【CCF BDCI 2023】多模态多方对话场景下的发言人识别 Baseline 0.71 CNN 部分
- 概述
- 数据预处理
- 查看数据格式
- 加载数据集
- 图像处理
- 限定图像范围
- 图像转换
- 加载数据
- CNN 模型
- Inception 网络
- ResNet 残差网络
- 总结
- 参数设置
- 训练 Train
- 模型初始化
- 数据加载
- 训练超参数
- 训练循环
- 验证 Valid
- 验证过程
- 模型评估
- 记录 & 保存
- 测试 Test
- 加载模型
- 加载测试数据
- 预测结果
- 参考文献
概述
CNN (Convolutional Neural Network) 能够自动, 有效的从图像数据中学习空间层次结构. CNN 通过一系列的卷积层 (Convolutional Layer)
, 池化层 (Pool Layer) 和全连接层 (Fully Connected Layer) 来处理图像, 每一层专注于提取图像的不同几倍的特征. 卷积层负责提取局部特征, 如: 边缘和纹理; 池化层负责降低特征空间维度, 增强模型泛化能力; 全连接层则用于最终的分类或回归任务.
Baseline 的代码分为三个文件, 分别为convex_optimization.py, dialog_roberta-constrasive.py, finetune_cnn-multiturn.py. 下面小白我就来带大家详解一下各个部分.
数据预处理
再多模态发言人识别中, 数据预处理的目的是将原视频 (帧图片) 转换为我们可以理解和处理的格式. 包括下面三个部分: 加载数据集, 图像转换和数据增强.
查看数据格式
小白我先带大家来看一下数据的格式, 我们先打开train-metada.jason, 下面是文件的样子:

查看文件长度:
# 读取 jason
train_metadata = json.load(open('../final_dataset-5_turns_chusai/train-metadata.json'))
print(len(train_metadata))
print(train_metadata[0])
输出结果:
13584
[{"frame": "s06e07-000377", "speaker": "phoebe", "content": "Yeah, I know because you have all the good words. What do I get? I get \"it\u2019s,\" \"and\" oh I'm sorry, I have \"A.\" Forget it.", "start": 297, "end": 491, "faces": [[[752, 135, 881, 336], "rachel"], [[395, 111, 510, 329], "leslie"]]}, {"frame": "s06e07-000504", "speaker": "rachel", "content": "Phoebe, come on that's silly.", "start": 498, "end": 535, "faces": [[[466, 129, 615, 328], "phoebe"]]}, {"frame": "s06e07-000552", "speaker": "phoebe", "content": "All right, so let's switch.", "start": 535, "end": 569, "faces": [[[426, 120, 577, 320], "phoebe"]]}, {"frame": "s06e07-000629", "speaker": "rachel", "content": "No, I have all of the good words. OK, fine, fine, we can switch.", "start": 569, "end": 689, "faces": [[[420, 125, 559, 328], "phoebe"], [[652, 274, 771, 483], "rachel"]]}, {"frame": "s06e07-000892", "speaker": "phoebe", "content": "Please...wait, how did you do that?", "start": 879, "end": 906, "faces": [[[424, 133, 573, 334], "phoebe"], [[816, 197, 925, 399], "bonnie"]]}]
结合图片我们可以看出 train 数据由 13584 条数据组成, 每条数据包含 5 段发言, 每段发言包含:
- frame: 图片对应的帧, 例如: s06e07-000377
- speaker: 发言人, 共计 11 人, 例如: phoebe
- content: 发言内容
- start: 开始帧
- end: 结束帧
- faces: 包含多个人脸的列表, 例如:
[[[752, 135, 881, 336], "rachel"], [[395, 111, 510, 329], "leslie"]]. 其中每个人脸包含 2 部分数据:- 坐标数据: [x1, y1, x2, y2], 分别表示人脸左上到右下的框, 例如:
[752, 135, 881, 336] - 人脸归属: 坐标中人脸对应的任务, 例如: rachel
- 坐标数据: [x1, y1, x2, y2], 分别表示人脸左上到右下的框, 例如:

加载数据集
下面我们来讲一下代码中的 FaceDataset 类, 这个类的主要功能是从指定的数据集中加载图像和标签, 并对图像进行必要的预处理. FaceDataset 根据不同的数据集分割加载相应的元数据, 并从中提取出每个帧的面部数据及其对应的标签. 这些信息被用于后续的模型训练和评估.
