01
引言
通义千问-72B(Qwen-72B)是阿里云研发的通义千问大模型系列的720亿参数规模模型。Qwen-72B的预训练数据类型多样、覆盖广泛,包括大量网络文本、专业书籍、代码等。Qwen-72B-Chat是在Qwen-72B的基础上,使用对齐机制打造的基于大语言模型的AI助手。
阿里云人工智能平台PAI是面向开发者和企业的机器学习/深度学习平台,提供包含数据标注、模型构建、模型训练、模型部署、推理优化在内的AI开发全链路服务。
本文将以Qwen-72B-Chat为例,介绍如何在PAI平台的交互式建模工具PAI-DSW中微调千问大模型。
02
运行环境要求
GPU推荐使用A800(80GB)
ps:推理需要2卡及以上资源,LoRA微调需要4卡及以上资源
Region:乌兰察布
环境:灵骏集群
镜像:pai-image-manage-registry.cn-wulanchabu.cr.aliyuncs.com/pai/llm-inference:vllm-0.2.1-v6
技术交流
建了技术交流群!想要进交流群、获取如下原版资料的同学,可以直接加微信号:dkl88194。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、添加微信号:dkl88194,备注:来自CSDN + 技术交流
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
资料1

资料2

03
准备工作
下载Qwen-72B-Chat
首先,下载模型文件。您可以选择直接执行下面脚本下载,也可以选择从ModelScope下载模型。运行如下代码下载模型。
def aria2(url, filename, d):!aria2c --console-log-level=error -c -x 16 -s 16 {url} -o {filename} -d {d}qwen72b_url = f"http://pai-vision-data-inner-wulanchabu.oss-cn-wulanchabu-internal.aliyuncs.com/qwen72b/Qwen-72B-Chat-sharded.tar"
aria2(qwen72b_url, qwen72b_url.split("/")[-1], "/root/")
! cd /root && tar -xvf Qwen-72B-Chat-sharded.tar
04
LoRA微调
下载示例数据集
! wget -c http://pai-vision-data-inner-wulanchabu.oss-cn-wulanchabu.aliyuncs.com/qwen72b/sharegpt_zh_1K.json -P /workspace/Qwen
为了快速跑通流程将num_train_epochs设为1,nproc_per_node根据当前示例gpu数量调整
! cd /workspace/Qwen && CUDA_DEVICE_MAX_CONNECTIONS=1 torchrun --nproc_per_node 8 \
--nnodes 1 \
--node_rank 0 \
--master_addr localhost \
--master_port 6001 \
finetune.py \
--model_name_or_path /root/Qwen-72B-Chat-sharded \
--data_path sharegpt_zh_1K.json \
--bf16 True \
--output_dir /root/output_qwen \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 8 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 1000 \
--save_total_limit 1 \
--learning_rate 3e-4 \
--weight_decay 0.1 \
--adam_beta2 0.95 \
--warmup_ratio 0.01 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--report_to "none" \
--model_max_length 2048 \
--lazy_preprocess True \
--use_lora \
--gradient_checkpointing \
--deepspeed finetune/ds_config_zero3.json
合并Lora权重,如果执行完后,存在GPU显存没有释放问题,可以关闭Kernel,再执行后续代码
from peft import AutoPeftModelForCausalLMmodel = AutoPeftModelForCausalLM.from_pretrained('/root/output_qwen', # path to the output directorydevice_map="auto",trust_remote_code=True
).eval()merged_model = model.merge_and_unload()
