文章目录
- C++入门
- 基本内容
- linux系统与基本命令
- 总体认知
- 基本内容
- 开发工具和git
- 基本内容
- 感言
- 一些感悟
C++入门
基本内容
小非是刚入职的员工, 在熟悉完git和vscode之后就开始了写代码 ,但是老张不放心,担心小飞写出屎山代码, 想要看看小飞的C++水平并且给小飞补补课。
今天天气格外的晴朗, 小飞哼着小曲在一遍看代码, 老张一瞧, 小伙子不错嘛, 看代码这么轻松, 走过去看看。
老张: 小伙子不错嘛, 看代码心情这么好。
小飞: 害, 很多我都看不懂,不过我心态好, 看不懂就先放着, 后面慢慢补。 怎么了, 老张,今天有空上课了?
老张: 被你看出来了, 哈哈, 教小徒弟我还是很愿意的。
小飞; 老张, 遇到你是我的缘~ 。
C++和如何成长的讨论
老张: 别扯了, 还不是担心你写出屎山代码。 接招: 我先问问你为什么选择C++, 这个语言和其他语言有啥区别?
小飞: 我能说我学不懂java么哈哈。 我当初选择C++也是因为这门语言用的比较多, 学了学java感觉那些框架太抽象了, 我不太懂底层原理, 就选择了一门学一个技能点容易知道底层原理的语言。 我主要分为6个点来说吧, 分别从适应领域、行业壁垒上来讲。
-
适应领域 : 因为C++在运行的时候是直接编译成二进制机器代码的, 虽然有些东西是要运行中决定, 例如函数的创建, 但是本身运行速度就很快, 不像java和python等语言需要额外一些工具帮你翻译成机器代码。 虽然python那些不用管理内存的语言开发速度很快, 但是内存垃圾回收容易导致突然变慢, 这在游戏等高性能领域是不被允许的, 你卡了别人不卡直接把你杀了, 电商搜索业务员你卡了或者慢了别人就换app搜了, 而下单业务等可以慢一点,因为已经决定好买了, 愿意花这点时间。 如果不那么在乎性能开销,那么 C++ 并不是最好的语言选择(Java、Go、Python 等正是填补了这些领域);或者软件规模不大、无需很多抽象手段来管理软件的复杂度,那么 C 语言就足够。但如果性能是软件的关键指标,同时又有越来越大的复杂度,那么 C++ 几乎是独一无二的选择。我们看到 C++ 这些年来的发展,都是紧扣 40 年前 Bjarne 为 C++ 设定的“生态位”与“核心精神”而开展的。
-
行业壁垒 : C++很难, 容易形成技术壁垒。 因为没有方便的库, 新手和很多浮躁的人不会进来, 而现在年轻人进来少, 因此值得学习。 C++ 语言本身一直在发展, 而且他有右值引用等等极其优化性能的设计, 不像python java等只有官方规定的规则, 不能极致优化。 C++的性能是go的5倍, 在并发、网络、模板等方面具有先天优势。 但是如果是界面开发或者客户端等不是高性能的地方, C++并不占优势。学到后期要去改源码, 裁剪源码, 形成自己的知识体系。 而且不同领域的C++开发认识的C++完全不一样, 写嵌入式的C++程序员对C++理解难以提升。 写视觉和音视频的话很多也都是c with class。 很多时候你会发现没有统一的库, 反而是好事, 将开发能力给了开发人员。 越是底层人员有占比能力的领域, 越不容易被资本收割, 例如嵌入式和互联网。
老张: 是的, 其实这方面认知我不好给你太多指点, 简单说一下, 你对C++ 适合领域认识上没问题的, C++就不适合做那些靠近日常业务的领域,这些领域不要求速度,完全可以用封装层级更高语言来做, 而且即使你用C++在这种领域做了, 性能也是不一定比java这些快的, 因为C++生态不太好,优秀的开源框架比较少更重要是公开度低, 你自己写的很多内容很可能人家其他语言是有公开而且经过迭代的 开源组件, 大部分普通程序员来达不到通过语言优势打败人家顶级程序员的, 同样的功能, 即使你会汇编来写, 可能能都不够人家用python写的, 因为你的水平不够。 因此对于一些中间件少,难以抽象, 业务复杂并且对实时性有要求的地方采用C++ ,其他领域你用C++也达不到人家用python写的性能, 这是人和时间的问题。一定要意识到C++是飞机, python 是电动车,你去10km的地方用C++并不合适, 你去10000km的地方用python 也不合适。 因此看你的业务是啥, 如果想赚块钱, 用C++是自讨苦吃, 那么多python开源框架不用, 自己手写, 等你写完别人都做了十几个了,而且性能还不如别人。 也就是说想赚块钱用python等, 但是想赚大钱得用C++ , 但是你看到的赚大钱的人很少, 大部分人都是靠赚小钱积累慢慢发财的。 在开汽车的需求上去开飞机大家只会觉得你是傻逼, 并不会觉得你屌, 连语言适合干啥都不懂。 此外学习C++其实也是基础, 就像你会中文,但是你个写代码的能去做中医嘛? 同样的道理你写后端服务C++的能去搞嵌入式C++么? 那么多领域知识就会把你卡住, 而且很多时候有些领域知识是随着迭代才能get到的, 书本上学不来的。
老张: 最近我还发现C++开发效率太低了。 看看c++那些string库是真的恶心,太难用了,还有json,做个字符修改的业务好麻烦,而python等都有高质量的生态库而且好安装,一般业务不都是普通逻辑加各种字符串处理么加各种接口调用,为啥不用呢?c++是搞复杂业务的,通过右值等特性优化,如果你的业务非常固定而且对耗时有要求,不会频繁改整体字符串那就c++了。大部分业务就是都是先实现满足人类业务逻辑的通用架构和基本业务,后面的人慢慢加if else逻辑代码。而且c++是编译成二进制运行,每次编译都要先解析所有依赖,非常麻烦,头文件包含要全部包进来,还要在编译期间解决所有的堆数据管理,还有模板和宏定义和代码优化解析等等,都要去做。java虽然也要做不少,但是相比较c++ 堆数据编译阶段不用去管理释放,没有宏定义,只包含使用的类申明,不用去编译优化。而python直接解释运行不编译,因此性能完全不一样。这样来看c++改都不好改,再加上官方生态不好,真的要放弃了。堆数据的等c++编译时直接搞成了相对地址,还要加入删除逻辑。而java等有虚拟机帮你创建,还有进程帮你释放内存。多爽,为啥要花时间在这么多编译时间上。。。时间不值钱么?天天搞环境。
老张: 那我问你, 在工作中我们如何学习呢?
小飞: 不知道。。。 就用到什么学什么?
老张: 这样肯定不行, 首先你一定要有自己的框架和不变的目标。 就像你玩游戏一样,一共40分钟时间, 基本上笑到最后的人都是那些一直坚持一个角色的人,就拿金铲铲来说,有些人是前期什么牌多玩什么, 但是这种是顶级玩家的玩法, 大部分玩家都是在各种整容尝试一遍之后坚持一套整容, 虽然前期牌不好,但是人家一直坚持, 能够度过游戏的几个低谷期。 相反, 新手如果叶公好龙, 很容易在每个整容的低谷期因为另外的牌好而换整容, 只看到当前的优势, 不想处理低谷期, 这种很容易在中后期跟不上别人的步伐, 你发现别人都在一步一步的脚印往最理想整容上走, 你这走了一半又去走另外的整容,等你整容成型别人早就成型了, 这时候就很容易被淘汰了。因此我希望你既然选择了学C++, 就坚持一下, 不要因为出来一个更好的语言就去换, 你可以去了解学习做借鉴,这是非常好的习惯, 但是要明白你的目标是为了C++的提升和沉淀, 不然你到了3-5年工作经验后, 发现别人都是一个语言的骨干, 自己在C++上骨干不起来, 在java上又没有人家作为主业的有经验, 就很容易像游戏一样被动出局, 或者在新手村一直打转。
小飞: 这个我之前还真没想过, 我自己的是比较喜欢写代码的, 之前是想什么都可以学一学, 但是老张你这番话点醒了, 重点是花大量时间去达到一个领域的大成, 而不是花很多时间选择到一个最好的领域 。 到了大成, 其实每个语言的差距是非常小的,做好自己的就行。
老张: 是的, 专注到一个点突破到极致到了后期随意发挥才这类游戏的玩法,关于如何专注到极致, 思维导图限制住目标, 小黄鸭讲解法提升理解能力, 不停的迭代让自己关注于挑战区, 培养能够突破时间和记忆的代码库, 多跟同行交流避免闭门造车,基本三年就可以达到一个很高的水平了。
小飞: 学到了, 小本本记上。 那老张我即使不看一个行业前景,也得有判断这个的能力吧, 你是怎么看一个领域比另外一个领域解决问题要更难的?
老张:一般来说服务器是比嵌入式好的。 因为计算机本身就在解决三种问题: 网络、存储、计算。例如嵌入式程序员基本不关心网络和存储,在计算上也是简单的业务计算。 在网络和存储过程中基本不考虑并发量和一致性 , 所以才说他的技术门槛底。 而后端C++程序员为啥高? 网络要解决延时等传输, 存储也要解决分布式问题, 计算可能简单一些,但是如果计算的领域是音视频或者ai, 那其实不简单。 因此明显门槛高一些。 当然这些都是说application的开发, 对于framework等专注只看你这个的价值, 不和其他领域做对比。你就按照这三个维度来看就行, 时间周期虽然会影响局部的判断, 但是长期还是看这三个指标。 但是要注意嵌入式对普通从业人员有壁垒帮助, 不过综合还是C++后端好一些。
老张: 好了,上面是宏观的, 接下来我们讲讲微宏观的内容, 也是辅助你更好的理解C++这门语言的。 我问你为什么学习C++感觉什么都做不了?
小飞: 我觉得主要是生态和抽象程度不高的问题, 像 Java、Python 这类语言,其自带的 SDK 提供了各种操作系统的功能。举个例子,C/C++ 语言本身不具备网络通信功能,必须使用操作系统提供的网络通信函数(#include<system/socket>如 Socket 系列函数);而对于 Java 来说,其 JDK 自带的 java.net 和 java.io 等包则提供了完整的网络通信功能。我在读书的时候常常听人说,QQ、360 安全卫士这类软件是用 C/C++ 开发的,但是当我学完整本 C/C++ 教材以后,仍然写不出来一个像样的窗口程序。
老张: 是的, 关于C++生态, 这是一个非常坑的问题,不过现在随着C++版本的提高, 很多操作系统的底层接口都被封装进来了, 例如线程, 互斥锁。 而且C++为了提升性能搞了一些模板,移动构造这些, 为了管理自己的堆, 提出了智能指针这些, 基本上你要是用现代的C++其实和其他语言差不多, 而且如果你注意用到一些模板和移动构造等技巧,比其他语言快是很正常的。因此生态上是慢慢上来了, 而且还有一些其他语言实现不了的性能提升语法。
小飞: 是的, 其实这东西关于就是自由和效率的问题, 想要自由就很难追求效率, 想要效率就很难更自由。 像java的web框架,我就觉得真的是为了效率搞了一大堆约束, 虽然这些用约束提升效率的思想长期来看你觉得是很有必要的, 但是前期来学习对于想自由和底层的人来说, 还是比较难受的。
老张: 不错, 对于java砍掉的C++一些内容,其实很多都是大型项目维护容易出问题的地方, 这些地方太影响效率了,不是必须要有的完全可以砍掉。 好了, 那我问你c和C++的区别是啥?
