前言导入
内存管理之虚拟内存空间 详细了解这部分知识,再看下面的内容会很舒服
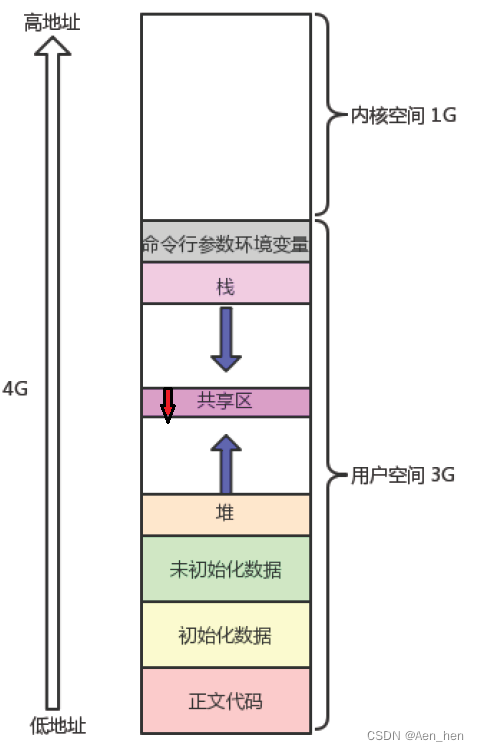
进程地址空间
以Linux内核2.6.7以前的进程内存布局为例,如下图所示(之后的内核,内存共享区是向上增长的)。
- 在32位Linux系统中,进程地址空间是这样分布的。其中内核空间独占1G,不允许用户操作,其余3G由用户操作。
- malloc的操作对象:堆是向上增长的,与之对应的共享区则是向下增长的。
进程控制块mm_struct
图中标出的是堆区的起始地址,结束地址以及栈区的起始地址。
在usr/src/linux-headers-5.15.0-76/include/linux/mm_types.h下

几个系统调用
操作系统提供了几个相关的系统调用来完成内存分配工作。
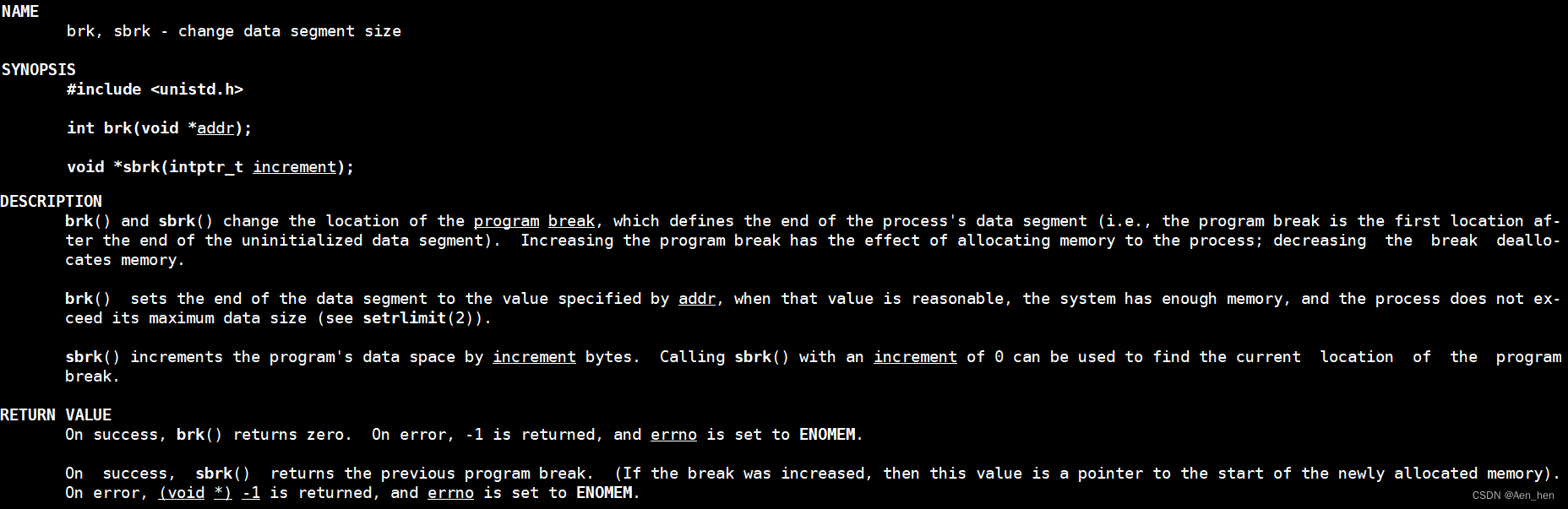
- 对于堆(heap),OS提供了
int brk(void *addr);函数,C库提供了void *sbrk(int* increment);)函数。其中,malloc使用的就是sbrk - 对于映射区域(mmap)的操作,操作系统提供了
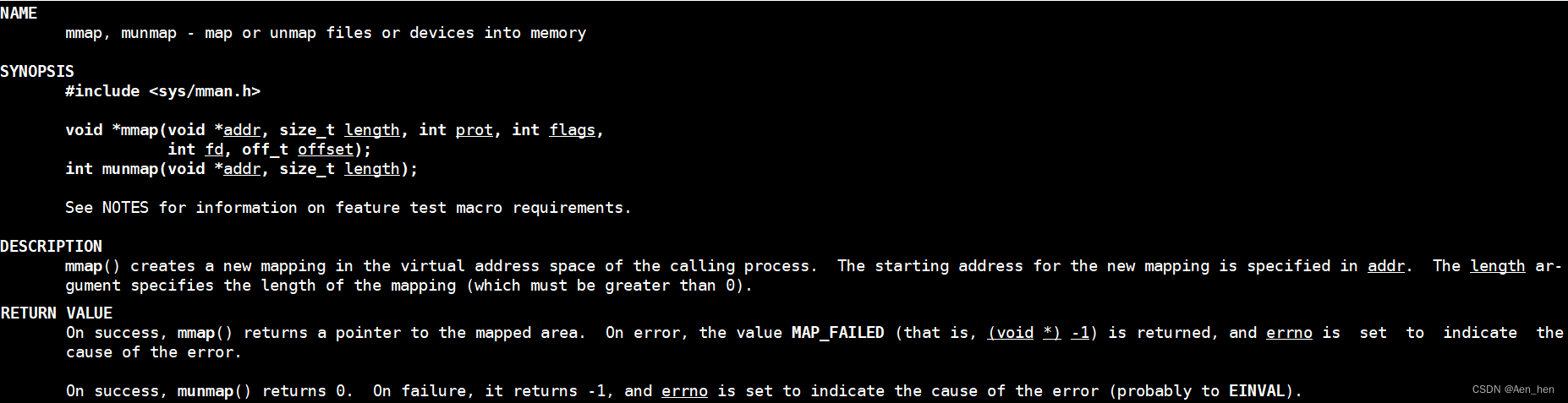
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);``int munmap(void *addr, size t length)两个函数
对于堆
由man手册中查到的信息:
- 堆是处于数据段中的动态分配内存的区域,brk,sbrk是用来设置未初始数据段的末尾位置的下一个位置。
- 其中 brk 通过形参指定堆的起始位置,如果该位置合理的话(每个进程有一个rlimit参数用于表示该进程可用资源的上限)。
- sbrk 则通过传入的参数,向上移动指定字节来扩展为未初始数据段的范围。
- malloc通常是通过sbrk(0)来获取当前program break的位置,然后sbrk(size)来扩展堆的大小。sbrk是brk的一个包装函数。
所以brk直接设置的是进程整个数据段的结尾,而不仅仅是堆区。堆区只是data segment中的一部分,是malloc等函数用于动态内存管理的空间。
对于内存映射区
mmap函数实际有两个功能:
- 我们常用的动态库就被加载到内存映射区,所有程序共享。这是从磁盘到内存,属于文件映射,用动态库文件填充物理内存。
- 用户使用malloc申请大内存时调用到了mmap,这种mmap的使用方式叫做匿名映射。
- 这种方式不属于映射磁盘文件到内存中,而是进程向内存申请一块空间,访问到了这块空间,触发缺页中断再分配实际物理内存给用户,不需要的时候就释放了,与heap的使用方式相同。
- 与动态库的映射不同,这种方式使用的mmap申请到的空间,进程间不共享,当对这块空间修改时,会触发写时拷贝。
munmap用来释放之前使用mmap申请的映射区域
malloc原理:Linux下的内存管理机制 ptmalloc
内存池
- malloc使用 ‘块’ (chunk)来进行管理动态分配的内存
- 由于以上几个接口都是系统调用,用户使用malloc申请内存,那么就意味着频繁的用户内核态的切换,这就会导致性能上的极大降低,因此,ptmalloc 采用了类似于STL的空间配置器使用的内存池的方式进行管理。
chunk结构
glibc中malloc目录下的malloc.h中:
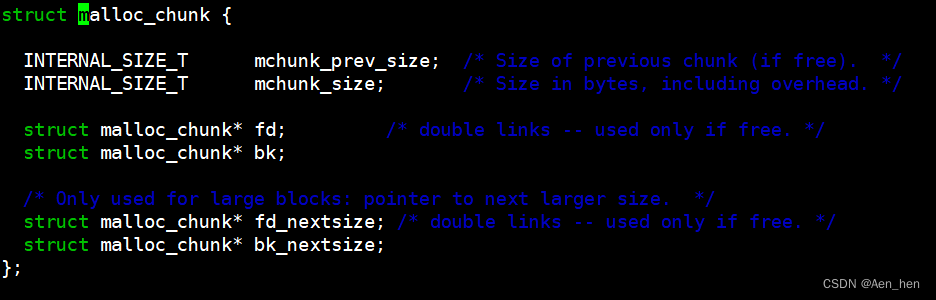
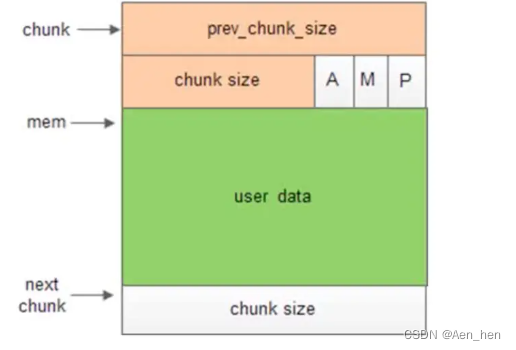
- 首先,空闲chunk和非空闲chunk在结构上是不一样的,非空闲字段会把某些用不上的字段当做程序能够使用的空间。
- 空闲chunk
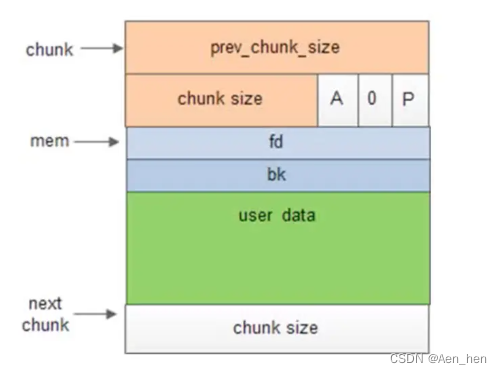
使用中的chunk
- mchunk_prev_size: 如果前一个chunk是空闲的,则该字段表示前一个chunk的大小,如果前一个chunk不空闲,该字段无意义。一段连续的内存被分成多个chunk,prev_size记录的就是相邻的前一个chunk的size,知道当前chunk的地址,减去prev_size便是前一个chunk的地址。prev_size主要用于相邻空闲chunk的合并。
- malloc_chunk_size :当前 chunk 的大小,并且记录了当前 chunk 和前一个 chunk 的一些属性,包括前一个 chunk 是否在使用中,当前 chunk 是否是通过 mmap 获得的内存,当前 chunk 是否属于非主分配区。
