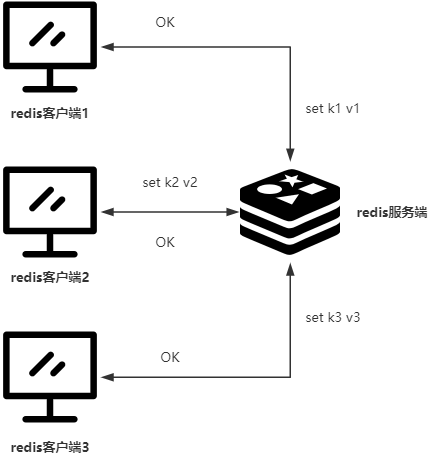
一、Redis面试题集锦
1.1、Redis到底是单线程还是多线程
Redis6.0版本之前的单线程指的是其网络IO和键值对读写是由一个线程完成的;
Redis6.0引入的多线程指的是网络请求过程采用了多线程,而键值对读写命令仍然是单线程的,所以多线程环境下,redis依然是并发安全的,也即只有网络请求模块和数组操作模块是单线程的,而其他的持久化、集群数据同步等,其实是由额外的线程执行的;
1.2、Redis单线程为什么还能这么快
(1)命令执行基于内存操作,一条命令在内存里操作的时间只有几十纳秒;
(2)命令执行是单线程操作的,这就省去了线程切换的开销;
(3)基于IO多路复用机制,提升了I/O的利用率;
(4)高效的数据存储结构:全局Hash表、跳表、压缩列表、链表等;

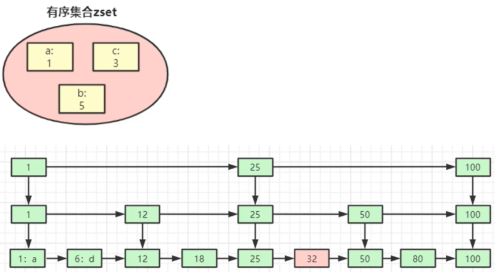
1.3、Redis底层数据是如何用跳表来存储的
所谓跳表,是指将有序链表改造为支持近似"折半查找"算法,可以进行快速的插入、删除、查找操作;
1.4、Redis key过期了,为什么内存没释放
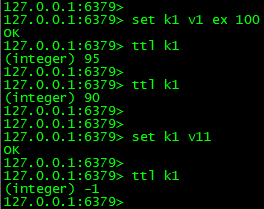
(1)原因一:先设置了key的过期时间,然后修改了key的值,修改key的值时没有指定过期时间,如下:
(2)原因二:跟redis过期key的删除策略有关
惰性删除:当读/写一个已经过期的key时,会触发惰性删除策略,判断当前要操作的key是否过期了,如果过期了则直接删除;
定时删除:由于惰性删除策略无法保证冷数据被及时删除,所以redis会定期(默认每100ms)主动淘汰一批已经过期的key,这里的一批只是一部分过期的key,所以也会出现部分key即使过期了,但是没有被及时清理掉的情况,导致内存没有被实时释放;
1.6、LRU vs LFU
LRU 和 LFU是redis中基于key的淘汰策略中的两种不同算法。区别如下:
LRU算法(Least Recently Used):最近最少使用,淘汰很久没被访问过的数据,以最近一次时间作为参考;
LFU算法(Least Frequently Used):最不经常使用,淘汰最近一段时间被访问次数最少的数据,以次数作为参考,绝大多数情况下我们都可以使用LRU策略,当存在大量热点缓存数据时,LFU可能会更好一些;
1.7、删除key的指令会阻塞redis吗
分情况。如果删除的是单个字符串类型的key,时间复杂度为o(1),不会阻塞redis,如果删除的是单个列表、集合、有序集合或者哈希表的类型,时间复杂度为o(M),M为数据结构内的元素的数量,如果M的值很大的话,将会导致redis阻塞;
1.8、Redis主从、哨兵、集群大PK
1.8.1、主从模式
Redis主从复制架构是用来解决数据的冗余备份的,主节点用来对外提供服务,从节点仅仅用来同步数据。

1.8.2、哨兵模式
在redis3.0之前的版本要想实现集群,一般是借助哨兵来监控master节点的状态,如果master节点异常,则会做主从切换,将某一台slave切换为主节点,哨兵的配置略微复杂,并且性能和高可用性等各方面表现一般,特别是在主从切换的瞬间,而且哨兵模式只有一个主节点对外提供服务,无法支持很高的并发,且单个主节点的内存也不宜设置的过大,否则会导致持久化文件过大,影响数据恢复或者主从同步的效率。

1.8.3、集群模式
