前面在深入理解kafka中提到的只是理论上的设计原理,
本篇讲得是基于c语言的kafka库的程序编写!!!!!
首先要编写生产者的代码,得先知道生产者的逻辑在代码上是怎么体现的
1.kafka生产者的逻辑

怎么理解呢?
我们在实例化生产者对象之前的话,肯定是要对一些参数进行配置,
比如下面介绍的conf这些
那么 配置完参数之后,就是创建生产者实例,那么实例化生产者之后,就是准备生产者
生产消息,那么我们在生产者生产消息的时候,肯定要初始化和构建消息对象发过去
因为用对象的方式去管理消息更容易拓展和后期进行维护和管理以及消费者读取消息也
不容易出错,那么构建完消息对象之后,那么就需要将消息对象交给生产者,让生产者
生产到指定的kafka的topic中的消息队列(也就是topic中的partition分区中,因为每个
分区都是独立的队列),生产到消息队列就是发送消息,到了消息队列就等消费者进行消费了,
如果不需要生产者了,那么就可以关闭该生产者了
配置参数:
- 在实例化生产者对象之前,你需要配置生产者的参数。这一般通过创建一个
RdKafka::Conf对象,并使用set方法为其设置各种配置选项。这些配置选项可以包括 Kafka 服务器的地址、消息传递语义(例如,至少一次交付、精确一次交付等)、序列化器、分区器等。这个Conf对象可以在实例化生产者时传递给构造函数。
示例:
RdKafka::Conf *conf = RdKafka::Conf::create(RdKafka::Conf::CONF_GLOBAL);
conf->set("bootstrap.servers", "your_kafka_broker");// 设置其他配置项...RdKafka::Producer::create(conf);
实例化生产者:
- 利用配置好的参数,创建 Kafka 生产者实例。这是通过调用
RdKafka::Producer::create()函数实现的。传递配置对象作为参数,确保生产者在创建时拥有所需的配置。
构建消息对象:
- 在生产者准备好之后,你可以构建消息对象。这通常包括指定消息的主题、键、内容等信息。
RdKafka::Message类提供了相应的接口来设置这些消息属性。
RdKafka::Producer *producer = RdKafka::Producer::create(conf);
RdKafka::Message *msg = RdKafka::Message::create();
msg->set_payload("Your message payload");
msg->set_topic("your_topic");
// 设置其他消息属性...// 生产者会在生产消息时拥有这个消息对象
producer->produce(msg);
生产消息:
- 调用生产者的
produce方法发送消息到 Kafka 集群。在这一步,消息将被放入生产者内部的缓冲区,然后异步发送到 Kafka 服务器。produce方法会返回一个错误码,你可以通过检查这个错误码来了解消息发送的状态。
轮询:
- 为了确保消息的投递报告(
RdKafka::DeliveryReportCb)回调被调用,你需要定期调用RdKafka::poll()。这个操作通常在一个独立的线程中完成,以确保消息报告的及时处理。
producer->poll(0); // 参数表示非阻塞 poll
投递报告函数(RdKafka::DeliveryReportCb)在 Kafka 生产者发送消息后,用于接收有关消息传递结果的回调通知。它的主要作用是确保消息是否成功投递到 Kafka 服务器以及最终的处理结果。
关闭生产者:
- 当生产者不再需要时,通过调用
delete释放资源。在释放资源之前,你可能需要调用flush确保所有挂起的消息都已经被发送。
producer->flush(10000); // 等待最多 10 秒钟
delete producer;
2.kafka的C++API
2.1 RdKafka::Conf 可以理解为上诉逻辑中的配置客户端参数
enum ConfType{ CONF_GLOBAL, // 全局配置 CONF_TOPIC // Topic配置
};
enum ConfResult{ CONF_UNKNOWN = -2, CONF_INVALID = -1, CONF_OK = 0
};
CONF_UNKNOWN: 表示配置未知,可能是因为没有进行相关的验证或检查。
CONF_INVALID: 表示配置无效,可能是由于配置值不符合期望的范围或格式。
CONF_OK: 表示配置有效,通过了验证。
这些接口不用全记住,收藏并关注就行,忘了的就来回忆一下!!!记住主要的就行
static Conf * create(ConfType type);
//创建配置对象。Conf::ConfResult set(const std::string &name, const std::string &value, std::string &errstr);
//设置配置对象的属性值,成功返回CONF_OK,错误时错误信息输出到errstr。Conf::ConfResult set(const std::string &name, DeliveryReportCb *dr_cb, std::string &errstr);
//设置dr_cb属性值。Conf::ConfResult set(const std::string &name, EventCb *event_cb, std::string &errstr);
//设置event_cb属性值。Conf::ConfResult set(const std::string &name, const Conf *topic_conf, std::string &errstr);
//设置用于自动订阅Topic的默认Topic配置。Conf::ConfResult set(const std::string &name, PartitionerCb *partitioner_cb, std::string &errstr);
//设置partitioner_cb属性值,配置对象必须是CONF_TOPIC类型。Conf::ConfResult set(const std::string &name, PartitionerKeyPointerCb *partitioner_kp_cb,std::string &errstr);
//设置partitioner_key_pointer_cb属性值。Conf::ConfResult set(const std::string &name, SocketCb *socket_cb, std::string &errstr);
//设置socket_cb属性值。Conf::ConfResult set(const std::string &name, OpenCb *open_cb, std::string &errstr);
//设置open_cb属性值。Conf::ConfResult set(const std::string &name, RebalanceCb *rebalance_cb, std::string &errstr);
//设置rebalance_cb属性值。Conf::ConfResult set(const std::string &name, OffsetCommitCb *offset_commit_cb, std::string &errstr);
//设置offset_commit_cb属性值。Conf::ConfResult get(const std::string &name, std::string &value) const;
//查询单条属性配置值。
2.2 RdKafka::Message
Message表示一条消费或生产的消息,或是事件。 这个可以理解为生产逻辑中的构建消息对象
下面是基于Message对象的接口(有些内容都封装在message里):
std::string errstr() const;
//如果消息是一条错误事件,返回错误字符串,否则返回空字符串。ErrorCode err() const;
//如果消息是一条错误事件,返回错误代码,否则返回0。Topic * topic() const;
//返回消息的Topic对象。如果消息的Topic对象没有显示使用RdKafka::Topic::create()创建,需要使用topic_name函数。std::string topic_name() const;
//返回消息的Topic名称。int32_t partition() const;
//如果分区可用,返回分区号。void * payload() const;
//返回消息数据。size_t len() const;
//返回消息数据的长度。const std::string * key() const;
//返回字符串类型的消息key。const void * key_pointer() const;
//返回void类型的消息key。size_t key_len() const;
//返回消息key的二进制长度。int64_t offset () const;
//返回消息或错误的位移。void * msg_opaque() const;
//返回RdKafka::Producer::produce()提供的msg_opaque。virtual MessageTimestamp timestamp() const = 0;
//返回消息时间戳。virtual int64_t latency() const = 0;
