文章目录
- 1、priority_queue
- 1.1 priority_queue的介绍和使用
- 1.2 priority_queue的使用
- 模拟实现:
- 2、容器适配器
- 2.1 什么是适配器
- 2.2 STL标准库中stack和queue的底层结构
- 3、deque
- 3.1 deque的原理介绍
- 3.2 deque的缺陷
- 4、为什么选择deque作为stack和queue的底层默认容器
1、priority_queue
1.1 priority_queue的介绍和使用
priority_queue文档介绍

翻译:
1. 优先队列是一种容器适配器 ,根据严格的弱排序标准,它的第一个元素总是它所包含的元素中最大的。
2. 此上下文类似于堆,在堆中可以随时插入元素,并且只能检索最大堆元素(优先队列中位于顶部的元素)。
3. 优先队列被实现为容器适配器,容器适配器即将特定容器类封装作为其底层容器类,queue提供一组特定的成员函数来访问其元素。元素从特定容器的“尾部”弹出,其称为优先队列的顶部。
4. 底层容器可以是任何标准容器类模板,也可以是其他特定设计的容器类。容器应该可以通过随机访问迭代器访问,并支持以下操作:
empty():检测容器是否为空
size():返回容器中有效元素个数
front():返回容器中第一个元素的引用
push_back():在容器尾部插入元素
pop_back():删除容器尾部元素
5. 标准容器类vector和deque满足这些需求。默认情况下,如果没有为特定的priority_queue类实例化指定容器类,则使用 vector。
6. 需要支持随机访问迭代器,以便始终在内部保持堆结构。容器适配器通过在需要时自动调用算法函数make_heap、push_heap和pop_heap来自动完成此操作。
1.2 priority_queue的使用
优先级队列默认使用vector作为其底层存储数据的容器,在vector上又使用了堆算法将vector中元素构造成堆的结构,因此 priority_queue就是堆加粗样式, 所有需要用到堆的位置,都可以考虑使用priority_queue。注意: 默认情况下priority_queue是大堆。
| 函数声明 | 接口说明 |
|---|---|
| priority_queue()/priority_queue(first,last) | 构造一个空的优先级队列 |
| empty( ) | 检测优先级队列是否为空,是返回true,否则返回false |
| top( ) | 返回优先级队列中最大(最小元素),即堆顶元素 |
| push() | 在优先级队列中插入元素x |
| pop() | 删除优先级队列中最大(最小)元素,即堆顶元素 |
注意:
1、默认情况下,priority_queue是大堆。
#include <vector>
#include <queue>
#include <functional> // greater算法的头文件int main()
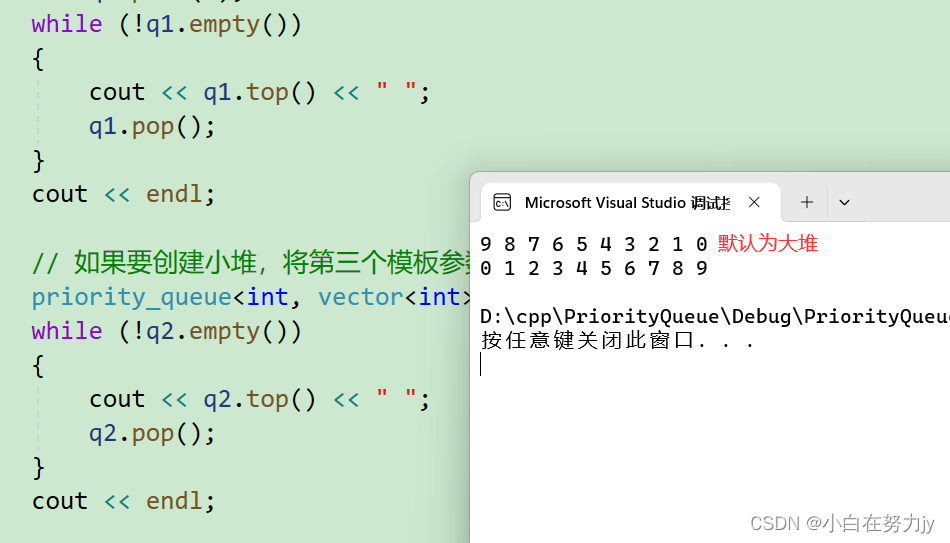