redis集群是一个由多个主从节点群组成的分布式服务器群,具有复制、高可用和分片的特性。redis集群不需要sentinel哨兵也能完成节点移除和故障转移功能。需要将每个节点设置成集群模式,这种集群模式没有中心节点,可以水平扩展,根据官方文档的数据,可以扩展至上万个节点(官方推荐不超过1000个节点),redis集群的性能和高可用性均优于之前版本的哨兵模式,且集群配置非常简单。

1.9、redis集群数据hash分片算法是怎么回事
redis集群将所有数据划分为16384个槽位(slots),每一个节点负责其中一部分槽位,槽位的信息存储于每个节点中,当redis集群的客户端来连接集群时,它会得到一份集群的槽位配置信息并将其缓存在客户端本地,这样当客户端要查找某个key时,就可以根据槽位定位算法定位到目标点位。
槽位定位算法:redis集群默认会对key的值使用crc16算法进行hash得到一个整数值,然后用这个整数值对16384取模得到具体的槽位,公式为:CRC16(key) mod 16384. 接着再根据槽位值和redis节点的对应关系就可以定位到key具体落到哪个redis节点上。

1.10、Redis主从切换导致缓存雪崩可能的原因
我们假设slave机器的时钟比master快很多,此时redis主节点里面设置了过期时间key,站在slave的角度来看,可能很多在master节点里面的数据其实已经过期了,此时如果进行了主从切换,把该slave节点提升为新的master节点了,那么就会清理大量过期的key,此时就可能会导致以下结果:
(1)master大量清理过期的key,主线程可能会发生阻塞,无法及时处理客户端的请求;
(2)系统中的缓存大量失效,恰好在这一时刻涌入进来了大量的客户端请求,导致缓存模块无法利用,进而引起大量的请求直接打到数据库服务器上,导致数据库阻塞甚至宕机。
当master节点和slave节点的机器时钟不一致时,对业务的影响非常大,所以我们一定要保证主从库的机器时钟一致性,避免发生类似的问题。
1.11、 Redis线上数据如何备份
方式一:写crontab定时调度脚本,每小时都拷贝一份rdb或者aof文件到另一台机器中去,保留最近48小时的备份;
方式二:每天都保留一份当日的数据备份到一个目录中去,可以保留最近一个月的备份;
方式三:每次拷贝备份的时候,都把太旧的备份删除了;
1.12、Redis集群网络抖动导致频繁主从切换怎么处理
真实世界的机房网络往往不是风平浪静的,它们经常会发生各种各样的小问题。例如网络抖动就是非常常见的一种现象,突然之间部分连接变得不可访问,然后很快又恢复正常。为了解决这种问题,redis集群提供了一种选线 cluster-node-timeout ,表示当某个节点持续timeout的时间失联时,才可以认定该节点出现故障,需要进行主从切换,如果没有这个选项,网络抖动将会导致频繁的主从切换。
1.13、Redis集群为什么至少需要三个master节点
因为新的master节点的选举需要大于半数的集群master节点同意才能选举成功,如果只有2个master节点,当其中一个挂了,是达不到新master节点的选举条件的。
1.14、Redis集群为什么推荐奇数个节点
因为新的master节点的选举需要大于半数的集群master节点同意才能选举成功,奇数个master节点可以在满足选举的基础上节省一个节点(节省节点就是节省钱),3个节点和4个节点的master集群相比,大家如果都挂了一个master节点的话,都能选举出新的master节点,如果挂了2个master节点的话,就无法选举出新的节点了,所以基数的节点更多的是从节省资源角度出发的。
