ELF(Executable and Linking Format)是一种对象文件的格式,它主要用于定义ELF(Executable and Linking Format)是一种对象文件的格式,它主要用于定义不同类型的对象文件中的内容以及它们的存储方式。一个ELF文件主要包含三个部分:文本段、数据段和堆栈段。
在程序运行时,每个线程都有一个独立的栈空间。这个栈空间用于存储函数调用时的局部变量和返回地址。当一个新的函数被调用时,处理器会将当前的栈指针移动到栈顶,为新的函数调用分配足够的空间来存储其局部变量和返回地址。当函数调用结束时,处理器会将栈指针恢复到原来的值,从而完成函数调用的上下文切换。
ELF文件格式解析
ELF(Executable and Linkable Format)是一种可执行文件和可链接文件的格式,它被广泛用于类Unix系统。ELF文件格式由以下几个部分组成:
-
ELF头(ELF Header):包含了文件的基本属性和结构信息,如文件类型、入口地址、程序头表位置等。
-
程序头表(Program Header Table):包含了文件中各个段的信息,如代码段、数据段、堆栈段等。每个段都有一个对应的程序头,其中包含了该段在文件中的位置、大小、读写权限等信息。
-
节头表(Section Header Table):包含了文件中各个节的信息,如符号表、字符串表等。每个节都有一个对应的节头,其中包含了该节在文件中的位置、大小、类型等信息。
-
符号表(Symbol Table):包含了文件中定义的全局变量、函数等符号信息。符号表中的每个符号都有一个对应的符号条目,其中包含了该符号的名称、类型、值等信息。
-
字符串表(String Table):包含了文件中所有的字符串常量。字符串表中的每个字符串都有一个对应的字符串条目,其中包含了该字符串的内容和长度等信息。
ELF节区信息概述
-
.shstrtab:这是一个字符串表,用于存储程序中的符号名。
-
.interp:这是一个指向解释器段的指针,用于支持动态链接。
-
.dynamic:这是一个动态段,包含了程序运行时所需的一些信息,如动态链接库、符号表等。
-
.note:这是一个注释段,用于存储程序中的各种注释信息。
-
.tbss:这是一个未初始化的数据段,用于存储程序中未初始化的全局变量和静态变量。
-
eh_frname:这是一个异常处理程序的名称段,用于存储异常处理程序的名称。
-
.bss:这是一个未初始化的数据段,用于存储程序中未初始化的全局变量和静态变量。
-
.init_array:这是一个初始化数组段,用于存储程序的初始化函数地址。
-
.fini_array:这是一个终止函数数组段,用于存储程序的终止函数地址。
-
.dynstr:这是一个动态字符串表段,用于存储动态链接库中的字符串。
-
.dynsym:这是一个动态符号表段,用于存储动态链接库中的符号信息。
-
.got.plt:这是一个全局偏移表(GOT)和过程链接表(PLT)段,用于存储动态链接库中的全局偏移表和过程链接表的地址。
-
.data:这是一个数据段,用于存储程序中的常量和静态变量。
-
.plt:这是一个过程链接表段,用于存储程序中需要调用的外部函数的地址。
-
.init:这是一个初始化函数段,用于存储程序的初始化函数地址。
-
.rela.dyn:这是一个重定位动态段,用于存储动态链接库中的重定位信息。
-
.rel.dyn:这是一个重定位动态段,用于存储动态链接库中的重定位信息。
-
.rela.plt:这是一个重定位过程链接表段,用于存储程序中需要调用的外部函数的重定位信息。
-
.rel.plt:这是一个重定位过程链接表段,用于存储程序中需要调用的外部函数的重定位信息。
-
.text:这是一个代码段,用于存储程序的可执行代码。
-
.fini:这是一个终止函数段,用于存储程序的终止函数地址。
-
.gun.version:这是一个版本信息段,用于存储程序的版本信息。
-
.gun.version_r:这是一个版本信息段,用于存储程序的版本信息。
-
.gun.hash:这是一个哈希值段,用于存储程序的哈希值。
深入分析ELF文件的可执行栈
ELF文件是一种常见的可执行文件格式,用于在Linux和其他类Unix系统上运行程序。ELF文件包含程序的可执行代码和其他相关信息,如数据段、符号表、重定位表等。
可执行栈是程序运行时用于存储局部变量、函数调用信息等的一块内存区域。ELF文件中的可执行代码被加载到内存中,操作系统会为程序分配一块可执行栈空间。在程序执行过程中,将局部变量等数据保存在栈上,并通过栈来维护函数调用的执行顺序。
要深入分析ELF文件的可执行栈,可以参考以下几个方面:
-
栈帧结构:程序的每个函数调用都会在栈上创建一个栈帧。栈帧包含函数的参数、局部变量以及一些与函数调用相关的信息,如返回地址、上一级函数的栈帧指针等。了解栈帧的结构可以帮助分析函数调用过程和内存布局。
-
栈指针:程序运行时,栈指针指向当前栈顶的位置。当函数调用时,栈指针会移动到新的栈帧起始位置,分配空间给新的局部变量。了解栈指针的变化可以追踪函数调用的过程。
-
缓冲区溢出漏洞:栈溢出是一种常见的安全漏洞,攻击者可以通过向缓冲区输入超出预留空间的数据来破坏程序的执行或注入恶意代码。分析可执行栈可以帮助识别和防止栈溢出漏洞。
-
异常处理:当程序运行遇到异常情况时,如除零错误或访问非法内存操作等,操作系统会通过异常处理机制来捕获并处理这些异常。了解可执行栈的结构和异常处理机制可以帮助理解程序运行时的错误处理过程。
Linux内存映射
Linux内存映射是一种将文件或设备映射到进程虚拟内存地址空间的机制。通过内存映射,进程可以像访问内存一样访问文件或设备的内容,而无需进行显式的读写操作。
在Linux中,内存映射主要通过下面两个系统调用来实现:
-
mmap():mmap系统调用可以将文件的一部分或整个文件映射到进程的虚拟内存地址空间中。通过mmap,进程可以直接访问文件内容,而不需要使用常规的I/O操作。
-
munmap():munmap系统调用用于解除对内存的映射关系。通过munmap,进程可以释放不再需要的内存映射。这样可以及时释放系统资源,避免内存泄漏。
