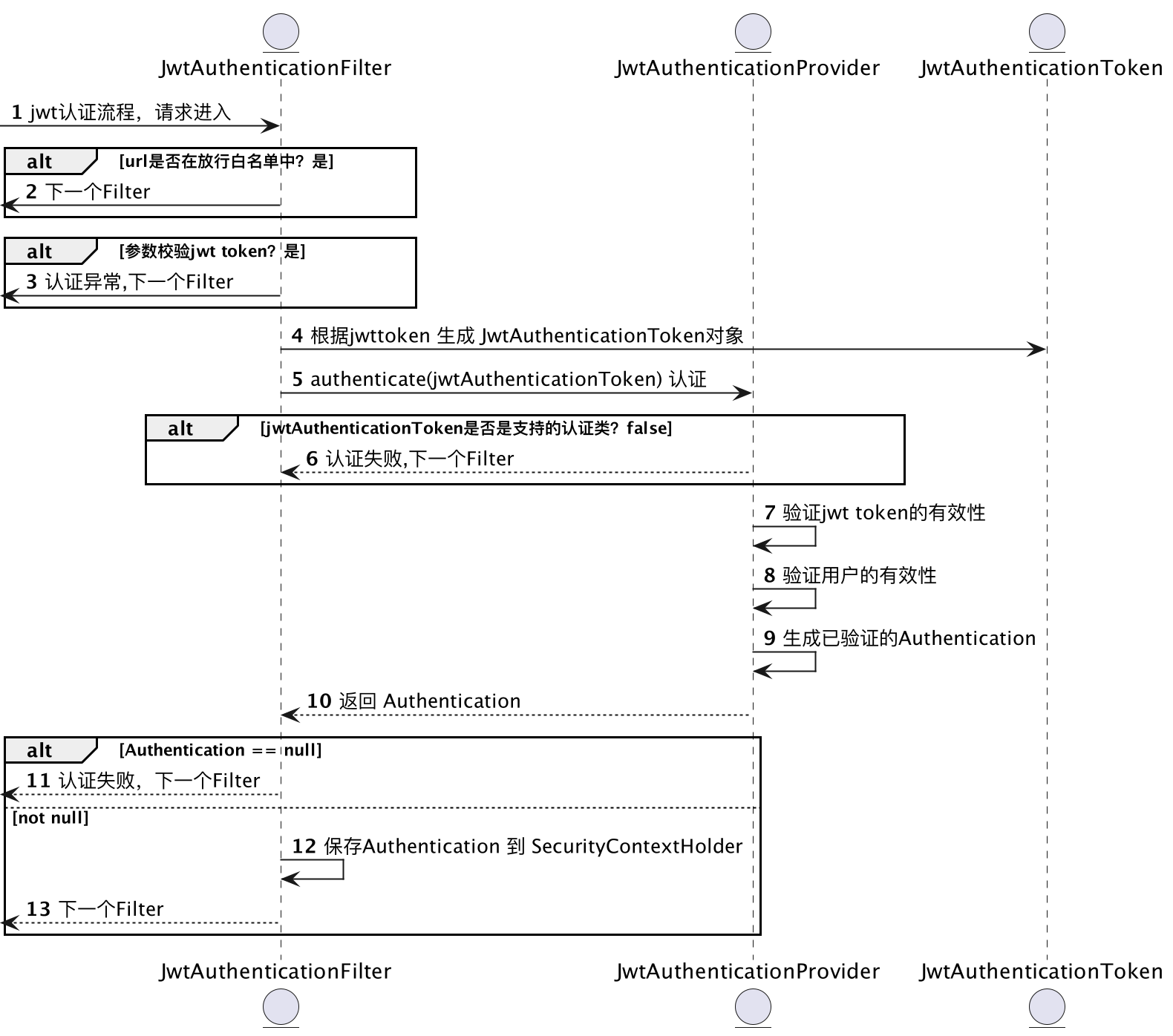
文章目录
- 前言
- 储存系统
- 地址转换
- 内存扩展
- 覆盖
- 交换
- 储存器分配——连续分配
- 固定大小分区
- 动态分区分配
- 动态分区分配算法
- 储存器分配——非连续分配
- 页式管理
- 基本思想
- 地址变换硬件
- 快表(TLB)
- 多级页表
- 段式管理
- 段页式管理
- 虚拟储存器——基于交换的内存扩充技术
- 基本概念
- 请求分页
- 页面置换算法
- 页面分配策略、抖动、工作集
- 内存映射文件
- 文件管理
前言
属实是极限冲刺了,距离考研还有10天,我还有俩本书没学完(乐),昨天一下午一晚上学完进程,今天再接再厉,直接学完储存和文件系统
IO部分参见我的计组笔记,非常详细
储存系统
我不喜欢重复造轮子,这一章我会比较简略,尽量写高层次的思想,具体内容我的另一篇笔记里面记录的很详细,如果基础不是很好,可以对照看。
操作系统笔记——储存器管理、文件管理、设备管理

地址转换
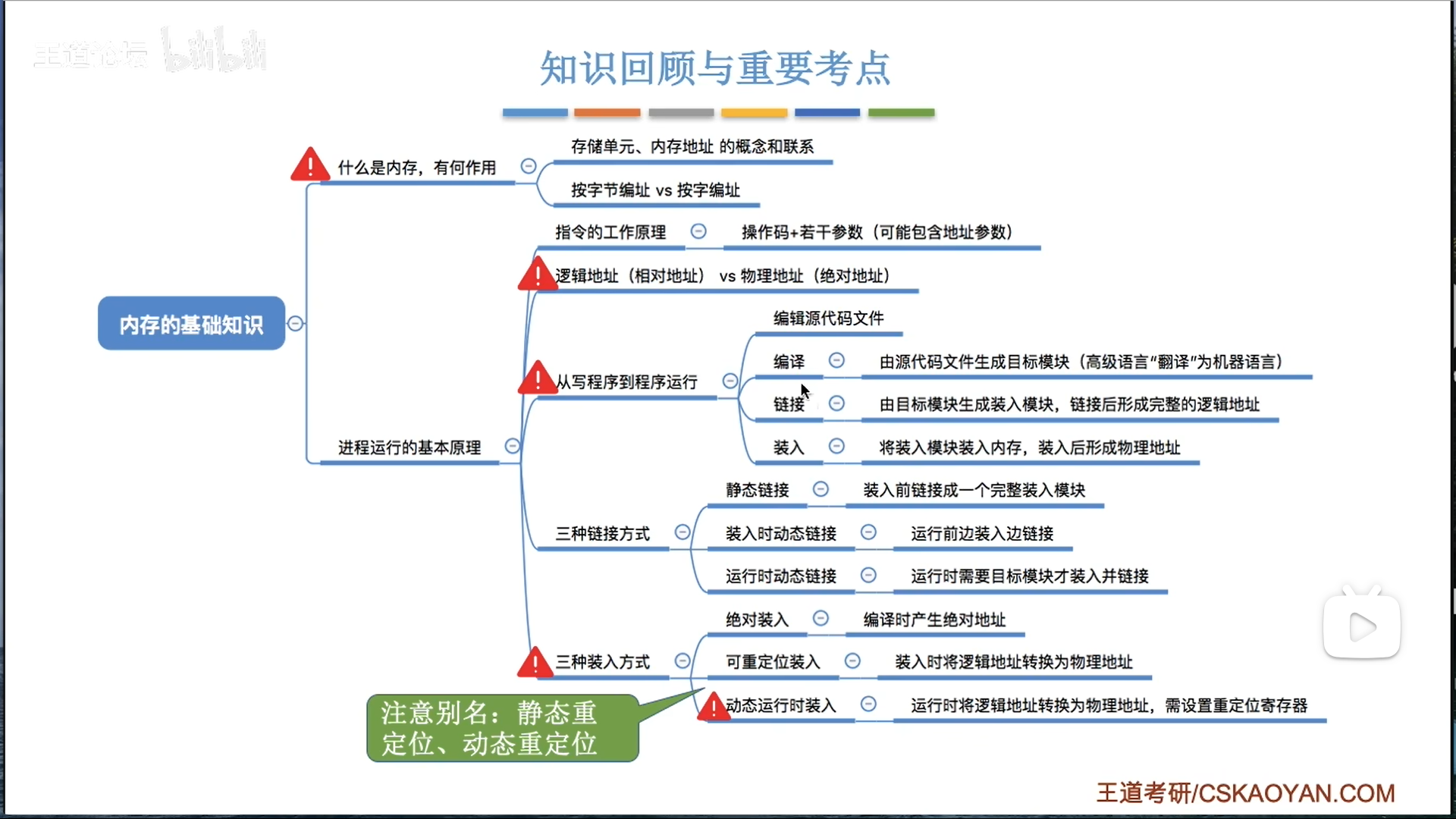
关于物理地址:
- 逻辑地址:从源程序到汇编语言程序的这些阶段,都用逻辑地址
- 逻辑地址默认0为地址起点,不考虑和其他程序之间的相互作用
- 因此,后续几步,直到把程序装入内存的整个过程,肯定是要将逻辑地址变为物理地址的
- 后续的步骤为编译链接为目标模块,装入内存。如何变,就形成了3种不同的方法
- 绝对装入(很low,没OS才这么做):在编译链接阶段形成物理地址
- 静态重定位(可重定位装入):在装入的过程中,将指令内容修改,形成物理地址
- 动态重定位(动态运行时装入):指令内容一直是逻辑地址,使用
重定位寄存器辅助地址偏移,在程序真正运行访存的时候才形成物理地址
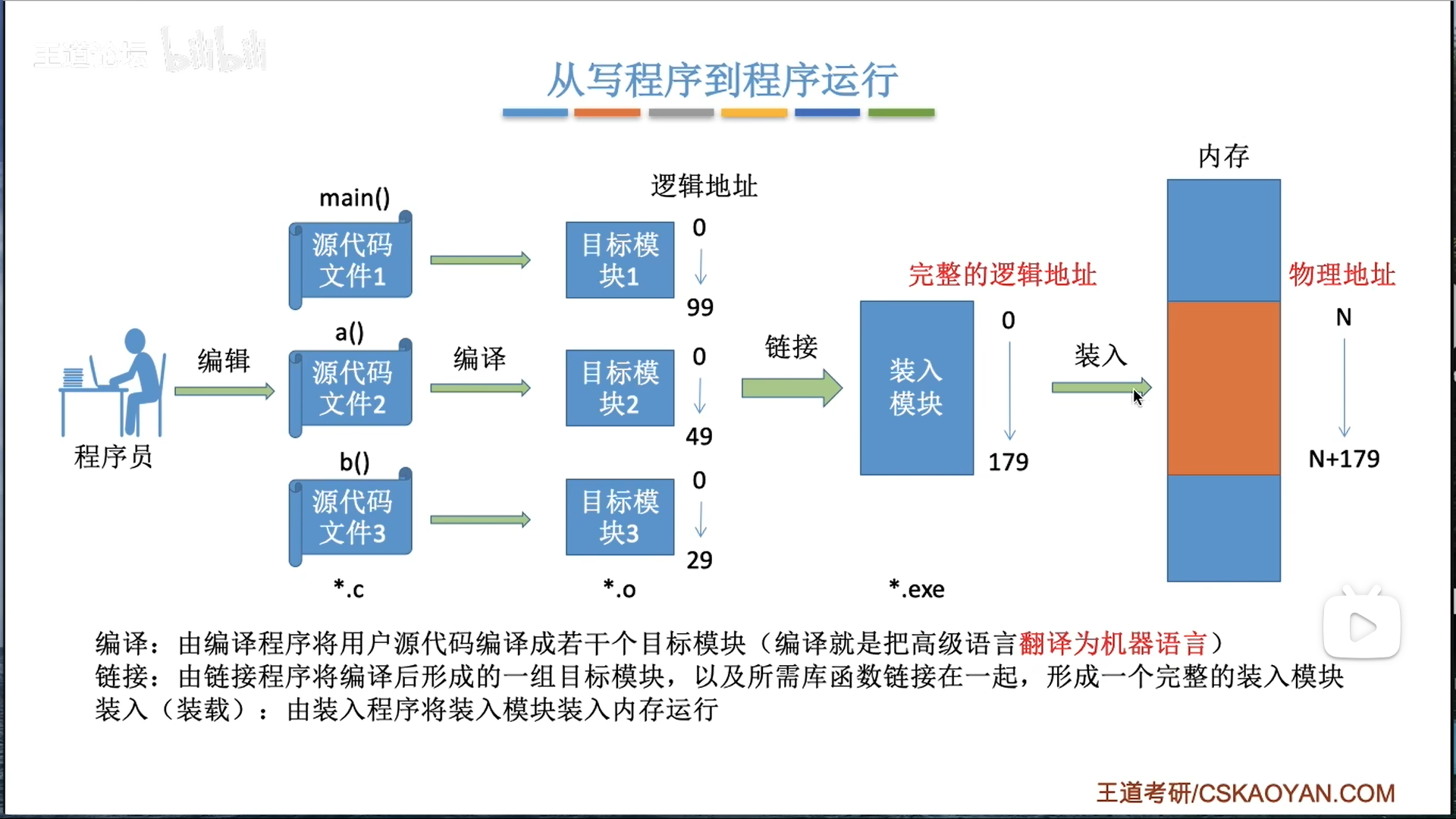
(才发现我们OS老师上课用的那张图是从王道这里来的,我就说风格怎么不一样)
我们前面讨论的是如何形成物理地址,其实形成如何把多个.o文件的逻辑地址统一起来,也是一个需要注意的点,这个技术就是链接
- 静态链接:链接阶段一次性组合
- 动态链接
- 装入时动态链接:装入的时候,一次性组合
- 运行时动态链接:调用的时候,才针对性的装入对应的模块(.dll动态链接库)
联系前面的物理地址生成,很显然,绝对装入方法只能搭配静态链接使用,而动态链接只能和重定位方法结合使用
视角抬高,内存管理除了负责部分地址转换以外,还有很多功能。
内存保护的两种思路:
- 上下限寄存器:直接记录程序物理地址的上下线
- 重定位寄存器+界地址寄存器:界地址寄存器规定了逻辑地址的上限
内存扩展