- malloc_chunk_fd 和 malloc_chunk_bk :指针 fd 和 bk 只有当该 chunk 块空闲时才存在,其作用是用于将对应的空闲 chunk 块加入到空闲chunk 块链表中统一管理,如果该 chunk 块被分配给应用程序使用,那么这两个指针也就没有用,被当作应用程序的使用空间,而不至于浪费。
- malloc_chunk__fd_nextsize 和 malloc_chunk_bk_nextsize: 当前的 chunk 存在于 large bins 中时, large bins 中的空闲 chunk 是按照大小排序的,但同一个大小的 chunk 可能有多个,增加了这两个字段可以加快遍历空闲 chunk ,并查找满足需要的空闲 chunk , fd_nextsize 指向下一个比当前 chunk 大小大的第一个空闲 chunk , bk_nextszie 指向前一个比当前 chunk 大小小的第一个空闲 chunk 。(同一大小的chunk可能有多块,在总体大小有序的情况下,要想找到下一个比自己大或小的chunk,需要遍历所有相同的chunk,所以才有fd_nextsize和bk_nextsize这种设计) 如果该 chunk 块被分配给应用程序使用,那么这两个指针也就没有用(该chunk 块已经从 size 链中拆出)了,所以也当作应用程序的使用空间,而不至于浪费。
- 其中 AMP字段的意义:
- chunk指针指向chunk开始的地址
- mem指针指向用户内存块开始的地址。
- p=0时,表示前一个chunk为空闲,prev_size才有效
- p=1时,表示前一个chunk正在使用,prev_size无效 p主要用于内存块的合并操作;ptmalloc 分配的第一个块总是将p设为1, 以防止程序引用到不存在的区域
- M=1 为mmap映射区域分配;M=0为heap区域分配
- A=0 为主分配区分配;A=1 为非主分配区分配。
分配区
- 在ptmalloc中,分配区分为主分配区和非主分配区。
- 主分配区和非主分配区的区别是:主分配区可以使用sbrk和mmap向OS申请内存,而非分配区只能通过mmap向OS申请内存。
主分配区

- 因为有内存池的存在,用户调用free函数释放内存的时候,ptmalloc并不会立即将其归还操作系统。在主分配区中包含一个bin数组(即空闲链表),该bin数组管理者内存池中申请的内存。
- bin数组每个元素是一个固定大小的chunk,每个块又是一个双向链表的结构,挂接着同样大小的块的地址。