class FaceDataset:def __init__(self, base_folder, transform='default', split='train', debug=False):# 设置图像文件的基本路径self.frames_path = os.path.join(base_folder, 'images')# debug模式用于快速测试(加载较少的数据)self.debug = debug# 数据集的分割类型(训练、测试或验证)self.split = split# 根据数据集的分割类型加载相应的元数据文件if split == 'test':metadata = json.load(open(os.path.join(base_folder, 'test-metadata.json')))elif split == 'test-hard':metadata = json.load(open(os.path.join(base_folder, 'test-hard-metadata.json')))else:metadata = json.load(open(os.path.join(base_folder, 'train-metadata.json')))
baseline 选择了 s01 开头的人脸作为厕所集, 其他作为训练集.
# 初始化存储样本和标签的列表self.examples, self.labels = list(), list()# 用于记录已处理的帧,避免重复处理frames_met = set()# 遍历元数据中的每个对话数据for dialog_data in metadata:# 遍历对话中的每个帧数据for frame_data in dialog_data:# 如果是验证集,只选择以's01'开头的帧if split == 'valid' and not frame_data['frame'].startswith('s01'):continue# 如果是训练集,排除以's01'开头的帧if split == 'train' and frame_data['frame'].startswith('s01'):continue# 检查帧是否已经处理过if frame_data['frame'] in frames_met:continue# 记录已处理的帧frames_met.add(frame_data['frame'])# 获取帧中的所有面部数据faces = frame_data['faces'] # [(bbox, id), (bbox, id), ...]
图像处理
限定图像范围
计算图片面积, 用于过滤无效图片.
def calculate_area(bbox):return (bbox[2] - bbox[0]) * (bbox[3] - bbox[1])
接着讲上面的 FaceDataset 部分, 再上面我们已经获得了每条数据每帧的人脸: Faces, 下面是如何获取 face 对应的 frame, face_label, bbox, label:
# 遍历每个面部数据
for bbox, face_label in faces:# 确保边界框的坐标在合理范围内bbox = [max(i, 0) for i in bbox]bbox = [min(bbox[0], 1280), min(bbox[1], 720), min(bbox[2], 1280), min(bbox[3], 720)]# 如果边界框面积为0,则跳过此面部if calculate_area(bbox) <= 0:continue# 标签为1如果面部是说话者,否则为0label = int(face_label == frame_data['speaker'])# 添加样本和标签到列表self.examples.append((frame_data['frame'], face_label, bbox, label))self.labels.append(label)
因为数据存在负数, 使用 max 和 min 限定标注为图片范围.
图像转换
我们需要将原始图像转化为我们需要的格式, 使得 CNN 模型能有效的处理数据. 这一过程包括调整图像大小, 标准化和图像增强.
