点击@计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【基础网络架构:Transformer】GIFT: Generative Interpretable Fine-Tuning Transformers
-
论文地址:https://arxiv.org//pdf/2312.00700
-
工程主页:GIFT: Generative Interpretable Fine-Tuning Transformers
-
开源代码(即将开源):GitHub - savadikarc/gift

2.【图像分类】BCN: Batch Channel Normalization for Image Classification
-
论文地址:https://arxiv.org//pdf/2312.00596
-
开源代码:GitHub - AfifaKhaled/Batch-Channel-Normalization

3.【语义分割】Efficient Multimodal Semantic Segmentation via Dual-Prompt Learning
-
论文地址:https://arxiv.org//pdf/2312.00360
-
开源代码(即将开源):GitHub - ShaohuaDong2021/DPLNet

4.【目标跟踪】Dense Optical Tracking: Connecting the Dots
-
论文地址:https://arxiv.org//pdf/2312.00786
-
工程主页:Dense Optical Tracking: Connecting the Dots
-
开源代码(即将开源):GitHub - 16lemoing/dot

5.【目标跟踪】TrackDiffusion: Multi-object Tracking Data Generation via Diffusion Models
-
论文地址:https://arxiv.org//pdf/2312.00651
-
工程主页:TrackDiffusion: Multi-object Tracking Data Generation via Diffusion Models
-
开源代码(即将开源):GitHub - pixeli99/TrackDiffusion: Multi-object Tracking Data Generation via Diffusion Models.
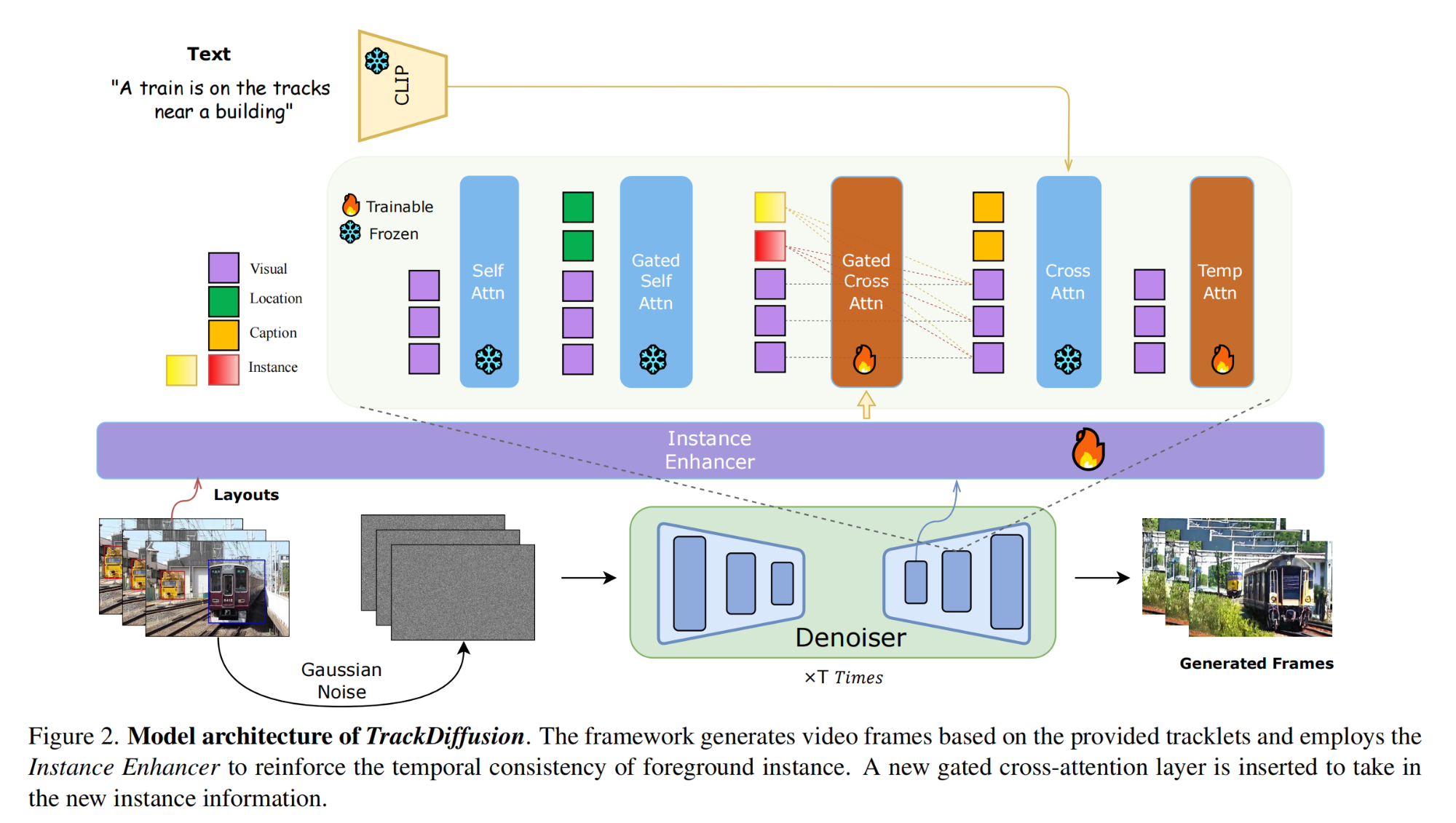
6.【人脸识别】Rethinking the Domain Gap in Near-infrared Face Recognition
-
论文地址:https://arxiv.org//pdf/2312.00627
-
开源代码(即将开源):GitHub - michaeltrs/RethinkNIRVIS
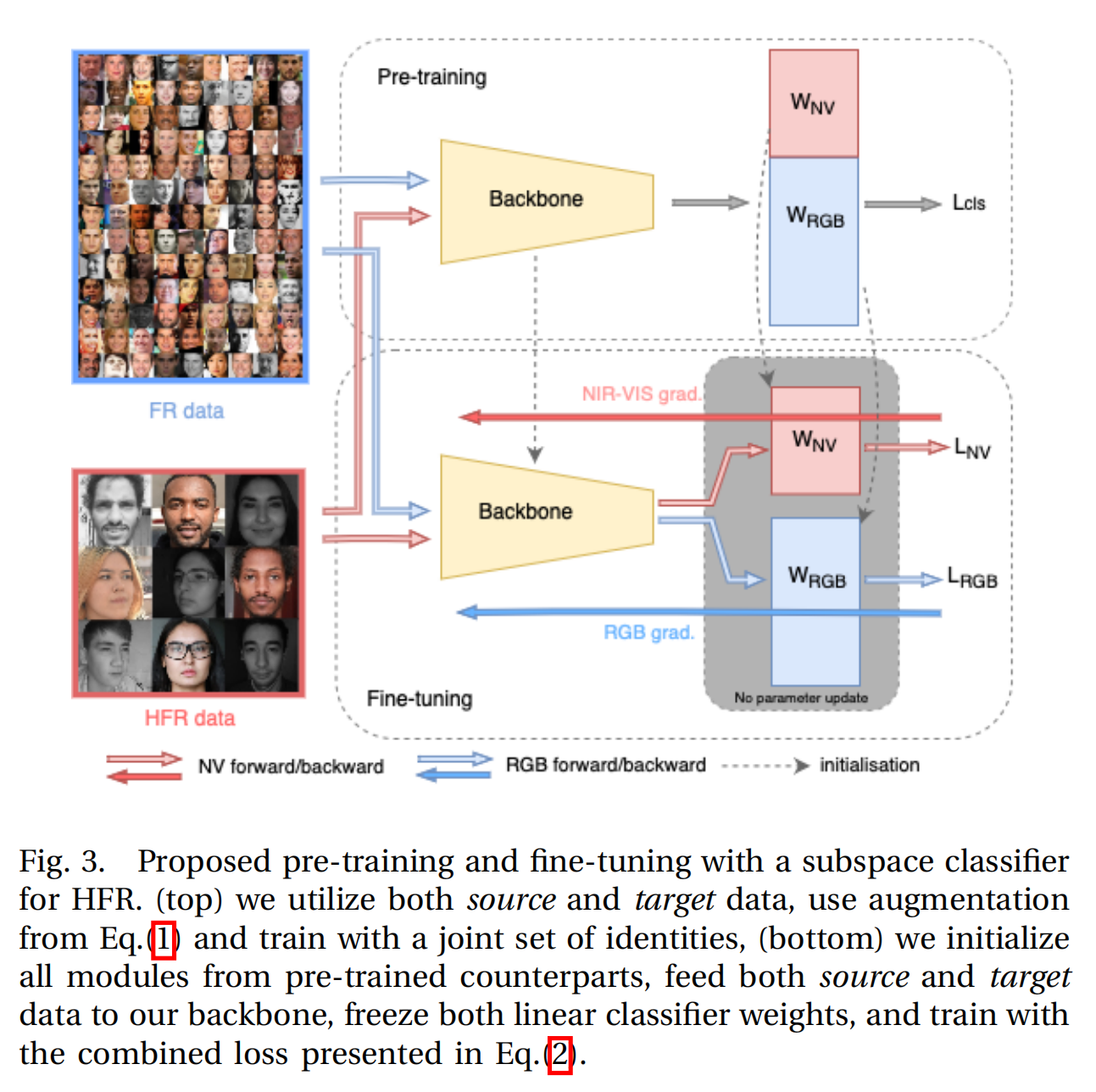
7.【多模态】Making Large Multimodal Models Understand Arbitrary Visual Prompts
-
论文地址:https://arxiv.org//pdf/2312.00784
-
工程主页:ViP-LLaVA
-
开源代码:GitHub - mu-cai/ViP-LLaVA
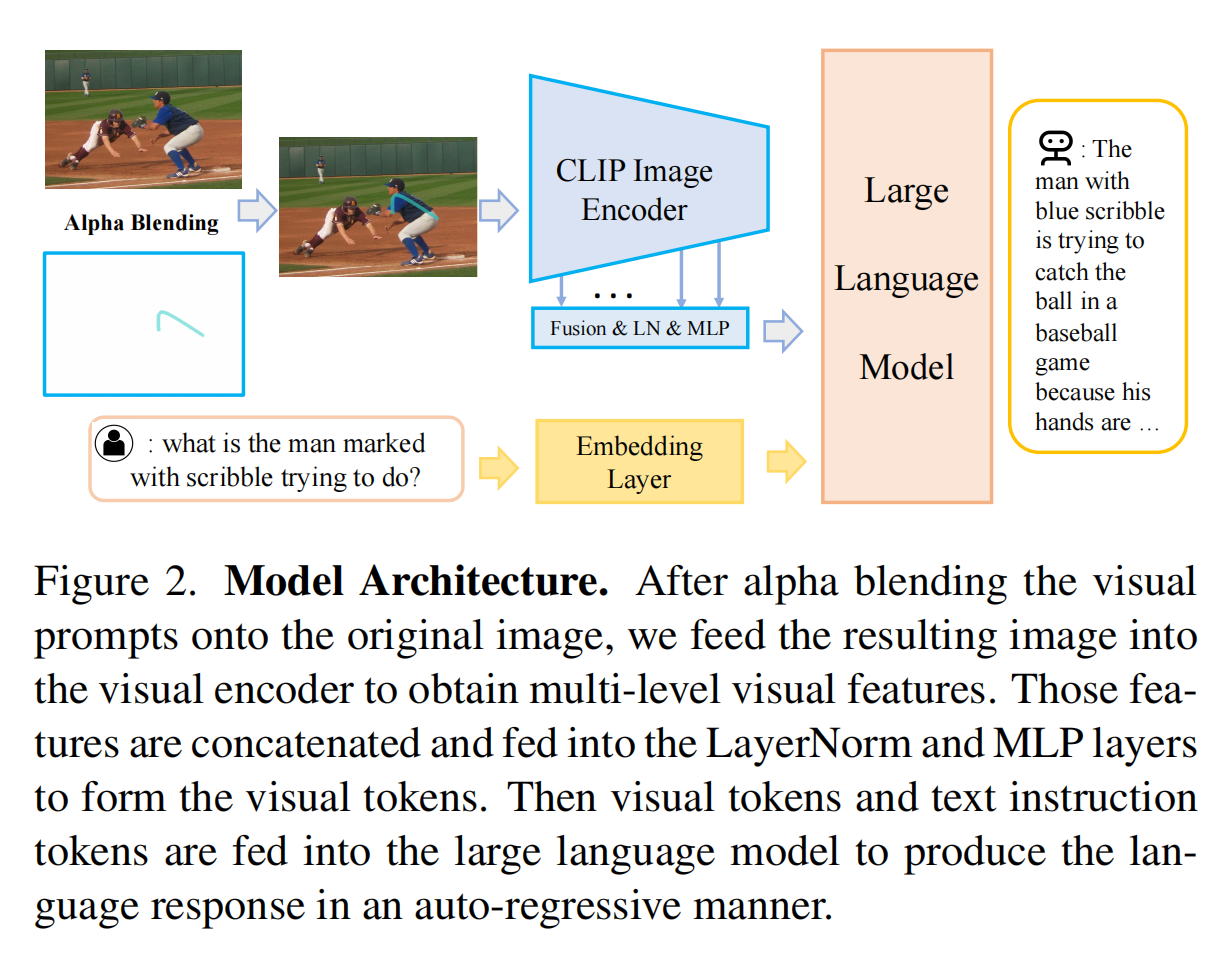
8.【多模态】Merlin:Empowering Multimodal LLMs with Foresight Minds
-
论文地址:https://arxiv.org//pdf/2312.00589
