文章目录
- 1. 多线程案例
- 1.1 单例模式
- 1.1.1 饿汉模式
- 1.1.2 懒汉模式
- 1.1.3 多线程下的单例模式
- 1.2 阻塞队列
- 1.2.1 阻塞队列定义
- 1.2.2 生产者消费者模型的意义
- 1.2.4 标准库中的阻塞队列
- 1.2.5 实现阻塞队列
- 1.2.6 用阻塞队列实现生产者消费者模型
- 1.3 实现定时器
- 1.3.1 标准库中的定时器
- 1.3.2 自己实现定时器
- 1.4 线程池
- 1.4.1 什么是线程池
- 1.4.2 标准库中的线程池
- 1.4.3 自己实现简答的线程池
1. 多线程案例
1.1 单例模式
单例模式是校招中最常考的设计模式之⼀
那什么是设计模式呢?
设计模式好⽐象棋中的"棋谱",软件开发中也有很多常⻅的"问题场景".
针对这些问题场景,⼤佬们总结出了⼀些固定的套路,按照这个套路来实现代码,也不会吃亏
设计模式是一种软性规定,遵守设计模式,代码的下限就被兜住了
单例模式就是单个实例(对象)
摸各类,在一个进程中,只应该创建出一个实例,使用单例模式,既可以对代码进行一个更严格的校验和检查
此处介绍两种最基本的实现方式
(1)饿汉模式
(2)懒汉模式
1.1.1 饿汉模式
“饿汉模式”单例模式中一种简单的写法
所谓 “饿” 形容 “非常追切”
实例是在类加载的时候就创建了,创建时机非常早,相当于程序一启动,实例就创建了
就使用 “饿汉” 形容 “创建实例非常迫切,非常早”
//就期望这个类只有唯一一个实例(一个进程中)
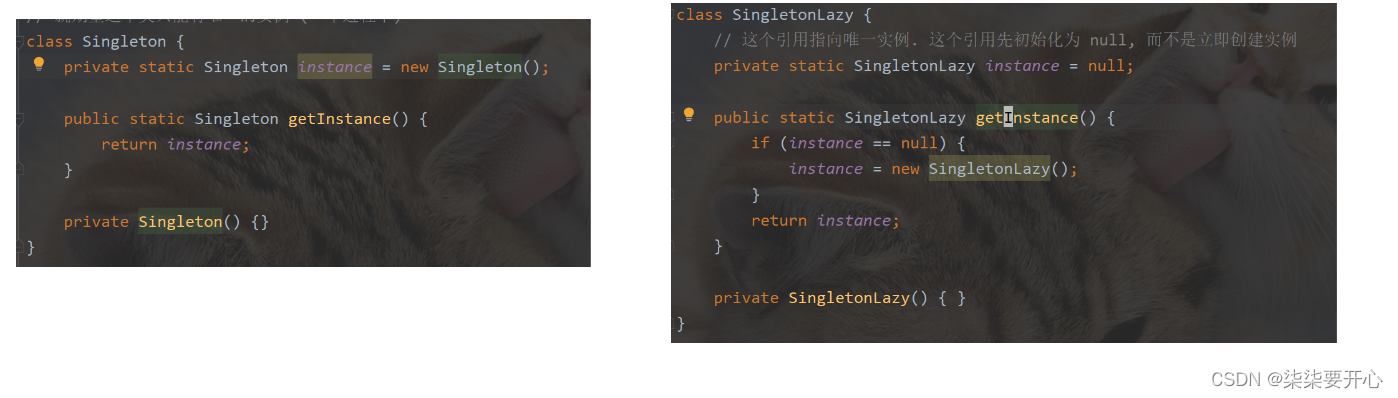
class Singleten {private static Singleten instance = new Singleten();//这个引用,就是我们期望创建出的唯一的实例引用public static Singleten getSingleten() {return instance;}private Singleten() {}
}public class ThreadDemo26 {public static void main(String[] args) {Singleten s = Singleten.getSingleten();Singleten s2 = Singleten.getSingleten();System.out.println(s == s2);}
}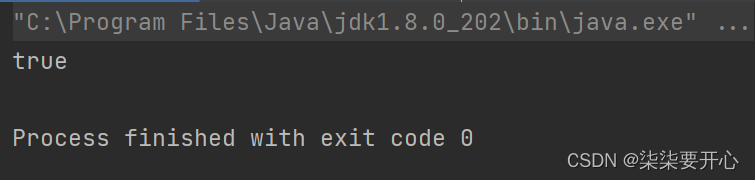


其他代码想要使用这个类的实力,就需要通过getSingleten 进行获取,不应该在其他代码中重新 new这个对象,而是使用这个方法获取发哦线程的对象

这个时候其他方法就没法 new ,只能使用 getSingleten
1.1.2 懒汉模式
懒汉模式和饿汉模式相比,创建的时机不太一样
创建实例的时机会更晚,直到第一次使用的时候,才会创建实例
在计算机中,这种懒汉模式很有意义,因为在实际中,加载一个数据可能会很大,但是懒汉模式会只加载一小部分,这样的话会节省不少内存
在创建懒汉模式的时候,先不初始化,先吧初始化设为 null

在下面进入 if 之后,如果是首次调用 getInstance 实例是null,就会创建新的实例
如果是后续再次调用,那么 instance 不是 null,这样就不会创建新的实例
这样设置,也会保证实例只有一个,同时创建实例的时机就是第一次调用 getInstance
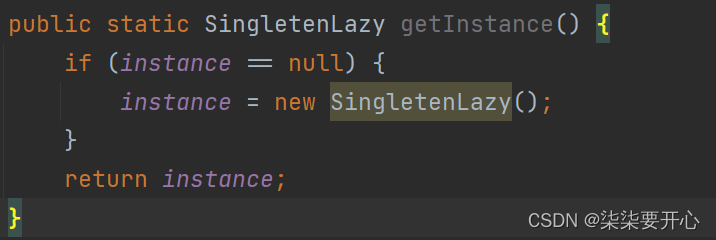
//懒汉模式实现单例模式
class SingletenLazy {private static SingletenLazy instance = null;public static SingletenLazy getInstance() {if (instance == null) {instance = new SingletenLazy();}return instance;}private SingletenLazy(){}
}public class ThreadDemo27 {public static void main(String[] args) {SingletenLazy s1 = SingletenLazy.getInstance();SingletenLazy s2 = SingletenLazy.getInstance();System.out.println(s1 == s2);}