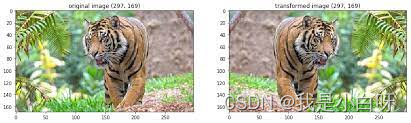
代码:
if transform == 'default':self.train_transform = transforms.Compose([np.float32,transforms.ToTensor(),transforms.RandomHorizontalFlip(p=0.5),transforms.RandomAffine(degrees=20, shear=20),transforms.Resize((512, 512)),fixed_image_standardization])self.valid_transform = transforms.Compose([np.float32,transforms.ToTensor(),transforms.Resize((512, 512)),fixed_image_standardization])
else:self.train_transform = transformself.valid_transform = transform
- 调整图像大小:
transforms.Resize((512, 512)), 将所有人脸调整为固定的 512*512 像素, 便于后续的 CNN 处理. FYI: 大部分 CNN 模型的输入都会拉成正方形 - 数据标准化:
fixed_image_standardization, 具体为:- 缩放像素值, 通过像素值 / 255, 将像素值范围从 [0, 255] 缩放到 [0, 1]
- 均值和标准差归一化 (Mean & Standard Deviation Normalization): 使得像素具有特定的均值和标准差. 具体的文档我没找到, 但是 ImageNet 的均值用的是 [0.485, 0.456, 0.406], 标准差是[0.229, 0.224, 0.225]
- 数据增强: baseline 使用的数据增强分为 2 部分: 水平翻转和随机仿射变换:
- 随机水平翻转:
transforms.RandomHorizontalFlip(p=0.5), 按照 0.5 的概率进行水平翻转图像. 通过水平翻转的增强, 模型可以学习到不同方向的特征, 增强模型的泛化性. 再人脸任任务中, 此方法特别使用, 因为左右脸是对称的 (差不多对称) - 随机仿射变化:
transforms.RandomAffine(degrees=20, shear=20), 包括旋转, 缩放, 评议和剪切,degrees=20, 随机旋转上限 20 度,shear=20, 剪切上限 20 度, 通过仿射变化, 对图片进行各种视角和姿态的变化, 可以提高模型对人脸图片的姿势和表情的泛化能力
- 随机水平翻转:
加载数据
__len__方法和__getitem__方法是继承自 PyTorch 数据集类 (Dataset). 下面小白我来分别解释一下两种方法.
__len__方法:
def __len__(self):return len(self.examples) if not self.debug else 32
- 不在调试模式下: 返回
self.example列表长度 - 调试模式下: 返回 32 样本
_get_item方法, 也是 Dataset 类的一个标准接口:
def __getitem__(self, index):frame_name, face_label, bbox, label = self.examples[index]image = cv2.imread(os.path.join(self.frames_path, frame_name + '.jpg'))image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)image = image[bbox[1]:bbox[3], bbox[0]:bbox[2]]if self.split == 'valid' or self.split.startswith('test'):image = self.valid_transform(image)return image, label, frame_name, face_labelelse:image = self.train_transform(image)return image, label
- 提取样本信息:
self.examples列表中获取指定的样本, 包含: 帧名 (frame_name), 人脸标签 (face_label), 边界框 (bbox), 标签 (label) - 加载和处理图像: 使用
cv2.iamge读取 bbox 中的 人脸, 这个就不细说了 - 应用图像转换: 再训练集使用
self.train_transform, 验证集和测试集使用slef.valid_transform - 返回处理后的样本
__getitem__法的实现确保了每次请求数据集时都能获取到正确处理和转换后的图像样本.
CNN 模型
InceptionResnetV1 结合了 Inception 和 ResNet (残差网络) 的特点.