//返回produce函数内生产消息的微秒级时间延迟,如果延迟不可用,返回-1。virtual struct rd_kafka_message_s *c_ptr () = 0;
//返回底层数据结构的C rd_kafka_message_t句柄。virtual Status status () const = 0;
//返回消息在Topic Log的持久化状态。virtual RdKafka::Headers *headers () = 0;
//返回消息头。virtual RdKafka::Headers *headers (RdKafka::ErrorCode *err) = 0;
//返回消息头,错误信息会输出到err。
主要:
在 RdKafka::Message 中,最主要和常用的成员函数和属性包括:
-
err(): 通过这个函数可以获取消息的错误码,用于检查消息在生产或消费过程中是否发生了错误。
-
len(): 返回消息的长度,表示消息体的字节数。
-
payload(): 提供对消息实际内容(有效负载)的访问。
-
topic_name(): 返回消息所属的主题名称。
-
partition(): 返回消息所在的分区编号。
-
offset(): 返回消息的偏移量,表示消息在分区中的位置。
这些成员函数和属性通常是处理 Kafka 消息时最重要的信息。通过这些信息,你可以检查消息的状态,了解消息的来源和内容,以及在消费者端追踪消息的位置。其他的一些属性,比如 key(),用于获取消息的键,是可选的,取决于消息是否包含键。
2.3 RdKafka::DeliveryReportCb
每收到一条RdKafka::Producer::produce()函数生产的消息,调用一次投递报告回调函数,RdKafka::Message::err()将会标识Produce请求的结果。
为了使用队列化的投递报告回调函数,必须调用RdKafka::poll()函数。
投递报告函数(RdKafka::DeliveryReportCb)在 Kafka 生产者发送消息后,用于接收有关消息传递结果的回调通知。它的主要作用是确保消息是否成功投递到 Kafka 服务器以及最终的处理结果。
投递报告函数起着以下作用:
-
确认消息是否成功发送: 一旦消息被生产者发送到 Kafka 服务器,投递报告函数被调用。这允许你知道消息是否已经成功到达服务器。
-
追踪消息传递状态: 投递报告函数提供了有关消息传递状态的信息。通过检查消息的错误码(通过
RdKafka::Message::err()获取),你可以了解消息是否成功投递到分区,以及可能的错误原因,比如消息发送超时、分区不存在等等。 -
确保消息处理: 这个回调函数可以帮助你确保消息得到了处理,无论是成功发送还是出现了一些错误。通过错误码,你可以适当地处理消息发送过程中的问题,例如重试、记录错误日志或者执行其他补救措施。
在整个流程中,投递报告函数是为了提供消息传递的状态和结果。它允许你追踪消息的处理情况,确保消息被成功地发送到了 Kafka 服务器,并且在出现问题时能够及时地得到通知和处理。因此,在实际的生产环境中,及时处理这个回调函数非常重要,以保证消息的可靠传递
virtual void dr_cb(Message &message)=0;
纯虚函数,需要继承来重写
当一条消息成功生产或是rdkafka遇到永久失败或是重试次数耗尽,投递报告回调函数会被调用。
C++封装示例:
class ProducerDeliveryReportCb : public RdKafka::DeliveryReportCb
{
public:void dr_cb(RdKafka::Message &message){if(message.err())std::cerr << "Message delivery failed: " << message.errstr() << std::endl;else{// Message delivered to topic test [0] at offset 135000std::cerr << "Message delivered to topic " << message.topic_name()<< " [" << message.partition() << "] at offset "<< message.offset() << std::endl;}}
};
2.4 RdKafka::Event
事件对象
是一个用于表示Kafka事件的类,它封装了与事件相关的信息。在你的描述中,列举了事件的不同类型,如EVENT_ERROR、EVENT_STATS、EVENT_LOG和EVENT_THROTTLE。每个事件都有相应的属性和方法来获取事件的类型、错误代码、日志信息等。
enum Type{ EVENT_ERROR, //错误条件事件 EVENT_STATS, // Json文档统计事件 EVENT_LOG, // Log消息事件 EVENT_THROTTLE // 来自Broker的throttle级信号事件
};virtual Type type() const =0;
//返回事件类型。
virtual ErrorCode err() const =0;
//返回事件错误代码。
virtual Severity severity() const =0;
//返回log严重级别。
virtual std::string fac() const =0;
//返回log基础字符串。
virtual std::string str () const =0;
//返回Log消息字符串。
virtual int throttle_time() const =0;
//返回throttle时间。
virtual std::string broker_name() const =0;
//返回Broker名称。
virtual int broker_id() const =0;
//返回Broker ID。
-
type(): 返回事件的类型。类型包括错误条件事件(
EVENT_ERROR)、JSON文档统计事件(EVENT_STATS)、日志消息事件(EVENT_LOG)以及来自Broker的throttle级信号事件(EVENT_THROTTLE)。 -
err(): 返回事件的错误代码,如果事件类型是错误条件事件。
-
severity(): 返回日志消息的严重级别。
-
fac(): 返回日志消息的基础字符串。
-
str(): 返回日志消息的字符串。
-
throttle_time(): 如果事件类型是throttle级信号事件,返回throttle的时间。
-
broker_name(): 返回与事件相关联的Broker的名称。
-
broker_id(): 返回与事件相关联的Broker的ID。
2.5 RdKafka::EventCb
事件回调
一个抽象基类,它定义了一个事件回调函数,用于处理RdKafka::Event。
事件是从RdKafka传递错误、统计信息、日志等消息到应用程序的通用接口。
virtual void event_cb(Event &event)=0; // 事件回调函数
纯虚函数,需要继承来重写
C++封装示例:
class ProducerEventCb : public RdKafka::EventCb
{
public:void event_cb(RdKafka::Event &event){switch(event.type()){case RdKafka::Event::EVENT_ERROR:std::cout << "RdKafka::Event::EVENT_ERROR: " << RdKafka::err2str(event.err()) << std::endl;break;case RdKafka::Event::EVENT_STATS:std::cout << "RdKafka::Event::EVENT_STATS: " << event.str() << std::endl;break;case RdKafka::Event::EVENT_LOG:std::cout << "RdKafka::Event::EVENT_LOG " << event.fac() << std::endl;break;case RdKafka::Event::EVENT_THROTTLE:std::cout << "RdKafka::Event::EVENT_THROTTLE " << event.broker_name() << std::endl;break;}}
};
这个回调函数的作用是在发生Kafka事件时被调用,将相应的RdKafka::Event对象传递给应用程序。应用程序可以实现自己的RdKafka::EventCb子类,然后在这个子类中实现event_cb方法,以处理具体的事件。这样,当有错误、统计信息、日志或来自Broker的throttle级信号事件发生时,那么逻辑就变成如下
-
配置参数: 你首先配置好生产者的参数,这包括Kafka集群的地址、topic的配置等。
-
创建生产者实例: 使用配置好的参数创建一个生产者实例。
-
准备生产者: 在生产消息之前,你可能需要进行一些准备工作,比如初始化和构建消息对象。
-
生产消息: 将构建好的消息对象交给生产者,让生产者将消息发送到指定的Kafka topic中。
-
处理事件: 这就是上述
RdKafka::Event和RdKafka::EventCb的作用了。在生产者的生命周期中,可能会发生一些异步事件,如错误、日志信息等。通过设置RdKafka::EventCb,你可以在相应的事件发生时得到通知,从而执行你自己的处理逻辑。 -
