Micro-expression spotting based on optical flow features
基于光流特征的微表情检测
Abstract
本文提出了一种高精度和可解释性的自动微表情检测方法。首先,我们设计了基于鼻尖位置的图像对齐方法,以消除由头部晃动引起的全局位移。其次,根据面部编码系统(FACS)中的动作单元定义,我们选择了十四个感兴趣区域(ROI)来捕捉微妙的面部运动。引入了密集光流来估计ROI的局部运动和时域变化。第三,我们设计了一种峰值检测方法,用于在时域变化曲线上精确定位运动间隔。最后,我们提出了一个重叠指数来衡量不同器官变化的一致性。在CAS(ME)2和SAMM Long Video数据库上的评估显示,我们的微表情检测方法在相对较低的计算成本下可能实现更高的准确性,并可应用于类似的面部图像处理应用。
1. Introduction
微表情(ME)检测是微表情研究的关键任务,旨在从长视频序列中定位微表情间隔[6]。微表情检测的效果将影响对微表情的后续分析。然而,由于微表情的强度极小,如图1所示,头部晃动、眨眼、面部差异等许多因素会降低检测结果的准确性。因此,微表情检测的准确性一直较低。因此,准确捕捉微弱的微表情运动并消除不相关的干扰被认为是一项具有挑战性的任务。本文提出了一种具有高准确性和可解释性的自动微表情(ME)检测方法。
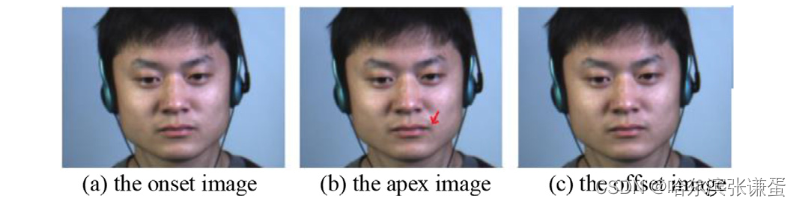
图1. 微表情起始、顶点和结束图像的示意图[6]。顶点帧包含最显著的微表情运动信息,红色箭头指向局部运动发生的区域。
LBP提取纹理特征,Li等人通过划分区域去提取区域的纹理特征---纹理特征对于检测面部运动性能较差。
LTP通过提取纹理变形的局部信息来进行微表情检测,但是LTP可能会受到不同面试者面部纹理信息差异的影响。
光流方法基于时序上的水平和垂直像素的变化寻找两个图像之间的变化关系。利用光流特征主方向的最大差异来检测微表情。由于摇头会降低光流特征的准确性,因此许多工作都致力于人脸对齐技术。一种常用的人脸对齐方法是在每个视频图像中根据面部标志对面部进行对齐和切割 [15,18],这在宏观表情分析中效果良好。然而,考虑到微表情的微小运动,面部标志的位置算法不够精确。这种方法无法满足微表情检测的要求。张等人 [19] 提出使用鼻部区域的均值光流特征估计全局面部位移,并从局部光流特征中去除全局运动以获取面部运动。
张等人 [20] 首次使用深度学习方法检测微表情。他使用卷积神经网络从微表情图像中提取特征。
于等人 [22] 提出了基于位置抑制的微表情检测网络(LSSNet)来检测微表情。由于很难收集微表情运动并标记它们,现有ME数据库的规模较小,无法满足使用深度学习模型的要求,从而导致过拟合等问题。基于深度学习的ME检测方法通常缺乏明确的依据,结果也不具有可解释性。在异常行为检测和情感监测的应用场景中,没有明确的证据支持,无法接受微表情检测和识别的结果。
本文:包括基于鼻尖位置的图像对齐方法、基于面部动作单元(AU)选择的十四个感兴趣区域(ROI)、使用光流进行特征提取、建立时域变化曲线以及从不同ROI中融合局部运动。
预处理:选用给予鼻尖位置的图像对齐方法来消除头部摇晃对光流特征的干扰。
ROI的选取:根据FACS的划分,选取十四个ROI建立时间域的变化曲线,并使用光流的方法对十四个RIO进行特征提取。
检测:设计了一种峰值检测方法,用于在时域变化曲线上精确定位运动间隔。
检测指标:我们提出了一个重叠指数来衡量不同器官变化的一致性。
总体而言,本文的idea由于光流方法在捕捉面部微妙的动态信息方面表现良好并且具有良好的可解释性,我们使用光流方法来估计面部运动。为了消除头部摇晃对光流特征的干扰,我们提出了一种基于鼻尖位置的图像对齐方法,有效提高了光流特征的准确性。在此基础上,我们根据面部编码系统(FACS)[23]中的动作单元(AU)的定义,在面部选择了十四个感兴趣区域(ROI)。我们实施光流方法来提取十四个ROI的特征并建立时间域变化曲线。使用峰值检测方法可以在时间域变化曲线上精确定位局部运动间隔。最后,有选择地融合不同ROI的局部运动,以准确计算微表情间隔。
- 我们提出了针对鼻尖位置的图像对齐方法的偏差度量指标,以确保微表情光流特征的准确性,并提供了一个精确的算法。
- 我们设计并实现了一个宏观和微观表情识别方法,并给出了整体方法的框架。
- 在实验部分,我们添加了面部动作单元(AU)分类的实验。分类结果进一步证明了偏差度量指标对面部对齐的有效性,光流特征能够捕捉微小的微表情运动。
- 我们进行了消融实验来验证鼻尖位置图像对齐方法的有效性,并讨论了改进识别结果的原因。
- 原始数据库中添加了包含微表情和宏观表情长视频的CAS(ME)2数据集。我们在CAS(ME)2数据库上进行了微表情和宏观表情的识别实验。在CAS(ME)2和SAMM Long Video数据库上的评估显示,我们的微表情识别方法在相对较低的计算成本下可能实现更高的准确性,并可应用于类似的面部图像处理应用。
我们将本文的其余部分组织如下:在第2节中,我们详细介绍Farneback光流方法[25]、提出的基于鼻尖位置的图像对齐方法、局部运动检测和融合方法。在第3节中,我们介绍了这个实验并讨论了我们方法的结果。最后,结论部分总结了本文并讨论了未来工作的可能性。
2. Macro- and micro-expression spotting method
