到数据集C4: the Colossal Clean Crawled Corpus。
Baseline
基线的目标是反应典型的现代实践。我们使用去噪的目标去标准的Transformer架构进行预训练,然后分别对每个下游任务进行微调。
Model
模型的encoder和decoder使用了和Bert-base相似的尺寸,encoder和decoder包含了12个堆叠块,前馈神经网络的输出层维度为3072,最终模型的参数有220million个,大约是Bert-base的两倍。自注意力共有12个头,每个头维度为64,隐藏层维度为768,使用了0.1的dropout。
Training
如前面所述,所有任务都被表述为从文本到文本的任务。这使得我们总是使用标准的最大似然进行训练,即交叉熵损失。对于优化,我们使用AdaFactor。在测试时,我们使用贪婪解码(即在每个时间步长上选择最高概率的logit)
我们使用最大序列长度512和128的batch_size,那么每次模型可获得=65,365个tokens。我们在C4上一共进行了
=524,288步预训练。整个模型一共预训练了
=34B个tokens。这远比BERT(137B)和RoBERT(2.2T)少。我们预训练的token数量获得了一个合理的计算消耗,但是仍然需要提供足够的预训练以获得可接受的性能。
个token仅仅占了C4语料的一部分,所以我们在预训练的时候不会重复训练数据。
我们还使用了“inverse square root”的学习率调度1/根号下max(n,k),其中n表示当前训练的迭代次数,k是warm-up步骤的数量(在实验中设为10000)。对于前10000个步骤中学习率设为0.01。然后以指数的方式衰减学习率,直到训练前结束。其中在已知训练步骤的情况下使用三角函数的效果会好一点,但是为了通用性还是使用了前面提到的学习率调度方法。
为了权衡低资源和高资源任务,我们的模型对所有的任务都进行了步微调,在微调中使用了长度为512,batch_size为128的输入。我们使用了0.001的恒定学习率。每5000步保存一个检查点然后比较性能,同时为每个任务独立的选择最佳检查点。
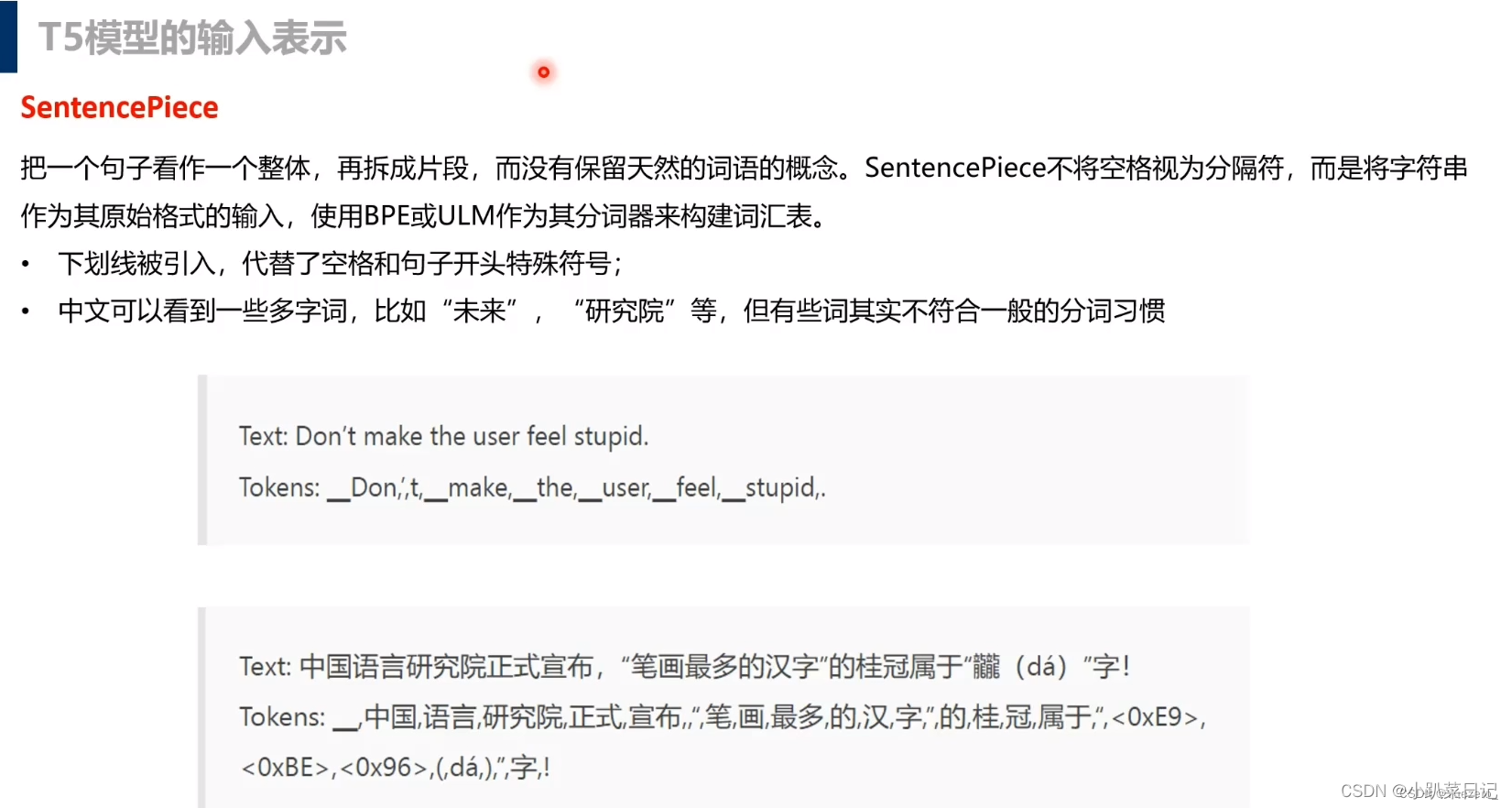
分词
我们使用SentencePiece对文本进行切割得到的token用于wordpiece。由于我们最终将英语模型调整为德语、法语和罗马尼亚语的翻译,因此我们还要求我们的词汇必须涵盖这些非英语语言。为了解决这个问题,我们将C4中使用的页面分为德语、法语和罗马尼亚语。然后,我们在10 part的英语C4数据上训练我们的句子片段模型,其中1 part数据分为德语、法语和罗马尼亚语。这个词汇表在我们的模型的输入和输出中都被共享了。请注意,我们的词汇表使我们的模型只能处理一组预先确定的、固定的语言集。
