目录
一、机器学习中的分类算法
1.1 基础分类算法
1.2 集成分类算法
1.3 其它分类算法:
二、各种机器学习分类算法的优缺点
分类算法也称为模式识别,是一种机器学习算法,其主要目的是从数据中发现规律并将数据分成不同的类别。分类算法通过对已知类别训练集的计算和分析,从中发现类别规则并预测新数据的类别。常见的分类算法包括决策树、朴素贝叶斯、逻辑回归、K-最近邻、支持向量机等。分类算法广泛应用于金融、医疗、电子商务等领域,以帮助人们更好地理解和利用数据。
本文介绍15种机器学习中的分类算法,并介绍相关的优缺点,在使用时可以根据优缺点选择合适的算法。
本文部分图文借鉴自《老饼讲解-机器学习》
一、机器学习中的分类算法
机器学习中常用的用于做分类的算法如下:
1.1 基础分类算法
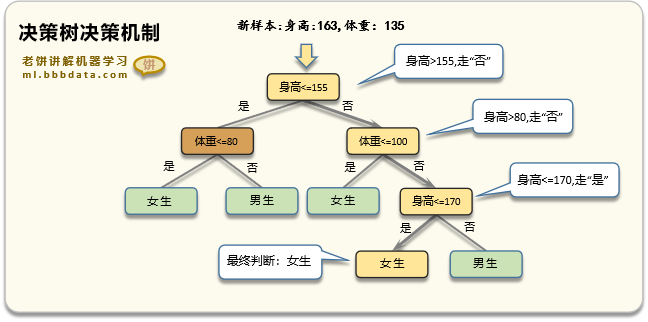
1.决策树:决策树算法通过将数据集划分为不同的子集来预测目标变量。它从根节点开始,根据某个特征对数据集进行划分,然后递归地生成更多的子节点,直到满足停止条件为止。决策树的每个内部节点表示一个特征属性上的判断条件,每个分支代表一个可能的属性值,每个叶节点表示一个分类结果。
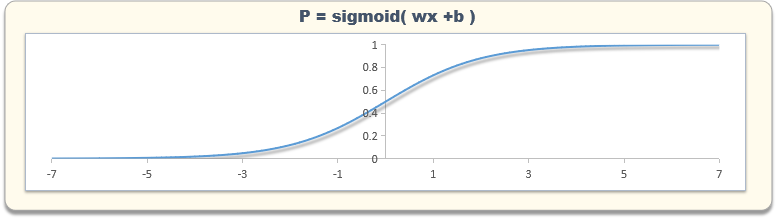
2.逻辑回归:逻辑回归算法是一种用于二元分类的算法,它通过使用逻辑函数将线性回归的结果映射到[0,1]范围内。逻辑回归模型将输入特征与输出类别之间的关系表示为线性回归函数,然后通过逻辑函数将线性回归的结果转换为一个概率值,用于预测目标变量。逻辑回归的优点是计算效率高,但在处理高维数据时可能会过拟合。
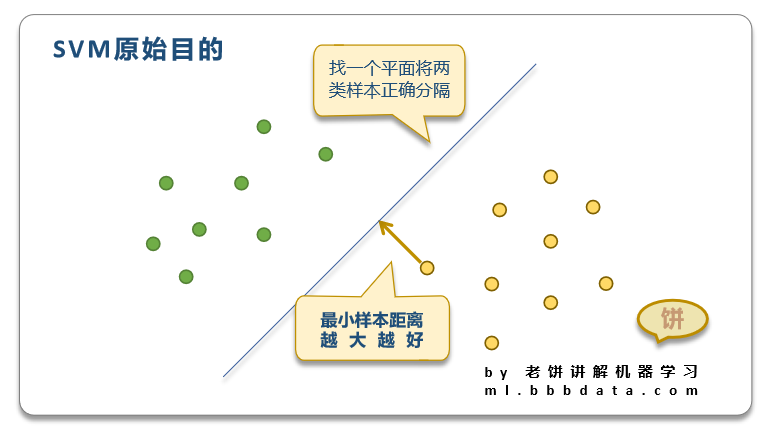
3.支持向量机(SVM):SVM算法通过找到一个超平面来划分不同的类别。它试图最大化两个类别之间的边界,这个边界被称为间隔。SVM的目标是找到一个能够将数据集中的点正确分类的超平面,同时最大化间隔。在二分类问题中,SVM通过求解一个二次优化问题来找到这个超平面。
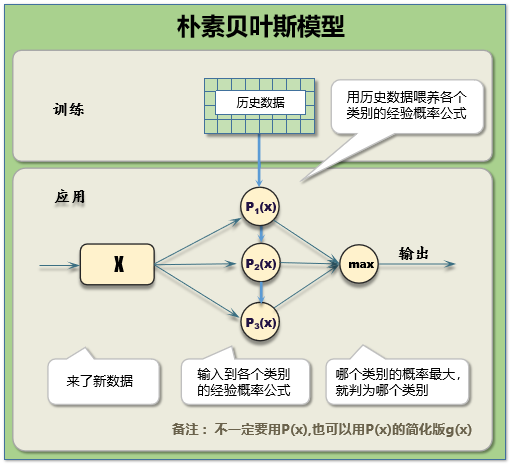
4.朴素贝叶斯:朴素贝叶斯算法是一种基于贝叶斯定理的分类算法,它通过计算每个类别的条件概率来预测目标变量。朴素贝叶斯算法假设每个特征之间是独立的,然后根据这个假设来计算类别的条件概率,并选择概率最大的类别作为预测结果。朴素贝叶斯的优点是在处理高维数据时效率高,并且对数据集的大小和分布不敏感。
5.K-最近邻(KNN):KNN算法是一种基于实例的学习算法,它根据数据集中的距离度量将新的实例分类到最近的类别中。KNN算法根据距离度量计算待分类项与数据集中每个项的距离,然后选取距离最近的K个项,根据这K个项的类别进行投票,将得票最多的类别作为待分类项的预测类别。KNN的优点是简单、易于理解和实现,但可能会受到数据集大小和维数的影响。