# max_shard_size and safe serialization are not necessary.
# They respectively work for sharding checkpoint and save the model to safetensors
merged_model.save_pretrained('/root/qwen72b_sft', max_shard_size="2048MB", safe_serialization=True)
! cp /root/Qwen-72B-Chat-sharded/qwen.tiktoken /root/qwen72b_sft/
! cp /root/Qwen-72B-Chat-sharded/tokenization_qwen.py /root/qwen72b_sft/
! cp /root/Qwen-72B-Chat-sharded/tokenizer_config.json /root/qwen72b_sft/
05
离线推理
tensor_parallel_size参数可以根据dsw示例配置中的GPU数量进行调整
from vllm import LLM
from vllm.sampling_params import SamplingParams
qwen72b = LLM("/root/qwen72b_sft/", tensor_parallel_size=2, trust_remote_code=True, gpu_memory_utilization=0.99)
samplingparams = SamplingParams(temperature=0.0, max_tokens=512, stop=['<|im_end|>'])
prompt = """<|im_start|>system
<|im_end|>
<|im_start|>user
<|im_end|>
Hello! What is your name?<|im_end|>
<|im_start|>assistant
"""
output = qwen72b.generate(prompt, samplingparams)
print(output)
# 通过如下命令释放加载模型del qwen72b
06
试玩模型
WebUI启动方式
我们可以通过如下方式在dsw中启动webui示例:
- 打开terminal1运行如下命令
python -m fastchat.serve.controller
- 打开terminal2运行如下命令
python -m fastchat.serve.vllm_worker --model-path /root/qwen72b_sft --tensor-parallel-size 2 --trust-remote-code --gpu-memory-utilization 0.98
- 在notebook运行如下命令拉起webui,点击生成的local URL跳转到webui界面进行试玩
! python -m fastchat.serve.gradio_web_server_pai --model-list-mode reload
# 通过如下命令杀死所有启动的fastchat服务! kill -s 9 `ps -aux | grep fastchat | awk '{print $2}'`
API启动方式
我们可以通过如下方式在dsw中启动API示例:
- 打开terminal1运行如下命令
python -m fastchat.serve.controller
- 打开terminal2运行如下命令
python -m fastchat.serve.vllm_worker --model-path /root/qwen72b_sft --tensor-parallel-size 2 --trust-remote-code --gpu-memory-utilization 0.98
- 打开terminal3运行如下命令
python -m fastchat.serve.openai_api_server --host localhost --port 8000
- 通过如下方式调用API
import openai
# to get proper authentication, make sure to use a valid key that's listed in
# the --api-keys flag. if no flag value is provided, the `api_key` will be ignored.
openai.api_key = "EMPTY"
openai.api_base = "http://0.0.0.0:8000/v1"
model = "qwen72b_sft"
# create a chat completion
completion = openai.ChatCompletion.create(model=model,temperature=0.0,top_p=0.8,# presence_penalty=2.0,frequency_penalty=0.0,messages=[{"role": "user", "content": "你好"}]
)
# print the completion
print(completion.choices[0].message.content)
# 通过如下命令杀死所有启动的fastchat服务! kill -s 9 `ps -aux | grep fastchat | awk '{print $2}'`
07
PAI SDK 部署eas服务
用户可以通过PAI SDK的方式将模型部署到PAI EAS
安装PAI SDK
! python -m pip install alipai==0.4.4.post0 -i https://pypi.org/simple
初始化配置
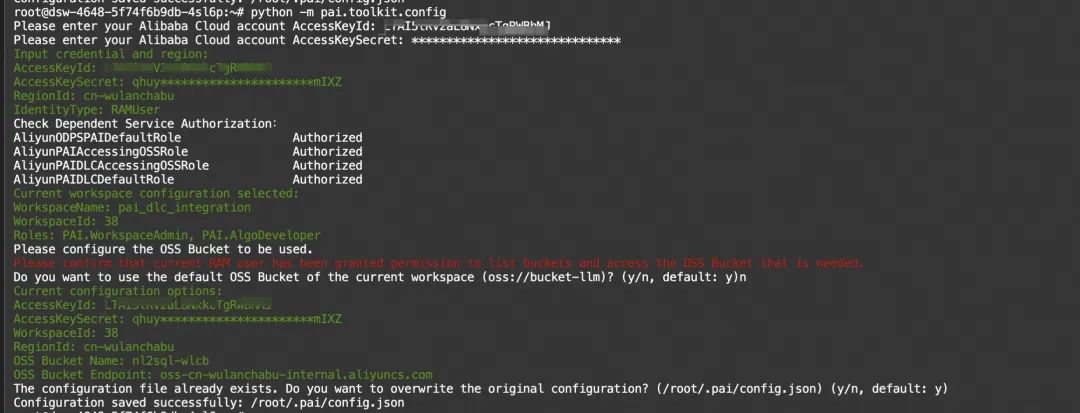
用户首次使用之前需要配置 访问密钥AccessKey (如何创建和获取AccessKey请见文档:创建AccessKey ),使用的 PAI工作空间 ,以及 OSS Bucket 。请在终端上通过以下命令,按照引导逐步完成配置。
请在安装完成后,在命令行终端上执行以下命令,按照引导完成配置
python -m pai.toolkit.config
上传模型至oss
import pai
from pai.session import get_default_sessionprint(pai.__version__)
sess = get_default_session()
from pai.common.oss_utils import upload
# 上传模型
model_uri = upload(source_path='/root/qwen72b_sft', oss_path="qwen72b_sft", bucket=sess.oss_bucket
)
print(model_uri)
使用PAI-BladeLLM部署API服务
配置eas服务config,基于如下的模版进行自定义修改
-
oss.path配置为qwen72b在OSS上的上级目录,如改示例会把oss://example-bucket/挂载至/model
-
