接part1介绍:
如何达到这个目的?业内常用的是对写入数据的数据进行随机化处理,这部分主要在SSD控制器中通过硬件实现。
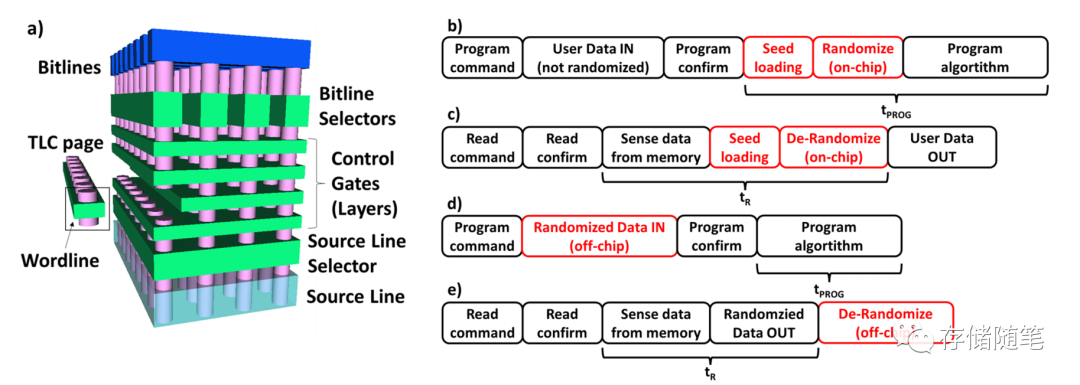
-
上图b/c:在控制器芯片通过硬件方式实现随机化的读写流程,这个也是业内通常做法。随机化处理是在写入数据之前完成,也是在LDPC encode之前。这部分随机化处理时间,也是会影响数据写入时间tPROG和读取出来tR。
-
上图d/e:随机化处理不是通过硬件实现,在业内并不常见做法。软件的方式处理很慢,且容易出现问题。
随机化的实现方式有多种,其中一种是利用线性反馈移位寄存器(LFSR)进行随机化。LFSR是一种可以用于生成伪随机序列的线性反馈移位寄存器,其初始值称为种子(seed)。其原理是将存储的数据进行移位操作,并向最低位添加新的随机数据。这个新的数据是根据一个特定的反馈函数生成的,它确保了序列的随机性。
ALFSR和LFSR是两种不同类型的随机数生成器,它们之间的区别主要体现在应用场景和生成随机数的机制上。
LFSR(Linear Feedback Shift Register)是一种线性反馈移位寄存器,它利用线性反馈的方式从一些输入位中选择一些位并将其移到输出位,从而实现随机数的生成。