提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 分布式ID
- 一、什么是分布式系统唯一ID
- 2. 二、分布式系统唯一ID的特点
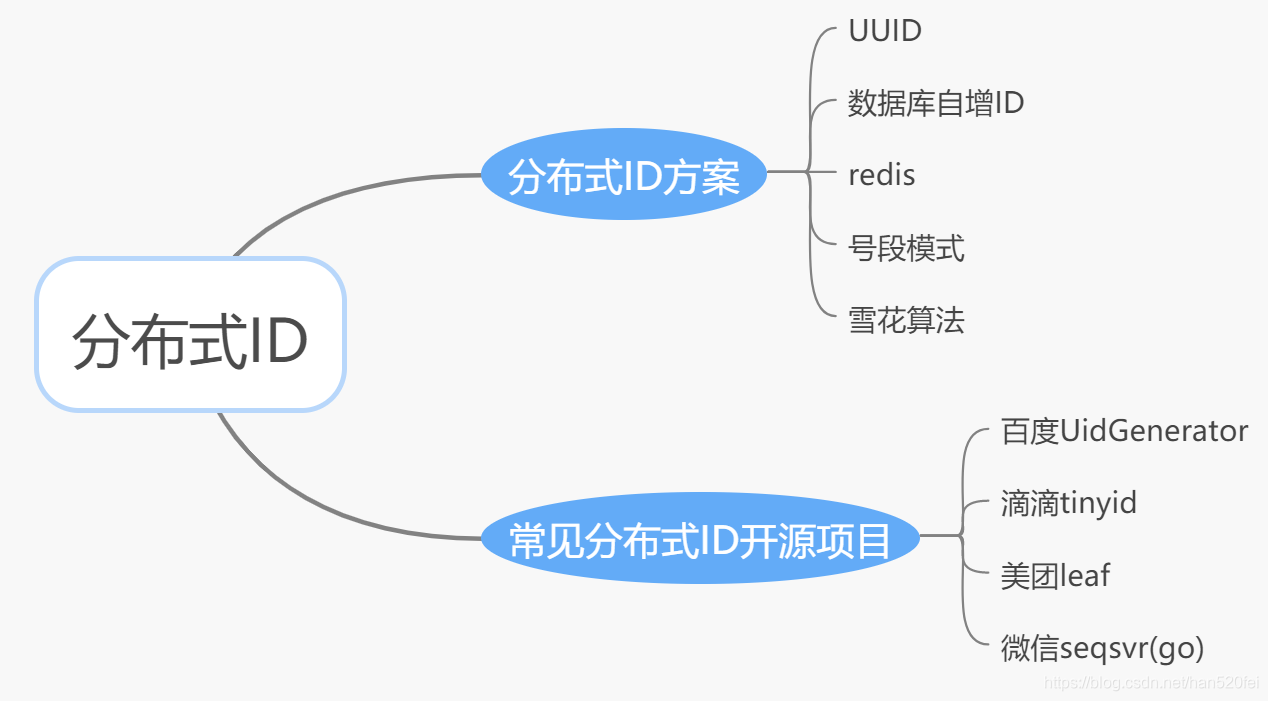
- 分布式ID-----实现方案
- 1、使用UUID生成分布式ID
- 2、基于数据库自增ID
- 3、Redis生成ID
- 4、号段模式
- 滴滴的开源项目TinyId使用的就是这个原理:
- 5、snowflake(雪花算法)方案
- 优点:
- 缺点:
- 应用举例Mongdb objectID
- 6、分布式开源项目
分布式ID
一、什么是分布式系统唯一ID
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。
- 如在金融、电商、支付、等产品的系统中,数据日渐增长,对数据分库分表后需要有一个唯一ID来标识一条数据或消息,数据库的自增ID显然不能满足需求,此时一个能够生成全局唯一ID的系统是非常必要的。
2. 二、分布式系统唯一ID的特点
- 全局唯一:必须保证ID是全局性唯一的,基本要求
- 高性能:高可用低延时,ID生成响应要快,否则反倒会成为业务瓶颈
- 高可用:100%的可用性是骗人的,但是也要无限接近于100%的可用性
- 好接入:要秉着拿来即用的设计原则,在系统设计和实现上要尽可能的简单
- 趋势递增:最好趋势递增,这个要求就得看具体业务场景了,一般不严格要求
分布式ID-----实现方案
1、使用UUID生成分布式ID
优点:
实现方式简单,本地生成,性能高,没有网络消耗。
public static void main(String[] args) {System.out.println(UUID.randomUUID());//75a90ba3-8bc9-4b37-992f-2d205de1b704}
缺点:
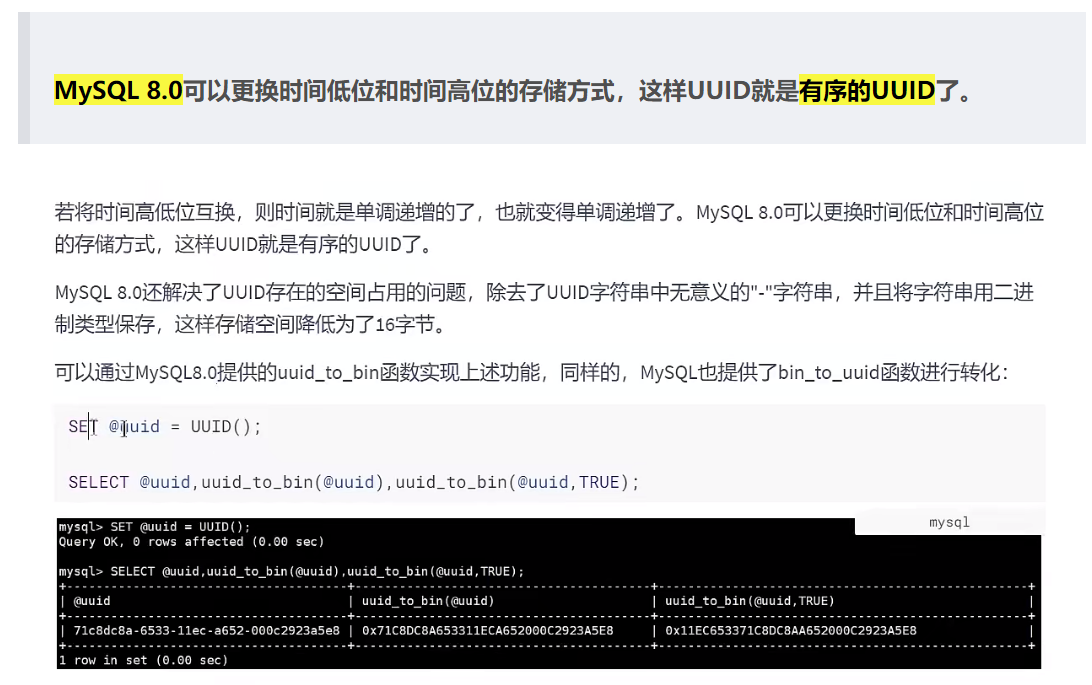
1、UUID太长,占用存储空间多。
2、UUID作为主键建立索引和基于索引进行查询存在性能问题,尤其是在InnoDB存储引擎下,UUID的无序性会导致索引位置频繁变动,导致分页。
注:UUID可能重复吗?
UUID理论上来说是可能重复的,经过16^32+1次生成之后会产生一次重复的值。但这是一个特别大的值,需要经过很长、很长、很长时间后可能出现一次重复值,所以UUID可以看成是不可重复的值。
2、基于数据库自增ID
单节点数据库生成分布式ID
需要一台单独的数据库服务器,创建一个张表:
