一、创建 CephFS 文件系统 MDS 接口
1、服务端操作
1)在管理节点创建 mds 服务
[root@admin ceph]# cd /etc/ceph
[root@admin ceph]# ceph-deploy mds create node01 node02 node03
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (2.0.1): /usr/bin/ceph-deploy mds create node01 node02 node03
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] subcommand : create
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x7f6ea6d703f8>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] func : <function mds at 0x7f6ea71cd488>
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] mds : [('node01', 'node01'), ('node02', 'node02'), ('node03', 'node03')]
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.mds][DEBUG ] Deploying mds, cluster ceph hosts node01:node01 node02:node02 node03:node03
[node01][DEBUG ] connected to host: node01
[node01][DEBUG ] detect platform information from remote host
[node01][DEBUG ] detect machine type
[ceph_deploy.mds][INFO ] Distro info: CentOS Linux 7.6.1810 Core
[ceph_deploy.mds][DEBUG ] remote host will use systemd
[ceph_deploy.mds][DEBUG ] deploying mds bootstrap to node01
[node01][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.conf
[node01][WARNIN] mds keyring does not exist yet, creating one
[node01][DEBUG ] create a keyring file
[node01][DEBUG ] create path if it doesn't exist
[node01][INFO ] Running command: ceph --cluster ceph --name client.bootstrap-mds --keyring /var/lib/ceph/bootstrap-mds/ceph.keyring auth get-or-create mds.node01 osd allow rwx mds allow mon allow profile mds -o /var/lib/ceph/mds/ceph-node01/keyring
[node01][INFO ] Running command: systemctl enable ceph-mds@node01
[node01][WARNIN] Created symlink from /etc/systemd/system/ceph-mds.target.wants/ceph-mds@node01.service to /usr/lib/systemd/system/ceph-mds@.service.
[node01][INFO ] Running command: systemctl start ceph-mds@node01
......
2)查看各个节点的 mds 服务
[root@admin ceph]# ssh root@node01 systemctl status ceph-mds@node01
● ceph-mds@node01.service - Ceph metadata server daemonLoaded: loaded (/usr/lib/systemd/system/ceph-mds@.service; enabled; vendor preset: disabled)Active: active (running) since 一 2023-07-17 14:44:28 CST; 2min 50s agoMain PID: 12690 (ceph-mds)CGroup: /system.slice/system-ceph\x2dmds.slice/ceph-mds@node01.service└─12690 /usr/bin/ceph-mds -f --cluster ceph --id node01 --setuser ceph --setgroup ceph7月 17 14:44:28 node01 systemd[1]: Started Ceph metadata server daemon.
7月 17 14:44:28 node01 ceph-mds[12690]: starting mds.node01 at
7月 17 14:44:28 node01 systemd[1]: [/usr/lib/systemd/system/ceph-mds@.service:15] Unknown lvalue 'LockPersonality' in section 'Service'
7月 17 14:44:28 node01 systemd[1]: [/usr/lib/systemd/system/ceph-mds@.service:16] Unknown lvalue 'MemoryDenyWriteExecute' in section 'Service'
7月 17 14:44:28 node01 systemd[1]: [/usr/lib/systemd/system/ceph-mds@.service:19] Unknown lvalue 'ProtectControlGroups' in section 'Service'
7月 17 14:44:28 node01 systemd[1]: [/usr/lib/systemd/system/ceph-mds@.service:21] Unknown lvalue 'ProtectKernelModules' in section 'Service'
7月 17 14:44:28 node01 systemd[1]: [/usr/lib/systemd/system/ceph-mds@.service:22] Unknown lvalue 'ProtectKernelTunables' in section 'Service'
[root@admin ceph]# ssh root@node02 systemctl status ceph-mds@node02
● ceph-mds@node02.service - Ceph metadata server daemonLoaded: loaded (/usr/lib/systemd/system/ceph-mds@.service; enabled; vendor preset: disabled)Active: active (running) since 一 2023-07-17 14:44:29 CST; 2min 57s agoMain PID: 3892 (ceph-mds)CGroup: /system.slice/system-ceph\x2dmds.slice/ceph-mds@node02.service└─3892 /usr/bin/ceph-mds -f --cluster ceph --id node02 --setuser ceph --setgroup ceph7月 17 14:44:29 node02 systemd[1]: Started Ceph metadata server daemon.
7月 17 14:44:29 node02 systemd[1]: Starting Ceph metadata server daemon...
7月 17 14:44:29 node02 systemd[1]: [/usr/lib/systemd/system/ceph-mds@.service:15] Unknown lvalue 'LockPersonality' in section 'Service'
7月 17 14:44:29 node02 systemd[1]: [/usr/lib/systemd/system/ceph-mds@.service:16] Unknown lvalue 'MemoryDenyWriteExecute' in section 'Service'
7月 17 14:44:29 node02 systemd[1]: [/usr/lib/systemd/system/ceph-mds@.service:19] Unknown lvalue 'ProtectControlGroups' in section 'Service'
7月 17 14:44:29 node02 systemd[1]: [/usr/lib/systemd/system/ceph-mds@.service:21] Unknown lvalue 'ProtectKernelModules' in section 'Service'
7月 17 14:44:29 node02 systemd[1]: [/usr/lib/systemd/system/ceph-mds@.service:22] Unknown lvalue 'ProtectKernelTunables' in section 'Service'
7月 17 14:44:29 node02 ceph-mds[3892]: starting mds.node02 at
[root@admin ceph]# ssh root@node03 systemctl status ceph-mds@node03
● ceph-mds@node03.service - Ceph metadata server daemonLoaded: loaded (/usr/lib/systemd/system/ceph-mds@.service; enabled; vendor preset: disabled)Active: active (running) since 一 2023-07-17 14:44:30 CST; 3min 6s agoMain PID: 3488 (ceph-mds)CGroup: /system.slice/system-ceph\x2dmds.slice/ceph-mds@node03.service└─3488 /usr/bin/ceph-mds -f --cluster ceph --id node03 --setuser ceph --setgroup ceph7月 17 14:44:30 node03 systemd[1]: Started Ceph metadata server daemon.
7月 17 14:44:30 node03 systemd[1]: Starting Ceph metadata server daemon...