{// 默认情况下,创建的是大堆,其底层按照小于号比较vector<int> v{ 3,2,7,6,0,4,1,9,8,5 };priority_queue<int> q1;for (auto& e : v) q1.push(e);while (!q1.empty()){cout << q1.top() << " ";q1.pop();}cout << endl;// 如果要创建小堆,将第三个模板参数换成greater比较方式priority_queue<int, vector<int>, greater<int>> q2(v.begin(), v.end());while (!q2.empty()){cout << q2.top() << " ";q2.pop();}cout << endl;return 0;
}
2、如果在priority_queue中放自定义类型的数据,用户需要在自定义类型中提供 > 或者 < 的重载。
class Date
{
public:Date(int year = 1900, int month = 1, int day = 1): _year(year), _month(month), _day(day){}bool operator<(const Date& d)const{return (_year < d._year) ||(_year == d._year && _month < d._month) ||(_year == d._year && _month == d._month && _day < d._day);}bool operator>(const Date& d)const{return (_year > d._year) ||(_year == d._year && _month > d._month) ||(_year == d._year && _month == d._month && _day > d._day);}friend ostream& operator<<(ostream& _cout, const Date& d){_cout << d._year << "-" << d._month << "-" << d._day;return _cout;}
private:int _year;int _month;int _day;
};void TestPriorityQueue()
{// 大堆,需要用户在自定义类型中提供<的重载priority_queue<Date> q1;q1.push(Date(2018, 10, 29));q1.push(Date(2018, 10, 28));q1.push(Date(2018, 10, 30));cout << q1.top() << endl;// 如果要创建小堆,需要用户提供>的重载priority_queue<Date, vector<Date>, greater<Date>> q2;q2.push(Date(2018, 10, 29));q2.push(Date(2018, 10, 28));q2.push(Date(2018, 10, 30));cout << q2.top() << endl;
}int main()
{TestPriorityQueue();return 0;
}
模拟实现:
我们刚已经了解到,priority_queue就是堆,并且默认是大堆,底层容器封装的是vector,因此我们模拟实现priority_queue也是比较简单的。
#include<vector>
#include<functional>
using namespace std;namespace lcx
