Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。
-
1、Flink 部署系列
本部分介绍Flink的部署、配置相关基础内容。 -
2、Flink基础系列
本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的datastream api用法、四大基石等内容。 -
3、Flik Table API和SQL基础系列
本部分介绍Flink Table Api和SQL的基本用法,比如Table API和SQL创建库、表用法、查询、窗口函数、catalog等等内容。 -
4、Flik Table API和SQL提高与应用系列
本部分是table api 和sql的应用部分,和实际的生产应用联系更为密切,以及有一定开发难度的内容。 -
5、Flink 监控系列
本部分和实际的运维、监控工作相关。
二、Flink 示例专栏
Flink 示例专栏是 Flink 专栏的辅助说明,一般不会介绍知识点的信息,更多的是提供一个一个可以具体使用的示例。本专栏不再分目录,通过链接即可看出介绍的内容。
两专栏的所有文章入口点击:Flink 系列文章汇总索引
文章目录
- Flink 系列文章
- 一、maven依赖
- 二、环境或版本说明
- 三、自定义数据源kafka(Flink 1.13.6 版本)
- 1、maven依赖
- 2、实现
- 3、验证
- 三、自定义数据源kafka(Flink 1.17.0 版本)
- 1、maven依赖
- 2、实现
- 3、验证
本文主要介绍Flink 的kafka作为数据源的使用,并给出了flink不同版本对kafka作为数据源的不同实现示例。
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本文除了maven依赖外,没有其他依赖。
本文依赖kafka的环境是好用的。
本专题分为以下几篇文章:
【flink番外篇】3、fflink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例(1) - File、Socket、Collection
【flink番外篇】3、fflink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例(2)- 自定义、mysql
【flink番外篇】3、flink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例(3)- kafka
【flink番外篇】3、flink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例(4)- redis -异步读取
【flink番外篇】3、flink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例(5)- clickhouse
【flink番外篇】3、flink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例 - 完整版
一、maven依赖
本文依赖见【flink番外篇】3、flink的source介绍及示例(1)- File、Socket、Collection,不再赘述。
如果有新增的maven依赖,则会在示例时加以说明,避免篇幅的过大。
二、环境或版本说明
1、该示例需要有kafka的运行环境,kafka的部署与使用参考文章:
1、kafka(2.12-3.0.0)介绍、部署及验证、基准测试
2、Flink关于kafka的使用在不同的版本中有不同的实现,最直观的的变化是由FlinkKafkaConsumer换成了KafkaSource,同理sink也有相应的由FlinkKafkaProducer换成了KafkaSink。
3、由于使用kafka涉及的内容较多,请参考文章:
40、Flink 的Apache Kafka connector(kafka source 和sink 说明及使用示例) 完整版
4、本文会提供关于kafka 作为source的2个版本,即1.13.6和1.17的版本。
5、以下属性在构建 KafkaSource 时是必须指定的:
- Bootstrap server,通过 setBootstrapServers(String) 方法配置
- 消费者组 ID,通过 setGroupId(String) 配置
- 要订阅的 Topic / Partition
- 用于解析 Kafka 消息的反序列化器(Deserializer)
三、自定义数据源kafka(Flink 1.13.6 版本)
Kafka Source 提供了构建类来创建 FlinkKafkaConsumer 的实例。
以下代码片段展示了如何构建 FlinkKafkaConsumer 来消费 “alan_kafkasource” 最早位点的数据, 使用消费组 “flink_kafka”,并且将 Kafka 消息体反序列化为字符串
1、maven依赖
<properties><encoding>UTF-8</encoding><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><java.version>1.8</java.version><scala.version>2.12</scala.version><flink.version>1.13.6</flink.version></properties><dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-scala_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-scala_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.11</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- flink连接器 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-sql-connector-kafka_2.12</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-csv</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-json</artifactId><version>${flink.version}</version></dependency><!-- 日志 --><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.7</version><scope>runtime</scope></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version><scope>runtime</scope></dependency></dependencies>2、实现
package org.datastreamapi.source.custom.kafka;import java.util.Properties;import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;/*** @author alanchan**/