小飞: C对于模板、继承多态这些高级封装现实场景的功能不支持。
老张: 这点我觉得要补充一下, 其实我们说面向对象是思想,而不是语言, 如果你有面向对象去解决问题的思想, 就算是用汇编也能写出来面向对象的代码, 如果你没有的话, 用python这些纯面向对象的语言你都写的是面向过程代码。 因此C++只是提供了类这些关键字帮助你更好的实现面向对象的代码,实现面向对象的过程中有一种很重要的问题就是为了面向对象而面向对象了, 把类设置的过于复杂, 忽略了自身想要解决的问题是什么, 属于迷失在面向对象中,而忘记了要解决的问题是过程, 因此这二者要有平衡。
小飞: 明白了, 主要还是看人怎么看待问题, 把问题抽象成代码的过程。 老张, 为啥感觉C++相比较其他语言好难学呢?
老张: 我觉得主要有几个原因吧。
- 首先就是C++在优化上很难有尽头, 如果你不考虑性能的话,C++写起来挺爽的。不考虑性能就是说,少用右值引用和移动语义,少去优化你的构造函数,能不用const就别去用,少去思考STL的内在实现,vector一招鲜,别去思考里面的内存增长缩放,别去管reserve不reserve的,别去考虑各个模板内在实现的差异,别去管对象的内存数据分布,别去考虑cache miss不miss的问题,别去管inline不inline的问题,别去管万能引用,别去管完美转发,别去管鲁棒性,别去管萃取不萃取的问题,别去管placement new和new有啥区别的问题,别去管各种算法内在实现,一个find走天下,别去思考各种allocater实现有啥差异,别去思考深拷贝浅拷贝的问题,别去管哪些数据该放栈里面哪些数据该放堆里面的问题等等等等。如果你不考虑这些问题,写C++可以像写python那样,很爽。但是一旦你需要考虑上面这些问题,需要考虑怎样写出优秀的,高效的,鲁棒性强的代码,任何一个小的点可能都需要费很大的功夫。所以事实上C++难就难在它可以提供很多种方案来达成我们的目的,但一百个人的实现可能有一百零一种方法,而这里面可能就一两种方法会比较好,其它的方法就是拿起石头砸自己脚。所以写C++很容易,写好却很困难。
- 此外C++本身还是函数式编程语言, 不仅仅是面向对象, 不像python这些纯面向对象。 尤其是函数式编程的模板元, 还有为了性能优化的宏定义, 真的是非常大大增加了代码的阅读难度, 本来函数式编程就很难, 你的代码中要是用了这些东西去提升性能, 很容易让新手看不懂。 因此前期不要碰模板和宏定义。
小飞: 老张, 那意思是我现在写代码用面向对象先写最基本的实现,然后考虑C++的特性去优化, 少用模板和宏定义么?
老张: 是的, 先做起来, 后面再优化哈。这些高级用法也只有你先用低级实现, 优化一遍之后你用的才熟练。 不然生搬硬套很容易照猫画虎出问题。
C++底层知识
老张: 前面你也提到了, C++是一门底层语言, 要自己考虑堆, 那么学习C++肯定要知道一些底层的知识, 那么我先问一下你,C++程序从编译到运行的流程是什么样的? 在运行中存在哪些优化的点?
小飞: 程序从编译到运行的流程挺复杂的。
-
编译 :代码写完之后, 我们开始进行程序的编译;(感悟, 所有语言转换成可执行文件之后, 都是指令和数据了, 所以可以跨语言调用。)
预处理(预处理如 #include、#define 等预编译指令的展开与解析, 生成 .i 或 .ii 文件)编译(编译器进行词法分析、语法分析、语义分析、中间代码生成、目标代码生成、优化,生成 .s 文件) -
汇编(汇编器把汇编码翻译成机器码,生成 .o 文件)。
-
链接( 这个过程第一阶段符号表解析 是把各个.o 文件的elf中同样段进行合并, 所有的符号表中und的变量都要在这过程中查找在哪, 解析成功之后给所有的符号分配虚拟地址。 , 最后生成 .out 文件 (注意这些过程根据objdump 查看elf文件) elf文件会包括了所有的信息。 可执行文件.out和.o大部分都相同, 但是可执行文件还有一个program 告诉系统哪些内容加载到内存中。 一般只加载代码段和数据段。
-
加载: 操作系统在装载应用程序时,主要分为三步:
4.1. 为进程分配虚拟内存(逻辑内存),一个进程是4G, 分为txt , data ,bss(存储为0或者未初始化的全局变量) , heap, shared stack(从上往下增加的, 要删除一个必须把下面的都删除了, 因此没有内存碎片) kernel 。 动态库和mmap会加载到headp到stack之间。 -
2 建立虚拟内存与可执行文件的映射(在内核态的页表, 以4K大小为单位,将虚拟内存地址与可执行文件的偏移建立映射关系。形成一个虚拟地址到物理地址的页表,注意这里不是寻址的页表)
4.3. 将CPU的指令寄存器设置为应用程序的入口地址(入口地址在elf文件中),启动运行。
- 开始运行 :在完成3步后,程序开始执行。CPU在脉冲的操作下, 将程序指令地址读到PC指令寄存器,然后如果需要数据, cpu把数据通过地址总线读到存储寄存器中, 然后运算单元对数据进行处理, 处理完成继续程序指令寄存器。
6: 运行过程中堆栈调用过程:
栈在内存中是连续的一块空间(向低地址扩展)最大容量是系统预定好的,堆在内存中的空间(向高地址扩展)是不连续的。堆在内存中呈现的方式类似于链表(记录空闲地址空间的链表)。栈里面不仅有压栈出栈的函数调用, 还能分配局部变量。 这里面能讲解很深的~, 一定要注意。堆栈调用非常关键,深刻理解很有用。 这里面我简单说一下石磊老师课程里面的代码, 局部变量不产生地址, 直接根据栈的偏移量计算的。 直接是一个move指令。 调用函数中$ { $ 会存储之前栈的地址,开辟sum函数的栈空间, 保存之前栈的下一步汇编地址。 然后 执行函数的指令, 最后将存储return结果的形参变量内容交给一个寄存器。 右括号负责将这个调用栈回退(pop 得到之前的栈底的地址, 赋值给当前的栈底esp, 并将call function 的下一行指令直接给pc寄存器执行,(一般在这就回退到真正的main函数栈顶), 然后将存返回值的寄存器内容给main栈中的ret , 并开始从main栈顶继续执行。 在这过程中可能会反复发生调度算法切换,但是没事,不影响正常的程序调用。
7 : 运行过程中虚拟内存如何工作
当我们代码中访问到具体的数据时候,而不是只是申请虚拟内存的时候, 就会发生页表的实际分配。 接下来就让我们看看这里是怎么切换的。
内存管理单元(MMU)管理着虚拟地址空间和物理内存的转换,操作系统为每一个进程维护了一个从虚拟地址到物理地址的映射关系的数据结构,叫页表,存储着程序地址空间到物理内存空间的映射表。页表寻址中可以通过查询页表中的状态位来确定所要访问的页面是否存在于内存中。每当所要访问的页面不在内存时(缓存不命中),会产生一次缺页异常加中断,此时操作系统会根据页表中的外存地址在外存中找到所缺的一页,将其调入内存。如果执行出错那么就直接退出了。在mmu上查找虚拟地址的物理地址时候,如果内存满了等会做缺页置换算法。例如LRU, 总之可以不用做实际的转换, 直接将物理地址返回给cpu。
如果需要实际访问的话第一次没有缓存而且标志位为空的话会产生缺页异常,如果映射整体是三级表 , 就是经历(1)逻辑地址转线性地址, 这样我们拿到了32位的地址, 然后拆分10 ,10 ,12 大小分别找页表,页, 物理地址。还要注意缺页异常是前提, 随后触发中断, 去真正的将外存放到内存中,说明已经做了一次实际映射,这种就不是malloc , 而是实际的访问了。
8 : cpu的调度算法
每个进程的PCB都是存在所有进程共享的内核空间中,操作系统管理进程,也就是在内核空间中管理的,在内核空间中通过链表管理所有进程的PCB,如果有一个进程要被创建,实际上多分配了这么一个4G的虚拟内存,并在共享的内核空间中的双向链表中加入了自己的PCB。PCB(Process Control Block)进程控制块,描述进程的基本信息和运行状态。
还要注意, 在多道程序而且多用户的情况下,组织多个作业或任务时,就要解决处理器的进程调度。 如果CPU调度算法生效了, 需要进行程序寄存器上下文的保存, 之后再去调度其他的进程。常见的方法有先来先服务法等。
9: 优化性能
最后在整个阶段我们需要考虑几个优化方面的问题 :(1)内存碎片的避免, (2)如何进行优化核态和用户态, 库函数在这个过程中做了什么?
关于内存碎片的避免就是采用每天定时启动, 此外还有malloc底层使用了内存池。采用不同的链表绑定不同需求, 如果请求的大小在链表中满足直接返回, 不满足再去重新开辟。
第二个内核态是发生在一些文件读写或者事件响应中的, 内核态拥有最高权限,可以访问所有系统指令;用户态则只能访问一部分指令。一些对硬件操作或者重要的指令只有内核态才能访问到。例如:当读取文件等(read,write),需要进入内核态。 进入的方式就是软中断和硬件中断。 中断是当前程序需要暂停当前的任务去做的事情, 为了区分不同的中断,每个设备有自己的中断号。系统有0-255一共256个中断。系统有一张中断向量表,用于存放256个中断的中断服务程序入口地址。每个入口地址对应一段代码,即中断服务程序。 一般需要保存现场(当前的执行位置和当前状态到两个寄存器上), 模式切换, 找中断表中的函数, 执行函数, 返回恢复状态。
那么内核态和用户态的交互太多是非常影响性能的, 一般我们使用read, mmap.sendfile去调用内核, 但是不同的方法效率不一样,1. 调用read函数读取文件, 需要进入内核态再返回用户态。这里面拷贝过程比较多。2上面那个步骤可以使用mmap去避免一次拷贝。 kafka使用了这个机制做消息持久化, 它开辟了一个磁盘的mmap , 数据直接从用户态映射到磁盘。
3. 0用户态拷贝 是通过sendfile实现的, 就是说内核直接打开这个底层磁盘, 将数据直接通过内核态发送给客户端。
第三个库函数问题: 其实一些库函数在应用层添加了缓存区, 使用库函数调用可以大大减少系统调用的次数, 这个和系统的内核态还不一样。
老张: 真的没看出来, 基础很扎实嘛。 前面你说的就是g++编译连接库文件、头文件、 本地cpp文件的过程,后面你说了一些堆的优化和内核态的考虑非常不错。 那你知道堆上的数据一般怎么分配么?
