作者:黑夜路人
时间:2023年7月
Transformer Block (通用块)实现

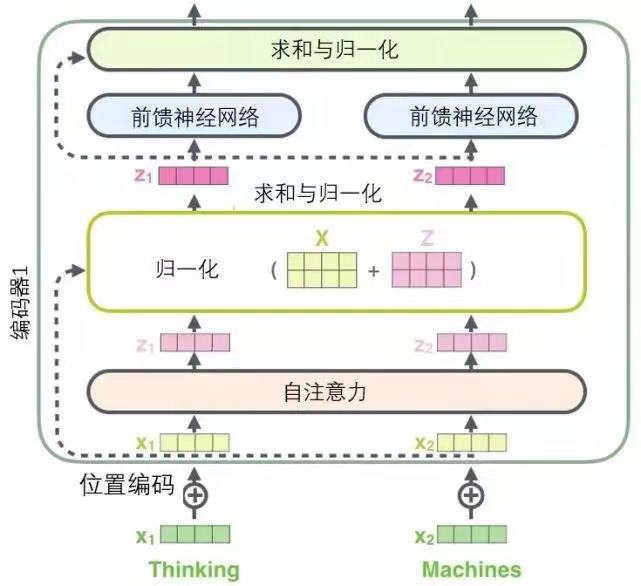
看以上整个链路图,其实我们可以很清晰看到这心其实在Encoder环节里面主要是有几个大环节,每一层主要的核心作用如下:
- Multi-headed self Attention(注意力机制层):通过不同的注意力函数并拼接结果,提高模型的表达能力,主要计算词与词的相关性和长距离次的相关性。
- Normalization layer(归一化层):对每个隐层神经元进行归一化,使其特征值的均值为0,方差为1,解决梯度爆炸和消失问题。通过归一化,可以将数据压缩在一个合适范围内,避免出现超大或超小值,有利于模型训练,也能改善模型的泛化能力和加速模型收敛以及减少参数量的依赖。
- Feed forward network(前馈神经网络):对注意力输出结果进行变换。
- Another normalization layer(另一个归一化层):Weight Normalization用于对模型中层与层之间的权重矩阵进行归一化,其主要目的是解决梯度消失问题
注意力(Attention)实现
参考其他我们了解的信息可以看到里面核心的自注意力层等等,我们把每个层剥离看看核心这一层应该如何实现。
简单看看注意力的计算过程:
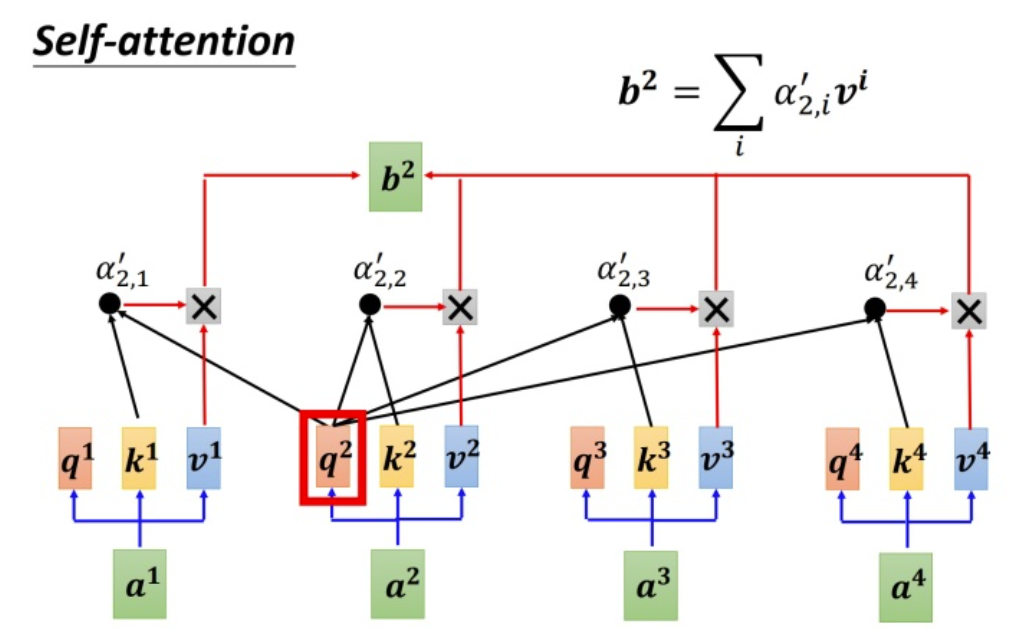
这张图所表示的大致运算过程是:
对于每个token,先产生三个向量query,key,value:
query向量类比于询问。某个token问:“其余的token都和我有多大程度的相关呀?”