使用内存映射的好处包括:
-
避免了频繁的文件I/O操作:内存映射可以将文件内容直接映射到进程的内存中,避免了频繁的读写操作,提高了读写效率。
-
简化了对文件数据的访问:通过内存映射,可以直接通过内存地址访问文件的内容,无需使用read()和write()等系统调用。
-
允许进程间共享数据:多个进程可以通过将同一个文件映射到它们的地址空间中来共享数据,实现高效的进程间通信。
-
方便处理大文件:通过内存映射,即使是超过进程地址空间大小的大文件也可以被处理,而不需要将其一次性读入内存。
二进制修复和重建
二进制修复和重建是指对损坏、缺失或不完整的二进制文件进行修复或重新构建的过程。这通常是在软件开发、系统管理和计算机安全等领域中遇到的问题。
二进制修复通常包括以下几个步骤:
-
检测和诊断:首先需要检测二进制文件的问题,并进行诊断。常见的问题包括缺少或损坏的代码、数据、库引用、符号表等。通过分析文件的结构和内容,以及使用相关工具进行静态或动态分析,可以帮助确定问题的位置和性质。
-
修复和恢复:一旦问题被确定,就可以进行修复和恢复工作。这可能包括从备份中恢复、重新生成缺失的部分、修复损坏的数据结构等。根据问题的具体性质和复杂程度,可能需要使用特定的工具和技术进行修复。
-
验证和测试:修复完成后,需要进行验证和测试,确保二进制文件恢复正常并没有引入新的问题。可以通过运行测试用例、执行静态和动态分析、进行漏洞扫描等方式来验证修复的效果。
二进制重建通常是指从已有的二进制文件中重建出源代码或高层次的抽象表示。这在逆向工程、漏洞分析、恶意软件分析等领域中非常有用。重建二进制文件的源代码可以帮助理解程序的逻辑、进行安全审计和修复漏洞等工作。
二进制重建常用的技术包括:
-
反汇编:通过将二进制文件转换为汇编代码,可以获得对程序逻辑的低级别理解。可以使用反汇编器工具来执行这个过程。
-
动态分析:通过运行二进制文件,并使用调试器和动态分析工具,可以观察和分析程序的执行行为。这可以帮助理解程序的运行流程、数据处理机制等。
-
符号恢复:尝试恢复丢失的符号信息,比如函数名、变量名等。这可以通过对二进制文件进行静态分析,观察函数调用关系、命名模式等来实现。
Linux C/C++ 从内存转储中恢复64位ELF可执行文件
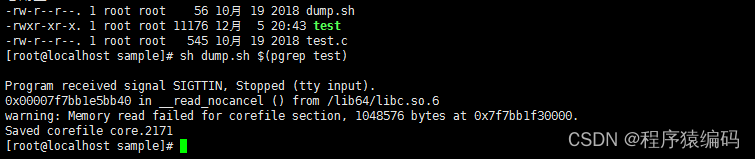
首先,我们需要获得一个程序的核心转储。为此,您可以使用gcore实用程序或提供的示例/dump.sh脚本,在调用gcore之前,它可以确保正确设置了coredump_filter。
dump.sh
#!/bin/sh
echo 0x07 > /proc/$1/coredump_filter
gcore $1
程序的核心转储示例:
...int main(int argc, char *argv[])
{bss_var = 0x13371337;int stack_var = 0xcafecafe;int *heap_var = (int *) malloc(sizeof(int));*heap_var = 0xabcdabcd;printf("bss_var....[%p]=0x%08x\n", &bss_var, bss_var);printf("data_var...[%p]=0x%08x\n", &data_var, data_var);printf("stack_var..[%p]=0x%08x\n", &stack_var, stack_var);printf("heap_var...[%p]=0x%08x\n", heap_var, *heap_var);data_var = 0xaf7e3; //aftergetc(stdin);return 0;
}./test &

sh dump.sh $(pgrep test)
在获得转储之后,为了恢复二进制文件,通过将核心转储文件作为第一参数和输出文件的所需名称作为第二参数来调用core_elf64程序就足够了,Linux C/C++ 从内存转储中恢复64位ELF可执行文件:
int main(int argc, char **argv)
{
...if ( argc != 3 ) printf("Usage: %s <core dump> <output file>", argv[0]);in = open(argv[1], O_RDONLY);if (in < 0) die("Coudln't open file: %s\n", argv[1]);if (read(in, core_e_ident, sizeof(core_e_ident)) != sizeof(core_e_ident)) printf("Read error\n");if(strncmp(core_e_ident, ELFMAG, SELFMAG))printf("%s is not an ELF file!\n", argv[1]);if(core_e_ident[EI_CLASS] != ELFCLASS64)printf("This version supports only 64 bit core dumps!\n");if(core_e_ident[EI_DATA] != ELFDATA2LSB)printf("This version supports only Little Endian!