小飞: 这个一般就是new和malloc分配的, 一般都是有底层内存池来管理的,避免内存碎片产生, 不是每次请求都要执行一次系统中断去调用的。 brk、sbrk、mmap都属于系统调用,若每次申请内存,都调用这三个,那么每次都会产生系统调用,影响性能;其次,这样申请的内存容易产生碎片,因为他不像栈,释放之前前面的必须释放,没有内存碎片。
所以malloc采用的是内存池(ptmalloc)来减少使用堆内存引起的内存碎片,也就是自己一次申请一块足够大的空间,然后自己来管理,用于大量频繁地new/delete操作。每次配置一大块内存,并维护对应的16个空闲链表,大小从8字节到128字节。如果有小额内存被释放,则回收到空闲链表中。
(1)如果有相同大小的内存需求,则直接从空闲链表中查找对应大小的子链表。
(2)如果在自由链表中查找不到或者空间不够,则向内存池进行申请。
老张: 不错, 内存碎片是发生在代码长时间运行的时候, 由于堆里面很多节点被小内存的数据结构占领了, 如果当你要分配比较大的数据结构,这时候很容易找不到足够大的连续空间, 从而一直服务失败, 这是非常难受的, 所有语言都有这个问题, 一般C++是用一些开源的内存池, 例如google的tmalloc去分配, 他的分配原理是非常复杂的, 这种组件基本不是个人实现的, 你自己造别人根本不敢用。
老张: 说道这里, 你晓得java的gc是什么意思么?为什么java不容易内存泄漏
小飞: 这个我知道, 这些语言堆上数据基本上都是自动释放的, 例如他会定期扫描你有没有不用的堆内存,然后给你释放掉, 但是C++如果用普通指针就不会, 因为它不知道其他的地方用到这个堆数据没, 因此需要手动释放。 但是gc运行的时间是不能固定的, 如果刚好你的程序在处理关键的业务, 但是gc要进行大量的不用堆数据释放, 就会占用cpu过多, 导致你的业务突然变卡, 这在游戏和搜索行业是绝对不容发生的, 因为这种业务场景, 用户不会容忍卡0.1s的 。
老张 : 不错, 是这样的。 不过gc里面的内容很复杂, 你这也是高度概括了一下。 好了, 看来你的基本功其实还是可以的。 那我们就开始说一下基本语法吧, 你先说说C++都有哪些基本语法?
小飞: 我理解基本语法就是数据类型, 循环控制, 函数这些。 比如下面的这个代码。
// main.cpp
#include <iostream>#include "calc.h"
using namespace std;int main(int args, char** argc) {double a = 0.2;int aa = 0;double b = 2.2;double c = sum(a, b);double d = multi(a, b);double e = multi(a);double f = multi(aa);cout << "c : " << c << endl;cout << "d : " << d << endl;cout << "e : " << e << endl;cout << "f : " << f << endl;for (int i = 0; i < 10; ++i) {cout << "i:" << i << endl;}
}
\end{lstlisting}
// calc.h#pragma once#include <vector>
using namespace std;double sum(double a, double b);double multi(double a, double b = 2.2);double multi(int a, double b = 2.2);double multi(vector<int>& a, vector<int>& b);// calc.cppdouble sum(double a, double b) { return a + b; }double multi(double a, double b) { return a + b; }double multi(int aa, double b) { return aa + b; }
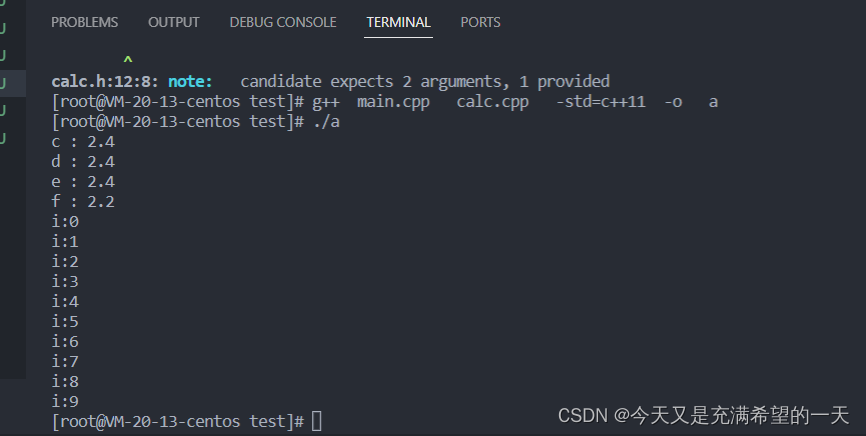
别看这部分的代码很少, 只是实现了基本的数值运算,但是能讲很多东西。
头文件:
1.1 我们使用了pragma once 保证头文件只被编译一次, 这在大型项目中非常有用, 因为头文件本身是存放函数和类的申明的, 别的代码需要用的时候需要包含进来,但是如果你自身写的代码又被别人使用了, 但是别人也用了calc做其实的事情, 不知道你已经包含了头文件,又include一次, 就会导致头文件被重复放进来。 如果在大型项目中, 日志模块的头文件会被经常包含到自己的代码中, 因为每个模块都需要使用日志, 如果不加pragma once 会导致头文件被包含很多次,至少20次以上吧。而如果你加了这个onece, 即使你包含了很多次, 也就用一次。
1.2 头文件一般不包含具体的定义, 只包含申明,因为如果是包含了定义的话别人能看到你的具体实现, 很多不开源的项目对外只提供头文件和自己的so,a文件, 如果让你看到了内部怎么实现, 万一被你抄了怎么办? 所以除了一些很简单的函数会直接在头文件上写出来具体实现, 或者一些日志库等简单并且开源库,直接给hpp文件让你包含了之后就能用,给你减少需要连接so库的麻烦,一般都不要在头文件中写出定义。
1.3 头文件中如果传入的参数是vector需要包含std命名空间和vector的声明头文件#include , 不要担心重复引用, 因为这种标准库一般都有prama once 。
1.4 头文件“”与<>的区别:用户定义和系统定义
1.5 头文件和库的关系:简单来说:库文件通过头文件向外导出接口。用户通过头文件函数声明找到库文件中函数定义。 编译成库之后.cc文件就没什么用处了。 一般我们直接提供头文件。让用户知道我们有什么代码的定义。
1.6 宏与using、typedef、const的区别 : 宏定义一般没有语法检查, 很多时候如果宏定义函数都是用在日志模块中, 类似于inline的作用, 直接在用到直接展开,do while(0)宏属于高级用法。 对于常量,我们现在都用const, 宏一般都是日志函数。
1.7 对于复杂的类需要用到其他类, 需要讲其他类的头文件包含进来, 而且如果两个类强耦合是可以写到一起的, 写到一个头文件中。
1.8 你的具体实现cpp文件中也要包含你的头文件声明, 不然它不知道你定义的是啥。
1.9 其他的内容例如: 条件编译, *extern “C” , 就先不展开了。
基本语法:
1.1 基础变量: 一般就是int, float, double这些, 如果你没有负数的场景加unsigned 。 此外注意long类型由于硬件的原因, 一般不让用, 需要你自己制定好自己的int是多少位的。 字符串的话注意string相比较char是多了一个 \ \backslash \n 的。而且你要知道数据都是存在哪里了, 你的int 这些局部变量是存在你的函数栈里面, 而你的int a = 2中的2 是存储在程序的静态区, 是你的栈中定义了int大小的位置存储了这个2所在的位置。 关于指针和引用一般都是在类中用到, 这里我就先不说了。 注意一个变量定义了记得初始化, 默认初始化习惯不太好, 让别人还以为你只是申明。
1.2 循环和if else :
1.2.1 这是基本的流程控制语句, 没啥好说的。 需要注意的就是i++和++i的区别, ++i在多线程中安全但是i++是不安全的, 因为该语句执行过程如下,先把i 的值取出来放到栈顶,可以理解为引入了一个第三方变量k,此时,k. 从上面的分析可知,i = i + 1语句的执行过程有多个操作组成,不是原子操作,因此不是线程安全的, 如果有人中途修改了i, 那么你的 =操作结果就会变, 而且i++多创建了一个临时变量性能消耗也比++i大。
1.2.2 需要注意continue和break的区别, 一般最好别在里面用吧我觉得, 因为会让你训练逻辑更复杂一点。
1.2.3 注意else的就近原则, 这也是一个坑, 很多时候如果写了两层if else, 一定要弄好递进关系, 不然很有可能顶层的else就近到了上一层。
1.3 函数:
1.3.1 函数方面这里我写的比较简单, 需要注意的点也是有一些。 例如如果你的函数内本身的代码和逻辑很少, 低于10行。 例如我这个calc中的计算, 完全可以搞成inline, 它会直接在你调用的地方展开,毕竟直接执行指令相比较换个调用栈执行的耗时更低, 当然即使你写了inline具体展不展开要看编辑器和你给的优化等级。
1.3.2 对于重载函数,可以根据你不同的输入进入到不同的重载函数中。 不过这部分其实可以用模板来代替,直接写成一个, 但是我的功底还没到使用模板来开发项目, 后续达到这个能力再补充。这部分在C++类中还会有重载操作符。
1.3.3 函数的默认值可以让你省略一些参数, 但是要注意右对齐。 很多python的类成员函数对于最右边的true flase传入参数都是有默认参数的,你即使忘记了也不影响使用,默认给的常规操作参数, 但是如果你想特殊化可以自己去显性的修改。 还要注意默认值在申明的时候一定要加上, 定义的时候可以不用加。
老张: 嗯, 大部分部分其实都比较简单, 但是其中宏定义一点都不简单,很多宏定义用法真的是非常恶心人, 这点我们到开源组件中再介绍。
老张: 我看你并没有讲一些const关键字,指针引用, 右值引用, this指针, 初始化列表,using, 命名空间 不知道你怎么考虑的。
小飞: 这部分我觉得大部分都是结合类来用的, 一般的变量其实都是栈上的, 没必要引用或者搞个指针, 常量很多都是宏定义。
老张: 是的, 一般这些特性都是在类中使用的, 你介绍一下吧。
小飞: 还是先看代码吧。
// main.cpp
#include <iostream>#include "calc.h"
using namespace std;int main(int args, char** argc) {// double a = 0.2;// int aa = 0;// double b = 2.2;// double c = sum(a, b);// double d = multi(a, b);// double e = multi(a);// double f = multi(aa);// cout << "c : " << c << endl;// cout << "d : " << d << endl;// cout << "e : " << e << endl;// cout << "f : " << f << endl;// for (int i = 0; i < 10; ++i) {// cout << "i:" << i << endl;// };vector<int> res{1, 23, 43, 54, 5, 46, 5, 34, 3};Calc b(res, 0);cout << "b :" << b.m_res[0] << endl;cout << b.m_res[0] << endl;int a = 111;int* p = new int(22);int* q = new int(23);Calc c(p, 0, 0);Calc d(q, 0, 1);cout << res[0] << endl;cout << "ponter:" << (*(c.m_res_pointer)) << endl;*p = 3;*q = 3;cout << "c ponter:" << (*(c.m_res_pointer)) << endl;cout << "d ponter:" << (*(d.m_res_pointer)) << endl;delete p;delete q;// 右值引用vector<int> res_two = {3232, 43, 5, 4, 5, 34, 3};Calc f(std::move(res_two), 0);Calc g(vector<int>(3, 1), 0);cout << "f :" << f.m_res[0] << endl;