{// 仿函数template <class T>class Less{public:bool operator()(const T& x, const T& y){return x < y;}};template <class T>class Greater{public:bool operator()(const T& x, const T& y){return x > y;}};template <class T, class Container = vector<T>, class Compare = Greater<T>>class priority_queue{public:priority_queue(){}template <class InputIterator>priority_queue(InputIterator first, InputIterator last):_con(first, last){for (int i = (_con.size() - 1 - 1) / 2; i >= 0; i--){adjust_down(i);}}bool empty() const{return _con.empty();}size_t size() const{return _con.size();}const T& top() const{return _con[0];}void push(const T& x){_con.push_back(x);adjust_up(_con.size() - 1);}void pop(){swap(_con[0], _con[_con.size() - 1]);_con.pop_back();adjust_down(0);}private:void adjust_up(int child){int parent = (child - 1) / 2;while (child > 0){//if (_con[child] > _con[parent])if(comp(_con[child], _con[parent])){swap(_con[child], _con[parent]);child = parent;parent = (child - 1) / 2;}else break;}}void adjust_down(size_t parent){size_t child = parent * 2 + 1;while (child < _con.size()){//if (child + 1 < _con.size()// && _con[child + 1] > _con[child])if(child + 1 < _con.size()&& comp(_con[child + 1], _con[child])){child++;}//if (_con[child] > _con[parent])if (comp(_con[child], _con[parent])){swap(_con[child], _con[parent]);parent = child;child = parent * 2 + 1;}else break;}}private:Container _con;Compare comp;};
};
这里如果还有对堆不熟悉的同学我们可以看看我的另外一篇文章,专门讲解堆的:C语言实现堆详细版本
2、容器适配器
2.1 什么是适配器
适配器是一种设计模式(设计模式是一套被反复使用的、多数人知晓的、经过分类编目的、代码设计经验的总结),该种模式是将一个类的接口转换成客户希望的另外一个接口。