}
1.1.3 多线程下的单例模式
在上面的懒汉模式和饿汉模式里面,哪个是线程安全的呢?
在饿汉模式中,getInstance 直接返回了 Instance 实例,其实只是一个读操作,这是线程安全的
然而在懒汉模式中,在 if 里面读,在new 里面写,这很明显不是线程安全的
懒汉模式详解:

如图所示,在 t1 线程走到 if 的时候,很有可能 t2 线程也开始,并且也进入到了 t2,那么就会进入 t2 new 一个新的实例,然后接着执行,又 new 了一个对象
这个时候,就有了两个对象,因此会是线程不安全的
那么我们如何让懒汉模式变成线程安全的呢?
这里我们就要用到前面所学的 synchronized
但是要注意,synchronized 必须要写到 if 的外面,因为我们需要把 if 和 new 进行打包,这样在 new 新的实例的时候,才能保证县城安全
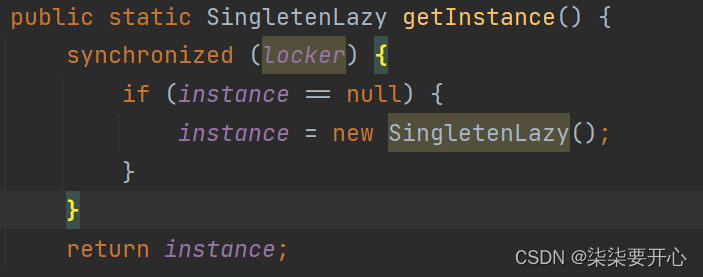
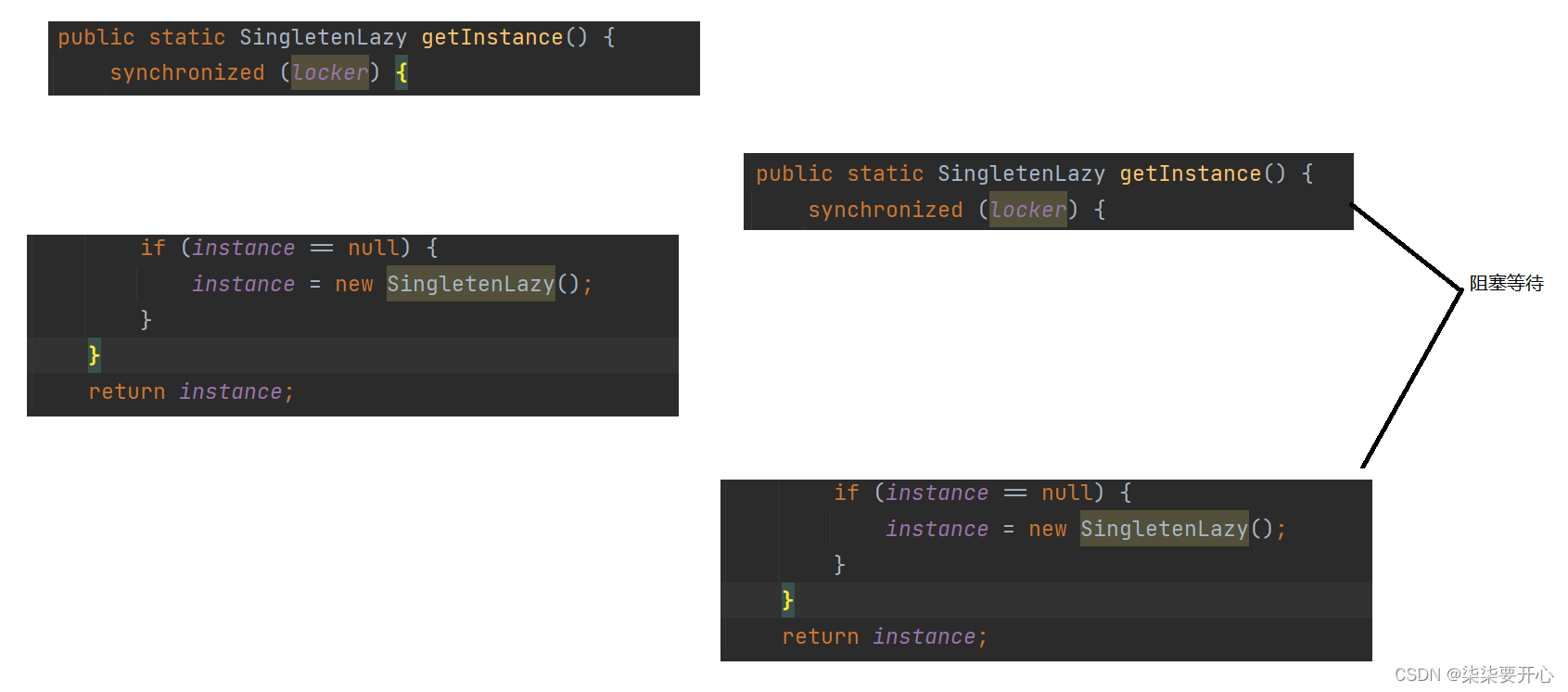
这样就可以保证,一定是 t1 执行完 new 操作,执行完修改 instance 之后,再回到 t2 执行 if 条件
t2 的 if 条件就不会成立了,t2 直接返回
但是上面的代码还是有问题,因为在创建完第一个实例,后面再次调用 getInstance 就是重复操作,线程本身是不会有现成安全问题的
这个时候每次调用,会让效率很低,因为线程阻塞会导致性能下降,会有很大的影响
这个时候,我们可以在外面套上一层 if ,用来判断我是否需要加锁
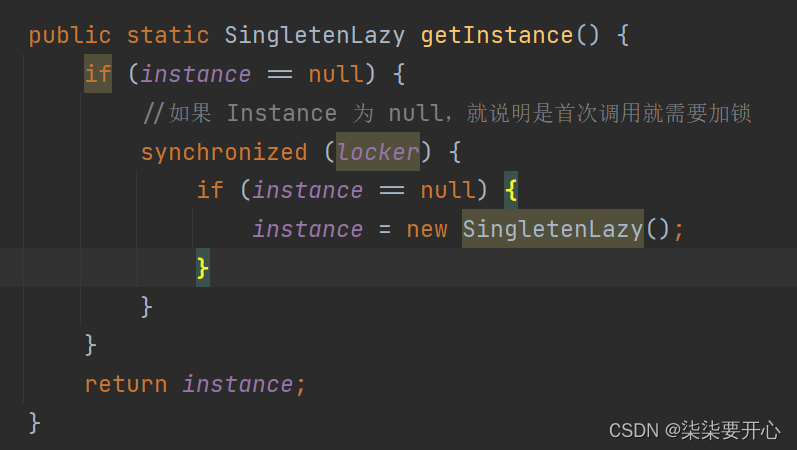
这样两个 if 的代码在多线程中是很重要的,由于线程的可调度性,如果不加if,线程可能会出现不同的结果
第一层 if 判断的是是否要加锁
第二层 if 判断的是是否要创建对象
这样就可以保证线程安全和执行效率了
这样的代码就被称为“双重校验锁”
但是,这个代码还是有问题的
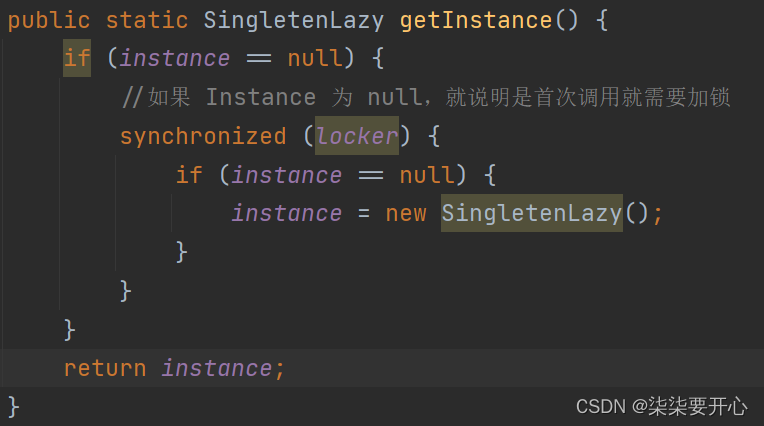
这就是“指令重排序”,引起的线程问题
什么是“指令重排序”呢?
指令重排序,也是编译器优化的一种方式
就是调整原有的执行顺序,保证逻辑不变的前提下,提高程序的效率
在上述代码中,最容易出现指令重排序的就是 new
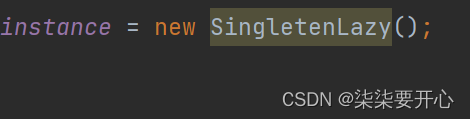
这条指令其实包含三个步骤:
- 申请一段内存空间
- 在这个内存上调用构造方法,常见出这个实例
- 把这个内存地址赋给 Instance 引用变量
正常情况下是 1 2 3 来执行,但是编译器可能会优化为 1 3 2 的循序来执行
但是如果在多线程就可能会出现问题
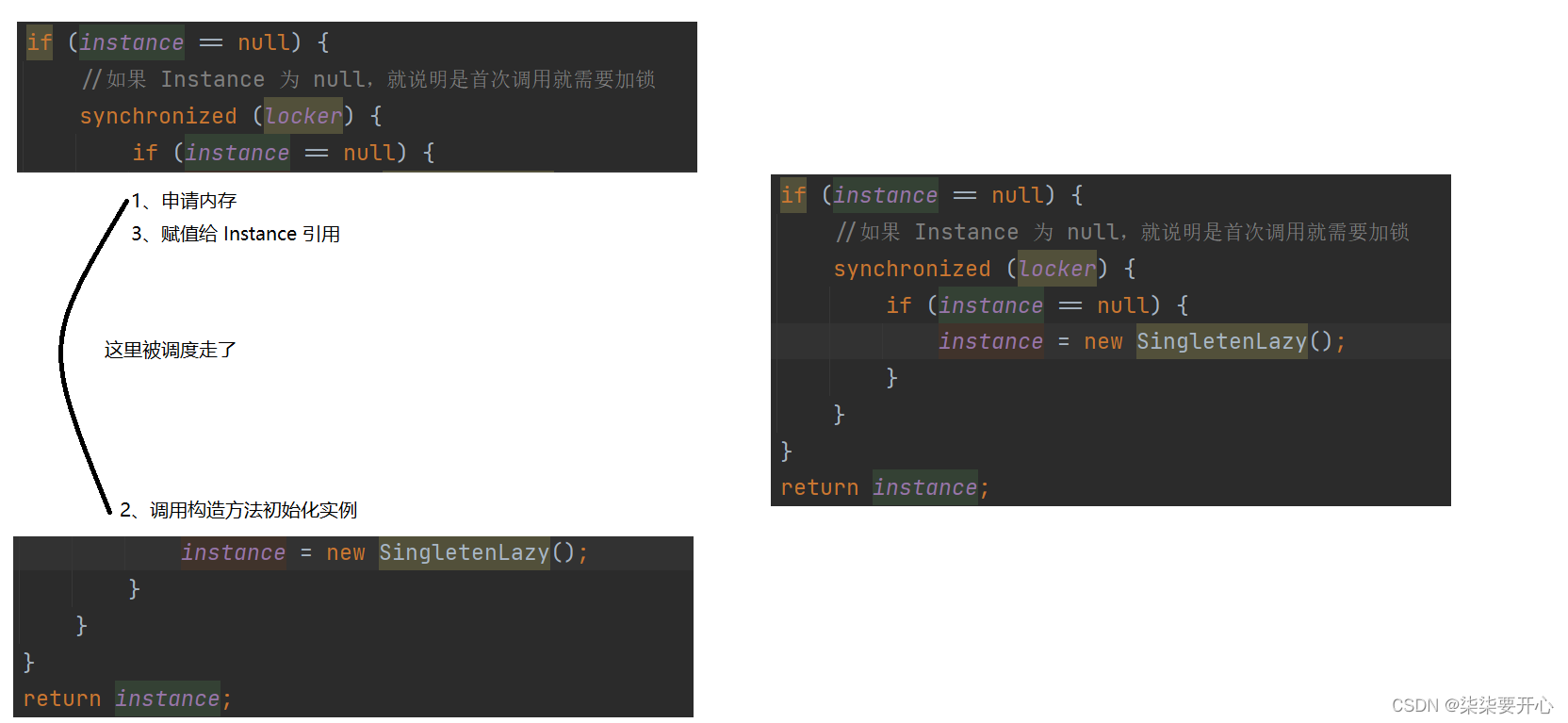
在上图中,t1 只执行了两步,刚给Instance 赋值,这个时候 instance 就已经不是 null 了,但是这个对象依然没有初始化
所以 进入t2 并不会触发 if 进行加锁,也不会进行堵塞,这样就会直接 return
但是由于 t1 并没有初始化结束,这个时候使用 instance 里面的属性或者方法,就会出错,导致代码的逻辑出行问题
如果先执行 2 后执行 3,这样的错误就不会出现
那么解决上述问题,我们需要 volatile
volatile 有两个功能:
- 保证内存可见性,每次访问变量必须都要重新读取内存,而不会优化到寄存器/缓存中
- 禁止指令重排序,针对这个被 volatile 修饰的变量的读写操作相关的只i选哪个,是不能被重排序的

这个时候这个变量的读写操作,就不会进行重排序了
1.2 阻塞队列
1.2.1 阻塞队列定义
阻塞队列,就是基于普通队列做出的扩展
1、阻塞队列是线程安全的
2、阻塞队列具有阻塞特性
(1)如果针对一个已经满了的队列进行入队列,此时入队列操作就会阻塞,一直阻塞到队列不满(其他线程出队列元素)之后
(2)如果针对一个已经空了的队列进行出队列,此时出队列操作就会阻塞,一直阻塞到队列不空(其他线程入队列元素)之后
阻塞队列的用处很大,基于阻塞队列,就可以实现“生产者消费者模型”
那什么是“生产者消费者模型”呢?