覆盖
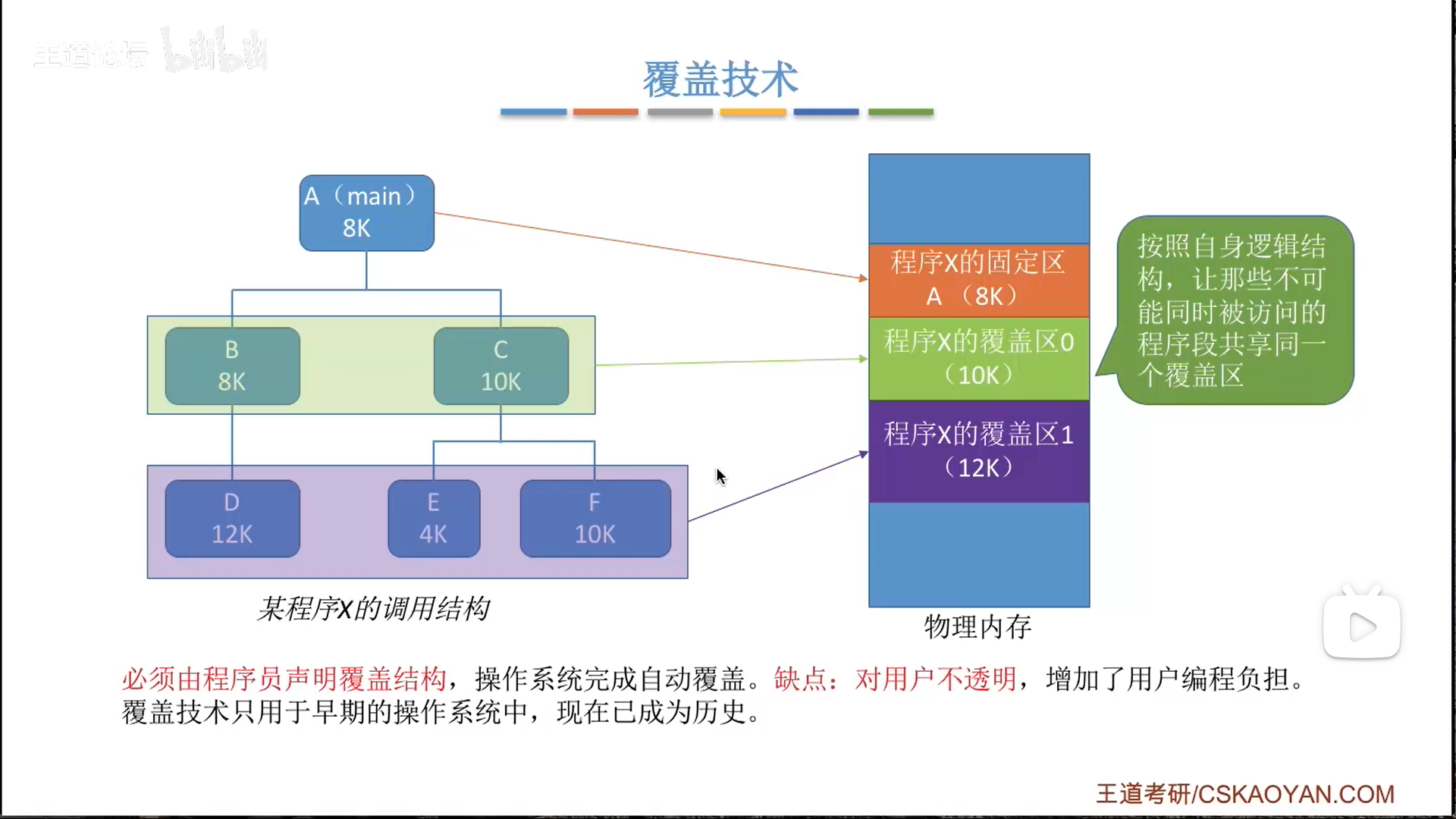
覆盖,就是让互斥的程序段公用一片内存,有两种可能:
- 固定区:互斥程序段只有一个,那么这片区域就是独占
- 一般来说,只有一个固定区(main函数)
- 覆盖区:有多个程序公用,每一个覆盖区都由当前覆盖段里占内存最大的模块决定。
- 比如B先用内存,C要用,就把B的部分直接覆盖就行,这也是这个名字的来源
这个方法的缺点就是需要人为指定覆盖结构(计算机不会分析),不方便。
交换
交换就是把暂时不用的程序换出,腾出空间给其他程序运行。
结合第二章,交换其实就对应着中级调度
因此换出的程序首选被挂起的程序,其次就是低优先级的,总之尽可能减小换出的副作用。
交换区要频繁读写,因此单独划出。
为了加快读写,采用连续分配的方式管理磁盘(IO更快)
储存器分配——连续分配
所谓连续分配,就是程序要放就是一整段全放进去,不可以拆开。
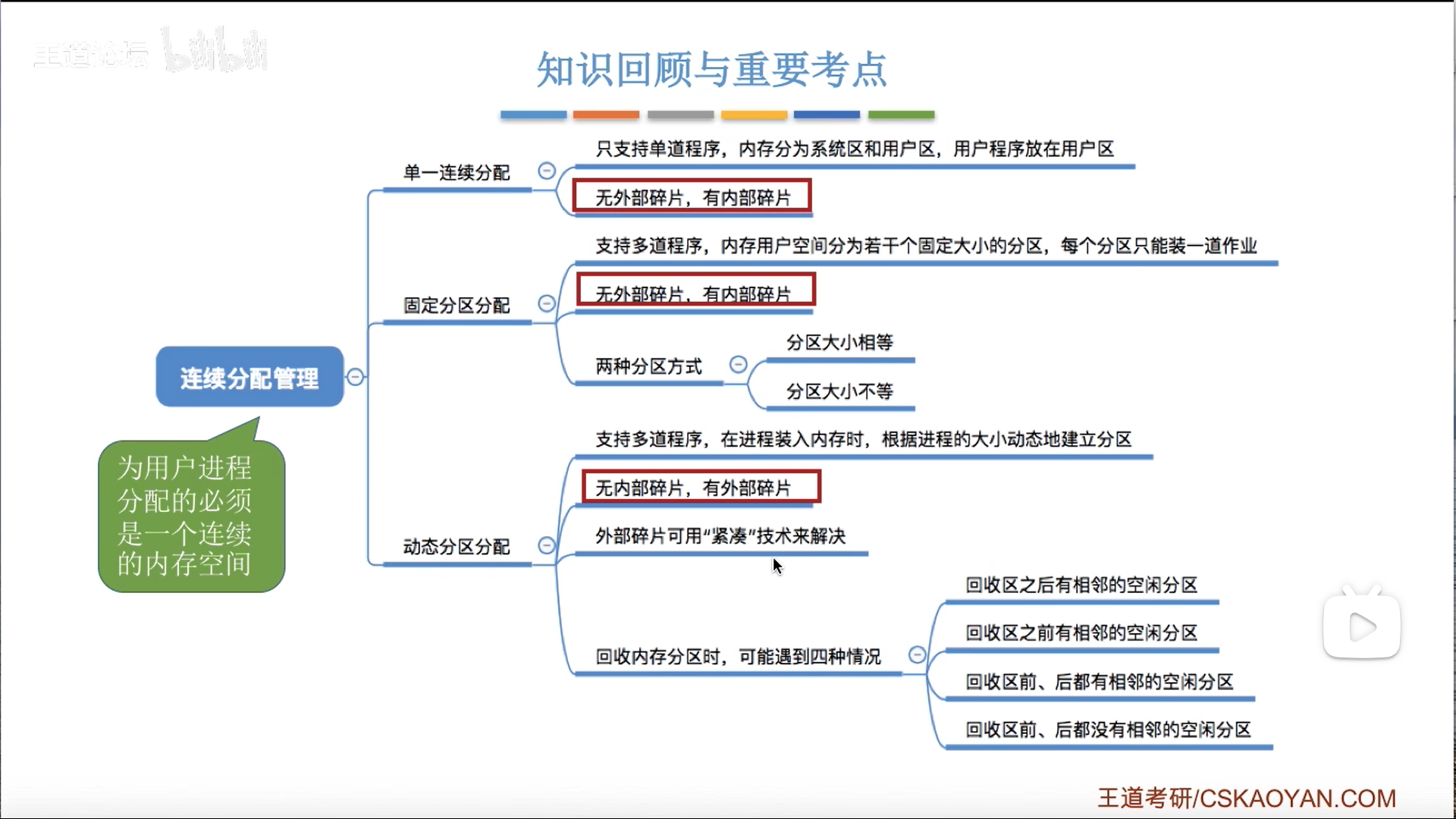
固定大小分区
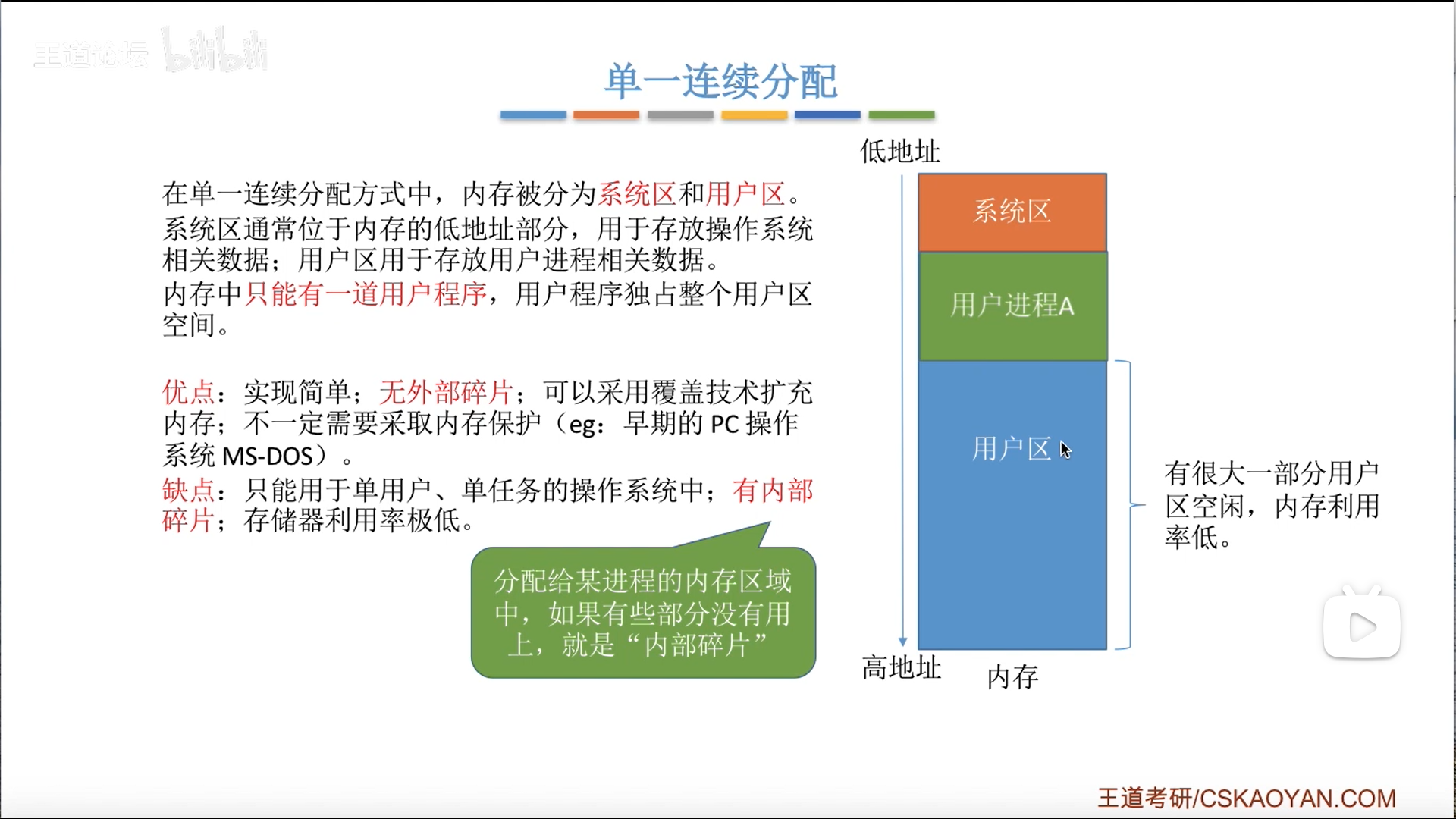
说白了,单一连续分配就是只有一个应用分区
因此没有外部碎片,只有内部碎片
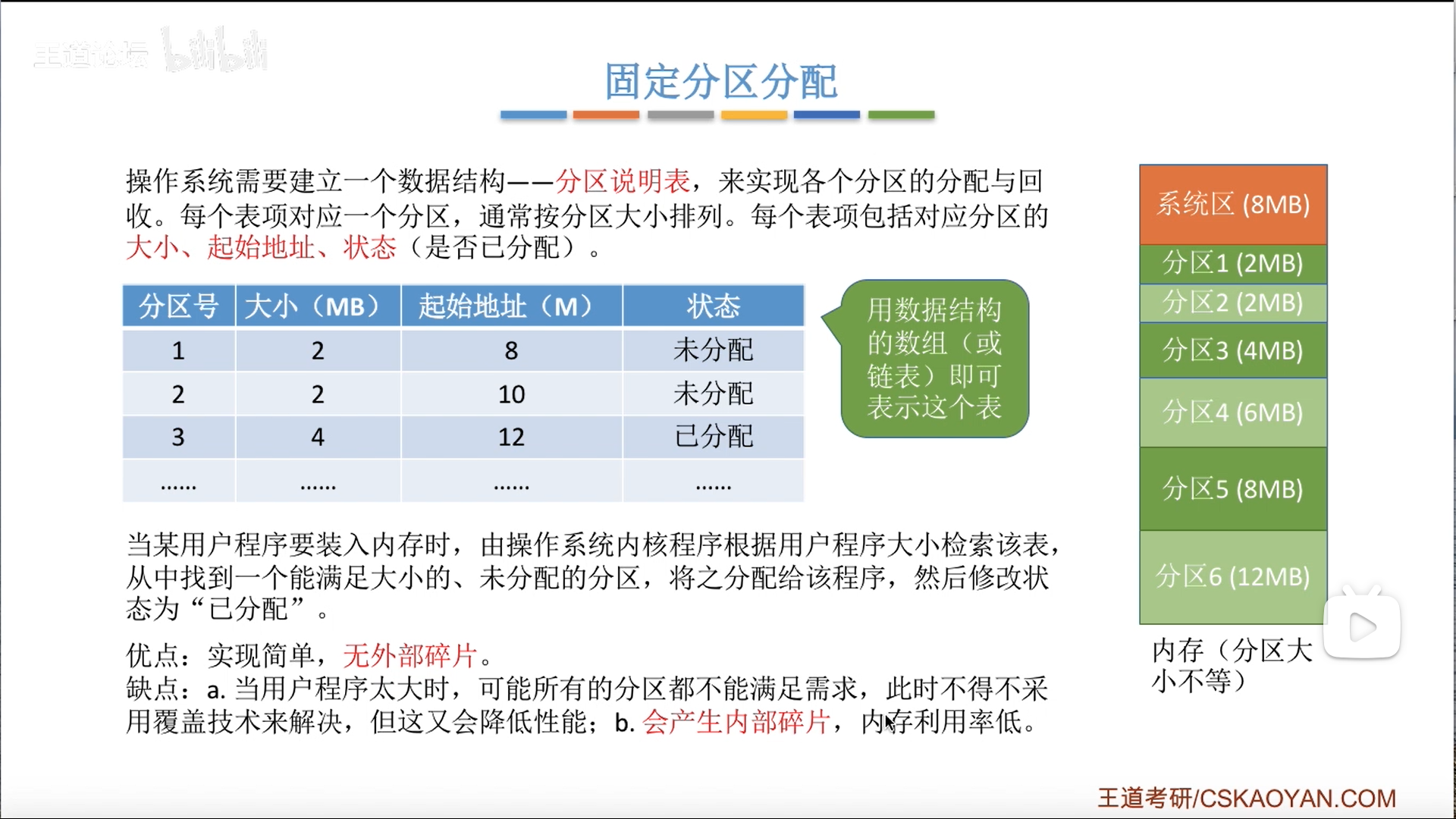
下面的固定分区分配,其实就是把这一个区,拆分成多个固定的区,只分配,不改变大小。
既然思想一致,只是分区数量的差异,那么碎片的逻辑也就一样了。
多个分区还要进行管理,需要一个固定分区表,这个表能修改的只有分配标记
如果最大的那个分区都满足不了当前程序,就上覆盖技术。
动态分区分配
动态分区就是固定分区加强版,除了可以修改标记以外,还可以修改区域的大小。
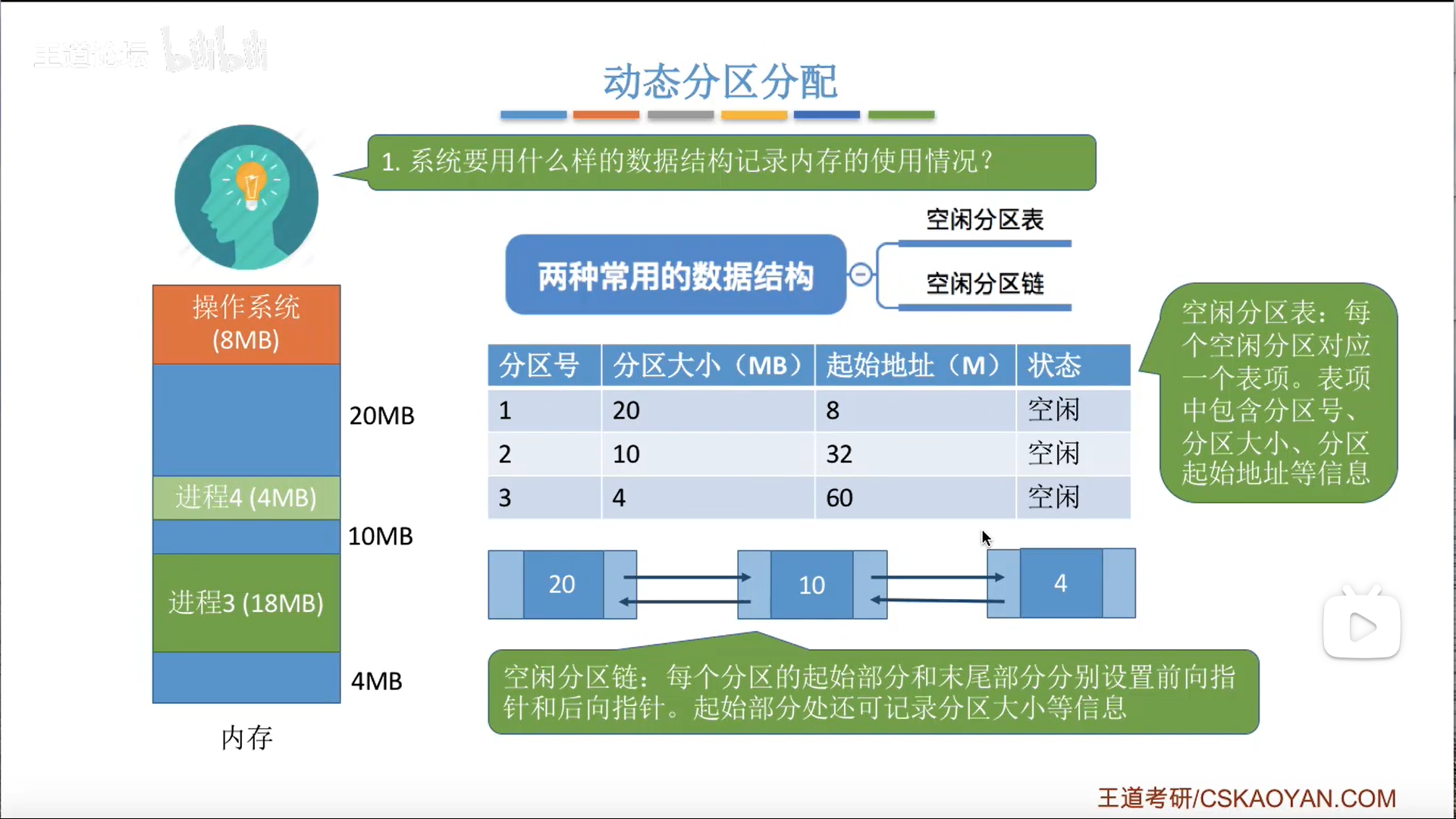
数据结构有两种:
- 分区表
- 沿用固定分区的思路
- 空闲分区链。这里注意一下其结构
- 这是一个双向链表,有首尾两侧链域
- 中间部分,可以存放分区的描述信息
分配和回收的过程中,要涉及到分区的拆分和回收合并:
- 拆分:动态分配算法
- 回收:会涉及到表项/节点的修改或者删除,要具体讨论
动态分区的思路,可以保证新分的区是满的,所以没有内部碎片
代价就是会产生外部碎片,内存中有一些地方因为太小是怎么也用不到的
解决方法也很直接,就是把分区挪一下,挤一挤,即紧凑技术。
很明显,程序在这个过程中浮动了,因此只能搭配 动态运行时装入(动态重定位)技术使用。