关闭生产者: 如果不再需要生产者,记得关闭它以释放资源。
下面是示例:
class MyEventCallback : public RdKafka::EventCb {
public:void event_cb(RdKafka::Event &event) override {// 处理事件的逻辑switch (event.type()) {case RdKafka::Event::EVENT_ERROR:// 处理错误事件break;case RdKafka::Event::EVENT_STATS:// 处理统计信息事件break;// 可以处理其他类型的事件default:break;}}
};int main() {// 配置生产者参数RdKafka::Conf *conf = RdKafka::Conf::create(RdKafka::Conf::CONF_GLOBAL);// 设置事件回调MyEventCallback eventCallback;conf->set("event_cb", &eventCallback, errstr);// 创建生产者实例RdKafka::Producer *producer = RdKafka::Producer::create(conf, errstr);if (!producer) {// 处理生产者创建失败的情况return 1;}// 准备生产者...// 生产消息...// 处理事件...// 关闭生产者delete producer;delete conf;return 0;
}
2.6 RdKafka::PartitionerCb
一个用于自定义消息分区策略的回调函数 partitioner_cb,它会在生产消息并决定消息应该发送到Kafka主题的哪个分区时被调用。当你在生产消息时,你可能希望某些特定的逻辑来决定消息应该发送到哪个分区,而不是使用默认的分区策略。
PartitionerCb用实现自定义分区策略,需要使用RdKafka::Conf::set()设置partitioner_cb属性。
virtual int32_t partitioner_cb(const Topic *topic, const std::string *key, int32_t partition_cnt,void *msg_opaque)=0;
//Partitioner回调函数
返回topic主题中使用key的分区,key可以是NULL或字符串。
partition_cnt表示该主题的分区数量(用于hash计算)
返回值必须在0到partition_cnt间,如果分区失败可能返回RD_KAFKA_PARTITION_UA (-1)。
msg_opaque与RdKafka::Producer::produce()调用提供的msg_opaque相同。
这个回调函数需要实现以下功能:
- 接收一个指向主题的指针
topic。 - 一个指向消息键的字符串指针
key。键可以是空或者字符串。 - 表示主题分区数量的整数
partition_cnt,用于帮助决定消息将会被分发到哪个分区。 - 一个指向消息不透明数据的指针
msg_opaque,与生产者发出消息时传递的msg_opaque相同。
回调函数需要返回一个整数值,表示消息应该发送到的分区。这个返回值必须介于0到 partition_cnt 之间,如果分区失败,则可以返回 RD_KAFKA_PARTITION_UA (-1)。
这个 partitioner_cb 回调函数的作用是,当生产者在发送消息到Kafka主题时需要决定消息发送到哪个分区时,会调用这个函数。你可以根据你自己的逻辑实现这个回调函数,让它根据消息的键或其他特征来决定消息应该发送到哪个分区。这样,你就可以自定义消息的分区策略。
在配置参数并创建生产者实例后,你可以使用 RdKafka::Conf::set() 来设置 partitioner_cb 属性,指定自定义的分区策略函数。然后,当你使用生产者发送消息时,Kafka客户端会调用你定义的 partitioner_cb 函数来确定消息应该发送到哪个分区。
一旦消息被分配到相应的分区,生产者就会将消息发送到该分区的消息队列中。消费者可以从这些分区的队列中读取消息。
当你完成生产者发送消息的任务后,可以关闭生产者实例。
C++封装示例:
class HashPartitionerCb : public RdKafka::PartitionerCb
{
public:int32_t partitioner_cb (const RdKafka::Topic *topic, const std::string *key,int32_t partition_cnt, void *msg_opaque){char msg[128] = {0};int32_t partition_id = generate_hash(key->c_str(), key->size()) % partition_cnt;// [topic][key][partition_cnt][partition_id] // :[test][6419][2][1]sprintf(msg, "HashPartitionerCb:topic:[%s], key:[%s]partition_cnt:[%d], partition_id:[%d]", topic->name().c_str(), key->c_str(), partition_cnt, partition_id);std::cout << msg << std::endl;return partition_id;}
private:static inline unsigned int generate_hash(const char *str, size_t len){unsigned int hash = 5381;for (size_t i = 0 ; i < len ; i++)hash = ((hash << 5) + hash) + str[i];return hash;}
};
伪代码示例:
#include <librdkafka/rdkafkacpp.h>class MyPartitionerCallback : public RdKafka::PartitionerCb {
public:int32_t partitioner_cb(const RdKafka::Topic *topic, const std::string *key, int32_t partition_cnt, void *msg_opaque) override {// 自定义分区逻辑// 在这里,你可以根据消息的键(key)或其他标准来决定消息应该分发到哪个分区// 你可以使用 topic、key、partition_cnt 等参数进行逻辑判断// 假设你的自定义逻辑是简单地根据键的哈希值来选择分区if (key) {std::hash<std::string> hasher;size_t hash_value = hasher(*key);return static_cast<int32_t>(hash_value % partition_cnt);} else {// 如果键为空,则使用默认分区策略return RD_KAFKA_PARTITION_UA;}}
};int main() {// 创建配置对象RdKafka::Conf *conf = RdKafka::Conf::create(RdKafka::Conf::CONF_GLOBAL);// 设置分区回调函数MyPartitionerCallback partitioner_callback;conf->set("partitioner_cb", &partitioner_callback, errstr);// 创建生产者实例RdKafka::Producer *producer = RdKafka::Producer::create(conf, errstr);if (!producer) {// 处理生产者创建失败的情况std::cerr << "Failed to create producer: " << errstr << std::endl;delete conf;return -1;}// 创建消息对象RdKafka::Producer::Message msg("my_topic", 0, RdKafka::Producer::RK_MSG_COPY, /* payload */, /* payload size */, /* key */, /* opaque */);// 生产消息RdKafka::ErrorCode resp = producer->produce(msg, /* partition */, /* delivery report callback */);if (resp != RdKafka::ERR_NO_ERROR) {// 处理消息发送失败的情况std::cerr << "Failed to produce message: " << RdKafka::err2str(resp) << std::endl;}// 在这里可以继续生产更多的消息// 关闭生产者delete producer;delete conf;return 0;
}
2.7 RdKafka::Topic
kafka中的主题对象,逻辑单元
RdKafka::Topic 扮演了管理 Kafka 主题(Topic)相关操作的角色。