生产者消费者模型描述的是一种多线程编程的方法
比如三个人 a b c 分工协作,a 负责生产,通过服务器传给 b 和 c ,b 和 c 拿 a 生产的东西进行再加工,那么 a 就是生产者,b 和 c 就是消费者,服务器就相当于“阻塞队列”
假如,a 的生产速度很快,b 和 c 很慢,那么这个时候 a 就需要等待 b 和 c,反之亦然,这个特性就是阻塞队列
1.2.2 生产者消费者模型的意义
生产者消费者模型在实际开发中的意义
1、引入生产者消费者模型,就可以更好的做到“解耦合”
在实际开发中,经常会使用到“分布式系统”,并且通过服务器之间的网络通信,最终完成整个功能
有的时候入口服务器和用户服务器 和 商品服务器关系太密切,就会导致一处崩溃处处崩溃
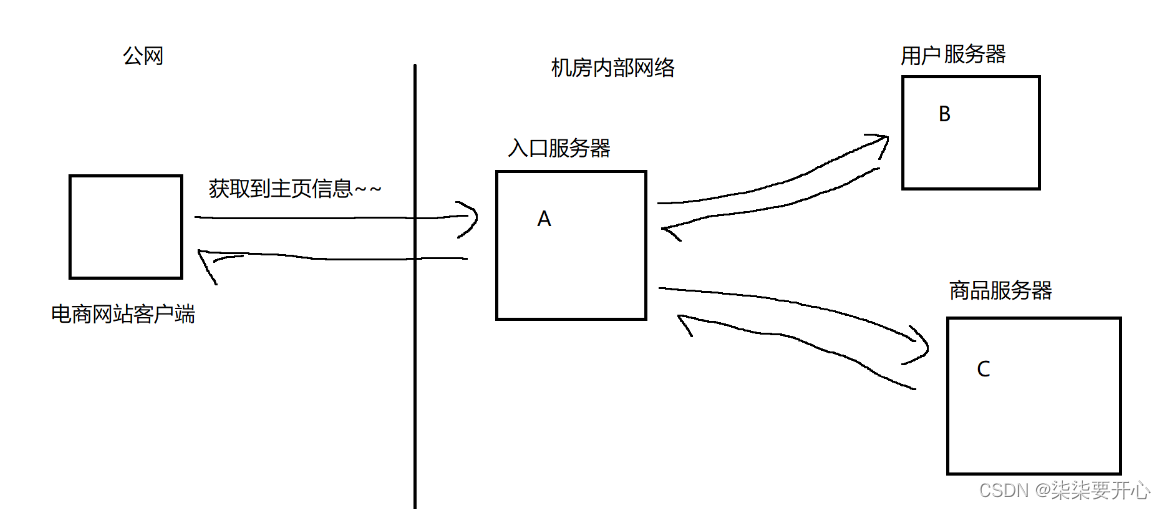
这个时候我们就需要使用生产者消费者模型,使用阻塞队列,来降低耦合
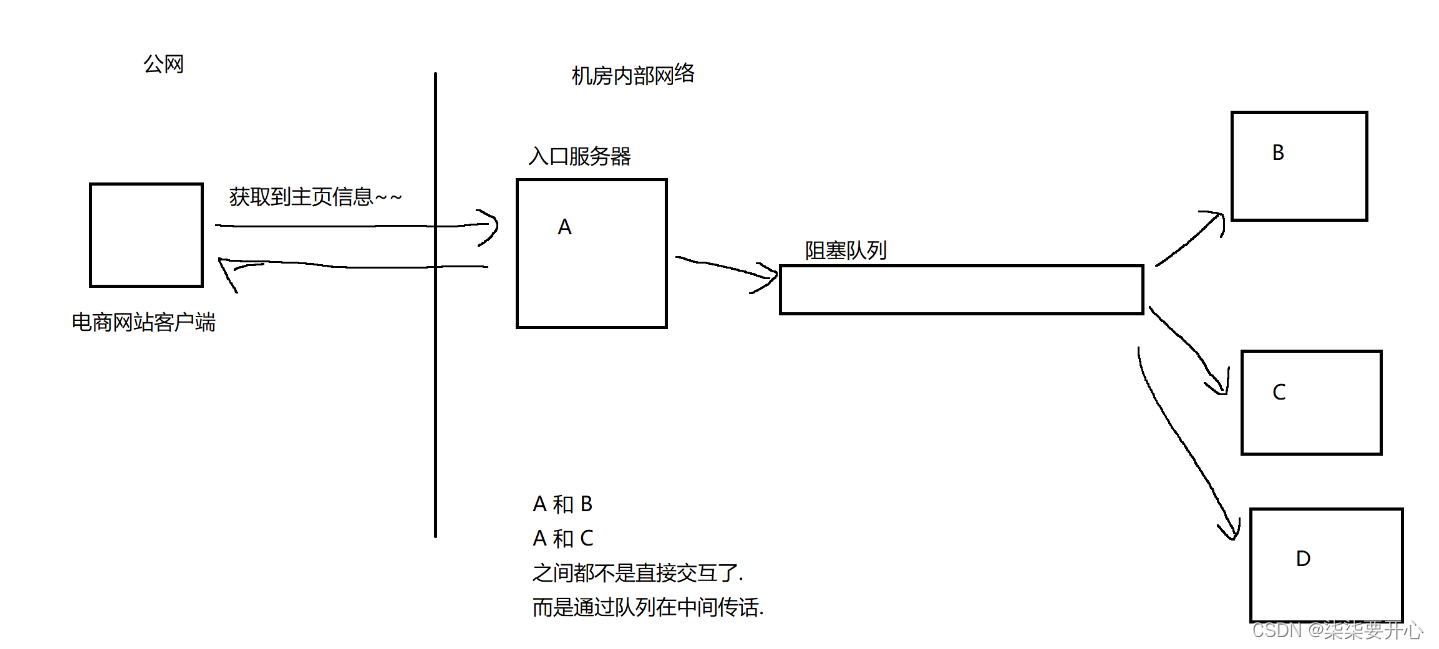
当我们引入阻塞队列,最明显的代价,就是余姚增加机器,引入更多的硬件资源
1)上述的阻塞队列,并非是简单的数据结构,而是基于这个数据结构实现的服务器程序,又被部署到单独的主机上了
2)会导致整个系统的结构更加复杂,需要维护的服务器更多了
3)引入了阻塞队列,经过队列的转发,中间是有一定的开销的,会导致性能下降
2、削峰填谷
当服务器遇到了类似像 “三峡大坝遇到降雨量骤增的” 这样的请求骤增的时候,就会进行“削峰填谷”
这里的“峰”和“谷”都不是长时间持续的,而是短时间出现的
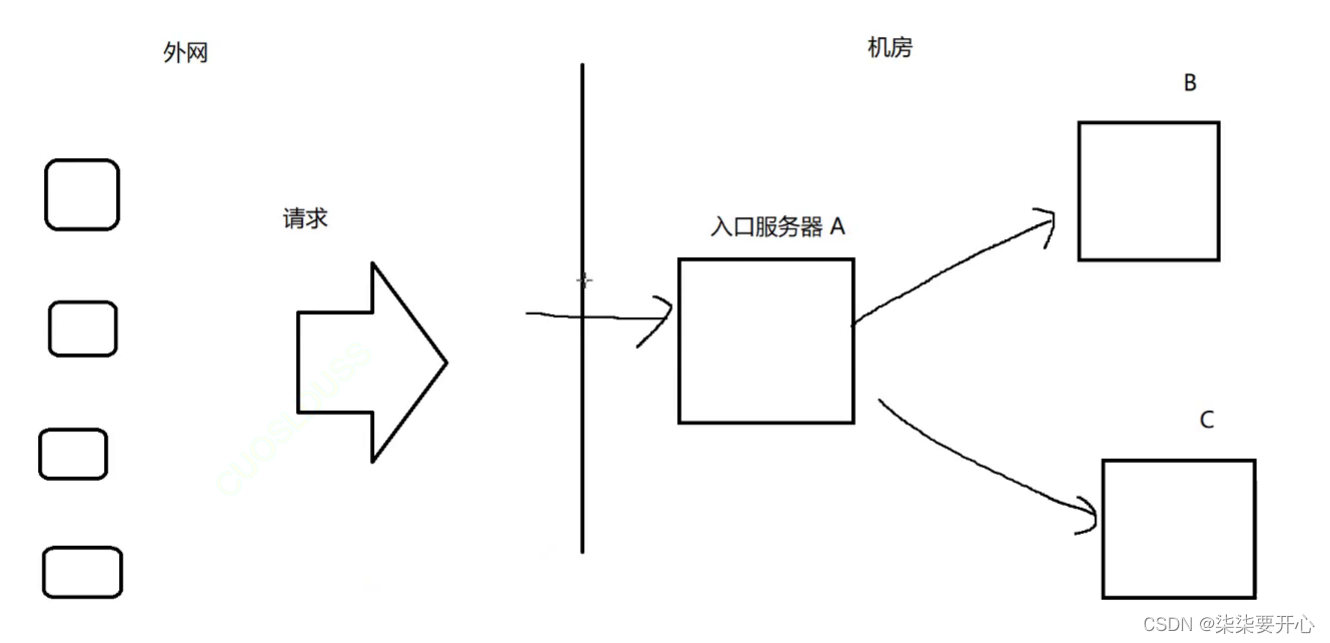
如果外网的请求突然骤增,那么入口服务器 A 的请求数量就会增加很多,压力就会变大,那么 B 和 C 的压力也会很大
那么为什么,请求多的时候,服务器就会挂掉?