动态分区分配算法
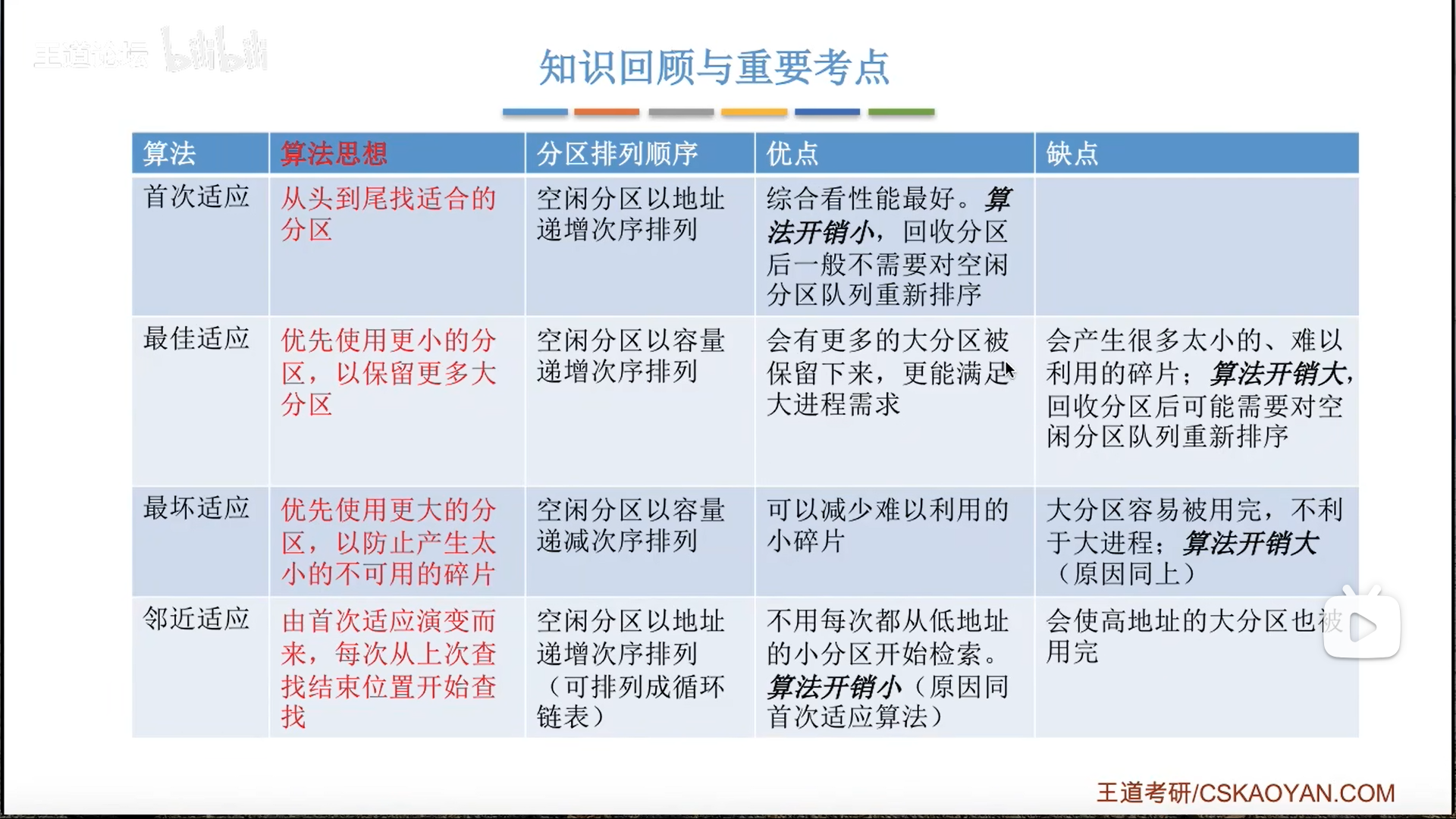
- 首次适应
- 遍历空闲分区表/链,第一个能用的就直接用,同时进行修改
- 优点:快
- 最佳适应(最小适应)
- 一种粗暴的思路是遍历全部空闲分区链
- 另一种更好一点的思路是维持空闲分区链的有序性
- 在修改后重新排序,因为分配只会导致减小,所以我们只需要对着前半截进行一次插入排序即可
- 优点:保证大空间
- 缺点:产生小碎片,慢
- 最坏适应(最大适应)
- 与2反其道而行之
- 优点:减少小碎片
- 缺点:破坏大空间,慢
- 邻近适应
- 对1的修改
- 从上一次停下的位置开始查找,这样可以跳过前面因为分配而产生的小空间,快速用到后面的大空间
- 缺点是破坏大空间
- 优点是比首次适应还快
储存器分配——非连续分配
页式管理
基本思想
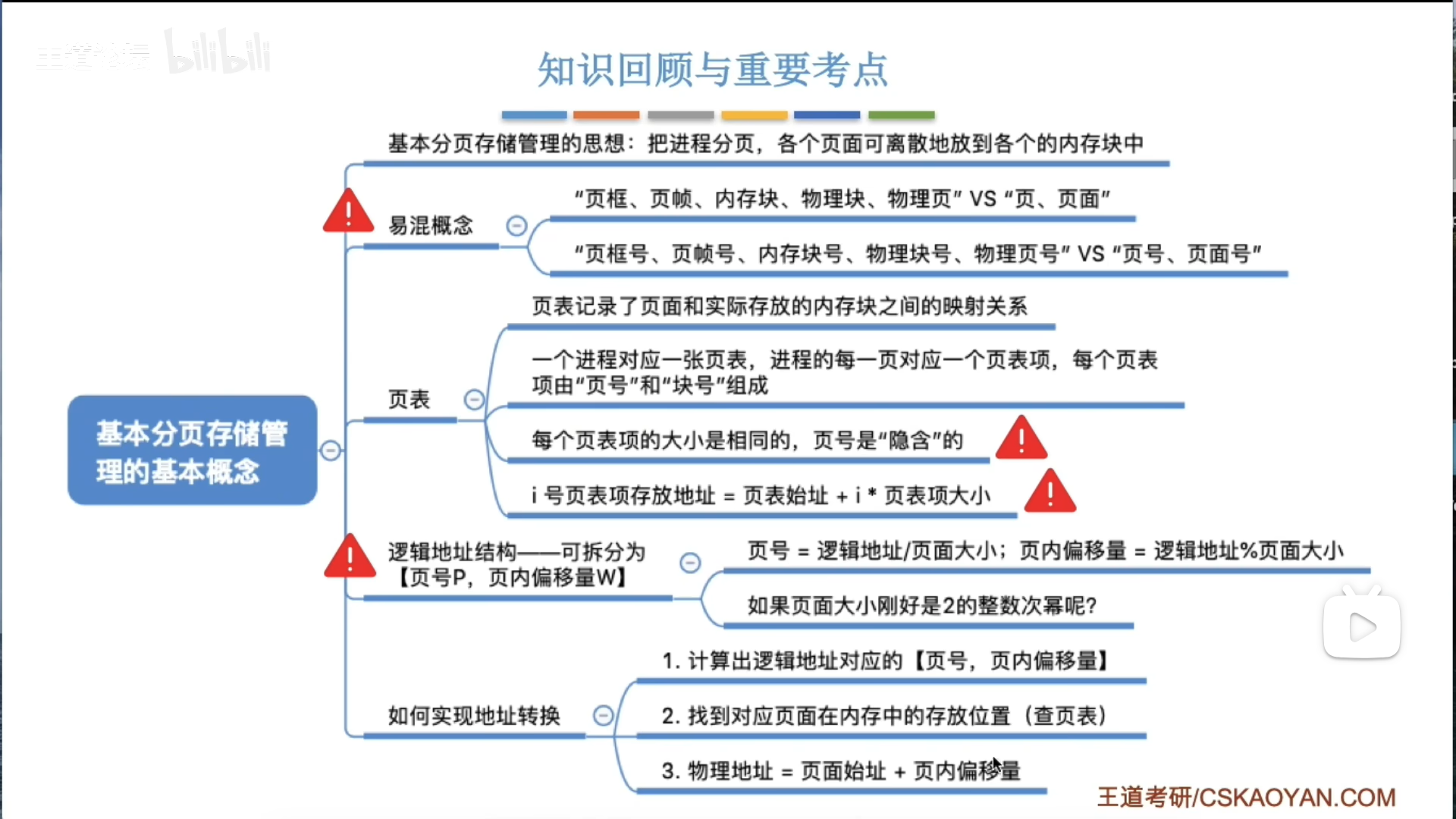
页式管理其实是分区的进化版,将分区粒度变得非常细,同时用页表建立索引,因此可以分散储存,大大提高空间利用率。
页表负责索引功能,将逻辑页号转为物理页号,这里区分一下名词:
- 逻辑页:对应程序,叫页,页面
- 物理页:对应内存,叫页框,页帧,物理块,物理页面,内存块
因为逻辑页是连续递增的,因此直接隐含在偏移地址里了,不在页表项里,而页表项的长度一定是要对齐的(k字节)
如何转换呢?
- 逻辑到物理:
- 说白了就是用索引表的页号查找对应页框号,然后拼接就可以
- 注意,页框号要
乘系数才是页起始地址
- 物理到逻辑:
- 1的逆过程,在二进制下其实很简单,直接截取地址,后半段就是页内偏移,前半段就是页框号
- 本质在于,页框大小固定,因此两部分都是定长
地址变换硬件
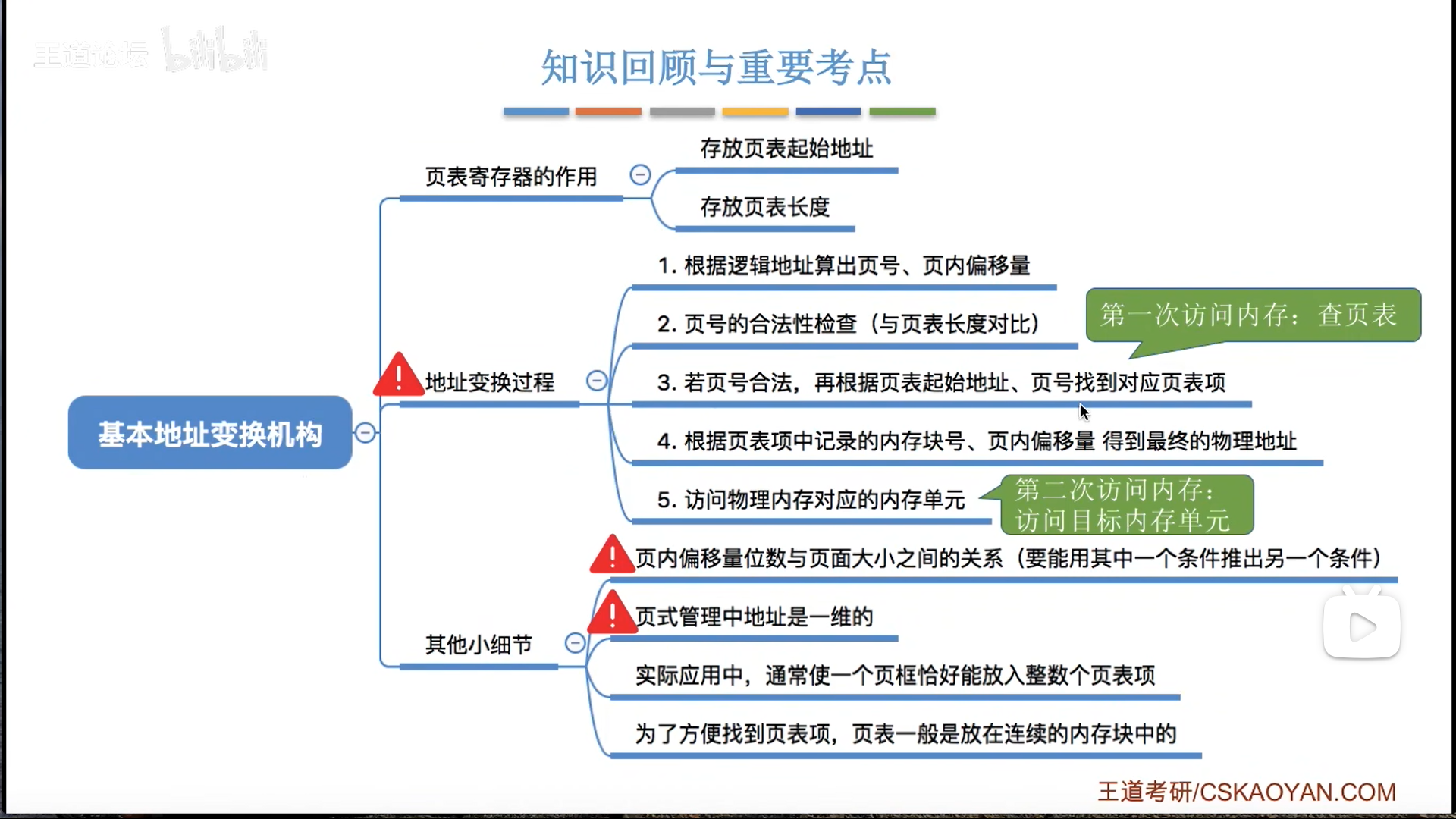
学过汇编的话,这个过程非常熟悉。

因为页表位置可以浮动,我们干脆就用一个页表寄存器储存地址(PTR)
考虑到安全性检验,还要再存页表长度,这两个是分成两节存在一个寄存器里的
需要注意,既然是寄存器,那其实也是程序上下文,所以随着进程切换,肯定也会有装入和保存的过程
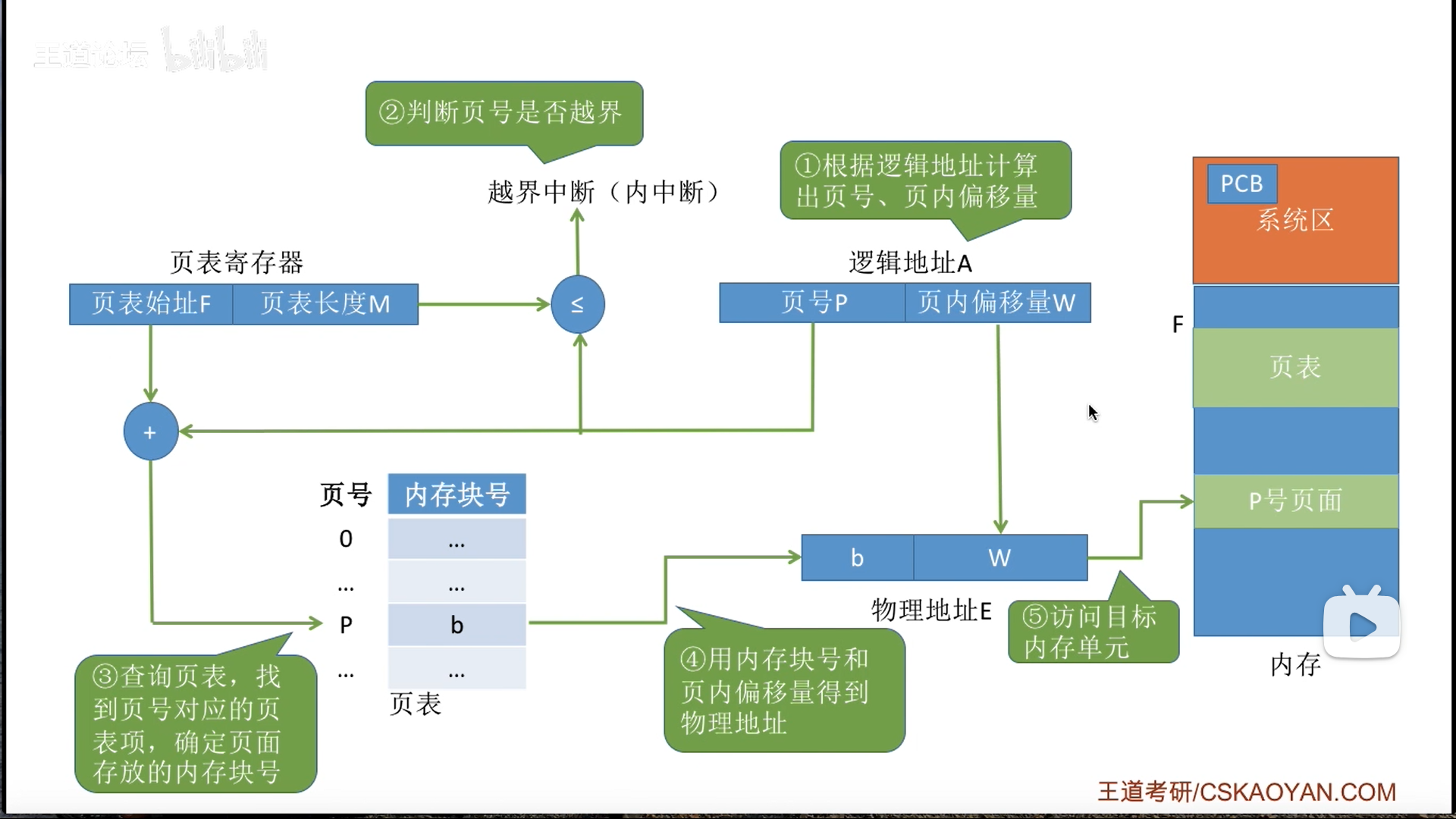
这个转换流程,用字母描述:
- P页号
- W页内偏移
- 需要注意的是越界验证,因为PTR存的是
页表长度,所以是虚高1位的,因此只要P等于M,就算越界 - 我们都是手算,实际上计算机直接拼接就行

