1.配置一个模板机
要求:IP DNS地址页 网址 防火墙 安装包
1.ip
ifconfig 查询
先用虚拟机看一下自己的网关
vim search/provides 命令 查找
# 修改网络配置文件
vim /etc/sysconfig/network-scripts/ifcfg-ens33
如果提示找不到vim命令,使用yum下载vim
yum install vim 选择yesBOOTPROTO="static"
ONBOOT=yes
IPADDR="192.168.10.100"
PREFIX="24"
GATEWAY="192.168.10.2"
DNS1="192.168.10.2"systemctl restart network //重启网络看看是否设置成功
// static 静态 固定别名
hostnamectl --static set-hostname hadoop1002.网址
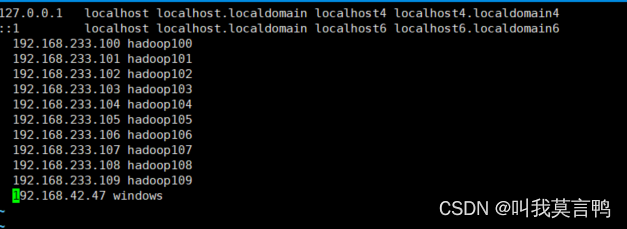
windows的hosts文件
位置:C:\Windows\System32\drivers\etc\hosts
Linux的hosts文件
vim /etc/hosts
这个根据网关设置
3.关闭防火墙
systemctl stop firewalld
systemctl disable firewalld.service
4.安装包
1.创建用户
先创建一个用户用于hadoop的使用(工作的时候没有root权限)
useradd atguigu
passwd atguigu
创建目录存安装包和程序,并赋予刚才创建的用户相应的权限
mkdir /opt/module // 存放程序
mkdir /opt/software // 存放安装包chown atguigu:atguigu /opt/module
chown atguigu:atguigu /opt/software
// 完了后ll查看一下看是否成功
2.卸载原装JDK