Wordpiece:BERT的token分词器,WordPiece类似于BPE,它首先将所有字符和符号包含到其基本词汇表中。我们定义所需的词汇大小,反复合并出现频率最高的相邻词元,不断添加子词,直到达到限制。
Unsupervised Objective
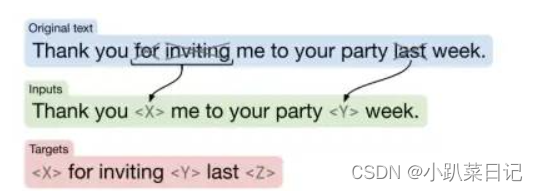
最近的工作表明去噪(MLM)的训练目标可以表现得更好。在去噪目标中,该模型被训练来预测输入中缺失或损坏的令牌。我们设计了一个目标,随机抽样,然后在输入序列中删除15%的标记。我们用一些唯一的特殊符号token id, 来表示原始样本中被随机masked的span或token,而目标样本则为被masked的span或token序列,用输入样本中对应位置的特殊符号分隔,最后加上一个特殊符号表示序列结束。
Baseline Performance
在每个下游任务上单独fine-tune,对所有下游任务进行步训练模型的性能。理论上,我们应该在一个任务上重复多次实验去获得一个置信区间。但是,这种做法十分昂贵,因为我们需要运行大量实验。作为代替,我们从头开始训练极限模型10次(采用不同的随机初始化和打乱数据集),假设基线模型的这些运行上的方差也适用于每个实验变量。我们不期望我们所做的大多数变化会对运行间的方差产生显著的影响,所以这应该提供一个关于不同变化的重要性的合理指示。这让我们了解了预训练在基线设置中给模型带来的好处。以下是部分实验结果:

可以发现pre-train的模型参数确实对下游任务的性能提升大有帮助。接下来我们就要基于Baseline模型,对模型的某一部分进行修改,进行大量对比实验了。
pre-training
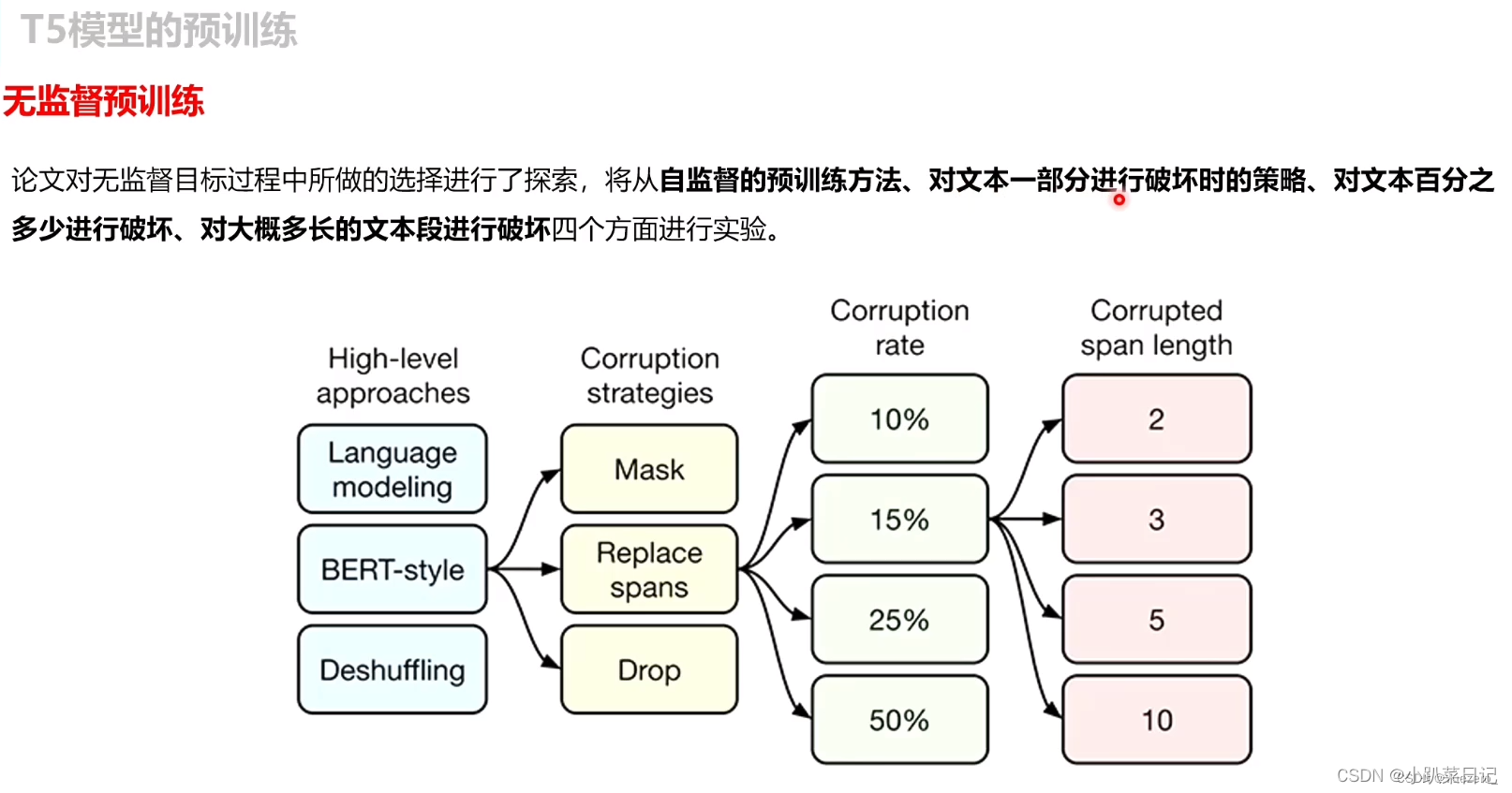
不同模型结构

如图所示为Transformer结构的几种变种,主要区别在于模型中self-attention机制的可见范围。
- Encoder-Decoder结构:传统transformer结构,seq2seq常用模型,编码器可以看见输入序列的每个元素,解码器只能看到当前字符及之前的字符
- LM模型:Encoder-Decoder结构中的decoder部分,只能看到当前字符及之前的字符
- 基于前缀的语言模型Prefix LM:前面一部分文本能看到前缀部分所有内容,后面的只能看到自己及之前的内容(在 Prefix LM 中,除了上下文序列外,还会提供一个前缀作为输入)