7月 17 14:44:30 node03 systemd[1]: [/usr/lib/systemd/system/ceph-mds@.service:15] Unknown lvalue 'LockPersonality' in section 'Service'
7月 17 14:44:30 node03 systemd[1]: [/usr/lib/systemd/system/ceph-mds@.service:16] Unknown lvalue 'MemoryDenyWriteExecute' in section 'Service'
7月 17 14:44:30 node03 systemd[1]: [/usr/lib/systemd/system/ceph-mds@.service:19] Unknown lvalue 'ProtectControlGroups' in section 'Service'
7月 17 14:44:30 node03 systemd[1]: [/usr/lib/systemd/system/ceph-mds@.service:21] Unknown lvalue 'ProtectKernelModules' in section 'Service'
7月 17 14:44:30 node03 systemd[1]: [/usr/lib/systemd/system/ceph-mds@.service:22] Unknown lvalue 'ProtectKernelTunables' in section 'Service'
7月 17 14:44:30 node03 ceph-mds[3488]: starting mds.node03 at
3)创建存储池,启用 ceph 文件系统
ceph 文件系统至少需要两个 rados 池,一个用于存储数据,一个用于存储元数据。此时数据池就类似于文件系统的共享目录。
[root@admin ceph]# ceph osd pool create cephfs_data 128 #创建数据Pool
pool 'cephfs_data' created
[root@admin ceph]# ceph osd pool create cephfs_metadata 128 #创建元数据Pool
pool 'cephfs_metadata' created- 创建 cephfs
命令格式:
ceph fs new <FS_NAME> <CEPHFS_METADATA_NAME> <CEPHFS_DATA_NAME>
[root@admin ceph]# ceph fs new mycephfs cephfs_metadata cephfs_data #启用ceph,元数据Pool在前,数据Pool在后
new fs with metadata pool 3 and data pool 2
[root@admin ceph]# ceph fs ls #查看cephfs
name: mycephfs, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
4)查看mds状态
[root@admin ceph]# ceph -s | grep mds #一个up,其余两个待命,目前的工作的是node01上的mds服务 mds: mycephfs:1 {0=node03=up:active} 2 up:standby
[root@admin ceph]# ceph mds stat
mycephfs:1 {0=node03=up:active} 2 up:standby5)创建用户
语法格式:ceph fs authorize <fs_name> client.<client_id> <path-in-cephfs> rw
- 账户为 client.lion,用户 name 为 lion,lion 对ceph文件系统的 / 根目录(注意不是操作系统的根目录)有读写权限
[root@admin ceph]# ceph fs authorize mycephfs client.lion / rw | tee /etc/ceph/lion.keyring
[client.lion]key = AQCa6LRkciHuEhAA36idbEDlatpT/cmmze/H4g==
- 账户为 client.tiger,用户 name 为 tiger,tiger 对文件系统的 / 根目录只有读权限,对文件系统的根目录的子目录 /test 有读写权限
[root@admin ceph]# ceph fs authorize mycephfs client.tiger / r /test rw | tee /etc/ceph/tiger.keyring
[client.tiger]key = AQDO6LRkAKUvCBAAwzG69McMflTW0OoxuYVy+w==
2、客户端操作(client)
1)客户端要在 public 网络内(client)
2)在客户端创建工作目录(client)
[root@client ceph]# mkdir /etc/ceph
3)在 ceph 的管理节点给客户端拷贝 ceph 的配置文件 ceph.conf 和账号的秘钥环文件(admin)
[root@admin ceph]# scp ceph.conf lion.keyring tiger.keyring root@client:/etc/ceph
The authenticity of host 'client (192.168.247.135)' can't be established.
ECDSA key fingerprint is SHA256:5eE5CvbymAz2TScU95abW/iB6vJ8pxtmWD2u6i6RVKc.
ECDSA key fingerprint is MD5:b8:ea:fc:67:52:8e:1f:ff:f2:ff:0a:ff:ae:df:44:ad.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'client,192.168.247.135' (ECDSA) to the list of known hosts.
root@client's password:
ceph.conf 100% 379 406.3KB/s 00:00
lion.keyring 100% 62 103.8KB/s 00:00
tiger.keyring
4)在客户端安装 ceph 软件包(client)
[root@client ceph]# cd /opt
[root@client opt]# wget https://download.ceph.com/rpm-nautilus/el7/noarch/ceph-release-1-1.el7.noarch.rpm --no-check-certificate
--2023-07-17 15:24:20-- https://download.ceph.com/rpm-nautilus/el7/noarch/ceph-release-1-1.el7.noarch.rpm
正在解析主机 download.ceph.com (download.ceph.com)... 158.69.68.124, 2607:5300:201:2000::3:58a1
正在连接 download.ceph.com (download.ceph.com)|158.69.68.124|:443... 已连接。
警告: 无法验证 download.ceph.com 的由 “/C=US/O=Let's Encrypt/CN=R3” 颁发的证书:颁发的证书已经过期。
已发出 HTTP 请求,正在等待回应... 200 OK
长度:4004 (3.9K) [application/x-redhat-package-manager]
正在保存至: “ceph-release-1-1.el7.noarch.rpm”100%[===============================================================================================================>] 4,004 --.-K/s 用时 0s2023-07-17 15:24:24 (795 MB/s) - 已保存 “ceph-release-1-1.el7.noarch.rpm” [4004/4004])[root@client opt]# rpm -ivh ceph-release-1-1.el7.noarch.rpm
准备中... ################################# [100%]软件包 ceph-release-1-1.el7.noarch 已经安装
[root@client opt]# yum install -y ceph
已加载插件:fastestmirror, langpacks, priorities
Loading mirror speeds from cached hostfile
epel/x86_64/metalink | 5.2 kB 00:00:00* base: mirrors.ustc.edu.cn* epel: ftp.iij.ad.jp* extras: mirrors.ustc.edu.cn* updates: mirrors.ustc.edu.cn
......