因为,服务器处理每个请求,都是需要消耗硬件资源的(包括不限于,cpu,内存,硬盘,网络带宽)
即使一个请求消耗的资源比较少,但是请求暴增,总的消耗也会急剧增多,这样服务器就无法反应了
当我们引入阻塞队列/消息队列的时候,情况就会发生改变
阻塞队列:是一种数据结构
消息队列:基于阻塞队列实现服务器程序
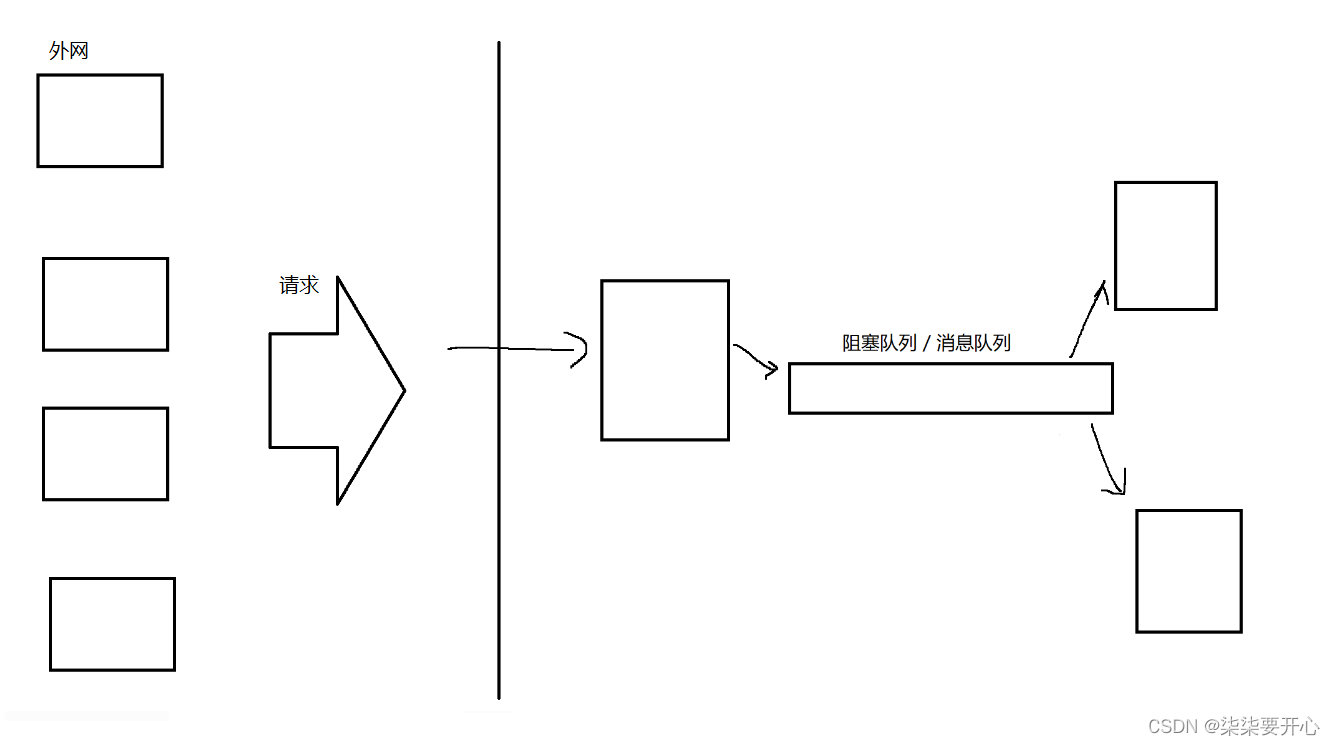
这个时候,即使外界请求出现峰值,也是由队列承担请求,后面的依然会按照原来的速度取请求
由于队列只是存储数据,抗压能力是比较强的
但是如果请求不断增加,还是可能会挂的
1.2.4 标准库中的阻塞队列
在 Java 标准库中内置了阻塞队列
• BlockingQueue 是⼀个接⼝,真正实现的类是 LinkedBlockingQueue
• BlockingQueue 下有以下之中类,ArrayBlockingQueue,LinkedBlockingQueue,PriorityBlockingQueue
• put ⽅法⽤于阻塞式的⼊队列,take ⽤于阻塞式的出队列
• BlockingQueue 也有 offer,poll,peek 等⽅法,但是这些⽅法不带有阻塞特性
put 入队列
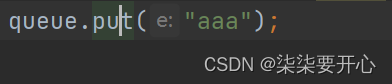
使用 put 和 offer 一样都是入队列,但是 put 是带有阻塞功能,offer 没有带阻塞(队列满了会返回结果)
take 出队列
take 方法用来出队列,也是带有阻塞功能的
public static void main(String[] args) throws InterruptedException {BlockingQueue<String> queue = new ArrayBlockingQueue<>(100);queue.put("aaa");String elem = queue.take();System.out.println(elem);elem = queue.take();System.out.println(elem);}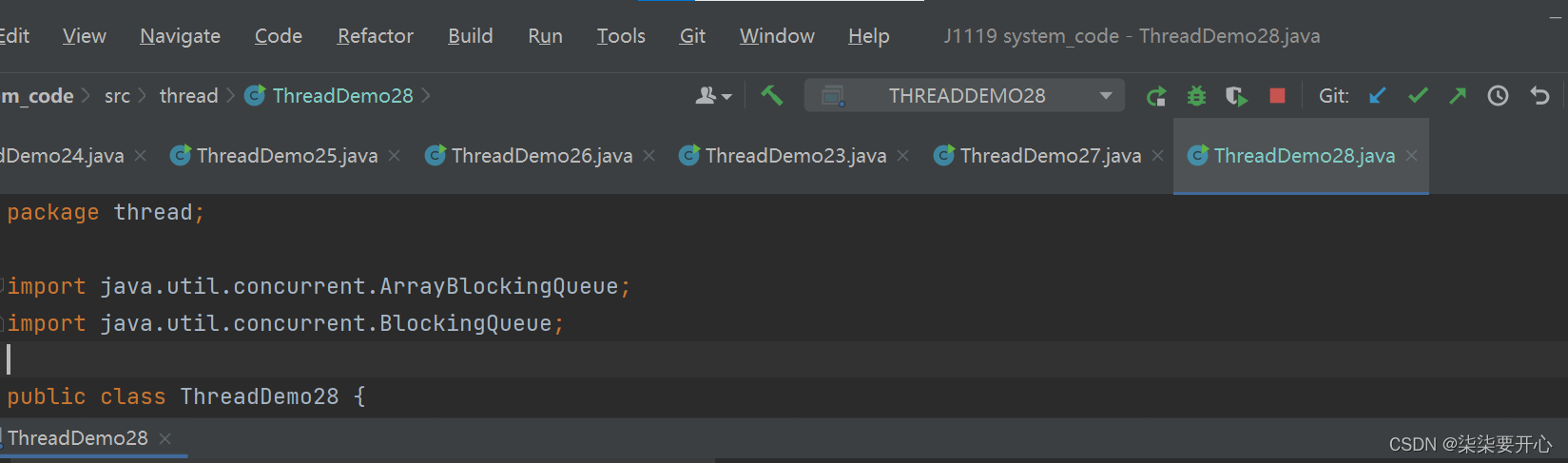
由于 take 是带阻塞的队列,如果队列中没有值就会阻塞,如上述所示,代码打印一行结汇阻塞
1.2.5 实现阻塞队列
步骤:
1、先实现普通队列
2、再加上线程安全
3、再加上阻塞功能
对于第一步,我们使用数组来实现一个环形队列
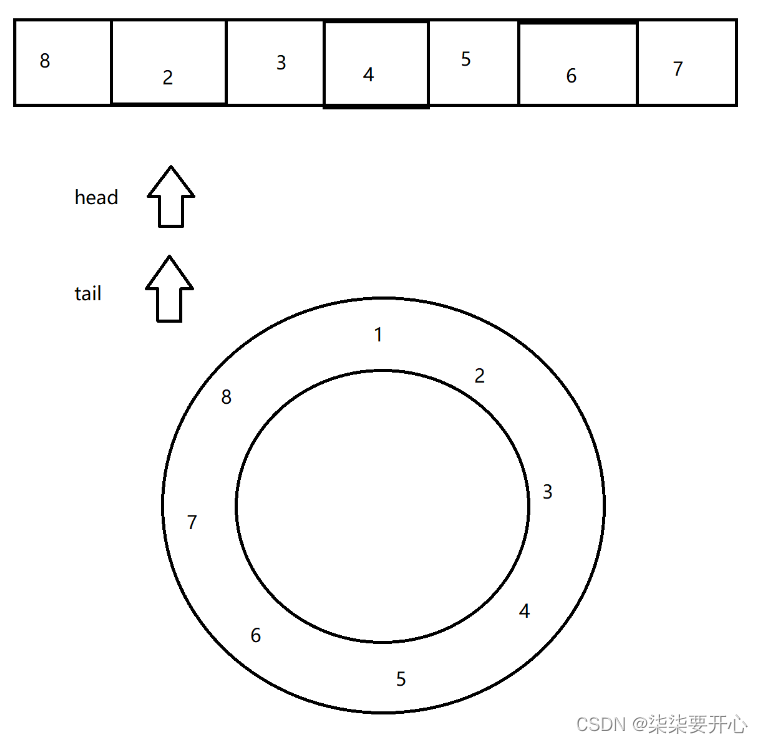
这个时候我们要注意什么时候队列空 和 队列满
(1)浪费一个给子,tail 最多走到 head 的前一个位置
(2)引入 size 变量(常用)
class MyBlockingQueue {private String[] elems = null;private int head = 0;private int tail = 0;private int size = 0;public MyBlockingQueue(int capacity) {elems = new String[capacity];}public void put(String elem) {if (size >= elems.length) {//队列满了//后续需要让这个代码能够阻塞return;}//新的元素放到 tail 指向的位置上elems[tail] = elem;tail++;if (tail >= elems.length) {tail = 0;}size++;}public String take() {if (size == 0) {//队列空了//后续也要让这个代码阻塞return null;}//取出 head 位置的元素并返回String elem = elems[head];head++;if (head >= elems.length) {head = 0;}size--;return elem;}
}public class ThreadDemo29 {public static void main(String[] args) {MyBlockingQueue queue = new MyBlockingQueue(1000);queue.put("aaa");queue.put("bbb");queue.put("ccc");queue.put("ddd");String elem = "";elem = queue.take();System.out.println("elem: " + elem);elem = queue.take();System.out.println("elem: " + elem);elem = queue.take();System.out.println("elem: " + elem);elem = queue.take();System.out.println("elem: " + elem);}
}
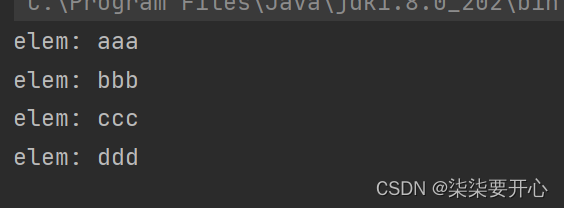
这个时候我们最基础的队列就写完了
接下来,我们就要引入锁,解决线程安全问题
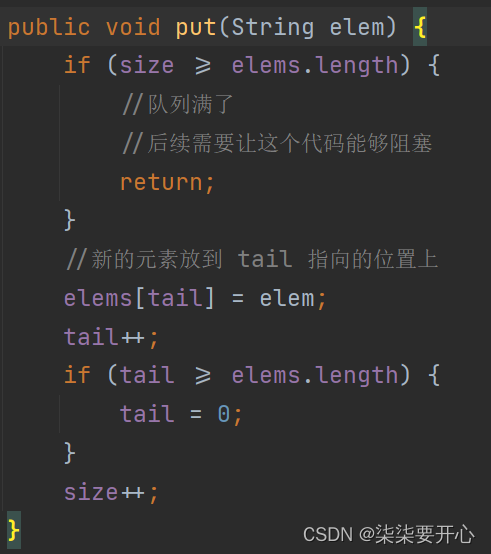
在 put 里面,if 下面的操作都是“写”操作,必须要用锁包裹起来
上面的 if 操作也是需要写到锁里面的,如果不写,就会导致队列中多加一个
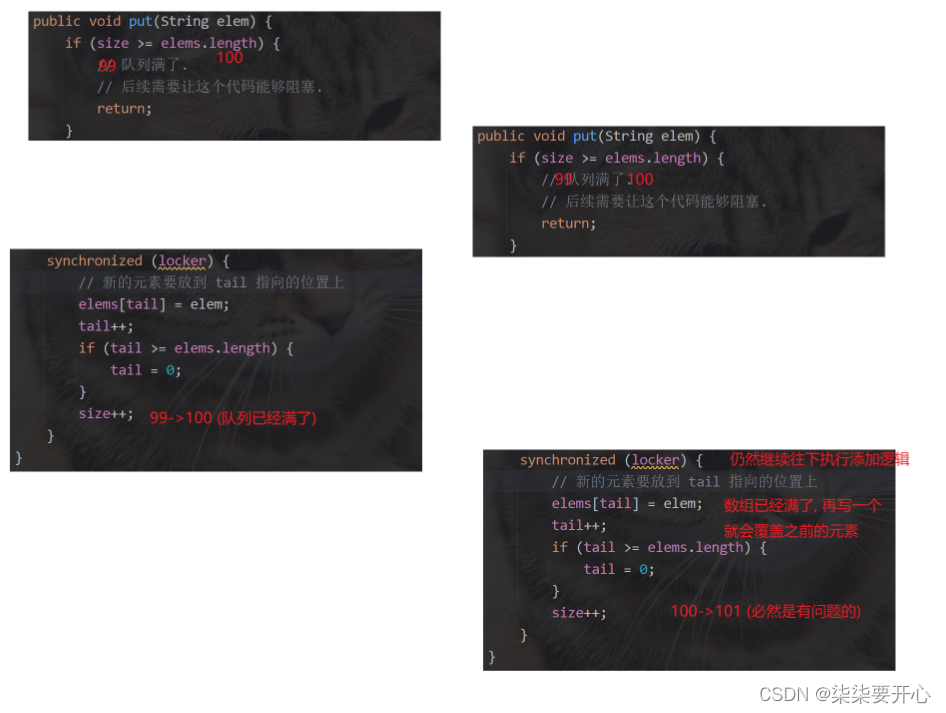
public void put(String elem) {//锁加到这里和加到方法上本质是一样的,加到方法上是给 this 加锁,此处是给 locker 加锁synchronized (locker) {if (size >= elems.length) {//队列满了//后续需要让这个代码能够阻塞return;}//新的元素放到 tail 指向的位置上elems[tail] = elem;tail++;if (tail >= elems.length) {tail = 0;}size++;}}public String take() {String elem = null;synchronized (locker) {if (size == 0) {//队列空了//后续也要让这个代码阻塞return null;}//取出 head 位置的元素并返回elem = elems[head];head++;if (head >= elems.length) {head = 0;}size--;return elem;}}
}接下来,我们来考虑如何阻塞