}
// calc.h#pragma once#include <vector>
using namespace std;// double sum(double a, double b);// double multi(double a, double b = 2.2);// double multi(int a, double b = 2.2);double multi(vector<int>& a, vector<int>& b);class Calc {public:static int global_cnt;Calc(const vector<int>& res, int cnt);Calc(int* res, int cnt, bool depth);Calc(vector<int>&& res, int cnt);~Calc();double sum(const double& a, const double& b);double sum(vector<double>& a, vector<double>& b);static int get_global_cnt() { return global_cnt; }int get_self_cnt() { return this->m_self_cnt; }vector<int> m_res;int* m_res_pointer;private:int m_self_cnt;int m_depth;
};// calc.cpp#include "calc.h"#include <iostream>
#include <vector>using namespace std;// Calc::Calc(const vector<int>& res, int cnt) {
// m_res = res;
// m_self_cnt = cnt;
// cout << "init & ok " << endl;
// }int Calc::global_cnt = 0;
Calc::Calc(vector<int>&& res, int cnt) {cout << "into &&" << endl;// 这里面又做了移动拷贝构造, 将res内容地址全部给m_res.m_res = res;m_self_cnt = cnt;
}
Calc::~Calc() {if (m_depth) {m_res_pointer = nullptr;} else {;}
}
Calc::Calc(const vector<int>& res, int cnt) : m_self_cnt(cnt) {m_res = res;global_cnt = global_cnt + 1;cout << "init & ok " << endl;
}Calc::Calc(int* res, int cnt, bool depth) : m_self_cnt(cnt) {m_depth = depth;if (m_depth) {m_res_pointer = new int(*res);} else {m_res_pointer = res;}global_cnt = global_cnt + 1;cout << "init * ok " << endl;
}double Calc::sum(const double& a, const double& b) {global_cnt = global_cnt + 1;m_self_cnt++;return a + b;cout << "sum double ok " << endl;
}double Calc::sum(vector<double>& a, vector<double>& b) {global_cnt = global_cnt + 1;m_self_cnt++;double answer = 0.0;for (auto& ch : a) {answer = answer + ch;}for (auto& ch : b) {answer = answer + ch;}return answer;cout << "sum vector ok " << endl;
}
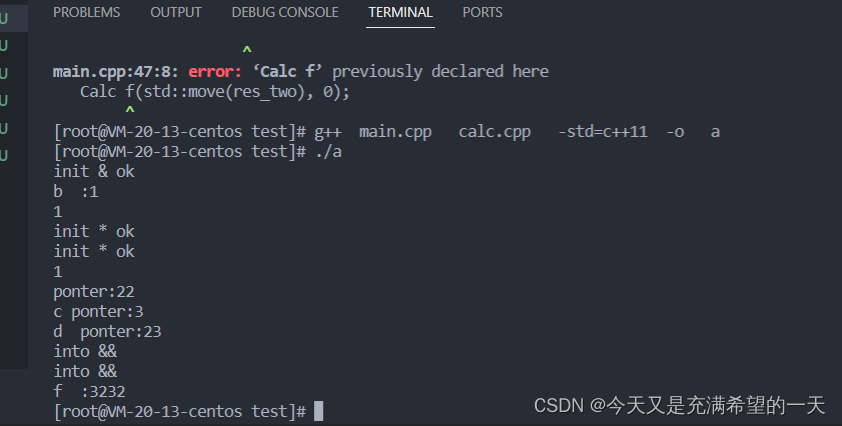
这部分需要讲解的东西非常多, 先说一下上面的代码实现的是什么: 调用了一个计算类, 类中有移动构造、构造函数、深拷贝浅拷贝、静态变量、局部成员变量, 静态成员函数、堆new。 我们依据上面的代码一一介绍里面的知识点。
- 类相比较函数的区别 : 我们可以看到相比较函数而言, 类中能做的东西有很多。过去我们想要实现一个功能, 必须把所有的变量都传入过去, 但是有些变量其实不需要我们自己传, 例如一些通用的变量, 完全可以放到类中, 然后我们只传入必须的参数, 这就大大的减轻了开发人员的工作量。 你可能会说这减轻了吗? 其实如果长远来看, 虽然构建一个类比一个函数要花的时候更多, 考虑的更多, 但是对于一个常用的功能, 封装成类之后, 你后面需要考虑的问题就会少很多。 用空间换时间的思想。
- const用法:
-
一般const是用在函数参数上的,一般如果你函数内部不修改传入的参数, 也不赋值给别人(如果你给一个非const变量了, 那你不就能改了, const就没意义了), 就加上const, 为了安全也为了给别人一个提示, 你不会改里面的内容。
-
const对象可以调用该方法,因为this指针为const,只能赋值给const接收方。 普通对象可以调用所有的, 因为不是const赋值, 所以没界限。
-
const和define区别
C++编译器在通常情况下不为const常量分配空间,而是将其值存放在符号表内.但当使用extern修饰常量或者类型强转这些时,则必须立即为此常量分配空间。 也就是本地的话就是define,但是有安全检查。 但是C中这就是个常量。推荐用const。 -
const存储地址例如const char *p3 = “123456”; 123456\0在常量区,p3在栈上。 其实就代表 "123456"是个常量而不是define , p3指向了这个常量, 所以不能修改。
- 指针和引用的区别
-
引用和指针的汇编代码是一样的。引用也是开辟了一个地址存储指针指向的地址。只不过不给用户暴露,够安全,而且一般不能更改。指针可以有多级,但是引用只能一级。(是否能为多级)引用必须初始化, 指针可以设置成野指针, 但是不提倡。 引用是更安全的指针,。引用变换内容值和指针解引用变换内容值的汇编指令是一模一样的,只不过我们看不见。 对指针赋值p = 30需要 , 但是当引用变量b = 30 时候其底层帮我们自动调用* , 而且也开辟了一个地址存储指针指向的地址。
-
. 引用绑定唯一变量,中途不用再担心被意外修改指向,变量被销毁,引用也跟着销毁。因此能用引用就都用引用。
- 右值、右值引用, move和forward是啥
代码中我们用右值构造接收了临时变量, 然后用了右值拷贝构造基本0消耗的接收了传入参数的内容。本质上右值引用和左值引用没啥区别, 就是可以使用移动构造和拷贝等。 而左值与右值的根本区别在于是否允许取地址&运算符获得对应的内存地址。右值引用是底层开辟空间去保存右值, 这样也可以对右值进行修改。 创建一个引用指针内存指向这个右值地方。 其实和左值差不多, 但是他可以使用移动构造等, 可以做到资源的转移。
-
. 右值没名字(临时变量),没内存(类似对象这种数据在寄存器中)一般没办法直接修改, 只有添加右值引用这种安全指针才能去修改。 右值引用变量本身是一个左值。右值引用可以引用并修改右值,通常情况下,修改一个临时值是没有意义的。一般是定义移动拷贝移动构造等来接收右值(临时变量),在里面将资源转换为自己的。(一般是move,如果是涉及指针的话自己去手动改)
-
. 右值引用int &&p =3的汇编和const int * p = 3 是一样的。其实分析起来发现原因是一样的。这样我们可把右值理解成const的数据, 右值引用是将一个安全的指针指向这个数据。
- . 注意&& 也可能是左值, 主要看你怎么用, 一般你搞成&& 代表你这里面的资源可能要转给别人了, 后面最好别再用了。
-
. move是通过static强转成右值引用,这样可以在他赋值给其他对象的时候,右值拷贝或者构造直接拿到这个右值引用指向的资源。 forward是转发本身的性质。 一般在模板实例化参数推导时候会用到。 由于目标函数可能需要能够既接受左值引用,又接受右值引用,所以考虑转发也需要兼容这两种类型。
- static
-. 代码中我们用static变量统计了全局calc类的计算次数, 你创建的多个对象每次调用都会+1。 因为 static 变量存放在静态存储区,所以它具备持久性和通信的作用。static 修饰的变量和函数属于类,而不是对象
- 注意static成员函数里面没有this指针, 只用static数据。
- 深拷贝和浅拷贝
-
深拷贝浅拷贝只存在于指针资源, 对于引用的资源释放就全释放了。 但是对于传入的指针, 如果你只是让自己的成员指针指向它, 如果外部释放了, 你就用不了, 这时候你还拿自己指针存的地址去访问就会coredump。 一般现代C++11都是智能指针, 不用担心这个释放问题, cnt为0 了自然释放。
-
有指针的话(也就是有外部资源,堆)浅拷贝析构时候会报错。 深拷贝的时候如果拷贝的是成员数据不占用外部资源,也可以理解不是带有外部资源的对象, 直接memcopy就会造成浅拷贝, 因此要for循环拷贝。
-
this指针, 有什么坑: this指针是你自身对象的线性地址。 delete this需要保证this是new 出来的才行(因为堆上的空间不会出作用域就自动析构)。 注意栈对象析构中写delete会重复调用delete,陷入循环。
-
初始化列表 : 直接构造避免赋值拷贝更方便。而且const变量在初始化构造,不能在构造里面赋值 ,因为如果没初始化列表,在构造的const已经随机赋值了。 静态数据不要在这初始化,因为属于类而不是对象。
-
拷贝构造函数的参数类型必须是引用 : 避免无穷构造
-
default 关键字,delete关键字,explict关键字 : 默认, 删除, 严格限制输入的数据类型不能隐式转换。
explict这里面也没用到, 其实就是为了防止你传入一个字符串到一个接收对象的函数时, 这个对象接收单个输入的构造函数会默认把你的字符串构造了成对象, 这样你的函数就以为你传入的是对象, 就不会报错。explicit会关闭这种用法。