5)在客户端制作秘钥文件(client)
[root@client opt]# cd /etc/ceph
[root@client ceph]# ceph-authtool -n client.lion -p lion.keyring > lion.key
[root@client ceph]# ceph-authtool -n client.tiger -p tiger.keyring > tiger.key
6)客户端挂载(client)
- 方式一:基于内核
语法格式:
mount -t ceph node01:6789,node02:6789,node03:6789:/ <本地挂载点目录> -o name=<用户名>,secret=<秘钥>
mount -t ceph node01:6789,node02:6789,node03:6789:/ <本地挂载点目录> -o name=<用户名>,secretfile=<秘钥文件>
[root@client ceph]# mkdir -p /data/lion
[root@client ceph]# mount -t ceph node01:6789,node02:6789,node03:6789:/ /data/lion -o name=lion,secretfile=/etc/ceph/lion.key
[root@client ceph]# df -hT
文件系统 类型 容量 已用 可用 已用% 挂载点
devtmpfs devtmpfs 894M 0 894M 0% /dev
tmpfs tmpfs 910M 0 910M 0% /dev/shm
tmpfs tmpfs 910M 11M 900M 2% /run
tmpfs tmpfs 910M 0 910M 0% /sys/fs/cgroup
/dev/mapper/centos-root xfs 37G 5.8G 32G 16% /
/dev/sda1 xfs 1014M 185M 830M 19% /boot
tmpfs tmpfs 182M 12K 182M 1% /run/user/42
tmpfs tmpfs 182M 0 182M 0% /run/user/0
192.168.247.131:6789,192.168.247.132:6789,192.168.247.133:6789:/ ceph 72G 0 72G 0% /data/lion7)验证用户权限(client)
[root@client ceph]# cd /data/tiger
[root@client tiger]# echo 123 > 2.txt
-bash: 2.txt: 权限不够
[root@client ~]# cd /data/lion #需要在有权限的用户创建test目录
[root@client lion]# mkdir test
[root@client lion]# cd /data/tiger
[root@client tiger]# echo 123 > test/2.txt- 停掉 node02 上的 mds 服务(admin)
[root@admin ceph]# ssh root@node02 "systemctl stop ceph-mds@node02"
[root@admin ceph]# ceph -scluster:id: 40a2227f-ea49-425e-bded-55832d1f5b77health: HEALTH_OKservices:mon: 3 daemons, quorum node01,node02,node03 (age 3h)mgr: node01(active, since 3h), standbys: node02mds: mycephfs:1 {0=node03=up:active} 1 up:standbyosd: 8 osds: 8 up (since 3h), 8 in (since 24h)data:pools: 3 pools, 384 pgsobjects: 23 objects, 9.5 KiBusage: 8.1 GiB used, 152 GiB / 160 GiB availpgs: 384 active+clean
- 测试客户端的挂载点仍然是可以用的,如果停掉所有的 mds,客户端就不能用了
●方式二:基于 fuse 工具
1)在 ceph 的管理节点给客户端拷贝 ceph 的配置文件 ceph.conf 和账号的秘钥环文件 zhangsan.keyring、lisi.keyring(admin)
[root@admin ceph]# scp ceph.client.admin.keyring root@client:/etc/ceph
root@client's password:
ceph.client.admin.keyring
2)在客户端安装 ceph-fuse(client)
yum install -y ceph-fuse
3)客户端挂载(client)
[root@client aa]# ceph-fuse -m node01:6789,node02:6789,node03:6789 /data/aa #挂载时,如果挂载点不为空会挂载失败,指定 -o nonempty 可以忽略
ceph-fuse[29593]: starting ceph client2023-07-17 16:23:38.230 7fa258b38f80 -1 init, newargv = 0x5619fca326d0 newargc=9ceph-fuse[29593]: starting fuse
二、创建 Ceph 块存储系统 RBD 接口
1、创建一个名为 rbd-demo 的专门用于 RBD 的存储池(admin)
[root@admin ceph]# ceph osd pool create rbd-demo 64 64
pool 'rbd-demo' created2、将存储池转换为 RBD 模式(admin)
[root@admin ceph]# ceph osd pool application enable rbd-demo rbd
enabled application 'rbd' on pool 'rbd-demo'3、初始化存储池(admin)
[root@admin ceph]# rbd pool init -p rbd-demo
4、创建镜像(admin)
rbd create -p rbd-demo --image rbd-demo1.img --size 10G
[root@admin ceph]# rbd create -p rbd-demo --image rbd-demo1.img --size 10G
5、镜像管理
① 查看存储池下存在哪些镜像(admin)
[root@admin ceph]# rbd ls -l -p rbd-demo
NAME SIZE PARENT FMT PROT LOCK
rbd-demo1.img 10 GiB 2
② 查看镜像的详细信息(admin)
[root@admin ceph]# rbd info -p rbd-demo --image rbd-demo1.img
rbd image 'rbd-demo1.img':size 10 GiB in 2560 objects #镜像的大小与被分割成的条带数order 22 (4 MiB objects) #条带的编号,有效范围是12到25,对应4K到32M,而22代表2的22次方,这样刚好是4Msnapshot_count: 0id: ad76349f8556 #镜像的ID标识block_name_prefix: rbd_data.ad76349f8556 #名称前缀format: 2 #使用的镜像格式,默认为2features: layering, exclusive-lock, object-map, fast-diff, deep-flatten #当前镜像的功能特性op_features:flags:create_timestamp: Mon Jul 17 16:34:09 2023access_timestamp: Mon Jul 17 16:34:09 2023modify_timestamp: Mon Jul 17 16:34:09 2023
③ 修改镜像大小(admin)
[root@admin ceph]# rbd resize -p rbd-demo --image rbd-demo1.img --size 20G
Resizing image: 100% complete...done.
[root@admin ceph]# rbd info -p rbd-demo --image rbd-demo1.img
rbd image 'rbd-demo1.img':size 20 GiB in 5120 objectsorder 22 (4 MiB objects)snapshot_count: 0id: ad76349f8556block_name_prefix: rbd_data.ad76349f8556format: 2features: layering, exclusive-lock, object-map, fast-diff, deep-flattenop_features:flags:create_timestamp: Mon Jul 17 16:34:09 2023access_timestamp: Mon Jul 17 16:34:09 2023modify_timestamp: Mon Jul 17 16:34:09 2023
④ 使用 resize 调整镜像大小,一般建议只增不减,如果是减少的话需要加选项 --allow-shrink(admin)
[root@admin ceph]# rbd resize -p rbd-demo --image rbd-demo1.img --size 5G --allow-shrink
Resizing image: 100% complete...done.
