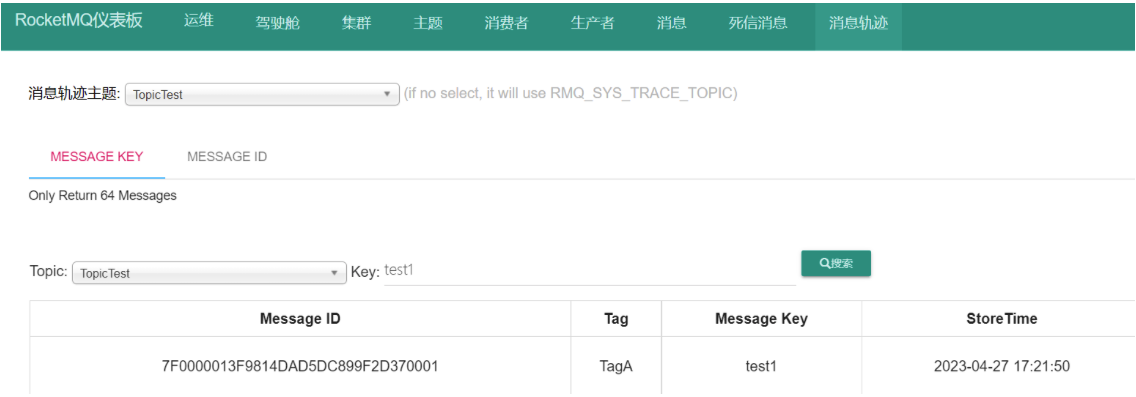
1.数据加载
在PyTorch中,数据加载可通过自定义的数据集对象。数据集对象被抽象为Dataset类,实现自定义的数据集需要继承Dataset,并实现两个Python魔法方法:
__getitem__:返回一条数据,或一个样本。obj[index]等价于obj.__getitem__(index)__len__:返回样本的数量。len(obj)等价于obj.__len__()
这里以Kaggle经典挑战赛"Dogs vs. Cat"的数据为例。"Dogs vs. Cats"是一个分类问题,判断一张图片是狗还是猫,其所有图片都存放在一个文件夹下,根据文件名的前缀判断是狗还是猫。
import numpy as np
import torch as timport osfrom PIL import Image
from torch.utils.data import Dataset
from torchvision import transforms as T
class DogCat(Dataset):def __init__(self, root):imgs = os.listdir(root) # 所有图片的相对路径self.imgs = [os.path.join(root, img) for img in imgs] # 这里不实际加载图片,只是指定路径,当调用__getitem__时才会真正读图片def __getitem__(self, index):img_path = self.imgs[index]# dog -> 1, cat -> 0label = 1 if 'dog' in img_path.split('/')[-1] else 0pil_img = Image.open(img_path)array = np.asarray(pil_img)data = t.from_numpy(array)return data, labeldef __len__(self):return len(self.imgs)
dataset = DogCat('data/dogcat/')for img, label in dataset:print(img.size(), img.float().mean(), label)
torch.Size([500, 497, 3]) tensor(106.4915) 0
torch.Size([499, 379, 3]) tensor(171.8085) 0
torch.Size([236, 289, 3]) tensor(130.3004) 0
torch.Size([374, 499, 3]) tensor(115.5177) 0
torch.Size([375, 499, 3]) tensor(116.8139) 1
torch.Size([375, 499, 3]) tensor(150.5079) 1
torch.Size([377, 499, 3]) tensor(151.7174) 1
torch.Size([400, 300, 3]) tensor(128.1550) 1
这里返回的数据不适合实际使用,因其具有如下两方面问题:
- 返回样本的形状不一,因每张图片的大小不一样,这对于需要取batch训练的神经网络来说很不友好
- 返回样本的数值较大,未归一化至[-1, 1]
针对上述问题,PyTorch提供了torchvision1。它是一个视觉工具包,提供了很多视觉图像处理的工具,其中transforms模块提供了对PIL Image对象和Tensor对象的常用操作。
对PIL Image的操作包括:
Scale:调整图片尺寸,长宽比保持不变CenterCrop、RandomCrop、RandomResizedCrop: 裁剪图片Pad:填充ToTensor:将PIL Image对象转成Tensor,会自动将[0, 255]归一化至[0, 1]
对Tensor的操作包括:
- Normalize:标准化,即减均值,除以标准差
- ToPILImage:将Tensor转为PIL Image对象
如果要对图片进行多个操作,可通过Compose函数将这些操作拼接起来,类似于nn.Sequential。注意,这些操作定义后是以函数的形式存在,真正使用时需调用它的__call__方法,这点类似于nn.Module。例如要将图片调整为 224 × 224 224\times 224 224×224,首先应构建这个操作trans = Resize((224, 224)),然后调用trans(img)。下面我们就用transforms的这些操作来优化上面实现的dataset。
transform = T.Compose([T.Resize(224), # 缩放图片Image,保持长宽比不变,最短边为224T.CenterCrop(224), # 从图片中间切出224*224的图片T.ToTensor(), # 将图片Image转成Tensor,归一化至[0,1]T.Normalize(mean=[.5, .5, .5], std=[.5, .5, .5]) # 标准化至[-1,1],规定均值和标准差
])
class DogCat(Dataset):def __init__(self, root, transform):imgs = os.listdir(root)self.imgs = [os.path.join(root, img) for img in imgs]self.transform = transformdef __getitem__(self, index):img_path = self.imgs[index]# dog->0, cat->1label = 0 if 'dog' in img_path.split('/')[-1] else 1data = Image.open(img_path)if self.transform:data = self.transform(data)return data, labeldef __len__(self):return len(self.imgs)