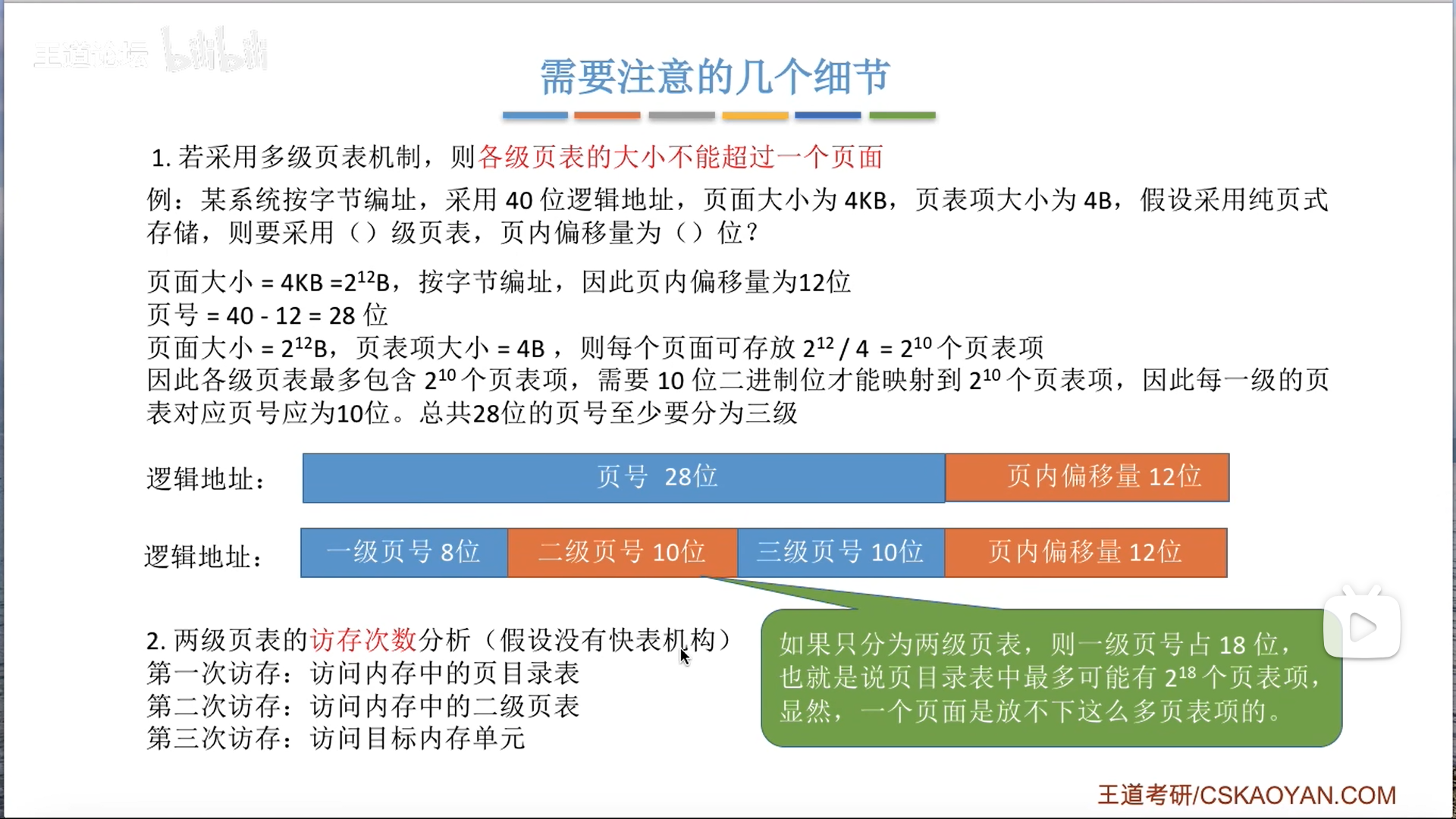
前面说到页表项大小要对齐到k字节,实际上不仅仅如此。
3B情况下,会产生页框内碎片,那么我如果要访问这个碎片地址上的页表项呢?那只能+1偏移,这样做很麻烦,而且容易出bug
所以干脆进行二次对齐,对齐到能够被页框大小整除,所以一般是用4字节,做题的时候要考虑这两种对齐。
快表(TLB)

参考cache原理,TLB其实就是页表的cache,材料也都是SRAM,只不过TLB的等级还要在cache之上,是最紧贴CPU的
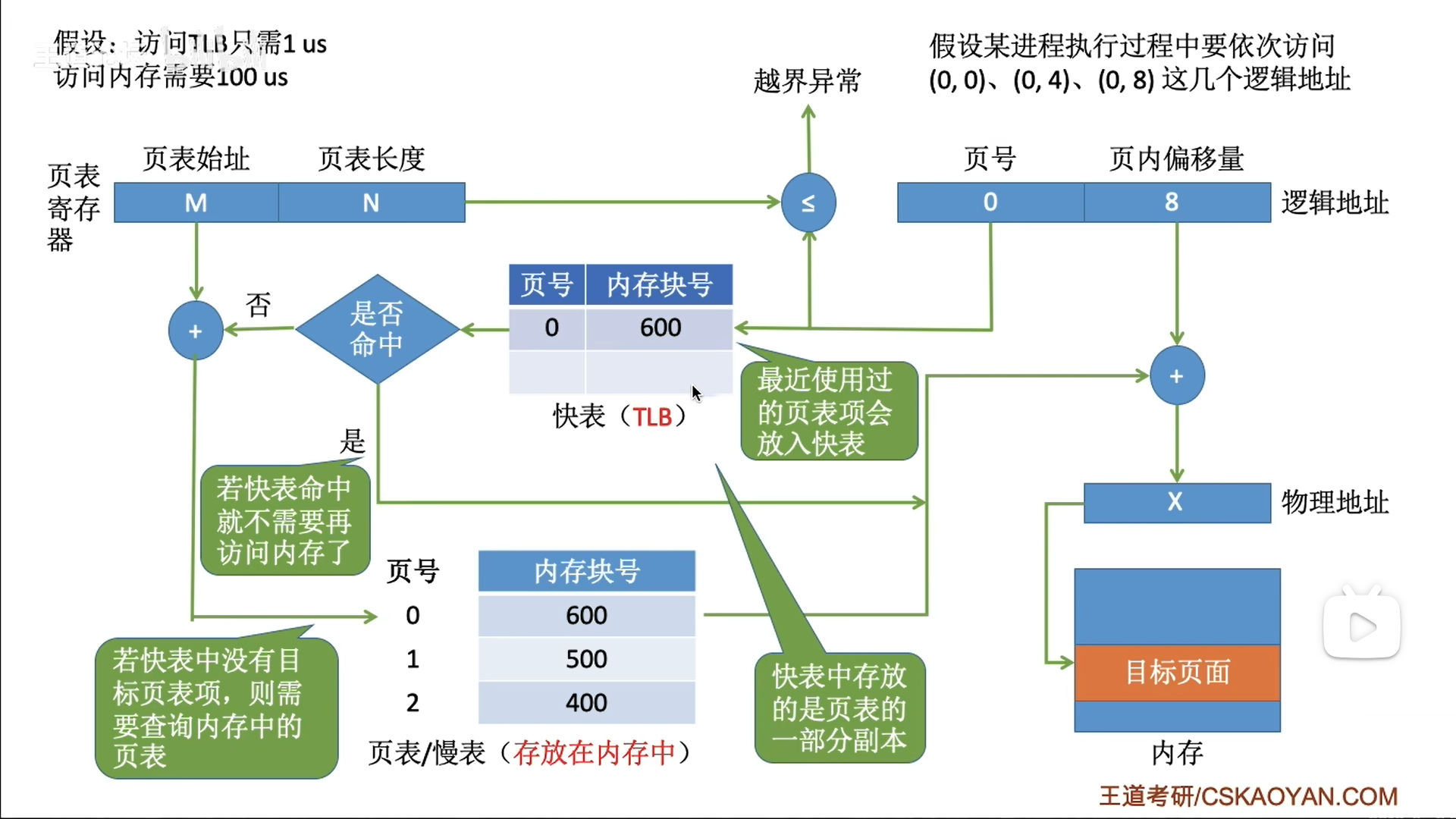
TLB是一种cache,更具体的说,应该是全相联方式储存的模式。
因此快表不能像页表那样,把页号隐藏在地址里,而是多加一个字段,且每次要遍历快表。
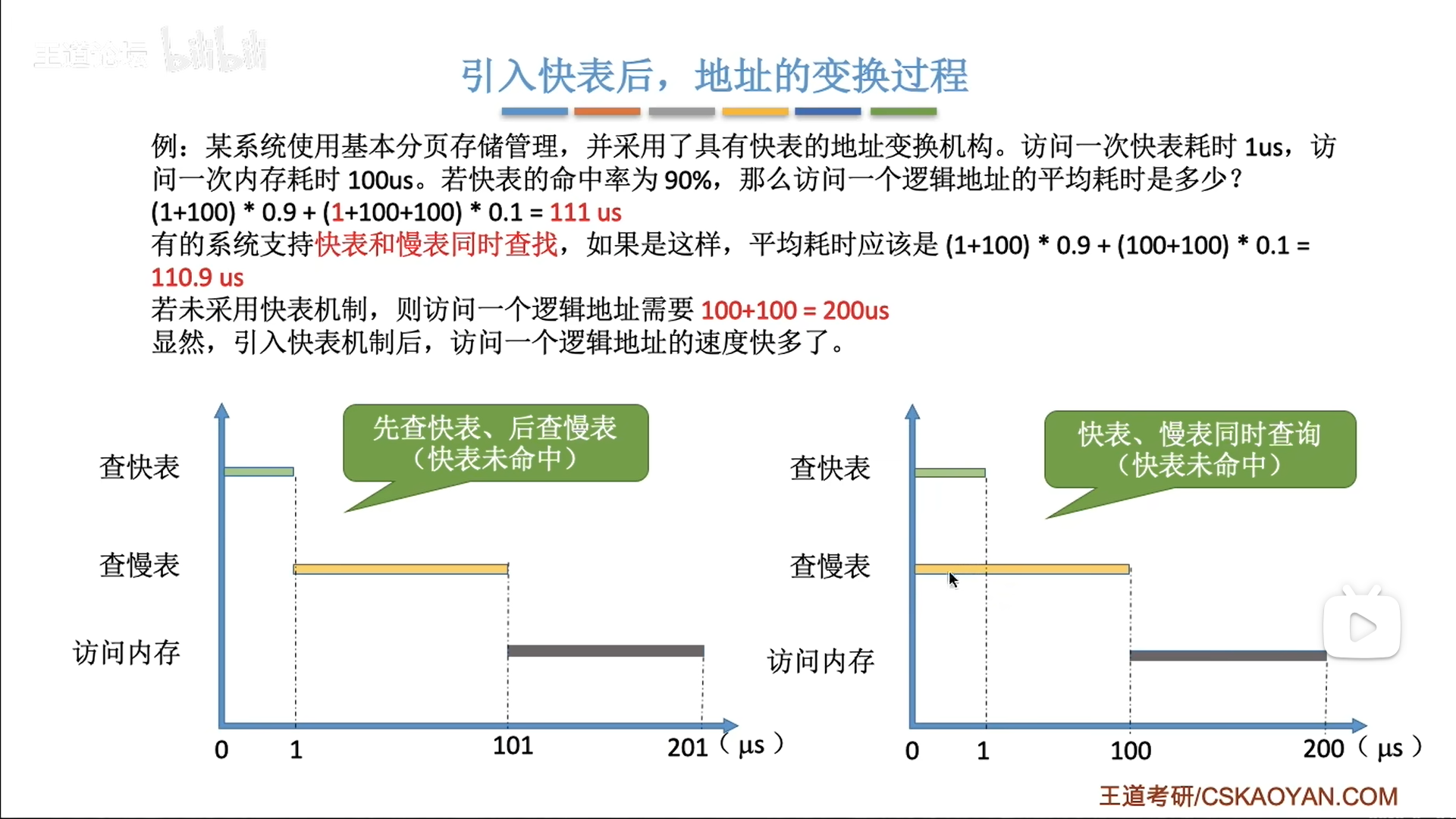
查找过程有两种:
- 先查TLB,再查页表
- 同时查询
进而衍生出不同耗时·的计算结果
TLB和cache的区别:
- cache会缓存一整个内存块
- TLB只cache页表项
- 从这个角度来看,其实TLB就是比cache更细,TLB是内存块的cache,而cache是整个内存的cache
多级页表
当一个页表存不下页表项,就需要用二级。
一般来说,只有二级页表,实际上可以多层
区分一下名称:
- 二级页表
- 外层页表,或顶层页表,页目录表
- 每一行:页目录项,页表描述符
- 一级页表
- 每一行:页表项,页描述符
转换过程无非就是前N次确定最终页号,最后1次进行访存,即N+1次

页表具体分几级,要根据地址长度来定,先抛去页内偏移,之后看看能拆几节页号地址。
段式管理

首先要明确,段式管理和页式管理是并列的,都是非连续的分配。
段式管理很像动态分区,但领域不一样:
- 动态分区是给内存进行分区,分区表是针对内存的,每个分区对应一个进程
- 段式管理是给进程空间进行分区,段表是针对一个进程的,每个分区对应程序的一个内存段
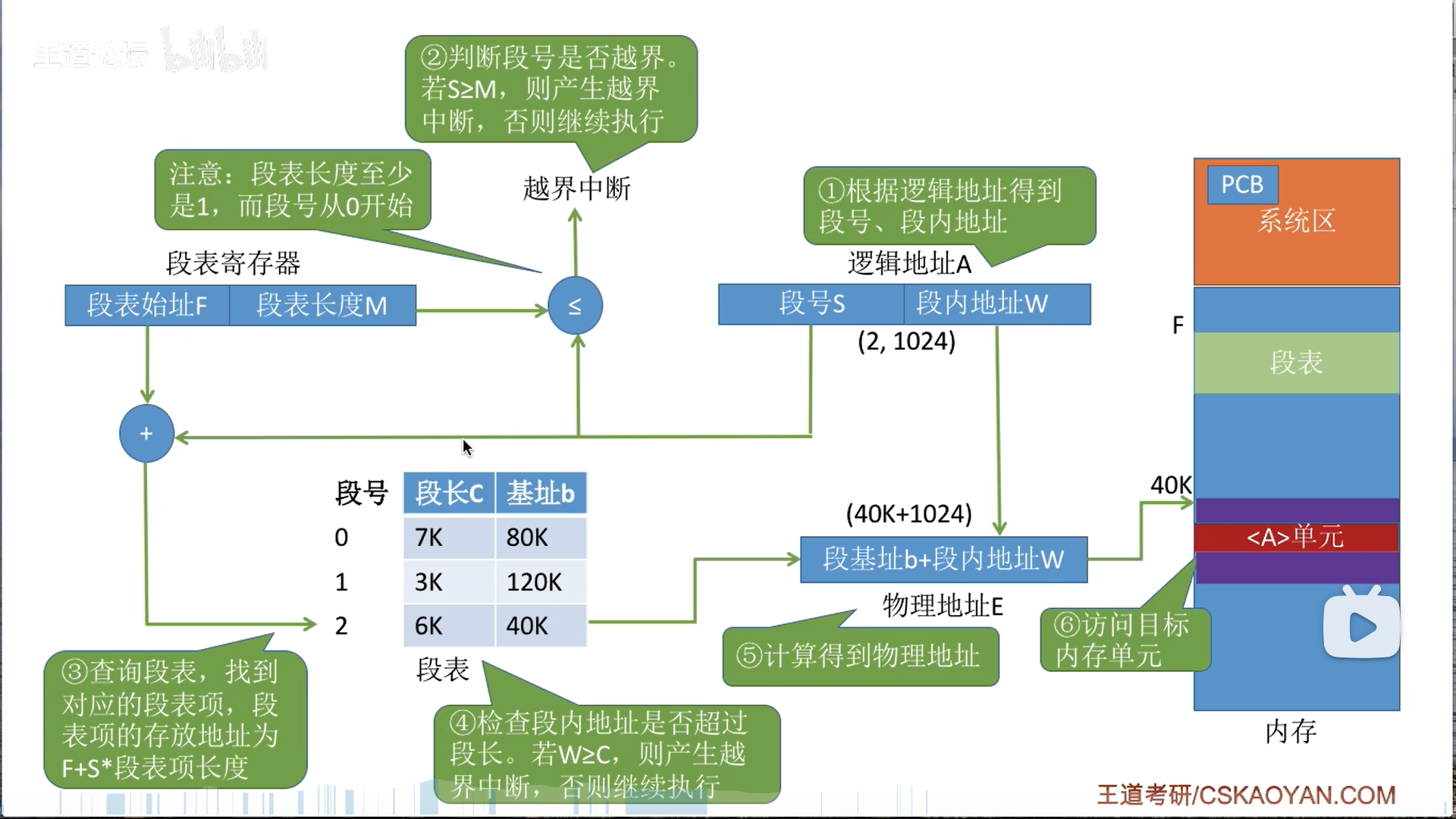
段表和页式管理类似,每个段表项都是等长的,段号都是隐含的(但是段不等长)
寻址过程也很类似,都是两次+越界检测
越界也是同理,这个段长是具体长度,虚高,所以只要满足W=C就代表越界了