2.2 STL标准库中stack和queue的底层结构
虽然stack和queue中也可以存放元素,但在STL中并没有将其划分在容器的行列,而是将其称为容器适配器, 这是因为stack和队列只是对其他容器的接口进行了包装,STL中stack和queue默认使用deque,比如:



3、deque
3.1 deque的原理介绍
deque(双端队列):是一种双开口的"连续"空间的数据结构,双开口的含义是:可以在头尾两端进行插入和删除,且时间复杂度为O(1),与vector比较,头插效率高,不需要搬移元素;与list比较,空间利用率比较高。
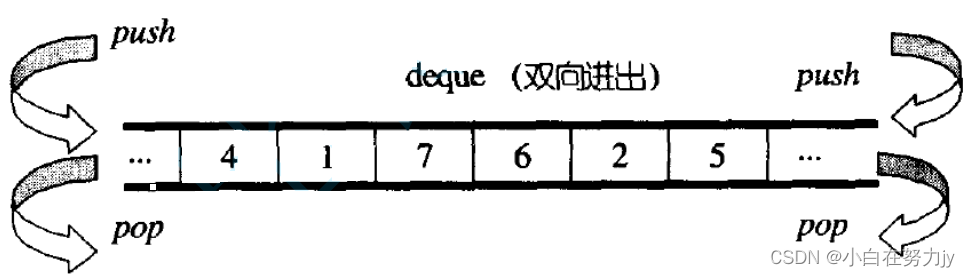
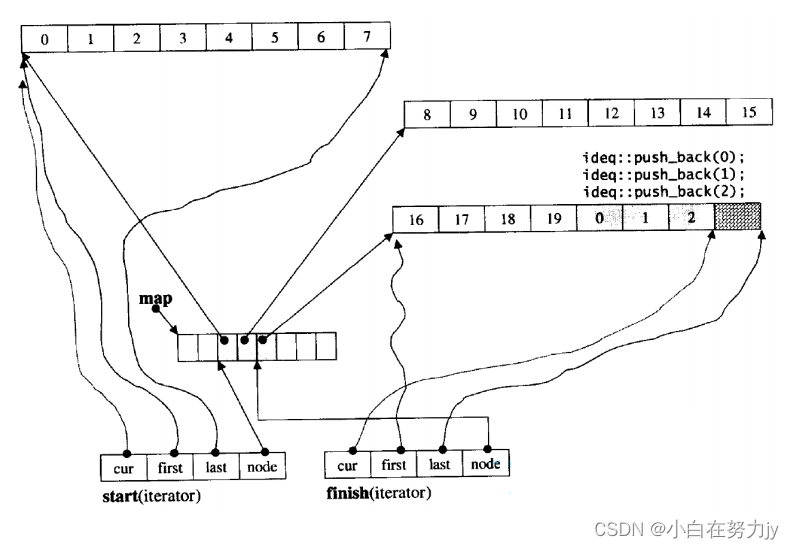
deque并不是真正连续的空间,而是由一段段连续的小空间拼接而成的,实际deque类似于一个动态的二维数组,其底层结构如下图所示:
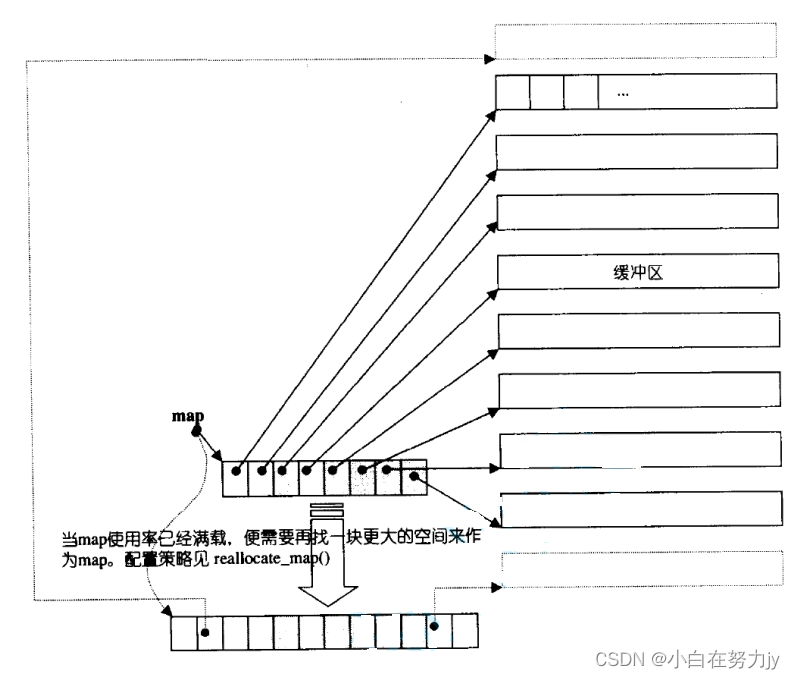
双端队列底层是一段假象的连续空间,实际是分段连续的,为了维护其“整体连续”以及随机访问的假象,落在了deque的迭代器身上,因此deque的迭代器设计就比较复杂,如下图所示:
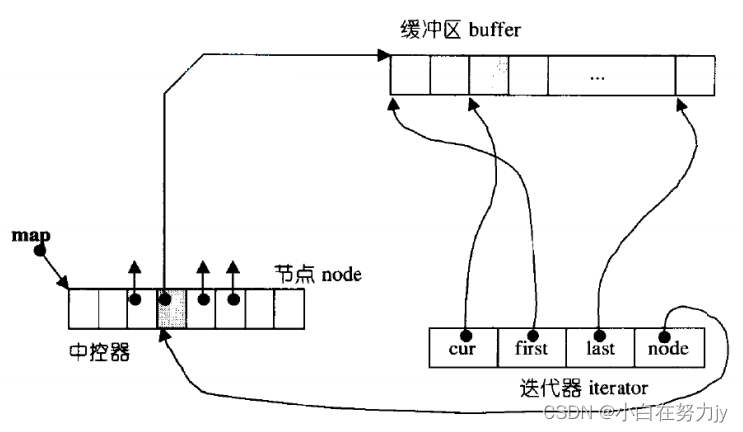
那deque是如何借助其迭代器维护其假想连续的结构呢?
3.2 deque的缺陷
与vector比较,deque的优势是:头部插入和删除时,**不需要搬移元素,效率特别高,而且在扩容时,也不需要搬移大量的元素,**因此其效率是必vector高的。
与list比较,其底层是连续空间,空间利用率比较高,不需要存储额外字段。
deque有一个致命缺陷:不适合遍历,因为在遍历时,deque的迭代器要频繁的去检测其是否移动到某段小空间的边界,导致效率低下。
而序列式场景中,可能需要经常遍历,因此在实际中,需要线性结构时,大多数情况下优先考虑vector和list,deque的应用并不多,而目前能看到的一个应用就是,STL用其作为stack和queue的底层数据结构。
4、为什么选择deque作为stack和queue的底层默认容器
stack是一种后进先出的特殊线性数据结构,因此只要具有push_back()和pop_back()操作的线性结构,都可以作为stack的底层容器,比如vector和list都可以;
queue是先进先出的特殊线性数据结构,只要具有push_back和pop_front操作的线性结构,都可以作为queue的底层容器,比如list。但是STL中对stack和queue默认选择deque作为其底层容器,主要是因为:
1. stack和queue不需要遍历(因此stack和queue没有迭代器),只需要在固定的一端或者两端进行操作。
2. 在stack中元素增长时,deque比vector的效率高(扩容时不需要搬移大量数据);queue中的元素增长时,deque不仅效率高,而且内存使用率高。
结合了deque的优点,而完美的避开了其缺陷。
![[陇剑杯 2021]日志分析](https://img-blog.csdnimg.cn/d6ff11ae73244e82b58624a6c1a9e324.png)


![[MySQL] SQL优化之性能分析](https://img-blog.csdnimg.cn/direct/3fbe5fe455e24a7fb4fd491ca3752b33.png)