⑤ 删除镜像
- 直接删除镜像(admin)
[root@admin ceph]# rbd rm -p rbd-demo --image rbd-demo2.img
Removing image: 100% complete...done.
[root@admin ceph]# rbd remove rbd-demo/rbd-demo2.img
Removing image: 100% complete...done.
- 推荐使用 trash 命令,这个命令删除是将镜像移动至回收站,如果想找回还可以恢复(admin)
[root@admin ceph]# rbd trash move rbd-demo/rbd-demo1.img
[root@admin ceph]# rbd ls -l -p rbd-demo
[root@admin ceph]# rbd trash list -p rbd-demo
ad76349f8556 rbd-demo1.img
⑥ 还原镜像(admin)
[root@admin ceph]# rbd trash restore rbd-demo/ad76349f8556
[root@admin ceph]# rbd ls -l -p rbd-demo
NAME SIZE PARENT FMT PROT LOCK
rbd-demo1.img 5 GiB 2
6、Linux客户端使用
1) 客户端使用 RBD 的方式
-
通过内核模块KRBD将镜像映射为系统本地块设备,通常设置文件一般为:/dev/rbd*
-
另一种是通过librbd接口,通常KVM虚拟机使用这种接口。
-
本例主要是使用Linux客户端挂载RBD镜像为本地磁盘使用。开始之前需要在所需要客户端节点上面安装ceph-common软件包,因为客户端需要调用rbd命令将RBD镜像映射到本地当作一块普通硬盘使用。并还需要把ceph.conf配置文件和授权keyring文件复制到对应的节点。
2)在管理节点创建并授权一个用户可访问指定的 RBD 存储池
① 示例,指定用户标识为client.osd-mount,对另对OSD有所有的权限,对Mon有只读的权限(admin)
[root@admin ceph]# ceph auth get-or-create client.osd-mount osd "allow * pool=rbd-demo" mon "allow r" > /etc/ceph/ceph.client.osd-mount.keyring
② 修改RBD镜像特性,CentOS7默认情况下只支持layering和striping特性,需要将其它的特性关闭(admin)
[root@admin ceph]# rbd feature disable rbd-demo/rbd-demo1.img object-map,fast-diff,deep-flatten
③ 将用户的keyring文件和ceph.conf文件发送到客户端的/etc/ceph目录下(admin)
[root@admin ceph]# cd /etc/ceph
[root@admin ceph]# scp ceph.client.osd-mount.keyring ceph.conf root@client:/etc/ceph
root@client's password:
ceph.client.osd-mount.keyring 100% 67 100.4KB/s 00:00
ceph.conf
④ 安装 ceph-common 软件包(client)
yum install -y ceph-common
⑤ 执行客户端映射(client)
[root@client aa]# cd /etc/ceph
[root@client ceph]# rbd map rbd-demo/rbd-demo1.img --keyring /etc/ceph/ceph.client.osd-mount.keyring --user osd-mount
/dev/rbd0
⑥ 查看映射(client)
[root@client ceph]# rbd showmapped
id pool namespace image snap device
0 rbd-demo rbd-demo1.img - /dev/rbd0
[root@client ceph]# rbd device list
id pool namespace image snap device
0 rbd-demo rbd-demo1.img - /dev/rbd0
⑦ 格式化并挂载(client)
[root@client ceph]# mkfs.xfs /dev/rbd0
Discarding blocks...Done.
meta-data=/dev/rbd0 isize=512 agcount=8, agsize=163840 blks= sectsz=512 attr=2, projid32bit=1= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=1310720, imaxpct=25= sunit=1024 swidth=1024 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2= sectsz=512 sunit=8 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@client ceph]# mkdir -p /data/bb
[root@client ceph]# mount /dev/rbd0 /data/bb
⑧ 在线扩容
- 在管理节点调整镜像的大小(admin)
[root@admin ceph]# rbd resize rbd-demo/rbd-demo1.img --size 30G
Resizing image: 100% complete...done.
- 在客户端刷新设备文件(client)
[root@client ceph]# xfs_growfs /dev/rbd0
meta-data=/dev/rbd0 isize=512 agcount=8, agsize=163840 blks= sectsz=512 attr=2, projid32bit=1= crc=1 finobt=0 spinodes=0
data = bsize=4096 blocks=1310720, imaxpct=25= sunit=1024 swidth=1024 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal bsize=4096 blocks=2560, version=2= sectsz=512 sunit=8 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
data blocks changed from 1310720 to 7864320- 刷新ext4类型文件系统容量(xfs类型不可使用)
resize2fs /dev/rbd0
⑨ 断开映射(client)
[root@client ceph]# rbd unmap rbd-demo/rbd-demo1.img
7、快照管理
- 对 rbd 镜像进行快照,可以保留镜像的状态历史,另外还可以利用快照的分层技术,通过将快照克隆为新的镜像使用
① 在客户端写入文件(client)
[root@client ceph]# echo 1111 > /data/bb/11.txt
[root@client ceph]# echo 2222 > /data/bb/22.txt
[root@client ceph]# echo 3333 > /data/bb/33.txt
② 在管理节点对镜像创建快照
[root@admin ceph]# rbd snap create --pool rbd-demo --image rbd-demo1.img --snap demo1_snap1
③ 列出指定镜像所有快照
[root@admin ceph]# rbd snap list rbd-demo/rbd-demo1.img
SNAPID NAME SIZE PROTECTED TIMESTAMP4 demo1_snap1 30 GiB Mon Jul 17 18:38:51 2023
④ 用json格式输出
[root@admin ceph]# rbd snap list rbd-demo/rbd-demo1.img --format json --pretty-format
[{"id": 4,"name": "demo1_snap1","size": 32212254720,"protected": "false","timestamp": "Mon Jul 17 18:38:51 2023"}
]
8、回滚镜像到指定
- 在回滚快照之前,需要将镜像取消镜像的映射,然后再回滚。
① 在客户端操作
[root@client ceph]# rm -rf /data/bb/*
[root@client ceph]# umount /data/bb
[root@client ceph]# rbd unmap rbd-demo/rbd-demo1.img
② 在管理节点操作
[root@admin ceph]# rbd snap rollback rbd-demo/rbd-demo1.img@demo1_snap1
Rolling back to snapshot: 100% complete...done.
