半同步半异步线程池介绍
在处理大量并发任务的时候,如果按照传统的方式,一个请求一个线程来处理请求任务,大量的线程创建和销毁将消耗过多的系统资源,还增加了线程上下文切换的开销,而通过线程池技术就可以很好的解决这些问题。线程池技术通过在系统预先创建一定数量的线程,当任务请求到来时从线程池中分配一个预先创建的线程去处理任务,线程在处理完任务之后还可以重用,不会销毁,而再等待下次任务的到来。这样,通过线程池能避免大量的线程创建和销毁动作,从而节省系统资源,这样做的一个好处是,对于多核处理器,由于线程会被分配到多个CPU,会提高并行处理的效率。另一个好处是每个线程独立阻塞,可以防止主线程被阻塞而使主流程被阻塞,导致其他的请求得不到响应的问题。
线程池分为半同步半异步线程池和领导者追随线程池,本章将主要介绍半同步半异步线程池,这种线程池在实现上更简单,使用的也比较多,也比较方便。半同步半异步线程池分成三层。
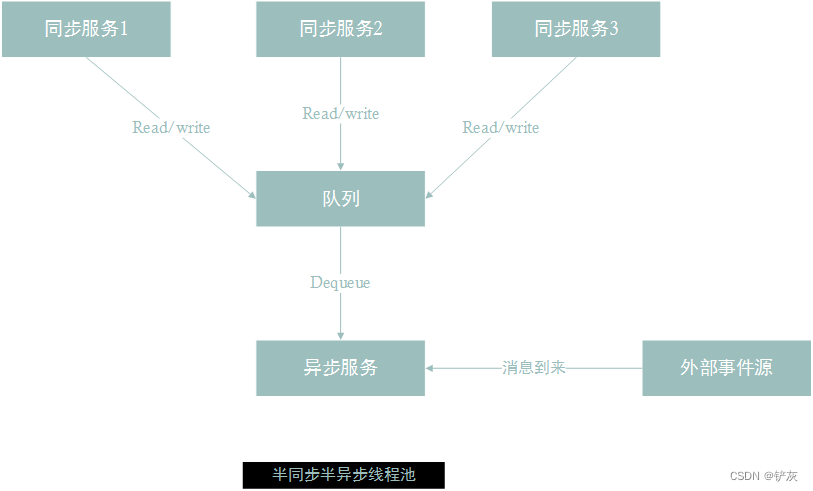
第一层是同步服务层,它处理来自上层的任务请求,上层的请求可能是并发的,这些请求不是马上就会被处理,而是将这些任务放到一个同步排队层中,等待处理。第二层是同步排队层,来自上层的任务请求都会加到排队层中等待处理。第三层是异步服务层,这一层中会有很多个线程同时处理排队层中的任务,异步服务层从同步排队层中取出任务并行的处理。
这种三层的结构可以最大程度处理上层的并发请求。对于上层来说只要将任务丢到同步队列中就行了,至于谁去处理,什么时候处理都不用关心,主线程也不会阻塞,还能继续发起新的请求。至于任务具体怎么处理,这些细节都是靠异步服务层的多线程并行来完成的,这些线程是一开始就创建的,不会因为大量的任务到来而创建新的线程,避免了频繁创建和销毁线程导致的系统开销,而且通过多核能处理大幅提高处理效率。
线程池实现的关键技术分析
线程池是由三层组成的:同步服务层,排队层和异步服务层,其中排队层居于核心地位,因为上层会将任务加到排队层中,异步服务层同时也会取出任务,这里有一个同步的过程。在实现时,排队层就是一个同步队列,允许多个线程同时去添加或取出任务,并且要保证操作过程是安全的。线程池有两个活动记录,一个是往同步队列中添加任务,另一个是从同步队列中取任务的过程。
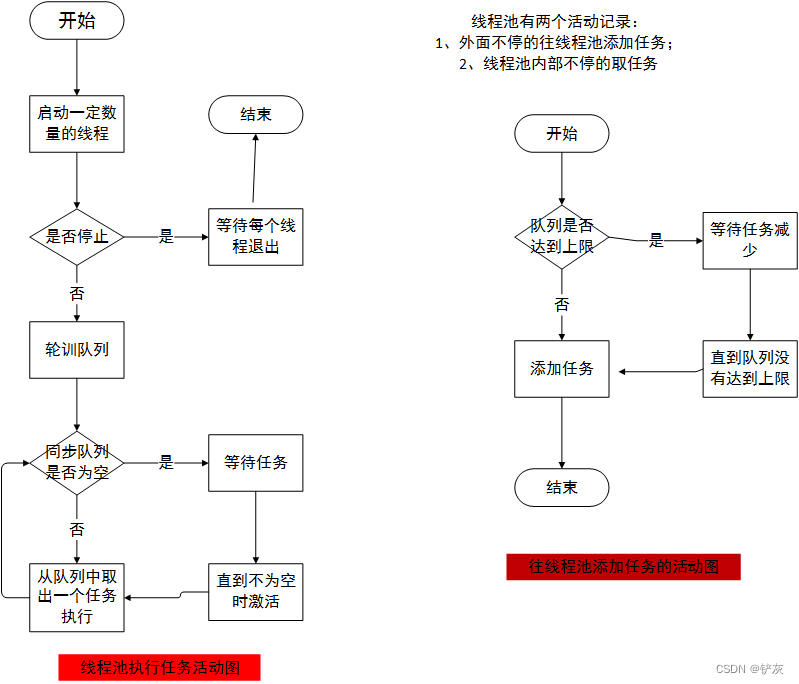
半同步半异步线程活动图
从活动图中可以看到线程池的活动过程,一开始线程池会启动一定数量的线程,这些线程属于异步层,主要用来并行处理排队层中的任务 ,如果排队层中的任务数为空,则这些线程等待任务的到来。如果发现排队层中有任务了,线程池则会从等待的这些线程中唤醒一个来处理新任务。同步服务层则会不断的将新的任务添加到同步排队层中,这里有一个问题值得注意,有可能上层的任务非常多,而任务又非常耗时,这是,异步层中的线程处理不过来,则同步排队层中的任务会不断添加,如果同步排队层不加上限控制,则可能会导致排队层中的任务过多,内存报错的问题。因此,排队层需要加上上限控制,当排队层中的任务数量达到上限,就不让上层的任务添加进来,起到限制和保护的作用。
同步队列
同步队列即为线程中三层结构中的中间那一层,它的主要作用是保证队列中共享数据线程安全,还为上一层服务层提供添加新任务的接口,以及为下一层异步服务层提供取任务的接口。同时,还要限制任务数的上限,避免任务过多导致内存暴涨的问题。同步队列的锁是用来线程同步,条件变量是用来实现线程通信,即线程池空了就要等待,不为空就通知一个线程去处理;线程池满了就等待,直到没有满的时候才通知上层添加新的任务。同步队列的具体实现如下所示:
#include <list>
#include <mutex>
#include <thread>
#include <condition_variable>
#include <iostream>
using namespace std;template<typename T>
class SyncQueue
{
public:SyncQueue(int maxSize = 1024) : m_maxSize(maxSize), m_needStop(false){}void Put(const T& x){Add(x);}void Put(T&& x){Add(std::forward<T>(x));}void Take(std::list<T>& list){std::unique_lock<std::mutex> locker(m_mutex);m_notEmpty.wait(locker, [this]{ return m_needStop || NotEmpty(); });if (m_needStop){return;}list = std::move(m_queue);m_notFull.notify_one();}void