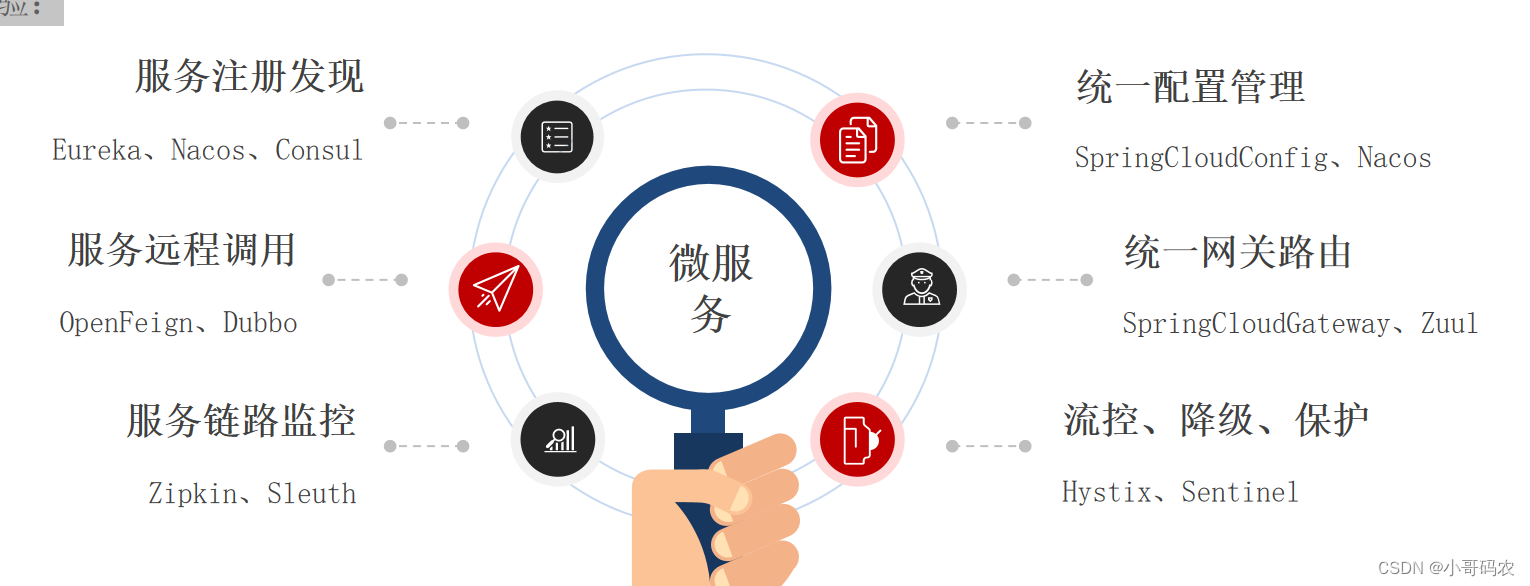
概述
28s应用崩溃查看内存使用有大量cache。
分析
- 查看free 信息平时的确存在大量cache使用的情况

- 查看dmes信息发现filesendserver崩溃

崩溃信息为系统调用 查看到page allocation failure:order 5
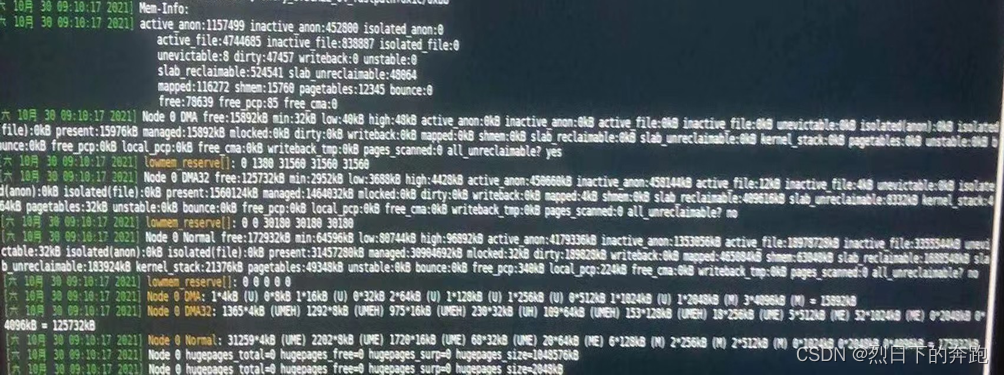
- 同时也看到系统内存使用情况

查看到系统实际还有部分内存为空闲内存,但是观察mode 0 Nornal 内存中有部分连续内存页使用完了。而恰巧重新申请的是order 为5的内存,查看内核中__get_free_pages()函数对于系统内存分配说明order参数是系统要分配的2的order次方的数量的连续内存页申请,这里对应的就是2的5次方4k连续内存页128kb内存的申请。因此应用崩溃的原因为,系统内存碎片化导致的。
- 同时还观察到系统find进程异常

同样查看内存使用情况为申请2的8次方4k连续内存页1024kb内存的申请同样查看为内存没有。
- 内存碎片化严重有2种解决思路
1 找到大量吃cache的进程进行程序的优化
2 调整系统预留内存修改vm.min_free_kbytes = 1153434
关于系统内存有pages_high pages_low pages_min 3条水位线

大概的关系换算关系的是
watermark[min] = per_zone_min_free_pages (min_free_kbytes换算为page单位)
watermark[low] = watermark[min] * 5 / 4
watermark[high] = watermark[min] * 3 / 2
系统内存使用达到pages_low才会开始回升cache,vm.min_free_kbytes可根据系统物理内存进行调节。
- 针对第一步情况我们进行了进一步的排查,通过脚本监控iotop信息发现find程序有长时间的读写操作。

和上面应用出现异常同时find程序异常相对应。同时观察到时间得到每天的9点5分开始 9点55多还在运行,同时查看syslog日志每天的9点5只有corn.daily执行。

查看到locate比较像每天会执行一次updatedb。手动运行updatedb命令发现ps查看的一模一样。updatedb主要用于生产系统所有文件的路径和文件名索引。
结论
查看了 df -h系统有大概220g的文件,该问题是由于系统updatedb命令在执行find遍历系统所有文件是占用了大量的buff导致的系统内存碎片化最终使得应用奔溃。
用户最终采取了以下措施解决该问题
- 删除了locate 定时任务
- 修改了vm.min_free_kbytes = 1153434
- 修改了/etc/crontab文件修改了每日定时任务的启动时间