class MyBlockingQueue {private String[] elems = null;private int head = 0;private int tail = 0;private int size = 0;//准备一个锁对象private Object locker = new Object();public MyBlockingQueue(int capacity) {elems = new String[capacity];}public void put(String elem) throws InterruptedException {//锁加到这里和加到方法上本质是一样的,加到方法上是给 this 加锁,此处是给 locker 加锁synchronized (locker) {if (size >= elems.length) {//队列满了//后续需要让这个代码能够阻塞locker.wait();}//新的元素放到 tail 指向的位置上elems[tail] = elem;tail++;if (tail >= elems.length) {tail = 0;}size++;//入队列成功之后进行唤醒locker.notify();}}public String take() throws InterruptedException {String elem = null;synchronized (locker) {if (size == 0) {//队列空了//后续需要让这个代码阻塞locker.wait();}//取出 head 位置的元素并返回elem = elems[head];head++;if (head >= elems.length) {head = 0;}size--;//元素出队列之后,进行唤醒locker.notify();return elem;}}
}
wait 要加入到 if 中,也要在 synchronized 里面
队列不满地时候,唤醒,也就是在出队列之后,进行唤醒
队列空了,再出队列,同样也需要阻塞,同样是在另一个队列成功后的线程中唤醒
我们的队列,一定是空或者是满的,不能即空又满
但是,上述代码里面依然存在问题,当 A 线程执行 put ,到了 wait 等待
这个时候 B 线程也执行 put ,到了wait 等待接下来 take 一个数,执行到了 notify
这个时候 A 被唤醒,接着往下走
但是 B 很有可能会被 A 代码下面的 notify 给唤醒
这样就出现了错误
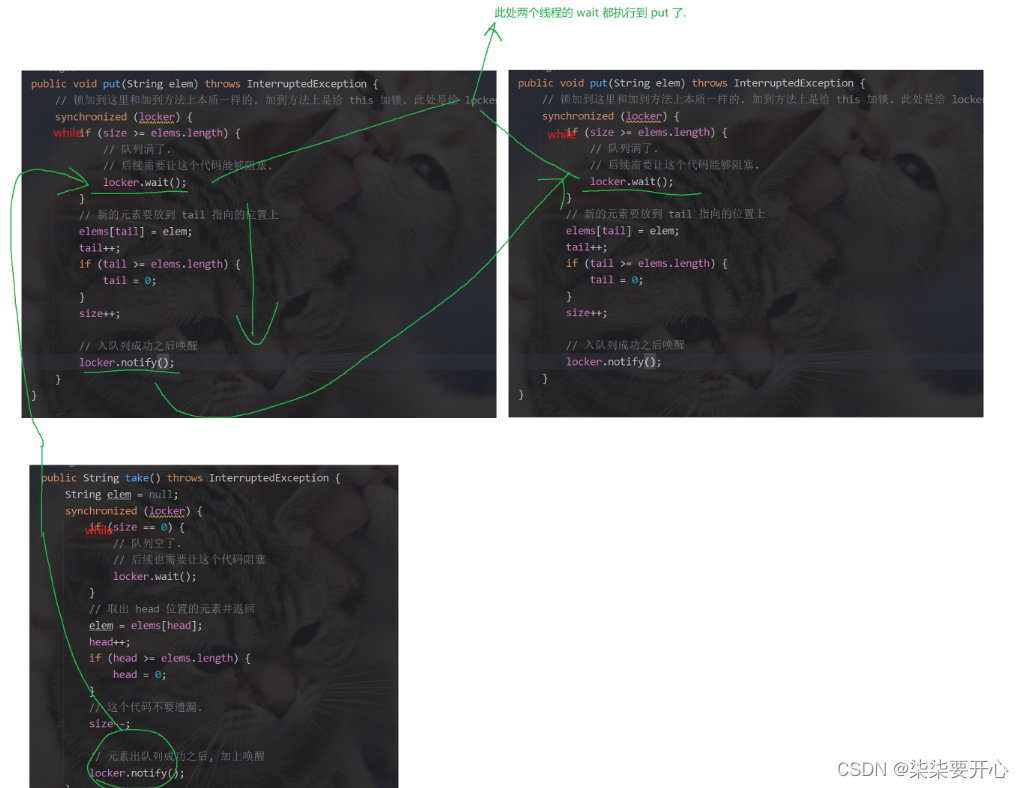
这个时候,我们仅需把 if 改成 while 即可
if 只能判断一次
一旦程序进入阻塞,再次被唤醒,中间的时间会非常长,会出现变故
这个时候有了变故之后,就难以保证,你的条件是否仍然满足
如果改成 while 之后,意味着,wait 唤醒之后,再判断一次条件
wait 之前判定一次,唤醒之后再判定一次,相当于多做了一步确认操作
如果再次确认,发现队列还是满的,就继续等待
class MyBlockingQueue {private String[] elems = null;private int head = 0;private int tail = 0;private int size = 0;//准备一个锁对象private Object locker = new Object();public MyBlockingQueue(int capacity) {elems = new String[capacity];}public void put(String elem) throws InterruptedException {//锁加到这里和加到方法上本质是一样的,加到方法上是给 this 加锁,此处是给 locker 加锁synchronized (locker) {while (size >= elems.length) {//队列满了//后续需要让这个代码能够阻塞locker.wait();}//新的元素放到 tail 指向的位置上elems[tail] = elem;tail++;if (tail >= elems.length) {tail = 0;}size++;//入队列成功之后进行唤醒locker.notify();}}public String take() throws InterruptedException {String elem = null;synchronized (locker) {while (size == 0) {//队列空了//后续需要让这个代码阻塞locker.wait();}//取出 head 位置的元素并返回elem = elems[head];head++;if (head >= elems.length) {head = 0;}size--;//元素出队列之后,进行唤醒locker.notify();return elem;}}
}
这个时候就是正确的阻塞队列代码了
1.2.6 用阻塞队列实现生产者消费者模型
public static void main(String[] args) {MyBlockingQueue queue = new MyBlockingQueue(1000);//生产者Thread t1 = new Thread(() -> {int n = 1;while (true) {try {queue.put(n + "");System.out.println("生产元素 " + n);n++;Thread.sleep(500);} catch (InterruptedException e) {e.printStackTrace();}}});//消费者Thread t2 = new Thread(() -> {while (true) {try {String n = queue.take();System.out.println("消费元素 " + n);} catch (InterruptedException e) {e.printStackTrace();}}});t1.start();t2.start();}
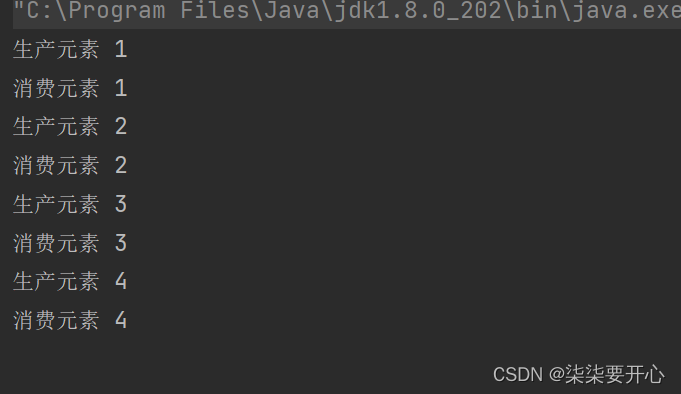
这里就是一个最简单的生产者模型
在以后得实际开发中,往往还是有多个生产者多个消费者,可有可能这
不简简单单是一个线程,也可能是独立的服务器程序,甚至是一组服务器程序
但是其最核心的还是阻塞队列,使用 synchronized 和 wait/notify 达到线程安全
1.3 实现定时器
定时器是日常开发中常用的组件工具,类似于“闹钟”
设定一个时间,当时间到了的时候,定时器自动的去执行某个逻辑
1.3.1 标准库中的定时器
在我们 java 标准库中是提供了定时器的
在实现定时器之前,我们先来看一下,java 中提供的定时器做了什么
public class ThreadDemo30 {public static void main(String[] args) {Timer timer = new Timer();//用来添加任务timer.schedule(new TimerTask() {@Overridepublic void run() {//时间到了之后,要实行的代码System.out.println("hello timer 3000");}},3000);timer.schedule(new TimerTask() {@Overridepublic void run() {System.out.println("hello timer 2000");}},2000);timer.schedule(new TimerTask() {@Overridepublic void run() {System.out.println("hello timer 1000");}},1000);System.out.println("hello main");}
}
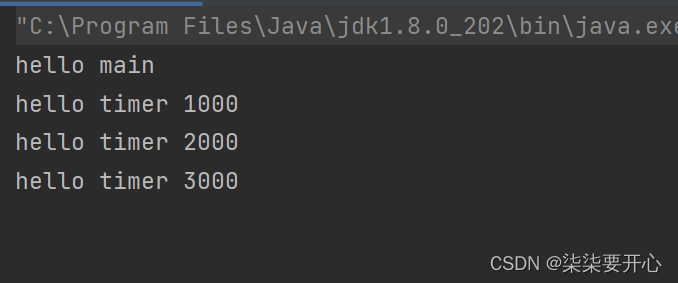
这里定义一个 timer 添加多个任务,每个任务同时会带有一个时间
这个进程并没有结束,因为 Timer 里内置了前台线程
使用 timer.cancel(); 可以让线程结束
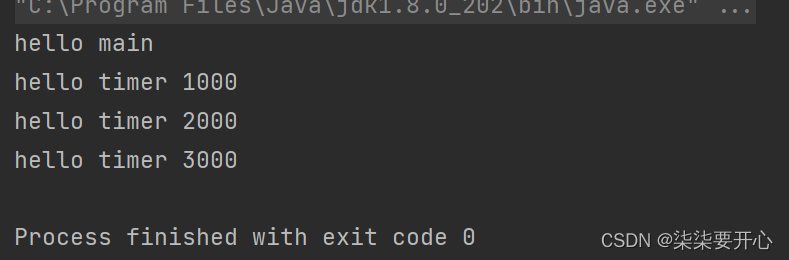
1.3.2 自己实现定时器
这个时候我们想要实现 Timer,里面需要什么内容呢?