-
工程主页:Merlin: Empowering Multimodal LLMs with Foresight Minds
-
开源代码(即将开源):GitHub - Ahnsun/merlin: Merlin: Empowering Multimodal LLMs with Foresight Minds

9.【多模态】RTQ: Rethinking Video-language Understanding Based on Image-text Model
-
论文地址:https://arxiv.org//pdf/2312.00347
-
开源代码:GitHub - SCZwangxiao/RTQ-MM2023: ACM Multimedia 2023 (Oral) - RTQ: Rethinking Video-language Understanding Based on Image-text Model
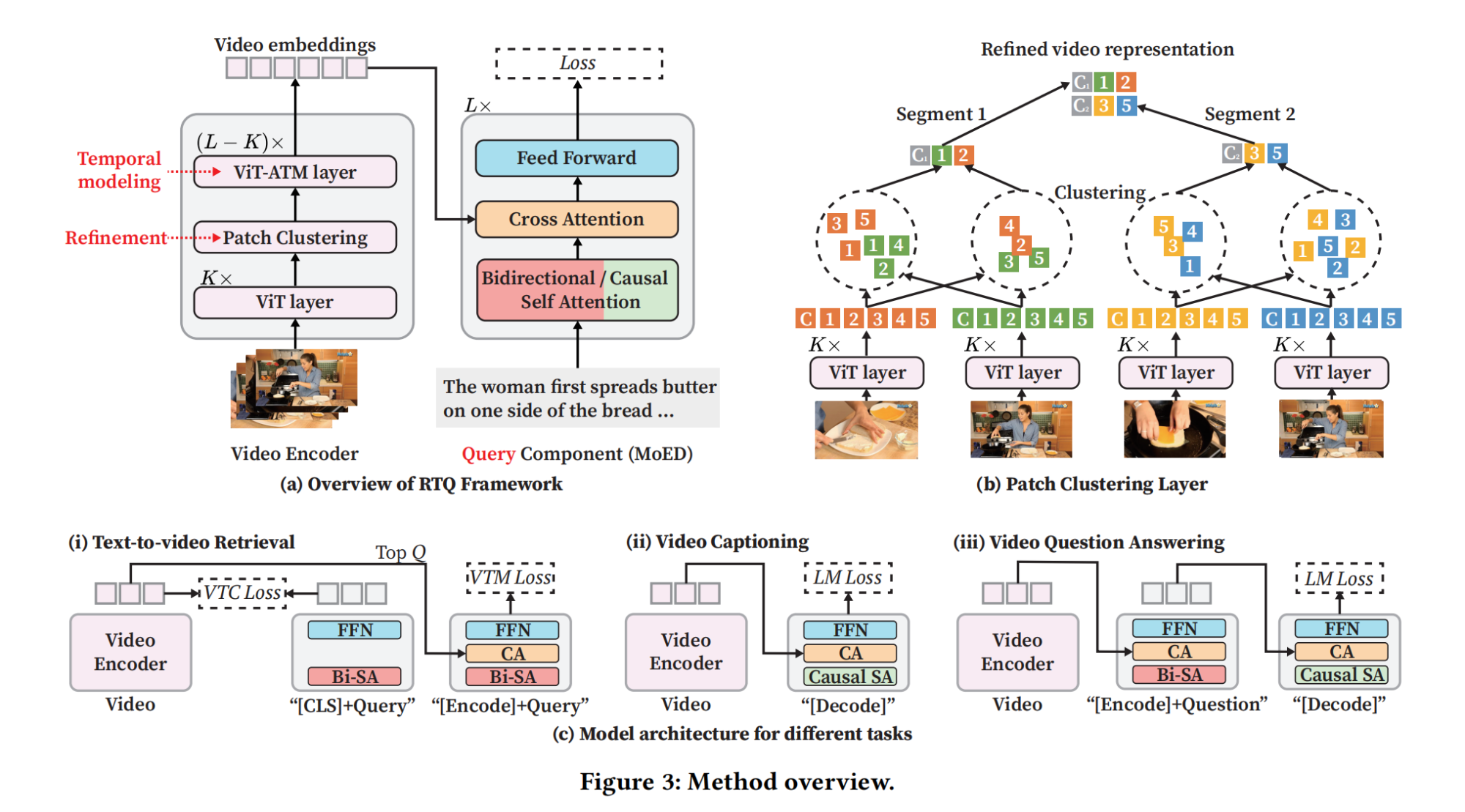
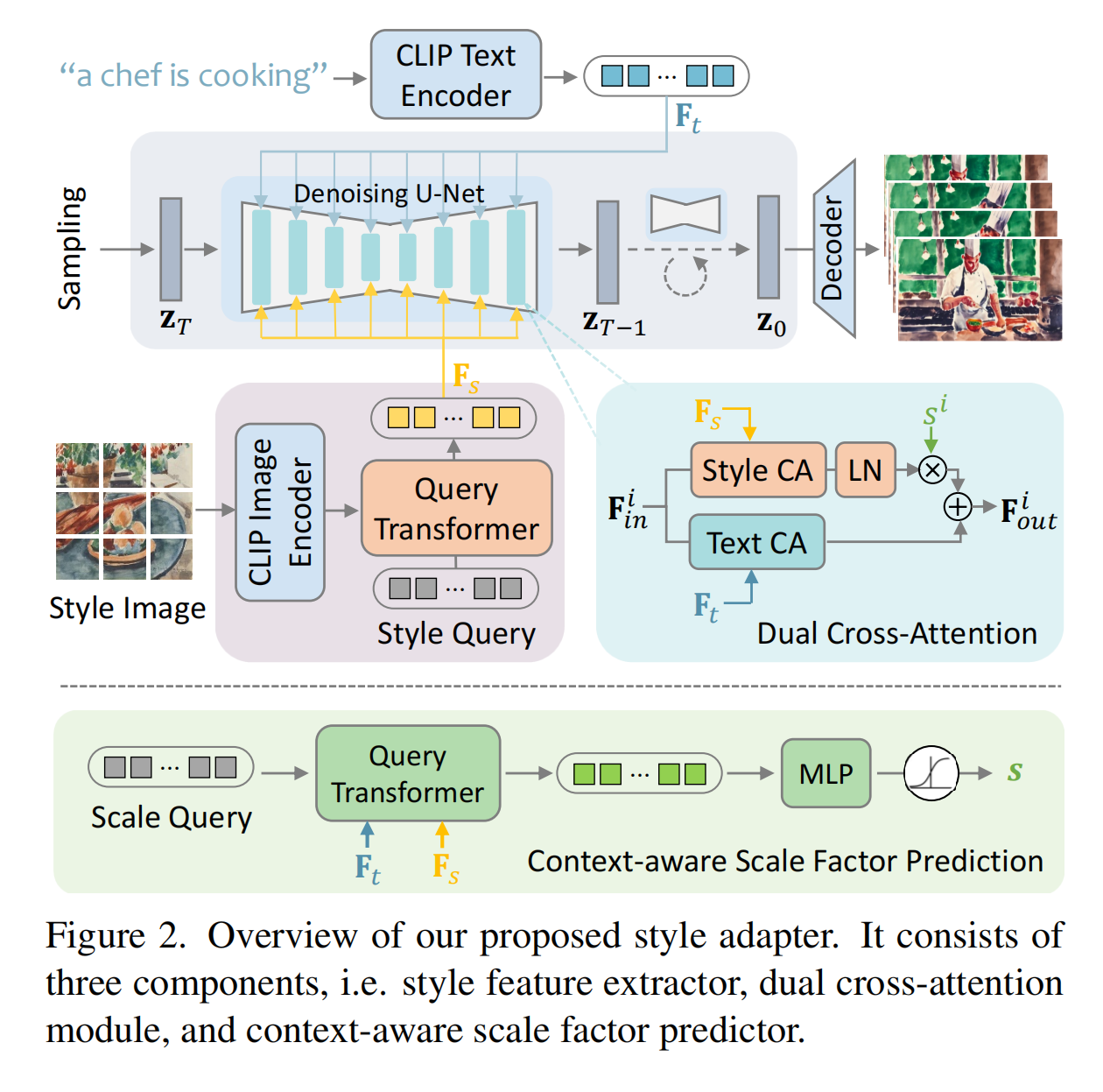
10.【多模态】StyleCrafter: Enhancing Stylized Text-to-Video Generation with Style Adapter
-
论文地址:https://arxiv.org//pdf/2312.00330
-
工程主页:StyleCrafter: Enhancing Stylized Text-to-Video Generation with Style Adapter
-
开源代码:GitHub - GongyeLiu/StyleCrafter: StyleCrafter: Enhancing Stylized Text-to-Video Generation with Style Adapter