老张: 害, 你这讲的都是概念,只有少部分干货。 那我问你, 很多关键字其实没必要记忆的, 需求到才用到。 其实写代码就是先抽象出来类, 在写类的时候注意封装, 然后函数传引用,返回临时变量,用移动构造接收。 返回时候如果是局部变量的话用move拿资源让接收调用移动构造。 如果是临时变量记得提前定义好右值构造。 但是一般移动构造很多业务代码是不会去实现的, 因为资源交换要自己写, 你就先做好传引用, 函数封装合理就行。
老张: 此外, 你还少说了一些using的用法, 这个用作命名空间的时候类似于python中import后自己代码中省略的. , 而头文件类似于python的 import 。 因此你可以对比很多python代码, 其实都是直接用os.内容的, 而不是from os import *, 因此我也建议你为了防止命名污染, 代码中直接加命名空间, 别省略, 防止冲突。 其实我们的头文件就是用到什么随便写什么, 反正只编译一次, 具体的实现cpp里面如果用到了新的包你就导入新的包,反正编译时候如果是动态库这些里面的内容都是二进制文件, 不用看。如果是项目代码就都包含进来了 因此我们项目中代码不要管cpp的头文件, 要包全h文件中的头文件, 不然会出现很多东西未定义 。 此外using 还能用作起外号, 它和typedef区别是可以用在模板上。 此外不要觉得起外号是多此一举, 很多时候一个复杂的长串函数可以给个业务挂钩的外号来搞一下。你对比一下python就可以明白,
老张: 此外你要注意你的代码是线程不安全的, 对于vector这种在堆上分配资源的数据结构和cnt这些, 我们使用的 cnt = cnt + 1明显不安全, 不是原子操作, 需要加锁才能正确统计。如果有些资源类为了避免多次创建, 你把你的对象都搞成static全局的了, 那基本所有修改数据的地方都不会安全, 需要处处加锁。
老张:这个问题卡住, 我们到多线程和C++11新特性上再讲。 你继续讲讲继承和多态。
小飞: 继续先 上代码吧。
// main.cpp#include <iostream>#include "calc_origin.hpp"
using namespace std;int calc(Calc* input, int a, int b) {int answer = input->handle(a, b);cout << "cnt :" << input->get_cnt() << endl;return answer;
}int main(int args, char** argc) {int a = 10;int b = 2;Sum* p = new Sum(3);Multi* q = new Multi(4);Sum aa(1);Multi bb(2);cout << calc(&aa, a, b) << endl;cout << calc(&bb, a, b) << endl;cout << calc(p, a, b) << endl;cout << calc(q, a, b) << endl;
}// calc_origin.hpp#include <iostream>
#include <vector>using namespace std;// Calc::Calc(const vector<int>& res, int cnt) {
// m_res = res;
// m_self_cnt = cnt;
// cout << "init & ok " << endl;
// }class Calc {public:Calc(int res) {father_cnt = res;cout << "father" << endl;}~Calc() {}virtual int handle(int a, int b) { father_cnt++; }virtual int get_cnt() { return father_cnt; }int father_cnt;
};class Sum : public Calc {public:Sum(int res) : Calc(20), sum_cnt(res) { cout << "Sum" << endl; }~Sum() { ; }int handle(int a, int b) {sum_cnt++;return a + b;}int get_cnt() { return sum_cnt; }int sum_cnt;
};class Multi : public Calc {public:Multi(int res) : Calc(10), multi_cnt(res) { cout << "Multi" << endl; }~Multi() {}int handle(int a, int b) {multi_cnt++;return a * b;}int get_cnt() { return multi_cnt; }int multi_cnt;
};
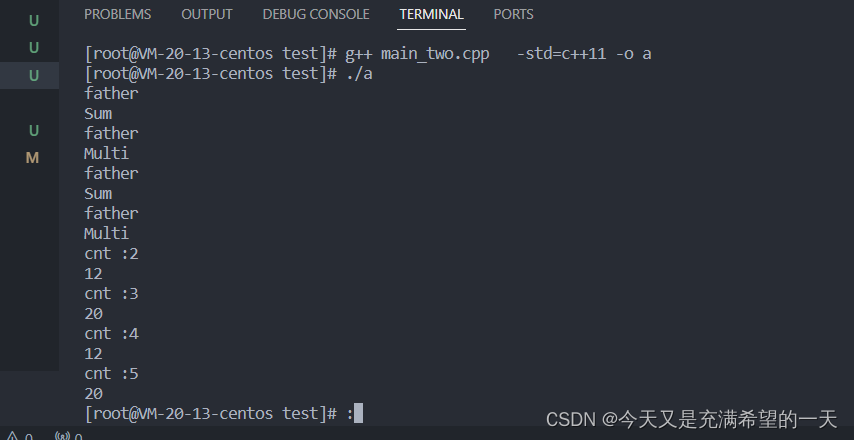
小飞; 上述的代码就是使用了多态来实现函数的接口封装, 虽然接收不同的对象但是以同样的一套接口来接收, 只不过展示的内容不一样, 这是一种非常好的业务封装。 这里需要注意, 多态其实就是基本函数定义为虚的, 而且要注意析构也要是虚函数,避免派生类无法释放。 底层是通过虚函数列表和虚函数指针实现了基类指针指向实际的派生类函数的功能。
老张; 是的, 对于大部分工具类, 我们都没有必要去搞继承,直接实现功能就行, 继承本身就是和多态一起工作的, 主要就是为了方便多种底层业务相似的类可以被别的高级业务类通过一个接口进行调用。 例如你实现了很多图形类, 并且提供了显示的接口, 这就是一个底层业务类, 当一个业务类需要通过画画而不需要关心你这个画图的形状, 就可以搞成这个这种多态形式。 例如你选中了一个圆圈, 说明你创建了一个圆圈业务类在你的画画业务中, 然后你想让你的图案显示出来, 就可以调用画画业务类的显示函数接口, 传入你图形业务基类, 通过基类指针调用到统一的圆圈业务类实现的显示接口, 就可以达到层层封装的代码解耦。 用户只关注于画画业务类。 你的项目也是这样, 如果你的很多底层业务功能类似但是有所属性不同,所以导致吐出的数据不同, 就可以用一个高级业务类去写这些底层业务类的基类函数接口, 达到统一的作用。
小飞: 原来是这样用的。。。 学到了。
老张: 其实这个技术是挺难得, 得你到了创建很多相似业务想吐的时候才会有这样的意识, 你会发现很多框架都是要用派生类的, 对于你一般写代码, 最好还是先忘记这个的用法, 派生类的使用只限于你理解一些复杂代码和框架代码上, 自己实现的话很容易出现解耦不全等设计不合理的问题。 总之就是一句话, 大量功能相似但是属性不同的基础业务可以搞成多态, 方便高级的业务类去调用。这样你每次写信的业务, 就不用动高级业务类了, 只需要写好自己新的基本业务类, 并按照其他基础业务类关联到抽象业务类的方式关联一下就行 了。
老张: 此外, 对于这些类,一定要关注你的类中资源的释放,如果没有释放造成了内存泄漏, 那线上服务过段时间就会因为内存一直增加而挂掉。要背锅的。
小飞: 我明白了。
老张: 好了, 时间不早了, 我们下午继续聊聊C++11的新特性多线程和一些容器的使用, 先午休了。
老张: 小飞, 快起来上课了, 我们继续讲。
小飞: 好困啊, 让我再睡会。
老张: 年纪轻轻的, 你怎么能睡得着觉,我像你这个年纪的时候每天凌晨1点下班。
小飞: 。。。。 这也太卷了, 哎。
C++11
老张: 哈哈, 开玩笑了, 没那么夸张。 来我们继续, 我问你C++11 新特性知道哪些?
小飞: 有很多, 例如智能指针提供RAII、nullptr 、auto auto&,auto&&、foreach、类型转换、函数对象(bind, function, lambda)、多线程、互斥锁、信号量。
老张: 那你讲讲智能指针吧, 一般用在什么地方? 为什么它管理的资源不用手动释放?
小飞: 智能指针就那三种, 就是用过一个计数器来统计有多少个指针指向了它, 是一种典型的用栈指针管理堆变量的思想, 出了作用域自动析构的。 一般需要跨函数生命周期的数据结构或者较大的数据都是在堆上, 你本地函数想要用最好搞成智能指针的方式,自动析构。
老张: 是的, 但是还要注意,share_ptr传递进去之后要避免交叉引用, 要先用weak_ptr接受, 具体使用的时候再进行升级。也有人直接传递了原生指针过去, 但是这样太不安全了, 要保证别释放才行。 那我问你, 智能指针是线程安全的么?
小飞: 这个不是的, 对于它的cnt是原子变量, 但是其内部管理的对象你还是要加锁控制读写的。
老张: 是的, 而且智能指针需要注意如果你的对象是资源或者fd这种,析构不了的, 要自定义删除器来处理这些资源。
老张: 此外C++11 中海油auto这种, 可以帮助你在模板或者写迭代器中做实参推演, 自动解析, 其实很多像python语言就是自动实现这个auto的, auto智能在赋值时候使用, 也就是你右边已经明确的时候, 自动补全左边。 自己都还没定义好不能这样用。
老张: 那我问你了解类型强转么, 一般什么时候用?
小飞: 这个我没怎么用过, 只是知道一般对于传递过来的函数指针等void类型的或者父类指针,需要进行强转之后才能用, 此外对于一些接口只接收父类指针的, 是需要强转一下的传递过去的。
老张: 是的, 关于这部分我在gdb调试中给你说一下, 很多强转不管用不用static这种,都会有大量指针取地址等操作, 这部分需要明确自己现在的内容, 想要转的内容, 去做。 然后还要能访问到里面成员函数和属性。
小飞: 我每次调试堆这方面最害怕了, 一看到gdb吐出来的内容是内存地址就发麻, 调试对于对象不知道该怎么看, 有些对象里面的成员变量还是对象, 感觉好复杂。
老张 : 这是高级用法, 我们到gdb调试时候再说。 我再问你, 关于函数对象你了解多少, 为什么要函数对象,lamdba表达式是怎么用的?
小飞: 我觉得主要是很多函数都不能带固定的参数吧, 例如我们有个接口是实现吐出当前用户的工作时间的, 这个实现就是需要函数对象, 而不仅仅是函数, 因为它本身需要带用户自身最开始进来的时间, 如果用函数我们没法做, 但是函数对象就可以。 一般函数对象就是用在函数需要记录个性化属性的地方。而且函数对象是一个对象, 就可以将这些函数对象绑定到一个容器当中,进行调用, 这相比较绑定函数指针更为方便,而且函数指针还需要考虑释放的问题。
小飞: 像bind就是将一个函数放到一个函数对象中, function也是, 不过bind可以设置参数。 一般我们都是将bind的函数对象放到function中, 然后统一放到map容器中, 提供调用。 根据不同的函数名找到map表中对应的函数对象, 然后调用。 这在web框架中是经常用到的。
小飞: 像lamdba就是一个简单的函数对象, 写起来比较简单, 而且可以接收当前的栈内部参数作为成员和入口, 类似bind。 但是一般lamdba是使用短暂或者函数代码不复杂的时候用, 如果复杂了还是, 单独实现一个函数用bind绑定吧。
老张: 是的, 关于bind也是一个非常高级的用法, 常出现在框架中, 我们后面遇到中间件再讲。 此外还需要注意C++的一些新特性例如for each 和nullptr, 都是提升效率的好手。
stl库
老张: 接下来我们讲讲stl的容器吧, 看看你都知道哪些?
