C-3PO: Cyclic-Three-Phase Optimization for Human-Robot Motion Retargeting based on Reinforcement Learning解析
- 摘要
- 1. 简介
- 2. 相关工作
- 2.1 运动重定向(Motion Retargeting)
- 2.2 强化学习(Reinforcement Learning)
- 3. 预备知识
- 3.1 深度强化学习
- 3.2 Source Dataset
- 3.3 数据预处理
- 4. 方法
- 4.1 问题表述
- 4.2 阶段1:学习潜在的Manifold
- 4.3 阶段2:学习映射功能
- 4.4 阶段3:通过微调进行策略优化
- 4.5 n-Step Monte-Carlo Learning
论文链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9196948&tag=1
论文代码:https://github.com/gd-goblin/C-3PO_Motion_Retargeting_Module
论文出处:2020 ICRA
论文单位:Korea University of Science and Technology,韩国
摘要
- 在不同尺寸和运动学构型的同质多形体之间进行运动重定位需要全面的(逆)运动学知识。
- 此外,提供一个与运动无关的通解是困难的。
- 在本研究中,我们开发了一种基于深度强化学习的人-机器人运动重定向**循环三阶段(cyclic three-phase)**优化方法。
- 该方法通过循环路径和滤波路径在潜在空间中使用精细数据进行运动重定向学习。
- 此外,基于人在环的三阶段方法从定量和定性两方面为改进运动重定向策略提供了一个框架。
- 利用所提出的C-3PO方法,我们成功地学习了NAO、Pepper、Baxter和C-3PO等多个机器人在人体骨骼和运动之间的运动重定向技能。
1. 简介
- 人类可以毫不费力地模仿不同体型的人甚至动物的动作。
- 这是因为人类具有非凡的运动重定向技能,从视觉信息中掌握目标的运动属性,并将其与自己的关节适当地连接起来。
- 运动重定向技术对人类来说并不困难,但对机器人来说却是一项具有挑战性的任务,因为它需要复杂的算法来理解运动属性、正确映射源和目标之间的关系以及处理特殊情况。
- 虽然有一些局限性,但已经提出了几种方法来教机器人的运动重定向。
- 例如,直接关节映射和基于逆运动学(IK)求解器的方法需要机器人运动学专业知识,并且由于它们的运动学构型不同,难以推广。它们还存在奇异位置问题和高IK计算成本的问题。
- 最近基于学习的方法从视觉传感器,动作捕捉(MoCap)和虚拟现实(VR)设备收集的演示中学习模仿技能。然而,基于视觉的采样(如人体骨骼)是非常嘈杂和不稳定的。MoCap和VR方法需要额外的成本,并且不方便佩戴。
- 直接教学(Direct teaching,DT) 直观地生成各种机器人动作,因为用户可以通过自己的手自由配置机器人的姿势。然而,由于与硬件的物理交互和相关的教学时间,它在收集大量演示时存在局限性。