在实际工作中,我们设计并实现了一个宏观和微观表情的识别方法。输入是一个长视频,输出是所有识别到的宏观和微观表情的时间段。如图2所示,我们使用一个固定的滑动窗口覆盖N帧图像来划分视频,然后在滑动窗口中识别宏观表情和微观表情。
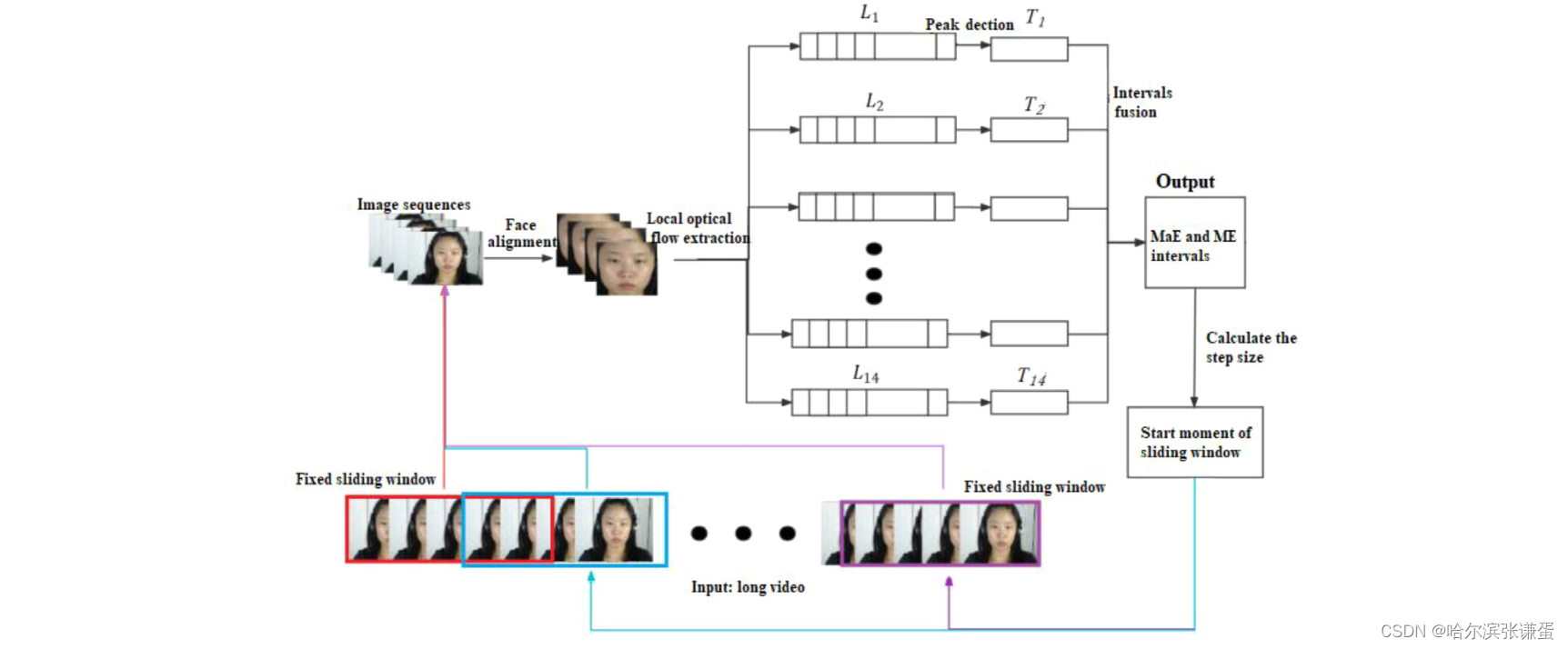
图二。宏表情和微表情定位方法的框架。
fixed sliding Window:固定滑动窗口;Image sequence:图像序列;local optical flow extraction:局部光流提取(十四个ROI生成是个局部光流序列);Peak detection:峰值检测;intervals fusion:间隔融合;MaE and ME intervals:MaE 和 ME 间隔;calculate the step size:计算步长;start moment of sliding windows:滑动窗口的起始时刻
在微表情检测中,"intervals fusion" 指的是将检测到的局部运动间隔(intervals)合并,以得到完整的微表情区间。微表情通常包含多个局部面部运动,因此首先检测这些局部运动,然后将它们融合在一起,形成一个完整的微表情区间。
在上下文中,"intervals" 可能指代一系列在时间轴上的连续图像帧,这些图像帧显示了面部运动的变化。"Fusion" 则表示将这些局部运动间隔整合为一个更全面的表达,以更准确地表示整个微表情的发生和结束。
这个过程有助于综合考虑多个局部运动,提高微表情检测的准确性,确保捕捉到完整和一致的微表情。
在滑动窗口中识别图像序列表情的过程包括四个步骤:面部对齐、局部光流特征提取、局部运动检测和局部运动间隔融合。然后,得到表情间隔集合T={[start1, end1], [start2, end2], ..., [startlast, endlast]}。滑动窗口的步长(S)根据识别到的表情的位置进行自适应调整。
如果在当前窗口中没有检测到微表情。
S = N/ 2 (1)
如果检测到微表情,
S = endlast + 1 (2)
在接下来的章节中,我们将介绍我们提出的微表情检测方法中使用的几种技术。
2.1. Farneback optical flow method ---Farneback光流法
本文使用Farneback光流方法[25]来估计面部运动。在使用光流方法时,必须满足两个条件:首先,视频图像的亮度保持恒定。其次,物体在时间域内的位置变化不会发生剧烈变化。
如公式(3)和(4)所示,在图像I1和I2上进行多项式估计:
I1(p)=pTA1p+ bT1p + c1(3)
I2(p) = pTA2p+bT2p+c2(4)
A1和A2是对称矩阵,bT1和bT2是向量,c1和c2是标量。p = (x, y)表示像素点,x是水平坐标,y是垂直坐标。I1(p)是图像I1在点p处的灰度值。假设图像I1和I2之间存在全局位移dis,可以得到第二张图像的多项式估计:
I2(p) = I1(p−dis) = (p−dis)TA1(p−dis) + bT1(p−1) +c1 (5)
= pTA1p+(b1−2A1dis)Tp +disTA1dis−bT1dis+c1
根据公式(4)和(5),以下三个方程成立:
A2 = A1(6)
b2 = b1 − 2A1dis(7)
c2 = disT A1dis − bT1dis + c1(8)
如果A1是非奇异矩阵,全局位移dis可以计算为:
dis =−½A−11(b2−b1) (9)
光流方法可以捕捉物体的微小运动信息,并对纹理差异具有鲁棒性。
假设 I = {I1, I2, ..., IN} 是一个微表情视频的图像序列,并且在序列 {I2, I3, ..., IN} 中的每一帧图像与第一帧图像I1之间实施 Farneback 光流方法,以计算密集光流图序列{F1, F2, ..., FN−1}.。
Fi= Franeback(I1, Ii+1 ), Fi∈Rw×h×2 (10)
Fi表示 Ii+1与第一帧图像I1之间的密集光流图,它包含两个表示:水平和垂直方向光流的矩阵。假设d是图像I0中点 p = (x, y)的运动。光流方法估计了在点 p = (x, y)处的运动为 u = Fi[x, y]。光流向量u 被认为是微表情相关运动 d和摇头运动v 的叠加。
u= d + v (11)
由于微表情的强度较小,摇头运动 v 可能会覆盖微表情运动 d,导致微表情特征的信噪比较低,给微表情分析带来了困难。因此,面部对齐方法对提高光流特征的准确性至关重要。
2.2. Nose tip location-based image alignment method--基于鼻尖位置的图像对准方法
面部对齐是确保微表情特征准确性的基本保证。基于鼻尖位置的图像对齐方法通过在图像序列中对齐面部来提高微表情识别结果。在这里,我们定义了偏差测量指数 b,它衡量了基于特定器官的图像序列中面部位置的变化。
我们定义了面部区域内的两个窗口,即面部裁剪框 Bface 和鼻尖裁剪框 Bnose,如图3所示。面部裁剪框覆盖了被试的脸部并去除了背景信息。根据当前的微表情研究,鼻尖在表情时不会移动。因此,我们根据鼻尖区域的平均光流来估计全局面部运动。当被试的脸在图像序列中移动时,我们根据每个图像的偏差测量指数 b 连续调整这两个窗口。面部和裁剪框的相对位置在图像序列中保持稳定。最后,根据鼻尖裁剪框 Bnose 对每个图像进行裁剪。

