RealCustom:缩小真实文本词的范围,实现实时开放域文本到图像的定制
文本到图像定制旨在为给定的主题合成文本驱动的图像,最近彻底改变了内容创作。现有的作品遵循伪词范式,即将给定的主题表示为伪词,然后将其与给定的文本组合在一起。然而,伪词与给定文本固有的纠缠扩散范围导致了双重最优悖论,即给定主题的相似性和给定文本的可控性不能同时达到最优。首次提出了RealCustom,通过将主语扩散精确地限制在相关部分,将相似性与可控性脱钩,这是通过将真实文本单词从其一般内涵逐渐缩小到特定主语,并利用其交叉注意力来区分相关性来实现的。具体来说,RealCustom引入了一种新颖的训练推理解耦框架:(1)在训练过程中,RealCustom通过一种新颖自适应评分模块,学习视觉条件与原始文本条件之间的一般对齐,以自适应地调节信息量;(2) 在推理过程中,提出了一种新的自适应掩码引导策略,迭代更新给定主题的扩散范围和扩散量,以逐渐缩小真实文本单词的生成范围。综合实验表明,RealCustom在开放域中具有卓越的实时定制能力,首次实现了给定主题前所未有的相似性和给定文本的可控性。
现有范式与改进范式之间的比较,如图3-19所示。
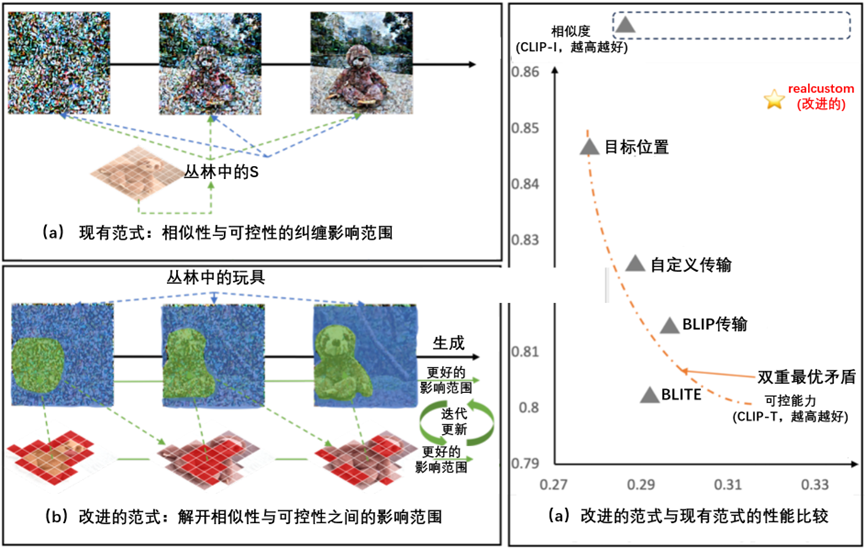
图3-19 现有范式与改进范式之间的比较
在图3-19中,(a)现有的范式将给定的主题表示为伪词(例如S*),将相同的整个信息范围与给定的文本纠缠在一起,导致了双重最优悖论,即给定主题的相似性和给定文本的可控性不能同时达到最优。(b)提出了RealCustom,这是一种新颖的范式,它首次通过精确给定的主题限制为仅包含相关部分的信息,而其余部分完全由给定的文本控制,从而将相似性与可控性脱钩。这是通过迭代更新指定受试者的扩散范围和扩散量来实现的。(c)定量比较表明,范式比现有范式的最新技术实现了更高的相似性和可控性。CLIP图像得分(CLIP-I)和CLIP文本得分(CLIP-T)用于评估相似性和可控性。