static Topic * create(Handle *base, const std::string &topic_str, Conf *conf, std::string &errstr);
//使用conf配置创建名为topic_str的Topic句柄。const std::string name ();
//获取Topic名称。bool partition_available(int32_t partition) const;
//获取parition分区是否可用,只能在 RdKafka::PartitionerCb回调函数内被调用。ErrorCode offset_store(int32_t partition, int64_t offset);
//存储Topic的partition分区的offset位移,只能用于RdKafka::Consumer,不能用于RdKafka::KafkaConsumer高级接口类。
//使用本接口时,auto.commit.enable参数必须设置为false。virtual struct rd_kafka_topic_s *c_ptr () = 0;
//返回底层数据结构的rd_kafka_topic_t句柄,不推荐利用rd_kafka_topic_t句柄调用C API,但如果C++ API没有提供相应功能,
//可以直接使用C API和librdkafka核心交互。
static const int32_t PARTITION_UA = -1; //未赋值分区
static const int64_t OFFSET_BEGINNING = -2; //特殊位移,从开始消费
static const int64_t OFFSET_END = -1; //特殊位移,从末尾消费
static const int64_t OFFSET_STORED = -1000; //使用offset存储
-
PARTITION_UA (-1): 这个常量代表未指定分区。在某些情况下,如果不想将消费者与特定分区绑定,可以使用这个常量表示未赋值分区。
-
OFFSET_BEGINNING (-2): 该常量表示从分区的起始位置开始消费消息。如果想要从 Kafka 主题的最早消息开始消费,可以使用这个常量。
-
OFFSET_END (-1): 这个常量用于表示从分区的末尾(最新消息)开始消费。如果希望消费者从主题中最新的消息开始消费,可以使用此常量。
-
OFFSET_STORED (-1000): 这个常量表示使用存储的偏移量进行消费。有时候,消费者可能会将消费的偏移量存储在某个地方(比如外部存储、数据库等),以便稍后继续从这个位置开始消费。这个常量可以帮助消费者指定使用存储的偏移量作为消费的起始位置。
这些常量提供了灵活的选项,使得消费者在消费 Kafka 主题消息时可以根据需要选择不同的起始位置或分区,以满足特定的业务需求。
伪代码示例:
#include <librdkafka/rdkafkacpp.h>int main() {// 创建 Kafka 消费者配置RdKafka::Conf *conf = RdKafka::Conf::create(RdKafka::Conf::CONF_GLOBAL);// 设置消费者配置参数...// 创建 Kafka 消费者RdKafka::Consumer *consumer = RdKafka::Consumer::create(conf, errstr);if (!consumer) {// 处理消费者创建失败的情况return 1;}// 指定主题和分区RdKafka::Topic *topic = RdKafka::Topic::create(consumer, "your_topic", NULL);// 设置消费者的分区和偏移量int32_t partition = RdKafka::Topic::PARTITION_UA; // 未指定分区int64_t offset = RdKafka::Topic::OFFSET_BEGINNING; // 从起始位置开始消费// 在消费者上订阅主题和分区RdKafka::ErrorCode resp = consumer->assign({RdKafka::TopicPartition("your_topic", partition, offset)});if (resp != RdKafka::ERR_NO_ERROR) {// 处理分配分区失败的情况return 1;}// 开始消费消息while (true) {// 从消费者拉取消息...RdKafka::Message *msg = consumer->consume(1000); // 1000毫秒超时// 处理消息...if (msg->err()) {// 处理消息消费错误} else {// 处理接收到的消息}// 释放消息资源delete msg;}// 关闭资源delete topic;delete consumer;return 0;
}
上述代码什么意思呢?
int32_t partition = RdKafka::Topic::PARTITION_UA; // 未指定分区
讲得是表示消费者并没有指定要消费的具体分区,因此消费者将会被动态地分配到可用的分区中。实际上,这种方式可以让消费者根据负载均衡策略被均匀地分配到不同的分区,以提高整体的消费效率。
如果是上述代码的话,消费者去消费的话,不会去特定分区去读取数据,而是根据kafka的消费者的分配策略(其实分配策略就是负载均衡策略!!!!!)机制被分配到消费者订阅的topic
中的某个分区中去读取
1.创建 Topic 对象:
在 Kafka 生产者逻辑中,首先需要创建 RdKafka::Topic 对象,通常通过 create 函数,该函数接受一些参数,包括 Kafka 主题的名称和配置。创建 Topic 对象是为了后续将消息发送到指定主题。
RdKafka::Topic *topic = RdKafka::Topic::create(/* parameters */);
2.构建消息对象:
在消息生产之前,你描述了初始化和构建消息对象的过程。这可能涉及到创建一个消息对象,设置消息的内容、键、分区等属性。这样的消息对象可以使用 Kafka 生产者库中提供的相应类(可能是 RdKafka::Message 或其他类)。
RdKafka::Message *message = /* 构建消息对象 */;3.将消息发送到主题:
通过创建的 Kafka 生产者实例和之前创建的 RdKafka::Topic 对象,可以将构建好的消息发送到 Kafka 集群中的指定主题。通常,发送消息的函数会接受 Topic 对象和消息对象作为参数。
producer->produce(topic, partition, /* other parameters */, message);
其中,producer 是之前创建的 Kafka 生产者实例,partition 是指定的分区。
2.8 RdKafka::Producer(核心)
static Producer * create(Conf *conf, std::string &errstr);
//创建一个新的Producer客户端对象,conf用于替换默认配置对象,本函数调用后conf可以重用。成功返回新的Producer客户端对象
//,失败返回NULL,errstr可读错误信息。ErrorCode produce(Topic *topic, int32_t partition, int msgflags, void *payload, size_t len,
const std::string *key, void *msg_opaque);
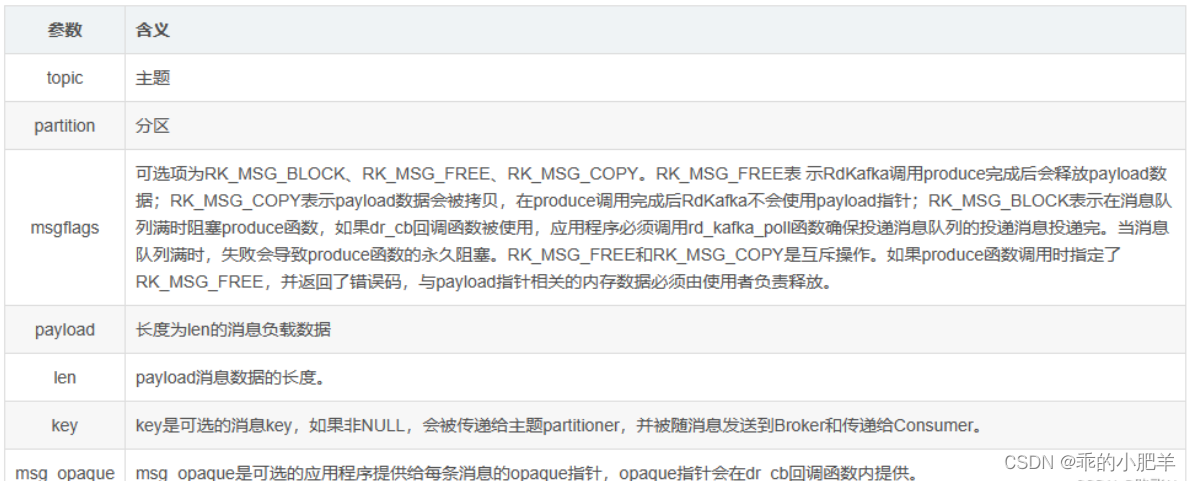
//生产和发送单条消息到Broker。msgflags:可选项为RK_MSG_BLOCK、RK_MSG_FREE、RK_MSG_COPY。
返回错误码:

ErrorCode produce(Topic *topic, int32_t partition, int msgflags, void *payload, size_t len,const void *key,
size_t key_len, void *msg_opaque);
//生产和发送单条消息到Broker,传递key数据指针和key长度。ErrorCode produce(Topic *topic, int32_t partition, const std::vector< char > *payload,
const std::vector< char > *key, void *msg_opaque);
//生产和发送单条消息到Broker,传递消息数组和key数组。接受数组类型的key和payload,数组会被复制。//ErrorCode flush (int timeout_ms);
//等待所有未完成的所有Produce请求完成。为了确保所有队列和已经执行的Produce请求在中止前完成,flush操作优先于销毁生产者
//实例完成。本函数会调用Producer::poll()函数,因此会触发回调函数。//ErrorCode purge (int purge_flags);
//清理生产者当前处理的消息。本函数调用时可能会阻塞一定时间,当后台线程队列在清理时。应用程序需要在调用poll或flush函数后
//,执行清理消息的dr_cb回调函数。virtual Error *init_transactions (int timeout_ms) = 0;