图3显示了面部裁剪框和鼻尖区域框的示意图。绿色框是面部裁剪框,黑色框是鼻尖框。鼻尖区域的放大图在左下角,其中绿色点表示鼻尖点。
偏移度量指数 b:该指数 b=(m,n)T 用于测量面部和裁剪框的相对位置变化,其中 m表示水平移动, n 表示垂直移动。偏移度量指数b 的计算如公式 (12) 所示。
 在公式 (12) 中, Fnose 是第一帧图像和当前图像之间鼻尖区域的密集光流, Fnose=Franeback(NOSE1,NOSEc),其中 Fnose∈Rwn×hn×2, wn 和hn 是鼻尖区域 NOSEc 的宽度和高度。我们通过基于 Bnose 对当前图像进行切割来获得 NOSEc。该过程如算法 1 所示。
在公式 (12) 中, Fnose 是第一帧图像和当前图像之间鼻尖区域的密集光流, Fnose=Franeback(NOSE1,NOSEc),其中 Fnose∈Rwn×hn×2, wn 和hn 是鼻尖区域 NOSEc 的宽度和高度。我们通过基于 Bnose 对当前图像进行切割来获得 NOSEc。该过程如算法 1 所示。
2.3.2. Peak detection and fusion method based on time-domain change curves
当发生微表情时,我们可以观察到 AU 生成区域的时间域变化曲线上出现了峰值。因此,我们通过检测时间域变化曲线的峰值来估计局部运动区间。我们对每个 ROI 的时间域变化曲线执行峰值检测方法,得到一组峰值区间Ti = {[start1, end1]i, ......, [startn, endn]i}, i ∈ {1, ..., 14}, i是 ROI 的索引,如算法 2 所示。首先,我们使用阈值 δ对时间域变化曲线 L j应用低通滤波器,以去除高频噪声。随后,我们通过计算滑动窗口中心位置处的曲线值与中心左右区域最小值之间的差异来检测波峰。r是滑动窗口的半径。如果差异足够大,我们认为这个中心点属于一个波峰,并将该点放入峰值集合中。然后移动滑动窗口以计算新的中心点。最后,将峰值中的相邻点连接起来形成时间区间[start, end],将其添加到Tj中。