- bin数组中存着不一样大小的块,类似于下图(small bins-画的是单向链表,实际是双向的)
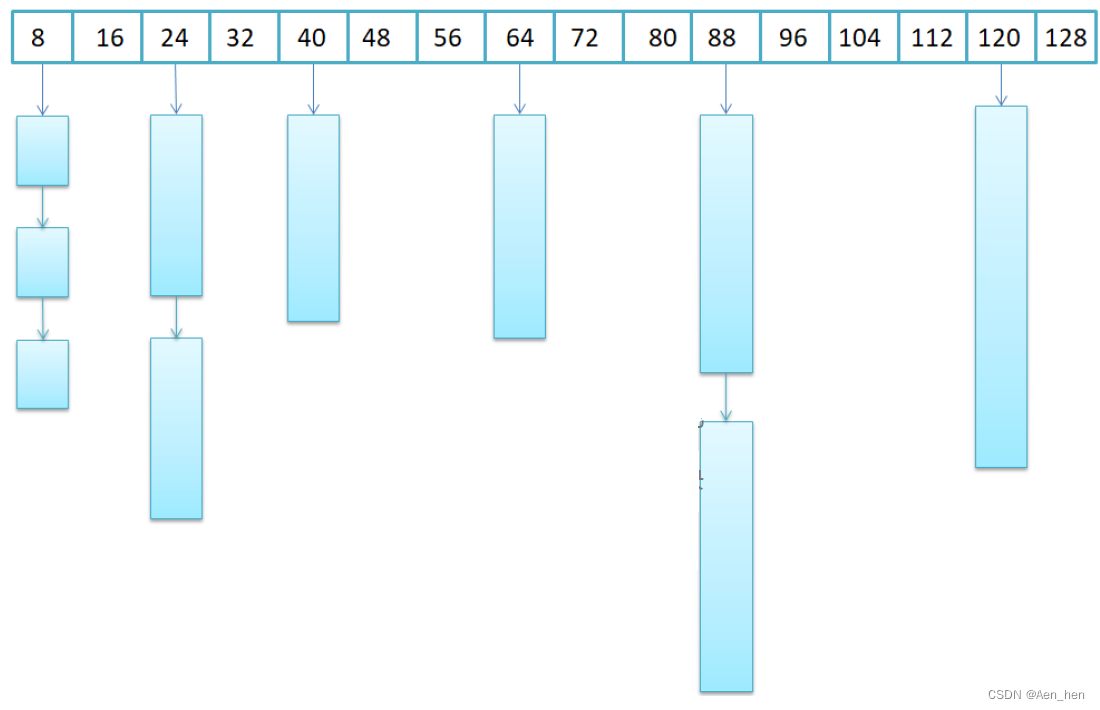
- malloc在实现bin时,把数组分为了不同的bin种类。
- 数组中第一个元素为unsorted bin,类似于缓冲区,运用了局部性原理。当一块空间被释放了,这块空间返还给内存池,但是由于局部性原理,这个大小的空间可能再一次被申请,那么malloc就直接先到这里面找,如果找不到再去找其他大小的chunk元素。
- 数组编号前2到前64的bin为 small bins,small bins 是 62 个双向循环链表,并且是 FIFO 的。
- 64-128 为 large bins。是 63 个双向循环链表,large bin的每个bin相差64字节,且同一个bin中的chunk大小也不一样,所以插入和删除可以发生在任意位置,内存分配器会找到最符合申请的大小的chunk进行分配。。large bins中的每一个bin分别包含了一个给定范围内的chunk,其中的chunk按大小序排列。
- fast bin。用于提高小内存分配效率。这个bin并不在bins数组中,不被bins数组维护。程序在运行时会经常需要申请和释放一些较小的内存空间。当分配器合并了相邻的几个小的 chunk 之后,也许马上就会有另一个小块内存的请求,这样分配器又需要从大的空闲内存中切分出一块,这样无疑是比较低效且易导致内存碎片的,故而,malloc 中在分配过程中引入了 fast bins,在申请非常小的内存时从这里面找,省去了分割chunk的开销。
同时,这里面的chunk由于P字段一直被置为1,即指示该chunk的前一个位置的chunk的使用状态一直是非空闲状态,导致前一个位置的chunk永远不会被合并,保证了没有分割chunk的开销。
以上是bins数组维护的常规块
但实际上还有一些非常规块,用来满足上面几种bin不能满足分配的情况
-
top chunk
top chunk是堆最上面的一段空间,不被bin维护,当所有的bin都无法满足分配要求时,就要从这块区域里来分配,将top chunk 切割成两部分,一部分用来满足用户的内存申请,另一部分变成last remainder chunk。last remainder chunk成为新的top chunk。如果top chunk的空间也不满足用户的请求。就要使用brk扩充数据段的空间或者使用mmap映射一段空间。