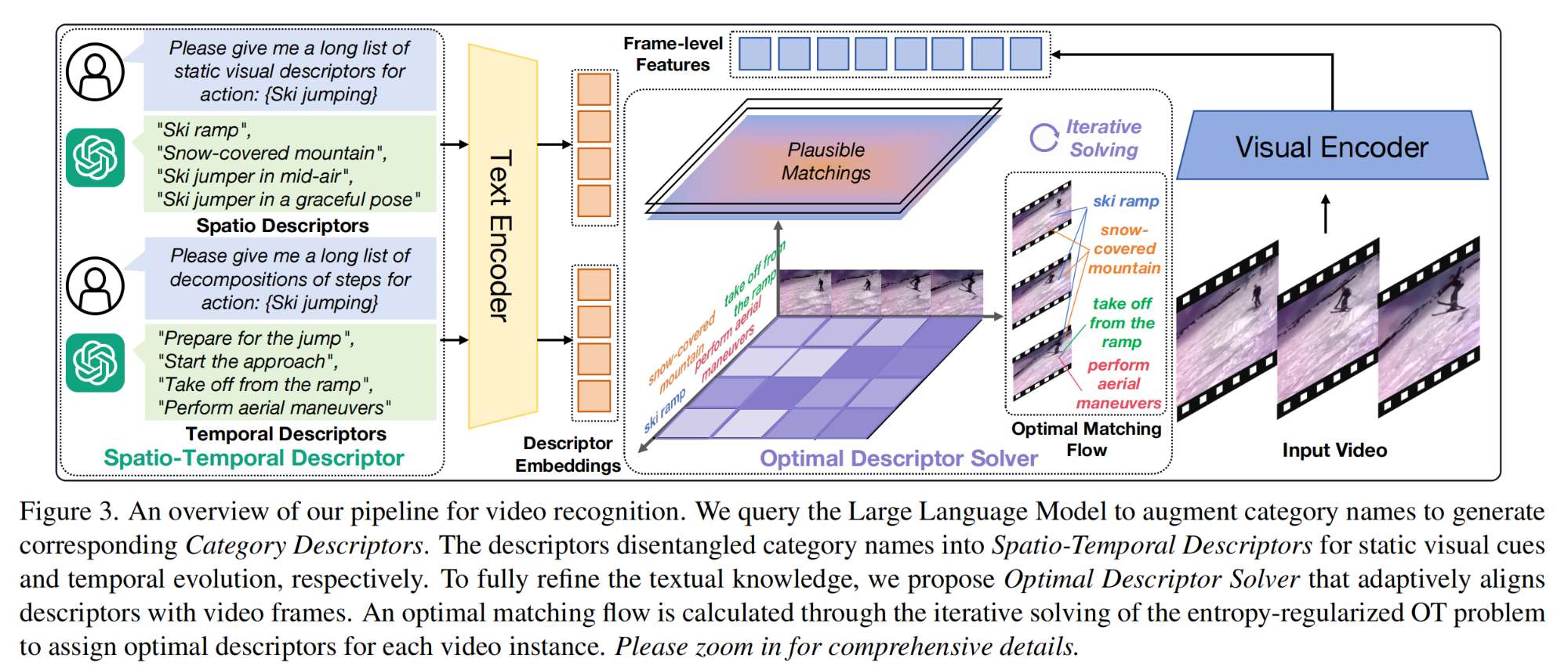
11.【多模态】OST: Refining Text Knowledge with Optimal Spatio-Temporal Descriptor for General Video Recognition
-
论文地址:https://arxiv.org//pdf/2312.00096
-
工程主页:OST: Refining Text Knowledge with Optimal Spatio-Temporal Descriptor for General Video Recognition
-
开源代码(即将开源):GitHub - tomchen-ctj/OST: OST: Refining Text Knowledge with Optimal Spatio-Temporal Descriptor for General Video Recognition
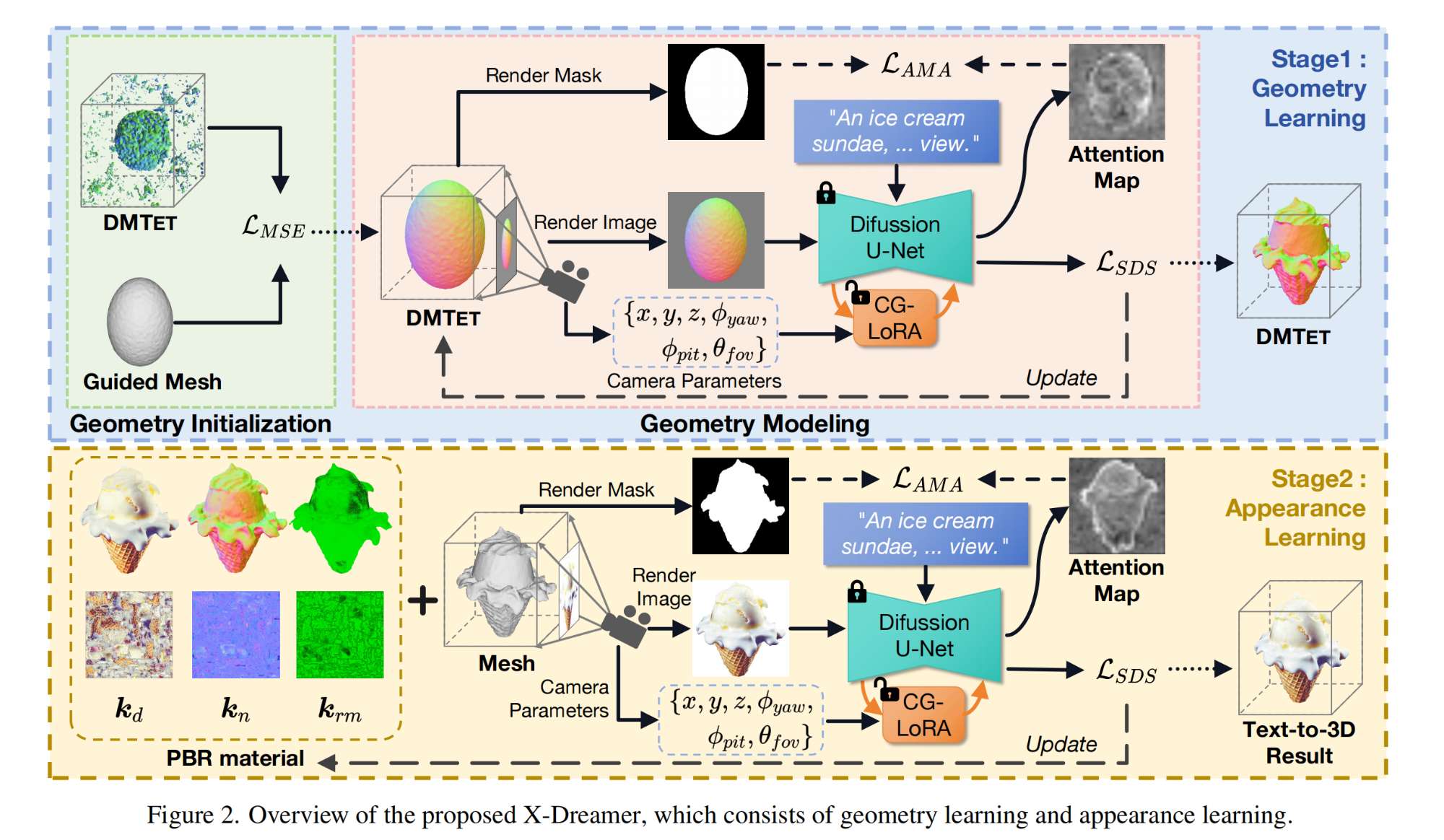
12.【多模态】X-Dreamer: Creating High-quality 3D Content by Bridging the Domain Gap Between Text-to-2D and Text-to-3D Generation
-
论文地址:https://arxiv.org//pdf/2312.00085
-
工程主页:X-Dreamer: Creating High-quality 3D Content by Bridging the Domain Gap Between Text-to-2D and Text-to-3D Generation
-