由于微表情包含一个或多个 AU,当发生局部面部运动时,就认为出现了微表情。当多个局部运动在相似的时间出现时,我们需要分析这些局部运动是否属于同一个微表情。此外,将属于同一表情的局部运动组合在一起,以获取完整的微表情区间。

使用重叠指数 μ 判断两个不同 ROI 的局部运动([startl, endl] 和 [startr, endr])是否属于同一微表情。
如果 μ 大于阈值 γ,则认为这两个局部运动属于同一微表情,并将它们合并为一个新的区间 [startnew, endnew]。
![]()
计算每两个局部运动的重叠指数 μ,以获取微表情的区间 TME = {[start1, end1], ......, [startV, endV]}。
3. Experiments and results
3.1. Databases and metric
我们使用两个主要的基准数据集进行宏表情(MaE)和微表情(ME)的定位:CAS(ME)2 [11] 和 SAMM 长视频 [18]。CAS(ME)2 包含 300 个宏表情(MaEs)和 57 个微表情(MEs)。CAS(ME)2-cropped 是 CAS(ME)2 的裁剪版本。SAMM 长视频数据集包含 343 个宏表情和 159 个微表情。CAS(ME)2-cropped、CAS(ME)2 和 SAMM-LV 的详细信息总结在表2中。

