目录
一、Redis数据类型
Redis 数据类型结构简单认识
每个数据类型具体的编码方式
1.string
2.hash
3.list
4.set
5.zset
典中典:记数字!!!
6.查看 key 对应 value 的实际编码方式
如果本文有帮助到你,不妨给个三连吧~
一、Redis数据类型
Redis 数据类型结构简单认识
Redis 中所有的 key 都是 string 类型,不同的是 value 的数据类型有很多种,接下来看看几种常见的类型
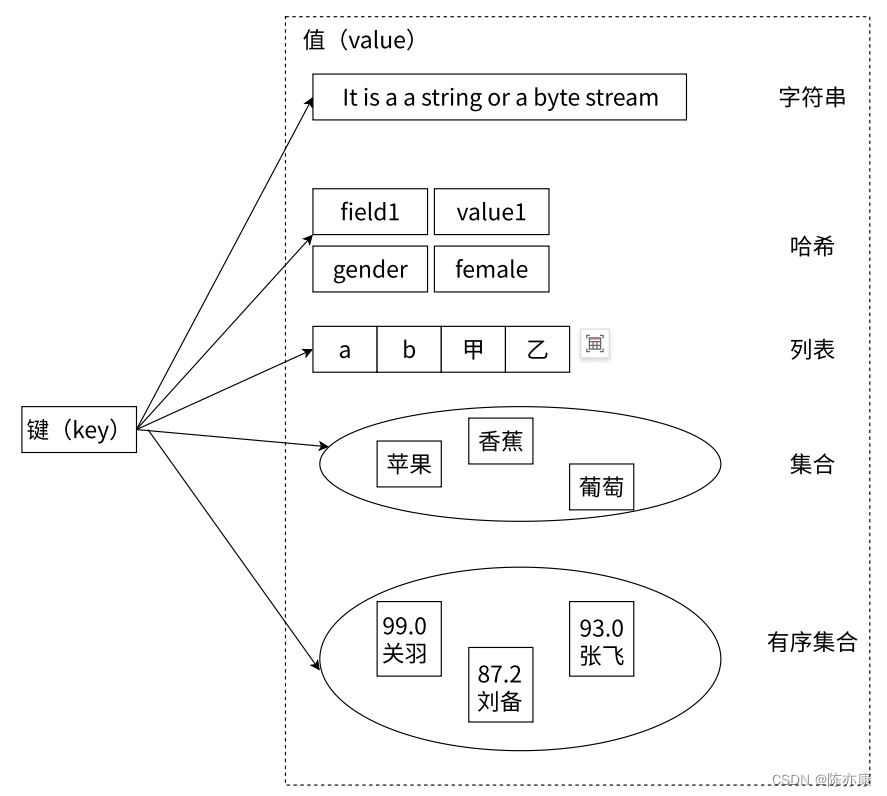
Redis 底层在实现上述数据类型的时候,会在源码层面,针对上述实现进特定的优化,达到 节省时间 / 节省空间 的效果,也就是说,内部具体实现的编码方式,还会有变数.
例如之前炒的很热的一个新闻:“指鼠为鸭”~
鸭脖店,承诺卖给你的这个东西吃起来和鸭脖是一样的,但是内部的数据结构,是否真的是鸭脖,可能就根据实际情况,做出一定的优化.
Ps:redis 承诺,这里有个 hash 表,你进行 查询、插入、删除、操作,都保证 O(1),但是背后的实现不一定就是标准的 hash 表,可能在特定场景下使用别的数据结构.
每个数据类型具体的编码方式
同一个数据类型,背后的可能的编码方式是不同的,会根据特定场景优化(redis 会自动适应,程序员在使用 redis 的时候一般感知不到~)
1.string
string 类型内部有以下三种编码方式:
- raw:最基本的字符串,底层就是一个 java 中 byte 类型的数组(C++ 中 char 类型的数组,C++ 中 char 是一个字节).
- int:整形类型,redis 通常用来实现 “计数”这样的功能,当 value 是一个整数的时候,此时 redis 可能直接使用 int 来保存.
- embstr:针对短字符串进行的特殊优化.
2.hash
hash 类型内部有以下两种编码方式:
- hashtable:最基本的哈希表(不是 java 标准库中的 HashTable),redis 内部对哈希表的实现方式和 java 中的哈希表可能不太一样,当时整体思想都是一样的(比如对数组下的节点进行赋值时,先检查有没有这个元素,若有就会直接覆盖,没有就会看有没有 hash 冲突...)