提出的RealCustom采用了一种新颖的训练推理解耦框架,如图3-20所示。
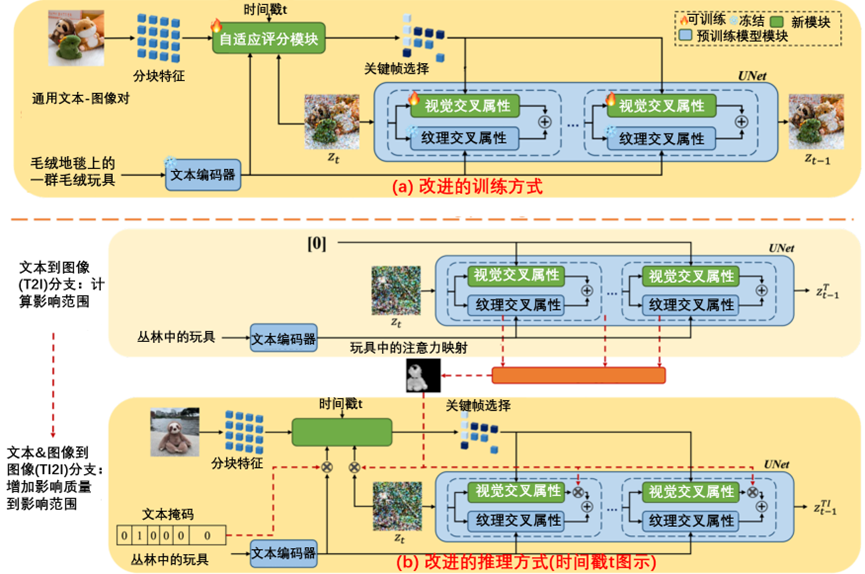
图3-20 提出的RealCustom采用了一种新颖的训练推理解耦框架
在图3-20中,(a)在训练过程中,所提出的自适应评分模块学习了视觉和原始文本条件之间的一般对齐,该模块根据文本和当前生成的特征准确推导出视觉条件。(b)在推理过程中,通过改进的自适应掩码引导策略,将一个真实的目标(例如玩具)从其最初的一般含义逐步缩小到给定的主题(例如,独特的棕色树懒玩具),该策略由两个分支组成,即文本到图像(T2I)分支,其中视觉条件设置为0,以及文本和图像到图像(TI2I)分支,其视觉条件设置指定的主题。T2I分支旨在通过聚合目标真实单词(例如玩具)的交叉注意力来计算信息扩散范围,而TI2I分支旨在将信息扩散量注入该范围。
自适应评分模块的图示,如图3-21所示。
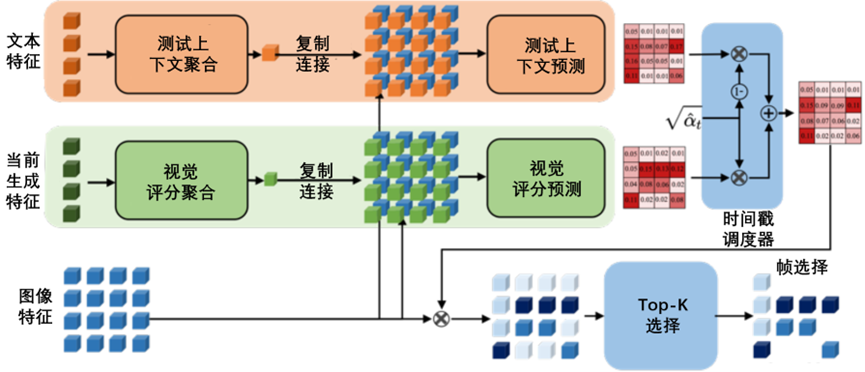
图3-21自适应评分模块的图示
在图3-21中,文本特征和当前生成的特征首先被聚合到文本和视觉上下文中,然后与图像特征在空间上连接起来,以预测文本和视觉得分。然后根据当前的时间步长,对这些分数进行融合。最终,根据融合分数只选择关键特征的一个子集。
改进方法与现有方法的定性比较,如图3-22所示。

图3-22 改进方法与现有方法的定性比较
在图3-22中,与现有作品相比,RealCustom可以产生更高质量的定制结果,这些结果与给定主题具有更好的相似性,与给定文本具有更好的可控性。此外,RealCustom展示了卓越的多样性(不同的拍摄对象姿势、位置等)和生成质量(例如,第3行的秋叶场景)。

![[OtterCTF 2018]-内存取证-WP](https://img2023.cnblogs.com/blog/3400631/202411/3400631-20241116002246403-1856461826.png)