\n");/* Read ELF header */if (lseek(in, 0, SEEK_SET) < 0) printf("Seek error\n");core_ehdr = (Elf64_Ehdr *) malloc(sizeof(Elf64_Ehdr));if (core_ehdr == NULL) printf("malloc error\n");if (read(in, core_ehdr, sizeof(Elf64_Ehdr)) != sizeof(Elf64_Ehdr)) printf("Read error\n");if (core_ehdr->e_type != ET_CORE) printf("%s is not a core dump!", argv[1]);if (core_ehdr->e_machine != EM_X86_64)printf("This version supports only 64 bit core dumps!");unsigned int core_phdr_size = core_ehdr->e_phentsize*core_ehdr->e_phnum;if (lseek(in, core_ehdr->e_phoff, SEEK_SET) < 0) printf("Seek error\n");core_phdr = (Elf64_Phdr *) malloc(core_phdr_size);if (core_phdr == NULL) printf("malloc error\n");if (read(in, core_phdr, core_phdr_size) < core_phdr_size) printf("Read error\n");printf("\n[*] Core dump contains the following segments:\n\n");printf("Index %16s Virt. addr. start Virt. addr. end Flags\n", "Type");for(i=0; i<core_ehdr->e_phnum; i++){printf("[%4d] %16s 0x%016lx - 0x%016lx %c %c %c\n", i,seg_type_to_str(core_phdr[i].p_type),core_phdr[i].p_vaddr, core_phdr[i].p_vaddr+core_phdr[i].p_memsz,core_phdr[i].p_flags & PF_R ? 'R' : ' ',core_phdr[i].p_flags & PF_W ? 'W' : ' ',core_phdr[i].p_flags & PF_X ? 'X' : ' ');}printf("\n[*] Valid text segments: ");for(i=0; i<core_ehdr->e_phnum; i++){/* 读取段的前4个字节,看看它是否为ELF */char *seg_data = xget(in, core_phdr[i].p_offset, SELFMAG);if( core_phdr[i].p_type == PT_LOAD &&core_phdr[i].p_flags == (PF_R | PF_X) &&strncmp(seg_data, ELFMAG, SELFMAG) == 0 ){printf("%d ", i);if ( (core_phdr[i].p_vaddr & (~0xfffff)) == 0x400000 )core_text_seg_index = i;} if(seg_data != NULL) free(seg_data);}printf("\n");if(core_text_seg_index == -1){printf("Unable to find a text segment near virtual address 0x400000, " "please specify a text segment index (usually 1): ");scanf("%d", &core_text_seg_index);} printf("[*] Text segment index = %d\n", core_text_seg_index);/* 检索文本段数据 */char *text_seg_data = xget(in, core_phdr[core_text_seg_index].p_offset, core_phdr[core_text_seg_index].p_filesz);Elf64_Ehdr *ehdr;Elf64_Phdr *phdr;ehdr = (Elf64_Ehdr *) text_seg_data;phdr = (Elf64_Phdr *) &text_seg_data[ehdr->e_phoff];printf("[*] Reconstructed Program Header:\n\n");printf("Index %16s Virt. addr. start Virt. addr. end Flags\n", "Type");for(i=0; i<ehdr->e_phnum; i++){printf("[%4d] %16s 0x%016lx - 0x%016lx %c %c %c\n", i,seg_type_to_str(phdr[i].p_type),phdr[i].p_vaddr, phdr[i].p_vaddr+phdr[i].p_memsz,phdr[i].p_flags & PF_R ? 'R' : ' ',phdr[i].p_flags & PF_W ? 'W' : ' ',phdr[i].p_flags & PF_X ? 'X' : ' ');}for(i=0; i<ehdr->e_phnum; i++){if( phdr[i].p_type == PT_LOAD && phdr[i].p_flags == (PF_R | PF_X) &&phdr[i].p_vaddr < ehdr->e_entry &&phdr[i].p_vaddr + phdr[i].p_memsz > ehdr->e_entry){text_seg_index = i;}if( phdr[i].p_type == PT_LOAD && (phdr[i].p_flags & PF_W) ){data_seg_index = i;}if( phdr[i].p_type == PT_DYNAMIC ){dyn_seg_index = i;}}if(text_seg_index == -1)die("Unable to find text segment");elseprintf("\n[*] Text segment: 0x%lx - 0x%lx\n", phdr[text_seg_index].p_vaddr,phdr[text_seg_index].p_vaddr + phdr[text_seg_index].p_memsz);if(data_seg_index == -1)printf("[*] Unable to find data segment\n");elseprintf("[*] Data segment: 0x%lx - 0x%lx\n", phdr[data_seg_index].p_vaddr,phdr[data_seg_index].p_vaddr + phdr[data_seg_index].p_memsz);if(dyn_seg_index == -1)printf("[*] Unable to find dynamic segment\n");elseprintf("[*] Dynamic segment: 0x%lx - 0x%lx\n", phdr[dyn_seg_index].p_vaddr,phdr[dyn_seg_index].p_vaddr + phdr[dyn_seg_index].p_memsz);/* 恢复找到的分段的内容 */char **seg_data = malloc(sizeof(char *)*ehdr->e_phnum);if(seg_data == NULL) printf("Malloc error\n");for(i=0; i<ehdr->e_phnum; i++){for (j=0; j<core_ehdr->e_phnum; j++) {/* If executable is PIE */if(ehdr->e_type == ET_DYN){if( phdr[i].p_vaddr >= core_phdr[j].p_vaddr - core_phdr[core_text_seg_index].p_vaddr &&phdr[i].p_vaddr < core_phdr[j].p_vaddr + core_phdr[j].p_filesz - core_phdr[core_text_seg_index].p_vaddr){//printf("%d recover with %d\n",i,j);seg_data[i] = xget( in,core_phdr[j].p_offset + phdr[i].p_vaddr - (core_phdr[j].p_vaddr - core_phdr[core_text_seg_index].p_vaddr),phdr[i].p_filesz );break;}}else{if( phdr[i].p_vaddr >= core_phdr[j].p_vaddr &&phdr[i].p_vaddr < core_phdr[j].p_vaddr + core_phdr[j].p_filesz ){//printf("%d recover with %d\n",i,j);seg_data[i] = xget( in,core_phdr[j].p_offset + phdr[i].p_vaddr - core_phdr[j].p_vaddr,phdr[i].p_filesz );break;}}}}
...written)int out = open(argv[2], O_WRONLY | O_CREAT | O_TRUNC, S_IRUSR | S_IWUSR | S_IXUSR);if (out < 0) die("Failed to create output file %s", argv[2]);for (i=0; i<ehdr->e_phnum; i++){if (lseek(out, phdr[i].p_offset, SEEK_SET) < 0)die("Error seek");if (write(out, seg_data[i], phdr[i].p_filesz) != phdr[i].p_filesz)die("Write error");if (phdr[i].p_offset + phdr[i].p_filesz > eof)eof = phdr[i].p_offset + phdr[i].p_filesz;}/* Write section strings */if (lseek(out, eof, SEEK_SET) < 0)die("Error Seek");if (write(out, shstr, sizeof(shstr)) != sizeof(shstr))die("Error writing shstr");/* Reset section header offset and number */ehdr->e_shoff = eof + sizeof(shstr);ehdr->e_shnum = 0;ehdr->e_shstrndx = 1;/*********************************//* Section header reconstruction *//*********************************/Elf64_Shdr shdr;Elf64_Word interp_index = 0; //Store interp section index needed below/* Recover simple sections (1:1 matching with segments) */printf("\n[*] Recovered sections:\n");/* NULL section */memset(&shdr, 0, sizeof(shdr));if (write(out, &shdr, sizeof(shdr)) != sizeof(shdr)) die("Write Error");ehdr->e_shnum++;/* .shstrtab */shdr.sh_name = sec_index(".shstrtab");