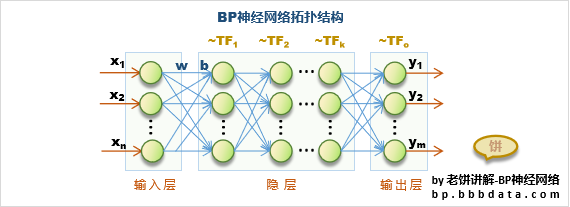
6.神经网络:神经网络是一种基于人工神经元的分类算法,它通过训练神经元之间的连接权重来预测目标变量。神经网络由多个神经元组成,每个神经元接收输入信号并产生输出信号,输出信号通过连接权重与下一个神经元的输入信号相乘得到新的输入信号,最终的输出信号由所有的神经元组成。神经网络的优点是在处理复杂和非线性问题时表现良好,但需要大量的数据和计算资源来训练模型。
7.贝叶斯网络:贝叶斯网络是一种基于概率论的分类算法,它通过建立条件独立关系来构建网络模型,并用于分类和概率推理。贝叶斯网络的优点是在处理不确定性和概率推理时表现良好。
8.线性判别分析(Linear Discriminant Analysis,LDA):线性判别分析是一种基于判别函数的分类算法,它通过构建一个线性判别函数来划分不同的类别。LDA的优点是在处理高维数据和多个类别时表现良好。
9.最大熵模型(Maximal Entropy Model):最大熵模型是一种基于概率论的分类算法,它通过最大化熵来构建模型,并用于分类和概率推理。最大熵模型的优点是在处理具有不确定性和噪声的数据时表现良好。
1.2 集成分类算法
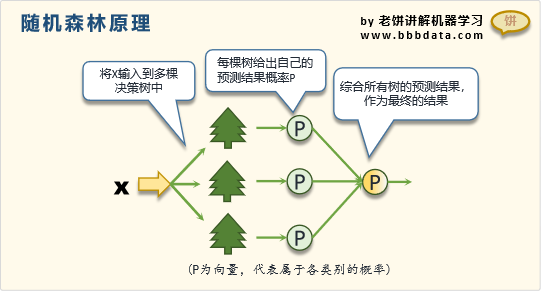
10.随机森林:随机森林算法基于决策树算法,通过构建多个决策树并组合它们的预测结果来提高分类精度。它通过随机选择样本和特征来生成多个决策树,然后以投票的方式将最多个数的结果作为最终分类结果。随机森林的优点是可以处理高维数据,并且对数据集的大小和分布不敏感。
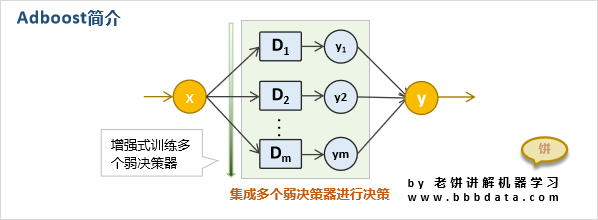
11.AdaBoost:AdaBoost是一种迭代算法,它通过将多个弱分类器的结果组合来预测目标变量。AdaBoost算法将数据集分成多个子集,然后针对每个子集训练一个弱分类器,并调整每个弱分类器的权重,使得分类错误的样本得到更大的权重,然后再次训练弱分类器。如此反复迭代,直到达到预设的迭代次数或者弱分类器的精度达到某个阈值为止。最终的预测结果由所有弱分类器的加权和决定。AdaBoost的优点是可以处理多类分类问题,并且对噪声和异常值不敏感。
12.梯度提升决策树(GBDT):GBDT算法是一种基于梯度提升的分类算法,它通过将多个决策树的结果组合来预测目标变量。GBDT算法通过不断地添加树、更新模型参数和优化目标函数来提高模型的精度。每棵树都是通过对样本特征空间进行划分、寻找最佳划分点来生成的。每棵树生成后,就对应一个残差函数,用当前所有树的残差和作为下一棵树的生成依据。如此反复迭代,直到达到预设的迭代次数或者满足其他停止条件为止。最终的预测结果由所有树的加权和决定。GBDT的优点是在处理复杂和非线性问题时表现良好,并且对数据集的大小和分布不敏感。
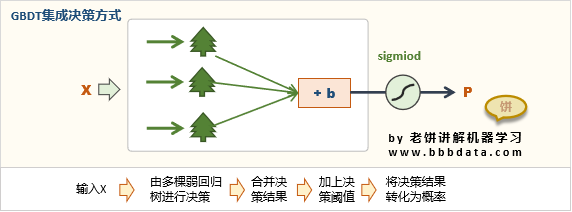