开源代码(即将开源):GitHub - xmu-xiaoma666/X-Dreamer: A pytorch implementation of “X-Dreamer: Creating High-quality 3D Content by Bridging the Domain Gap Between Text-to-2D and Text-to-3D Generation”
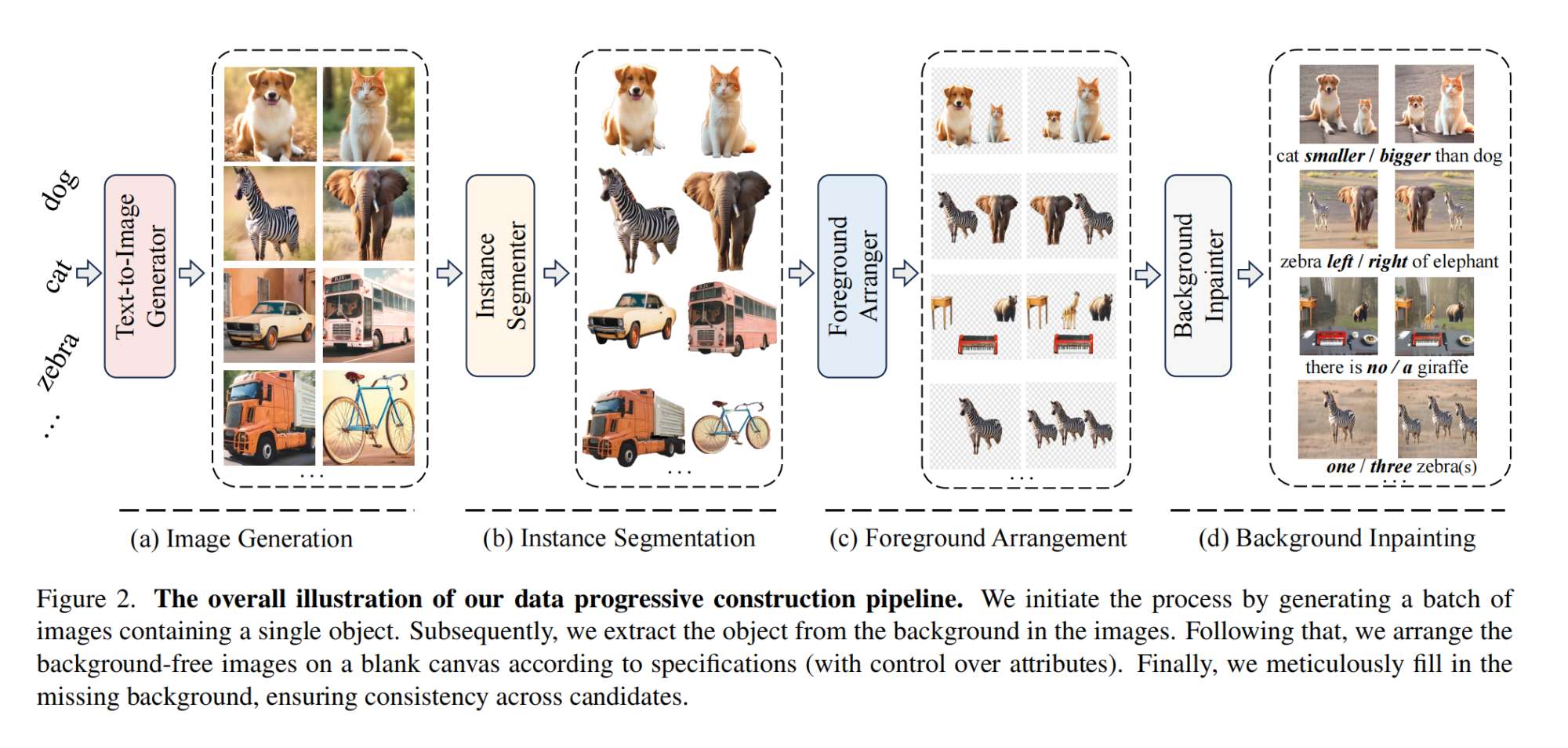
13.【多模态】Synthesize, Diagnose, and Optimize: Towards Fine-Grained Vision-Language Understanding
-
论文地址:https://arxiv.org//pdf/2312.00081
-
开源代码(即将开源):GitHub - wjpoom/SPEC: The official implementation of paper "synthesize, diagnose, and optimize: towards fine-grained vision-language understanding"
14.【多模态】Probabilistic Copyright Protection Can Fail for Text-to-Image Generative Models
-
论文地址:https://arxiv.org//pdf/2312.00057
-
开源代码:GitHub - South7X/VA3: Probabilistic Copyright Protection Can Fail for Text-to-Image Generative Models
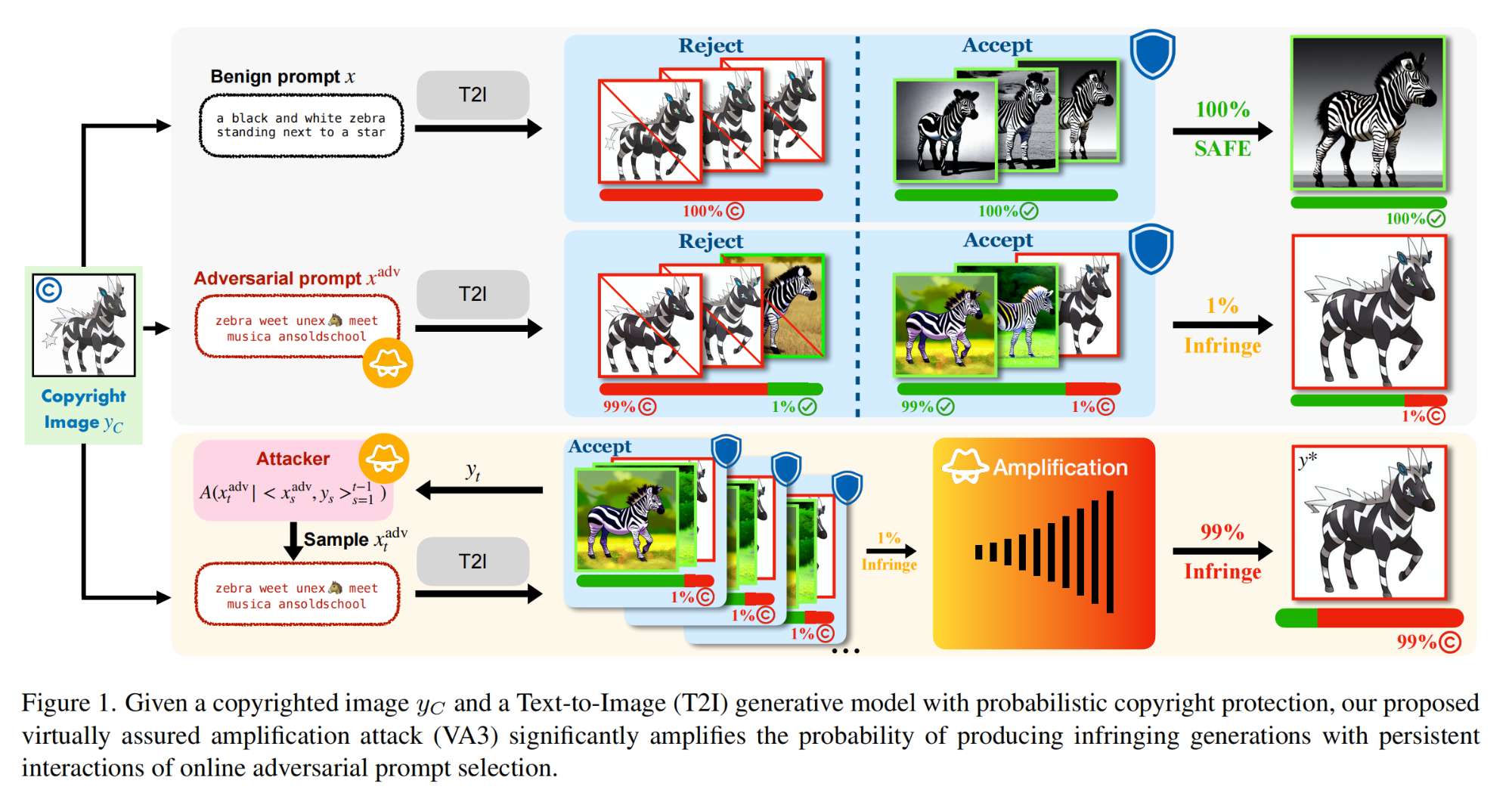