// 卸载原装JDK 如果虚拟机最小化安装可忽略
[root@hadoop100 ~]# rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
3. 传输安装包(XFTP)
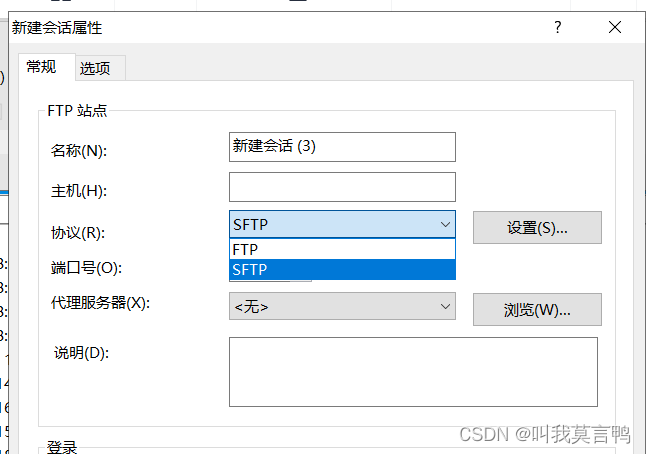
注意这里一定要使用SFTP
解压JDK
// z 通过gzip指令压缩/解压缩文件,文件名最好为*.tar.gz
// x 从归档文件中提取文件,解包.tar文件
// v 显示操作过程
// f 指定文件名
// 产生.tar打包文件
// 压缩gz 就是 zcvf 解压缩 zxvf
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
配置环境变量
// 进入自定义环境变量文件
sudo vim /etc/profile.d/my_env.sh//内容 和Window配置一样 ,JAVA_HOME PATH
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
重新加载环境变量
source /etc/profile
java -version
5.hadoop安装
1.解压
// 进入安装包目录
cd /opt/software/
// 解压
tar -zxvf hadoop-3.3.4.tar.gz -C /opt/module/
2.配置环境变量
// 进入文件
sudo vim /etc/profile.d/my_env.sh//配置环境变量
#HADOOP_HOME 注意这里配置了bin和sbin
export HADOOP_HOME=/opt/module/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin#退出 重新加载环境变量
source /etc/profile
bin:存放对Hadoop相关服务(hdfs,yarn,mapred)进行操作的脚本,这个好像看着不太常用