1、需要一个线程,负责计算时间,等任务到大合适的时间,这个线程就负责执行
2、需要一个队列/数组,能够保存所有 schedule 进来的任务
这个时候们就要不断的去扫描上述队列的每个元素,到时间再执行
但是如果队列很长,这个开销就会很大
这个时候,我们实现优先级队列会更好
由于每个任务都是有时间的,用优先级队列,就不需要遍历,只看队首元素就可以了
就可以使用标准库提供的 PriorityQueue (线程不安全)
标准库也提供了 PriorityBlockingQueue (线程安全)
推荐使用 PriorityQueue,这个时候可以手动加锁
首先我们先创建一个类
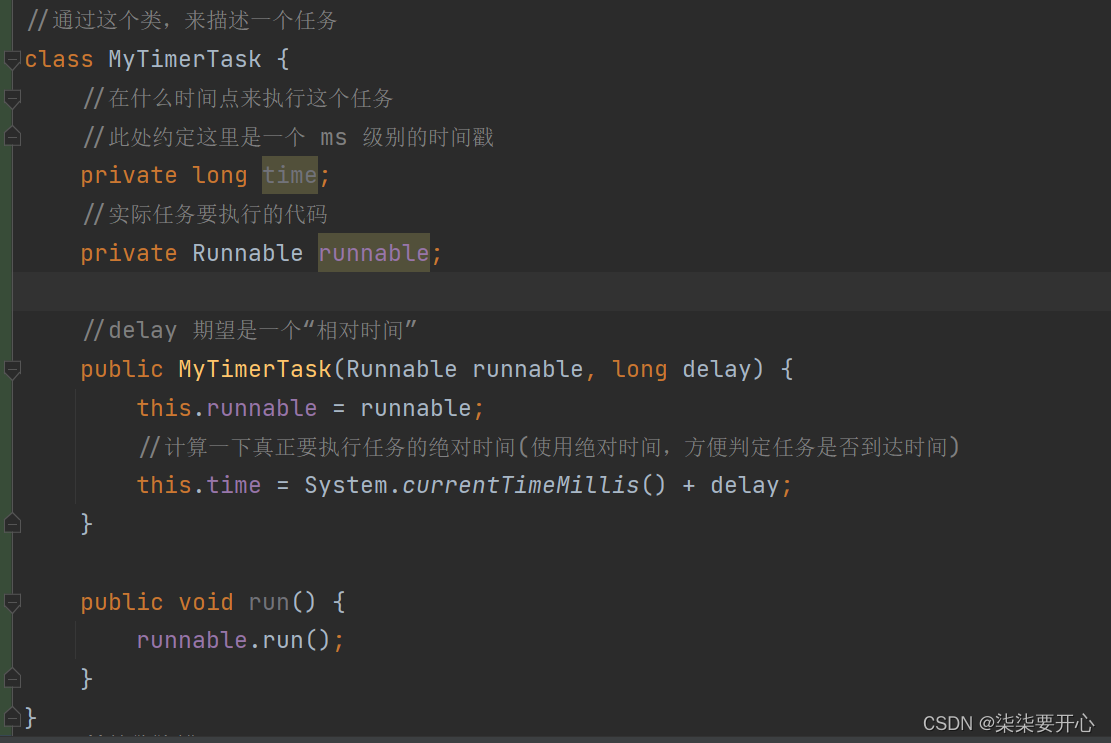
在这个类里面有一点小小的问题
问题就是,这里面没有比较呀,我们需要在这里实现equal 方法
不过本身 Object 提供了这俩方法的实现,但是有些时候,为了让 hash 表更搞笑,需要重写 equals 和 hashCode
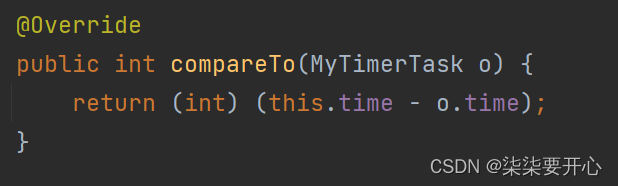
这个时候加上了比较方法,但是怎么比较呢
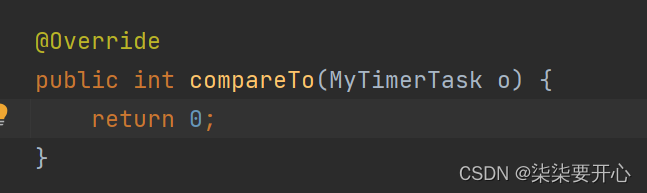
这个时候,最好的方法是试一试
接下来,我们创建好了主线程来进行添加
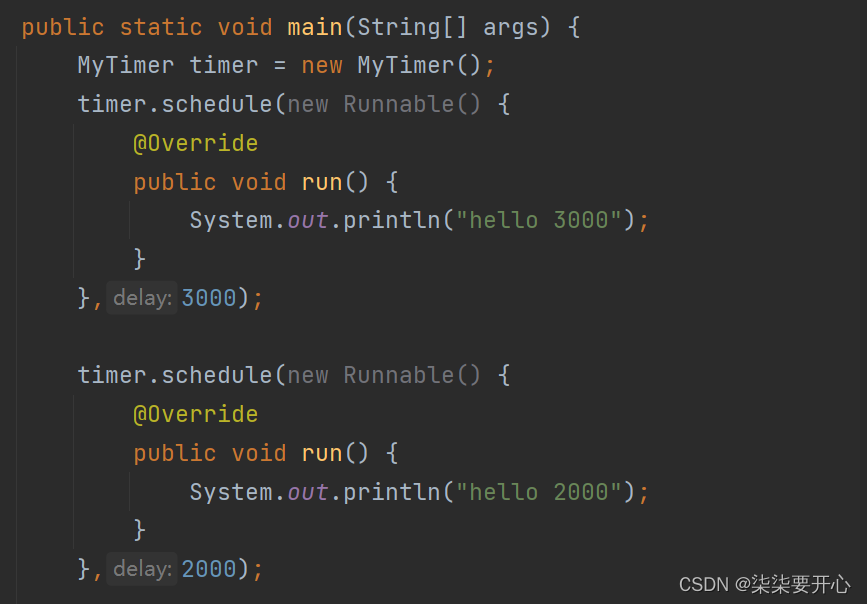
但是上面还有一个线程进行扫描
这个时候就会导致线程安全问题,我们需要对线程进行加锁
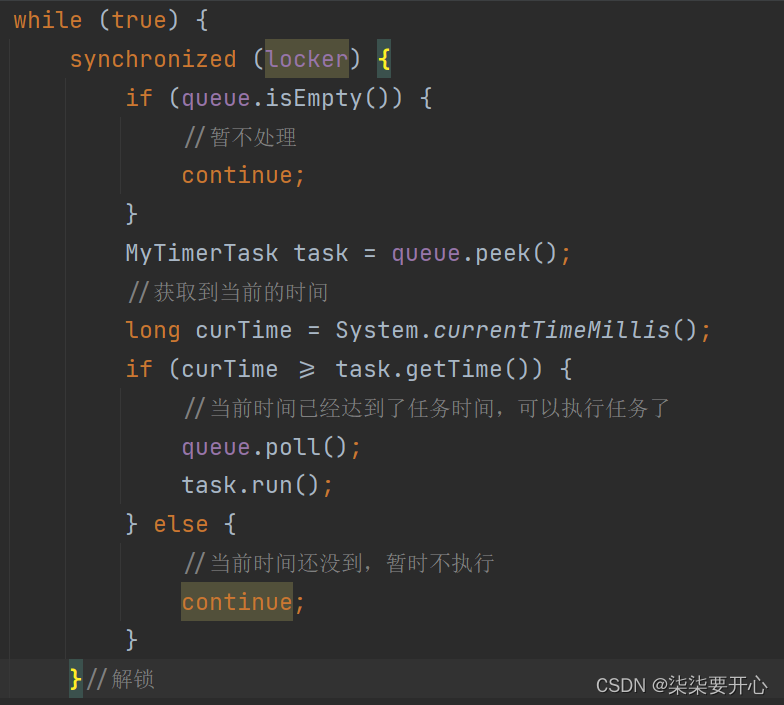
这个时候我们就加上了锁
但是这里我们思考一个问题,是否能把synchronized 放到 while 的外面呢?