计算定位到的区间 Qspotted 与真实区间 QgroundTruth 之间的 IoU,以区分 Qspotted 是否是正确的检测,如公式(18)所示。

如果 IoU 大于阈值 k(k 设为 0.5),则 Qspotted 是真正的阳性结果(TP)。相反,它是假正结果(FP)。使用 F1 分数来评估提出的方法。我们通过公式(19)-(21)计算宏表情、微表情和整体的 F1 分数。

AME 和 AMaE 是真正阳性结果的数量;MME 和 MMaE 是所有 ME 和 MaE 区间的数量;NME 和 NMaE 是被发现的 ME 和 MaE 区间的数量。
3.2. Experiment configuration
在实验中,滑动窗口的长度 N 被设置为包含在七秒视频间隔内的图像数。我们使用相同的方法来检测宏表情和微表情。持续时间小于 0.5 秒的表情被视为微表情。我们使用 Dlib 工具 [26] 来定位脸部的 68 个关键点。原始图像在面部切割后被规范化为 240 × 240。ROI 的大小被设置为 10×10 像素。在峰值检测方法中,搜索半径 m 被设置为视频中包含的一秒间隔内的图像数。上述参数都是经验值。在峰值检测方法中,眼睛区域 ROI 的阈值 θeye 为 2.4 像素,嘴巴区域 ROI 的阈值 θmouth 为 2.2 像素,鼻翼区域 ROI 的阈值 θnose 为 2.0 像素。局部运动融合方法中的阈值 γ 为 0.1。
3.3. Analysis of experimental results
3.3.1. AUs classification result
AU(面部动作单元)分类被认为是分析微表情的强大工具 [27,28]。我们使用在第一张图像和表情达到最高点的图像之间的十四个 ROI 的平均光流向量 diapex= (miapex, niapex )T ,其中 i ∈ {1, 2, ..., 14} 进行 AU 分类。如图 4 所示,ME 的最高点图像可以从时间域曲线的最高点搜索到。同时,在我们提出的 ME 检测方法中计算了 diapex= (miapex, niapex )T。使用 SVM 作为分类器,输入是十四个 ROI 的平均光流向量。
![]()
并且输出是 One-Hot 编码,表示 AU 的存在或不存在。

图4. 十四个感兴趣区域(ROI)的示意图 [12]。
我们使用精确度(PRE)和 F1 分数来评估提出的 AU 分类方法。我们采用了5折交叉验证策略,并计算了5折分类结果的平均值作为最终结果。CASME II [6] 中的 AU 分类结果如表3所示。分类结果进一步证明了基于面部对齐的偏差测量指数以及所提出的局部特征能够捕捉微妙的微表情运动。

3.3.2. Macro- and micro-expression spotting results of databases
参数分析。我们分析了峰值检测方法和局部运动融合方法中参数的影响,如图7所示。使用 F1 分数评估了宏表情(MaE)和微表情(ME)的检测性能。

