缓存数据一致性探究

缓存是一种较低成本提升系统性能的方式,自它面世第一天起就备受广大开发者的喜爱。然而正如《人月神话》中的那句经典的“没有银弹”中所说,软件工程的设计没有银弹。
就像每一次发布上线修复问题的同时,也极易引入新的问题,自缓存诞生的第一天起,缓存与数据库的数据一致性问题就深深困扰着开发者们。
关键词:原子性、事务性、数据一致性、双写一致性
缓存的查询
先查询缓存,如果查询失败,那么去查询DB,之后重建缓存,基本上不存在异议。
缓存的更新
先更新DB还是先更新缓存?是更新缓存还是删除缓存?在常规情况下,怎么操作都可以,但一旦面对高并发场景,就值得细细思量了。
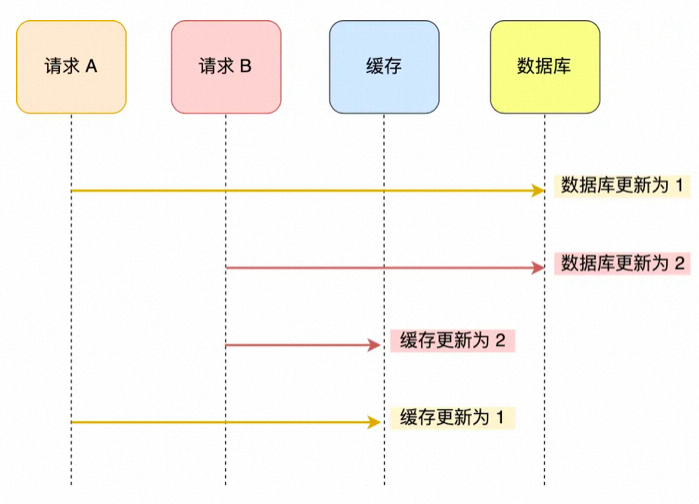
1、先更新数据库再更新缓存
线程A:更新数据库(第1s)——> 更新缓存(第10s)
线程B:更新数据库 (第3s)——> 更新缓存(第5s)
并发场景下,这样的情况是很容易出现的,每个线程的操作先后顺序不同,这样就导致请求B的缓存值被请求A给覆盖了,数据库中是线程B的新值,缓存中是线程A的旧值,并且会一直这么脏下去直到缓存失效(如果你设置了过期时间的话)。
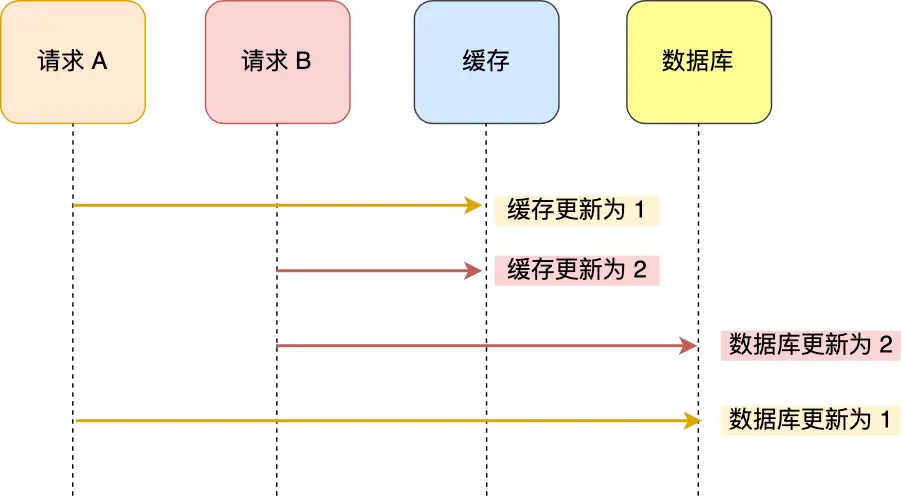
2、先更新缓存再更新数据库
线程A:更新缓存(第1s)——> 更新数据库(第10s)
线程B: 更新缓存(第3s)——> 更新数据库(第5s)
和前面一种情况相反,缓存中是线程B的新值,而数据库中是线程A的旧值。
前两种方式之所以会在并发场景下出现异常,本质上是因为更新缓存和更新数据库是两个操作,我们没有办法控制并发场景下两个操作之间先后顺序,也就是先开始操作的线程先完成自己的工作。
如果把它化简,更新时只更新数据库,同时删除缓存。等待下一次查询时命中不到缓存,再去重建缓存,是不是就解决了这个问题?