key向量类比于索引。某个token说:“我把每个询问内容的回答都压缩了下装在我的key里”
value向量类比于回答。某个token说:“我把我自身涵盖的信息又抽取了一层装在我的value里”
注意力计算代码:
def attention(query: Tensor,key: Tensor,value: Tensor,mask: Optional[Tensor] = None,dropout: float = 0.1):"""定义如何计算注意力得分参数:query: shape (batch_size, num_heads, seq_len, k_dim)key: shape(batch_size, num_heads, seq_len, k_dim)value: shape(batch_size, num_heads, seq_len, v_dim)mask: shape (batch_size, num_heads, seq_len, seq_len). Since our assumption, here the shape is(1, 1, seq_len, seq_len)返回:out: shape (batch_size, v_dim). 注意力头的输出。注意力分数:形状(seq_len,seq_ln)。"""k_dim = query.size(-1)# shape (seq_len ,seq_len),row: token,col: token记号的注意力得分scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(k_dim)if mask is not None:scores = scores.masked_fill(mask == 0, -1e10)attention_score = F.softmax(scores, dim=-1)if dropout is not None:attention_score = dropout(attention_score)out = torch.matmul(attention_score, value)return out, attention_score # shape: (seq_len, v_dim), (seq_len, seq_lem)以图中的token a2为例:
它产生一个query,每个query都去和别的token的key做“某种方式”的计算,得到的结果我们称为attention score(即为图中的$$\alpha $$)。则一共得到四个attention score。(attention score又可以被称为attention weight)。
将这四个score分别乘上每个token的value,我们会得到四个抽取信息完毕的向量。
将这四个向量相加,就是最终a2过attention模型后所产生的结果b2。
整个这一层,我们通过代码来进行这个逻辑的简单实现:
class MultiHeadedAttention(nn.Module):def __init__(self,num_heads: int,d_model: int,dropout: float = 0.1):super(MultiHeadedAttention, self).__init__()assert d_model % num_heads == 0, "d_model must be divisible by num_heads"# 假设v_dim总是等于k_dimself.k_dim = d_model // num_headsself.num_heads = num_headsself.proj_weights = clones(nn.Linear(d_model, d_model), 4) # W^Q, W^K, W^V, W^Oself.attention_score = Noneself.dropout = nn.Dropout(p=dropout)def forward(self,query: Tensor,key: Tensor,value: Tensor,mask: Optional[Tensor] = None):"""参数:query: shape (batch_size, seq_len, d_model)key: shape (batch_size, seq_len, d_model)value: shape (batch_size, seq_len, d_model)mask: shape (batch_size, seq_len, seq_len). 由于我们假设所有数据都使用相同的掩码,因此这里的形状也等于(1,seq_len,seq-len)返回:out: shape (batch_size, seq_len, d_model). 多头注意力层的输出"""if mask is not None:mask = mask.unsqueeze(1)batch_size = query.size(0)# 1) 应用W^Q、W^K、W^V生成新的查询、键、值query, key, value \= [proj_weight(x).view(batch_size, -1, self.num_heads, self.k_dim).transpose(1, 2)for proj_weight, x in zip(self.proj_weights, [query, key, value])] # -1 equals to seq_len# 2) 计算注意力得分和outout, self.attention_score = attention(query, key, value, mask=mask,dropout=self.dropout)# 3) "Concat" 输出out = out.transpose(1, 2).contiguous() \.view(batch_size, -1, self.num_heads * self.k_dim)# 4) 应用W^O以获得最终输出out = self.proj_weights[-1](out)return out
Norm 归一化层实现
# 归一化层,标准化的计算公式
class NormLayer(nn.Module):def __init__(self, features, eps=1e-6):super(LayerNorm, self).__init__()self.a_2 = nn.Parameter(torch.ones(features))self.b_2 = nn.Parameter(torch.zeros(features))self.eps = epsdef forward(self, x):mean = x.mean(-1, keepdim=True)std = x.std(-1, keepdim=True)return self.a_2 * (x - mean) / (std + self.eps) + self.b_2前馈神经网络实现