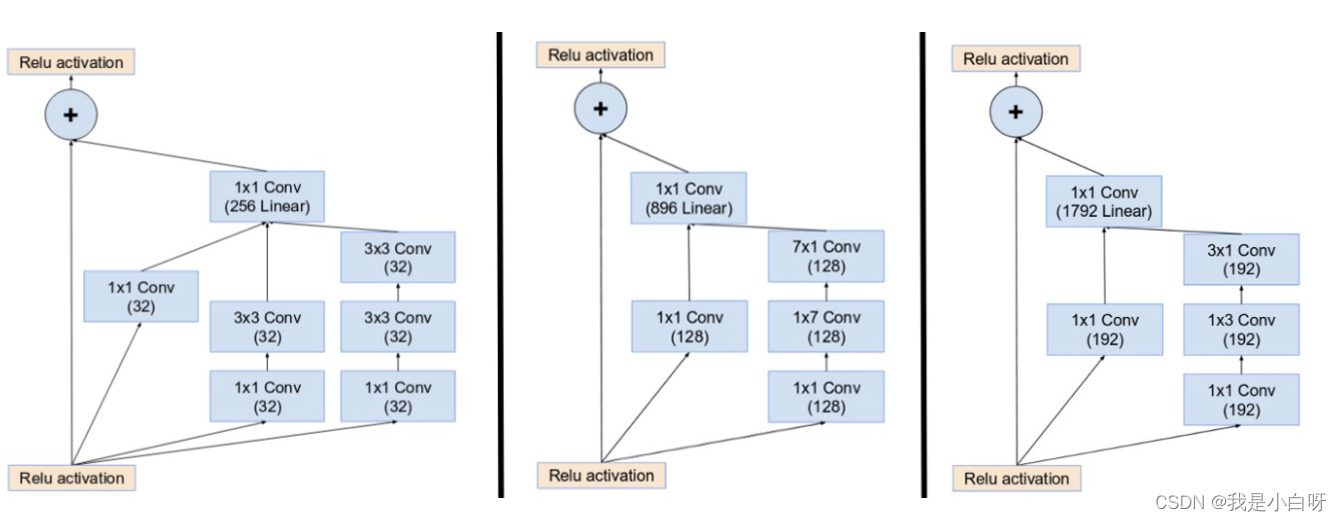
Inception 网络
Inception 由 GoogleNet 提出, 核心思想是在网络上同一层使用多种不同尺寸的卷积核 (Convolution Kernel), 以提取不同尺度的特征. 较小的卷积核可以捕捉到细节特征, 较大的卷积核则能捕捉大范围的特征.
ResNet 残差网络
ResNet 通过残差连接, 将前一层的输出结果添加到后面的层上, 解决深度学习中的梯度消失问题 (Vanishing Gradient Problem), 使得网络的层数得以加深.
关于梯度消失和梯度爆炸的详解, 参考我这篇博客.
总结
InceptionResnetV1 在 Inception 模块的基础上加入了残差连接. 以保持Inception 模块多尺度特征提取优势的同时, 避免了深层网络可能出现的梯度相关问题.
参数设置
argprase
# 创建一个ArgumentParser对象,用于解析命令行参数
parser = argparse.ArgumentParser()# 添加'--func'参数,用于指定脚本的功能模式(如'test'或'train')。默认值为'test'。
parser.add_argument('--func', type=str, default='test')# 这行代码被注释掉了,但它展示了如何添加另一个'--func'参数的例子,其默认值为'train-friends'。
# parser.add_argument('--func', type=str, default='train-friends')# 添加'--debug'参数,这是一个标志参数。如果在命令行中出现,则其值为True,否则为False。
parser.add_argument('--debug', action='store_true')# 添加'--load_pretrained'参数,用于控制是否加载预训练模型。它是一个整数类型,1表示加载,0表示不加载。默认值为1。
parser.add_argument('--load_pretrained', type=int, default=1)# 添加'--data_base_folder'参数,用于指定数据集的基本路径。默认值为'../final_dataset-5_turns_chusai'。
parser.add_argument('--data_base_folder', type=str, default='../final_dataset-5_turns_chusai')# 添加'--batch_size'参数,用于指定批处理大小。默认值为16。
parser.add_argument('--batch_size', type=int, default=16)# 添加'--num_workers'参数,用于指定数据加载时使用的工作线程数。默认值为2。
parser.add_argument('--num_workers', type=int, default=2)# 添加'--num_epochs'参数,用于指定训练的总周期数。默认值为40。
parser.add_argument('--num_epochs', type=int, default=40)# 添加'--lr'(学习率)参数,用于指定优化器的学习率。默认值为0.001。
parser.add_argument('--lr', type=float, default=0.001)# 添加'--weight_decay'参数,用于指定优化器的权重衰减。默认值为0。
parser.add_argument('--weight_decay', type=float, default=0.)# 添加'--decay_interval'参数,用于指定学习率衰减的间隔周期。默认值为3。
parser.add_argument('--decay_interval', type=int, default=3)# 添加'--output_path'参数,用于指定输出文件的路径。默认值为'out'。
parser.add_argument('--output_path', type=str, default='out')# 添加'--model_ckpt'参数,用于指定模型检查点的路径。默认值为'../ckpts/5_turns/cnn-best_model.pth'。
parser.add_argument('--model_ckpt', type=str, default='../ckpts/5_turns/cnn-best_model.pth')# 解析命令行输入的参数
args = parser.parse_args()# 打印解析得到的参数值
print(args)
训练 Train
模型初始化
if args.func.split('-')[0] == 'train':if args.load_pretrained:resnet = InceptionResnetV1(classify=True, pretrained='../pretrain_model/torch/20180402-114759-vggface2.pt', num_classes=2).to(device)else:resnet = InceptionResnetV1(classify=True, num_classes=2).to(device)softmax = torch.nn.Softmax()
- 判断是否为 train
- 判断是否加载预训练模型 vggfacenet2
- 初始化 softmax 激活函数, 将最终概率限制到 [0, 1]
数据加载
train_dataset = FaceDataset(args.data_base_folder, split='train', debug=args.debug)
valid_dataset = FaceDataset(args.data_base_folder, split='valid', debug=args.debug)
train_loader = DataLoader(train_dataset, num_workers=args.num_workers, batch_size=args.batch_size, shuffle=True, drop_last=True)