从设计理念上来说,段页还是不同的,如下:
- 页式管理完全是为了系统服务的
- 是物理性的,纯粹按照地址切分的
- 用户不可见
- 段式管理更多的是为了用户服务
- 是逻辑性的,分模块的
- 用户可见
由设计理念来引申,共享与保护:
- 因为段是逻辑的,我们共享的时候也是按照模块共享的,逻辑上非常直观
- 比如我可以专门为可重入代码,或者共享数据建立一个段,这个段直接整体共享即可(不可重入代码不可共享)
- 而页并不具备这种逻辑的整体性,一页里面可能啥都有
- 同理,段也更有利于保护,整个模块一起保护很方便
- 页的内容很复杂错乱,所以共享管理很麻烦
定不定长也是一个区分点:
- 页式管理定长,因此给定一个逻辑地址,就可以直接通过除法运算锁定页号
- 页式管理一维,给地址直接上线性地址
- 段式管理不定长,给一个逻辑地址,只能截取段号,而不是除法运算
- 因此段式管理是二维的,给地址的时候要给两部分,段命(对应段号)和段内地址
段页式管理
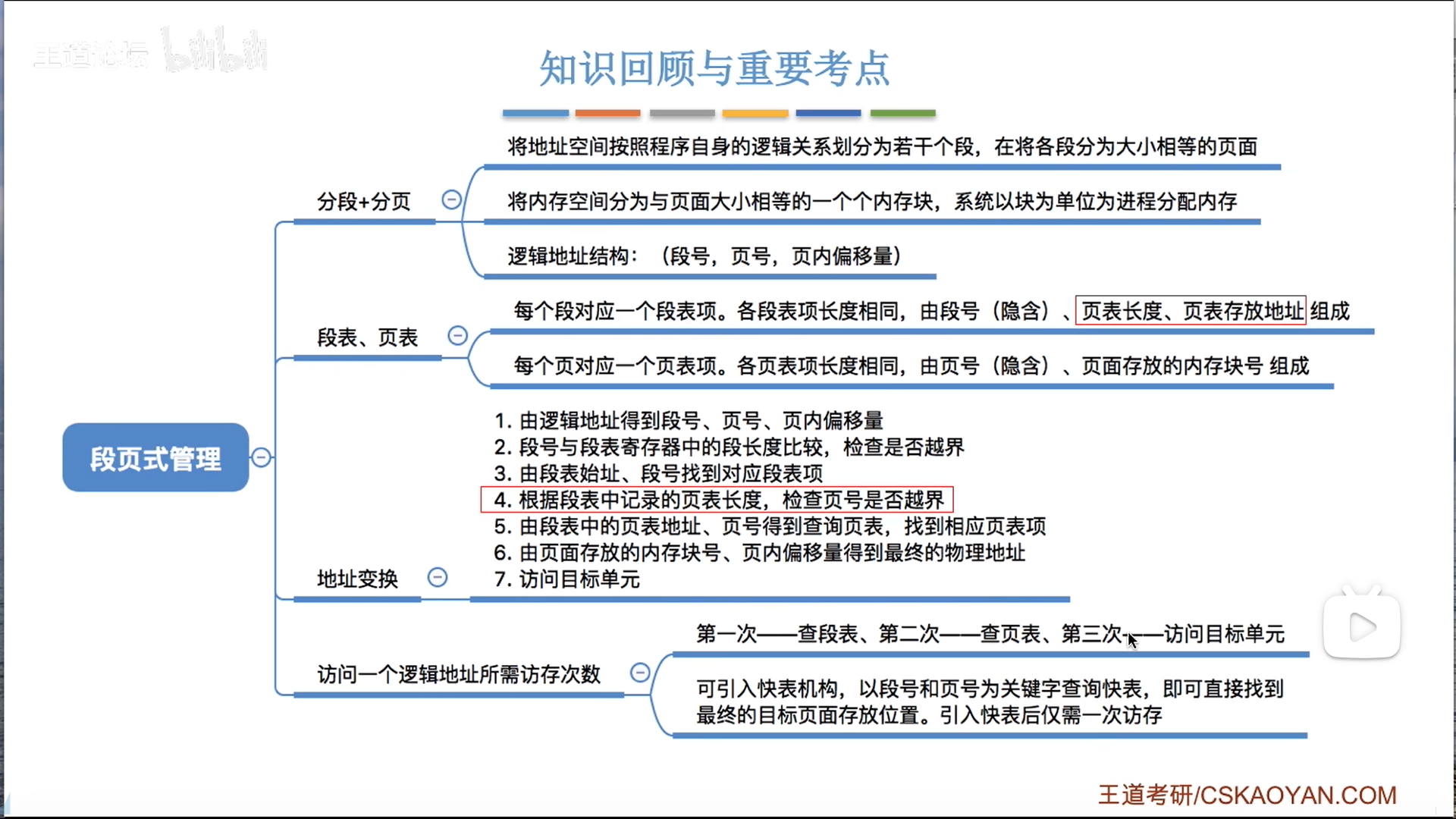
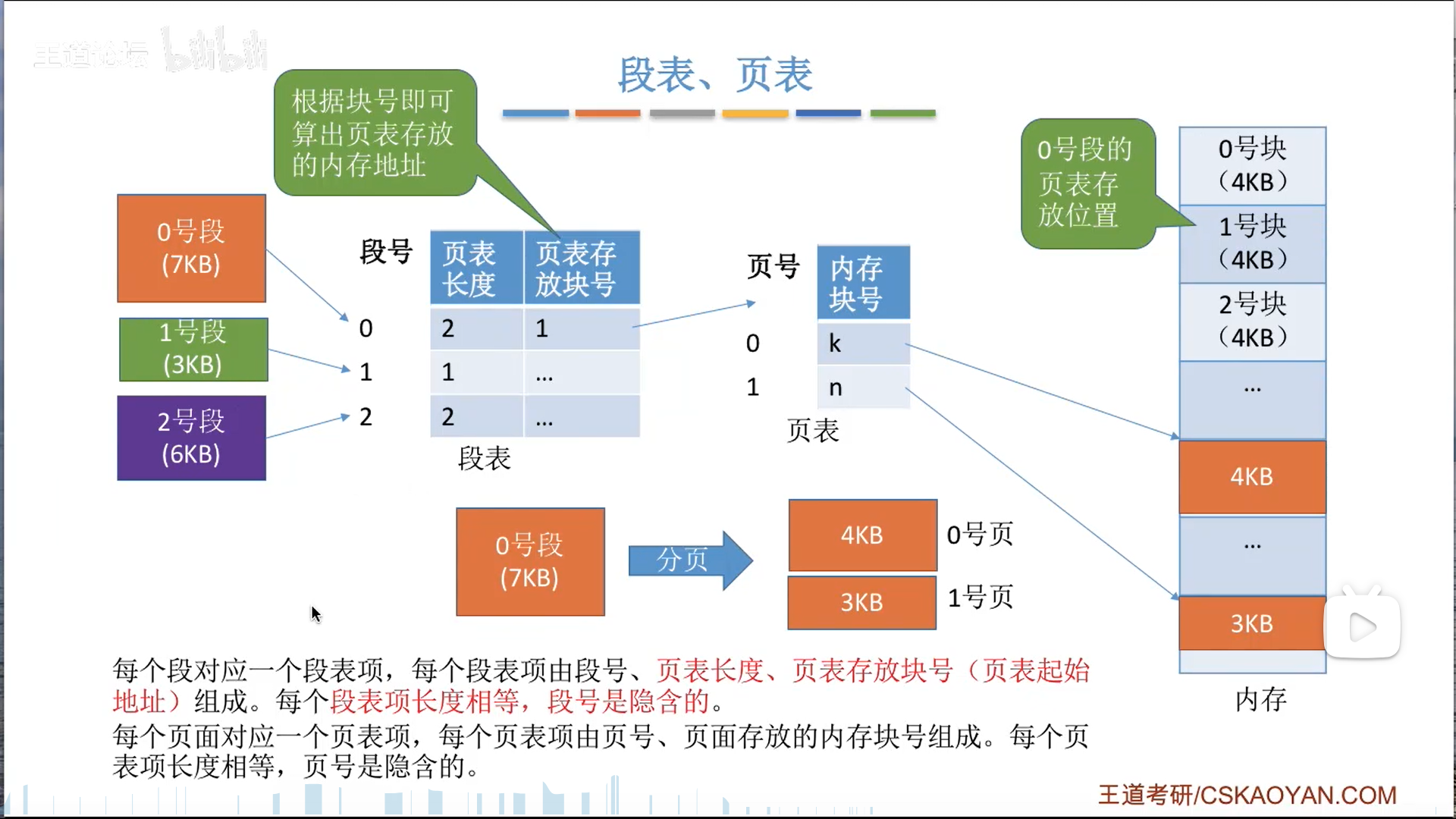
终于到了段页式管理了,这才是版本真神。
段页式管理是页+段的综合,底层用页,高层用段。
另一种理解就是把二级页表爆改成段表了

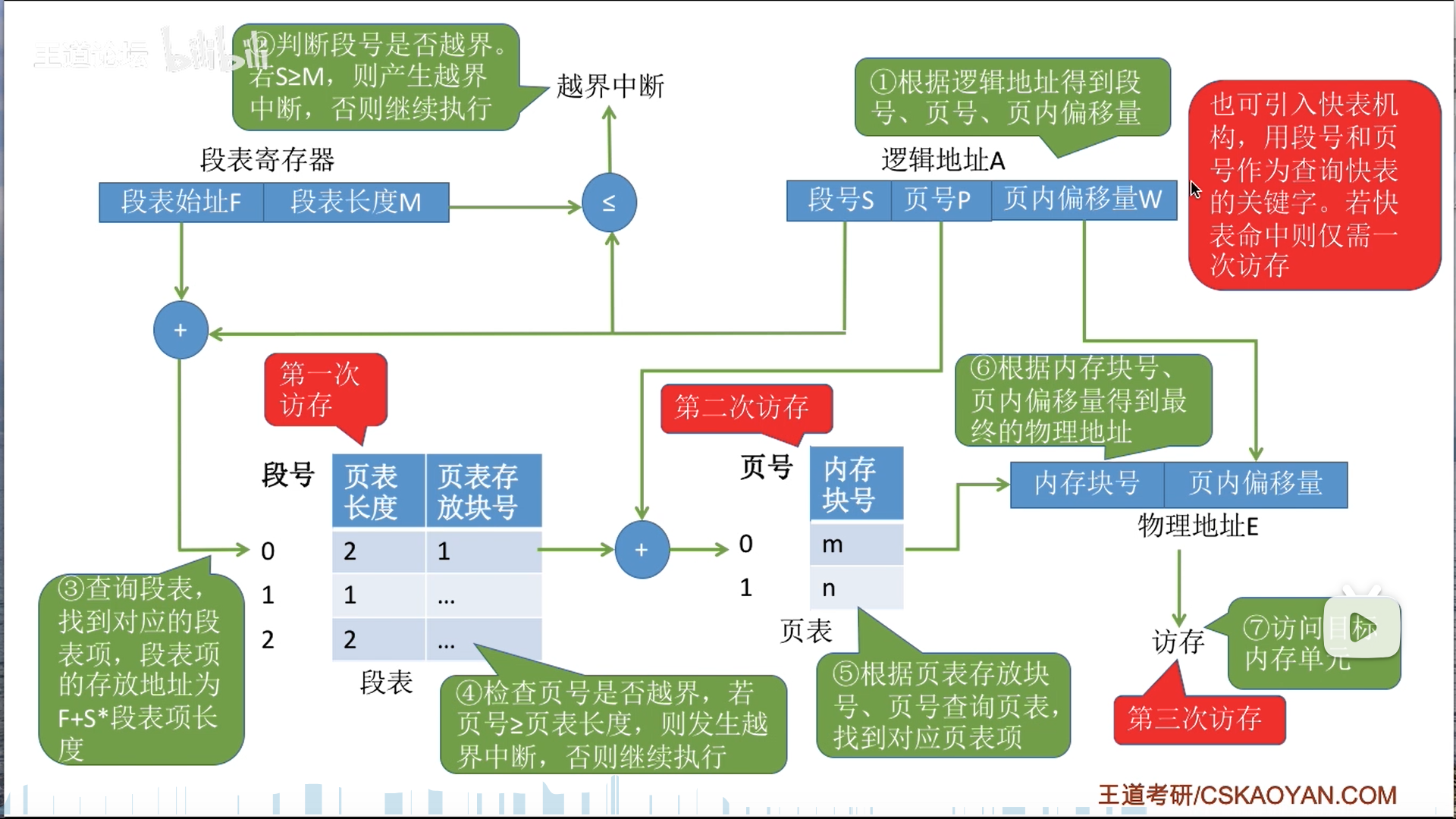
段页式是两级的,所以访存次数是2+1=3
要进行两次越界判断,由此可得,其实二级页表也得进行两次越界判断。
注意,这个TLB是把段号和页号一起作为一个tag的,而不是弄两个TLB
虚拟储存器——基于交换的内存扩充技术
基本概念
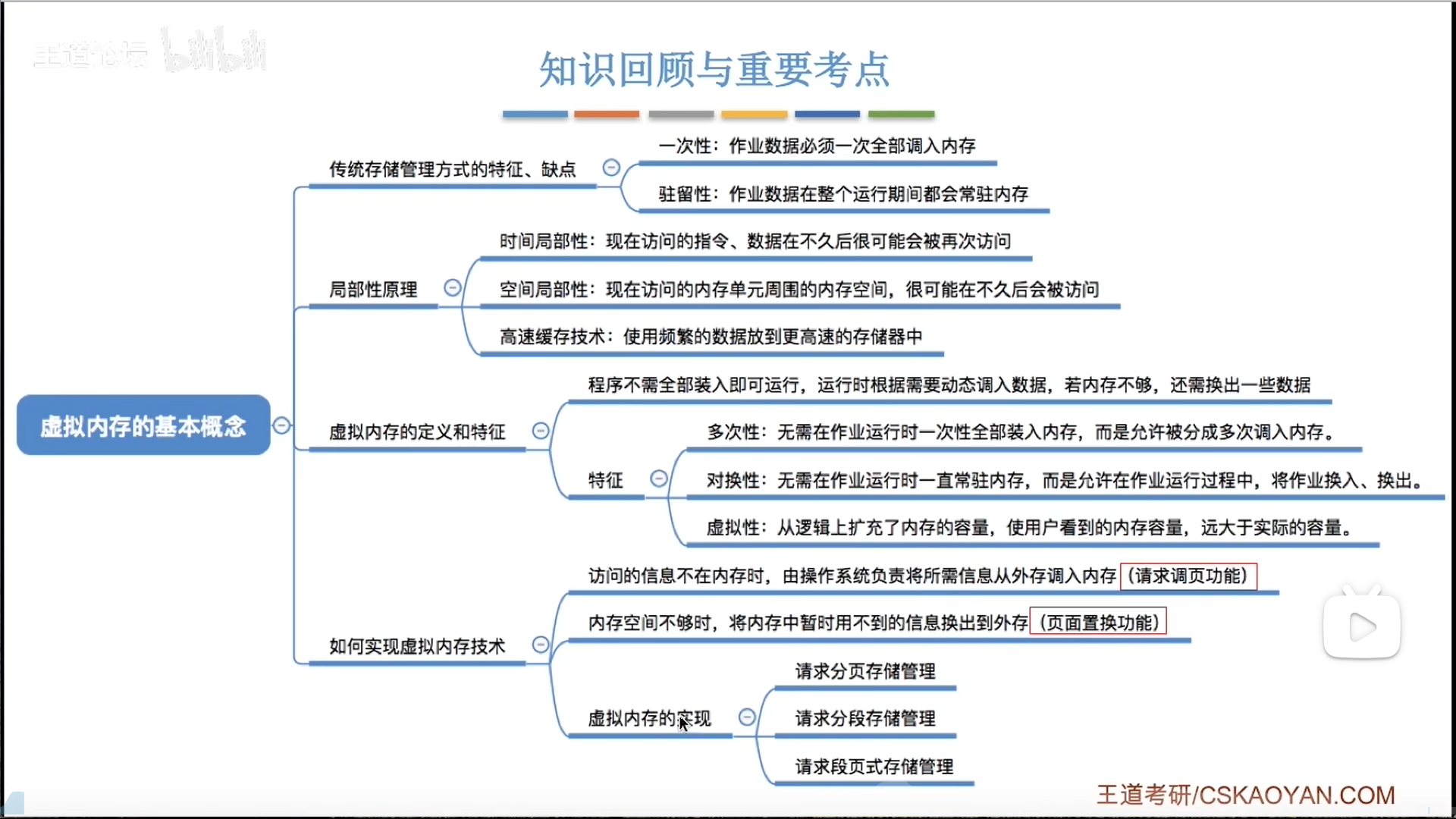
虚拟内存的特征:
- 多次性:针对装入过程来说
- 对换性:内外交换
- 虚拟性:针对空间视图来说,看到的很大,但是是虚拟的
因为虚拟内存是把进程的内存空间拆分了,所以必须使用非连续性内存分配技术。
在此基础上,增添两个功能:
- 请求调入
- 置换
后面以页举例,更复杂的也是类似逻辑。
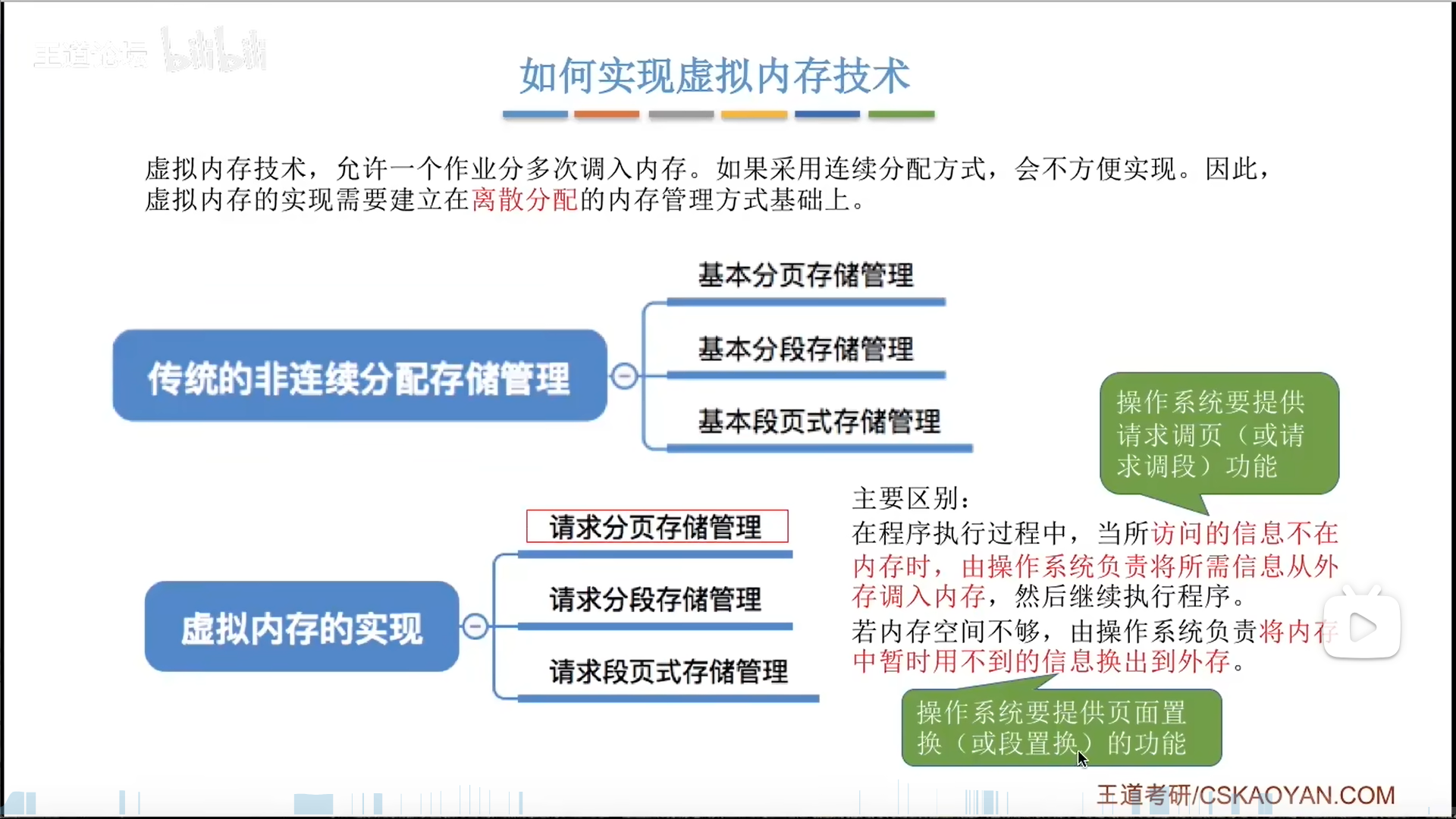
请求分页