在Bert中,我们使用分类器[CLS]来对文本进行分类,然后在Prefix LM中我们直接预测目标后面的词的类型为隐含、矛盾、中性等词来对文本进行分类。因此前缀LM和BERT的区别是分类器被集成到前缀LM transformer解码器的输出层中了。
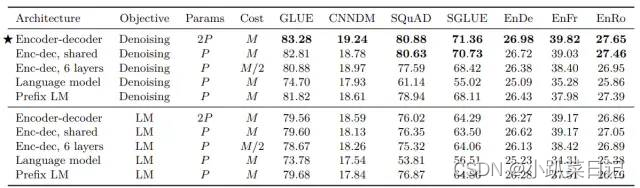
P表示参数量,M表示计算代价,从表中可以发现,
(1) 采用encoder-decoder结构且使用去噪Denoising目标的效果最好;
(2) encoder和decoder共享参数(Enc-dec, shared)的结构表现也差不多好;
(3) 相同参数量的encoder-decoder结构(Enc-dec, shared)要比Prefix LM结构的效果好,说明添加显式的encoder和decoder之间的attention是有用的;
(4) 采用Denoising目标函数的效果要好于采用一般的语言模型目标函数。
(5)encoder-decoder虽然参数量为2P,但是计算代价和参数量为P的模型一样;
(6)相比之下,将编码器和解码器堆栈中的层数减半会显著影响性能;
(7)在不同块之间共享参数可以在不牺牲大量性能的情况下降低总参数的有效方法;
不同破坏(去噪目标mask)
本文比较了三种不同的训练目标:1、LM;2、MLM(BERT-style);3、deshuffling objective
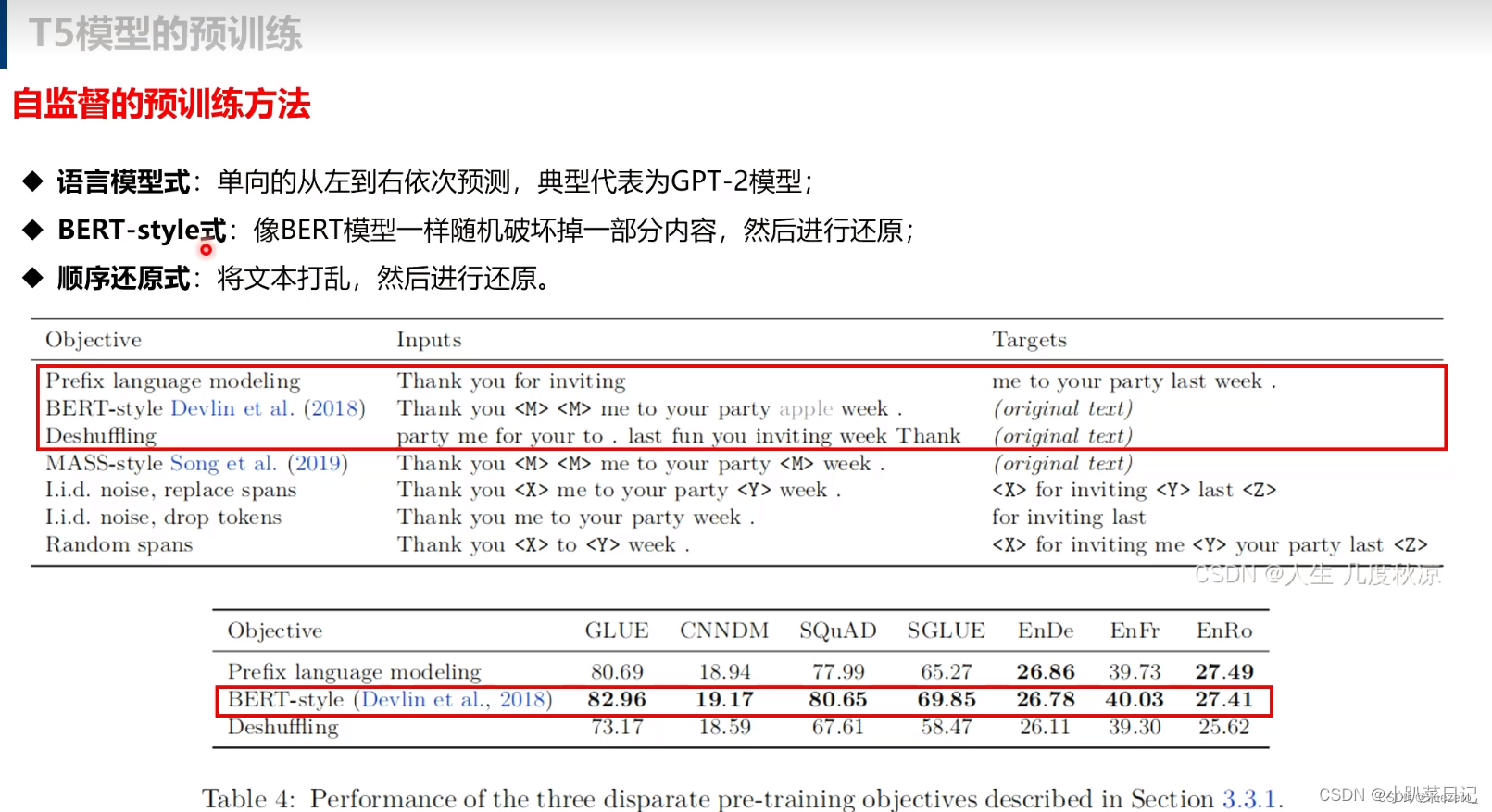
实验表明BERT-style预训练目标的效果最好,因此作者又进一步分析了该目标的几种变种形式。
我们考虑使用一个简化的BERT-style的训练目标,其中并不包括随机交换token,只是简单地用掩码标记替换输入中15%的标记,并训练模型来重建原始的序列。Song等人(2019年)也使用了类似的掩蔽目标,并将其称为“MASS”。然后看看是否有可能避免预测整个未损坏的文本跨度,因为这需要对解码器中的长序列进行自我注意。我们使用了两种策略来实现:首先,我们使用了唯一的掩码token来替换每个连续损坏的span,而不是使用mask token去代替一个损坏的token。其次我们简单地从输入序列中完全删除破坏的标记,并按照顺序重构删除的标记的模型。
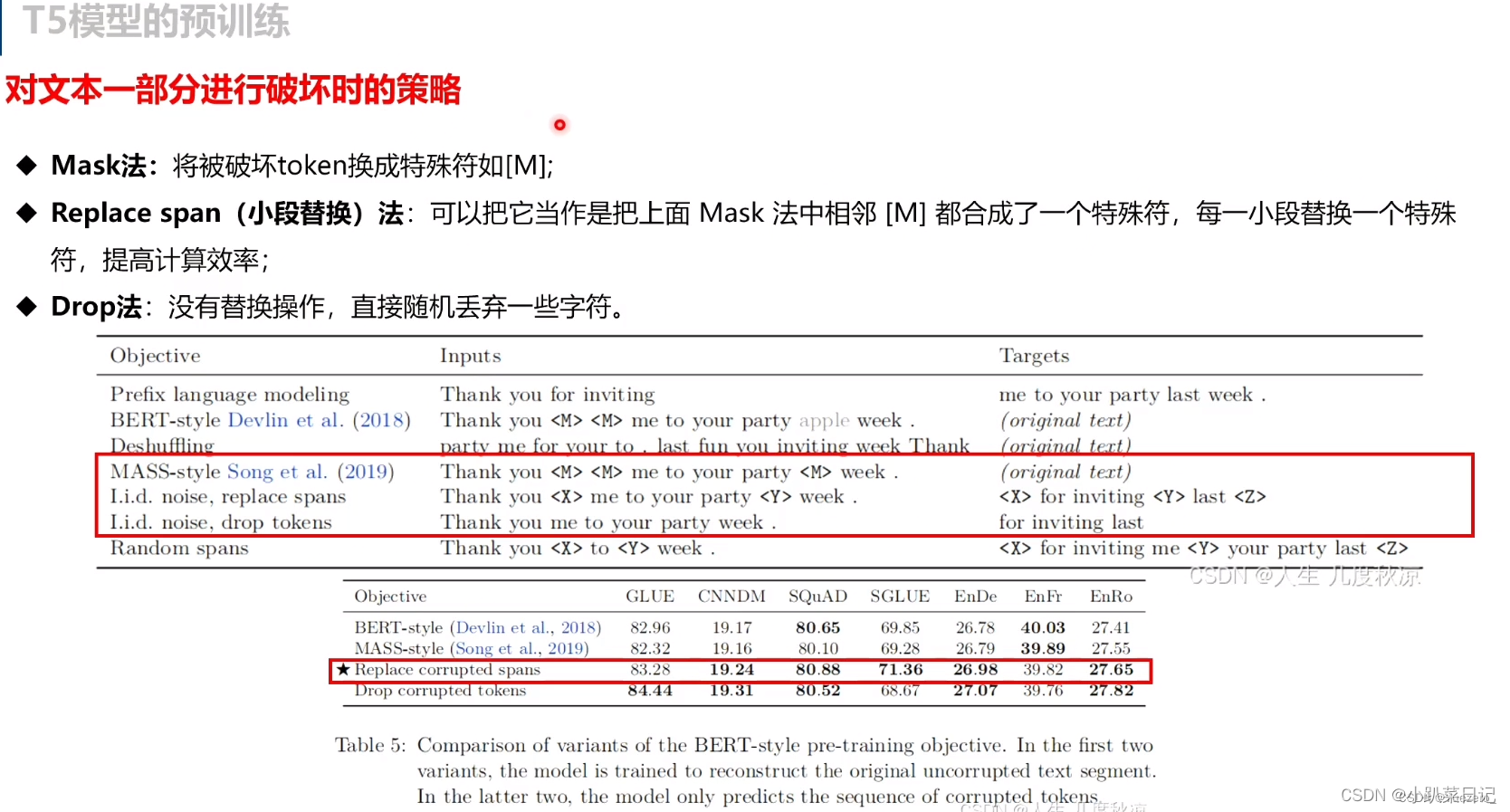
其中Replace corrupted spans就是上上图中的noise replace spans目标,Drop corrupted tokens就是上上图中的noise, drop tokens目标。结果表明,这几种BERT-style预训练目标的变种效果差不多,但是后两种方法不需要预测整个输入序列,而仅需要预测被mask的部分,因此预测的序列长度更短,训练速度也更快。