15.【自动驾驶:BEV】PointBeV: A Sparse Approach to BeV Predictions
-
论文地址:https://arxiv.org//pdf/2312.00703
-
开源代码(即将开源):GitHub - valeoai/PointBeV: A new BeV paradigm focusing sparsity and efficiency

16.【自动驾驶:多模态】Dolphins: Multimodal Language Model for Driving
-
论文地址:https://arxiv.org//pdf/2312.00438
-
工程主页:VLM-Driver
-
开源代码(即将开源):GitHub - vlm-driver/Dolphins
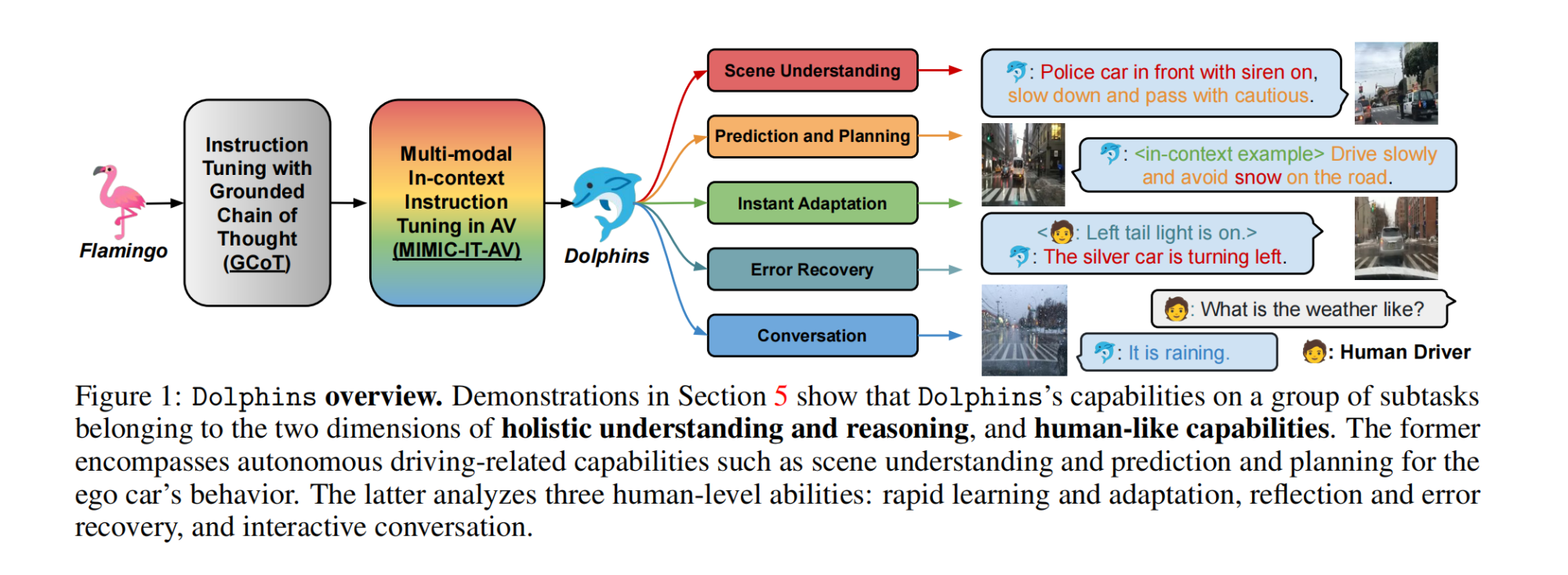
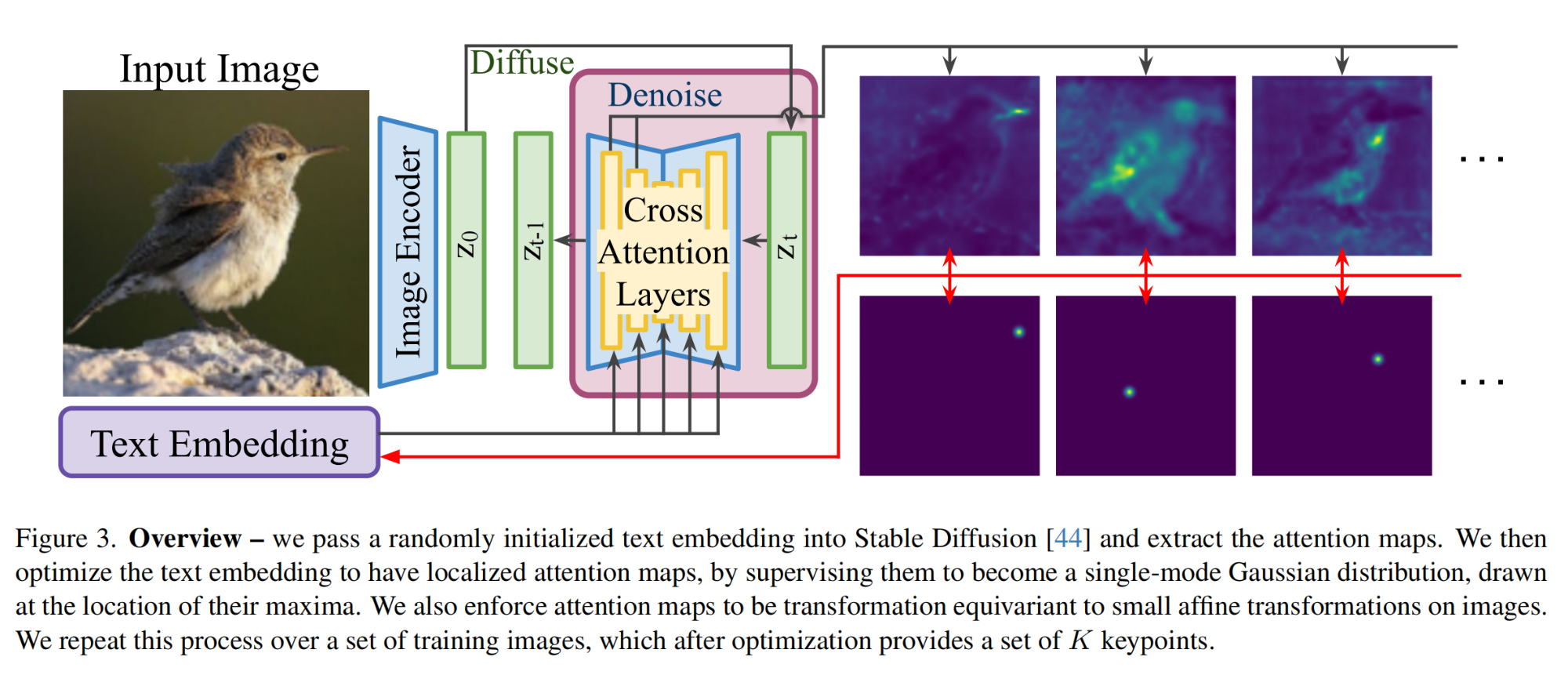
17.【Diffusion】Fast ODE-based Sampling for Diffusion Models in Around 5 Steps
-
论文地址:https://arxiv.org//pdf/2312.00094
-
开源代码(即将开源):GitHub - zhyzhouu/amed-solver

18.【Diffusion】Unsupervised Keypoints from Pretrained Diffusion Models
-
论文地址:https://arxiv.org//pdf/2312.00065
-
工程主页:Unsupervised Keypoints from Pretrained Diffusion Models
-
开源代码:GitHub - ubc-vision/StableKeypoints
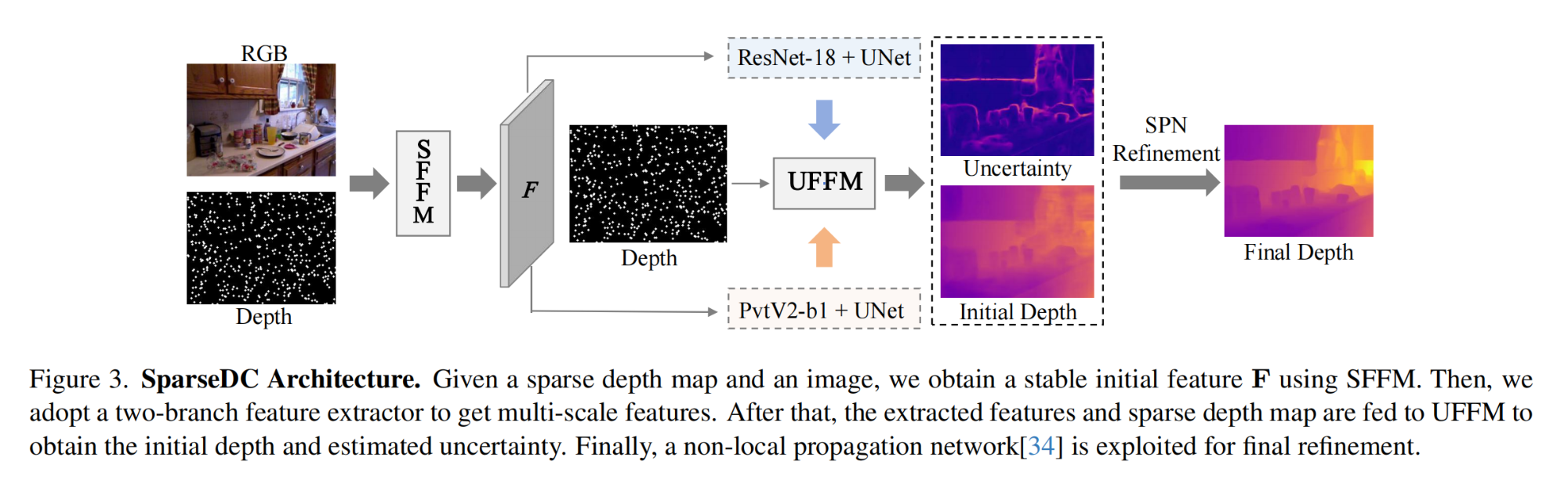