//初始化Producer实例的事务。失败返回RdKafka::Error错误对象,成功返回NULL。
//通过调用RdKafka::Error::is_retriable()函数可以检查返回的错误对象是否有权限重试,调用
//RdKafka::Error::is_fatal()检查返回的错误对象是否是严重错误。返回的错误对象必须elete。virtual Error *begin_transaction () = 0;
//启动事务。本函数调用前,init_transactions()函数必须被成功调用。
//成功返回NULL,失败返回错误对象。通过调用RdKafka::Error::is_fatal_error()函数可以检查是否是严重错误,返回的错误对象
//必须delete。virtual Error send_offsets_to_transaction (const std::vector &offsets,const ConsumerGroupMetadata*group_metadata,int timeout_ms) = 0;
//发送TopicPartition位移链表到由group_metadata指定的Consumer Group协调器,如果事务提交成功,位移才会被提交。virtual Error *commit_transaction (int timeout_ms) = 0;
//提交当前事务。在实际提交事务时,任何未完成的消息会被完成投递。
//成功返回NULL,失败返回错误对象。通过调用错误对象的方法可以检查是否有权限重试,是否是严重错误、可中止错误等。virtual Error *abort_transaction (int timeout_ms) = 0;
//停止事务。本函数从非严重错误、可终止事务中用于恢复。未完成消息会被清理。
3 Kafka 生产者客户端开发
3.1 必要的参数配置(bootstrap.servers)
(1)指定连接 Kafka 集群所需要的 broker 地址清单,具体的内容格式为 host1:port1,host2:port2,可以设置一个或者多个地址,中间以逗号进行隔开,此参数的默认值为 “”。
(2)注意这里并非需要所有的 broker 地址,因为生产者会从给定的 broker 里查找其他 broker 的信息。
(3)过建议至少要设置两个以上的 broker 地址信息,当其中任意一个宕机时,生产者仍然可以连接到 Kafka 集群上。
提示个东西!!!
就是我们生产者producer在连接kafka集群当中的话,可以连接kafka集群当中的一个kafka服务器
或者多个kafka服务器。kafka服务器对应broker。
如下图示例:

// 创建Kafka Conf对象
m_config = RdKafka::Conf::create(RdKafka::Conf::CONF_GLOBAL);
if(m_config == NULL)
{std::cout << "Create RdKafka Conf failed." << std::endl;
}
// 创建Topic Conf对象
m_topicConfig = RdKafka::Conf::create(RdKafka::Conf::CONF_TOPIC);
if(m_topicConfig == NULL)
{std::cout << "Create RdKafka Topic Conf failed." << std::endl;
}
// 设置Broker属性
RdKafka::Conf::ConfResult errCode;
m_dr_cb = new ProducerDeliveryReportCb;
std::string errorStr;
errCode = m_config->set("dr_cb", m_dr_cb, errorStr);
if(errCode != RdKafka::Conf::CONF_OK)
{std::cout << "Conf set failed:" << errorStr << std::endl;
}
m_event_cb = new ProducerEventCb;
errCode = m_config->set("event_cb", m_event_cb, errorStr);
if(errCode != RdKafka::Conf::CONF_OK)
{std::cout << "Conf set failed:" << errorStr << std::endl;
}m_partitioner_cb = new HashPartitionerCb;
errCode = m_topicConfig->set("partitioner_cb", m_partitioner_cb, errorStr);
if(errCode != RdKafka::Conf::CONF_OK)
{std::cout << "Conf set failed:" << errorStr << std::endl;
}errCode = m_config->set("statistics.interval.ms", "10000", errorStr);
if(errCode != RdKafka::Conf::CONF_OK)
{std::cout << "Conf set failed:" << errorStr << std::endl;
}errCode = m_config->set("message.max.bytes", "10240000", errorStr);
if(errCode != RdKafka::Conf::CONF_OK)
{std::cout << "Conf set failed:" << errorStr << std::endl;
}
errCode = m_config->set("bootstrap.servers", m_brokers, errorStr);
if(errCode != RdKafka::Conf::CONF_OK)
{std::cout << "Conf set failed:" << errorStr << std::endl;
}
3.2 其他重要的生产者参数
3.2.1 acks
用来指定分区中必须要有多少个副本收到这条消息,之后生产者才会认为这条消 息是成功写入的。 acks是生产者客户端中一个非常重要的参数 ,它涉及消息的可靠性和吞吐量之间的权衡。acks 参数有3种类型的值(都是字符串类型)。
1.acks = 1。默认值即为 1。生产者发送消息之后,只要分区的 leader 副本成功写入消息,那么它就
会收到来自服务端的成功响应。如果消息无法写入 leader 副本,比如在 leader 副本崩溃、重新选
举新的 leader 副本的过程中,那么生产者就会收到一个错误的响应,为了避免消息丢失,生产者
可以选择重发消息。如果消息写入 leader 副本并返回成功给生产者,且在被其他 follower 副本拉
取之前 leader 副本崩溃,那么此时消息还是会丢失,因为新选举的 leader 副本中并没有这条对应
的消息。acks 设置为 1,是消息可靠性和吞吐量之间的折中方案。
2.acks = 0。生产者发送消息之后不需要等待任何服务端的响应。
如果在消息从发送到写入 Kafka 的过程中出现了某些异常,导致 Kafka 并没有收到这条消息,那么生产者也无从得知,消息也就丢失了。
在其他配置环境相同的情况下,acks 设置为 0 可以达到最大的吞吐量。
3.acks = -1 或 acks = all。生产者在消息发送之后,需要等待 ISR 中的所有副本都成功写入消息之后才能够收到来自服务端的成功响应。
在其他配置环境相同的情况下,acks 设置为 -1 可以达到最强的可靠性。
但是并不意味着消息就一定可靠,因为 ISR 中可能只有 leader 副本,这样就退化成了 acks = 1 的
情况。要获得更高的消息可靠性需要配合 min.insync.replicas 等参数的联动。
注意 acks 参数配置的值是一个字符串类型,而不是整数类型。
//范例:
RdKafka::Conf *conf = RdKafka::Conf::create(RdKafka::Conf::CONF_GLOBAL);
ConfResult ret = conf->set("acks", "1", errstr);
ConfResult ret = conf->set("acks", "0", errstr);
ConfResult ret = conf->set("acks", "all", errstr);
3.2.2 max.request.size
这个参数用来限制生产者客户端能够发送的消息的最大值,默认值为 1048576 B,即 1 MB。
一般情况下,这个默认值就可以满足大多数的应用场景了。
不建议盲目地增大这个参数的配置值,尤其是在对 Kafka 整体脉络没有足够把控的时候。
因为这个参数还涉及一些其他参数的联动,比如 broker 端的 message.max.bytes 参数,如果配
置错误可能会引起一些不必要的一场。
比如讲 broker 端的 message.max.bytes 参数配置为 10, 而 max.request.size 参数配置为 20,
那么当我们发送一条消息大小为 15 的消息时,生产者客户端就会报出异常:
The reqeust included a message larger than the max message size the server will accept.