研究结果还表明,对与我们在这里所考虑的目标类似的目标的额外探索可能不会给我们所考虑的任务和模型带来显著的收益。相反,探索完全不同的利用未标记数据的方法可能是偶然的。
不同破坏百分比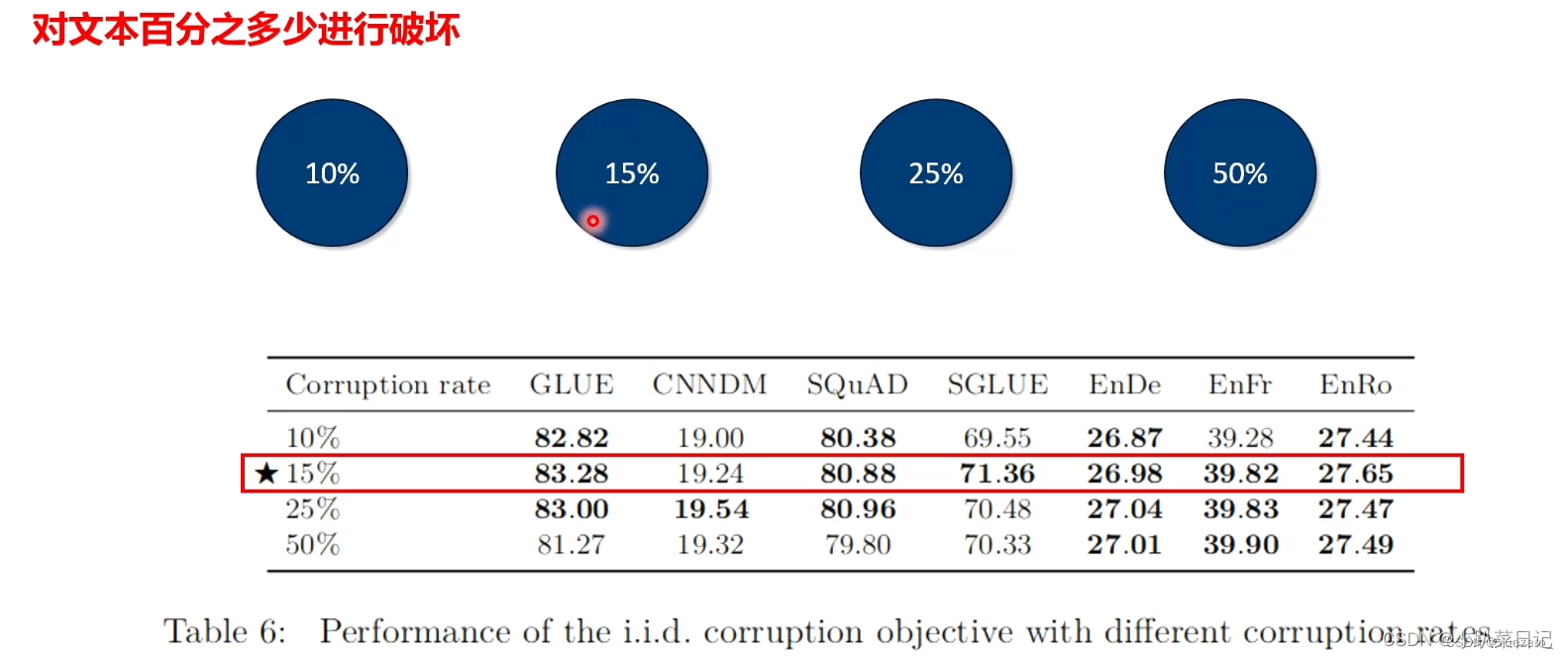
不同破坏长度
例如,对于500个token的序列,随机的破坏15%的token,也就是75个token,然后破坏25个span。不同长度被破坏span之间的性能差异不大,但是长的span会加速训练的时间
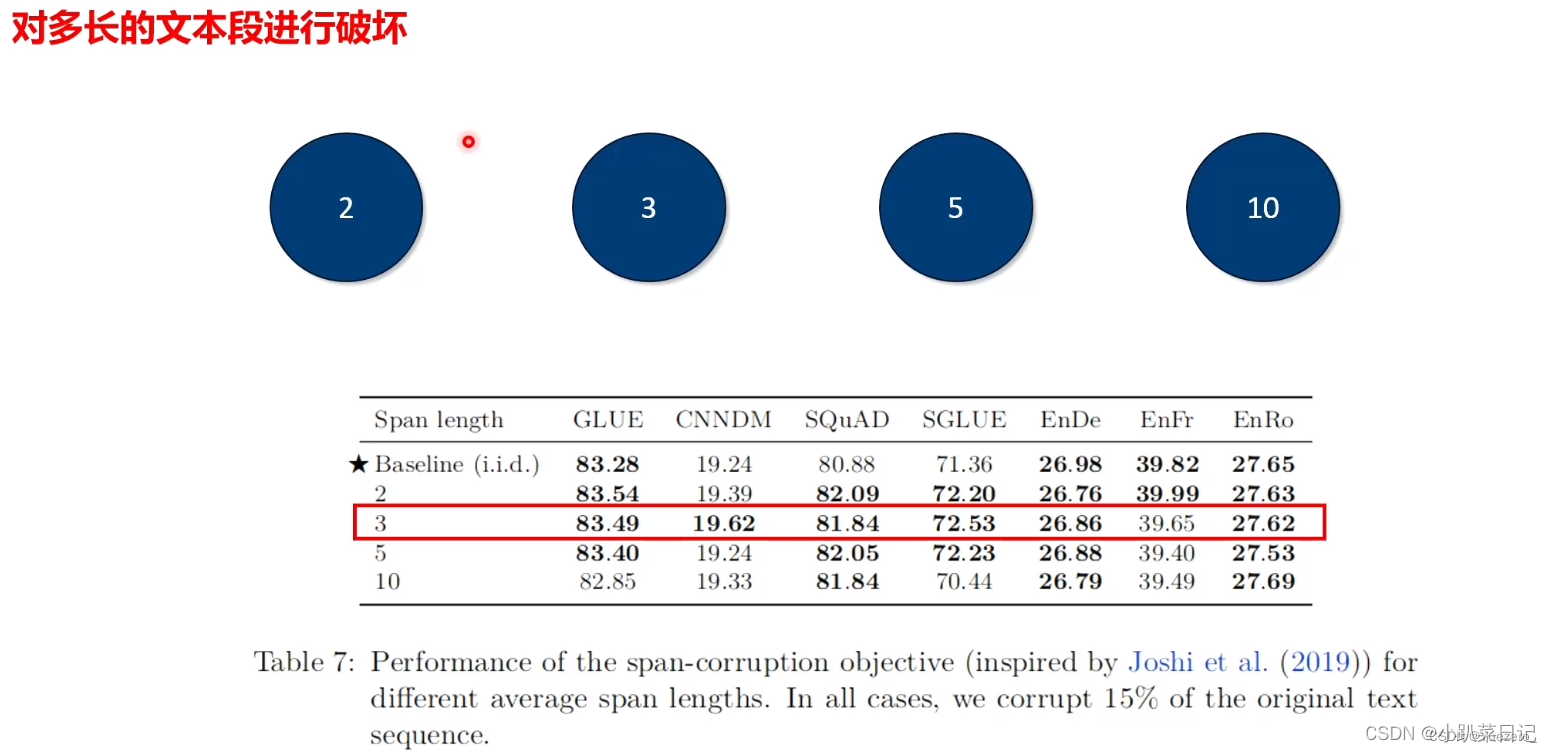 最终参数选择
最终参数选择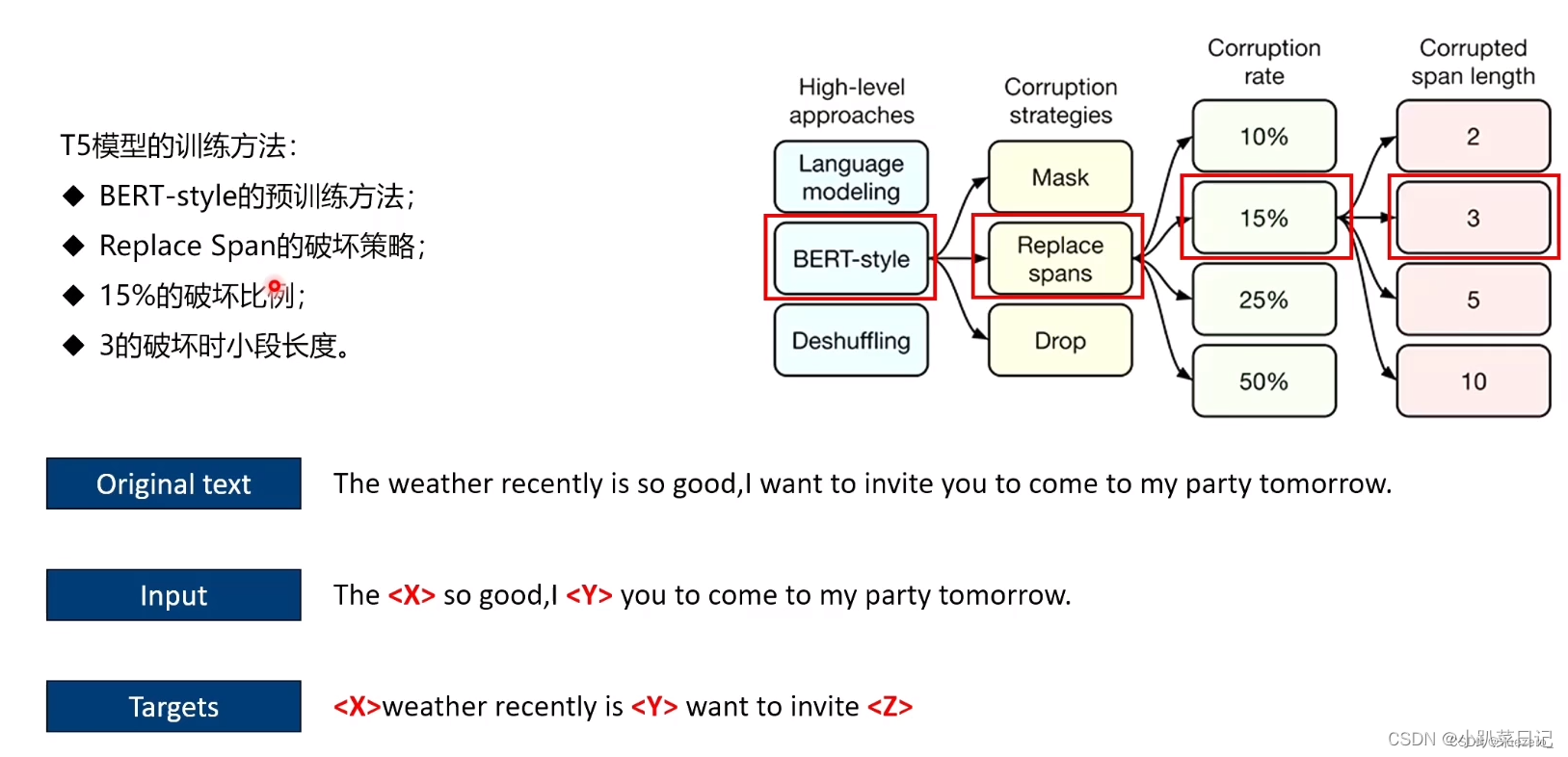
Pre-training Data set
数据集
我们需要测量这种过滤是否会提高下游任务的性能。为此,我们比较了预训练后的基线模型的性能:

C4,unfiltered是没有经过过滤(比如去重、去除代码等)的数据集
RealNews-like是从C4中筛选的仅新闻领域的数据
WebText-like是从Common Crawl中过滤筛选的Reddit用户评分至少为3的数据,数据质量高
Wikipedia是英文百科全书的数据
TBC全称是Toronto Books Corpus,数据主要来自于电子书,和百科全书是不同的领域(different domains)。
注意,为了保证训练过程中除了数据集的种类,其他参数设置一样,作者在预训练时只用了大约34Btokens,也就是各个数据集参与训练的样本数量是一样的。
从实验结构可以看出,
(1) C4比unfiltered C4效果好,说明数据清洗的重要性;
(2) Wikipedia+TBC在SGLUE上的效果比C4好,主要是因为在SGLUE中的MultiRC任务得分很高,MultiRC是一个阅读理解数据集,其中的数据主要是小说书籍,和TBC属于同一领域数据。由此说明预训练的数据集中包含一定的领域数据对下游该领域任务的性能提升有效;
数据集大小
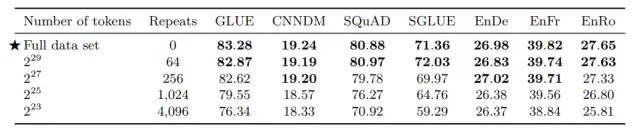
从表中可以看出,随着数据集不断缩小,模型的性能逐渐下降,说明大的模型很可能在小的数据集上发生了过拟合,因此建议预训练模型还是尽可能使用大数据集。
Training Strategy
到目前为止,我们已经考虑了一个设置,即模型的所有参数都在无监督任务上进行预先训练,然后在单个监督任务上进行微调。虽然这种方法很简单,但已经提出了各种训练模型的下游/监督任务的替代方法。在本节中,我们除了在多个任务上同时训练模型的方法外,还比较了微调模型的不同方案。