请求分页逻辑可以参考cache来,其实是一个思想
但是具体还是不太一样:cache仅仅是缓存,管理能力很弱,而虚拟内存的管理能力很强,除了页框内容的缓存外,还专门有页表来管理页框,我们研究的其实是页表的管理。
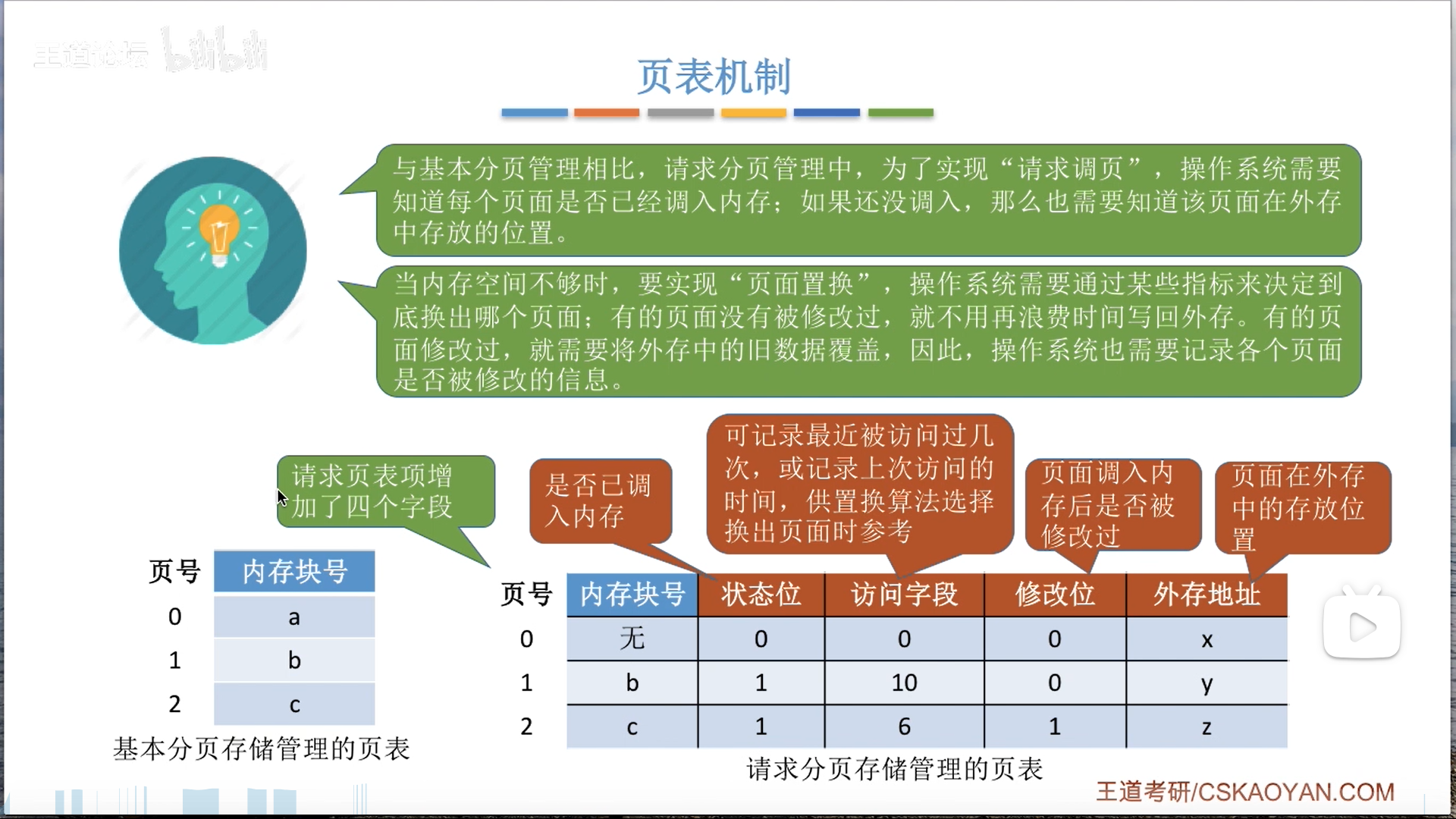
请求页表结构:
- 首先,虚拟页表的管控对象是内存+外存
- 管控对象到底在内存还是外存?因此要用状态位+内存块号+外存地址进行区分和寻址
- 其次,考虑置换过程
- 置换哪一个?因此要有访问字段,辅助置换算法
- 换出的时候是否要写回?因此有修改位,需要考虑是否被修改(类似cache脏位)
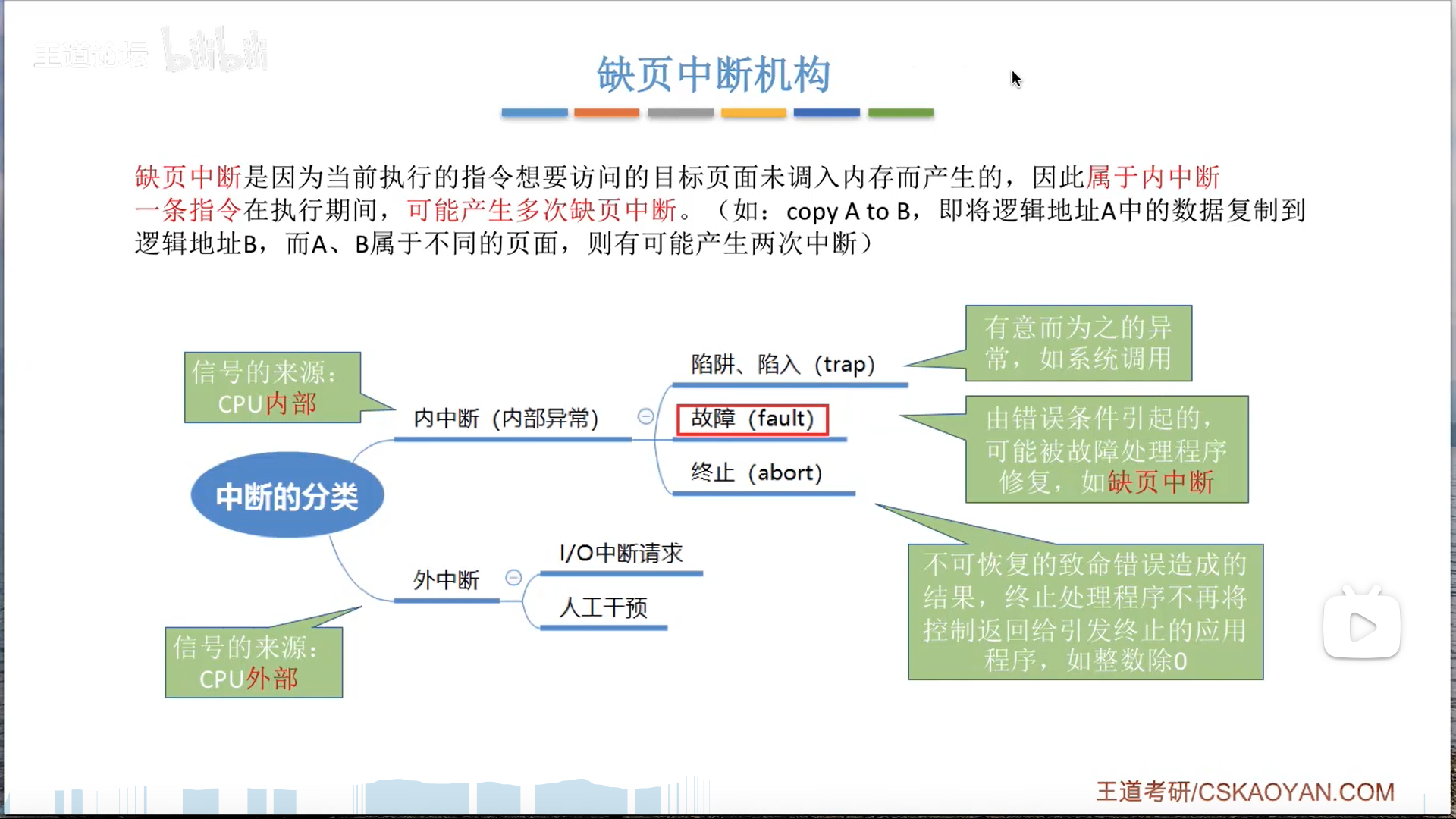
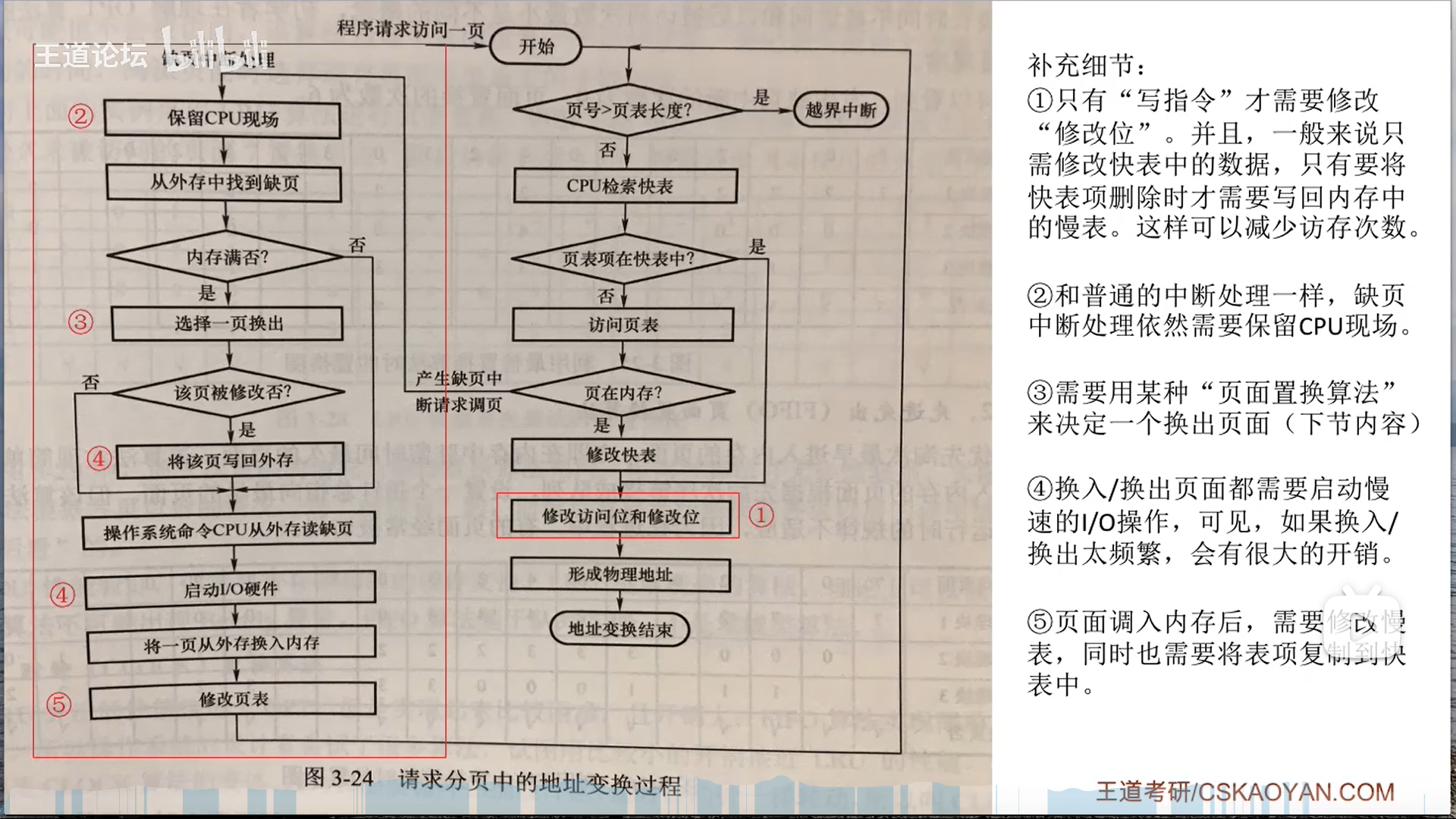
如果目标页的有效位=0,说明在外存,发生缺页中断。
注意,缺页中断并不是外中断,而是广义的中断,实际上是异常。
之后研究一下请求分页管理中的细节,其实和基本分页的区别无非就是两点:
- 额外的检查
- 状态位
- 额外的修改
- 外存:置换前是否写回外存
- 页表:置换后页表的标志位要刷新
- TLB:快表的有效位恒等于1,因此换出的时候,要TLB删除(否则出错),换入的时候也可以根据局部性原理将这个页表项复制到TLB
不过不得不说,这个过程真的挺复杂的,后面做题继续细化吧,你且知道相关联的三个部分就可以:外存,页表项(以及对应的页框),TLB
页面置换算法
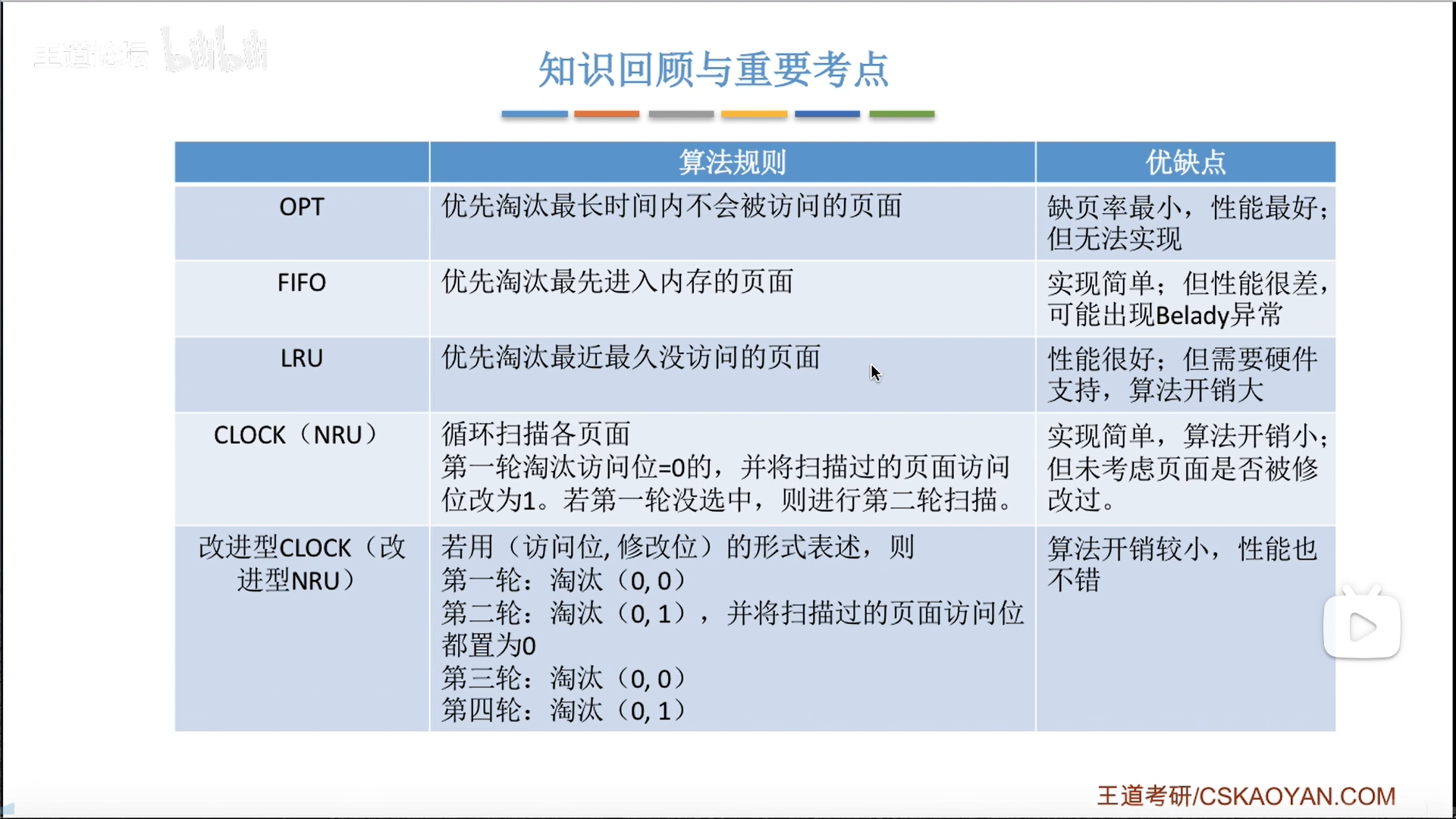
这几个方法在我另一篇笔记里已经有详细的描述了,这里进行细化。
注意,页面置换次数≠缺页次数,缺页是要更加广泛的,注意题目问的是哪个。
首先是OPT
具体做的时候,就是从发生缺页的位置开始,查看后面要调用的页,在这里面找我们当前物理块里装的页,排在最后一个的就是要置换出去的。
然后是FIFO和LRU,具体过程很简单:
- FIFO,有两种理解方式,效果相同,做题的时候自己看着办
- 新进来的页会把原来的页推下去,末位淘汰,直观
- 另一种理解方式是用一个指针指向即将要替换的位置,每次替换都让指针挪一位
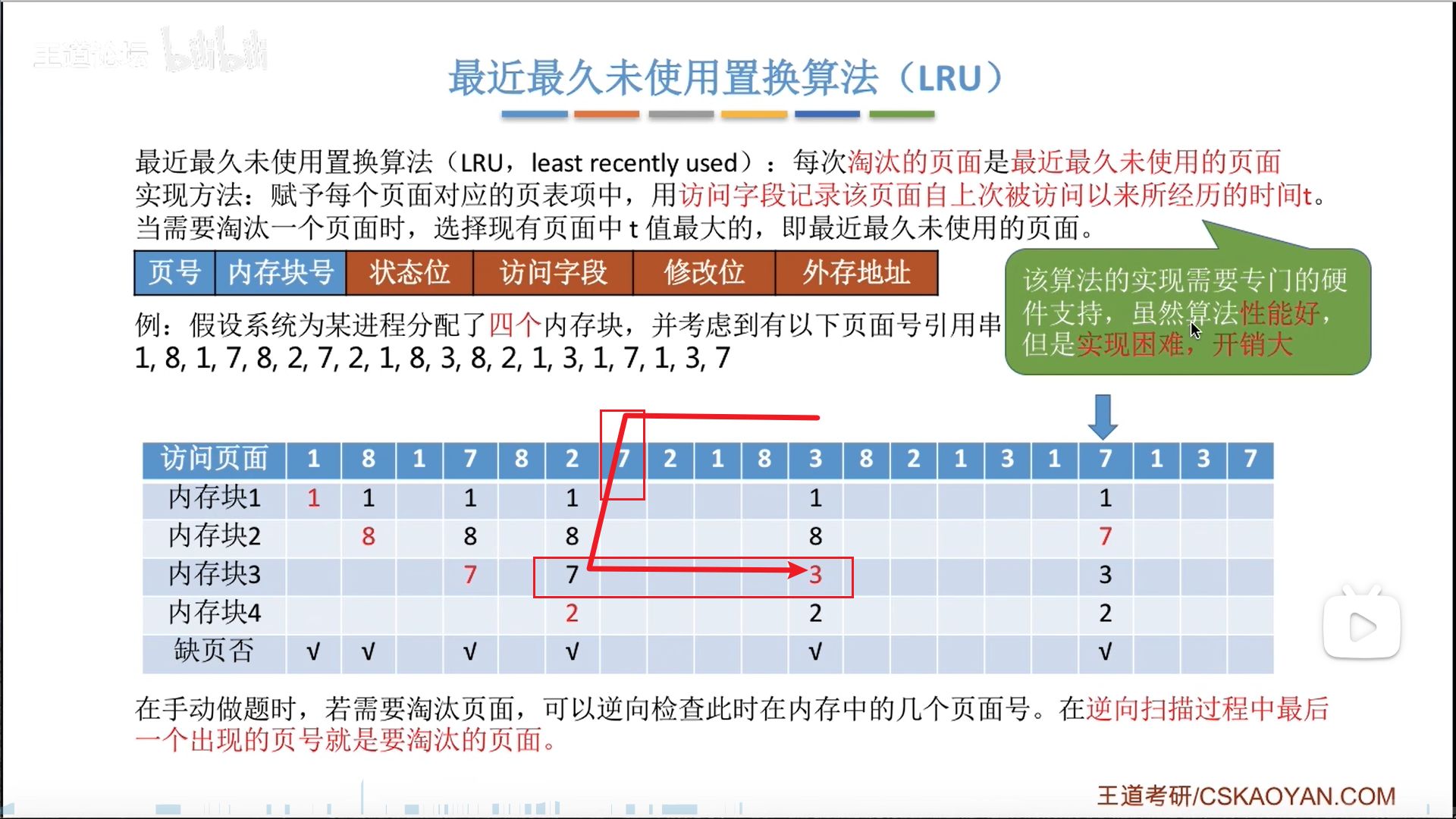
- LRU,也是两种理解方式
- 类似于FIFO的下推+末位淘汰,但是如果命中,就把这个块提到最上面(刷新存在感)
- 另一种理解方式是逆向遍历访问序列,类似于OPT,最后一个出现的就是要淘汰的(只不过方向相反)
- 效果对比
- FIFO有Belady异常,而LRU就没有
- LRU效果是最接近OPT的,但是开销太大,需要硬件计时器(参考cache替换),要求的数量还不少。
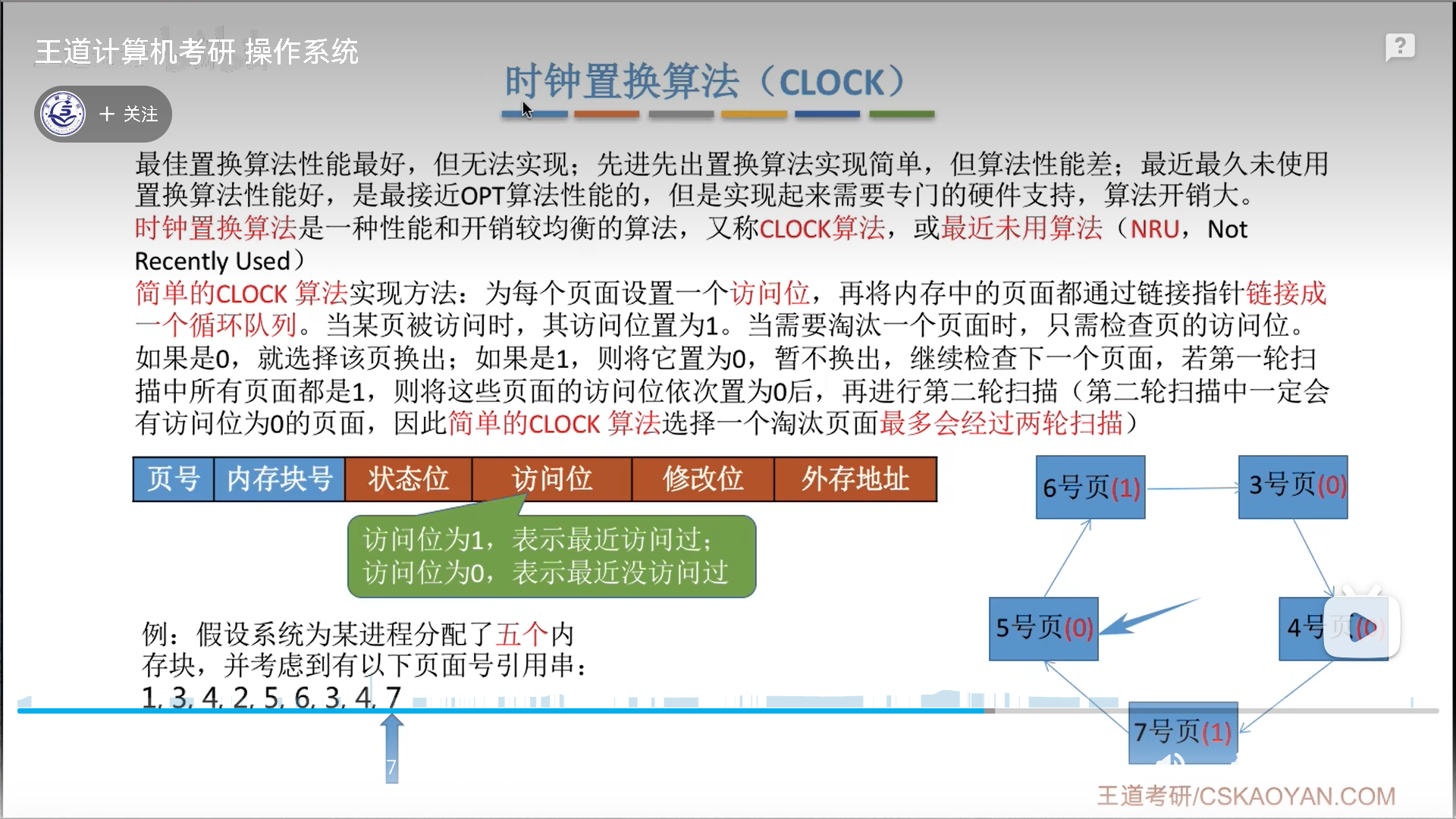
再说时钟置换算法CLOCK(NRU)
思想很简单:
- 排成循环队列
- 命中,刷新访问位=1
- 注意,命中不需要转时钟,指针不变
- 不命中,按照时钟方式扫描,进行替换
- 1置0,访问位=1,相当于免死金牌
- 0置换,访问位=0,则受斩
- 置换后要将指针后移,防止这个新的页面在下一轮扫描的一开始就掉血
极限情况是进行1轮+1次扫描,也就是两轮扫描,这个方法兼顾了效率和效果。