CREATE TABLE sequence(id bigint(20) unsigned NOT NULL auto_increment,stub char(1) NOT NULL default '',PRIMARY KEY(id),UNIQUE KEY stub(stub)
) ENGINE=MyISAM;
REPLACE INTO sequence(stub) VALUES('a');
SELECT LAST_INSERT_ID();以MySQL举例,利用给字段设置auto_increment_increment和auto_increment_offset来保证ID自增,每次业务使用下列SQL读写MySQL得到ID号。
这种方案的优缺点如下:
优点:
- 非常简单,利用现有数据库系统的功能实现,成本小,有DBA专业维护。
- ID号单调自增,可以实现一些对ID有特殊要求的业务。
缺点: DB单点存在宕机风险,无法扛住高并发场景
- 强依赖DB,当DB异常时整个系统不可用,属于致命问题。
- 配置主从复制可以尽可能的增加可用性,但是数据一致性在特殊情况下难以保证。主从切换时的不一致可能会导致重复发号。
- ID发号性能瓶颈限制在单台MySQL的读写性能。
如果你想到了扩展数据库服务器数量,那么又会引入一个新的问题。
- 如果要增加数据库,那么之前每台数据库设置好的初始值和步长,就需要人工去修改了。这就需要停掉前面配置的所有数据库,去统一修改配制,这样是极其不方便的
- 并且我们为了生成自增的ID去扩展很多数据库服务器,不觉得有些大材小用吗?这就需要我们从新的角度考虑生成分布式ID的方案。
3、Redis生成ID
当使用数据库来生成ID性能不够要求的时候,我们可以尝试使用Redis来生成ID。
这主要依赖于Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY来实现。
比较适合使用Redis来生成每天从0开始的流水号。比如订单号=日期+当日自增长号。可以每天在Redis中生成一个Key,使用INCR进行累加。
优点:
1)不依赖于数据库,灵活方便,且性能优于数据库。
2)数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
1)如果系统中没有Redis,还需要引入新的组件,增加系统复杂度。
2)需要编码和配置的工作量比较大。
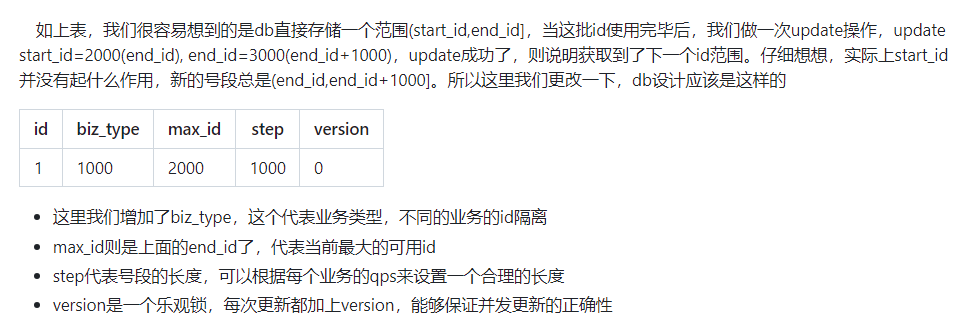
4、号段模式
- 号段模式的大致意思是服务每次从数据库获取ID时,获取ID的一段范围,表示服务获取到了这段范围的所有ID的使用权,比如[1,1000],
- 表示当前生成的ID从这段范围内自增,每次服务从这段范围内返回一个自增的ID(可以通过AutomicLong实现)