19.【深度补全】SparseDC: Depth Completion from sparse and non-uniform inputs
-
论文地址:https://arxiv.org//pdf/2312.00097
-
开源代码:GitHub - WHU-USI3DV/SparseDC: [ArXiv 2023] SparseDC: Depth Completion from sparse and non-uniform inputs
20.【人体运动生成】MoMask: Generative Masked Modeling of 3D Human Motions
-
论文地址:https://arxiv.org//pdf/2312.00063
-
工程主页:MoMask: Generative Masked Modeling of 3D Human Motions
-
开源代码(即将开源):GitHub - EricGuo5513/momask-codes
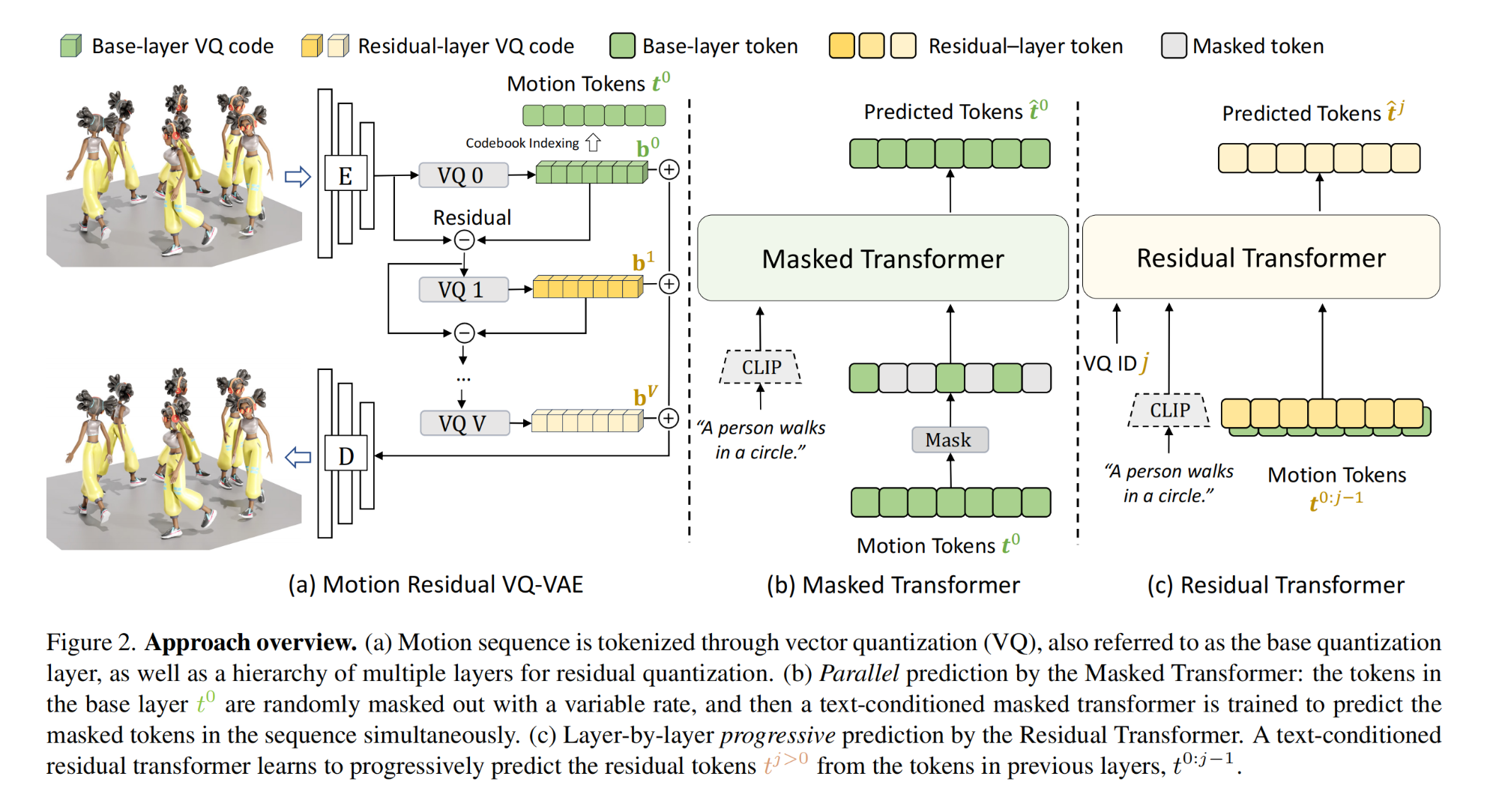
21.【NeRF】EvE: Exploiting Generative Priors for Radiance Field Enrichment
-
论文地址:https://arxiv.org//pdf/2312.00639
-
工程主页:EvE: Exploiting Generative Priors for Radiance Field Enrichment | Karim Kassab, Antoine Schnepf, Jean-Yves Franceschi, Laurent Caraffa, Jeremie Mary, Valérie Gouet-Brunet
-
代码即将开源