dataset = DogCat('data/dogcat/', transform=transform)for img, label in dataset:print(img.size(), label)
torch.Size([3, 224, 224]) 1
torch.Size([3, 224, 224]) 1
torch.Size([3, 224, 224]) 1
torch.Size([3, 224, 224]) 1
torch.Size([3, 224, 224]) 0
torch.Size([3, 224, 224]) 0
torch.Size([3, 224, 224]) 0
torch.Size([3, 224, 224]) 0
torchvision已经预先实现了常用的Dataset,包括经典的CIFAR-10,以及ImageNet、COCO、MNIST、LSUN等数据集,可通过诸如torchvision.datasets.CIFAR10来调用,具体使用方法请参看官方文档1。在这里介绍一个会经常使用到的Dataset——ImageFolder,它的实现和上述的DogCat很相似。ImageFolder假设所有的文件按文件夹保存,每个文件夹下存储同一个类别的图片,文件夹名为类名,其构造函数如下:
ImageFolder(root, transform=None, target_transform=None, loader=default_loader)
它主要有四个参数:
root:在root指定的路径下寻找图片transform:对PIL Image进行的转换操作,transform的输入是使用loader读取图片的返回对象target_transform:对label的转换loader:给定路径后如何读取图片,默认读取为RGB格式的PIL Image对象
label是按照文件夹名顺序排序后存成字典,即{类名:类序号(从0开始)},一般来说最好直接将文件夹命名为从0开始的数字,这样会和ImageFolder实际的label一致,如果不是这种命名规范,建议看看self.class_to_idx属性以了解label和文件夹名的映射关系。
from torchvision.datasets import ImageFolder
dataset = ImageFolder('data/dogcat_2/')
dataset.class_to_idx # cat文件夹的图片对应label 0, dog对应1
{'cat': 0, 'dog': 1}
dataset.imgs # 所有图片的路径和对应的label
[('data/dogcat_2/cat\\cat.12484.jpg', 0),('data/dogcat_2/cat\\cat.12485.jpg', 0),('data/dogcat_2/cat\\cat.12486.jpg', 0),('data/dogcat_2/cat\\cat.12487.jpg', 0),('data/dogcat_2/dog\\dog.12496.jpg', 1),('data/dogcat_2/dog\\dog.12497.jpg', 1),('data/dogcat_2/dog\\dog.12498.jpg', 1),('data/dogcat_2/dog\\dog.12499.jpg', 1)]
# 没有任何的transform,所以返回的还是PIL Image对象
dataset[0][1] # 第一维是第几张图,第二维为1返回label
dataset[0][0] # 为0返回图片数据

# 加上transform
normalize = T.Normalize(mean=[0.4, 0.4, 0.4], std=[0.2, 0.2, 0.2])
transform = T.Compose([T.RandomResizedCrop(224),T.RandomHorizontalFlip(),T.ToTensor(),normalize,
])
dataset = ImageFolder('data/dogcat_2/', transform=transform)
dataset[0][0].size() # 通道数×图片高×图片宽 C×H×W
torch.Size([3, 224, 224])
to_img = T.ToPILImage()
# 0.2和0.4是标准差和均值的近似
to_img(dataset[0][0]*0.2+0.4)

Dataset只负责数据的抽象,一次调用__getitem__只返回一个样本。前面提到过,在训练神经网络时,最好是对一个batch的数据进行操作,同时还需要对数据进行shuffle和并行加速等。对此,PyTorch提供了DataLoader帮助我们实现这些功能。
DataLoader的函数定义如下:
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, num_workers=0, collate_fn=default_collate, pin_memory=False, drop_last=False)
- dataset:加载的数据集(Dataset对象)
- batch_size:batch size
- shuffle::是否将数据打乱
- sampler: 样本抽样,后续会详细介绍
- num_workers:使用多进程加载的进程数,0代表不使用多进程
- collate_fn: 如何将多个样本数据拼接成一个batch,一般使用默认的拼接方式即可
- pin_memory:是否将数据保存在pin memory区,pin memory中的数据转到GPU会快一些
- drop_last:dataset中的数据个数可能不是batch_size的整数倍,drop_last为True会将多出来不足一个batch的数据丢弃