...if (write(out, &shdr, sizeof(shdr)) != sizeof(shdr)) die("Error .shstrtab");ehdr->e_shnum++;for (i=0; i<ehdr->e_phnum; i++){switch(phdr[i].p_type){/* .interp */case PT_INTERP:shdr.sh_name = sec_index(".interp");
...if (write(out, &shdr, sizeof(shdr)) != sizeof(shdr)) die("Error .interp");ehdr->e_shnum++;printf("\t.interp\n");break;/* .dynamic */case PT_DYNAMIC:shdr.sh_name = sec_index(".dynamic");
...if (write(out, &shdr, sizeof(shdr)) != sizeof(shdr)) die("Error .dynamic");ehdr->e_shnum++;printf("\t.dynamic\n");break;/* .note */case PT_NOTE:shdr.sh_name = sec_index(".note");
...if (write(out, &shdr, sizeof(shdr)) != sizeof(shdr)) die("Error .note");ehdr->e_shnum++;printf("\t.note\n");break;/* .tbss */case PT_TLS:shdr.sh_name = sec_index(".tbss");
...if (write(out, &shdr, sizeof(shdr)) != sizeof(shdr)) die("Error .tbss");ehdr->e_shnum++;printf("\t.tbss\n");break;/* .eh_frame_hdr and .eh_frame */case PT_GNU_EH_FRAME:shdr.sh_name = sec_index(".eh_frame_hdr");
...if (write(out, &shdr, sizeof(shdr)) != sizeof(shdr)) die("Error .eh_frame_hdr");ehdr->e_shnum++;printf("\t.eh_frame\n");shdr.sh_name = sec_index(".eh_frame");
... if (write(out, &shdr, sizeof(shdr)) != sizeof(shdr)) die("Error .eh_frame");ehdr->e_shnum++;printf("\t.eh_frame_hdr\n");break;}} if(data_seg_index != -1){shdr.sh_name = sec_index(".bss");
...if (write(out, &shdr, sizeof(shdr)) != sizeof(shdr)) die("Error .bss");ehdr->e_shnum++;printf("\t.bss\n");}...for(; dyn->d_tag != DT_NULL; ++dyn){switch(dyn->d_tag){ case DT_BIND_NOW: //Full relrobindnow = 1;break;case DT_INIT:init = dyn->d_un.d_ptr;break;case DT_FINI:fini = dyn->d_un.d_ptr;break;case DT_INIT_ARRAY:init_array = dyn->d_un.d_ptr;break;case DT_INIT_ARRAYSZ:init_arraysz = dyn->d_un.d_val;break;case DT_FINI_ARRAY:fini_array = dyn->d_un.d_ptr;break;case DT_FINI_ARRAYSZ:fini_arraysz = dyn->d_un.d_val;break;case DT_GNU_HASH:if(pie) dyn->d_un.d_ptr -= core_phdr[core_text_seg_index].p_vaddr;gnu_hash = dyn->d_un.d_ptr;break;case DT_STRTAB:if(pie) dyn->d_un.d_ptr -= core_phdr[core_text_seg_index].p_vaddr;strtab = dyn->d_un.d_ptr;break;case DT_SYMTAB:if(pie) dyn->d_un.d_ptr -= core_phdr[core_text_seg_index].p_vaddr;symtab = dyn->d_un.d_ptr;break;case DT_STRSZ:strsz = dyn->d_un.d_val;break;case DT_SYMENT:syment = dyn->d_un.d_val;break;case DT_PLTGOT:if(pie) dyn->d_un.d_ptr -= core_phdr[core_text_seg_index].p_vaddr;pltgot = dyn->d_un.d_ptr;break;case DT_PLTRELSZ:pltrelsz = dyn->d_un.d_val;break;case DT_PLTREL:pltrel = dyn->d_un.d_val;break;case DT_JMPREL:if(pie) dyn->d_un.d_ptr -= core_phdr[core_text_seg_index].p_vaddr;jmprel = dyn->d_un.d_ptr;break;case DT_RELA:if(pie) dyn->d_un.d_ptr -= core_phdr[core_text_seg_index].p_vaddr;rela = dyn->d_un.d_ptr;break;case DT_RELASZ:relasz = dyn->d_un.d_val;break;case