改进NRU还考虑到了写回的IO损耗,尽可能避免IO(替换修改位=0的页面),同时还要维持原本NRU的原则,于是根据(访问位,修改位),可以分成4个优先级:
- 0,0,既没用,又没修改过,直接换
- 0,1,没用,但是被修改过,换的成本大点,但是造成的影响不大
- 1,0,用过,不得不换,只能找个换的成本小点的
- 1,1,成本最大,不得已的办法
具体如何去扫描呢?分4轮:
- 先在没访问过的里面扫两轮
- 第一轮扫(0,0),
- 第二轮扫(0,1),同时置零访问位
- 第二轮才会像NRU一样置零访问位,因为这两轮整体并做对访问位的检查,所以只置零一次
- 之后在访问过的里面扫两轮
- 注意,这两轮本来是(1,0),(1,1)的专长,但是因为第一组操作已经把访问位置0,所以走到这里的,肯定在第一组操作之前全部都是(1,x)的情况
- 第三轮扫(0,0)
- 第四轮扫(0,1),走到这一步一定会有一个页被置换出去
- 这一组操作其实是针对修改位而来的
改进NRU非常的完美:
- 两组操作继承自NRU,对访问位的置0也和NRU完全一致
- 而在在两组操作内部,又加入了对修改位的考察
虽然改进NRU最多进行4轮考察,但是这点内存中的消耗和降低IO损耗带来的收益相比,微不足道
页面分配策略、抖动、工作集


之后介绍三种分配+置换的搭配:
- 固定分配+局部置换
- 其实就是我们前面做题的时候用的思路
- 当前进程和外存进行交换
- 可变分配+全局置换
- 只要缺页,就增加物理块
- 当前进程
不直接和外存进行交换,而是直接用空闲的,或者从其他进程抢一个(未锁定)的页框过来 - 之所以不直接,是因为抢夺其他进程页框,也会间接导致其他进程的交换,实际上还是要交换
- 这个方法反而还不如局部置换稳定
- 可变分配+局部置换
- 在1的前提下,如果系统察觉到1的缺页率比较高,就分配空闲块
- 当然,3方法也存在抢夺物理块的情况,但是频率比2低多了

- 请求调页
- 就是缺页中断,精确度很高,IO开销大
- 预调页策略
- 目标是减少IO开销
- 就是一种预测,因为其效果一般,所以只是在程序刚启动才这么干,这个时候调入不需要置换,就算翻车也无所谓。
再论从何处调页:
- 普通系统
- 对换区大,那就全在对换区操作就行,因此要先复制到对换区再调入
- 对换区小,因此要尽可能精细化,只把要修改的,可能反复IO的数据写回到对换区
- Unix系统
- 介于普通系统的两个策略之间,精细度居中
- 第一次是从文件区调入
- 之后换出的页面,不管是否被修改过,都放到对换区
内存映射文件
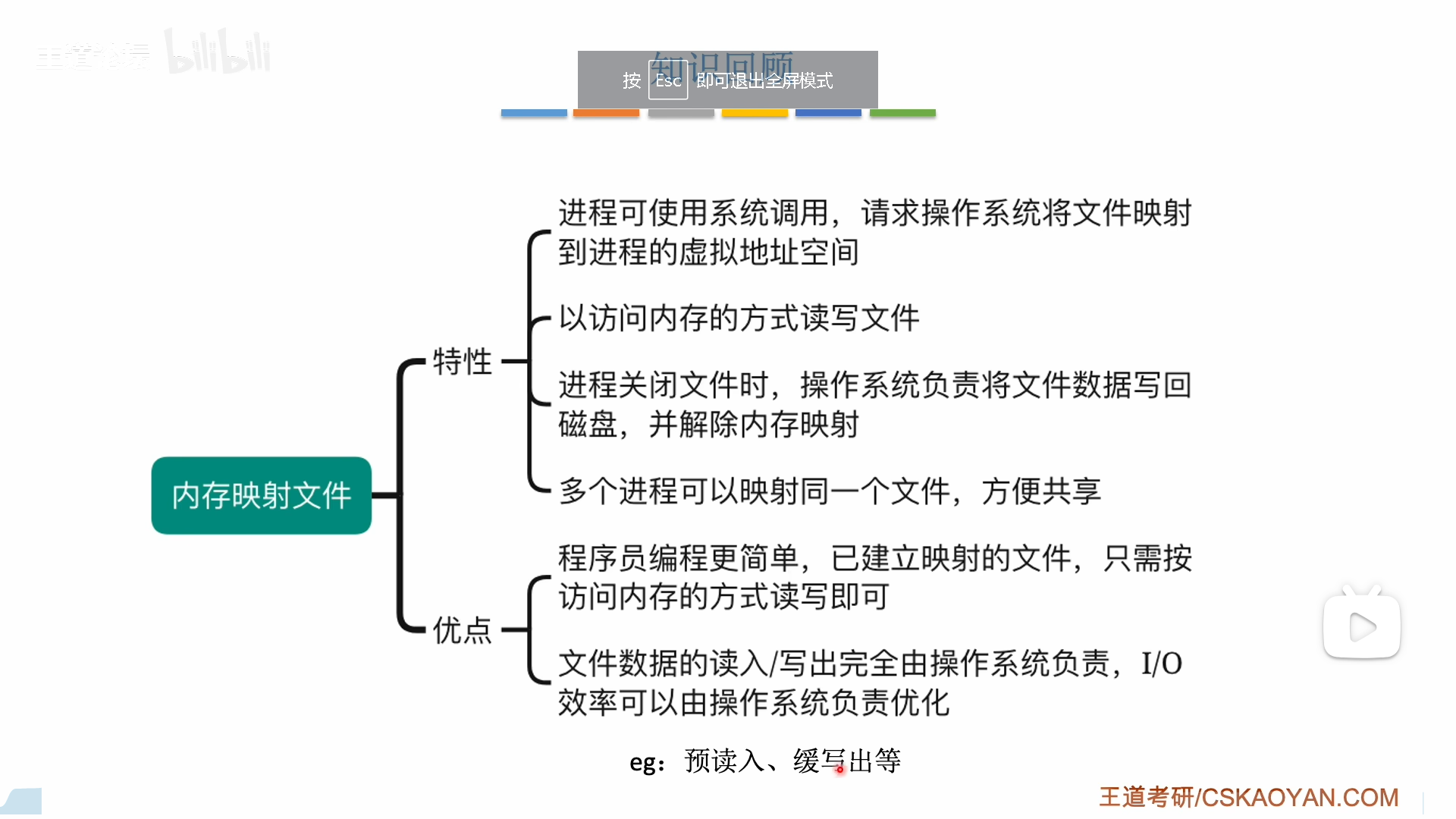
传统文件读写,要进行内存文件的多级索引,比较麻烦,如果你不是一次性读入,那么每读一个块都要多级索引一次。
内存映射文件直接把文件索引一次性读到内存里,分出一些页表项直接把文件地址记录进去
出于效率考虑,这里只是分配了页表项,并没有将文件读入,但是后续的读入已经很简单了,不需要多级索引,只需要IO就可以,效率高多了。
修改只需要在内存中,这进一步减少了IO损耗,最后进程关闭文件的时候,才将文件一次性写回,非常方便。
总之,内存映射,既可以减少索引损耗,又可以减少IO损耗