sbin:管理员常用的命令,对集群的一些管理操作(例如启动、重启、关闭)这样一些操作 集群的操作,比较常用
2.单个机器创建
当前模版机状态: Hadoop安装完成,
需要操作: 修改IP 主机名 根据要求配置Hadoop文件
修改IP和主机名 模版机第一步类似
1.关于hadoop的架构
1.整体架构
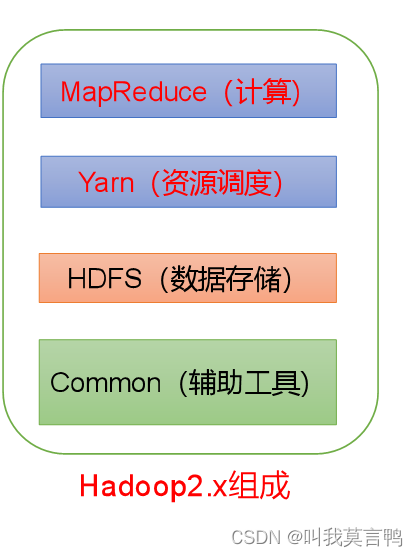
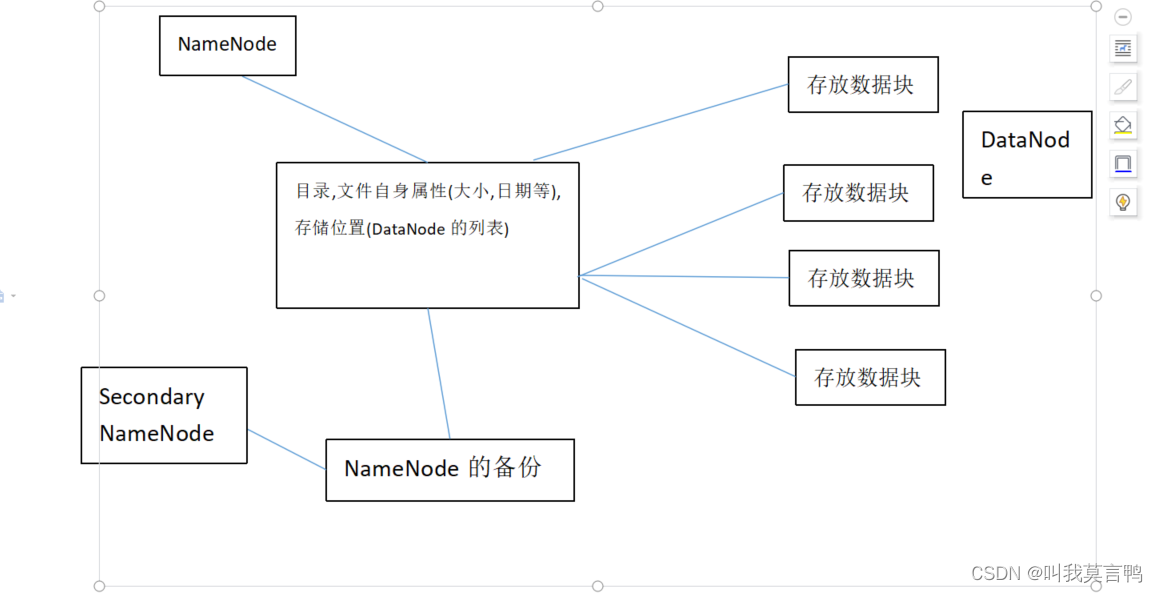
2.HDFS
分布式文件系统
主要结构3个:
- NameNode(NN) 目录,存储文件名,文件属性以及文件的块列表和Datanode
- DataNode(dn): 存储文件块数据和块数据的校验和
- Secondary NameNode(2nn) 每隔一段时间对NameNode元数据备份,所以他和NameNode不能在同一个机器上,不然就失去意义了
3.Yarn 资源调配
注意看,一个yarn只有一个RM(Resource Manager)负责整个的资源调配
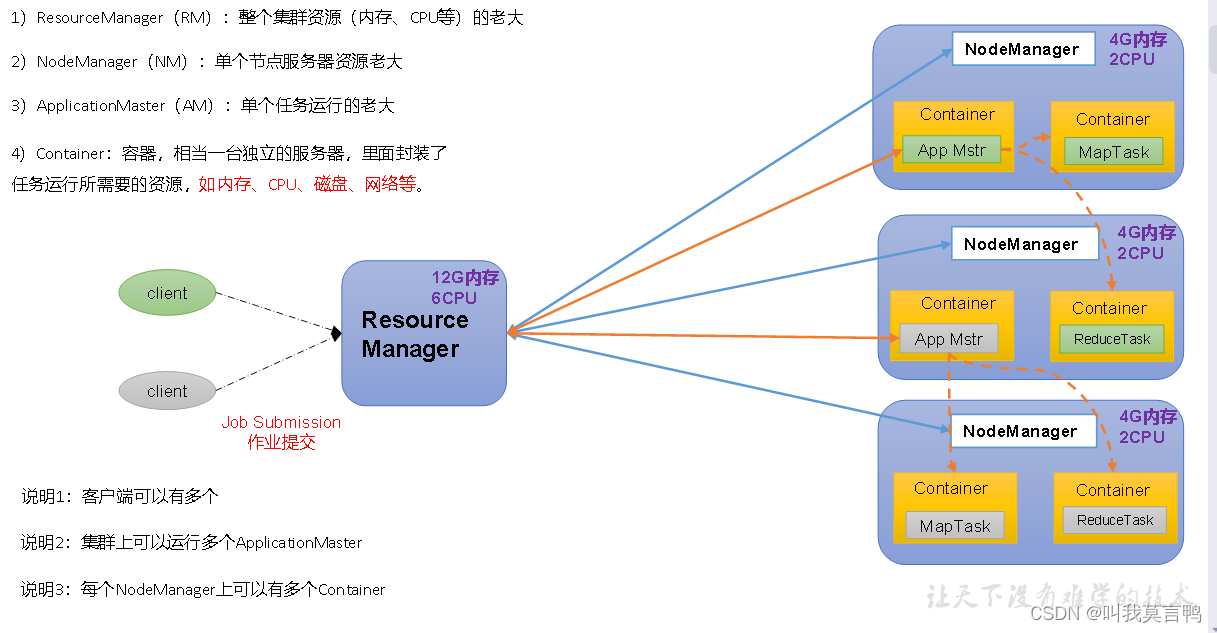
RM和NodeManager 是1对多的关系
4. MapReduce 计算 分与合
- Map阶段并行处理输入数据
- Reduce阶段对Map结果进行汇总
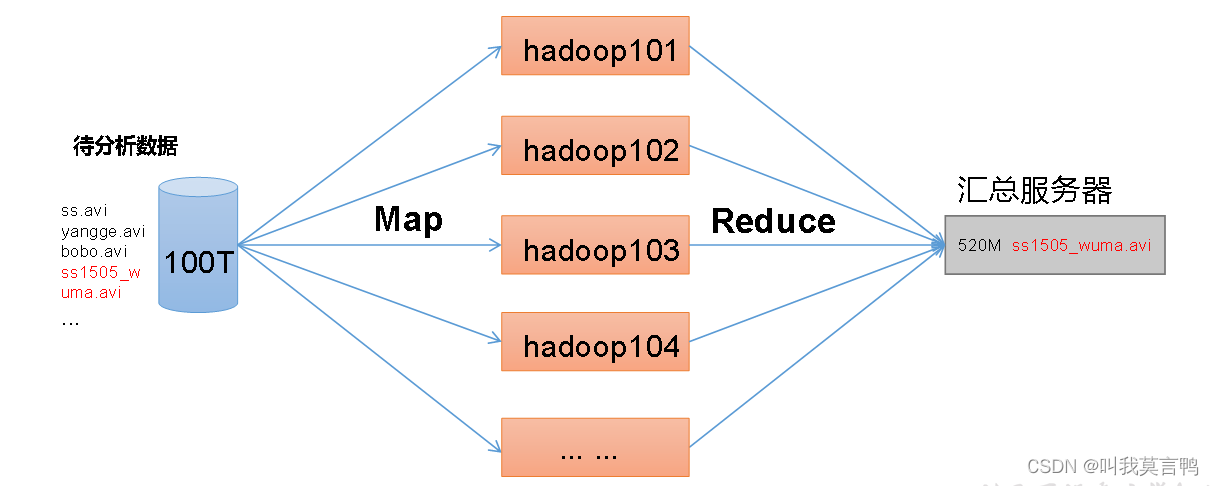
5.关系
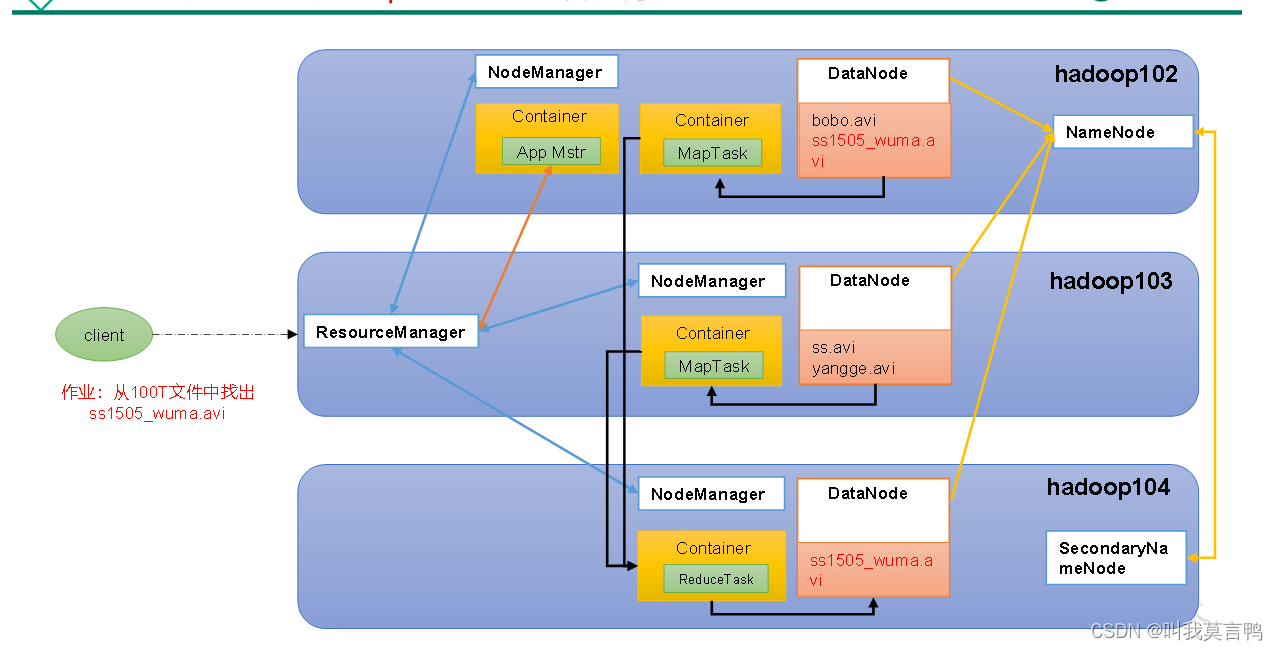
MapReduce 就相当于sql语句 和分析器啥的
HDFS 相当于只是存储的数据库
YARN 来分配资源去计算和存储
Commom 辅助
2.配置文件了解
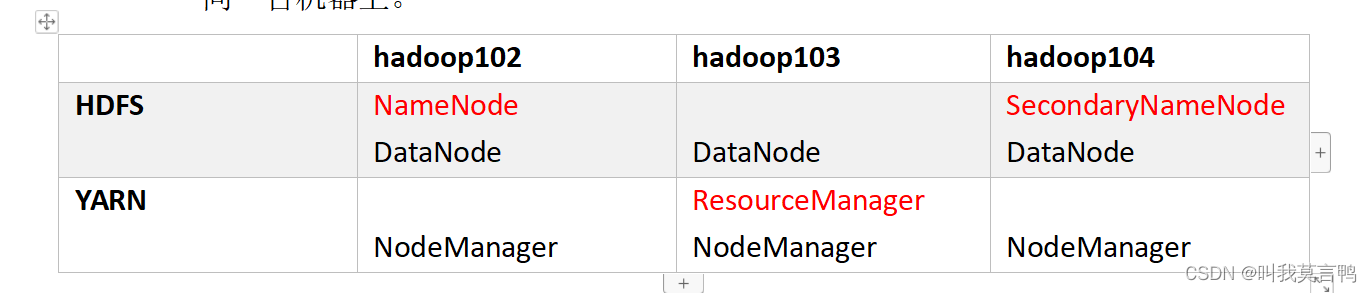
1.要求
- NameNode和SecondaryNameNode 不要同一台机器