- 在我们之前的工作中,我们设计了一个基于 actor-critic 的简单网络架构,仅使用骨架编码器和基于已知架构机器人的运动解码器。然而,critic 网络的输入不足以评估 actor 的质量,因为它应该基于编码的骨架,而不是完整的运动学配置。此外,编码骨架直接反映了原始输入骨架的严重噪声。
- 在本文中,为了克服这些限制,我们提出了一种先进的方法来改进我们在之前的工作开发的三相框架(three-phase framework),用于学习鲁棒的人机运动重定向技能。
- 在改进的框架中,我们引入了新的滤波和循环路径结构来处理有噪声的输入,并以更丰富的状态信息更好地评估参与者。
- 在强化学习中,广泛使用的时间差分(TD)方法在马尔可夫环境下有效地工作。如果机器人任务处于马尔可夫环境中,机器人代理的状态不仅应该包括角度位置,还应该包括角速度,以便从当前状态预测下一个状态。然而,低成本电机如Dynamixel可能无法提供准确的角速度,因为传感器误差和控制系统中的延迟。
- 因为我们的目标是建立一个可以应用于这种低成本系统的模型,我们将我们的运动重定向建模为一个非马尔可夫问题,其中智能体的状态只有位置信息而没有速度。我们尝试学习基于MonteCarlo (MC)方法的运动重定向策略,该方法在非马尔可夫环境下比TD方法更有效地工作。
- 我们的主要贡献可以概括如下:
(1)我们通过重用之前工作中忽略的网络提出了一种新的架构。
(2)基于新提出的循环路径和滤波路径,我们定义了扩展的潜在状态和改进的奖励函数。这比我们以前的工作显示出更高的性能。
(3)基于六个运动类的统一策略和编码器-解码器网络,我们证明了我们的模型可以在非马尔可夫环境下使用MC方法充分执行人机运动重定向。
2. 相关工作
运动重定向已经引起了包括机器人和计算机图形学在内的许多研究领域的极大关注。在本节中,我们回顾了运动重定向和强化学习的相关研究。
2.1 运动重定向(Motion Retargeting)
- 在机器人领域,对人体运动和类人机器人之间的运动重定向进行了大量的研究。
- Behzad等人提出了一种基于约束IK求解器的在线运动重定向方法,该方法将深度传感器获取的人体运动信息传递给仿人机器人ASIMO。
- Sen等人从深度传感器的3D点云中估计一个人的姿态,并将其姿态重新定位到一个没有任何骨骼和关节限制的类人机器人。
- Ko等人提出了一种运动重定向方法,该方法同时解决了运动变形和运动优化的几何参数辨识问题。
- 利用动作捕捉传感器,基于 IK 求解器的从人到机器人的运动重定向方法近年来得到了广泛的研究。
- 尽管大多数运动重定向研究都使用了基于IK求解器的方法,但在本研究中,我们将深度强化学习(DRL) 应用于运动重定向,而不使用任何IK求解器。我们还利用微调方法在主学习后进行姿态校正。
2.2 强化学习(Reinforcement Learning)
- 近年来,强化学习(RL)已被用于各种研究领域,包括电脑游戏、机器人和动画,并且优于以前的方法。
- 机器人领域的许多研究将强化学习用于特定任务,如投球、拾取和放置、基于视觉的机器人抓取、机器人导航以及日常生活中的其他机器人任务。
