【AIGC第三十一篇】SDXL Turbo:一种实时的文本到图像生成模型 - 知乎【 SDXL Turbo通过采用全新的蒸馏技术,实现了最先进的性能,能够以前所未有的质量进行单步图像生成,将所需的步骤数量从50步减少到仅需一步。这种创新技术大大提高了图像生成的效率和质量,为实时的文本到图像生…![]() https://zhuanlan.zhihu.com/p/670000715实测下来不如lcm-lora,如果仅仅是从加速角度出发,更建议使用lcm-lora,加速sd一般是两种方法,1.更快的采样器,比如dpm++等,从ODE角度更快的接触数值解;2.蒸馏,目前包括lcm_lora在内的方法,都是对扩散的去噪过程进行蒸馏,从之前的五十步,三十步道1-4步即可出图。注意文生图算法通常来说,包括两个维度,1.模型架构维度,vae encoder+diffusion+vae decoder,通常再包括一个clip encoder给text侧做embedding,2.扩散理论的加噪和去噪的训练和采样过程,模型架构可以一样,但是在加噪和去噪上同样可以有多种方法的改进,比如采样器,cm,lcm,lcm-lora以及sdxl-turbo这种。sdxl-turbo总的来说是采用了对抗扩散蒸馏方法ADD,用了两个损失,1.adversarial loss,定义了一个判别器来判定生成图像的图像和真实的图像;2.distillation loss,让student和teacher的输出保持一致。
https://zhuanlan.zhihu.com/p/670000715实测下来不如lcm-lora,如果仅仅是从加速角度出发,更建议使用lcm-lora,加速sd一般是两种方法,1.更快的采样器,比如dpm++等,从ODE角度更快的接触数值解;2.蒸馏,目前包括lcm_lora在内的方法,都是对扩散的去噪过程进行蒸馏,从之前的五十步,三十步道1-4步即可出图。注意文生图算法通常来说,包括两个维度,1.模型架构维度,vae encoder+diffusion+vae decoder,通常再包括一个clip encoder给text侧做embedding,2.