errCode = conf->set("message.max.bytes", "10240000", errorStr);
3.2.3 retries 和 retry.backoff.ms
retries 重试次数,默认0
retry.backoff.ms 重试间隔,默认100
1. retries 参数用来配置生产者重试的次数,默认值为 0,即发生异常的时候不进行任何的重试动作。
-
retries参数:- 默认为 0,控制生产者的重试次数,设置为大于 0 可在发生可恢复异常时进行内部重试。
2. 消息在从生产者发出道成功写入服务器之前可能发生一些临时性的异常,比如网络抖动、Leader副本的选举等,这种异常往往是可以自行恢复的,生产者可以通过配置 retries 大于 0 的值,以此通过内部重试来恢复而不是一味的将异常抛给生产者的应用程序。
-
临时性异常处理:
- 临时异常(如网络抖动、Leader副本选举)可通过配置
retries恢复,避免将异常传递给应用程序
- 临时异常(如网络抖动、Leader副本选举)可通过配置
3. 如果重试达到设定的次数,那么生产者就会放弃重试并返回异常。
不过并不是所有的异常都是可以通过重试来解决的,比如消息太大,超过 max.request.size 参数 配置的值时,这种方式就不行了。
-
重试次数限制:
- 达到设定的次数后,生产者放弃重试并返回异常。
4. 重试还和另一个参数 retry.backoff.ms 有关,这个参数的默认值为 100,它用来设定两次重试之间的时间间隔,避免无效的频繁重试。
-
不可重试异常:
- 并非所有异常都可通过重试解决,如消息过大超过
max.request.size。
- 并非所有异常都可通过重试解决,如消息过大超过
5. 在配置 retries 和 retry.backoff.ms 之前,最好先估算一下可能的异常恢复时间,这样可以设定总的重试时间大于这个异常恢复时间,以此来避免生产者过早地放弃重试。
-
retry.backoff.ms参数:- 控制两次重试之间的时间间隔,默认为 100 毫秒,避免频繁无效的重试。
7. Kafka 可以保证同一个分区中的消息时有序的。
-
Kafka 中的顺序:
- 同一分区中的消息保持有序。
8. 如果生产者按照一定的顺序发送消息,那么这些消息也会顺序的写入分区,进而消费者也可以按照 同样的顺序消费它们。
- 生产者按顺序发送消息,Kafka 按顺序写入,支持有序消费。
9. 对于某些应用来说,顺序性非常重要,比如 Mysql 的 binlog 传输,如果出现错误就会造成非常严 重的后果。如果讲 retries 参数设置为非零值,并且 max.in.flight.requests.per.connection 参数配置为大于1 的值,那么就会出现错序的现象:如果第一批次消息写入失败,而第二批次消息写入成功,那么生产者会重试发送第一批次的消息,此时如果第一批次的消息写入成功,那么这两个批次的消息就出 现了错序。
- 对于顺序敏感应用(如 MySQL binlog 传输),配置
retries和max.in.flight.requests.per.connection要小心,以避免错序。
10. 一般而言,在需要保证顺序的场合建议把参数 max.in.flight.requests.per.connection 配置为 1,而不是把retries 配置为 0. 不过这样也会影响整体的吞吐。
max.in.flight.requests.per.connection = 1 限制客户端在单个连接上能够发送的未响应请求的个数。设置此值是1表示kafka broker在响应请求之前client不能再向同一个broker发送请求。注意:设置此参数是为了避免消息乱序
-
max.in.flight.requests.per.connection参数:- 设置为 1,限制在单个连接上未响应请求的数量,避免消息错序,但可能影响整体吞吐。
3.2.4 compression.type
这个参数用来指定消费的压缩方式,默认值为 “none”,即默认情况下,消息不会被压缩。
该参数还可以配置为 “gzip”,“snappy”,“lz4”。
对消息进行压缩可以极大地减少网络传输量、降低网络 I/O ,从而提高整体的性能。
消息压缩是一种使用时间换空间的优化方式,如果对时延有一定的要求,则不推荐对消息进行压
缩。
3.2.5 connection.max.idle.ms
这个参数用来指定在多久之后关闭闲置的连接,默认值时 540000 ms,即 9 分钟。
3.2.6 linger.ms
这个参数用来指定生产者发送 Producer Batch 之前等待更多消息(ProducerRecord)加入
ProducerBatch 的时间,默认值为 0。
生产者客户端会在 ProducerBatch 被填满或等待时间超过 linger.ms 值时发送出去。
增大这个参数的值会增加消息的延迟,但是同时能提升一定的吞吐量。
这个 linger.ms 参数与 TCP 协议中的 Nagle 算法有异曲同工之妙。
3.2.7 receive.buffer.bytes
这个参数用来设置 Socket 接受消息缓冲区(SO_RECBUF)的大小,默认值为 32768(B),即 32
KB。
如果设置为 -1,则使用操作系统的默认值。
如果 Producer 与 Kafka 处于不同的机房,则可以适当调大这个参数值。
3.2.8 send.buffer.bytes
这个参数用来设置 Socket 发送消息缓冲区(SO_SNDBUF)的大小,默认值为 131072 (B),即
128 KB。
与 receive.buffer.bytes 参数一样,如果设置为 -1 ,则使用操作系统默认值。
3.2.9 request.timeout.ms
这个参数用来配置 Producer 等待请求响应的最长时间,默认值为 30000 ms。
请求超时之后可以选择进行重试。
注意这个参数需要比 broker 端参数 replica.lag.time.max.ms 的值要大,这样可以减少因客户端重
试而引起的消息重复的概率。
根据具体场景和需求,需要根据网络状况、Kafka集群负载和消息处理要求来调整该参数值。较低延迟要求的场景可以选择较小的值,而对于网络不稳定或处理压力较大的情况,可能需要适当增加该参数值。
3.2.10 client.id
用来设定 KafkaProducer 对应的客户端 id。默认值为 “”。
3.2.11 batch.size
batch.size 是 producer 最重要的参数之一 !它对于调优 producer 吞吐量和延时性能指标都有着非常
重要的作用 。
producer 会将发往同一分区的多条消息封装进一个 batch中,当 batch 满了的时候, producer 会发送
batch 中的所有消息 。不过, producer并不总是等待batch满了才发送消息,很有可能当batch还有很
多空闲空间时 producer 就发送该 batch 。显然,batch 的大小就显得非常重要 。
通常来说,一个小的 batch 中包含的消息数很少,因而一次发送请求能够写入的消息数也很少,所以
producer 的吞吐量会很低;一个 batch 非常之巨大,那么会给内存使用带来极大的压力,因为不管是
否能够填满,producer 都会为该batch 分配固定大小的内存。
因此batch.size 参数的设置其实是一种时间与空间权衡的体现 。batch.size 参数默认值是 16384 ,即
16KB 。这其实是一个非常保守的数字。 在实际使用过程中合理地增加该参数值,通常都会发现
producer 的吞吐量得到了相应的增加 。
声明和定义分离!!!!!