DT_RELAENT:relaent = dyn->d_un.d_val;break;case DT_REL:rel = dyn->d_un.d_ptr;break;case DT_RELSZ:relsz = dyn->d_un.d_val;break;case DT_RELENT:relent = dyn->d_un.d_val;break;case DT_VERNEED:verneed = dyn->d_un.d_ptr;break;case DT_VERNEEDNUM:verneednum = dyn->d_un.d_val;break;case DT_VERSYM:if(pie) dyn->d_un.d_ptr -= core_phdr[core_text_seg_index].p_vaddr;versym = dyn->d_un.d_ptr;break;default://printf("%ld\n", dyn->d_tag);break;}}/* 如果PIE将正确的值重写到.dynamic部分 */if(pie){uint64_t fd_pos;if ((fd_pos = lseek(out, 0, SEEK_CUR)) < 0) die("Error seek");if (lseek(out, phdr[dyn_seg_index].p_offset, SEEK_SET) < 0)die("Error seek");if (write(out, seg_data[dyn_seg_index], phdr[dyn_seg_index].p_filesz) != phdr[dyn_seg_index].p_filesz)die("Write error");if (lseek(out, fd_pos, SEEK_SET) < 0)die("Error seek");} if(init_array != 0 && init_arraysz != 0){shdr.sh_name = sec_index(".init_array");
....if (write(out, &shdr, sizeof(shdr)) != sizeof(shdr)) die("Error .init_array");ehdr->e_shnum++;printf("\t.init_array\n");}/* .fini_array - In data segment, contains pointer to code to be* execute at the end */if(fini_array != 0 && fini_arraysz != 0){shdr.sh_name = sec_index(".fini_array");
....if (write(out, &shdr, sizeof(shdr)) != sizeof(shdr)) die("Error .fini_array");ehdr->e_shnum++;printf("\t.fini_array\n");}/* .dynstr, usually followed by versym */Elf64_Word dynstr_index = 0;if(strtab != 0 && versym != 0){shdr.sh_name = sec_index(".dynstr");
....dynstr_index = ehdr->e_shnum;if (write(out, &shdr, sizeof(shdr)) != sizeof(shdr)) die("Error .dynstr");ehdr->e_shnum++;printf("\t.dynstr\n");}Elf64_Word dynsym_index = 0; if(symtab !=0 && strtab !=0){shdr.sh_name = sec_index(".dynsym");shdr.sh_type = SHT_DYNSYM;....dynsym_index = ehdr->e_shnum;if (write(out, &shdr, sizeof(shdr)) != sizeof(shdr)) die("Error .dynsym");ehdr->e_shnum++;printf("\t.dynsym\n");}uint64_t got_entries = 0;if(pltrel != 0 && pltrelsz !=0 && (relent != 0 || relaent != 0) && pltgot != 0){if(pltrel == DT_RELA)got_entries = ((pltrelsz/relaent) + 3);else got_entries = ((pltrelsz/relent) + 3);shdr.sh_size = got_entries * sizeof(Elf64_Addr);shdr.sh_name = sec_index(".got.plt");
...if (write(out, &shdr, sizeof(shdr)) != sizeof(shdr)) die("Error .got.plt");ehdr->e_shnum++;printf("\t.got.plt\n");}/* .data - resides after .got.plt */if(pltgot != 0 && got_entries != 0){shdr.sh_name = sec_index(".data");
...if (write(out, &shdr, sizeof(shdr)) != sizeof(shdr)) die("Error .data");ehdr->e_shnum++;printf("\t.data\n");}/*.plt*/Elf64_Word plt_addr = 0;Elf64_Word plt_index = 0;/* 从init开始,然后搜索.plt模式 */if(init != 0 && pltgot != 0 && got_entries != 0){