class FeedForward(nn.Module):def __init__(self, d_model, d_ff=2048, dropout=0.1):super().__init__()# 设置 d_ff 缺省值为2048self.linear_1 = nn.Linear(d_model, d_ff)self.dropout = nn.Dropout(dropout)self.linear_2 = nn.Linear(d_ff, d_model)def forward(self, x):x = self.dropout(F.relu(self.linear_1(x)))x = self.linear_2(x)Encoder(编码器曾)实现
Encoder 就是将前面介绍的整个链路部分,全部组装迭代起来,完成将源编码到中间编码的转换。
class EncoderLayer(nn.Module):def __init__(self, d_model, heads, dropout=0.1):super().__init__()self.norm_1 = Norm(d_model)self.norm_2 = Norm(d_model)self.attn = MultiHeadAttention(heads, d_model, dropout=dropout)self.ff = FeedForward(d_model, dropout=dropout)self.dropout_1 = nn.Dropout(dropout)self.dropout_2 = nn.Dropout(dropout)def forward(self, x, mask):x2 = self.norm_1(x)x = x + self.dropout_1(self.attn(x2, x2, x2, mask))x2 = self.norm_2(x)x = x + self.dropout_2(self.ff(x2))return xclass Encoder(nn.Module):def __init__(self, vocab_size, d_model, N, heads, dropout):super().__init__()self.N = Nself.embed = Embedder(d_model, vocab_size)self.pe = PositionalEncoder(d_model, dropout=dropout)self.layers = get_clones(EncoderLayer(d_model, heads, dropout), N)self.norm = Norm(d_model)def forward(self, src, mask):x = self.embed(src)x = self.pe(x)for i in range(self.N):x = self.layers[i](x, mask)return self.norm(x)Decoder(解码器层)实现
Decoder部分和 Encoder 的部分非常的相似,它主要是把 Encoder 生成的中间编码,转换为目标编码。
class DecoderLayer(nn.Module):def __init__(self, d_model, heads, dropout=0.1):super().__init__()self.norm_1 = Norm(d_model)self.norm_2 = Norm(d_model)self.norm_3 = Norm(d_model)self.dropout_1 = nn.Dropout(dropout)self.dropout_2 = nn.Dropout(dropout)self.dropout_3 = nn.Dropout(dropout)self.attn_1 = MultiHeadAttention(heads, d_model, dropout=dropout)self.attn_2 = MultiHeadAttention(heads, d_model, dropout=dropout)self.ff = FeedForward(d_model, dropout=dropout)def forward(self, x, e_outputs, src_mask, trg_mask):x2 = self.norm_1(x)x = x + self.dropout_1(self.attn_1(x2, x2, x2, trg_mask))x2 = self.norm_2(x)x = x + self.dropout_2(self.attn_2(x2, e_outputs, e_outputs,src_mask))x2 = self.norm_3(x)x = x + self.dropout_3(self.ff(x2))return xclass Decoder(nn.Module):def __init__(self, vocab_size, d_model, N, heads, dropout):super().__init__()self.N = Nself.embed = Embedder(vocab_size, d_model)self.pe = PositionalEncoder(d_model, dropout=dropout)self.layers = get_clones(DecoderLayer(d_model, heads, dropout), N)self.norm = Norm(d_model)def forward(self, trg, e_outputs, src_mask, trg_mask):x = self.embed(trg)x = self.pe(x)for i in range(self.N):x = self.layers[i](x, e_outputs, src_mask, trg_mask)return self.norm(x)Transformer 实现
把整个链路结合,包括Encoder和Decoder,最终就能够形成一个Transformer框架的基本MVP实现。
class Transformer(nn.Module):def __init__(self, src_vocab, trg_vocab, d_model, N, heads, dropout):super().__init__()self.encoder = Encoder(src_vocab, d_model, N, heads, dropout)self.decoder = Decoder(trg_vocab, d_model, N, heads, dropout)self.out = nn.Linear(d_model, trg_vocab)def forward(self, src, trg, src_mask, trg_mask):e_outputs = self.encoder(src, src_mask)d_output = self.decoder(trg, e_outputs, src_mask, trg_mask)output = self.out(d_output)return output代码说明
如果想要学习阅读整个代码,访问 black-transformer 项目,github访问地址:
GitHub - heiyeluren/black-transformer: black-transformer 是一个轻量级模拟Transformer模型实现的概要代码,用于了解整个Transformer工作机制
取代你的不是AI,而是比你更了解AI和更会使用AI的人!
##End##