Take(T& t){std::unique_lock<std::mutex> locker(m_mutex);m_notEmpty.wait(locker, [this]{ return m_needStop || NotEmpty(); });if (m_needStop){return;}t = m_queue.front();m_queue.pop_front();m_notFull.notify_one();}void Stop(){{std::lock_guard<std::mutex> locker(m_mutex);m_needStop = true;}m_notFull.notify_all();m_notEmpty.notify_all();}bool Empty(){std::lock_guard<std::mutex> locker(m_mutex);return m_queue.empty();}bool Full(){std::lock_guard<std::mutex> locker(m_mutex);return m_queue.size() == m_maxSize;}size_t Size(){std::lock_guard<std::mutex> locker(m_mutex);return m_queue.size();}int Count(){return m_queue.size();}private:bool NotFull() const{bool full = m_queue.size() > m_maxSize;if (full){cout << "缓冲区满了,需要等待..." << endl;}return !full;}bool NotEmpty() const{bool empty = m_queue.empty();if (empty){cout << "缓冲区空了,需要等待...异步层的线程ID: " << this_thread::get_id() << endl;}return !empty;}template<typename F>void Add(F&& x){std::unique_lock<std::mutex> locker(m_mutex);m_notFull.wait(locker, [this]{ return m_needStop || NotFull(); });if (m_needStop){return;}m_queue.push_back(std::forward<F>(x));m_notEmpty.notify_one();}private:int m_maxSize; ///同步队列最大的sizebool m_needStop; ///停止的标志std::list<T> m_queue; ///缓冲区std::mutex m_mutex; ///互斥量和条件变量结合使用std::condition_variable m_notEmpty; ///不为空的条件变量std::condition_variable m_notFull; ///没有满的条件变量};Take(std::list<T>& list)函数做到了一次加锁就能将队列中所有数据都取出来,从而大大减少加锁的次数。在获取互斥锁之后,我们不再只获取一条数据,而是通过std::move来将队列中所有数据move到外面去,这样既大大减小了获取数据加锁的次数,又直接通过移动避免了数据的复制,提高了性能。
下面具体介绍同步队列的3个函数Take,Add和Stop的实现。
Take函数
先创建一个unique_lock获取mutex,然后再通过条件变量m_notEmpty来等待判断式,判断式由两个条件组成,一个是停止的标志,另一个是不为空的条件,当不满足任何一个条件时,条件变量会释放mutex并将线程置于waiting状态,等待其他线程调用notify_one/notify_all将其唤醒;当满足任何一个条件时,则继续往下执行后面的逻辑,即将队列中的任务取出,并唤醒一个正处于等待状态的添加任务的线程去添加任务。当处于waiting状态的线程被notify_one或notify_all唤醒时,条件变量会先重新获取mutex,然后再检查条件是否满足,如果满足,则往下执行,如果不满足,则释放mutex继续等待。
void Take(std::list<T>& list){std::unique_lock<std::mutex> locker(m_mutex);m_notEmpty.wait(locker, [this]{ return m_needStop || NotEmpty(); });if (m_needStop){return;}list = std::move(m_queue);m_notFull.notify_one();}Add函数