Fine-tune Methods
文本分类任务的迁移学习结果主张只对分类器的参数进行微调,该分类器被喂入预训练模型产生的句子嵌入。这种方法不太适用于我们的编码器-解码器模型,因为整个解码器必须经过训练来输出给定任务的目标序列。相反,我们将关注两种可选的微调方法,它们只更新我们的编码器-解码器模型的参数的一个子集。
第一个可选的方法是使用adapter learning,在原始的预训练网络中添加一个adapter layer,然后我们只更新adapter的部分参数。具体做法是对Transformer中前缀神经网络后添加一个dense-ReLU-dense块。
第二个可选的方法是“gradual unfreezing”,初始微调时,只有最后一层的参数被更新,训练一段时间后,倒数第二层及其之后的参数被更新,直到整个网络参数被更新。为了将这种方法适应于我们的编码器-解码器模型,我们从顶部开始逐步开始更新编码器和解码器中所有的层。由于我们的输入嵌入矩阵和输出分类矩阵的参数是共享的,所以我们在整个微调过程中更新它们。
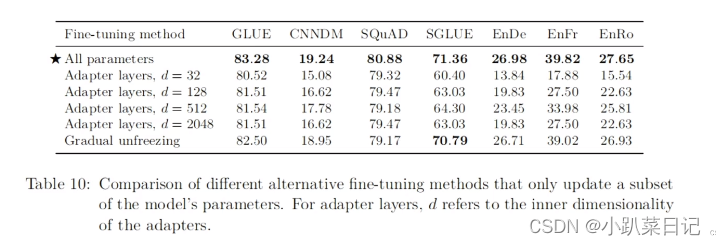 实验表明:所有参数一起更新效果最佳,但缺点是慢!像SQuAD这样的低资源任务在较小的d值下面工作良好,而高资源任务需要较大的维度d才能实现更好的性能。gradual unfreezing尽管在微调过程中确实提供了一定的加速,但全局解冻会在所有任务中造成轻微的性能下降。因此通过更仔细的调整解冻时间表,可以获得更好的结果
实验表明:所有参数一起更新效果最佳,但缺点是慢!像SQuAD这样的低资源任务在较小的d值下面工作良好,而高资源任务需要较大的维度d才能实现更好的性能。gradual unfreezing尽管在微调过程中确实提供了一定的加速,但全局解冻会在所有任务中造成轻微的性能下降。因此通过更仔细的调整解冻时间表,可以获得更好的结果
Multi-Task Pertrain and Finetune
一次在多个任务上训练模型。这种方法在每个任务中共享模型的参数,一次训练所有任务,我们只是简单的将所有的数据集混在一起。因此,在使用多任务学习时,我们可以通过将无监督任务作为混合在一起的任务之一,仍然可以对未标记数据进行训练。相比之下,大多数多任务学习对NLP的应用增加了特定任务的分类网络或对每个任务使用不同的损失函数。多任务学习的一个重要因素是模型应该从每个任务中训练多少的数据。我们的目标是使模型在每个任务上表现得好,而不是过度训练或者不充分训练,也不是让模型见过多的数据。如何准确地设置来自每个任务的数据的比例可能取决于各种因素,包括数据集的大小、学习任务的“难度”,正则化等等。另一个潜在得因素使“任务推理”或者“消极迁移”,在某一个任务上性能好,可能会影响在其他任务上得性能。