13.极端梯度提升(XGBoost):XGBoost算法是一种改进的梯度提升算法,它通过使用二阶导数信息来优化损失函数。XGBoost算法在生成每棵树时,不仅考虑了一阶导数信息,还考虑了二阶导数信息,从而能够更好地拟合数据集。此外,XGBoost算法还引入了一个正则化项来控制模型的
1.3 其它分类算法:
14.决策树桩(Decision Stump):决策树桩是一种简化版的决策树算法,它只在一个层级上进行划分,从而简化模型的复杂度。决策树桩的优点是在处理小型数据集和进行实时分类时效率高。
15.K-最近邻朴素贝叶斯(K-Nearest Neighbor Naive Bayes):K-最近邻朴素贝叶斯算法结合了K-最近邻和朴素贝叶斯的原理,它通过计算每个类别的最近邻数量来进行分类。K-最近邻朴素贝叶斯的优点是在处理大规模数据集和进行实时分类时效率高。
二、各种机器学习分类算法的优缺点
上述分类算法的优缺点如下:
决策树、随机森林和梯度提升决策树(GBDT):
这些算法都属于集成学习方法,通过将多个弱学习器组合起来提高预测精度。它们能够处理非线性问题,并且对数据量较大的数据集有较好的处理效果。但是,它们可能会过拟合训练数据,导致泛化能力下降。此外,它们也需要较大的计算资源和时间来进行训练。
支持向量机(SVM):
SVM是一种有坚实理论基础的新颖的小样本学习方法,它基本上不涉及概率测度及大数定律等,因此不同于现有的统计方法。SVM利用内积核函数代替向高维空间的非线性映射,能够处理高维数据,并且不用降维。但是,SVM对特征空间划分的最优超平面是未知的,因此需要人为设定一些参数。
逻辑回归:
逻辑回归是一种简单易懂的分类算法,计算速度快,适用于小数据集。但是,它假设数据服从线性分布,因此对非线性问题处理效果不佳。另外,逻辑回归对多重共线性数据较为敏感,可能导致模型不稳定。
K-最近邻(KNN):
KNN是一种简单且易于实现的分类算法,适用于小数据集和大规模数据集。但是,它对数据分布的敏感度较高,对于一些特殊的数据分布可能会导致较差的预测效果。
朴素贝叶斯:
朴素贝叶斯算法基于贝叶斯定理,对给定的问题能够提供概率形式的决策支持。它能够处理多类分类问题,并且对缺失数据和不完整数据的处理能力较强。然而,朴素贝叶斯算法假设特征之间相互独立,这在实际应用中往往难以满足。
神经网络:
神经网络具有较强的非线性拟合能力,可以处理复杂的模式识别和预测问题。它具有自学习、自组织和适应性等特点,可以处理大规模的数据集。但是,神经网络的训练过程较为复杂,需要大量的计算资源和时间。此外,神经网络的参数较多,需要仔细调整才能获得最佳的预测效果。
总的来说,不同的机器学习分类算法都有其优缺点,选择哪种算法取决于具体的应用场景和问题特点。在选择算法时,需要考虑数据的规模、特征的复杂性、模型的泛化能力、计算资源和时间等因素。
如果觉得本文有帮助,点个赞吧!