是不可以的,因为在主线程中new 一个 MyTumer 的时候就进入了构造方法,进来如果直接加上锁,while又是死循环,这样就永远也解不了锁了
这个时候我们通过加锁解决了线程安全问题,但是我们还有一个问题“线程饿死”
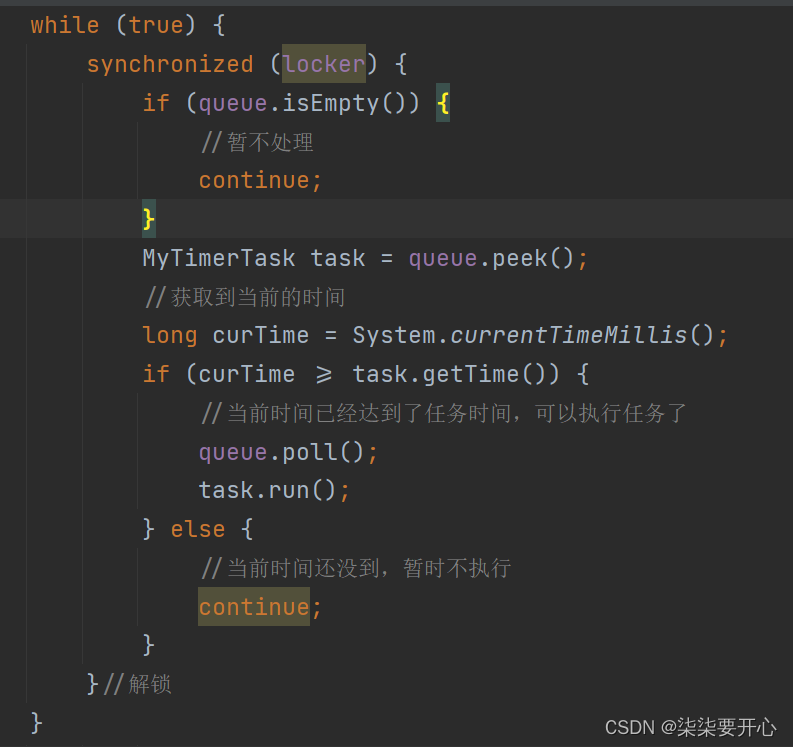
这里代码执行速度非常快,在解锁之后又会重新加锁,那么就会导致其他线程通过 schedule 想要加锁,但是加不上,就导致了线程饿死
这个时候就要引入 wait
首先我们看队列为空的时候,这个时候我们就需要等待,在添加完元素之后就可以唤醒了


接下来,我们再看如果要求唤醒的时间没有到,这个时候也是需要等待的
因为如果没有等待,这个循化会一直执行到时间到,这种代码被称为“忙等”(虽然是在等待,但是cpu一直在运算)
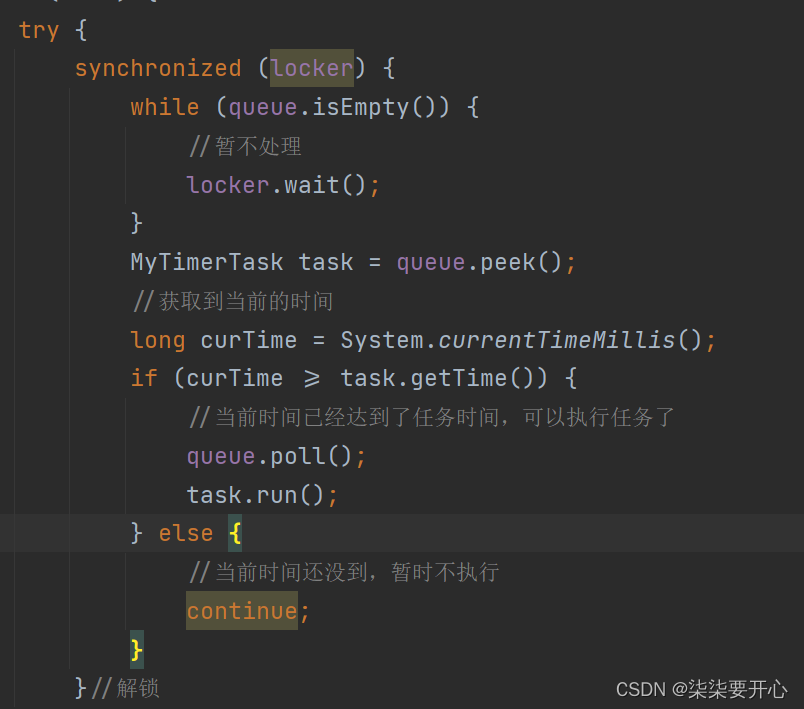
为了让 cpu 资源可以在别的线程运行的时候可以使用,这个时候我们就可以用 wait
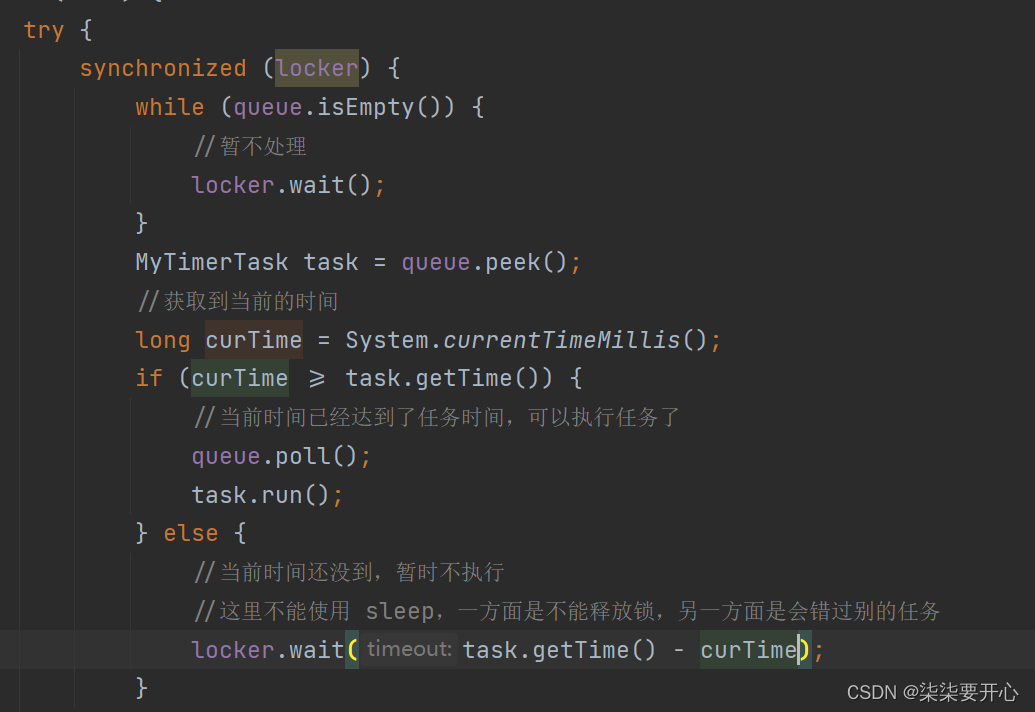
- wait 的过程中,有新的任务来了,wait 就会被唤醒,schedule 有 notify 的
这个时候需要根据新的任务,重新计算等待的时间,因为不知道这个新的任务是不是最早的任务 - wait 过程中,没有新的任务,时间到了,执行之前的这个最早的任务即可
这样我们的代码就可以正常运行了
import java.util.PriorityQueue;//通过这个类,来描述一个任务
class MyTimerTask implements Comparable<MyTimerTask>{//在什么时间点来执行这个任务//此处约定这里是一个 ms 级别的时间戳private long time;//实际任务要执行的代码private Runnable runnable;public long getTime() {return time;}//delay 期望是一个“相对时间”public MyTimerTask(Runnable runnable, long delay) {this.runnable = runnable;//计算一下真正要执行任务的绝对时间(使用绝对时间,方便判定任务是否到达时间)this.time = System.currentTimeMillis() + delay;}public void run() {runnable.run();}@Overridepublic int compareTo(MyTimerTask o) {return (int) (this.time - o.time);}
}//通过这个类来表示一个定时器
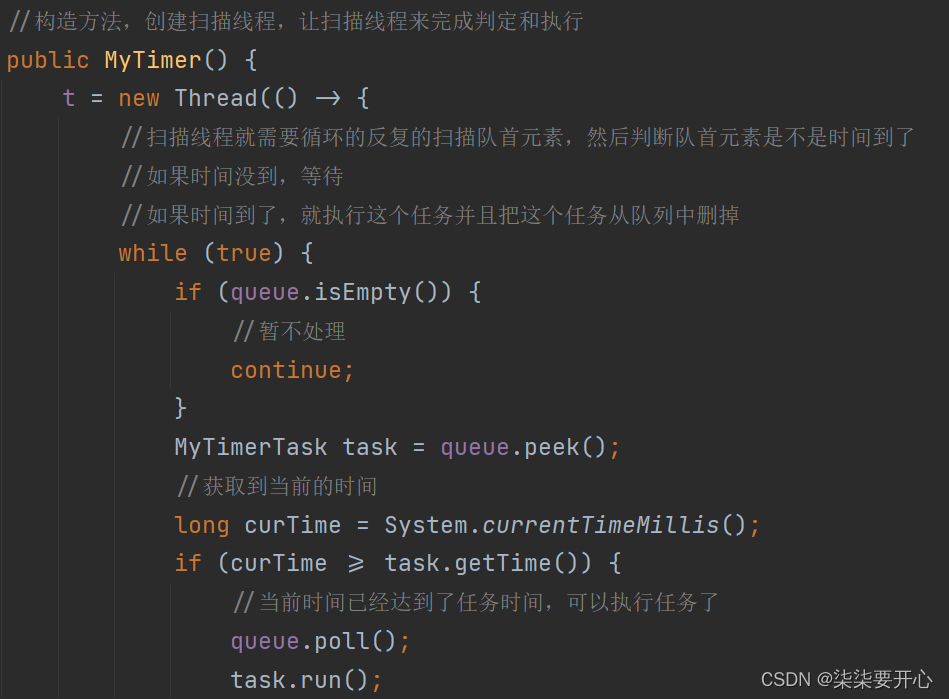
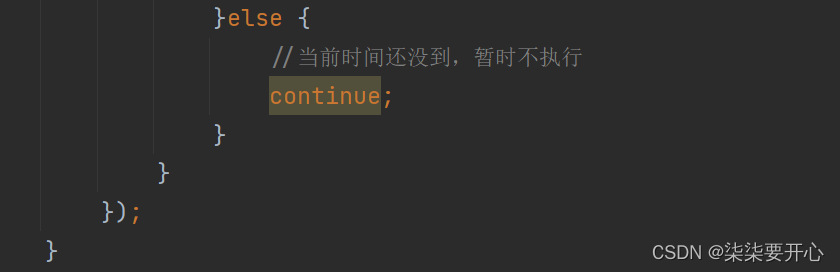
class MyTimer {//负责扫描任务队列,执行任务的线程protected Thread t = null;//任务队列private PriorityQueue<MyTimerTask> queue = new PriorityQueue<>();//创建一个锁对象,此处使用this也可以private Object locker = new Object();public void schedule(Runnable runnable, long delay) {synchronized (locker) {MyTimerTask task = new MyTimerTask(runnable, delay);queue.offer(task);//添加新的元素之后,就可以唤醒扫描线程的 wait 了locker.notify();}}public void cancel() {//结束 t 线程}//构造方法,创建扫描线程,让扫描线程来完成判定和执行public MyTimer() {t = new Thread(() -> {//扫描线程就需要循环的反复的扫描队首元素,然后判断队首元素是不是时间到了//如果时间没到,等待//如果时间到了,就执行这个任务并且把这个任务从队列中删掉while (true) {try {synchronized (locker) {while (queue.isEmpty()) {//暂不处理locker.wait();}MyTimerTask task = queue.peek();//获取到当前的时间long curTime = System.currentTimeMillis();if (curTime >= task.getTime()) {//当前时间已经达到了任务时间,可以执行任务了queue.poll();task.run();} else {//当前时间还没到,暂时不执行//这里不能使用 sleep,一方面是不能释放锁,另一方面是会错过别的任务locker.wait(task.getTime() - curTime);}}//解锁} catch (InterruptedException e) {e.printStackTrace();}}});t.start();}
}public class ThreadDemo31 {public static void main(String[] args) {MyTimer timer = new MyTimer();timer.schedule(new Runnable() {@Overridepublic void run() {System.out.println("hello 3000");}},3000);timer.schedule(new Runnable() {@Overridepublic void run() {System.out.println("hello 2000");}},2000);timer.schedule(new Runnable() {@Overridepublic void run() {System.out.println("hello 1000");}},1000);System.out.println("hello main");}
}
1.4 线程池
1.4.1 什么是线程池
池 是一个非常重要的概念,我们常见的有:常量池、数据库连接池、线程池、进程池、内存池…
其核心内容有两点:
1、提前把要用的对象准备好
2、把用完的对象也不要立即释放,先留着以备下次使用
这样是为了提高效率
进程能够解决并发编程的问题,但是冰饭创建销毁进程,成本太高了,引入了轻量级进程,这就是“线程”
但是如果创建销毁线程的频率进一步提高,这个时候我们就要想办法来优化了
解决方案有两种:
- 引入轻量级 线程 -> 也称为纤程/协程