...if(plt_addr == 0)goto section_rebuild_end;shdr.sh_name = sec_index(".plt");...plt_index = ehdr->e_shnum;if (write(out, &shdr, sizeof(shdr)) != sizeof(shdr)) die("Error .got.plt");ehdr->e_shnum++;printf("\t.plt\n");}/* .init - is just before .plt */if(init != 0 && plt_addr != 0){shdr.sh_name = sec_index(".init");
...if (write(out, &shdr, sizeof(shdr)) != sizeof(shdr)) die("Error .got.plt");ehdr->e_shnum++;printf("\t.init\n");}/* .rel.dyn or .rela.dyn */if( (rela != 0 && relaent !=0) || (rel != 0 && relent != 0) ){if(rela != 0 && relaent != 0){shdr.sh_name = sec_index(".rela.dyn");shdr.sh_type = SHT_RELA;shdr.sh_addr = rela;shdr.sh_entsize = relaent; if(jmprel)shdr.sh_size = jmprel - shdr.sh_addr;elseshdr.sh_size = relasz;}else{shdr.sh_name = sec_index(".rel.dyn");shdr.sh_type = SHT_REL;shdr.sh_addr = rel;shdr.sh_entsize = relent;if(jmprel)shdr.sh_size = jmprel - shdr.sh_addr;elseshdr.sh_size = relsz;}...if (write(out, &shdr, sizeof(shdr)) != sizeof(shdr))die("Error .rel.dyn or .rela.dyn");ehdr->e_shnum++;if(rela != 0)printf("\t.rela.dyn\n");elseprintf("\t.rel.dyn\n");}if((relent != 0 || relaent != 0) && init != 0 && jmprel != 0) {if(pltrel == DT_RELA){shdr.sh_name = sec_index(".rela.plt");shdr.sh_type = SHT_RELA;shdr.sh_entsize = relaent;}else{shdr.sh_name = sec_index(".rel.plt");shdr.sh_type = SHT_REL;shdr.sh_entsize = relent;}
...if (write(out, &shdr, sizeof(shdr)) != sizeof(shdr))die("Error .rel.dyn or .rela.dyn");ehdr->e_shnum++;if(pltrel == DT_RELA)printf("\t.rela.plt\n");elseprintf("\t.rel.plt\n");}if(plt_addr != 0 && got_entries != 0 && fini != 0){shdr.sh_name = sec_index(".text");
...if (write(out, &shdr, sizeof(shdr)) != sizeof(shdr)) die("Error .text");ehdr->e_shnum++;printf("\t.text\n");}/* .fini *//* TODO - find size*/if(fini != 0){shdr.sh_name = sec_index(".fini");
...if (write(out, &shdr, sizeof(shdr)) != sizeof(shdr)) die("Error .fini");ehdr->e_shnum++;printf("\t.fini\n");}/* .gnu.version */if(versym != 0 && strtab != 0 && symtab != 0){shdr.sh_name = sec_index(".gnu.version");
...if (write(out, &shdr, sizeof(shdr)) != sizeof(shdr)) die("Error .gnu.version");ehdr->e_shnum++;printf("\t.gnu.version\n");}/* .gnu_versioni_r - before .rel or .rela */if(verneed != 0 && verneednum != 0 && pltrel != 0){shdr.sh_name = sec_index(".gnu.version_r");