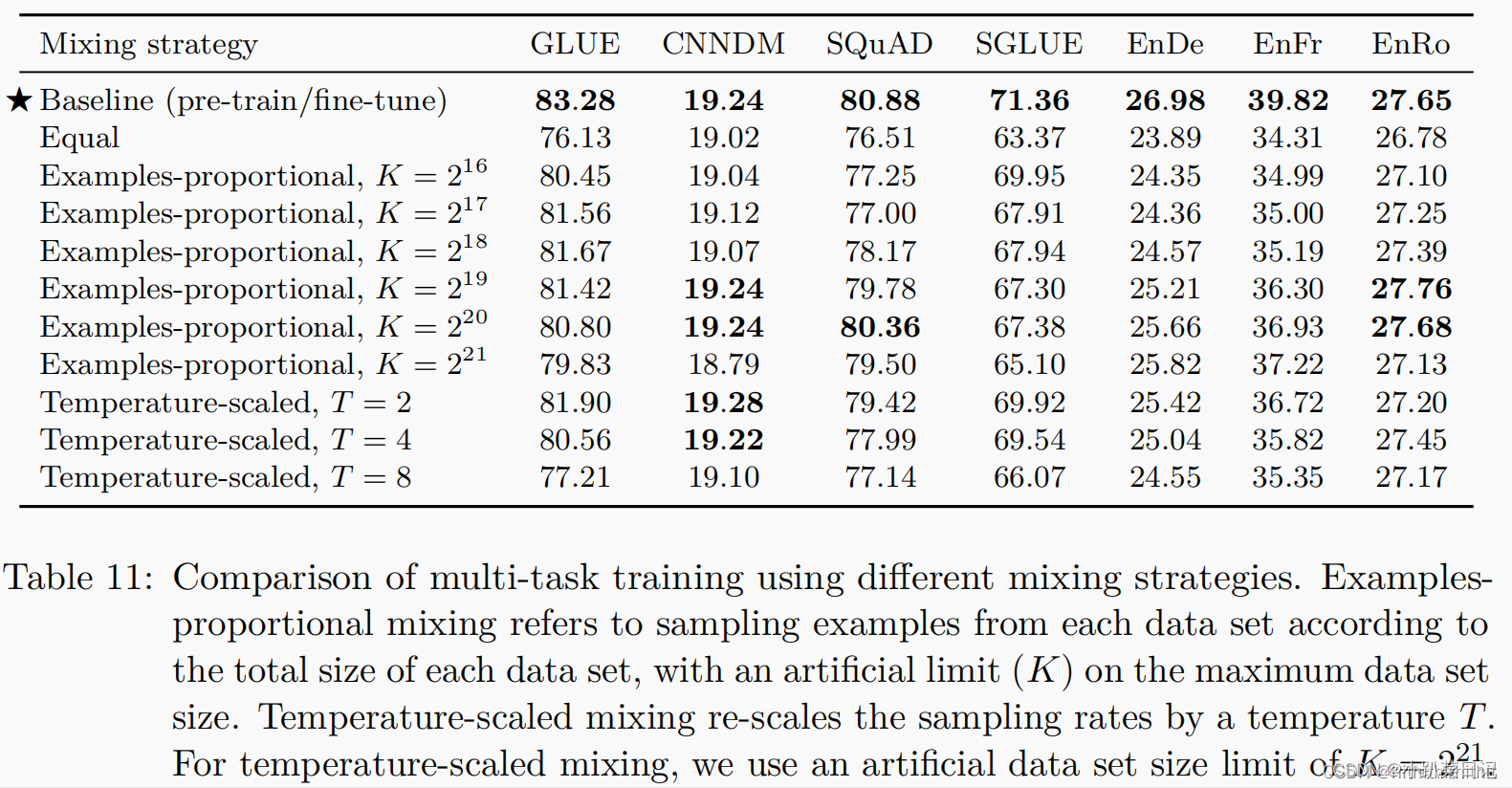
Examples-proportional mixing:模型对给定任务的拟合速度的一个主要因素是数据集的大小。因此,一个常见的做法是设置每个任务数据集的比例。但是,请注意,我们包括了我们的无监督去噪任务,它使用的数据集比其他任务的数据集大几个数量级。由此可见,如果我们简单地按照每个数据集的大小进行抽样,模型看到的绝大多数数据将未标记,并且将在所有监督任务上训练不足。即使没有无监督的任务,某些任务的训练集还是很大,以至于其他任务训练不够。为了解决这个问题,我们在开始计算比例之前设置一个人工的“limit”在数据集的尺寸上面。其中K表示人工设置的数据集尺寸限制。K越大,越倾向于全部采样或者等比例采样,K越小越趋向于均等采样。
Temperature-scaled mixing:设置混合比例的“temperature”,multilingual BERT采用了这种方法以确保模型在低资源上得到充分训练,当T=1的时候,相当于前面的比例混合采样,T越大,越相当于均匀采样。

仅仅多任务训练不微调,效果不如单任务。对于大多数任务,K有一个最佳点。多任务模型比单个的模型在单个任务上较好已经在先前的实验中得到证实,因为多任务设置可以从相似的任务中得到好处。
 多任务有监督预训练+微调:
多任务有监督预训练+微调: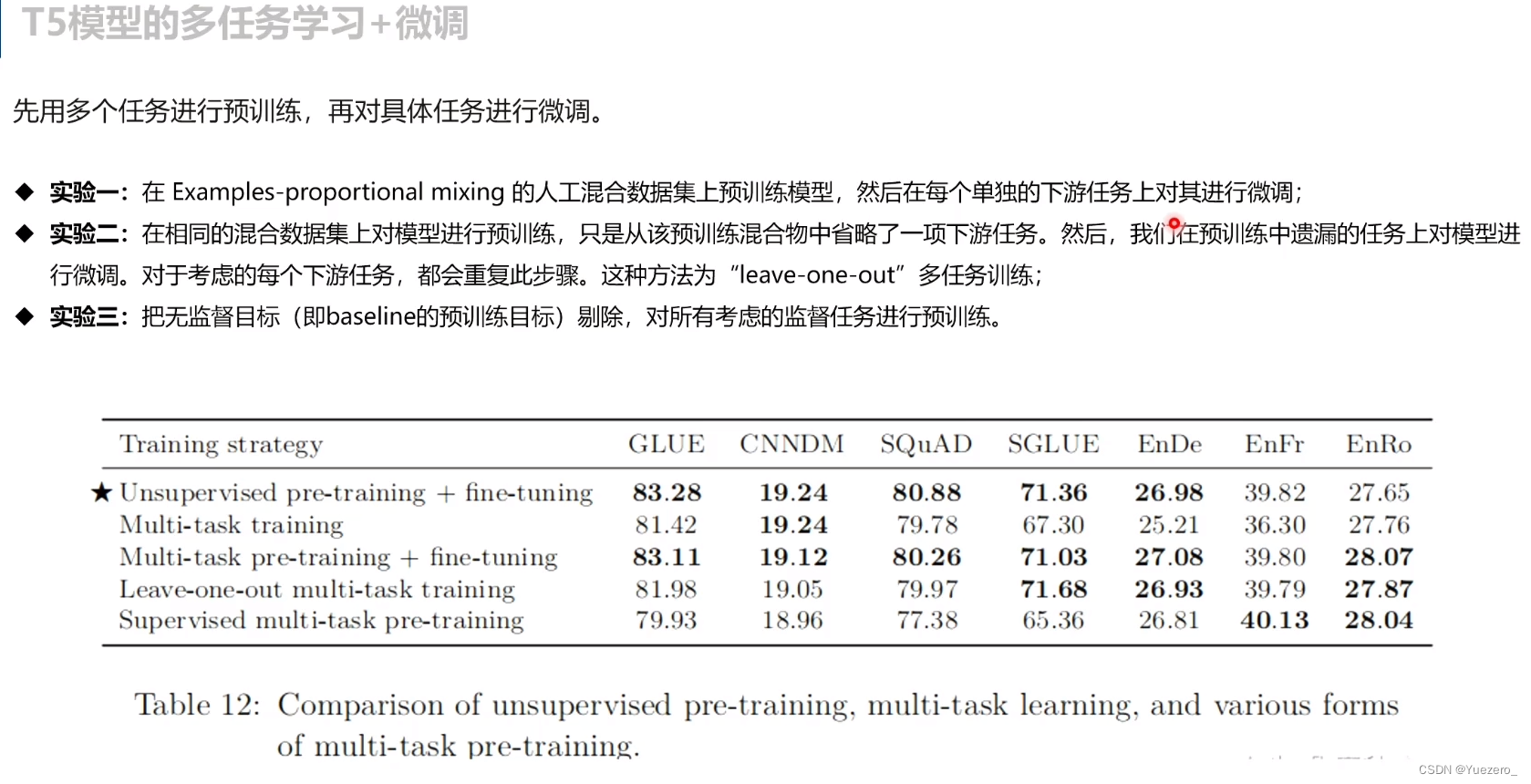
模型规模
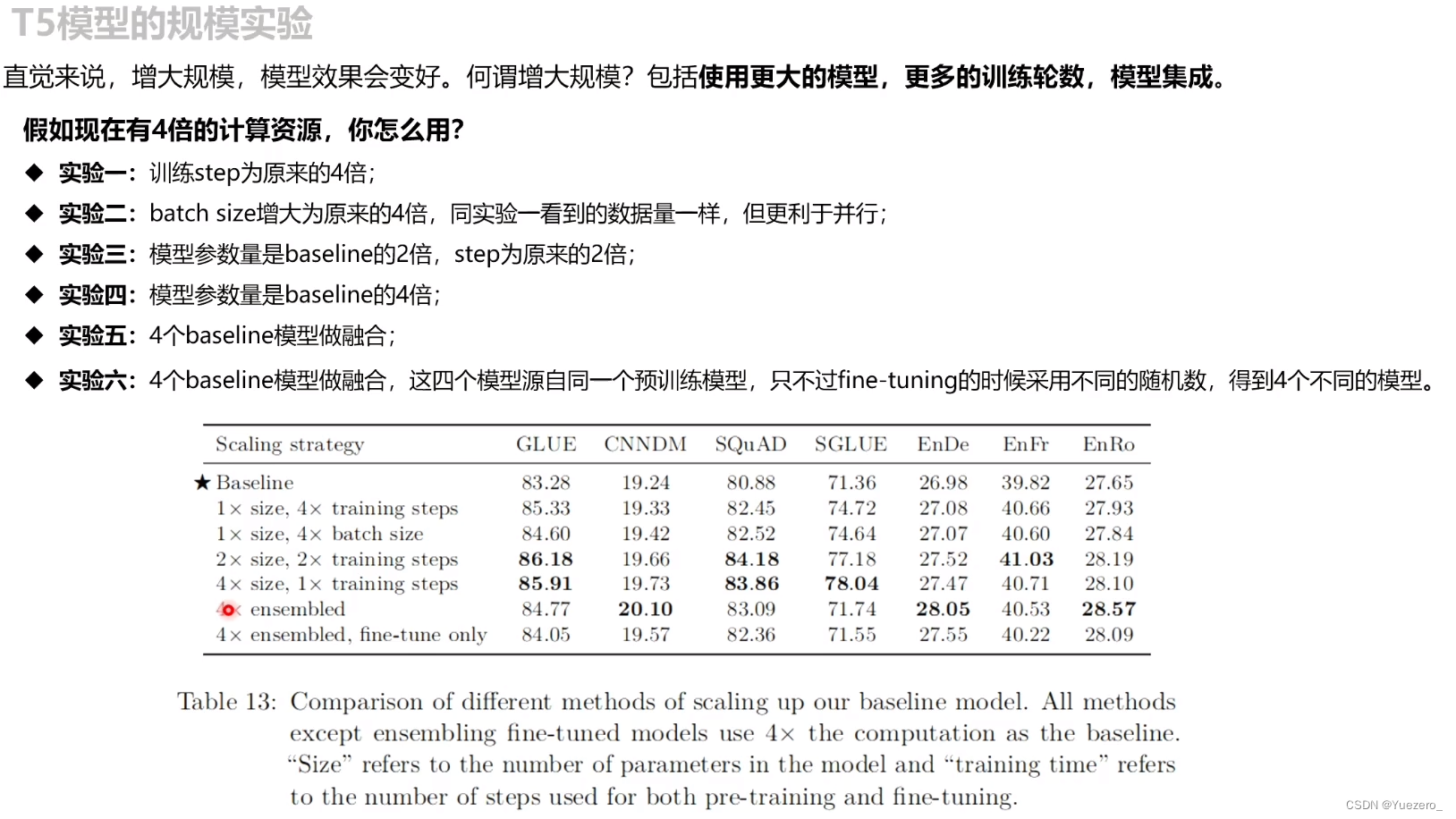
从表中可以看出,
(1) 扩大模型规模和增长训练时间都能提高模型性能;
(2) 将模型扩大到2倍规模,同时训练时间也扩大2倍的效果和将模型扩大到4倍规模的效果差不多,说明增加训练时间和扩大模型规模很可能是两种互补的可以提高模型性能的方法;
(3) emsemble对提高模型性能确实有效
Putting It All Together
我们通过系统的研究,从基础模型开始然后做出以下改变:
Objective:我们使用了IID来对span进行破坏。具体来说,我们使用的平均跨度长度为3,并破坏了原始序列的15%。我们发现,这个目标产生了略好的性能,但是由于目标序列长度较短,计算效率略高。
Longer training:我们的模型使用了相对小的预训练计算量。额外的训练对模型的性能确实是有用的,而且增加批处理的大小和增加训练步骤都可以增加性能。使用较小的C4变体进行重复的训练是有害的,数据集也很重要。