小飞 : STL中存放了不少能够复用的数据结构和算法, 主要有iterator、算法、线性容器(vector, array, list, deque, forwardlist),非线性容器(map, set , unordered-map)、 适配器(stack,queue, priority-queue)。但是他们都不是线程安全的, 如果在对全局容器操作的时候记得加锁, 我们用下面一个例子做一下vector和map的操作。
#include <map>
#include <string>
#include <unordered_map>
#include <vector>#include "common_tools/time_interval.hpp"
using namespace std;
int main() {vector<string> in;int count = 10000000;{TIME_INTERVAL_SCPOE("reserver time:");in.reserve(count);}{TIME_INTERVAL_SCPOE("push_back time:");for (int i = 0; i < count; i++) {string temp("test");in.push_back(temp);}}in.clear();{TIME_INTERVAL_SCPOE("push_back move(string) time:");for (int i = 0; i < count; i++) {std::string temp("test");in.push_back(std::move(temp));}}in.clear();{TIME_INTERVAL_SCPOE("push_back && time:");for (int i = 0; i < count; i++) {in.push_back("test");}}in.clear();{TIME_INTERVAL_SCPOE("emplace back time :");for (int i = 0; i < count; i++) {in.push_back("test");}}map<int, string> res;{TIME_INTERVAL_SCPOE("insert time:");for (int i = 0; i < count; i++) {pair<int, string> STL = {i, "test"};res.insert(STL);}}res.clear();{TIME_INTERVAL_SCPOE("insert && time:");for (int i = 0; i < count; i++) {res.insert({i, "test"});}}res.clear();{TIME_INTERVAL_SCPOE("emplace && time:");for (int i = 0; i < count; i++) {pair<int, string> STL = {i, "test"};res.emplace(STL);}}res.clear();{TIME_INTERVAL_SCPOE("[] = time:");for (int i = 0; i < count; i++) {res[i] = "test";}}unordered_map<int, string> res2;{TIME_INTERVAL_SCPOE("hash insert && time:");for (int i = 0; i < count; i++) {pair<int, string> STL = {i, "test"};res.insert(STL);}}unordered_map<int, string>::iterator answer;{TIME_INTERVAL_SCPOE("hash find time:");for (int i = 0; i < count / 100; i++) {if ((answer = res2.find(i)) != res2.end()) {// cout << answer->second << endl;;}}}map<int, string>::iterator answer1;{TIME_INTERVAL_SCPOE("map find time:");for (int i = 0; i < count / 100; i++) {if ((answer1 = res.find(i)) != res.end()) {// cout << answer1->second << endl;;}}}
}
可以看到上面的代码我们使用了最基本的几个容器,也是最常用的几个容器, 并且计算了它们的耗时如下, 可以看到不同的接口实现的耗时是不一样的。
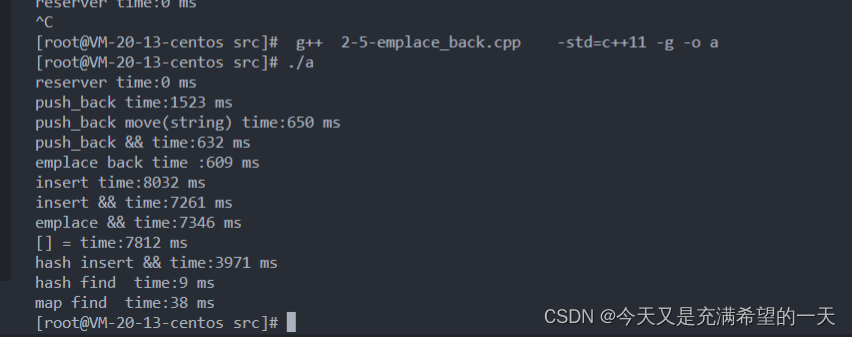
一般我们对于一些对顺序无要求而且是遍历访问的数据, 就使用线性容器, 注意这里vector的扩容机制, 对于大量的数据最好先用reverse或者resize真实创建,一般都是先用reverse, 因为我们不知道具体要创建多少个。 此外放入 的时候需要用emplack直接走拷贝构造, 不需要先构造再用拷贝或者移动构造。
对于对顺序访问无要求但是是直接访问的数据, 用unordered_map, 对于有顺序要求也需要直接访问的就是map。 对于有先进先出等业务数据要求的, 就调用队列这些。
老张: 没错, 此外你还要注意, 如果插入会导致迭代器失效, 这时候需要返回新的迭代器吗迭代器本省就是一个安全的泛型指针帮你隐藏。
老张: 好好想想你之前写的代码, 其实有个业务类型完全可以用unordered_map 但是你用了map, 这就是屎山代码。
小飞: 。。。 我知道错了, 下次一定改。
老张:好了。 接下来我们说说模板这些。 你讲一讲你对模板的认识吧。
小飞: 我理解面向对象将项目中可以统一到一起的代码高度封装, 不一样的部分完全切开。 但是其实这还不够, 类和函数中一些数据类型是写死的, 那你每换种数据结构执行同样的功能需要再重新写一个类或者重载函数,这也太麻烦了, 因此有了模板, 在编译的时候自动将你的代码从模板中替换成自己的类型,而模板元其实就是复杂点儿的模板,简单的模板在特化时基本只包含类型的查找与替换,这种模板可以看作是“类型安全的宏”。而模板元编程就是将一些通常编程时才有的概念比如:递归,分支等加入到模板特化过程中的模板,但其实说白了还是模板,自动代码生成而已。
老张: 不错, 虽然说工作中我们需要谨慎使用模板, 但是对于一些冗余切类似的代码, 完全可以通过模板来重写, 例如每个rpc, 你用模板 做到main函数中部分逻辑用模板接收不同业务rpc类成为一个参数, 就可以实现代码的解耦,因为其接口基本都是一致的。不过模板在一些根本无太多复用性的地方别用啊, 例如你一个功能只有一个函数或者类, 而这个类的数据类型固定不变, 且无其他相关业务, 就别去搞, 模板写出来的代码别人很难看懂的, 是开发难度和开发效率之间的冲突, 要做一个平衡。
linux系统与基本命令
总体认知
基本内容
我以小飞和老张作为对话模式来介绍一下linux基本操作。小飞是一个刚入职的毕业生,在学校基本就只用过linux的基本命令, 来到公司有了如下的对话。
老张问他你linux熟不熟呀?小飞满脸自信的说, 还不错, 在学校经常用。
老张: 那我问一下你linux是什么呢?
小飞说: 这个简单, linux就是一个类unix的系统, 是开源的, 我们可以安装不同版本的linux进行开发, linux相比较window在系统稳定性上有得天独厚的优势, 很少会死机, 但是其GUI系统和面向消费者用户的软件生态不是很好, 所以一般都是用来做开发的。
老张: 不错呀, 那我问题一般开发用什么版本的linux, 都有什么区别呢?
小飞: 这个也很简单, 一般开发都是用centos,这个版本好像非常稳定, 是一个红帽系统的加固版本, 不同版本的centos安装的gcc和g++版本是不同的。
老张: 不错不错, 那g++版本不同有什么影响呢?
小飞: 一般就是支持的C++标准库不一样, 而且编译器也不一样,例如常用的centos7安装的gcc是4.8.5, c++14的语法是不支持的。
老张: 嗯嗯不错, 不过一般开发要看公司, 很多公司其实就只用到C++11, 高级的编译器不需要, 也有风险, 例如最新的编译器可能对一些功能并没有经过迭代, 容易踩坑, 所以不是越新的版本越好。 适合自己开发就行。这个话题能聊很久, 我们今天就讲讲linux的使用。
小飞: 明白了, 那张老师, 我现在该怎么开发呢?
老张: 我先给你开个普通用户吧, 你用这个账号去开发代码就行。 (老张自己百度了一下,添加了一个有sudo权限的用户给我)
小飞: 好的, 那我这个用户sudo会影响到别人嘛?能直接给我一个root用户嘛
老张: 这可不行,root用户安装的东西其他普通用户都受到影响, 一般我们都是用普通用户的, 安装软件你就用sudo就行,但是sudo貌似会影响到别人的(https://blog.csdn.net/hktxt/article/details/83658978?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-83658978-blog-79025360.pc_relevant_aa_2&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-83658978-blog-79025360.pc_relevant_aa_2&utm_relevant_index=1), 尤其是你往一些/root/等地方写东西时候, 本身是没有权限, 但是你强行sudo就会影响别人的。 不过你安装软件到你自己的/usr/lib/下是没问题的, 并且设置你自己home用户下的环境变量, 别搞成全局的。
小飞: 好吧, 这个我还不会。。。后面要测试一下。 那老张我拿到这个账户怎么登录呀?
老张: 一般就是你直接ssh登录啊, 把本地的公钥复制到服务器上, 就可以免密登录。 此外你还要记得你服务器的公钥给到github上, 不然每次拉取代码都要github密码, 而且要设置remote是走的ssh。
随后小飞开始一顿操作, 成功拉下来了代码, 并且编译成功,上传也成功了。 得意洋洋。
老张: 好, 代码跑下来了, 现在让你找一下main函数?
小飞: 这个简单, 我先找找一下main.cpp
find ./my_pearl/ -name “main.cpp”
老张: 不错, 那你找一下TimeInterval这个函数在哪个文件吧。
小飞: 简单, 看着。
grep -r “TimeInterval” ./my_pearl/

老张: 不错, 好了现在你把代码跑起来,看看进程占用资源和端口吧。
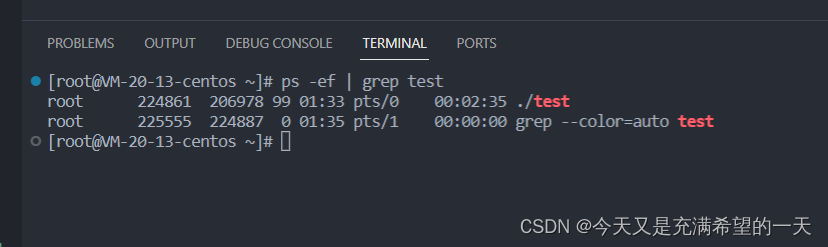
小飞:
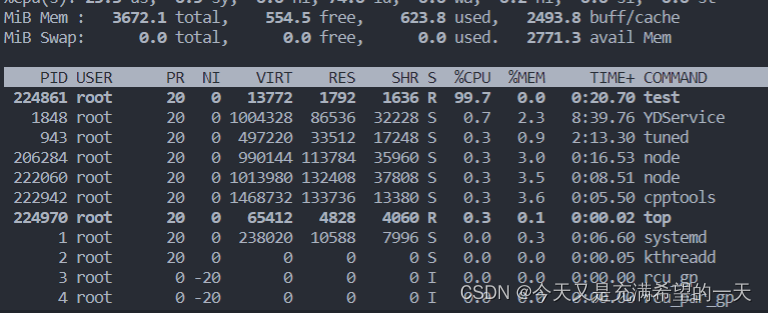
top 看看资源占用
ps -ef | grep test 看看进程信息
老张:解释一下上面两个图吧,并且说说资源占用率能不能过100? 你这个程序会一直运行嘛?有什么意外嘛?怎么解决?