- ziplist:压缩列表,当哈希表里的元素比较少的时候,就优化成了 ziplist 了,能够节省空间(压缩的原因:redis 上有很多 key,可能某些 key 的 value 是 hash,此时如果 key 特别多,对应的 hash 也特别多,但是每个 hash 又不是特别大的情况下,就尽量去压缩,让整体占用内存更小了);
3.list
list 类型内部有以下两种编码方式:
- linkedlist:双向链表,当一个 list 包含了数量比较多的元素,又或者 list 中包含的元素都是比较长的字符串时,Redis就会使用 linkedlist 作为 list 的底层实现。
- ziplist:压缩列表,当哈希表里的元素比较少的时候,就优化成了 ziplist 了,能够节省空间(压缩的原因:redis 上有很多 key,可能某些 key 的 value 是 hash,此时如果 key 特别多,对应的 hash 也特别多,但是每个 hash 又不是特别大的情况下,就尽量去压缩,让整体占用内存更小了);
Ps:redis 从 3.2 开始,引入了新的实现方式 quicklist,quicklist 就是一个链表,每个元素又是一个 ziplist,同时兼顾了 linkedlist 和 ziplist 的优点,空间和效率都兼顾到了.
4.set
set 类型内部有以下两种编码方式:
- hashtable:最基本的哈希表(不是 java 标准库中的 HashTable),redis 内部对哈希表的实现方式和 java 中的哈希表可能不太一样,当时整体思想都是一样的(比如对数组下的节点进行赋值时,先检查有没有这个元素,若有就会直接覆盖,没有就会看有没有 hash 冲突...)
- intset:是一个集合中存的都是整数的结构.
5.zset
zset 类型内部有以下两种编码方式:
- skiplist:跳表,类似于 leetcode 上的一个经典题目,“复制带随机指针的链表”,跳表也是链表,不同于普通的链表,每一个节点上有多个指针域,巧妙的搭配这些指针域的指向就可以做到,从跳表上查询元素的时间复杂度是 O(logN).
- ziplist:压缩列表,当哈希表里的元素比较少的时候,就优化成了 ziplist 了,能够节省空间(压缩的原因:redis 上有很多 key,可能某些 key 的 value 是 hash,此时如果 key 特别多,对应的 hash 也特别多,但是每个 hash 又不是特别大的情况下,就尽量去压缩,让整体占用内存更小了).
典中典:记数字!!!
redis 会根据当前的 实际情况选择内部的编码方式,自动适应,那么是否要记住,啥时候使用啥编码方式呢?
只记思想,不记数字!!!
比如网上可能会说:“如果字符串的长度小于 39 字节使用 embstr ,超过 39 字节使用 raw”。
可能你就会觉得,啊,这 39 就是一个重点,但我要告诉你的是,记数字,没有任何意义!!!
- 数字都是可配置的.
- 数字是咋来的?需要考证清楚!相比于知道数字,更重要的是知道数字是怎么得到的,就可以根据所处的实际场景,重新得到这样的数字.
很多同学会陷入“记数字”的误区,大多是因为学校的考试和工作面试差别很大:学校考试有标准答案,而面试中有一部分有标准答案,也有一部分没有标准答案,面试官看中的不是答案,而是你解决问题的过程和思路,哪怕是错的,可能看你思维不错,也会留用你~
可能大家记得最多的就是 HashMap 的相关数字,比如,链表长度达到 xx ,就会变成红黑树,负载因子达到 xx 就会触发扩容,在实际的工作中,遇到的场景,和上述数字就不一定合适了,正确的做法是,根据实际的测试结果,测试出一个更合适的数值,类似还有线程池线程数目设置成多少这样的问题...
这些参数都是很常见的,同时也是可调的~
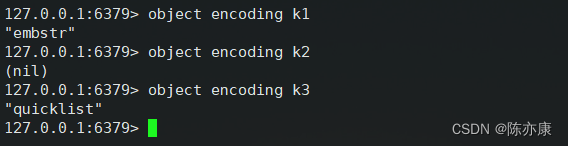
6.查看 key 对应 value 的实际编码方式
如果你想了解当前场景下,你的 value 到底被优化成了何种编码方式,也是可以通过以下指令观察到的~
object encoding key