- ResourceManager不要和 NameNode 同一台
2.模拟的结构
3.默认配置文件

3.配置文件的配置
1.核心配置core-site.xml
- NameNode的地址(HDFS的主机地址) 这个用于处理交互(后端),而HDFS中的用于处理页面请求服务,
- hadoop数据存储目录
- 使用静态网站的默认用户
<configuration><!-- 指定NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://hadoop102:8020</value></property><!-- 指定hadoop数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-3.3.4/data</value></property><!-- 配置HDFS网页登录使用的静态用户为atguigu --><property><name>hadoop.http.staticuser.user</name><value>atguigu</value></property>
</configuration>

2.HDFS配置文件hdfs-site.xml
vim hdfs-site.xml
- 配置NN和2NN的访问地址 处理web端服务的端口和地址,只是处理页面访问
<configuration><!-- nn web端访问地址--><property><name>dfs.namenode.http-address</name><value>hadoop102:9870</value></property><!-- 2nn web端访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>hadoop104:9868</value></property>
</configuration>
3.YARN配置文件yarn-site.xml
- 这里要注意一下,yarn里指定了MR的配置???
- 指定ResourceManager的地址
- 环境变量的继承
<!-- 指定MR走shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定ResourceManager的地址--><property><name>yarn.resourcemanager.hostname</name><value>hadoop103</value></property><!-- 环境变量的继承 --><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property>
4.MapReduce配置文件 mapred-site.xml
<!-- 指定MapReduce程序运行在Yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property>
5.配置workers
vim /opt/module/hadoop-3.3.4/etc/hadoop/workers
将集群机器加进去
hadoop102
hadoop103
hadoop104
5.总结一下
core配置Node后端供给端口,存储目录,还有默认用户
HDFS配置 页面服务端端口
Yarn 配置将MR走shuffle 指定自己的ResourceManager地址 并且继承环境变量
Map 指定在yarn上运行
3.集群开启关闭
1.格式化NameNode(第一次启动必须格式化)
格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止namenode和datanode进程,并且要删除所有机器的data和logs目录,然后再进行格式化
hdfs namenode -format
2.启动HDFS
sbin/start-dfs.sh
3.启动YARN 这个要在ResourceManager的节点
sbin/start-yarn.sh