【论文阅读】《Distilling the Knowledge in a Neural Network》
- 推荐指数:
1. 动机
(1)虽然一个ensemble的模型可以提升模型的效果,但是在效率方面实在难以接受,尤其是在每个模型都是一个大型的网络模型的时候。
(2)前人的研究结果也已表明:模型参数有很多其实是冗余的。
2. 方法
- distilling the knowledge in an ensemble of models into a single model.
作者们之所以这么做又是因为之前有篇文章得到的结论,这个结论【这是一个很重要的结论】是:
it is possible to compress the knowledge in an ensemble into single model.
更加具体的就是:
raise the temperature of the final softmax until the cumbersome model produces a suitably soft set of targets.
3.具体实现
在谈具体实现之前,先把本文涉及到的一些专有术语解释一下:
distilled model: 小模型(学生模型)
We have shown that distilling works very well for transferring knowledge from an ensemble or from a large highly regularized model into a smaller, distilled model.
cumbersome model: 大模型(教师模型)
4.1 训练教师模型
文中没提到如何训练教师模型,但我的理解是普通的那种训练方式即可。
4.2 训练学生模型
训练学生模型的过程:
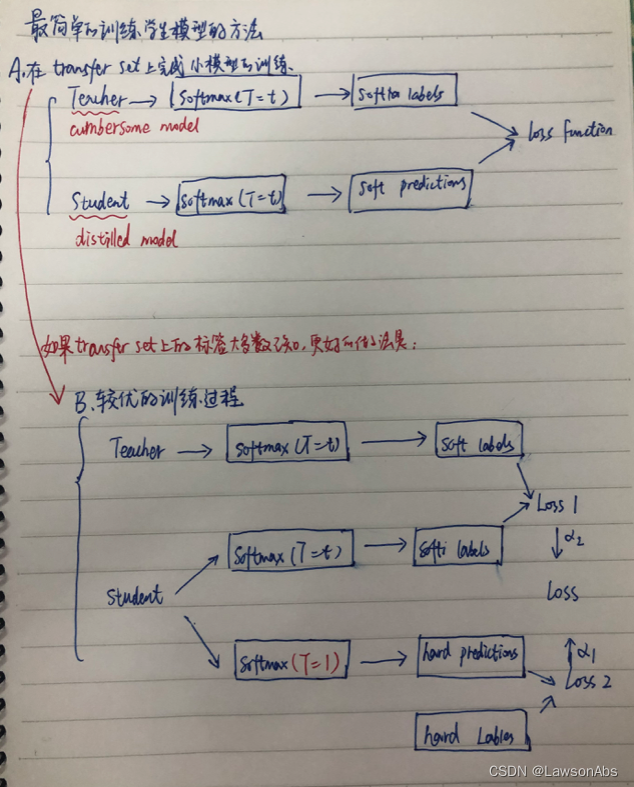
第一项损失:与软目标的交叉熵损失;
第二项损失:与正确目标的交叉熵损失;【权重较小】
5.效果
作者们提出了不同的压缩方法,并且在MNIST数据集上取得了惊人的成绩。同时在一个大量使用的商业系统的声学模型中,也有改善。
不正确值的相对概率告诉我们许多(繁重的模型是如何倾向泛化的)。文中举例解释道:将BMW误认为垃圾车的概率很小,但是这个概率会比将BMW认为是胡萝卜大很多。
作者们提出一种叫做“蒸馏”的通用解决方法,这种方法的做法是:提升最终的softmax中的温度系数直到复杂模型能够产生一个合适的软标签;然后在训练学生模型时照样使用高温度系数来匹配这些软标签。
5.数学知识
文中提到了一个数学知识,也就是下面这个:
 具体的推导我也不会,后面学习了再更。
具体的推导我也不会,后面学习了再更。