在free chunk的时候,如果chunk size不属于fastbin的范围,就要考虑是不是和top chunk挨着,如果挨着,就要合并到top chunk中。 -
mmaped chunk
当分配的内存非常大(大于分配阀值,默认128K)的时候,需要被mmap映射,则会放到mmaped chunk上,当释放mmaped chunk上的内存的时候会直接交还给操作系统。(chunk中的M标志位置1) -
last remainder chunk
位于堆的顶部,用于指示堆区域的结束。当有小块内存请求且在small bin中找不到符合要求的chunk时,last remained chunk会被分割以服务,一部分返回给用户,剩下的成为新的last remainder chunk。它的存在使得连续的小空间内存申请,分配到的内存都是相邻的,从而达到了更好的局部性。
而当需要扩展堆时,last remained chunk会被去除last remained标记,然后进行brk系统调用移动堆末尾指针来扩展堆。
同时,它把堆的最高地址作为边界,防止堆上分配的chunk溢出到其他数据段。
由于last remained chunk在末尾,当相邻的chunk释放时,可以通过它们融合成一个更大的空闲快。
malloc分配堆空间流程
- 先从fast bin中判断,如果大于
global_max_fast宏时,就会去unsorted bin中找,即缓冲区作用的bin中找,如果没有找到就去small bin,还没找到就去large bin。 - 如果在这bins里面都没有找到的话,就去topchunk超大块里面找
- 如果还小了就用mmap去内存映射区映射一块内存出来
- 具体malloc申请多大空间从哪里获取内存,这里推荐一个视频,最后详细介绍了按照多少字节走哪个bin进行分配,该up在文末画了一张流程图,很详细。
参考资料:
https://zhuanlan.zhihu.com/p/428216764【源码分析,贴合作者工作中bug万字详解malloc】
https://samwho.dev/memory-allocation/【英文文档,可视化方式介绍内存分配】
https://jacktang816.github.io/post/mallocandfree/【简单易懂】