③ 在客户端重新映射并挂载
[root@client ceph]# rbd map rbd-demo/rbd-demo1.img --keyring /etc/ceph/ceph.client.osd-mount.keyring --user osd-mount
/dev/rbd0
[root@client ceph]# mount /dev/rbd0 /data/bb
[root@client ceph]# ls /data/bb
11.txt 22.txt 33.txt
④ 限制镜像可创建快照数
rbd snap limit set rbd-demo/rbd-demo1.img --limit 3
⑤ 解除限制
rbd snap limit clear rbd-demo/rbd-demo1.img
⑥ 删除快照
- 删除指定快照
rbd snap rm rbd-demo/rbd-demo1.img@demo1_snap1
- 删除所有快照
rbd snap purge rbd-demo/rbd-demo1.img
⑦ 快照分层
- 快照分层支持用快照的克隆生成新镜像,这种镜像与直接创建的镜像几乎完全一样,支持镜像的所有操作。唯一不同的是克隆镜像引用了一个只读的上游快照,而且此快照必须要设置保护模式
9、快照克隆
1)将上游快照设置为保护模式
[root@client ceph]# rbd snap create rbd-demo/rbd-demo1.img@demo1_snap666
[root@client ceph]# rbd snap protect rbd-demo/rbd-demo1.img@demo1_snap666
2)克隆快照为新的镜像
[root@client ceph]# rbd clone rbd-demo/rbd-demo1.img@demo1_snap666 --dest rbd-demo/rbd-demo666.img
[root@client ceph]# rbd ls -p rbd-demo
rbd-demo1.img
rbd-demo666.img
3)命令查看克隆完成后快照的子镜像
[root@client ceph]# rbd children rbd-demo/rbd-demo1.img@demo1_snap666
rbd-demo/rbd-demo666.img
10、快照展平
-
通常情况下通过快照克隆而得到的镜像会保留对父快照的引用,这时候不可以删除该父快照,否则会有影响。
rbd snap rm rbd-demo/rbd-demo1.img@demo1_snap666
#报错 snapshot ‘demo1_snap666’ is protected from removal. -
如果要删除快照但想保留其子镜像,必须先展平其子镜像,展平的时间取决于镜像的大小
1) 展平子镜像
[root@client ceph]# rbd flatten rbd-demo/rbd-demo666.img
Image flatten: 100% complete...done.
2)取消快照保护
[root@client ceph]# rbd snap unprotect rbd-demo/rbd-demo1.img@demo1_snap666
3)删除快照
[root@client ceph]# rbd snap rm rbd-demo/rbd-demo1.img@demo1_snap666
Removing snap: 100% complete...done.
[root@client ceph]# rbd ls -l -p rbd-demo
NAME SIZE PARENT FMT PROT LOCK
rbd-demo1.img 30 GiB 2
rbd-demo1.img@demo1_snap1 30 GiB 2
rbd-demo666.img 30 GiB 2
11、镜像的导出导入
① 导出镜像
[root@client ceph]# rbd export rbd-demo/rbd-demo1.img /opt/rbd-demo1.img
Exporting image: 100% complete...done.
② 卸载客户端挂载,并取消映射
[root@client ceph]# umount /data/bb
[root@client ceph]# rbd unmap rbd-demo/rbd-demo1.img③ 清除镜像下的所有快照,并删除镜像
[root@client ceph]# rbd snap purge rbd-demo/rbd-demo1.img
Removing all snapshots: 100% complete...done.
[root@client ceph]# rbd rm rbd-demo/rbd-demo1.img
Removing image: 100% complete...done.
[root@client ceph]# rbd ls -l -p rbd-demo
NAME SIZE PARENT FMT PROT LOCK
rbd-demo666.img 30 GiB 2
④ 导入镜像
[root@client ceph]# rbd import /opt/rbd-demo1.img rbd-demo/rbd-demo1.img
Importing image: 100% complete...done.
[root@client ceph]# rbd ls -l -p rbd-demo
NAME SIZE PARENT FMT PROT LOCK
rbd-demo1.img 30 GiB 2
rbd-demo666.img 30 GiB 2
三、创建 Ceph 对象存储系统 RGW 接口
1、对象存储概念
- 对象存储(object storage)是非结构数据的存储方法,对象存储中每一条数据都作为单独的对象存储,拥有唯一的地址来识别数据对象,通常用于云计算环境中。
- 不同于其他数据存储方法,基于对象的存储不使用目录树。
- 虽然在设计与实现上有所区别,但大多数对象存储系统对外呈现的核心资源类型大同小异。从客户端的角度来看,分为以下几个逻辑单位:
① Amazon S3提供了:用户(User)、存储桶(Bucket)、对象(Object)
② 三者的关系是
- User将Object存储到系统上的Bucket
- 存储桶属于某个用户并可以容纳对象,一个存储桶用于存储多个对象
- 同一个用户可以拥有多个存储桶,不同用户允许使用相同名称的Bucket,因此User名称即可做为Bucket的名称空间
③ OpenStack Swift
- 提供了user、container和object分别对应于用户、存储桶和对象,不过它还额外为user提供了父级组件account,用于表示一个项目或用户,因此一个account中可以包含一到多个user,它们可共享使用同一组container,并为container提供名称空间
④ RadosGW
-
提供了user、subuser、bucket和object,其中的user对应于S3的user,而subuser则对应于Swift的user,不过user和subuser都不支持为bucket提供名称空间,因此不同用户的存储桶不允许同名;不过,自jewel版本起,RadosGW引入了tenant(租户)用于为user和bucket提供名称空间,但他是个可选组件
-
从上可以看出大多数对象存储的核心资源类型大同小异,如 Amazon S3、OpenStack Swift 与 RadosGw。其中 S3 与 Swift 互不兼容,RadosGw 为了兼容 S3 与 Swift, Ceph 在 RadosGW 集群的基础上提供了 RGW(RadosGateway)数据抽象层和管理层,它可以原生兼容 S3 和 Swift 的 API。
-
S3和Swift它们可基于http或https完成数据交换,由RadosGW内建的Civetweb提供服务,它还可以支持代理服务器包括nginx、haproxy等以代理的形式接收用户请求,再转发至RadosGW进程。
RGW 的功能依赖于对象网关守护进程实现,负责向客户端提供 REST API 接口。出于冗余负载均衡的需求,一个 Ceph 集群上通常不止一个 RadosGW 守护进程。
2、创建 RGW 接口
- 如果需要使用到类似 S3 或者 Swift 接口时候才需要部署/创建 RadosGW 接口,RadosGW 通常作为对象存储(Object Storage)使用,类于阿里云OSS
① 在管理节点创建一个 RGW 守护进程(生产环境下此进程一般需要高可用,后续介绍)
[root@admin ~]# cd /etc/ceph
[root@admin ceph]# ceph-deploy rgw create node01
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (2.0.1): /usr/bin/ceph-deploy rgw create node01