Model sizes:更大的模型可以有效的提高性能。在计算资源有限的情况下,使用更小的模型可能会有所帮助。基于这些因素,我们训练了如下尺寸的模型:
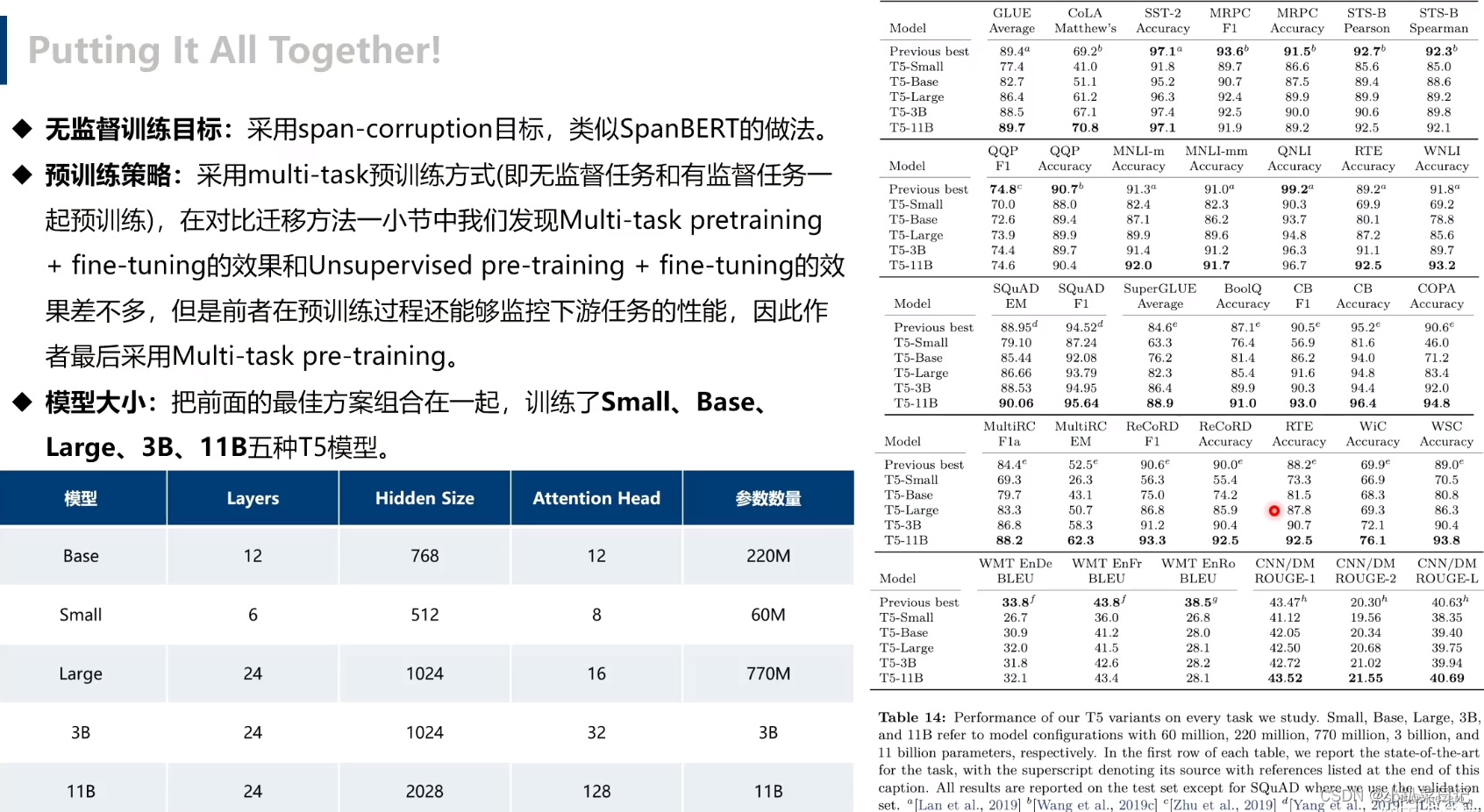 最后就是结合上面所有实验结果,训练了不同规模几个模型,由小到大:
最后就是结合上面所有实验结果,训练了不同规模几个模型,由小到大:
- Small,Encoder 和 Decoder 都只有 6 层,隐维度 512,8 头;
- Base,相当于 Encoder 和 Decoder 都用 BERT-base;
- Large,Encoder 和 Decoder 都用 BERT-large 设置,除了层数只用 12 层;
- 3B(Billion)和11B,层数都用 24 层,不同的是其中头数量和前向层的维度。
- 11B,最后在 GLUE,SuperGLUE,SQuAD,还有 CNN/DM 上取得了 SOTA,而 WMT 则没有。看了性能表之后,我猜想之所以会有 3B 和 11B 模型出现,主要是为了刷榜。看表就能发现
比如说 GLUE,到 3B 时效果还并不是 SOTA,大概和 RoBERTa 评分差不多都是 88.5,而把模型加到 11B 才打破 ALBERT 的记录。然后其他实验结果也都差不多,3B 时还都不是 SOTA,而是靠 11B 硬拉上去的。除了 WMT 翻译任务,可能感觉差距太大,要拿 SOTA 代价过大,所以就没有再往上提。根据这几个模型的对比,可以发现即使是容量提到 11B,性能提升的间隔还是没有变缓,因此我认为再往上加容量还是有提升空间。
mT5
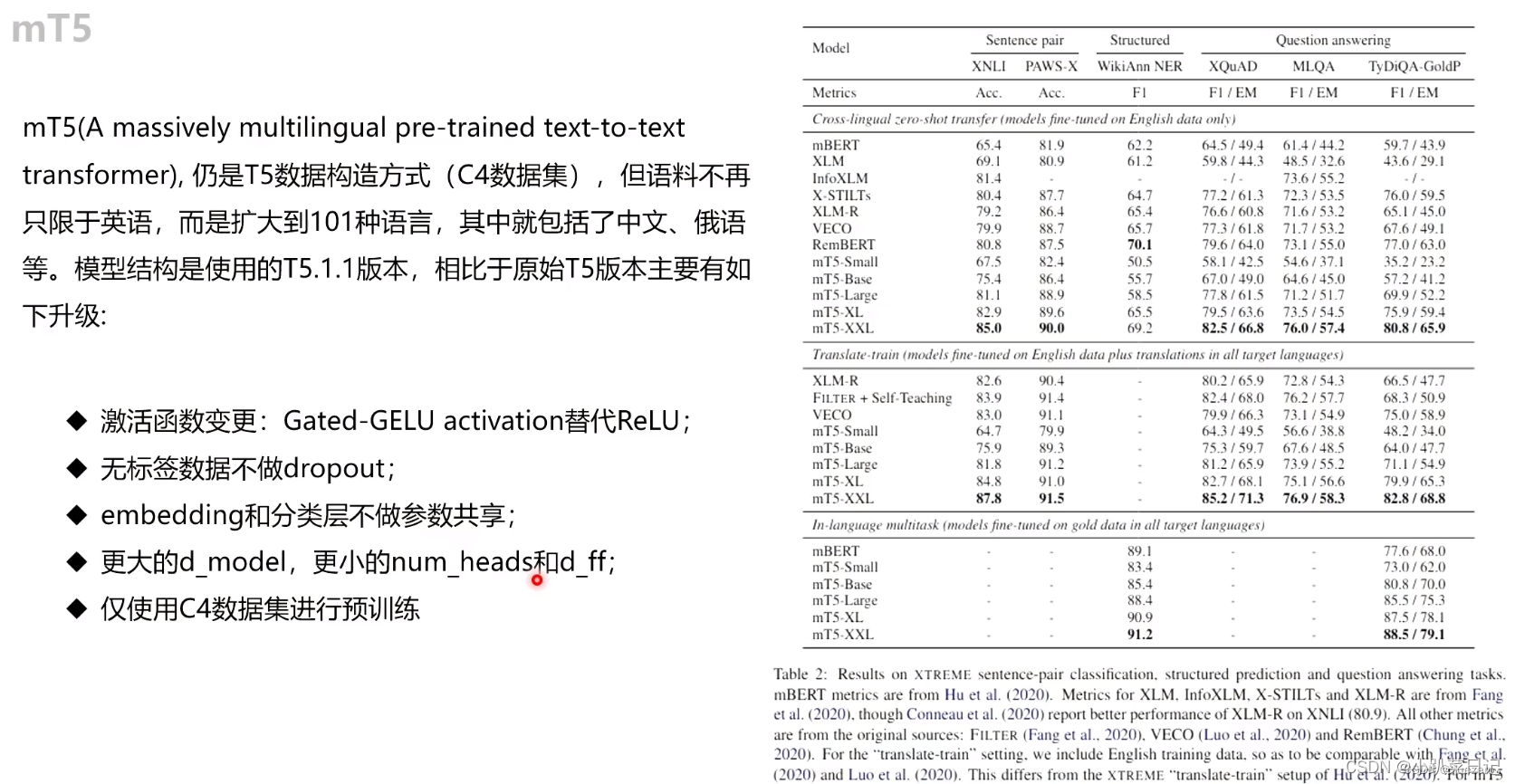 mT5
mT5
不幸的是,许多这样的语言模型仅在英语文本上进行过预训练。鉴于世界上大约80%的人口不会说英语,这极大地限制了它们的使用(Crystal,2008年)。 社区解决这种以英语为中心的方法之一就是发布数十种模型,这些模型已经在一种非英语语言上进行了预训练(Carmo等人,2020; de Vries等人,2019; Le等人 ; 2019; Martin等人,2019; Delobelle等人,2020; Malmsten等人,2020; Nguyen和Nguyen,2020; Polignano等人,2019等)。 一个更通用的解决方案是生成,已经在多种语言的混合中进行了预训练的多语言模型。 