LFSR的优点是简单、速度快、硬件实现简单,但它的随机性相对较差,容易受到反馈函数的影响,可能存在预测性和循环性等问题。LFSR 有一个特点,如果初始状态不是全零,那么它会在 2^k - 1 个状态后回到初始状态,其中 k 是寄存器的位数。这个周期性使得 LFSR 生成的序列不会出现重复。
ALFSR(Advanced Linear Feedback Shift Register)是一种高级线性反馈移位寄存器,它是在LFSR的基础上改进而来的,通过增加更多的状态和反馈函数来提高随机性。ALFSR的反馈函数更复杂,可以更好地混合输入位,从而生成更随机、不可预测的随机数。此外,ALFSR还采用了多周期跳变和状态跳跃等技术,可以更好地防止循环和预测性。
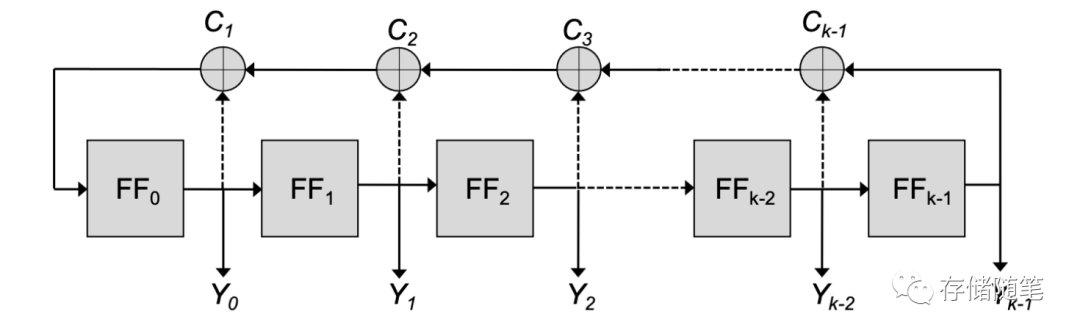
因此,ALFSR和LFSR的主要区别在于应用场景和生成随机数的机制。LFSR适用于对随机性要求不太高、简单快速的随机数生成场景,而ALFSR则适用于对随机性要求较高、需要更高质量和更安全随机数的场景,例如密码学、信息安全、计算机程序等。
LFSR/ALFSR方法也有一些局限性,它不能保证垂直方向上的数据随机化,比如下图,4-bit AFSR随机化处理后,依然有垂直方向的连续1或者连续0。