1.15、Redis集群支持批量操作命令吗
对于类似mset、mget这样的多个key的原生批量操作指令,redis集群只支持所有key落在同一slot的情况,如果有多个key一定要用mset命令在redis集群上操作,则可以在key的前面加上{xxx},这样参数数据分片hash计算的只会是大括号里面的值,这样就能保证不同的key都能落到同一个slot里面去,如下:
mset {user1}:1:name zhangsan {user1}:1:age 18
假设name和age计算出的hash slot值不一样,但是由于这条命令是在集群下执行的,redis只会用大括号里面的user1作为hash slot计算,所以计算出来的slot值肯定相同,最终保证批量的数据都落在同一slot上。
1.16、Lua脚本能在Redis集群中执行吗
redis官方规定Lua脚本想在redis集群里面执行,需要Luau脚本里操作的所有的key落在集群的同一个节点上,这样的话我们可以给Lua脚本的key前面加上一个相同的hash tag,即{xxx},这样就能保证Lua脚本里所有的key都落在相同的节点上了。
1.17、Redis的分布式锁的底层实现原理
1.1.8、Redis主从复制的核心原理
1.19、Redis和MySQL如何保证数据一致性
方案一:先更新MySQL,再更新redis,如果redis更新失败,将会导致redis中的数据和DB中的数据不一致;
方案二:先删除redis中的数据,再更新mysql,再次查询的时候在将数据添加到redis缓存中,这种方案能解决方案一中出现的问题,但是在高并发场景下性能较低,而且仍然会出现数据不一致的问题,比如线程一删除了redis缓存的数据,正在更新MySQL,此时线程二执行查询操作,发现缓存没有,于是查询数据库并将查询到的结果放进redis,那么就会把MySQL中的老数据重新放回到redis中;
方案三:延时双删,所谓延时双删指的是,先删除redis中缓存的数据,再更新MySQL中的数据,延迟几百毫秒后再次删除redis中的数据,这样就算在更新MySQL时,其他线程读取了MySQL,把老数据读取到了redis中,那么存储进redis中的数据也会被删除掉,从而保证Redis和MySQL的数据一致性;
1.20、Redis的集群方案
1.21、布隆过滤器原理 & 优缺点
1.22、分布式系统中常用的缓存方案有哪些
(1)客户端缓存:页面和浏览器缓存、APP缓存、H5缓存、localStorage缓存、sessionStorage缓存;
(2)CSN缓存;
内容存储:数据的缓存
内容分发:负载均衡
(3)Nginx缓存:静态资源;
(4)服务端缓存:本地缓存、外部缓存;
(5)数据库缓存:持久层缓存(MyBatis、Hibernate多级缓存)、MySQL查询缓存;
(6)操作系统缓存:Page Cache、Buffer Cache
1.23、缓存穿透 vs 缓存击穿 vs 缓存雪崩
1.23.1、缓存穿透
概述:执行的查询逻辑,缓存中查询不到,数据库中也查询不到。
解决方案:
(1)业务逻辑层对参数进行合法性校验;
(2)将数据库中没有查询到的数据也写入缓存;注意事项:为了防止redis被无用的key占满,这一类型的key的有效期要尽可能的设置的短一点;
(3)引入布隆过滤器,在访问redis之前先判断数据是否存在;注意事项:使用布隆过滤器存在一定的误判率,并且布隆过滤器只能加数据,不能减数据;
MyBatis是如何解决缓存穿透的?
将数据库中没有查询到的结果,也进行缓存;
项目中有没有遇到?