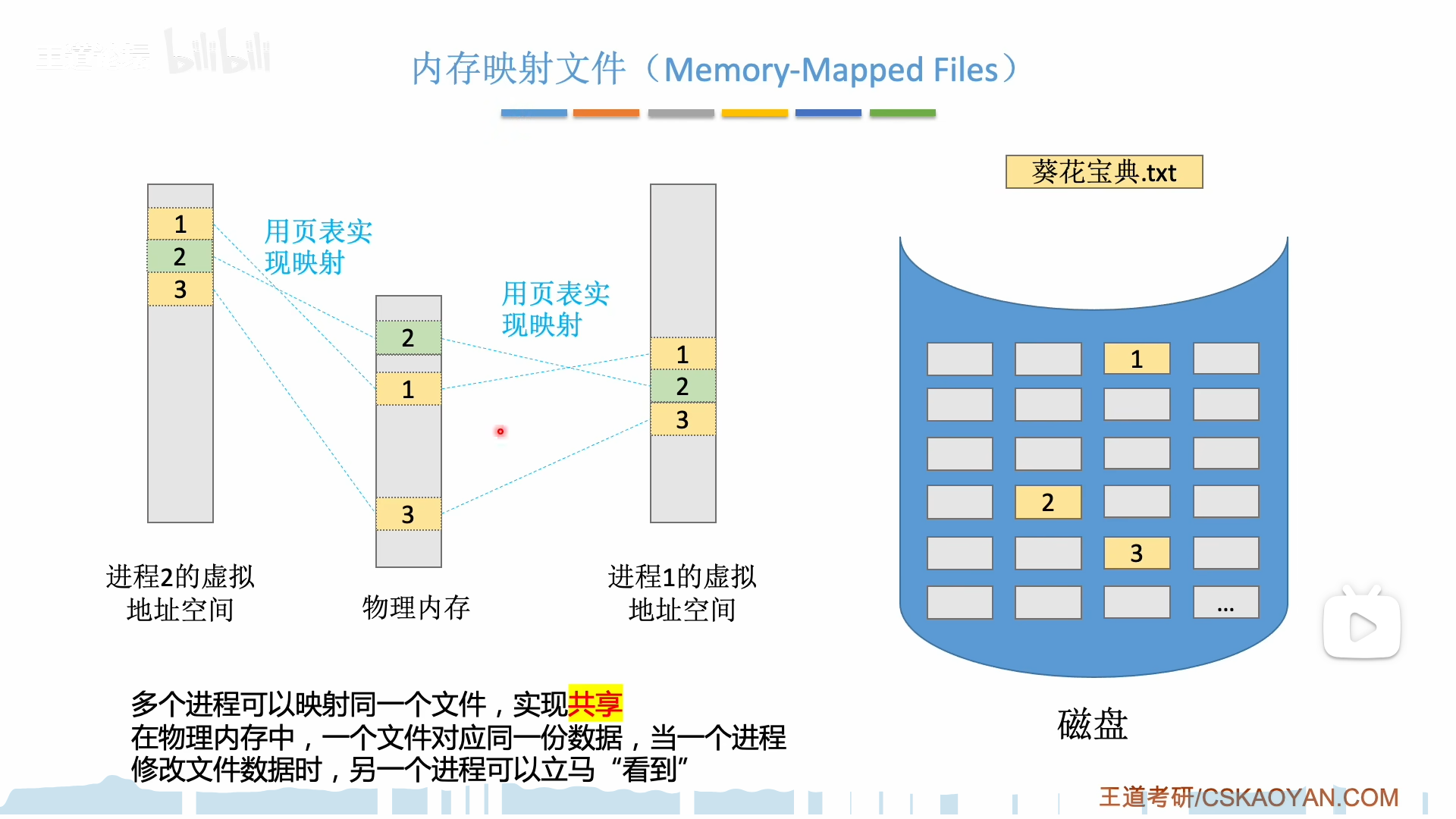
文件映射还有另一个好处,就是便于共享文件。
注意区分页表项和物理页框,实际上读入后的文件是放在物理页框里的,我们说的共享只是让不同进程的页表项指向同一个页框。
文件管理

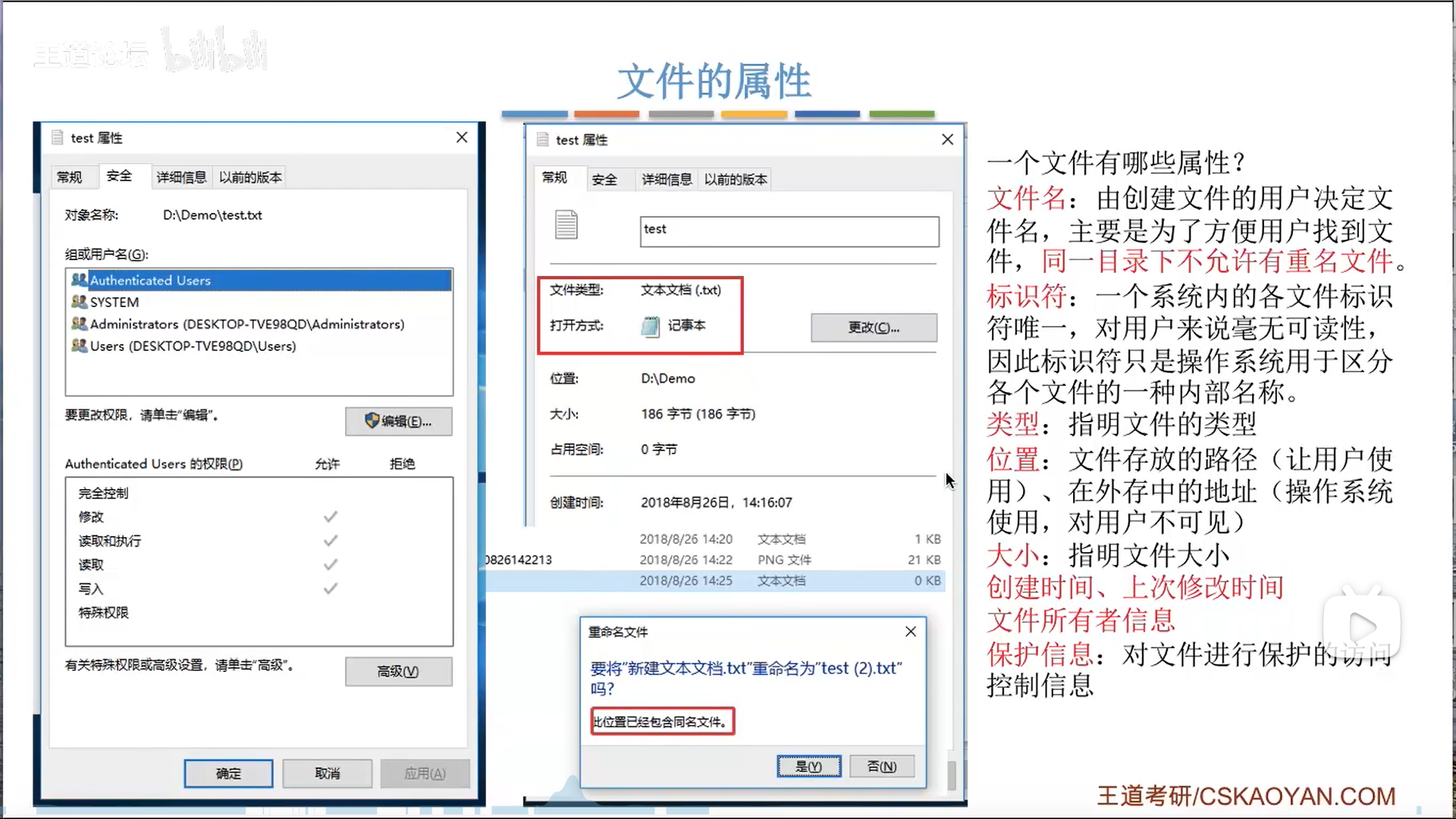
区分:
- 标识符vs文件名
- 前者是OS内部用,后者给用户
- 外存地址vs文件目录
- 前者给OS内部用,后者给用户
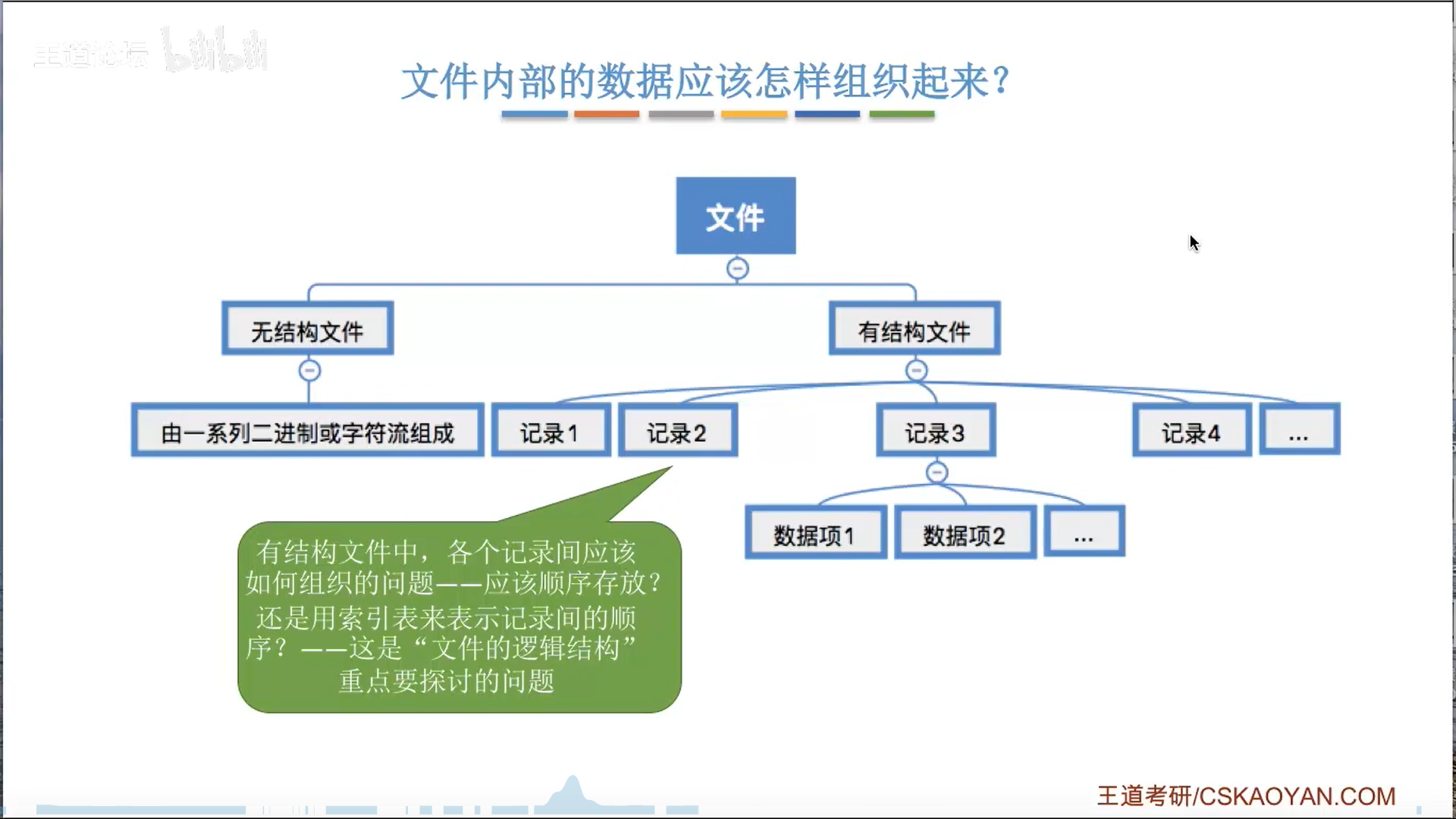
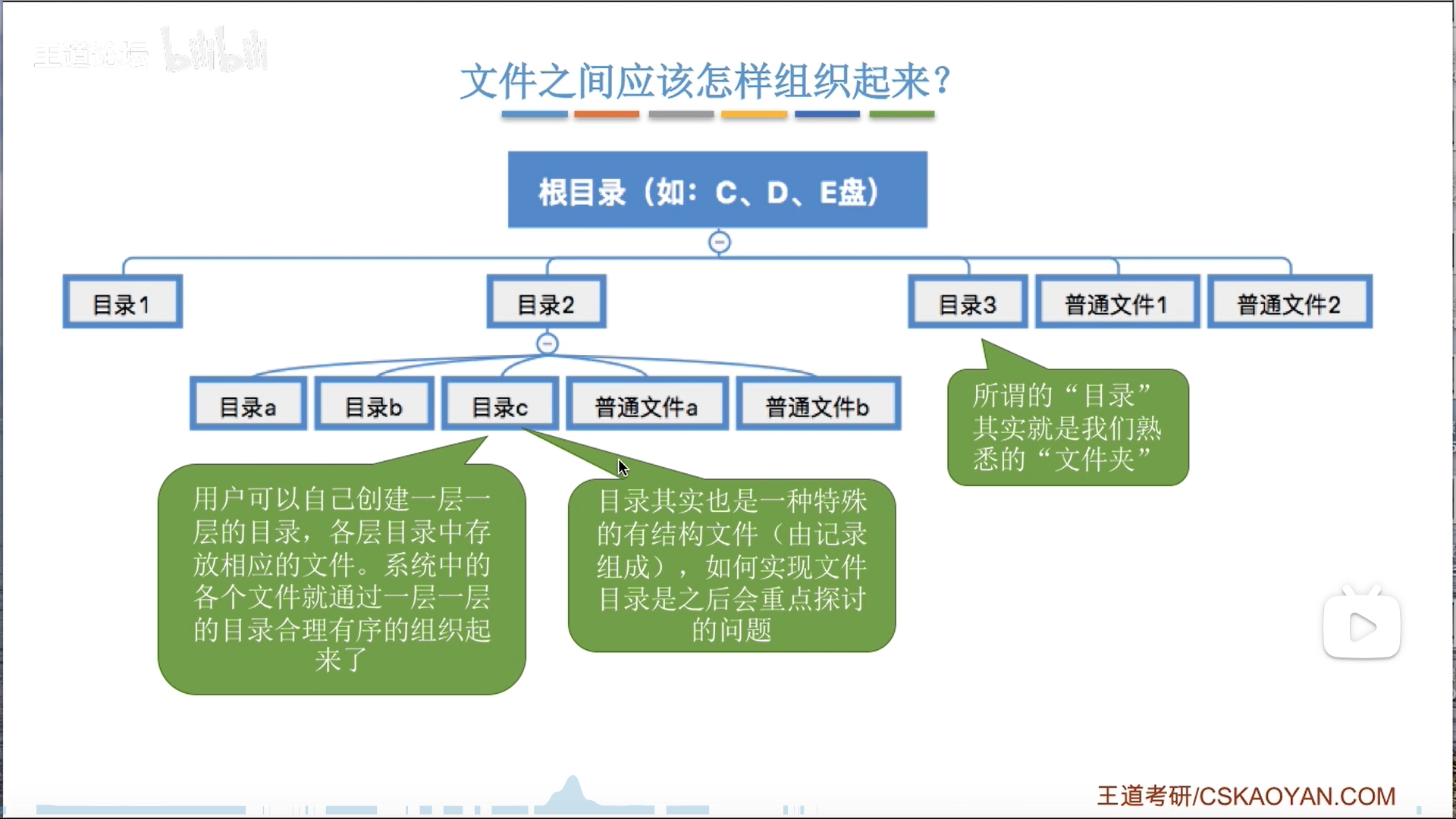
文件内部,和文件之间,都需要组织。