- 在我们的学习模型中,我们采用了参考运动和基于变分自编码器(VAE) 网络架构的PPO算法。
3. 预备知识
3.1 深度强化学习
- 我们将运动重定向建模为一个infinite-horizon discounted partially observable Markov decision process (POMDP)的元组:M = {S,O,A,T,r,γ,S}。
状态空间S,部分观测空间O,动作空间A,状态转移概率函数T,奖励函数r:S × A >R,折现因子γ ∈ (0;1],初始状态分布S。
智能体的目标是学习一个确定性策略π:O >A 在无限范围内最大化预期折现奖励

其中返回值定义如下

- 我们采用基于PPO的 actor-critic算法来学习 w for the actor and ζ for the critic network。
- critic network 评估政策的行动价值。
- 我们定义了一个Q函数,它描述了在策略 π 下的期望收益,参数为 ζ,从动作 a_t 在状态s_t,如下所示
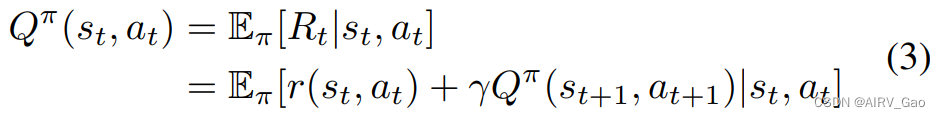
3.2 Source Dataset
- 为了学习人机运动重定向技能,我们使用了公共人体运动数据集NTU-DB。
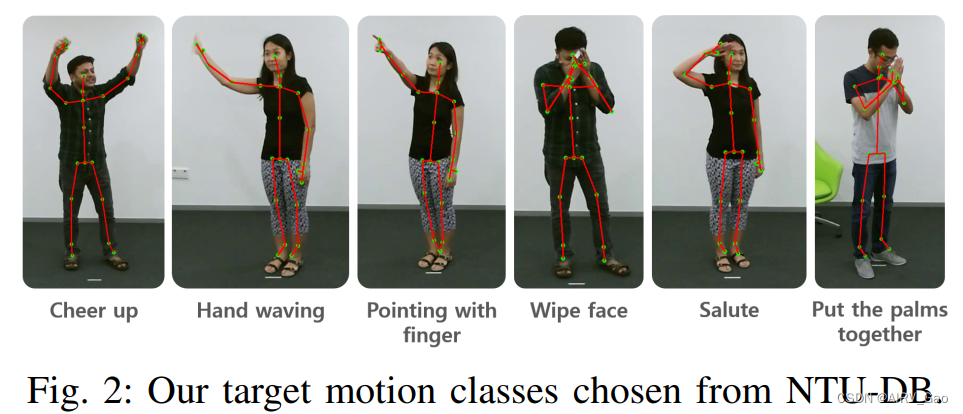
- 在60个运动类别中,选择12个运动类别,排除了shake head 等6个运动类别,因为仅使用骨架无法识别这些运动。最终确定的6个动作类别是:{fcheer up,hand waving, pointing with finger, wipe face, salute, and put the palms togetherg},如图2所示:
- 我们还排除了噪声严重的数据,将90%的数据用于训练,剩余的10%用于评估(表1)。

3.3 数据预处理
- NTU-DB的骨架数据以相机坐标给出,而机器人数据以躯干坐标给出。
- 由于第二阶段的奖励是使用方向向量相似度来计算的,因此骨骼和机器人之间的坐标对齐过程是必不可少的。
- 为了正确对齐,我们做了以下假设。至少在选定的运动类中:
(1)腰部不存在弯曲的姿势。
(2)因此,肩膀、躯干和骨盆在骨骼中的中心关节是共面的。
(3)从左肩关节到右肩关节的向量总是平行于地面。 - 基于这些假设,我们分两步执行坐标对齐:
(1)关于(w.r.t)骨架躯干框架的归一化
(2)转动 w.r.t 机器人基架。 - 第一步,每个骨架关节位置通过减去所有骨骼关节的躯干位置而归一化.
- 第二步,我们首先需要为机器人躯干框架创建一个相同的局部坐标。

- 我们可以计算出 anterior axis 通过 u’,获得 cranial vector 通过 w。
- 从归一化的局部坐标系坐标系出发,建立方向余弦矩阵(DCM),利用DCM转置变换相机坐标系下的骨架,该矩阵与机器人基坐标系矩阵 I 相同
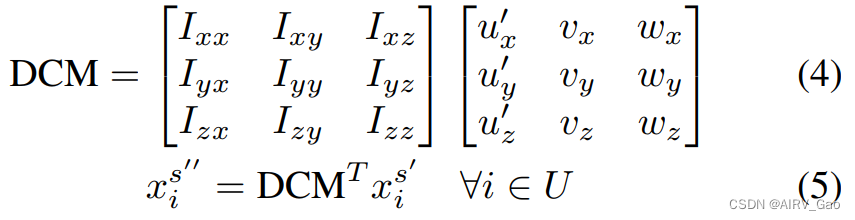
4. 方法
在本节中,我们将详细描述我们的 three-phase framework,包括过滤和循环路径。同时,介绍了n-step MC 及其公式。