扩散理论的加噪和去噪的训练和采样过程,模型架构可以一样,但是在加噪和去噪上同样可以有多种方法的改进,比如采样器,cm,lcm,lcm-lora以及sdxl-turbo这种。sdxl-turbo总的来说是采用了对抗扩散蒸馏方法ADD,用了两个损失,1.adversarial loss,定义了一个判别器来判定生成图像的图像和真实的图像;2.distillation loss,让student和teacher的输出保持一致。

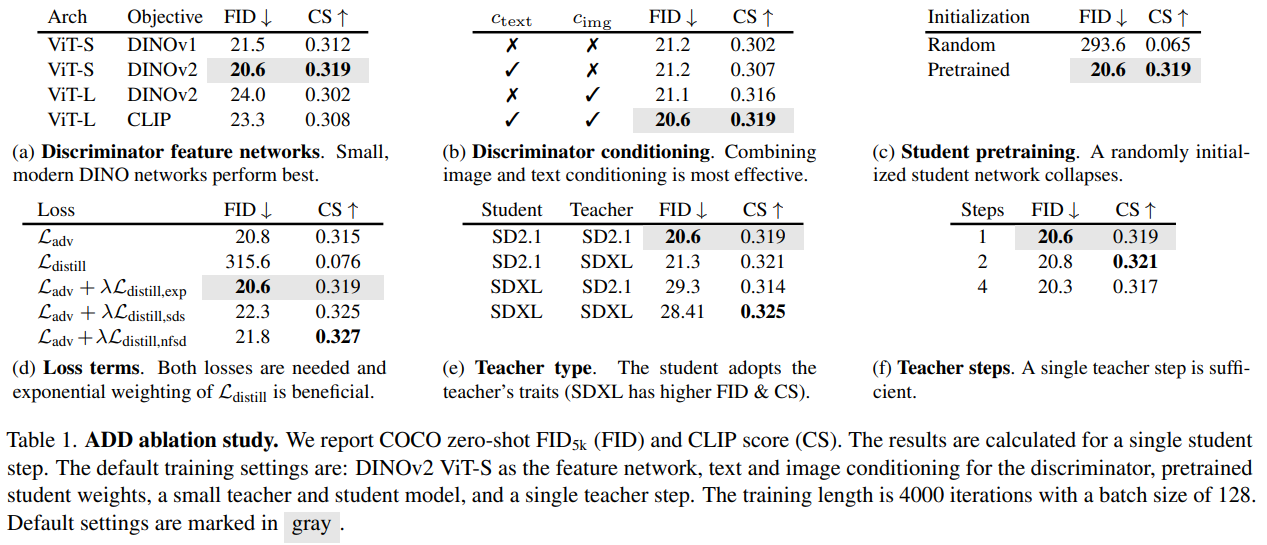
如上图所示,主要就是两个loss,一个GAN损失,一个是distillation loss,相当于diffusion为主,GAN校准的思路。首先,ADD训练流程包括三个网络:1.一个ADD-student网络,从预训练的unet-DM中初始化,一个判别器,以及一个DM-teacher网络,权重保持固定。
本文的方法是在pixel space上进行的,不过也可以迁移到latent space中,对于LDM,pixel space蒸馏时梯度计算更加稳定。
1. score distillation
1.ADD-student从Tstudent采样一个时间步s,通过一个前向扩散过程从真实图像X0加噪得到Xs,接着Xs通过ADD-student网络去噪得到生成图;
2.DM-teacher从Tteacher中采样一个时间步t,再在把ADD-student生成图加噪得到时间步t的噪声图;
3.通过DM-teacher噪声预测得到生成图;
distillation loss就是缩小ADD-student模型的生成图和DM-teacher模型的生成图之间的差异,|| x-y||2,l2损失。
2.adversarial training
对抗训练时,生成的样本和真实图像样本都会传递给判别器,判别器目标是区分它们。判别器使用预训练的VIT和可训练的判别器head组成。为了提高性能,判别器可以通过条件输入来获取额外的信息。
使用hingle loss作为对抗目标损失。
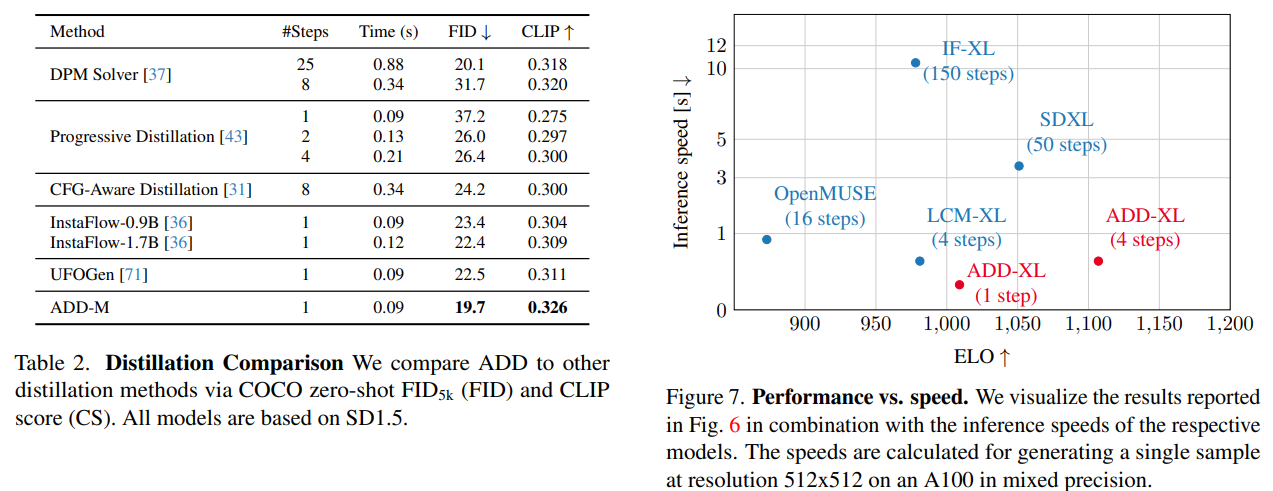
3.评估