完整代码:

kafka_producer.h
#ifndef KAFKAPRODUCER_H
#define KAFKAPRODUCER_H#pragma once
#include <string>
#include <iostream>
#include "librdkafka/rdkafkacpp.h"class KafkaProducer
{
public:/*** @brief KafkaProducer* @param brokers* @param topic* @param partition*/explicit KafkaProducer(const std::string& brokers, const std::string& topic, int partition);/*** @brief push Message to Kafka* @param str, message data*/void pushMessage(const std::string& str, const std::string& key);~KafkaProducer();private:std::string m_brokers; // Broker列表,多个使用逗号分隔std::string m_topicStr; // Topic名称int m_partition; // 分区RdKafka::Conf* m_config; // Kafka Conf对象RdKafka::Conf* m_topicConfig; // Topic Conf对象RdKafka::Topic* m_topic; // Topic对象RdKafka::Producer* m_producer; // Producer对象/*只要看到Cb 结尾的类,要继承它然后实现对应的回调函数*/RdKafka::DeliveryReportCb* m_dr_cb;RdKafka::EventCb* m_event_cb;RdKafka::PartitionerCb* m_partitioner_cb;
};#endif
std::string m_brokers; // Kafka集群的Broker地址列表
std::string m_topicStr; // Kafka主题的名称
int m_partition; // 消息要发送到的分区号
RdKafka::Producer* m_producer; // Kafka Producer实例
RdKafka::Topic* m_topic; // Kafka Topic实例
RdKafka::Conf* m_config; // Kafka全局配置
RdKafka::Conf* m_topicConfig; // Kafka Topic配置
RdKafka::ProducerDeliveryReportCb m_dr_cb; // 生产者投递报告回调函数 RdKafka::ProducerEventCb m_event_cb; // 生产者事件回调函数
RdKafka::HashPartitionerCb m_partitioner_cb; // 分区器回调函数
kafka_producer.cc
#include "kafka_producer.h"// call back
class ProducerDeliveryReportCb : public RdKafka::DeliveryReportCb
{
public:void dr_cb(RdKafka::Message &message){if(message.err())std::cerr << "Message delivery failed: " << message.errstr() << std::endl;else{// Message delivered to topic test [0] at offset 135000std::cerr << "Message delivered to topic " << message.topic_name()<< " [" << message.partition() << "] at offset "<< message.offset() << std::endl;}}
};class ProducerEventCb : public RdKafka::EventCb
{
public:void event_cb(RdKafka::Event &event){switch (event.type()){case RdKafka::Event::EVENT_ERROR:std::cout << "RdKafka::Event::EVENT_ERROR: " << RdKafka::err2str(event.err()) << std::endl;break;case RdKafka::Event::EVENT_STATS:std::cout << "RdKafka::Event::EVENT_STATS: " << event.str() << std::endl;break;case RdKafka::Event::EVENT_LOG:std::cout << "RdKafka::Event::EVENT_LOG " << event.fac() << std::endl;break;case RdKafka::Event::EVENT_THROTTLE:std::cout << "RdKafka::Event::EVENT_THROTTLE " << event.broker_name() << std::endl;break;}}
};class HashPartitionerCb : public RdKafka::PartitionerCb
{
public:int32_t partitioner_cb(const RdKafka::Topic *topic, const std::string *key,int32_t partition_cnt, void *msg_opaque){char msg[128] = { 0 };int32_t partition_id = generate_hash(key->c_str(), key->size()) % partition_cnt;// [topic][key][partition_cnt][partition_id] // :[test][6419][2][1]sprintf(msg, "HashPartitionerCb:topic:[%s], key:[%s]partition_cnt:[%d], partition_id:[%d]", topic->name().c_str(),key->c_str(), partition_cnt, partition_id);std::cout << msg << std::endl;return partition_id;}
private:static inline unsigned int generate_hash(const char *str, size_t len){unsigned int hash = 5381;for (size_t i = 0; i < len; i++)hash = ((hash << 5) + hash) + str[i];return hash;}
};KafkaProducer::KafkaProducer(const std::string& brokers, const std::string& topic, int partition)
{m_brokers = brokers;m_topicStr = topic;m_partition = partition;/* 创建Kafka Conf对象 */m_config = RdKafka::Conf::create(RdKafka::Conf::CONF_GLOBAL);if(m_config==NULL)std::cout << "Create RdKafka Conf failed." << std::endl;/* 创建Topic Conf对象 */m_topicConfig = RdKafka::Conf::create(RdKafka::Conf::CONF_TOPIC);if (m_topicConfig == NULL)std::cout << "Create RdKafka Topic Conf failed." << std::endl;/* 设置Broker属性 */RdKafka::Conf::ConfResult errCode;std::string errorStr;m_dr_cb = new ProducerDeliveryReportCb;// 设置dr_cb属性值errCode = m_config->set("dr_cb", m_dr_cb, errorStr);if (errCode != RdKafka::Conf::CONF_OK){std::cout << "Conf set failed:" << errorStr << std::endl;}// 设置event_cb属性值m_event_cb = new ProducerEventCb;errCode = m_config->set("event_cb", m_event_cb, errorStr);if (errCode != RdKafka::Conf::CONF_OK){std::cout << "Conf set failed:" << errorStr << std::endl;}// 自定义分区策略m_partitioner_cb = new HashPartitionerCb;errCode = m_topicConfig->set("partitioner_cb", m_partitioner_cb, errorStr);if (errCode != RdKafka::Conf::CONF_OK){std::cout << "Conf set failed:" << errorStr << std::endl;}// 设置配置对象的属性值,都是在kafka全局配置对象中设置errCode = m_config->set("statistics.interval.ms", "10000", errorStr);if (errCode != RdKafka::Conf::CONF_OK){std::cout << "Conf set failed:" << errorStr << std::endl;}errCode = m_config->set("message.max.bytes", "10240000", errorStr);if (errCode != RdKafka::Conf::CONF_OK){std::cout << "Conf set failed:" << errorStr << std::endl;}errCode = m_config->set("bootstrap.servers", m_brokers, errorStr);if (errCode != RdKafka::Conf::CONF_OK){std::cout << "Conf set failed:" << errorStr << std::endl;}/* 创建Producer */m_producer = RdKafka::Producer::create(m_config, errorStr);if (m_producer == NULL){std::cout << "Create Producer failed:" << errorStr << std::endl;}/* 创建Topic对象 */m_topic = RdKafka::Topic::create(m_producer, m_topicStr, m_topicConfig, errorStr);if (m_topic == NULL){std::cout << "Create Topic failed:" << errorStr << std::endl;}
}KafkaProducer::~KafkaProducer()
{while (m_producer->outq_len() > 0){std::cerr << "Waiting for " << m_producer->outq_len() << std::endl;m_producer->flush(5000);}delete m_config;delete m_topicConfig;delete m_topic;delete m_producer;delete m_dr_cb;delete m_event_cb;delete m_partitioner_cb;
}void KafkaProducer::pushMessage(const std::string& str, const std::string& key)
{int32_t len = str.length();void* payload = const_cast<void*>(static_cast<const void*>(str.data()));RdKafka::ErrorCode errorCode = m_producer->produce(m_topic,RdKafka::Topic::PARTITION_UA,RdKafka::Producer::RK_MSG_COPY,payload,len,&key,NULL);m_producer->poll(0);if (errorCode != RdKafka::ERR_NO_ERROR){std::cerr << "Produce failed: " << RdKafka::err2str(errorCode) << std::endl;if (errorCode == RdKafka::ERR__QUEUE_FULL){m_producer->poll(100);}}
}
下面是KafkaProducer::KafkaProducer函数的流程
- 初始化成员变量:
m_brokers存储 Kafka broker 地址。m_topicStr存储 Kafka topic 名称。m_partition存储分区号。
m_brokers = brokers; m_topicStr = topic; m_partition = partition;
- 创建全局配置对象 (
m_config):- 通过
RdKafka::Conf::create(RdKafka::Conf::CONF_GLOBAL)创建 Kafka 全局配置对象。 - 如果创建失败,输出错误信息。
- 通过
m_config = RdKafka::Conf::create(RdKafka::Conf::CONF_GLOBAL); if(m_config==NULL) std::cout << "Create RdKafka Conf failed." << std::endl;
- 创建 Topic 配置对象 (
m_topicConfig):- 通过
RdKafka::Conf::create(RdKafka::Conf::CONF_TOPIC)创建 Kafka Topic 配置对象。 - 如果创建失败,输出错误信息。
- 通过
m_topicConfig = RdKafka::Conf::create(RdKafka::Conf::CONF_TOPIC); if (m_topicConfig == NULL) std::cout << "Create RdKafka Topic Conf failed." << std::endl;
- 设置回调函数和其他配置属性:
- 创建
ProducerDeliveryReportCb类的实例作为 delivery report 的回调函数。 - 创建
ProducerEventCb类的实例作为 event callback 的回调函数。 - 创建
HashPartitionerCb类的实例作为自定义分区策略的回调函数。 - 使用
set方法将这些回调函数设置到对应的配置对象中。 - 设置一些其他配置属性,如统计间隔、消息最大大小、以及 bootstrap.servers。
- 创建
m_dr_cb = new ProducerDeliveryReportCb; errCode = m_config->set("dr_cb", m_dr_cb, errorStr); m_event_cb = new ProducerEventCb; errCode = m_config->set("event_cb", m_event_cb, errorStr); m_partitioner_cb = new HashPartitionerCb; errCode = m_topicConfig->set("partitioner_cb", m_partitioner_cb, errorStr); // 其他配置属性的设置
- 创建 Kafka Producer 实例 (
m_producer):- 使用上述配置对象创建 Kafka Producer 实例。
- 如果创建失败,输出错误信息。
m_producer = RdKafka::Producer::create(m_config, errorStr); if (m_producer == NULL) { std::cout << "Create Producer failed:" << errorStr << std::endl; }
1. 创建topic对象
CMakeLists.txt
cmake_minimum_required(VERSION 2.8)project(KafkaProducer)set(CMAKE_CXX_STANDARD 11)
set(CMAKE_CXX_COMPILER "g++")
set(CMAKE_CXX_FLAGS "-std=c++11 ${CMAKE_CXX_FLAGS}")
set(CMAKE_INCLUDE_CURRENT_DIR ON)# Kafka头文件路径
include_directories(/usr/local/include/librdkafka)
# Kafka库路径
link_directories(/usr/lib64)aux_source_directory(. SOURCE)add_executable(${PROJECT_NAME} ${SOURCE})
TARGET_LINK_LIBRARIES(${PROJECT_NAME} rdkafka++)
测试文件main.cc
#include <iostream>
#include "KafkaProducer.h"
using namespace std;int main()
{// 创建Producer// KafkaProducer producer("127.0.0.1:9092,192.168.2.111:9092", "test", 0);KafkaProducer producer("127.0.0.1:9092", "test", 0);for(int i = 0; i < 10000; i++){char msg[64] = {0};sprintf(msg, "%s%4d", "Hello RdKafka ", i);// 生产消息char key[8] = {0}; // 主要用来做负载均衡sprintf(key, "%d", i);producer.pushMessage(msg, key); }RdKafka::wait_destroyed(5000);
}
编译:
mkdir build
cd build
cmake ..
make
4. 总结
Kafka Producer使用流程:
创建Kafka配置实例。
创建Topic配置实例。
设置Kafka配置实例Broker属性。
设置Topic配置实例属性。
注册回调函数(分区策略回调函数需要注册到Topic配置实例)。
创建Kafka Producer客户端实例。
创建Topic实例。
阻塞等待Producer生产消息完成。
等待Produce请求完成。
销毁Kafka Producer客户端实例。

![[ 蓝桥杯Web真题 ]-布局切换](https://img-blog.csdnimg.cn/img_convert/eb91b2d102d8af1da7def68abf95e729.png)