public class TestCustomKafkaSourceDemo {public static void main(String[] args) throws Exception {// 1、envStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2、 source// 准备kafka连接参数Properties props = new Properties();// 集群地址props.setProperty("bootstrap.servers", "192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092");// 消费者组idprops.setProperty("group.id", "flink_kafka");// latest有offset记录从记录位置开始消费,没有记录从最新的/最后的消息开始消费// earliest有offset记录从记录位置开始消费,没有记录从最早的/最开始的消息开始消费props.setProperty("auto.offset.reset", "latest");// 会开启一个后台线程每隔5s检测一下Kafka的分区情况,实现动态分区检测props.setProperty("flink.partition-discovery.interval-millis", "5000");// 自动提交(提交到默认主题,后续学习了Checkpoint后随着Checkpoint存储在Checkpoint和默认主题中)props.setProperty("enable.auto.commit", "true");// 自动提交的时间间隔props.setProperty("auto.commit.interval.ms", "2000");// 使用连接参数创建FlinkKafkaConsumer/kafkaSourceFlinkKafkaConsumer<String> kafkaSource = new FlinkKafkaConsumer<String>("alan_kafkasource", new SimpleStringSchema(), props);// 使用kafkaSourceDataStream<String> kafkaDS = env.addSource(kafkaSource);// 3、 transformation// 4、 sinkkafkaDS.print();// 5、executeenv.execute();}
}3、验证
1、创建kafka主题alan_kafkasource,kafka命令发送数据
[alanchan@server2 bin]$ kafka-topics.sh --create --bootstrap-server server1:9092 --topic alan_kafkasource --partitions 1 --replication-factor 1[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list 192.168.10.41:9092 --topic alan_kafkasource
>alan,18
>alanchan,19
>alanchan,202、启动应用程序,并观察控制台输出

三、自定义数据源kafka(Flink 1.17.0 版本)
Kafka Source 提供了构建类来创建 KafkaSource 的实例。
以下代码片段展示了如何构建 KafkaSource 来消费 “alan_kafkasource” 最早位点的数据, 使用消费组 “flink_kafka”,并且将 Kafka 消息体反序列化为字符串
1、maven依赖
<properties><encoding>UTF-8</encoding><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><java.version>1.8</java.version><scala.version>2.12</scala.version><flink.version>1.17.0</flink.version></properties><dependencies><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-csv</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-json</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- flink连接器 --><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-kafka --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka</artifactId><version>${flink.version}</version></dependency></dependencies>2、实现
为了避免误解,1.13.6版本与1.17.0版本实现不同的地方KafkaSource和FlinkKafkaConsumer的不同,相关属性值是一样的,只是本例中没有将1.13.5的中的所有属性都列出来。
package org.datastreamapi.source.custom.kafka;import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;/*** @author alanchan**/
public class TestCustomKafkaSourceDemo {public static void main(String[] args) throws Exception {// 1、envStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 2、 sourceKafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers("192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092").setTopics("alan_kafkasource").setGroupId("flink_kafka").setStartingOffsets(OffsetsInitializer.earliest()).setValueOnlyDeserializer(new SimpleStringSchema()).build();DataStreamSource<String> kafkaDS = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");// 3、 transformation// 4、 sinkkafkaDS.print();// 5、executeenv.execute();}
}3、验证
1、创建kafka主题alan_kafkasource,kafka命令发送数据
[alanchan@server2 bin]$ kafka-topics.sh --create --bootstrap-server server1:9092 --topic alan_kafkasource --partitions 1 --replication-factor 1[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list 192.168.10.41:9092 --topic alan_kafkasource
>alan,18
>alanchan,19
>alanchan,20
2、启动应用程序,并观察控制台输出
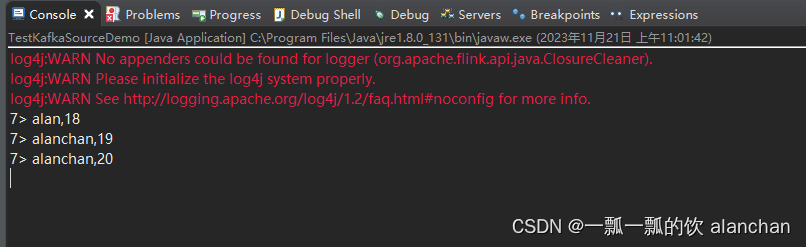
以上,本文主要介绍Flink 的kafka作为数据源的使用,并给出了flink不同版本对kafka作为数据源的不同实现示例。
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本专题分为以下几篇文章:
【flink番外篇】3、fflink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例(1) - File、Socket、Collection
【flink番外篇】3、fflink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例(2)- 自定义、mysql
【flink番外篇】3、flink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例(3)- kafka
【flink番外篇】3、flink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例(4)- redis -异步读取
【flink番外篇】3、flink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例(5)- clickhouse
【flink番外篇】3、flink的source(内置、mysql、kafka、redis、clickhouse)介绍及示例 - 完整版