没有用到。项目中我们使用的是MyBatis框架作为持久层,MyBatis已经解决了缓存穿透的问题。
1.23.2、缓存击穿
概述:
执行的查询逻辑,缓存中查询不到,数据库中可以查询的到,一般出现在数据初始化及key过期了的情况;
存在的问题:
写入缓存需要一定的时间,如果是在高并发的场景下,恰巧在数据还没有写入到redis缓存中时,大量请求蜂拥而至,那么一瞬间就会有大量请求访问DB,给DB造成巨大的压力,甚至宕机;
解决方案:
(1)设置热点key永不过期;注意事项:要在value中包含一个逻辑上的过期时间,然后另起一个线程,定期重建这些缓存;
(2)加载DB的时候,防止高并发,也可以通过限流的方式来解决;
1.23.3、缓存雪崩
概述:
在系统运行的某一时刻,突然系统中的缓存全部失效,恰好在这一时刻涌来了大量的客户请求,导致所有模块缓存无法利用,进而引起大量请求涌向数据库查询的极端情况,导致数据库阻塞或者挂起;
解决方案:
(1)缓存永久存储(不推荐);
(2)针对于不同的业务数据,设置不同的超时时间;
1.24、简述redis的事务实现原理
redis的事务实现主要包含如下三个步骤,即:事务开始、命令入队、事务执行。下面分别介绍:
事务开始:MULTI命令的执行,标识着一个事务的开始。MULTI命令是在客户端状态的flags属性中打开REDIS_MULTI标识来完成的;
命令入队:当一个客户端切换到事务状态之后,服务器会根据这个客户端发送过来的命令执行不同的操作。如果客户端发送的命令为MULTI、EXEC、WATCH、DISCARD指令中的任意一个,那么服务器将会立即执行该命令,否则将命令放入一个事务队列里面,然后向客户端返回QUEUED回复;详细流程如下:
(1)如果客户端发送的命令为MULTI、EXEC、WATCH、DISCARD指令中的任意一个,那么服务器将会立即执行该命令;
(2)如果客户端发送的是上述四个命令之外的其他指令,那么服务器并不立即执行这个命令;
(3)检查命令的格式是否正确,如果不正确,服务端会在客户端状态的flags属性关闭REDIS_MULTI标识,并返回错误信息给客户端;如果正确,则将这个命令放入一个事务队列里面,然后返回QUEUED的响应给客户端;
(4)事务队列是按照FIFO的方式保存入队的命令;
事务执行:客户端发送EXEC命令,服务器执行EXEC命令逻辑;
(1)如果客户端状态的flags属性不包含REDIS_MULTI标识、或者包含REDIS_DIRTY_CAS或者REDIS_DIRTY_EXEC标识,那么将直接取消事务的执行;
(2)服务器遍历客户端的事务队列,然后执行事务队列中的所有命令,最后将返回结果给客户端;
注意事项:
(1)redis不支持事务回滚机制,但是它会检查每一个事务中的命令是否存在错误;
(2)redis事务不支持检查那些程序员自己犯的错误;
1.25、WATCH & MULTI & EXEC & DISCARD & UNWATCH
1.25.1、WATCH概述
WATCH指令是一个乐观锁,可以为redis事务提供check-and-set(CAS)行为。可以监控一个或者多个键,一旦其中一个键被修改或者删除,之后的事务都将不会执行,监控一直持续到EXEC命令。
1.25.2、MULTI概述
MULTI指令用于开启一个事务,它总是返回OK。MULTI指令执行之后,客户端可以继续向服务器发送任意多条命令,这些命令不会立即执行,而是被放到一个队列中,当EXEC指令被调用时,队列中的所有命令才会被立即执行;