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] rgw : [('node01', 'rgw.node01')]
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] subcommand : create
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x7f7d6f4c3290>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] func : <function rgw at 0x7f7d6fd80578>
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.rgw][DEBUG ] Deploying rgw, cluster ceph hosts node01:rgw.node01
[node01][DEBUG ] connected to host: node01
[node01][DEBUG ] detect platform information from remote host
[node01][DEBUG ] detect machine type
[ceph_deploy.rgw][INFO ] Distro info: CentOS Linux 7.6.1810 Core
[ceph_deploy.rgw][DEBUG ] remote host will use systemd
[ceph_deploy.rgw][DEBUG ] deploying rgw bootstrap to node01
[node01][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.conf
[node01][WARNIN] rgw keyring does not exist yet, creating one
[node01][DEBUG ] create a keyring file
[node01][DEBUG ] create path recursively if it doesn't exist
[node01][INFO ] Running command: ceph --cluster ceph --name client.bootstrap-rgw --keyring /var/lib/ceph/bootstrap-rgw/ceph.keyring auth get-or-create client.rgw.node01 osd allow rwx mon allow rw -o /var/lib/ceph/radosgw/ceph-rgw.node01/keyring
[node01][INFO ] Running command: systemctl enable ceph-radosgw@rgw.node01
[node01][WARNIN] Created symlink from /etc/systemd/system/ceph-radosgw.target.wants/ceph-radosgw@rgw.node01.service to /usr/lib/systemd/system/ceph-radosgw@.service.
[node01][INFO ] Running command: systemctl start ceph-radosgw@rgw.node01
[node01][INFO ] Running command: systemctl enable ceph.target
[ceph_deploy.rgw][INFO ] The Ceph Object Gateway (RGW) is now running on host node01 and default port 7480
[root@admin ceph]# ceph -scluster:id: 40a2227f-ea49-425e-bded-55832d1f5b77health: HEALTH_OKservices:mon: 3 daemons, quorum node01,node02,node03 (age 12m)mgr: node01(active, since 12m), standbys: node02mds: mycephfs:1 {0=node03=up:active} 2 up:standbyosd: 8 osds: 8 up (since 12m), 8 in (since 46h)rgw: 1 daemon active (node01)task status:data:pools: 8 pools, 576 pgsobjects: 317 objects, 199 MiBusage: 8.5 GiB used, 151 GiB / 160 GiB availpgs: 576 active+clean
② 创建成功后默认情况下会自动创建一系列用于 RGW 的存储池
[root@admin ceph]# ceph osd pool ls
mypool
cephfs_data
cephfs_metadata
rbd-demo
.rgw.root
default.rgw.control #控制器信息
default.rgw.meta #记录元数据
default.rgw.log #日志信息
default.rgw.buckets.index #为 rgw 的 bucket 信息,写入数据后生成
default.rgw.buckets.data #是实际存储的数据信息,写入数据后生成
③ 默认情况下 RGW 监听 7480 号端口
[root@admin ceph]# ssh root@nood01 netstat -lntp | grep 7480
ssh: Could not resolve hostname nood01: Name or service not known
[root@admin ceph]# ssh root@node01 netstat -lntp | grep 7480
tcp 0 0 0.0.0.0:7480 0.0.0.0:* LISTEN 12676/radosgw
tcp6 0 0 :::7480 :::* LISTEN 12676/radosgw
[root@admin ceph]# curl node01:7480
<?xml version="1.0" encoding="UTF-8"?><ListAllMyBucketsResult xmlns="http://s3.amazonaws.com/doc/2006-03-01/"><Owner><ID>anonymous</ID><DisplayName></DisplayName></Owner><Buckets></Buckets></ListAllMyBucketsResult>
3、开启 http+https ,更改监听端口(node01)
- RadosGW 守护进程内部由 Civetweb 实现,通过对 Civetweb 的配置可以完成对 RadosGW 的基本管理
- 要在 Civetweb 上启用SSL,首先需要一个证书,在 rgw 节点生成证书
① 生成CA证书私钥
[root@admin ceph]# openssl genrsa -out civetweb.key 2048
Generating RSA private key, 2048 bit long modulus
............+++
..........+++
e is 65537 (0x10001)
② 生成CA证书公钥
[root@admin ceph]# openssl req -new -x509 -key civetweb.key -out civetweb.crt -days 3650 -subj "/CN=192.168.247.131"
[root@admin ceph]# ls
ceph.bootstrap-mds.keyring ceph.bootstrap-rgw.keyring ceph.conf civetweb.crt lion.keyring
ceph.bootstrap-mgr.keyring ceph.client.admin.keyring ceph-deploy-ceph.log civetweb.key rbdmap
ceph.bootstrap-osd.keyring ceph.client.osd-mount.keyring ceph.mon.keyring dashboard_passwd.txt tiger.keyring
③ 将生成的证书合并为pem
[root@admin ceph]# cat civetweb.key civetweb.crt > /etc/ceph/civetweb.pem
4、更改监听端口
- Civetweb 默认监听在 7480 端口并提供 http 协议,如果需要修改配置需要在管理节点编辑 ceph.conf 配置文件
cd /etc/cephvim ceph.conf
......