小飞: 上面我的程序占用了99.7的cpu, 但是并没有全部占用哈, 因为我这个服务器是双核的, 但是我程序中是单进程而且只开了一个线程, 那么一个线程之能占用一个cpu, 所以最多就100, 如果我再开一个线程或者程序里面创建一个新的进程执行同样的内容就能到200, 当然如果我再开一个,cpu占满估计我的ssh就无法操作了,这种就很危险了。 此外我的程序是有父进程的, 我的父进程是用户ssh进程, 用户ssh进程父进程是0号进程, 如果你把运行的终端给直接kill掉这个程序就自动停止了, 最好是用nohub让其脱离当前父进程哈。 (也能理解, 假如你一直运行一个程序, 没有停止, 但是你的终端都结束了, 自然会通知其子进程, 不然成为了孤儿进程, 太多了, 影响别的用户的使用。)
老张: 不错, 那你看一下为啥你的内存占用率这么低?
小飞: 这是因为代码中基本没有分配啥数据结构, 堆栈都没占用多少, 一个程序起来会有4g空间, 而我基本都没用, 如果虽然我cpu占用率搞但是我基本没用啥变量, 就一直计算,所以内存比较少,随着我用到的堆栈越多,内存占用率越高。 我创建一个很大堆变量或者一个比较大的栈变量, 就会发生coredump,
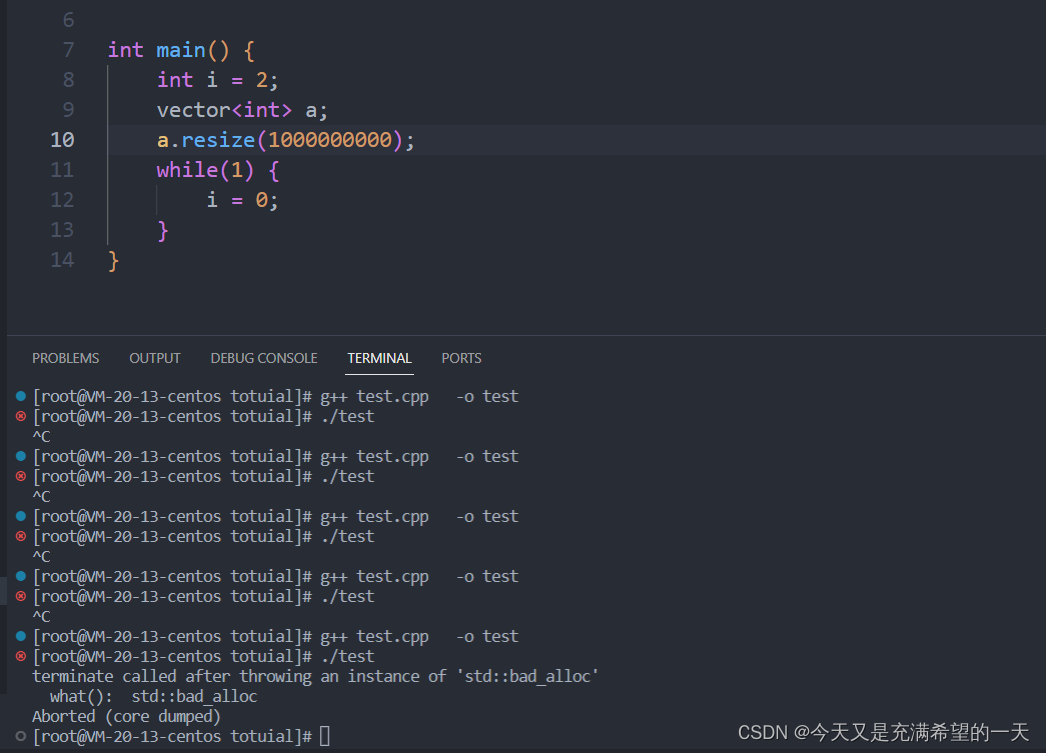
老张: 不错, 基础很扎实。 记住cpu占用率要看所有核加起来的占比, 如果cpu占用率占的很大的话而且在运行的线程或者进程数, 就容易发生竞争, 很多时间花在切换上, 这会导致业务变慢, 因为你运行一半就要被别的线程和其他进程占用。 此外内存也不能太大啊, 尤其是栈数据, 不能放大的数据, 不然很容易coredump,堆上数据如果你没有释放让别人用到了产生内存泄漏也很容易dump。。 而且内存这东西还要算cache和swap这些, 不过这些比较细节,先跳过。
小飞:C++代码真的好难, 这么多需要考虑的。
老张: 要学的还有很多, 不过我们不讨论这, 继续回到linux, 现在你程序运行起来了, 那你去看看代码运行的日志吧, 日志一般你怎么看呢? 怎么查找关键的内容呢?
小飞:这个我不懂, 平常都是vi去看, 但是快捷命令也不懂。
老张: 这个你可以参照https://zhuanlan.zhihu.com/p/75052300。 一般看日志都是先df - h看看日志存放的位置, 一般大文件的地方就是日志存放的地方。
cat service.log或者tail -f service.log 或者vim serivice.log都能看
这个取决于你怎么用, 一般对于配置文件我们是直接cat + grep去搜索。 对于日志我们如果关心是否有数据过来, 就执行tail -f service.log 看最新的。 如果你想查找内容就vim , 然后按g调到末尾, 按?加内容查找内容, 按N往下查询。 一般vim查询比较方便, cat是用来统计或者对比的。
小飞: 明白了 , 哈哈。
老张: 那你知道重定向是啥不? 为啥要用重定向呢?
小飞: 这个我知道, 一般我们终端的输入和输出默认就是用户的输入和屏幕输出, 但是一般我们 的启动服务是后台运行的, 要加&, 这种输出很多都需要重定向到一个日志文件或者到垃圾回收的地方, > 这样用的。
老张: 没错,小伙子, 刚才我们讨论的是性能和linux基本操作, 实际上线程和coredump这些东西我都还没问你呢, 这个时间关系我后面问。 先来问一下你平时怎么排查网络问题的?
小飞: 一般我就是ping, 然后查看网络的ip 是ifconfig。 此外还有如果我们要看一个进程占用的端口或者端口被哪些进程占用就netstat -nap | grep 进程或者端口, 输入不同显示的不同。 一般网络都是绑定在端口上的, 别人能够通过端口访问到你。 可以看看我们下面这张图就是端口绑定了很多ssh进程, 所以我们的多个网络套接字可以绑定到一个端口, 设置端口重用就行, 会有不同的套接字区分。 这样一个端口就可以连接上千个用户的网络套接字。
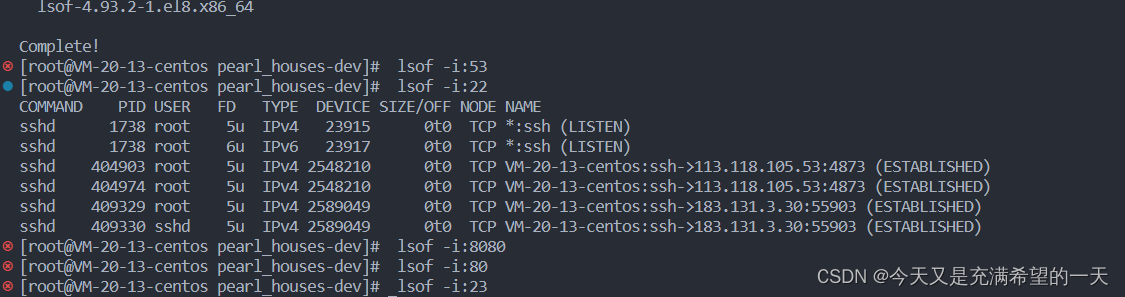
老张: 嗯嗯, 这个套接字数量还是可以改的, 而且要注意一定要设置好time_wait, 不然很多套接字都是用完120s才释放, 就会导致其他用户请求过来需要套接字弄不上。 那我问你软连接一般什么时候用呢?
小飞: 这个一般是如果你更换gcc版本用这个, 其实系统的gcc可执行文件就是软连接了一个gcc版本, 你可以将你信的gcc版本软连接到系统默认找运行程序的路径, 替换里面的gcc,这样就可以不用设置用户变量就可以找到, 但是要注意你的动态库啊, 编译器的其他gcc-*也都要链接过去, 不能只链接一个, 那样你链接的动态库啥的还是之前版本的, 很有可能不支持。
小飞: 明白, 老张, 还有什么高级的用法, 放马过来?
老张: 你的水平我差不多理解了, 新手中上, 今天给你好好上上课, 主要关于环境变量、系统启动脚本、/proc目录怎么看。
小飞:。。。。 这些我确实不会, 老张你也太厉害了, 这一会就知道我的水平了。
老张: 来, 上课, 我问你, linux的启动原理是啥?
小飞: 这个我会一点, 基本就是先去boot目录下加载内核文件检查硬件, 然后启动init进程, init进程里面会启动一些终端和守护进程,维护系统的正常运行。 然后用户可以通过终端进程访问系统, 操作一些守护进程和安装一些新的软件。 此外还
老张:那你说说linux的目录中都是在干嘛?
小飞; 一般boot是bios的, dev是所有的硬件文件, mnt是挂载一些dev设备尤其是文件设备, proc是虚拟文件系统存放内存数据, 主要是关于进程状态的; /bin 存放基本的程序, 需要注意用户和全局的系统变量, 他们规定了一些命令从哪里找, 例如你在终端输入的ls实际上是一个存放在bin目录下的程序,寻找路径是通过启动脚本配置的环境变量。 sbin存放一些会影响系统运行的命令, 一般用户没有这里面命令的访问权限。 而home/用户下也存放了一些用户的程序和lib动态库, 一般程序安装到这里的话别的用户看不到,而到了/bin就会, 最好装到自己的bin中。
老张: 是的, 了解这些之后, 其实你就知道linux运行的过程和逻辑了, 后面找问题咱们也好解决。
老张; 其他一些边角料的知识点
- /bin/rm 和rm的区别在于, 用户的rm很可能是alis函数, 会在rm上加一些额外的参数, 最好就用/bin的rm直接调用。
- xargs 一般是和其他命令组合到一起, 用别的命令的输出内容作为xargs的命令参数, 例如find . -name “a.cpp” | xargs rm -rf 去批量删除找到的内容。
- 一般我们的代码都是运行在1号进程下, 然后需要使用守护进程去控制开关, 不然如果你用自己的终端控制没加nohub, 启动起来的进程绑定到你的终端, 结束后会kill掉。
开发工具和git
基本内容
小天是刚入职的员工, 老张看小天使用的是notepad编程, 还以为小天是大佬, 一问才知道原来小天这个编辑文档的东西连编译器都没有用, 经过一番沟通, 老张发现小天其实懂得不少的, 但是并没有一个系统理解, 于是有了如下的对话, 帮助小天系统的梳理这方面的知识。
老张: 小天, 你知道IDE和编辑器的区别嘛?