基于此,后面的两种方案应运而生。
3、先删除缓存再更新数据库
通过这种方式,我们很惊喜地发现,前面困扰我们的并发场景的问题确实被解决了!两个线程都只修改数据库,不管谁先,数据库以之后修改的线程为准。
但这个时候,我们来思考另一个场景:两个并发操作,一个是更新操作,另一个是查询操作,更新操作删除缓存后,查询操作没有命中缓存,先把老数据读出来后放到缓存中,然后更新操作更新了数据库。于是,在缓存中的数据还是老的数据,导致缓存中的数据是脏的。很显然,这种状况也不是我们想要的。
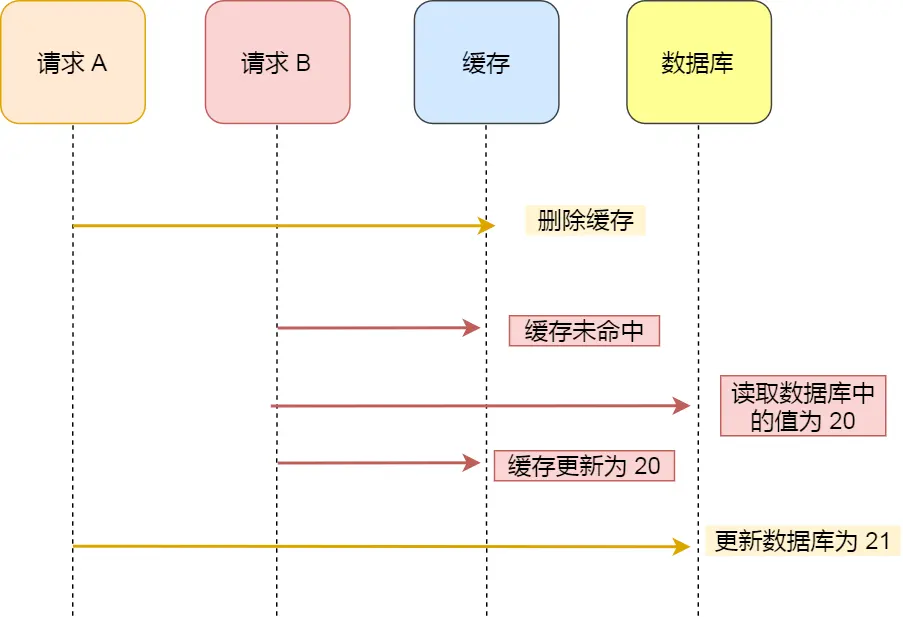
延时双删
在这种方案下,拓展出了延时双删的解决手段。
1.删除缓存
2.更新数据库
3.睡眠一段时间
4.再次删除缓存
加了个睡眠时间,主要是为了确保请求 A 在睡眠的时候,请求 B 能够在这这一段时间完成「从数据库读取数据,再把缺失的缓存写入缓存」的操作,然后请求 A 睡眠完,再删除缓存。
所以,请求 A 的睡眠时间就需要大于请求 B 「从数据库读取数据 + 写入缓存」的时间。
但是具体睡眠多久其实是个玄学,很难评估出来,所以这个方案也只是尽可能保证一致性而已,极端情况下,依然也会出现缓存不一致的现象。
因此,还是不太建议这种方案。
4、先更新数据库再删除缓存(cache aside)
这种方式,在方案3的基础上,又将二者的顺序进行了调换。我们再把前面的场景在这种方案下进行验证:一个是查询操作,一个是更新操作的并发,我们先更新了数据库中的数据,此时,缓存依然有效,所以,并发的查询操作拿的是没有更新的数据,但是,更新操作马上让缓存的失效了,后续的查询操作再把数据从数据库中拉出来。而不会方案3一样,后续的查询操作一直在取老的数据。
而这,也正是缓存使用的标准的design pattern,也就是cache aside。包括Facebook的论文《Scaling Memcache at Facebook》也使用了这个策略。
那么,是否这种方案就是万无一失的完美策略呢?其实也并不然,再来看看这种场景:一个是读操作,但是没有命中缓存,然后就到数据库中取数据,此时来了一个写操作,写完数据库后,让缓存失效,然后,之前的那个读操作再把老的数据放进去,所以,会造成脏数据。