1.25.3、EXEC概述
EXEC指令用于执行队列中的所有指令,返回队列中所有命令的返回值,按照命令执行的先后顺序依次执行,当操作被打断时,返回空值nil;
1.25.4、DISCARD概述
DISCARD指令用于清空事务队列中已经入队的指令,并放弃事务的执行,执行此命令后客户端还会从事务状态中退出;
1.25.5、UNWATCH概述
UNWATCH指令用于取消watch对所有key的监控;
1.26、生产上你们的redis内存设置多少
一般推荐Redis设置内存为最大物理内存的四分之三,例如你的物理机的内存为32G,则设置的Redis的物理内存为24G。
1.27、如何配置 & 修改redis的内存大小
1.27.1、查看redis的最大占用内存
配置文件查看:
redis的最大占用内存是在redis.conf中配置的,默认的配置信息如下:
通过查看默认配置发现,maxmemory被注释掉了,说明其存在默认内存大小,那么默认的规则又是什么呢?规则如下:如果不设置最大内存或者设置的最大内存大小为0,那么在64位操作下不限制内存大小,在32位操作系统下最多使用3G内存。
命令查看:

1.27.2、修改redis的内存大小
配置文件中修改:
修改maxmemory的值即可。注意事项:maxmemory的单位为字节,设置时注意单位的转换。
命令修改(单位:字节):

1.28、如果内存满了你怎么办
redis的内存如果满了,这时如果你还想往里边设值,将会报OOM异常:(error)OOM command not allowed when used memory > 'maxmemory'。解决方法是:调整redis的最大内存大小,避免出现OOM。
1.29、redis的缓存淘汰策略你了解吗
1.29.1、概述
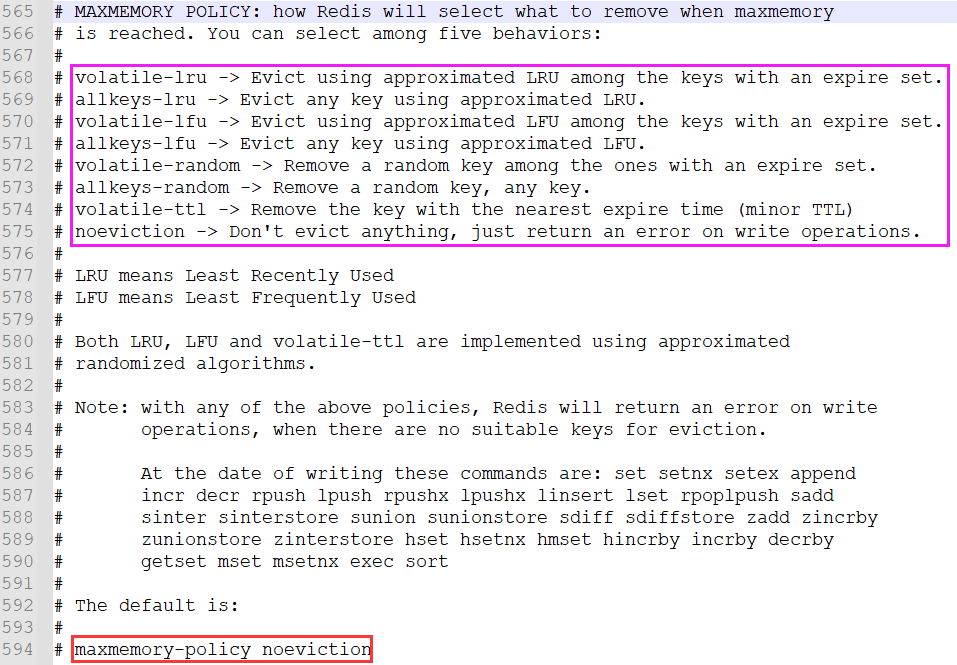
我们知道redis是基于内存的数据库,当内存达到设定的maxmemory时,将会触发redis的主动清理策略。主动清理策略在redis4.0之前一共实现了6种,在4.0之后又增加了2种,共计分为3类8种,redis.conf中的详细配置如下:
中文解释:
第一类:针对设置了过期时间key的处理
(1)volatile-ttl:在筛选时,会针对设置了过期时间的key,根据过期时间的先后顺序进行删除,越早过期的key越先被删除;
(2)volatile-random:就像它的名字一样,在设置了过期时间的key,随机删除;
(3)volatile-lru:使用LRU算法筛选设置了过期时间的key;
(4)volatile-lfu:使用LFU算法筛选设置了过期时间的key;
第二类:针对所有key的处理
(1)allkeys-random(禁止使用):对所有key随机删除;
(2)allkeys-lru(生产上建议使用):对所有key使用LRU算法进行删除;
(3)allkeys-lfu:对所有key使用LFU算法进行删除;
第三类:不处理(默认)
noeviction(默认,生产环境不建议用):不会踢出任何数据,拒绝所有写入操作并返回客户端信息(OOM),此时redis只响应读操作;
小总结:
3个维度:过期键中筛选、所有键中筛选、不处理
4个方面:LRU、LFU、random、ttl
8种选择:
1.29.2、redis过期键的删除策略
思考:如果一个键过期了,那么到了过期时间它会立即从内存中被删除吗?