...if (write(out, &shdr, sizeof(shdr)) != sizeof(shdr)) die("Error .gnu_version_r");ehdr->e_shnum++;printf("\t.gnu_version_r\n");}/* .gnu.hash */if(gnu_hash != 0 && symtab != 0){shdr.sh_name = sec_index(".gnu.hash");shdr.sh_type = SHT_GNU_HASH;shdr.sh_addr = gnu_hash;shdr.sh_offset = gnu_hash - phdr[text_seg_index].p_vaddr;shdr.sh_size = symtab - gnu_hash;shdr.sh_flags = SHF_ALLOC;shdr.sh_link = dynsym_index;shdr.sh_info = 0;shdr.sh_addralign = 8;shdr.sh_entsize = 0;if (write(out, &shdr, sizeof(shdr)) != sizeof(shdr)) die("Error .gnu.hash");ehdr->e_shnum++;printf("\t.gnu.hash\n");}if(bindnow){printf("[*] FULL Relro binary, no GOT reconstruction is needed\n");goto section_rebuild_end;}else if(got_entries == 0){printf("[*] WARNING Can't recover GOT entries\n");goto section_rebuild_end;}printf("\n[*] %ld GOT entries found\n", got_entries);uint64_t got_off = phdr[data_seg_index].p_offset +(pltgot - phdr[data_seg_index].p_vaddr);uint64_t got_entry = 0x0;for (i = 1; i < 3; i++){if (lseek(out,got_off + sizeof(Elf64_Addr) * i,SEEK_SET) < 0)
...}/* 使用恢复的PLT地址恢复GOT部分 */for(i = 3; i < got_entries; i++){if (lseek(out,got_off + sizeof(Elf64_Addr)*i,SEEK_SET) < 0) die("Seek error");...}section_rebuild_end:/* 所有部分都恢复。现在用正确的节数重写ELF头 */if (lseek(out, 0 , SEEK_SET) < 0) die("Seek error");if (write(out, (char *)ehdr, sizeof(Elf64_Ehdr)) != sizeof(Elf64_Ehdr)) die("Write error");/* 释放分配的内存并关闭文件 */ for(i=0; i<ehdr->e_phnum; i++){free(seg_data[i]);}
...return 0;
}
If you need the complete source code, please add the WeChat number (c17865354792)
运行效果:
…/core_elf64 core.2171 rebuild

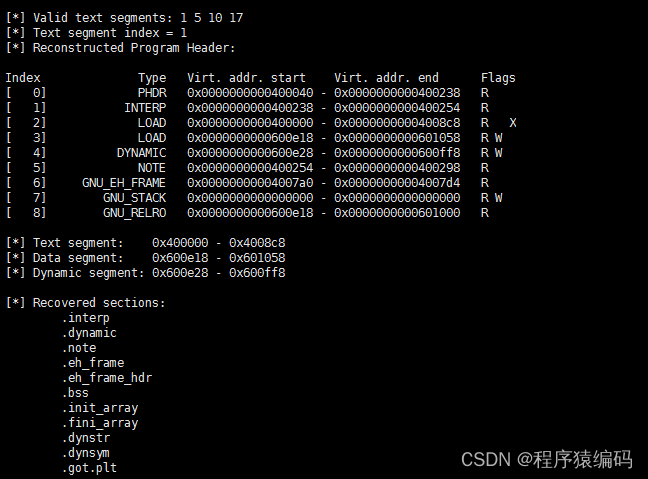
./rebuild
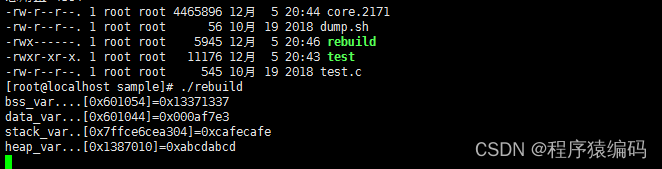
从转储中恢复二进制文件
从转储中恢复二进制文件的一般步骤如下:
-
使用适当的工具(如gcore、windbg等)生成进程的内存转储文件。这需要在合适的时间点进行,以确保转储文件包含了所需的二进制数据。
-
确定目标二进制文件的基址,即二进制文件加载到进程内存中的起始地址。可以通过查看进程的内存映射信息或使用调试工具来获取此信息。
-
使用适当的工具打开内存转储文件,并根据基址将所需的二进制数据提取出来。这可以通过从内存转储中复制包含目标二进制代码和数据区域的内存块来实现。这需要根据目标平台和文件格式进行解析和提取。
-
如果内存转储文件不包含相关的符号信息,则可能需要使用反汇编工具对提取的二进制数据进行反汇编。这样可以获得与汇编指令对应的代码。
-
对提取的二进制数据进行适当的修复和调整,以使其成为有效的可执行文件。这可能包括修复段和节表、添加相关的符号信息、修复链接关系等。
-
验证并测试恢复的二进制文件。这可以包括使用适当的调试器工具来运行和调试恢复的可执行文件,确保其功能正确。
请注意,恢复二进制文件可能涉及到操作系统、文件格式和调试方面的复杂知识和技术。因此,在执行此过程时,建议有相关的经验和对底层系统有深入的了解。
总结
从内存转储中恢复64位ELF可执行文件需要以下步骤:
-
首先,获取内存转储文件。这可以通过使用操作系统提供的工具(如Windows的Task Manager或Linux的GDB)或专用工具(如Volatility)来完成。
-
确定内存转储文件中的ELF可执行文件。这可以通过检查文件的头部信息来完成。ELF文件的头部通常包括魔数、文件类型和机器架构等信息。
-
从内存转储文件中提取ELF可执行文件。这可以通过解析文件的节区表和程序头表来完成。节区表描述了不同节区(如代码段、数据段)在文件中的位置和大小,而程序头表则描述了不同的程序段(如可加载的段、动态链接段)。
-
重建ELF可执行文件的结构。这包括创建文件头、节区表、程序头表以及各个节区的内容。通过将这些信息写入新的文件中,就能够得到一个完整的ELF可执行文件。
-
修复可能损坏的部分。由于从内存转储中恢复ELF可执行文件可能会丢失一些数据,因此可能需要进行一些修复工作。这可能包括修复损坏的符号表、重建重定位表等。
总结起来,从内存转储中恢复64位ELF可执行文件需要解析内存转储文件的结构,提取ELF文件,并通过重建文件的结构来恢复文件。
Welcome to follow WeChat official account【程序猿编码】
参考:
https://systemoverlord.com/2017/03/19/got-and-plt-for-pwning.html
https://stackoverflow.com/questions/58076539/plt-plt-got-what-is-different



![[架构之路-261]:目标系统 - 设计方法 - 软件工程 - 软件设计 - 架构设计 - 网络数据交换格式](https://img-blog.csdnimg.cn/direct/23d059d38f7640c0b740cfb2812143ec.png)