[client.rgw.node01]
rgw_host = node01
rgw_frontends = "civetweb port=80+443s ssl_certificate=/etc/ceph/civetweb.pem num_threads=500 request_timeout_ms=60000"
| 字段 | 作用 |
|---|---|
| rgw_host | 对应的RadosGW名称或者IP地址 |
| rgw_frontends | 这里配置监听的端口,是否使用https |
| port | 如果是https端口,需要在端口后面加一个s |
| ssl_certificate | 指定证书的路径 |
| num_threads | 最大并发连接数,默认为50,根据需求调整,通常在生产集群环境中此值应该更大 |
| request_timeout_ms | 发送与接收超时时长,以ms为单位,默认为30000 |
| access_log_file | 访问日志路径,默认为空 |
| error_log_file | 错误日志路径,默认为空 |
- 修改完 ceph.conf 配置文件后需要重启对应的 RadosGW 服务,再推送配置文件
[root@admin ceph]# ceph-deploy --overwrite-conf config push node0{1..3}
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (2.0.1): /usr/bin/ceph-deploy --overwrite-conf config push node01 node02 node03
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] overwrite_conf : True
[ceph_deploy.cli][INFO ] subcommand : push
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x7fd98bdfec68>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] client : ['node01', 'node02', 'node03']
[ceph_deploy.cli][INFO ] func : <function config at 0x7fd98c23d1b8>
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.config][DEBUG ] Pushing config to node01
[node01][DEBUG ] connected to host: node01
[node01][DEBUG ] detect platform information from remote host
[node01][DEBUG ] detect machine type
[node01][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.conf
[ceph_deploy.config][DEBUG ] Pushing config to node02
[node02][DEBUG ] connected to host: node02
[node02][DEBUG ] detect platform information from remote host
[node02][DEBUG ] detect machine type
[node02][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.conf
[ceph_deploy.config][DEBUG ] Pushing config to node03
[node03][DEBUG ] connected to host: node03
[node03][DEBUG ] detect platform information from remote host
[node03][DEBUG ] detect machine type
[node03][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.conf
[root@admin ceph]# ssh root@node01 systemctl restart ceph-radosgw.target
- 在 rgw 节点上查看端口
如果在rgw节点上查看不到端口,重新在node节点生成密钥
[root@node01 ~]# netstat -lntp | grep -w 80
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 20897/radosgw
[root@node01 ~]# netstat -lntp | grep 443
tcp 0 0 0.0.0.0:443 0.0.0.0:* LISTEN 20897/radosgw
- 在客户端访问验证(client)
[root@client ~]# curl http://192.168.247.131:80
<?xml version="1.0" encoding="UTF-8"?><ListAllMyBucketsResult xmlns="http://s3.amazonaws.com/doc/2006-03-01/"><Owner><ID>anonymous</ID><DisplayName></DisplayName></Owner><Buckets></Buckets></ListAllMyBucketsResult>
[root@client ~]# curl -k https://192.168.247.131:443
<?xml version="1.0" encoding="UTF-8"?><ListAllMyBucketsResult xmlns="http://s3.amazonaws.com/doc/2006-03-01/"><Owner><ID>anonymous</ID><DisplayName></DisplayName></Owner><Buckets></Buckets></ListAllMyBucketsResult>[root@client ~]#
5、创建 RadosGW 账户
- 在管理节点使用 radosgw-admin 命令创建 RadosGW 账户
[root@admin ceph]# radosgw-admin user create --uid="rgwuser" --display-name="rgw test user"
{"user_id": "rgwuser","display_name": "rgw test user","email": "","suspended": 0,"max_buckets": 1000,"subusers": [],"keys": [{"user": "rgwuser","access_key": "RT14ETLVVH2BFVBA2HXE","secret_key": "ISxhn9mAxQXccdKObucWLJdNlFzJ93nA7cG8YHgM"}],"swift_keys": [],"caps": [],"op_mask": "read, write, delete","default_placement": "","default_storage_class": "","placement_tags": [],"bucket_quota": {"enabled": false,"check_on_raw": false,"max_size": -1,"max_size_kb": 0,"max_objects": -1},"user_quota": {"enabled": false,"check_on_raw": false,"max_size": -1,"max_size_kb": 0,"max_objects": -1},"temp_url_keys": [],"type": "rgw","mfa_ids": []
}
- 创建成功后将输出用户的基本信息,其中最重要的两项信息为 access_key 和 secret_key 。用户创建成后功,如果忘记用户信息可以使用下面的命令查看
[root@admin ceph]# radosgw-admin user info --uid="rgwuser"
{"user_id": "rgwuser","display_name": "rgw test user","email": "","suspended": 0,"max_buckets": 1000,"subusers": [],"keys": [{"user": "rgwuser","access_key": "RT14ETLVVH2BFVBA2HXE","secret_key": "ISxhn9mAxQXccdKObucWLJdNlFzJ93nA7cG8YHgM"}],"swift_keys": [],"caps": [],"op_mask": "read, write, delete","default_placement": "","default_storage_class": "","placement_tags": [],"bucket_quota": {"enabled": false,"check_on_raw": false,"max_size": -1,"max_size_kb": 0,"max_objects": -1},"user_quota": {"enabled": false,"check_on_raw": false,"max_size": -1,"max_size_kb": 0,"max_objects": -1},"temp_url_keys": [],"type": "rgw","mfa_ids": []
}
6、S3 接口访问测试
1)在客户端安装 python3、python3-pip
[root@admin ceph]# yum install -y python3 python3-pip
[root@admin ceph]# python3 -V
Python 3.6.8
[root@admin ceph]# pip3 -V
pip 9.0.3 from /usr/lib/python3.6/site-packages (python 3.6)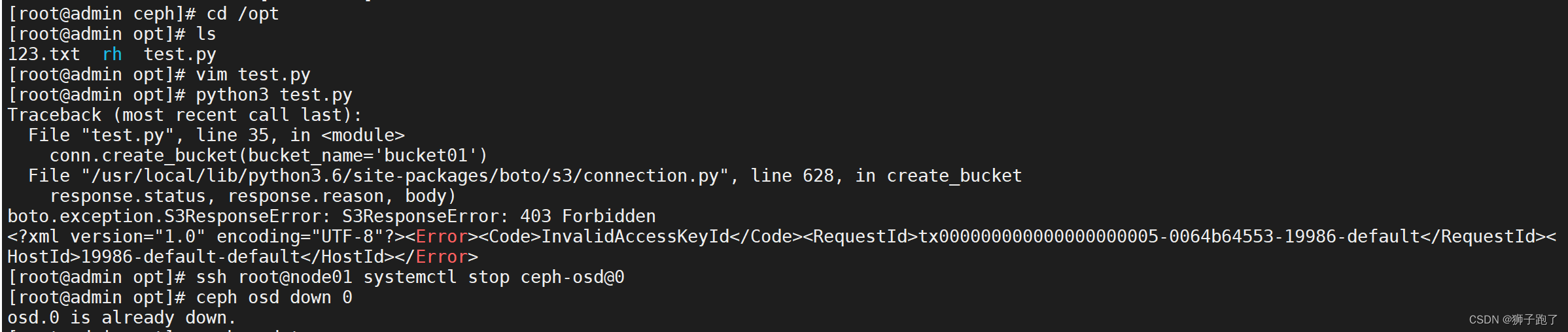
2)安装 boto 模块,用于测试连接 S3
[root@admin ceph]# pip3 install boto
WARNING: Running pip install with root privileges is generally not a good idea. Try `pip3 install --user` instead.