这种类型的流行模型是mBERT(Devlin,2018),mBART(Liu等,2020)和XLM-R(Conneau等,2019),它们是BERT的多语言变体(Devlin等,2018)。 ,BART(Lewis等人,2019a)和RoBERTa(Liu等人,2019)。在本文中,我们通过发布mT5(T5的多语言变体)来延续这一传统。 我们使用mT5的目标是生成一个大规模的多语言模型,该模型尽可能少地偏离用于创建T5的方法。 因此,mT5继承了T5的所有优点,例如其通用的文本到文本格式,基于大规模实证研究得出的观点的设计及其规模。 为了训练mT5,我们引入了称为mC4的C4数据集的多语言变体。 mC4包含从公共“Common Crawl”网络抓取中提取的101种语言的自然文本。具体来说,我们基于“T5.1.1”方法建立了mT5,对mT5进行了改进,使用GeGLU非线性(Shazeer,2020年)激活函数,在更大模型中缩放dmodel而不是改变dff, 对无标签数据进行预训练而没有dropout等措施。 为简洁起见,更多详细信息请参考Raffel et al. (2019)。预训练多语言模型的主要因素是如何从每种语言中采样数据。最终,这种选择是零和博弈:如果对低资源语言的采样过于频繁,则该模型可能过拟合;反之亦然。如果高资源语言没有经过足够的训练,则该模型将欠拟合。因此,我们采用(Devlin,2018; Conneau et al.,2019; Arivazhagan et al.,2019)中使用的方法,并根据p(L)∝ |L|α的概率通过采样样本来增强资源较少的语言,其中p(L)是在预训练期间从给定语言采样文本的概率和|L|是该语言中样本的数量。超参数α(通常α<1)使我们可以控制在低资源语言上“boost”训练概率的程度。先前工作使用的值,mBERT(Devlin,2018)是α= 0.7,XLM-R(Conneau等人,2019)的α= 0.3,MMNMT(Arivazhagan等人,2019)的α= 0.2。我们尝试了所有这三个值,发现α= 0.3可以在高资源语言和低资源语言的性能之间做出合理的折衷。我们的模型涵盖了100多种语言,这需要更大的单词表量。 遵循XLM-R(Conneau et al.,2018)之后,我们将单词表量增加到250,000个单词。 与T5一样,我们使用SentencePiece(Kudo and Richardson,2018; Kudo,2018)单词模型,这些单词模型以与训练期间,使用的相同语言采样率进行训练。 为了适应具有大字符集(例如中文)的语言,我们使用0.99999的字符覆盖率,但还启用了SentencePiece的“byte-fallback”特征,以确保可以唯一编码任何字符串。