valid_loader = DataLoader(valid_dataset, num_workers=args.num_workers, batch_size=args.batch_size, shuffle=False)
使用 Dataloader 加载训练和验证数据.
训练超参数
loss_fn = torch.nn.CrossEntropyLoss()
metrics = {'fps': training.BatchTimer(), 'acc': training.accuracy}
writer = SummaryWriter(os.path.join(args.output_path, 'tensorboard_logs'))
optimizer = optim.Adam(resnet.parameters(), lr=args.lr, weight_decay=args.weight_decay)
scheduler = MultiStepLR(optimizer, list(range(args.decay_interval, args.num_epochs, args.decay_interval)))
- loss_fn: 损失函数, 交叉熵
- metrics: 评估标准, acc
- optimizer: 优化器, Adam
- scheduler: 学习率递减
训练循环
for epoch_i in range(args.num_epochs):print('\nEpoch {}/{}'.format(epoch_i + 1, args.num_epochs))resnet.train()train_loss, train_metrics = training.pass_epoch(resnet, loss_fn, train_loader, optimizer, scheduler,batch_metrics=metrics, show_running=False, device=device,writer=writer)
training.pass_epoch: 是封装好的函数, 用于训练数据
验证 Valid
验证过程
with torch.no_grad():resnet.eval()test_output = dict()for images, labels, frame_names, face_labels in valid_loader:images = images.to(device)labels = labels.to(device)y_preds = softmax(resnet(images))[:, 1]for y_pred, frame_name, face_label, label in zip(y_preds, frame_names, face_labels, labels):y_pred = float(y_pred.cpu())label = int(label.cpu())if frame_name not in test_output:test_output[frame_name] = dict()test_output[frame_name][face_label] = {'pred': y_pred, 'label': label}
- 禁用梯度:
with torch.no_grad() - 模型评估模式:
resnet.eval(), 忽略 Droupout 和 Batch Normalization 层, 具体表现为eval()的 Dropout 不会关闭神经元, Batch Normalization 会使用训练的全局均值和方差, 而不是根据每个 batch 调整
模型评估
计算帧准确率 (acc):
val_metrics = dict()
frame_acc_dict, dialog_acc_list = dict(), list()
for frame_id, frame_pred in test_output.items():y_preds = [i['pred'] for i in frame_pred.values()]y_golds = [i['label'] for i in frame_pred.values()]if not any(y_golds): # 都是0,说明说话人不在frame中frame_acc_dict[frame_id] = 0else:frame_acc_dict[frame_id] = (np.argmax(y_preds) == np.argmax(y_golds))val_metrics['frame_acc'] = sum(frame_acc_dict.values()) / len(frame_acc_dict)
计算对话准确率 (acc):
val_metadata = json.load(open(os.path.join(args.data_base_folder, 'train-metadata.json')))
for dialog_data in val_metadata:for frame_data in dialog_data:if frame_data['frame'] in frame_acc_dict:dialog_acc_list.append(frame_acc_dict[frame_data['frame']])
val_metrics['dialog_acc'] = sum(dialog_acc_list) / len(dialog_acc_list)
记录 & 保存
for key in val_metrics:writer.add_scalar('valid/' + key, val_metrics[key], epoch_i)print('epoch %d' % epoch_i)
print('dialog level acc: {}'.format(val_metrics['dialog_acc']))
print('val acc: {}, best_acc: {}'.format(val_metrics['frame_acc'], best_acc))