小天: 这个我知道, 一般IDE就是继承了编译器或者解释器, 而且提供了基本的项目管理功能, 但是其实大型项目都是有需要有自己的项目管理工具, 例如bazel和maven这些。 而编辑器一般类似于vscode。 vsocde你可以理解是一个编辑器, 类似于notepad的本地文档, 它不能将里面的代码运行, 需要你自己制定编辑器来运行。 当然它也提供了runner工具包, 但是这个包还是有很多局限的。 因此我们在安装了vscode之后, 还要安装编译器才能运行代码。
老张 ; 不错, 工作中我们经常都是用vscode连接远程开发机器进行开发的。 也就是说一般你点击运行主函数文件是运行不了的, 因为你本身没有指定开发的编译器, 而且就算你指定了, 直接点击运行也是非常麻烦的一件事情, 一般我们都是在终端自己执行, 不用点击的, 只不过开发时候修改和查看文件比较方便。
小天: 嗯嗯, 这个工具我也是经常用的, 不过很多时候都是链接本地的开发编译器开发python, C++这方面开发比较少。
老张: 嗯嗯, 那你知道vscode插件是干嘛的么?
小天: 插件是辅助你开发的, 例如你刚装上vscode安装c++插件后, 一些c++语法就能够高亮, 装上c++ intellgence之后, 一些常用的语法就会自动补全。 python也是同样的道理, 你安装anaconda插件, vscode就能够显示你当前所在的虚拟环境在哪。 你还可以安装leetcode插件去刷题。
老张: 刷题就别让人看到了, 哈哈, 平常有些插件你可以参照添加链接描述 去看着装一下, 现在我 需要你使用远程连接到一个服务器上,而且要用ssh, 不要每次都输入账号和密码的那种, 那种容易被人破解。
小天: 这个我会, 首先要在本地生成秘钥,
之后去这个目录下将自己的公开秘钥复制到服务器中的.ssh/ authorized_keys中, 然后重新连接就可以了。
老张: 不错, 就是这样, 记得还要配置你的拉代码权限, 一般你的开发机要配置git的权限到你的仓库中, 不过vscode也有直接连接git的插件, 但是如果不是用github做远程代码管理, 而是公司自研的, 就不行了。 注意你还要在远程开发机器上安装一些插件, 本地和远程是不一样的。 你需要在开发机上执行同样的步骤, 然后将github地址放过去。
小飞: 好的我明白了.
老张: 好的, 接下来我们讲讲git, 首先你先说说你对git的理解
小张: GIT就是一个修改版本记录工具,我们在每次修改的时候都可以覆盖,如过想过回到过去的版本只需要一个命令就可以解决。 而且git是方便多人进行开发的, 他有本地分支和远程分支两个, 一般你本地提交之后合并到远程,别人也需要同步你的内容再去开发,这样来达到协同工作的。
老张: 嗯, 这些只是基本的理解, 那我问你刚才你配置秘钥提交和直接拉取别人的代码进行提交有什么区别嘛?
小飞: 这个肯定有了, 你自己配置好秘钥的代表这个库你能够开发, push上去就是直接的提交到了代码中, 但是如果你不是这个项目的开发人员, 例如一些开源框架, 你提交了一个问题的解决, 那就是pull request, 是否接收你的提交要看人家review代码之后决定的。
老张 : 是的, 那你现在就拉取一个代码吧, 我们来实际操作一下。
小飞: 好的, 首先我先 在git上创建一个项目,
之后我可以直接clone下来或者本地init 或者设置init链接进来都行, 这里为了方便我直接clone下来吧。
git clone git@github.com:liupeng678/pearl_houses.git
老张: 这样也行, 那你这拉下来的代码是master, 注意很多时候我们拉取下来的代码都是其他分支, 你可以用git clone -b dev git@github.com:liupeng678/pearl_houses.git来拉取dev分支的代码。 你试一下。
小飞: 好的, 我已经把dev的代码拉下来了(但是速度好慢啊。
老张: 这个没办法, 是比较慢, 你可以传到gitee上。 你拉下来需要注意这时候要看本地是master分支还是dev, 远程的是dev分支, 然后你可以用git remote -v 去查看自己的连接地址是不是走的ssh, 如果不是的话, 需要git remote add origin git***更换成为ssh, 不然你的公私钥白配置了。
小飞 : 好的, 那我们平常开发都是自己新建一个分支 git checkout -b my_dev, 然后git add. git commit -m “add code” , git push origin 自己 远程分支上去么.
老张: 是这样的, 但是你要注意几个点, 首先你的git add .要在最开头的目录下执行, 不然有些修改你是没有push上去的, 此外你的提交内容别人看不懂, 你这个提交备注add code 太不负责任, 如果别人看你代码, 都不知道你这次修改是做了什么, 而且你自己如果遇到问题要回退,一看历史记录全是add code, 根本不知道要回退到哪里, 如果你想保存这次本地的提交, 其实完全可以使用git commit --ammend -m "覆盖内容"去全部弄到一个日志中, 不用提交这么多次。 但是你第三个命令是挺好的,很多人直接就git push , 默认了提交到master分支, 这是非常危险的。 git add. 是提交到缓存区, 你可以是用git status -s看看修改的记录。
小飞 : 好的, 我改一下, 之前都是一个人开发, 一直没有注意。。。 现在你一说, 我就感觉到问题的严重性了。
老张: 嗯嗯, 如果你本地的修改不是你想要的, 你想要直接强制覆盖为远程的怎么搞呢?
小飞 : 这种我会,一般就是git fetch --all 获取远程记录, 然后git reset --hard origin/devv 到这个分支最开始, 然后git pull origin devv。
老张: 可以, 那你就用这些命令先开发吧
时间过去了几周, 小张开发了不少代码, 这时候小飞遇到问题跑去找老张。
小飞 :
小飞 : 老张, 你看我这边代码提交了很多了, 但是我发现自己代码写错了, 想回退一下, 这个怎么搞啊。
老张:这种 一般就是要看你有没有提交到远程, 如果没有的话就git log查看一下,然后git reset -hard id完全回退到原始的状态(注意这reset一般是用作你想撤回一个add内容的, 用在回退中也可以, 在回退中使用不加–hard就会保留缓存区内容 。如果是revert就是只改中间的一次提交)。 但是如果你已经push上去了就多一步, 首先还是本地先回退, 然后强制提交git push -f origin devv。 但是这里你要注意一下, 一定要看别人有没有提交新的, 确保你强制覆盖的分支别人没有正在提交, 这时候你最好就是git pull或者git fetch --all 查看一下提交记录, 确保本地的log最新最后再执行。 一般最好不要做这种覆盖远程的, 但是发生了也没办法。
小飞: 好的, 老张, 那我现在还想将自己的代码合并到master, 这个怎么操作呢。
老张: 首先合并到master你要明白, 如果有人修改了master的a文件, 但是你修改了b文件, 它先合并了, 你是不需要先pull下来的, 只要没有文件级别的冲突, 是自动合并的, 这个和同一个分支提交不一样。 之后我们说你的合并请求, 一般都是要自己在本地分支合并的, 首先你先在本地master或者main分支上将主干代码拉取下来, 然后你使用 git merge --squash origin/devv --allow-unrelated-histories合并, 这时候合并内容没有commit,你自己commit然后push上去。 切记不要直接merge, 因为这会把你的日志全部按照日期添加到master分支, 非常恶心。 提交完成git push origin --delete dev 删除远程分支, 然后git branch -d dev删除本地的分支, 就可以了。
小飞 : 好的, 那我问一下如何解决合并冲突呢?
老张: 这个问题比较复杂, 一般有冲突你要自己确定好和别人冲突的地方, 在本地修改好冲突的文件要留下的内容, 然后再覆盖。 这个问题我下次再给你讲吧, 我先工作了, 一般你现在新手开发很少遇到能和别人冲突的地方, 大部分冲突都是你自己改的地方不对了。 等你熟练了我们再讲这个问题。
小飞 : 哈哈, 好的。 下次聊。
- fetch 和pull的区别是fetch是统计远程信息, 需要git merge将远程和本地合并, git pull是直接合并。
感言
不知道不觉, 这份C++后端入门手册已经写到了尾声,回过来头来看,小飞就是刚入职工作的我,而老张是我身边帮助我的同事和自己面对问题去解决问题的态度。 他们化作了老张一直在我身边, 让一个连git都用不熟练的新手成长为了一个能够支撑一片业务的骨干。 在我学习和做笔记的时候, 我试过很多方式,最终摸索出来这种对话方式的学习, 并且写下了这份笔记。 希望现在的我能够成为你成长路上的老张, 帮助你在这个领域站起来, 让我们一起努力。
一些感悟
- 长时间来看努力大于选择,真正的核心竞争力在于度过行业周期。
过于我在学生时代, 由于自身习惯等等原因, 做事总是想走最快最省事的捷径, 但是慢慢的我开始明白了几个道理, 一个就是关于人的选择其实不能占比太多时间,而且360行行行出状元, 在一个领域做不成功, 换一个风口赛道就能成功嘛? 任何领域和事情站在前面的人其实大都是那些具备在一个领域做到极致能力的人, 这种极致能力不在于特定领域(不过有点限制于个人性格和特点)。 雷军说站在风口上猪都能飞起来, 这句话确实在那个时代不假, 但是以后随着信息的公开, 这种领域会越来越少, 此外即使风口, 你会发现站到最上面的其实还是雷军这些能把事情做到极致的人,并不是一些投机取巧的人。过于将精力投入到最短路径寻找中, 只会让自己一时过得比较好, 但是一旦这个领域经历几次周期之后,这些最短路径从业者就会跟不上。此外选择热门领域,你会发现非常的卷, 人才特别多, 可能你是8分的人, 但是这个领域来了一堆9分的人, 即使你占据先进赛道的优势, 但是如果中后期不努力其实最终还是会被摔下去。相反如果是冷门领域人才进去的少,你8分的人可能就在该领域算9分。
- 那么我最终想说什么呢? 我想说现在大家基本都有机会进入到有难度的领域, 而这些有难度的领域往往都是那些前期比较难或者枯燥, 但是需要人坚持的领域, 只要你努力去做, 不停在挑战区工作, 然后知道真正的成长就是在突破舒适圈、行业下沉、无从下手()的时候,你感觉无从下手, 别人同样也是这样, 你选择了常人不选的坚持, 坚持到了后面 , 慢慢的就拉开了。 正常人在行业低迷和难度过大的时候会选择逃离, 你选择坚持, 就会笑到最后。 因此不管你选择java还是python还是C++, 这些赛道其实重要性不大,每个领域的高手都有自己相比较一般入行人员的核心竞争力, 人家通过时间和努力打磨的竞争力远比选择赛道不同带来的收益更大。 虽然两个高手选择了不同赛道, 都形成了竞争力, 确实会存在一个人收入高一些, 一个人收入低一些, 但是低收入的人差距没那么大, 而且人家那边竞争小,容易冒头, 处于行业下降时候进场能够在上升时候站稳资源的上头。可以看看, 万事万物都是存在一个平衡的, 想要一力破万军和走捷径来填补别人那么多年的努力是违背宇宙客观规律的, 强入恒星都要面临死亡, 何况是个人呢, 还想突破规律。
- 学习的时候一定要注意内存和外存, 做东西细致后出做出创新。