图7. 参数对检测性能的影响。 (a) 参数θeye的影响。横轴表示θeye的值。 (b) 参数γ的影响。横轴表示γ的值。 (a) 和 (b) 中的纵轴表示在CAS(ME)2上的MaE和ME检测的F1分数。
如图7(a)所示,当θeye为2.4像素时(红线),检测性能最佳。根据峰值检测方法,当θeye变小时,将检测到幅度较小的表情,真正阳性结果的数量会提高。然而,较小的θeye也会带来更多噪声,假正例的数量也会增加。因此,当假正例显著增加时,F1分数开始下降。θmonth和θnose的值的确定方式与θeye相同。参数γ表示两个局部运动之间的重叠指数的阈值。从图7(b)中可以看出,当阈值γ为0.1时,检测性能最佳。
MaE和ME的检测性能。在两个数据库CAS(ME)2和SAMM Long Videos中进行了实验,结果如表4和表5所示。对于CAS(ME)2,精度为0.2634,召回率为0.5350,F1分数为0.3530。对于SAMM Long Videos,精度为0.3824,召回率为0.3565,F1分数为0.3690。由于MaE的强度大于ME,因此MaE的检测结果显著高于ME。
消融实验分析。我们通过比较提出的方法和去除调整切割框步骤的方法进行了消融实验。通过执行光学特征u与全局运动向量v之间的差分运算来计算运动d。表6中的结果表明,通过调整切割框步骤,检测结果显著改善,这表明了所提出的面部矫正方法的重要性。当头部晃动较大时,如图8(a)所示,u和v是基于两个大位移估计的,这不符合光流方法的条件。通过光流方法估计全局运动v和局部运动u将产生显著的误差。因此,结果d也是不准确的。通过调整切割框,面部与切割框在后续图像中的相对位置保持稳定,降低了全局运动v的振幅,如图8(b)所示。此时,u和v都反映出最小的位移,符合光流方法的要求,u和v将更加准确。然后,通过公式(11)获得运动d。


图8. 在面部对齐前后局部区域的光流向量示意图。
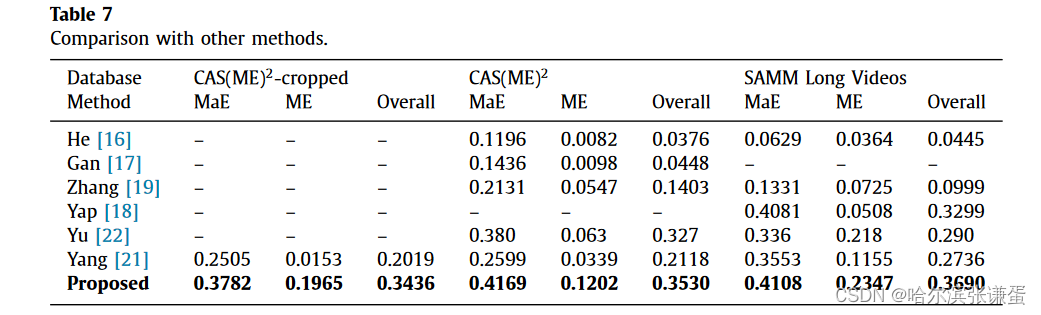
与其他方法的比较。表7比较了不同方法在检测宏表达、微表达和总体方面的效果。所提出的方法在微表达、宏表达和总体数据库的F1分数显著高于其他研究。
4. Conclusion
本文提出了一种自动微表情(ME)检测方法。首先,为了在长视频中对齐面部,我们设计了一种基于鼻尖位置的图像对齐方法,该方法基于面部表情和肌肉运动的特征。其次,我们实现了密集的光流方法,以捕捉脸部十四个感兴趣区域的微小运动并构建时域变化曲线。第三
所提出的方法在CAS(ME)2和SAMM Long Videos数据库上进行了评估。对于CAS(ME)2数据库,F1分数为0.3530。对于SAMM数据库,F1分数为0.3682。与其他微表情检测方法相比,该方法的检测结果得到了很大的改善。所提出的特征不仅可用于微表情检测,而且在AU分类中也表现良好。在未来的工作中,我们将尝试构建一个基于多特征融合的微表情检测和识别系统。
Declaration of Competing Interest
作者声明他们没有已知的可能影响本文报告的竞争性财务利益或个人关系。Haifeng Li 报告称其得到了黑龙江省科技厅的资助。Lin Ma 报告称其得到了中华人民共和国科学技术部社会发展科技司的资助。
Data Availability
已经使用的数据是保密的。
Acknowledgments
这篇论文的早期版本[24]曾在2021年ACM多媒体国际会议上报告。该工作得到了中国国家重点研发计划(2020YFC0833204)和黑龙江省重点研发计划(GY2021ZB0206)的部分支持。

![[NAND Flash] 3.1 闪存的组成结构原理与使用挑战](https://img-blog.csdnimg.cn/direct/a85eca0f4e874071b5cebc43aa8a2049.png#pic_center)