4.1 问题表述
- 骨架生成函数 fs 取人体姿态 Dt 在时刻 t 的图像,生成与输入人体姿态对应的骨架向量 xs_t = fs(Dt),其中原始骨架数据包含所有关节的 x、y、z 位置 xs_t = {x1,y1,z1,…,x25,y25,z25}。
- 然后,骨架编码器 ρs 从原始骨架数据中获取转换后的骨架 xs_t’’ (Eq.(5)),并生成一个七维潜在表示 zs_t = ρs(xs_t’')。
- 骨架潜在向量 zs_t 可以被骨架解码器 βs 解码,以便以后用于骨架重建和潜在表征学习。
- 同理,机器人运动 xrj_t = {θ1;θ2;···;θ14} 由关节角(rad)在时刻 t 定义,由机器人运动编码器 ρr 编码为 zr_t = ρr(xrj_t)。
- 机器人运动的潜在向量 zr_t 也可以被机器人运动解码器 解码,以便将来用于机器人运动重建和潜在表征学习。
- 我们的映射策略 πw 通过在潜在表示骨架 zs_t 和 机器人运动 zr_t 之间进行映射来执行运动重定向,zr_t = πw(zs_t)。
4.2 阶段1:学习潜在的Manifold
- 在第一阶段,我们使用VAE学习骨架和机器人运动的 latent manifold(图4)。
- 在第一阶段,使用NTU-DB和机器人参考运动 训练 骨架和机器人运动的latent manifold。

- 骨架编码器 ρs 由具有ReLU的 512、256、128、64 四个全连通(FC)层组成,将变换后的骨架xs_t’’ 编码在 7 维潜在向量 zs_t 中。
- 骨架解码器具有与编码器相同的结构,但顺序相反。
- 我们通过一次学习所有六个运动类数据创建了一个统一的骨架编码器-解码器。
- 为了学习机器人运动编解码器,我们需要为每个类采样一组参考机器人运动轨迹。
- 机器人运动网络由三个具有Tanh的FC层组成,其中编码层为256、128、64,潜在表示层为7,解码器层相同但顺序相反。
- MSE损失用于骨架和机器人运动网络。
4.3 阶段2:学习映射功能
- 在第二阶段,我们学习了基于模拟器和奖励函数的适当运动重定向的映射策略 πξ。

- 评价网络πζ基于这个包含骨架和机器人在时刻t运动信息的完整状态来评价agent的动作值。
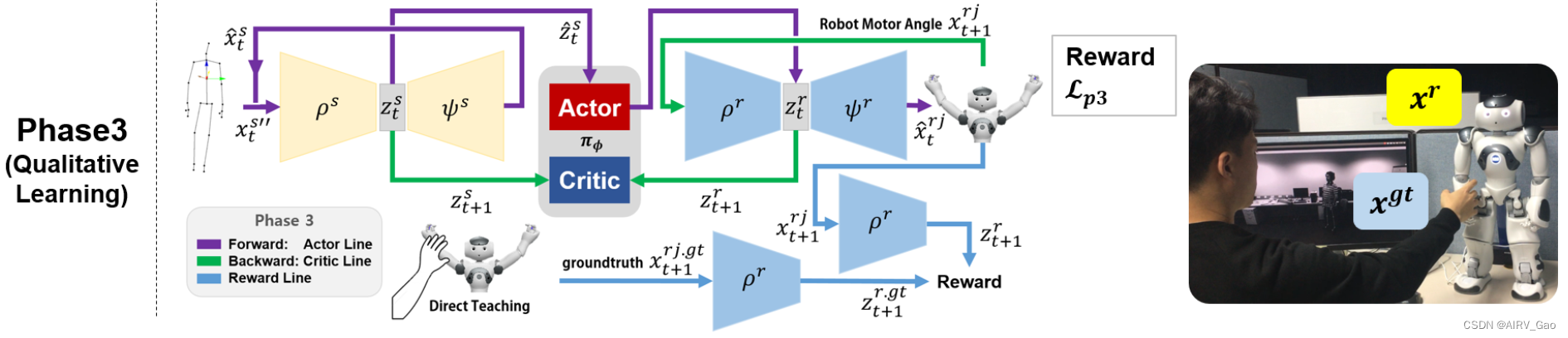
4.4 阶段3:通过微调进行策略优化
- 尽管该策略在阶段1中通过参考运动学习到的潜在流形之间执行映射,但由于阶段2的奖励不考虑头部或手腕的姿势,因此可能会发生错误的重定向。
- 在最后阶段,我们尝试使用基于 DT(直接学习) 的微调来纠正这种错误的重定向。
4.5 n-Step Monte-Carlo Learning
- 一般来说,MC方法具有无偏、高方差估计,而TD方法具有偏和低方差估计。这是因为MC经验地用实际回报更新策略,而TD通过使用自举(bootstrapping)的推理来估计预期回报。
- MC通常在情景环境中工作,然而,它可以应用于我们的动作重定向,因为我们将问题建模为非情景任务,并且可以在每个时间框架中获得奖励。