metadata.quota_id、metadata.workspace_id根据当前用户的实际情况进行调整,注意确保配置的AK所属用户具备当前工作空间权限
-
blade需要事先对模型进行切分从而节省模型导入时间,若第一次部署服务,切分模型步骤的耗时会较长
config = {"containers": [{"image": "pai-blade-registry.cn-wulanchabu.cr.aliyuncs.com/pai-blade/blade-llm:0.4.0","port": 8081,"script": "[ ! -d \"/model/qwen72b_sft_blade_split_4\" ] && blade_llm_split --world_size 4 --model /model/qwen72b_sft --output_dir /model/qwen72b_sft_blade_split_4;blade_llm_server --model /model/qwen72b_sft_blade_split_4 --attn_cls paged --world_size 4 "}],"metadata": {"cpu": 60,"gpu": 4,"instance": 1,"memory": 256000,"quota_id": "quotaydok5h3tt77","quota_type": "Lingjun","resource_burstable": False,"workspace_id": "38"},"storage": [{"empty_dir": {"medium": "memory","size_limit": 24},"mount_path": "/dev/shm"},{"mount_path": "/model","oss": {"path": "oss://example-bucket/","readOnly": False},"properties": {"resource_type": "model"}}]
}
# service_name可以按需进行修改,同一个region只能存在一个同名服务
from pai.model import Model
m = Model().deploy(service_name = 'qwen72b_sdk_blade_example',options=config)
调用api服务,将Authorization配置为服务token,url填写模型服务路径
import json
import timefrom websockets.sync.client import connectheaders = {"Authorization": "*******"
}
url = 'ws://1612285282502324.cn-wulanchabu.pai-eas.aliyuncs.com/api/predict/qwen72b_sdk_blade_example/generate_stream'prompt = """<|im_start|>system
<|im_end|>
<|im_start|>user
<|im_end|>
Hello! What is your name?<|im_end|>
<|im_start|>assistant
"""
with connect(url, additional_headers=headers) as websocket:websocket.send(json.dumps({"prompt": prompt,"sampling_params": {"temperature": 0.0,"top_p": 0.9,"top_k": 50},"stopping_criterial":{"max_new_tokens": 512,"stop_tokens": [151645, 151644, 151643]}}))tic = time.time()while True:msg = websocket.recv()msg = json.loads(msg)if msg['is_ok']:print(msg['tokens'][0]["text"], end="", flush=True)if msg['is_finished']:breakprint(time.time()-tic)print()print("-" * 40)
在测试完成之后,用户可以在控制台删除服务,也可以通过调用以下命令删除服务.
m.delete_service()
使用fastchat部署webui服务
配置eas服务config,基于如下的模版进行自定义修改
-
oss.path配置为qwen72b在OSS上的目录,如改示例会把oss://example-bucket/qwen72b_sft挂载至/qwen72b
-
metadata.quota_id、metadata.workspace_id根据当前用户的实际情况进行调整,注意确保配置的AK所属用户具备当前工作空间权限
config = {"containers": [{"image": "pai-image-manage-registry.cn-wulanchabu.cr.aliyuncs.com/pai/llm-inference:vllm-0.2.1-v6","port": 7860,"script": "nohup python -m fastchat.serve.controller > tmp1.log 2>&1 & python -m fastchat.serve.gradio_web_server_pai --model-list-mode reload > tmp2.log 2>&1 & python -m fastchat.serve.vllm_worker --model-path /qwen72b --tensor-parallel-size 4 --gpu-memory-utilization 0.98 --trust-remote-code"}],"metadata": {"cpu": 60,"enable_webservice": True,"gpu": 4,"instance": 1,"memory": 256000,"quota_id": "quotaydok5h3tt77","quota_type": "Lingjun","resource_burstable": True,"workspace_id": "38"},"storage": [{"empty_dir": {"medium": "memory","size_limit": 24},"mount_path": "/dev/shm"},{"mount_path": "/qwen72b","oss": {"path": "oss://example-bucket/qwen72b_sft/","readOnly": False},"properties": {"resource_type": "model"}}]
}
# service_name可以按需进行修改,同一个region只能存在一个同名服务
from pai.model import Model
m = Model().deploy(service_name = 'qwen72b_sdk_example',options=config)
在测试完成之后,用户可以在控制台删除服务,也可以通过调用以下命令删除服务.
m.delete_service()