协程本质,是程序员在用户态代码中进行调度,不是靠内核的调度器调度的,这样就节省了很多调度上的开销 - 使用线程池
把使用的线程提前创建好,用完不直接释放,而是存放起来下次使用,这样就节省了创建/销毁线程的开销
在这个使用的过程中,并没有真的频繁创建销毁,而只是从线程池里,取线程使用,用完了还给线程池
1.4.2 标准库中的线程池
ThreadPoolExecutor 是标准库中提供的线程池
这个类构造方法有很多参数

- corePoolSize 核心线程数
一个线程池中最少有多少线程(相当于正式员工) - maximumPoolSize 最大线程数
一个线程池中最多有多少线程(相当于正式员工+临时工) - keepAliveTime 临时工允许的空闲时间
如果临时工线程空闲,这个时候会等待一段时间,凡是出现下一时刻任务暴增 - workQueue 传递任务的阻塞队列
线程池的内部可以持有很多任务,可以通过阻塞队列进行组织
传入 BlockingQueue,也可传入 PriorityBlockingQueue(这个带有优先级) - threadFactory 创建线程的⼯⼚,参与具体的创建线程⼯作
这里就要提到工厂模式
工厂模式,也是一种常见的设计模式,通过专门的“工厂类” / “工厂对象”来创建指定的对象
在 java 中,有的时候我们想创建两种不同的方法来做一种事情,这个时候我们会用到重载,但有的时候重载也会无能为力

为了解决这种问题,我们就引入了“工厂模式”,使用普通的方法来创建对象,就是把构造方法封装了一层

threadFactory 类里面提供的方法,让方法去封装 new Thread 的操作,并且同时给 Thread 设置一些属性,这样的操作就构成了 threadFactory 线程工厂 - RejectedExecutionHandler 拒绝策略(最重要!!!)
在任务池中,有一个阻塞队列,能够容纳的元素有上限
当任务队列中已经满了,如果继续往队列中添加任务,那任务池会如何做呢?
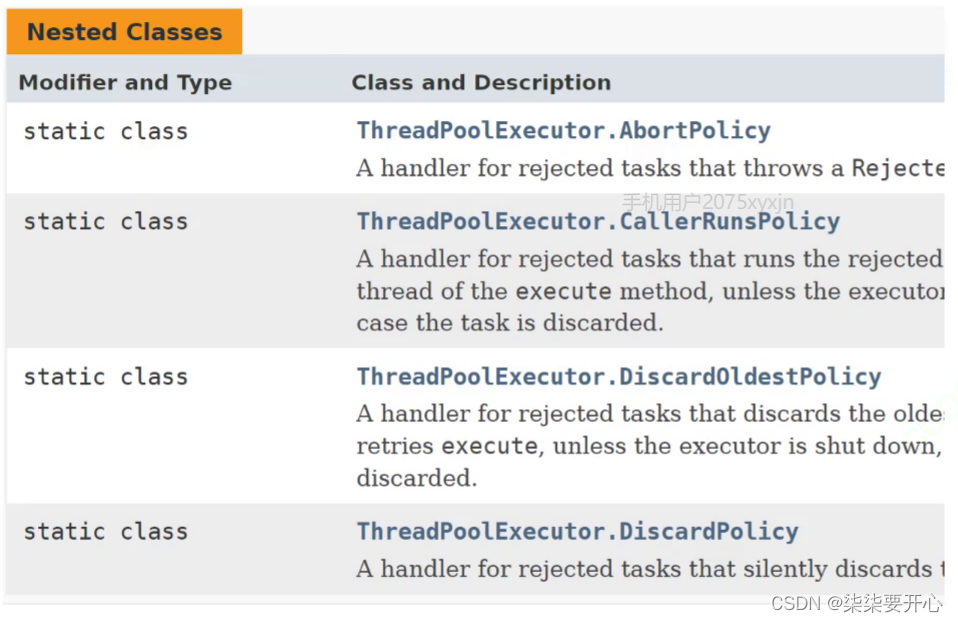 1、AbortPolicy():超过负荷,直接抛出异常
1、AbortPolicy():超过负荷,直接抛出异常
(新任务、旧任务都不执行)
2、CallerRunsPolicy():调⽤者负责处理多出来的任务
(新的任务,由添加任务的线程执行)
3、DiscardOldestPolicy():丢弃队列中最⽼的任务
4、DiscardPolicy():丢弃新来的任务
ThreadPollExceutor 本身用起来比较复杂,因此标准库还提供了另一个版本(Executor),把 ThreadPollExceutor 给封装了起来
Executor 工厂类,通过这个类创建出来不同的线程对象(在内部把 ThreadPollExceutor 创建好了并且设置了不同的参数)
public class ThreadDemo32 {public static void main(String[] args) {ExecutorService service = Executors.newFixedThreadPool(4);service.submit(new Runnable() {@Overridepublic void run() {System.out.println("hello");}});}
}

那什么时候使用 Executor(简单使用),什么时候使用 ThreadPollExceutor(高级定制化) 呢?
由于程序的复杂性,很难直接对线程池的线程数量进行估算,更适合的方式就是通过测试的方式找到合适的线程数目,还是要具体情况具体分析
1.4.3 自己实现简答的线程池
写一个固定数量的线程池
- 提供一个构造方法,指定创建多少个线程
- 在构造方法中,把这些线程都创建好
- 有一个阻塞队列,能够持有要执行的任务
- 提供 submit 方法,可以添加新的任务

当我们的代码写到最后,发现报错了,这里的 i 为什么会错误呢?
这是因为变量捕获,new Runnable 是一个匿名内部类,而run 是一个回调函数,回调函数访问当前外部作用域的变量就是变量捕获
变量捕获的变量不能是一个变化的变量,需要是一个 final 或者事实 final
这里就需要把代码进行改变
此处的 n 就是一个“事实final” 变量
每循环,都是一个新的 n , n 本身没有改变,这样就可以捕获
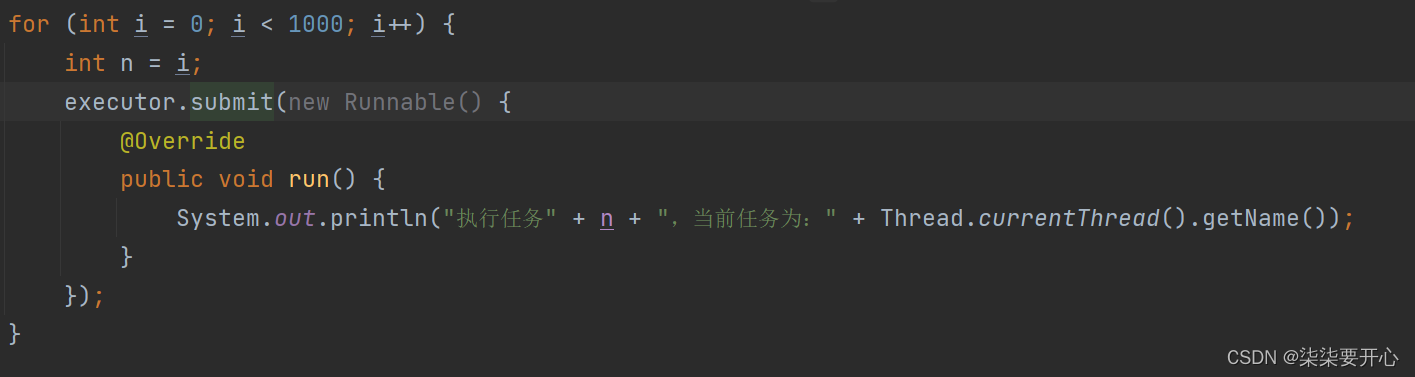
class MyThreadPoolExecutor {private List<Thread> threadList = new ArrayList<>();//这就是一个用来保存任务的队列private BlockingQueue<Runnable> queue = new ArrayBlockingQueue<>(1000);//通过 n 指定创建多少个线程public MyThreadPoolExecutor(int n) {for (int i = 0; i < n; i++) {Thread t = new Thread(() -> {//线程要做的事情就是把任务队列中的任务不停的取出来,并且进行执行while (true) {try {//此处的 take 带有阻塞功能//如果队列为空,此处的 take 就会阻塞Runnable runnable = queue.take();//取出一个任务就执行一个任务runnable.run();} catch (InterruptedException e) {e.printStackTrace();}}});t.start();threadList.add(t);}}public void submit(Runnable runnable) throws InterruptedException {queue.put(runnable);}
}public class ThreadDemo33 {public static void main(String[] args) throws InterruptedException {MyThreadPoolExecutor executor = new MyThreadPoolExecutor(4);for (int i = 0; i < 1000; i++) {int n = i;executor.submit(new Runnable() {@Overridepublic void run() {System.out.println("执行任务" + n + ",当前任务为:" + Thread.currentThread().getName());}});}}
}
这里可以看出,多个线程的执行顺序是不确定的,某个线程去到某个任务了,但是并非立即执行,这个过程中可能另一个线程就插到前面了