from torch.utils.data import DataLoaderdataloader = DataLoader(dataset, batch_size=3, shuffle=True, num_workers=0, drop_last=False)
dataiter = iter(dataloader)
imgs, labels = next(dataiter)
imgs.size() # bach_size, channel, height, weight
torch.Size([3, 3, 224, 224])
dataloader是一个可迭代的对象,意味着我们可以像使用迭代器一样使用它,例如:
for batch_datas, batch_labels in dataloader:train()
或
dataiter = iter(dataloader)
batch_datas, batch_labesl = next(dataiter)
在数据处理中,有时会出现某个样本无法读取等问题,比如某张图片损坏。这时在__getitem__函数中将出现异常,此时最好的解决方案即是将出错的样本剔除。如果实在是遇到这种情况无法处理,则可以返回None对象,然后在Dataloader中实现自定义的collate_fn,将空对象过滤掉。但要注意,在这种情况下dataloader返回的batch数目会少于batch_size。
class NewDogCat(DogCat): # 继承前面实现的DogCat数据集def __getitem__(self, index):try:# 调用父类的获取函数,即DogCat.__getitem__(self, index)return super(NewDogCat, self).__getitem__(index)except:return None, None
from torch.utils.data.dataloader import default_collate # 导入默认的拼接方式def my_collate_fn(batch):batch = list(filter(lambda x:x[0] is not None, batch)) # 过滤为None的数据 if len(batch) == 0: return t.Tensor()return default_collate(batch)
dataset = NewDogCat('data/dogcat_wrong/', transform=transform)
dataset[5]
(tensor([[[ 0.9020, 1.3333, 2.0000, ..., -1.0196, -1.0784, -1.1176],[ 0.9608, 1.4314, 2.0196, ..., -0.9804, -1.0588, -1.1176],[ 1.0196, 1.5294, 2.0588, ..., -1.0000, -1.0588, -1.1176],...,[-0.2745, -0.1569, 0.1373, ..., 0.7843, 0.7451, 0.7059],[-0.3333, -0.1765, 0.2745, ..., 0.7255, 0.7059, 0.6667],[-0.4706, -0.2353, 0.3137, ..., 0.7255, 0.7255, 0.6863]],[[ 0.8235, 1.2549, 1.8824, ..., -0.4510, -0.4510, -0.4314],[ 0.7059, 1.1176, 1.8235, ..., -0.4510, -0.4510, -0.4706],[ 0.6863, 1.1176, 1.8235, ..., -0.4706, -0.4706, -0.4706],...,[-0.1961, -0.0588, 0.2549, ..., 0.6471, 0.6667, 0.6471],[-0.2157, -0.0392, 0.3529, ..., 0.6667, 0.6863, 0.6863],[-0.3333, -0.0980, 0.3725, ..., 0.7059, 0.7451, 0.7647]],[[-0.3529, 0.0000, 0.7647, ..., 0.1176, 0.1373, 0.1373],[-0.3333, 0.0588, 0.6863, ..., 0.0392, 0.0392, 0.0392],[-0.2745, 0.1373, 0.6863, ..., -0.0196, 0.0000, 0.0196],...,[-0.8039, -0.7647, -0.4902, ..., -0.2353, -0.1961, -0.2157],[-1.0588, -0.9608, -0.6078, ..., -0.2549, -0.1765, -0.2157],[-1.2941, -1.1569, -0.7059, ..., -0.2353, -0.1569, -0.1569]]]),0)
dataloader = DataLoader(dataset, 2, collate_fn=my_collate_fn, num_workers=0,shuffle=True)
for batch_datas, batch_labels in dataloader:print(batch_datas.size(),batch_labels.size())
torch.Size([2, 3, 224, 224]) torch.Size([2])
torch.Size([2, 3, 224, 224]) torch.Size([2])
torch.Size([1, 3, 224, 224]) torch.Size([1])
torch.Size([2, 3, 224, 224]) torch.Size([2])
torch.Size([1, 3, 224, 224]) torch.Size([1])