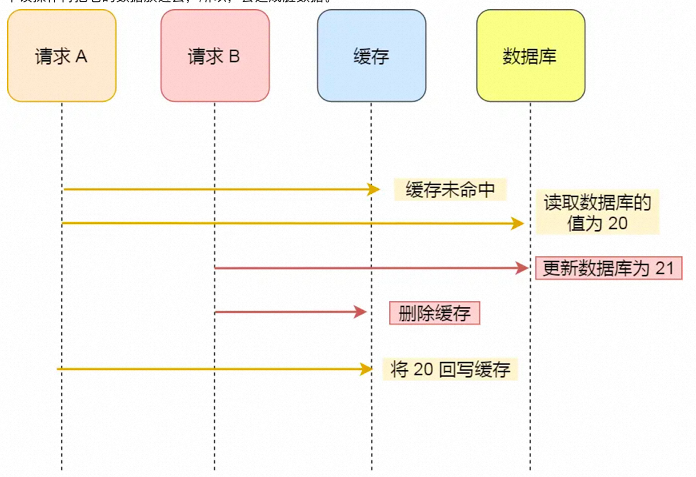
但是这个case理论上会出现,不过,实际上出现的概率可能非常低,因为这个条件需要发生在读缓存时缓存失效,而且并发着有一个写操作。而实际上数据库的写操作会比读操作慢得多,而且还要锁表,而读操作必需在写操作前进入数据库操作,而又要晚于写操作更新缓存,所有的这些条件都具备的概率基本并不大。
所以,要么通过2PC或是Paxos协议保证一致性,要么就是拼命的降低并发时脏数据的概率,而Facebook使用了这个降低概率的玩法,因为2PC太慢,而Paxos太复杂。当然,最好还是为缓存设置上过期时间,这样,即使数据出现了不一致,也能在一段时间之后失效,更新上一致的数据。
操作失败
上面虽然列举了不少较为复杂的并发场景,但实际上还是理想情况:即,对数据库和缓存的操作都是成功的。然而在实际生产中,由于网络抖动、服务下线等等原因,操作是有可能失败的。
举例说明:应用要把数据 X 的值从 1 更新为 2,先成功更新了数据库,然后在 Redis 缓存中删除 X 的缓存,但是这个操作却失败了,这个时候数据库中 X 的新值为 2,Redis 中的 X 的缓存值为 1,出现了数据库和缓存数据不一致的问题。
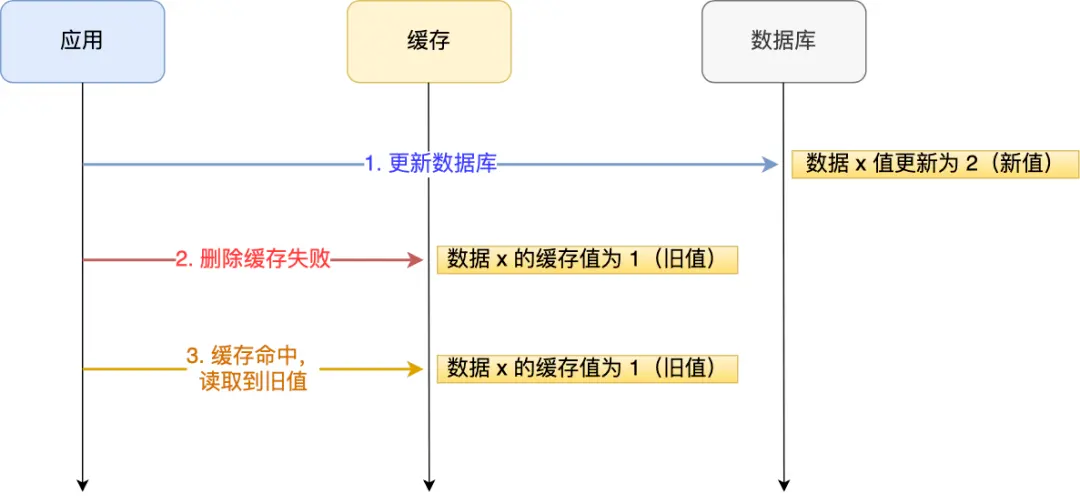
那么,后续有访问数据 X 的请求,会先在 Redis 中查询,因为缓存并没有 诶删除,所以会缓存命中,但是读到的却是旧值 1。
其实不管是先操作数据库,还是先操作缓存,只要第二个操作失败都会出现数据一致的问题。
问题原因知道了,该怎么解决呢?有两种方法:
-
重试机制。
-
订阅 MySQL binlog,再操作缓存。
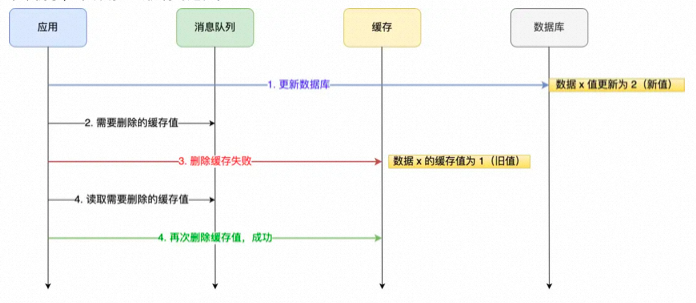
重试机制
我们可以引入消息队列,将第二个操作(删除缓存)要操作的数据加入到消息队列,由消费者来操作数据。
-
如果应用删除缓存失败,可以从消息队列中重新读取数据,然后再次删除缓存,这个就是重试机制。当然,如果重试超过一定次数,还是没有成功,我们就需要向业务层发送报错信息了。
-
如果删除缓存成功,就要把数据从消息队列中移除,避免重复操作,否则就继续重试。