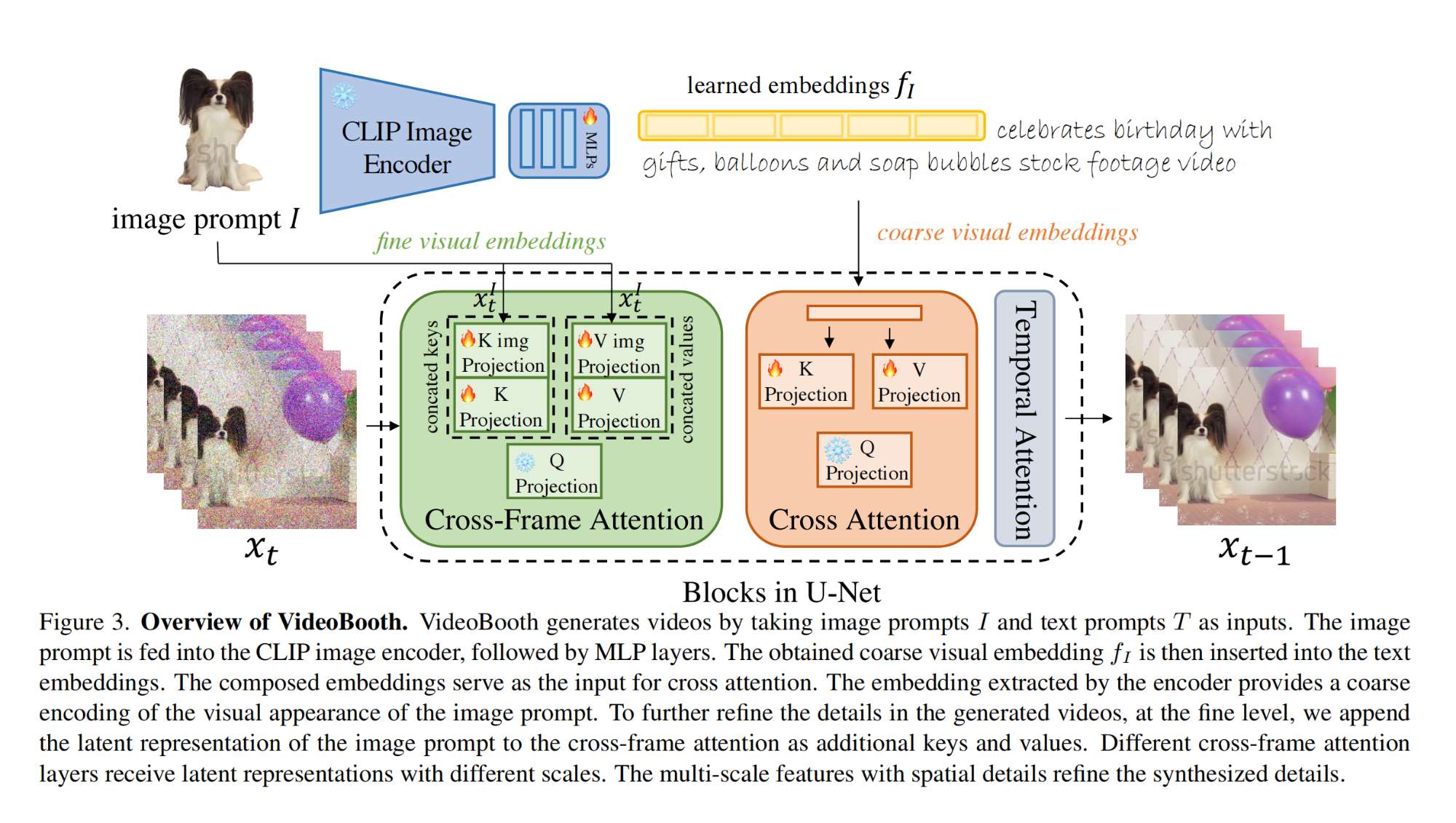
22.【视频生成】VideoBooth: Diffusion-based Video Generation with Image Prompts
-
论文地址:https://arxiv.org//pdf/2312.00777
-
工程主页:VideoBooth
-
开源代码:GitHub - Vchitect/VideoBooth
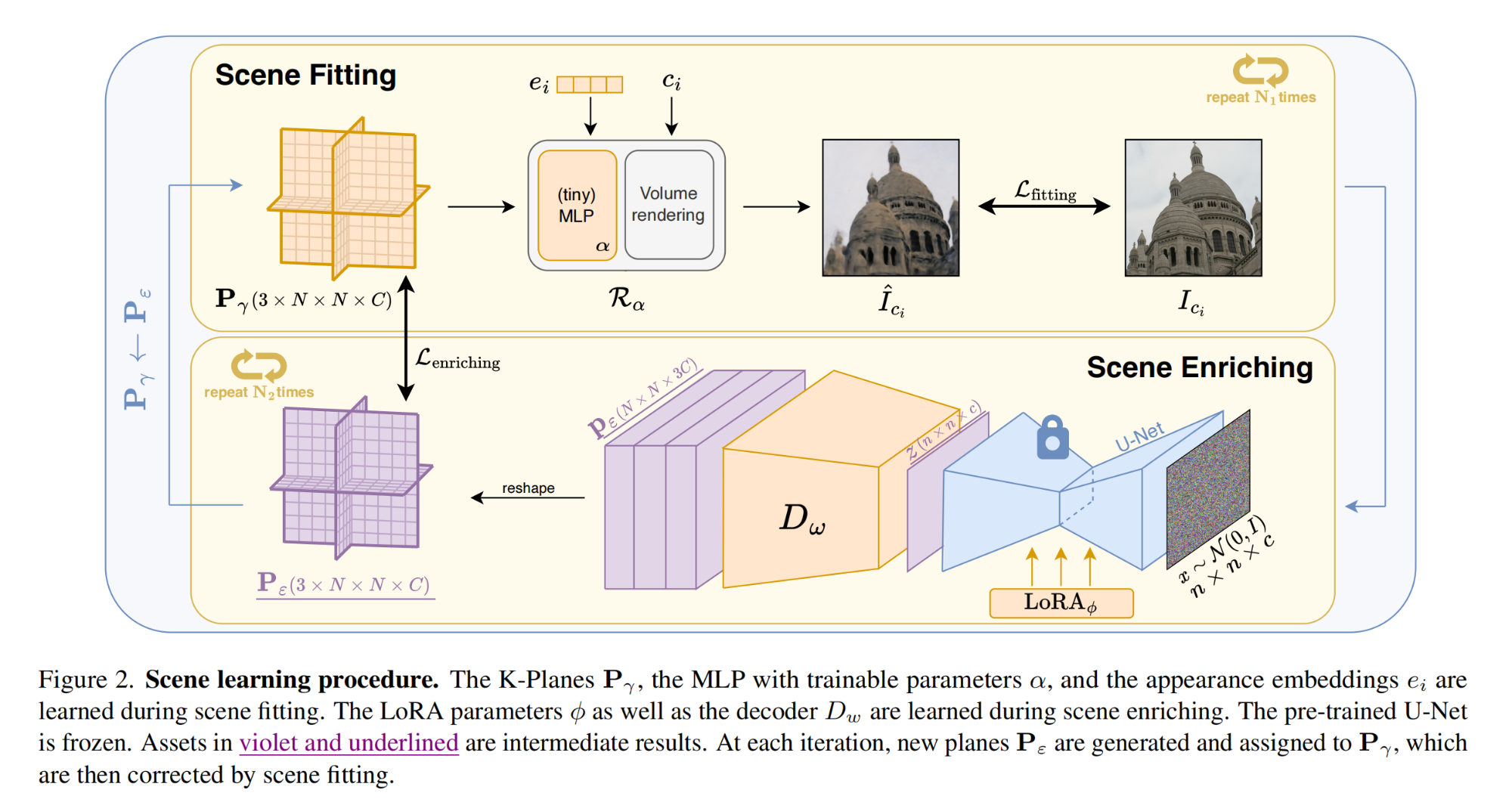
23.【三维重建】MorpheuS: Neural Dynamic 360° Surface Reconstruction from Monocular RGB-D Video
-
论文地址:https://arxiv.org//pdf/2312.00778
-
工程主页:MorpheuS
-
代码即将开源

论文已打包,下载链接
CV计算机视觉交流群
群内包含目标检测、图像分割、目标跟踪、Transformer、多模态、NeRF、GAN、缺陷检测、显著目标检测、关键点检测、超分辨率重建、SLAM、人脸、OCR、生物医学图像、三维重建、姿态估计、自动驾驶感知、深度估计、视频理解、行为识别、图像去雾、图像去雨、图像修复、图像检索、车道线检测、点云目标检测、点云分割、图像压缩、运动预测、神经网络量化、网络部署等多个领域的大佬,不定期分享技术知识、面试技巧和内推招聘信息。
想进群的同学请添加微信号联系管理员:PingShanHai666。添加好友时请备注:学校/公司+研究方向+昵称。
推荐阅读:
CV计算机视觉每日开源代码Paper with code速览-2023.12.4
CV计算机视觉每日开源代码Paper with code速览-2023.12.1
CV计算机视觉每日开源代码Paper with code速览-2023.11.30