来看一下上述batch_size的大小。其中第2个的batch_size为1,这是因为有一张图片损坏,导致其无法正常返回。而最后1个的batch_size也为1,这是因为共有9张(包括损坏的文件)图片,无法整除2(batch_size),因此最后一个batch的数据会少于batch_szie,可通过指定drop_last=True来丢弃最后一个不足batch_size的batch。
对于诸如样本损坏或数据集加载异常等情况,还可以通过其它方式解决。例如但凡遇到异常情况,就随机取一张图片代替:
class NewDogCat(DogCat):def __getitem__(self, index):try:return super(NewDogCat, self).__getitem__(index)except:new_index = random.randint(0, len(self)-1)return self[new_index]
相比较丢弃异常图片而言,这种做法会更好一些,因为它能保证每个batch的数目仍是batch_size。但在大多数情况下,最好的方式还是对数据进行彻底清洗。
DataLoader里面并没有太多的魔法方法,它封装了Python的标准库multiprocessing,使其能够实现多进程加速。在此提几点关于Dataset和DataLoader使用方面的建议:
- 高负载的操作放在
__getitem__中,如加载图片等。 - dataset中应尽量只包含只读对象,避免修改任何可变对象,利用多线程进行操作。
第一点是因为多进程会并行的调用__getitem__函数,将负载高的放在__getitem__函数中能够实现并行加速。
第二点是因为dataloader使用多进程加载,如果在Dataset实现中使用了可变对象,可能会有意想不到的冲突。在多线程/多进程中,修改一个可变对象,需要加锁,但是dataloader的设计使得其很难加锁(在实际使用中也应尽量避免锁的存在),因此最好避免在dataset中修改可变对象。例如下面就是一个不好的例子,在多进程处理中self.num可能与预期不符,这种问题不会报错,因此难以发现。如果一定要修改可变对象,建议使用Python标准库Queue中的相关数据结构。
class BadDataset(Dataset):def __init__(self):self.datas = range(100)self.num = 0 # 取数据的次数def __getitem__(self, index):self.num += 1return self.datas[index]
使用Python multiprocessing库的另一个问题是,在使用多进程时,如果主程序异常终止(比如用Ctrl+C强行退出),相应的数据加载进程可能无法正常退出。这时你可能会发现程序已经退出了,但GPU显存和内存依旧被占用着,或通过top、ps aux依旧能够看到已经退出的程序,这时就需要手动强行杀掉进程。建议使用如下命令:
ps x | grep <cmdline> | awk '{print $1}' | xargs kill
ps x:获取当前用户的所有进程grep <cmdline>:找到已经停止的PyTorch程序的进程,例如你是通过python train.py启动的,那你就需要写grep 'python train.py'awk '{print $1}':获取进程的pidxargs kill:杀掉进程,根据需要可能要写成xargs kill -9强制杀掉进程
在执行这句命令之前,建议先打印确认一下是否会误杀其它进程
ps x | grep <cmdline> | ps x
PyTorch中还单独提供了一个sampler模块,用来对数据进行采样。常用的有随机采样器:RandomSampler,当dataloader的shuffle参数为True时,系统会自动调用这个采样器,实现打乱数据。默认的是采用SequentialSampler,它会按顺序一个一个进行采样。这里介绍另外一个很有用的采样方法:
WeightedRandomSampler,它会根据每个样本的权重选取数据,在样本比例不均衡的问题中,可用它来进行重采样。
构建WeightedRandomSampler时需提供两个参数:每个样本的权重weights、共选取的样本总数num_samples,以及一个可选参数replacement。权重越大的样本被选中的概率越大,待选取的样本数目一般小于全部的样本数目。replacement用于指定是否可以重复选取某一个样本,默认为True,即允许在一个epoch中重复采样某一个数据。如果设为False,则当某一类的样本被全部选取完,但其样本数目仍未达到num_samples时,sampler将不会再从该类中选择数据,此时可能导致weights参数失效。下面举例说明。
dataset = DogCat('data/dogcat/', transform=transform)# 狗的图片被取出的概率是猫的概率的两倍
# 两类图片被取出的概率与weight的绝对大小无关,只和比值有关
weights = [2 if label == 1 else 1 for data, label in dataset]
weights
[2, 2, 2, 2, 1, 1, 1, 1]
from torch.utils.data.sampler import WeightedRandomSampler
sampler = WeightedRandomSampler(weights,num_samples=9, replacement=True
)
dataloader = DataLoader(dataset,batch_size=3,sampler=sampler)for datas, labels in dataloader:print(labels.tolist())
[0, 1, 0]
[1, 1, 1]
[1, 1, 1]
http://pytorch.org/docs/master/torchvision/datasets.html ↩︎ ↩︎