Add的过程和Take的过程类似,也是先获取mutex,然后检查条件是否满足,不满足条件,释放mutex继续等待,如果条件满足,则将新任务插入到队列中,并唤醒取任务的线程去取数据。
template<typename F>void Add(F&& x){std::unique_lock<std::mutex> locker(m_mutex);m_notFull.wait(locker, [this]{ return m_needStop || NotFull(); });if (m_needStop){return;}m_queue.push_back(std::forward<F>(x));m_notEmpty.notify_one();}Stop函数
Stop函数先获取mutex,然后将停止标志置为true。注意,为了保证线程安全,这里需要先获取mutex,在将其标志置为true,再唤醒所有等待的线程,因为等待的条件是m_needStop,并且满足条件,所以线程会继续往下执行。由于线程在m_needStop为true时会退出,所以所有的等待的线程也相继退出。另外一个值得注意的地方,我们把m_notFull.notify_all()放到lock_guard保护范围之外,这里也可以将把m_notFull.notify_all()放到lock_guard保护范围之内,放到外面是为了做一点优化。因为notify_one或notify_all会唤醒一个在等待的线程,线程被唤醒后先获取mutex再检查条件是否满足,如果这时被lock_guard保护,被唤醒的线程则需要lock_guard析构释放mutex才能获取。如果在lock_guard之外notfiy_one或notify_all,被唤醒的线程获取锁的时候不需要等待lock_guard释放锁,性能会好一点,所以在执行notify_one或notify_all时不需要加锁保护。
void Stop(){{std::lock_guard<std::mutex> locker(m_mutex);m_needStop = true;}m_notFull.notify_all();m_notEmpty.notify_all();}线程池
一个完整的线程池包括三层:同步服务层,排队层和异步服务层,其实这也是一种生产者-消费者模型,同步层是生产者,不断将新任务丢到排队层中,因此,线程池需要提供一个添加新任务的接口供生产者使用;消费者是异步层,具体是由线程池中预先创建的线程去处理排队层中的任务。排队层是一个同步队列,它内部保证了上下两层对共享数据的安全访问,同时还要保证队列不会被无限制地添加任务导致内存暴涨。另外,线程池还要提供一个停止的接口,让用户能够在需要的时候停止线程池的运行,下面是线程池的实现方式:
#include <list>
#include <thread>
#include <functional>
#include <memory>
#include <atomic>
#include "sync.h"const int MaxTaskCount = 100;
class ThreadPool
{
public:using Task = std::function<void()>;ThreadPool(int numThreads = std::thread::hardware_concurrency()) :m_queue(MaxTaskCount){printf("create thread num:%d\n", numThreads);Start(numThreads);}~ThreadPool(){Stop();}void Stop(){///保证多线程情况下只调用一次StopThreadGroupstd::call_once(m_flag, [this]{StopThreadGroup(); });}void AddTask(Task&& task){m_queue.Put(std::forward<Task>(task));}void AddTask(const Task& task){m_queue.Put(task);}private:void Start(int numThreads){m_running = true;for(int i = 0; i < numThreads; i++){///创建线程组m_threadgroup.push_back(std::make_shared<std::thread>(&ThreadPool::RunInThread, this));}}void RunInThread(){while(m_running){///取任务分别执行std::list<Task> list;m_queue.Take(list);for(auto &task : list){if (!m_running)return;task();}}}void StopThreadGroup(){m_queue.Stop();m_running = false;for(auto thread : m_threadgroup){if (thread){thread->join();}}m_threadgroup.clear();}private:std::list<std::shared_ptr<std::thread>> m_threadgroup; ///处理任务的线程组SyncQueue<Task> m_queue; ///同步队列atomic_bool m_running; ///是否停止的标志std::once_flag m_flag;
};ThreadPool pool;void func1()
{for(int i = 0; i < 10; i++){auto thdId = this_thread::get_id();pool.AddTask([thdId]{cout << "同步层线程1的线程ID:" << thdId << endl;} );}
}void func2()
{for(int i = 0; i < 10; i++){auto thdId = this_thread::get_id();pool.AddTask([thdId]{cout << "同步层线程2的线程ID:" << thdId << endl;} );}
}int main()
{thread t1(func1);thread t2(func2);getchar();pool.Stop();t1.join();t2.join();return 0;
}在上面的例子中,ThreadPool有3个成员,一个是线程组,这个线程组中的线程是预先创建的,应该创建多少个线程由外部传入,一般建议创建CPU核数的线程以达到最优的效率,线程组循环从同步队列中取出任务并执行,如果线程池为空,线程组将处于等待状态,等待任务的到来。另外一个成员变量是同步队列,它不仅用来做线程同步,还用来限制同步队列的上限,这个上限也是由使用者设置的。第三个成员变量是用来停止线程池的,为了保证线程的安全。
在这个例子中,外部线程将不断的像线程池中添加新任务,线程池内部的线程将会并行处理同步队列中的任务。
缓冲区空了,需要等待...异步层的线程ID: 140667074565888
缓冲区空了,需要等待...异步层的线程ID: 140666806126336
同步层线程1的线程ID:140666537686784
同步层线程1的线程ID:缓冲区空了,需要等待...异步层的线程ID: 140666537686784
同步层线程2的线程ID:140666269247232
同步层线程2的线程ID:140666269247232
同步层线程2的线程ID:140666269247232
同步层线程2的线程ID:140666269247232
140666806126336同步层线程2的线程ID:140666269247232
同步层线程2的线程ID:140666269247232
同步层线程2的线程ID:140666269247232
同步层线程2的线程ID:140666269247232
同步层线程2的线程ID:140666269247232同步层线程2的线程ID:140666269247232
同步层线程1的线程ID:140666537686784
同步层线程1的线程ID:140666537686784
同步层线程1的线程ID:140666537686784
同步层线程1的线程ID:140666537686784
同步层线程1的线程ID:140666537686784
同步层线程1的线程ID:140666537686784
同步层线程1的线程ID:140666537686784
同步层线程1的线程ID:140666537686784
缓冲区空了,需要等待...异步层的线程ID: 140667074565888测试结果如上所示。
由测试结果可以看到,线程池初始化创建了两个内部的线程,线程ID分别是140667074565888和140666806126336,由于初始化时,线程池中的同步队列是空的,所以这两个线程将进入等待状态,直到队列中有数据时才开始处理数据。线程池的上层有两个线程,线程ID分别是140666537686784和140666269247232,这两个线程不断往线程池中添加数据,这些数据会被添加到排队层中,供异步服务层的线程处理。最终的结果是,异步层的线程交替处理来自上层的任务,交替打印出上层的线程ID,缓冲区空了就会等待,满了之后也会等待,不允许无限制添加任务。