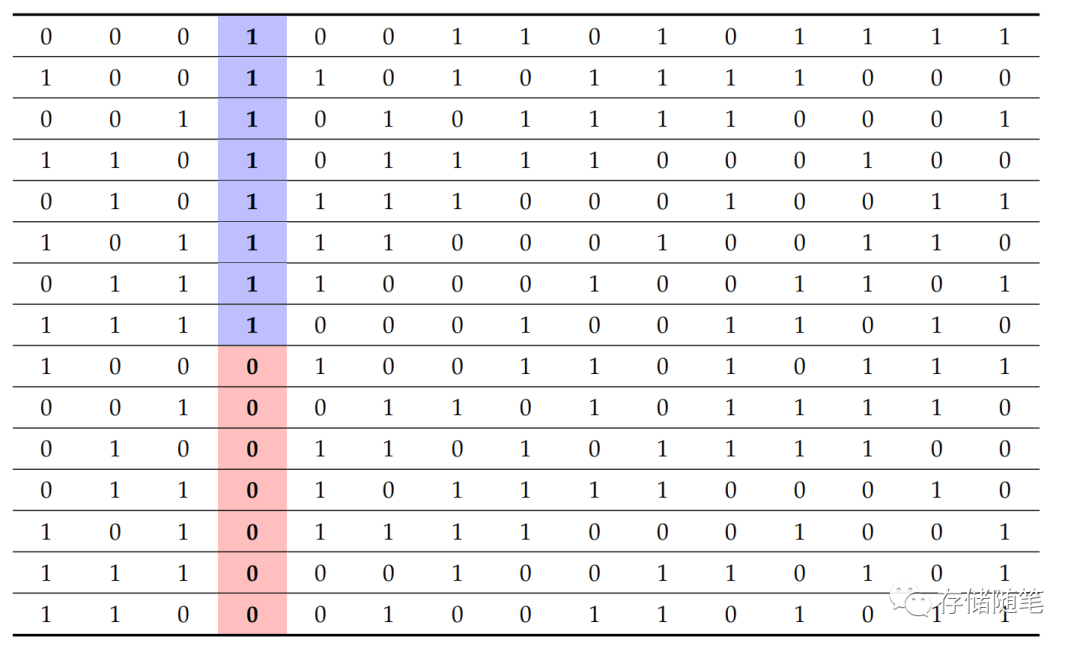
为了解决这个问题,有些控制器制造商会采用多种子方法来降低不同 ALFSR/LFSR 之间数据的相关性,从而增强数据的随机性。比如下图中,垂直方向和水平方向,均实现了随机化处理。
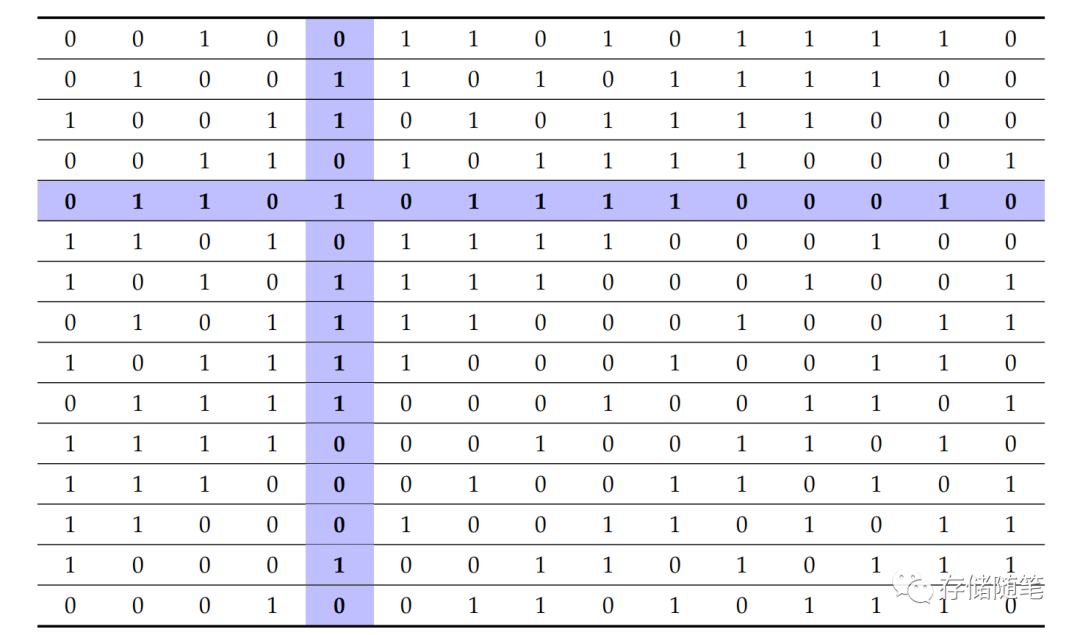
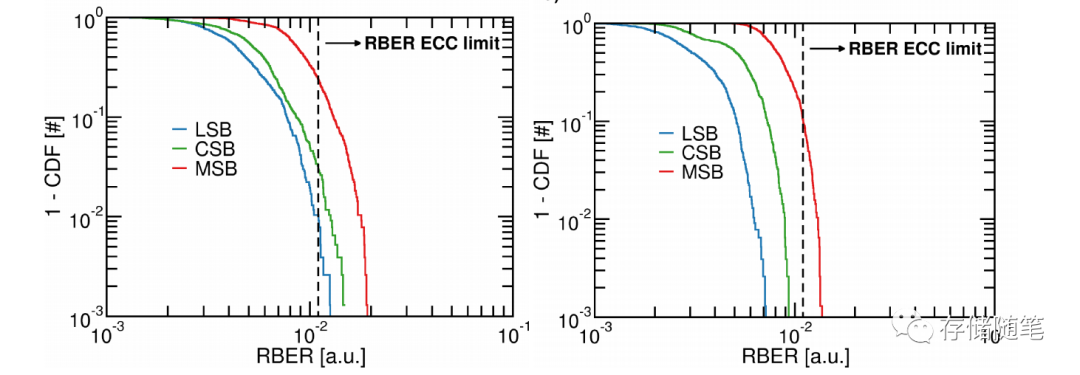
水平方向随机化(Horizontal Centric,HC)和双向随机化(Bidimensional Randomization)的效果对比如何呢?
在Endurance测试方面:
-
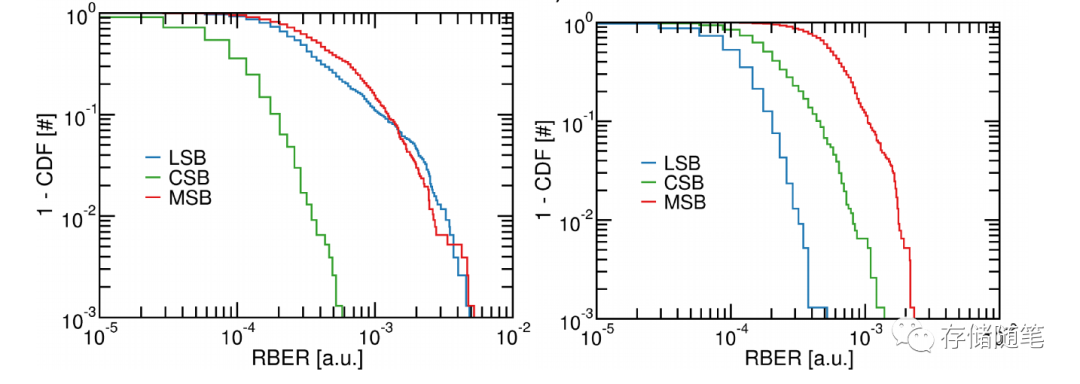
下图左-水平方向随机化:LSB、CSB、MSB的REBR相差很大,特别是LSB/MSB REBR较差
-
下图右-双向随机化:RBER均有了较大的提升,其中LBA效果最好。
在Retention测试方面:
-
下图左-水平方向随机化:LSB、CSB、MSB的REBR均超过了ECC最高界限
-
下图右-双向随机化:只有MSB超过了ECC最高界限,提升也很明显。