if val_metrics['frame_acc'] > best_acc:best_acc = val_metrics['frame_acc']torch.save(resnet.state_dict(), os.path.join(args.output_path, 'best_model.pth'))json.dump(test_output, open(os.path.join(args.output_path, 'valid_output.json'), 'w'))
- 记录评估指标
- 控制台输出评估指标
- 保存模型
测试 Test
加载模型
elif args.func.startswith('test'):resnet = InceptionResnetV1(classify=True, num_classes=2).to(device)resnet.eval()print('loading checkpoint from %s' % args.model_ckpt)resnet.load_state_dict(torch.load(args.model_ckpt))softmax = torch.nn.Softmax()
- 初始化模型: InceptionResnetV1
- 设置评估模式:
reset.eval() - 加载训练好的模型:
resnet.load_state_dict(torch.load(args.model_ckpt))
加载测试数据
for split in ['test', 'test-hard']:test_dataset = FaceDataset(args.data_base_folder, split=split, debug=args.debug)test_loader = DataLoader(test_dataset, num_workers=args.num_workers, batch_size=args.batch_size, shuffle=False)
- 分别加载 test / test-hard 测试数据
预测结果
with torch.no_grad():resnet.eval()test_output = dict()for images, labels, frame_names, face_labels in test_loader:images = images.to(device)labels = labels.to(device)y_preds = softmax(resnet(images))[:, 1]for y_pred, frame_name, face_label, label in zip(y_preds, frame_names, face_labels, labels):y_pred = float(y_pred.cpu())label = int(label.cpu())if frame_name not in test_output:test_output[frame_name] = dict()test_output[frame_name][face_label] = {'pred': y_pred, 'label': label}test_metrics = dict()
frame_acc_dict, dialog_acc_list = dict(), list()
for frame_id, frame_pred in test_output.items():y_preds = [i['pred'] for i in frame_pred.values()]y_golds = [i['label'] for i in frame_pred.values()]if not any(y_golds): # 都是0,说明说话人不在frame中frame_acc_dict[frame_id] = 0else:frame_acc_dict[frame_id] = (np.argmax(y_preds) == np.argmax(y_golds))test_metrics['frame_acc'] = sum(frame_acc_dict.values()) / len(frame_acc_dict)
if split.startswith('test'):test_metadata = json.load(open(os.path.join(args.data_base_folder, 'test-metadata.json')))
else:test_metadata = [example for example in json.load(open(os.path.join(args.data_base_folder, 'train-metadata.json'))) if example[0]['frame'].startswith('s01')]for dialog_data in test_metadata:for frame_data in dialog_data:if frame_data['frame'] in frame_acc_dict:dialog_acc_list.append(frame_acc_dict[frame_data['frame']])else:dialog_acc_list.append(0) # 没有人脸,因此本模型无从判断
test_metrics['dialog_acc'] = sum(dialog_acc_list) / len(dialog_acc_list)print('dialog level acc: {}'.format(test_metrics['dialog_acc']))
print('frame level acc: {}'.format(test_metrics['frame_acc']))
json.dump(test_output, open(os.path.join(args.output_path, '%s_output.json' % split), 'w'))
将测试过程中的输出保存为 json 文件.
参考文献
比赛链接
上述代码均源自比赛 Baseline