- 这样就不用每次获取Id时都去请求数据库。直到ID自增到1000时,也就表示当前这段的ID使用完了,再去数据库取下一段的ID。
滴滴的开源项目TinyId使用的就是这个原理:
https://github.com/didi/tinyid/wiki/tinyid%E5%8E%9F%E7%90%86%E4%BB%8B%E7%BB%8D


5、snowflake(雪花算法)方案
这种方案大致来说是一种以划分命名空间(UUID也算,由于比较常见,所以单独分析)来生成ID的一种算法,这种方案把64-bit分别划分成多段,分开来标示机器、时间等,比如在snowflake中的64-bit分别表示如下图(图片来自网络)所示:
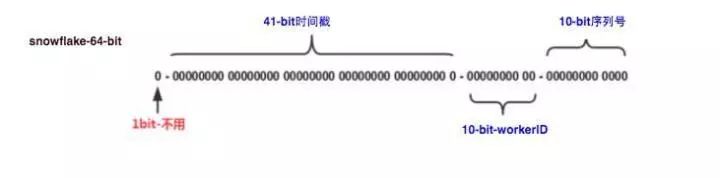
- 第一个bit位(1bit):Java中long的最高位是符号位代表正负,正数是0,负数是1,一般生成ID都为正数,所以默认为0。
- 时间戳部分(41bit):毫秒级的时间,不建议存当前时间戳,而是用(当前时间戳 -
固定开始时间戳)的差值,可以使产生的ID从更小的值开始;41位的时间戳可以使用69年,(1L << 41) / (1000L 60 60 24 365) = 69年 - 工作机器id(10bit):也被叫做workId,这个可以灵活配置,机房或者机器号组合都可以。
- 序列号部分(12bit),自增值支持同一毫秒内同一个节点可以生成4096个ID
10-bit机器可以分别表示1024台机器。如果我们对IDC划分有需求,还可以将10-bit分5-bit给IDC,分5-bit给工作机器。这样就可以表示32个IDC,每个IDC下可以有32台机器,可以根据自身需求定义。12个自增序列号可以表示2^12个ID,理论上snowflake方案的QPS约为409.6w/s,这种分配方式可以保证在任何一个IDC的任何一台机器在任意毫秒内生成的ID都是不同的。
这种方式的优缺点是:
优点:
- 毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
- 不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
- 可以根据自身业务特性分配bit位,非常灵活。
缺点:
- 强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
应用举例Mongdb objectID
MongoDB官方文档 ObjectID可以算作是和snowflake类似方法,通过“时间+机器码+pid+inc”共12个字节,通过4+3+2+3的方式最终标识成一个24长度的十六进制字符。
6、分布式开源项目