答:不会立即删除。
1.29.3、3种不同的删除策略(思想)
定时删除:
Redis不可能时刻遍历所有被设置了生存时间的key,来检测数据是否已经到达过期时间,然后对它进行删除。立即删除的确能保证内存中数据的最大新鲜度,因为它保证过期键会在过期后马山删除,其所占用的内存也会随之释放。但是立即删除对cpu是最不友好的。因为删除操作会占用cpu的时间,如果刚好碰上了cpu很忙的时候,比如正在做交集或者排序等计算的时候,就会给cpu造成额外的压力,让cpu很累,时时需要删除,忙死!并且还会产生大量的性能消耗,同时也会影响数据的读取操作。
惰性删除:
数据到达过期时间,不做处理,等下次访问该数据时,判断该数据是否过期,如果没有过期则返回,如果过期了再删除,返回不存在。很明显惰性删除策略对内存是最不友好的!如果一个键已经过期,而这个键又仍然存在redis数据库中,那么只要这个过期的键没有被访问到,其所占用的内存就不会被释放,在使用过期策略时,如果数据库中有非常多的过期键,而这些键又恰巧没有被访问到的话,那么它们永远也不会被删除了(PS:除非用户手动执行了flushdb指令),我们甚至可以将这种情况看做是一种内存泄露(大量无用的垃圾占用了大量的内存,而服务器却不会自己去释放它们),这对于运行状态非常依赖于内存的redis服务器来说,肯定不是一个好消息。
定期删除策略:
上边分析了定时删除和惰性删除存在的问题,不管是定时删除还是惰性删除走的都是极端,显然是不利于服务器发挥出最大性能。那么定期删除策略应运而生,所谓定期策略可以看做是定时策略和惰性策略两者的折中。定期删除策略每隔一段时间执行一次删除过期键的操作,并通过限制删除操作执行的时长和频率来减少删除操作对CPU时间的影响。
周期性轮询redis数据库中的时效性数据,采用随机抽取的策略,利用过期数据占比的方式控制删除频率。
特点1:cpu性能占用设置有峰值,检测频率可以自定义设置;
特点2:内存压力不是很大,长期占用内存的冷数据会被持续清理;
总结:周期性检查存储空间(随机抽查,重点抽查)
举例:redis默认每100ms检查一次是否存在过期的key,有过期key则删除。注意:redis不是每隔100ms就将所有的key检查一次,而是随机抽取进行检查(如果redis中的缓存数据异常的庞大,想要100ms就将所有的key检查一遍判断是否过期,那cpu得直接干冒烟),因此,如果只是采用定期删除策略,将会出现很多过期的key没有及时被删除的情况。
定期删除策略的难点再于如何确定删除操作的执行时长和频率:如果删除操作执行的太频繁或者执行的时间太长,就会退化为定时删除策略,以至于将cpu的时间过多的浪费在查找过期键&删除过期键上。而如果删除操作执行的频繁太少或者执行的时间太短,则又会退化为惰性删除策略。因此,如果采用定期删除策略的话,服务器必须根据实际情况,合理地设置删除操作的执行时长和执行频率。
1.29.4、如何设置redis的过期删除策略
方式一:修改redis.conf的配置文件,例如:
方式二:命令修改

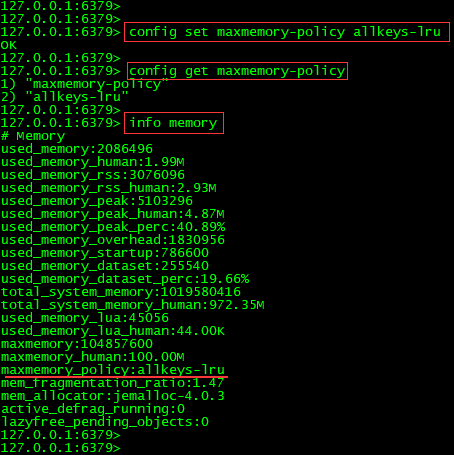
1.30、Redis的LRU算法了解吗?可否手写一个LRU算法?
1.30.1、概述
LRU是Least Recently Used的单词缩写,中文意思为最近最少使用,是一种常用的页面置换算法,根据此算法可以选择最近最久未使用的数据予以淘汰。
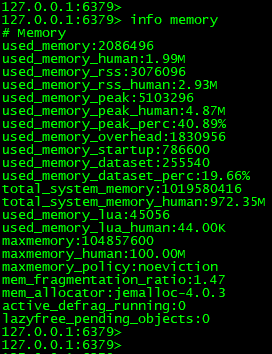
1.31、如何查看当前redis的内存使用情况
info memory