举个例子,来说明重试机制的过程。
订阅 MySQL binlog,再操作缓存
「先更新数据库,再删缓存」的策略的第一步是更新数据库,那么更新数据库成功,就会产生一条变更日志,记录在 binlog 里。
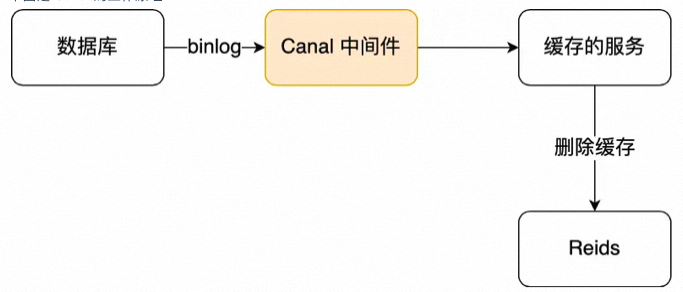
于是我们就可以通过订阅 binlog 日志,拿到具体要操作的数据,然后再执行缓存删除,阿里巴巴开源的 Canal 中间件就是基于这个实现的。
Canal 模拟 MySQL 主从复制的交互协议,把自己伪装成一个 MySQL 的从节点,向 MySQL 主节点发送 dump 请求,MySQL 收到请求后,就会开始推送 Binlog 给 Canal,Canal 解析 Binlog 字节流之后,转换为便于读取的结构化数据,供下游程序订阅使用。
下图是 Canal 的工作原理:
所以,如果要想保证「先更新数据库,再删缓存」策略第二个操作能执行成功,我们可以使用「消息队列来重试缓存的删除」,或者「订阅 MySQL binlog 再操作缓存」,这两种方法有一个共同的特点,都是采用异步操作缓存。
总结
1、cache aside并非万能
虽然说catch aside可以被称之为缓存使用的最佳实践,但与此同时,它引入了缓存的命中率降低的问题,(每次都删除缓存自然导致更不容易命中了),因此它更适用于对缓存命中率要求并不是特别高的场景。如果要求较高的缓存命中率,依然需要采用更新数据库后同时更新缓存的方案。
2、缓存数据不一致的解决方案
前面已经说了,在更新数据库后同时更新缓存,会在并发的场景下出现数据不一致,那我们该怎么规避呢?方案也有两种。
引入分布式锁
在更新缓存之前尝试获取锁,如果已经被占用就先阻塞住线程,等待其他线程释放锁后再尝试更新。但这会影响并发操作的性能。
设置较短缓存时间
设置较短的缓存过期时间能够使得数据不一致问题存在的时间也比较长,对业务的影响相对较小。但是与此同时,其实这也使得缓存命中率降低,又回到了前面的问题里...
所以,综上所述,没有永恒的最佳方案,只有不同业务场景下的方案取舍。
行文至此,不由得默念一声:“There is no silver bullet!”,并再次为《人月神话》作者的精准洞见而感叹。