Collecting botoDownloading https://files.pythonhosted.org/packages/23/10/c0b78c27298029e4454a472a1919bde20cb182dab1662cec7f2ca1dcc523/boto-2.49.0-py2.py3-none-any.whl (1.4MB)100% |████████████████████████████████| 1.4MB 47kB/s
Installing collected packages: boto
Successfully installed boto-2.49.0
3)测试访问 S3 接口
echo 123123 > /opt/123.txt
vim test.py
#coding:utf-8
import ssl
import boto.s3.connection
from boto.s3.key import Key
try:_create_unverified_https_context = ssl._create_unverified_context
except AttributeError:pass
else:ssl._create_default_https_context = _create_unverified_https_context#test用户的keys信息
access_key = "ER0SCVRJWNRIKFGQD31H" #输入 RadosGW 账户的 access_key
secret_key = "YKYjk7L4FfAu8GHeQarIlXodjtj1BXVaxpKv2Nna" #输入 RadosGW 账户的 secret_key#rgw的ip与端口
host = "192.168.80.11" #输入 RGW 接口的 public 网络地址#如果使用443端口,下述链接应设置is_secure=True
port = 443
#如果使用80端口,下述链接应设置is_secure=False
#port = 80
conn = boto.connect_s3(aws_access_key_id=access_key,aws_secret_access_key=secret_key,host=host,port=port,is_secure=True,validate_certs=False,calling_format=boto.s3.connection.OrdinaryCallingFormat()
)#一:创建存储桶
#conn.create_bucket(bucket_name='bucket01')
#conn.create_bucket(bucket_name='bucket02')#二:判断是否存在,不存在返回None
exists = conn.lookup('bucket01')
print(exists)
#exists = conn.lookup('bucket02')
#print(exists)#三:获得一个存储桶
#bucket1 = conn.get_bucket('bucket01')
#bucket2 = conn.get_bucket('bucket02')#四:查看一个bucket下的文件
#print(list(bucket1.list()))
#print(list(bucket2.list()))#五:向s3上存储数据,数据来源可以是file、stream、or string
#5.1、上传文件
#bucket1 = conn.get_bucket('bucket01')name的值是数据的key
#key = Key(bucket=bucket1, name='myfile')
#key.set_contents_from_filename('/opt/123.txt')读取 s3 中文件的内容,返回 string 即文件 123.txt 的内容
#print(key.get_contents_as_string())#5.2、上传字符串
#如果之前已经获取过对象,此处不需要重复获取
bucket2 = conn.get_bucket('bucket02')
key = Key(bucket=bucket2, name='mystr')
key.set_contents_from_string('hello world')
print(key.get_contents_as_string())#六:删除一个存储桶,在删除存储桶本身时必须删除该存储桶内的所有key
bucket1 = conn.get_bucket('bucket01')
for key in bucket1:key.delete()
bucket1.delete()
4)按照以上步骤执行 python 脚本测试
[root@admin opt]# python3 test.py
Traceback (most recent call last):File "test.py", line 35, in <module>conn.create_bucket(bucket_name='bucket01')File "/usr/local/lib/python3.6/site-packages/boto/s3/connection.py", line 628, in create_bucketresponse.status, response.reason, body)
boto.exception.S3ResponseError: S3ResponseError: 403 Forbidden
<?xml version="1.0" encoding="UTF-8"?><Error><Code>InvalidAccessKeyId</Code><RequestId>tx000000000000000000005-0064b64553-19986-default</RequestId><HostId>19986-default-default</HostId></Error>
四、OSD 故障模拟与恢复
1、模拟 OSD 故障
-
如果 ceph 集群有上千个 osd,每天坏 2~3 个太正常了,我们可以模拟 down 掉一个 osd
-
如果 osd 守护进程正常运行,down 的 osd 会很快自恢复正常,所以需要先关闭守护进程
[root@admin opt]# ssh root@node01 systemctl stop ceph-osd@0
- down 掉 osd
[root@admin opt]# ceph osd down 0
osd.0 is already down.
[root@admin opt]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.15588 root default
-3 0.05846 host node010 hdd 0.01949 osd.0 down 1.00000 1.000003 hdd 0.01949 osd.3 up 1.00000 1.000006 hdd 0.01949 osd.6 up 1.00000 1.00000
-5 0.05846 host node021 hdd 0.01949 osd.1 up 1.00000 1.000004 hdd 0.01949 osd.4 up 1.00000 1.000007 hdd 0.01949 osd.7 up 1.00000 1.00000
-7 0.03897 host node032 hdd 0.01949 osd.2 up 1.00000 1.000005 hdd 0.01949 osd.5 up 1.00000 1.00000
2、将坏掉的 osd 踢出集群(推荐方法2)
① 方法一
- 将 osd.0 移出集群,集群会开始自动同步数据
ceph osd out osd.0
- 将 osd.0 移除 crushmap
ceph osd crush remove osd.0
- 删除守护进程对应的账户信息
ceph auth rm osd.0
ceph auth list
- 删掉 osd.0
ceph osd rm osd.0
ceph osd stat
ceph -s
② 方法二
[root@admin opt]# ceph osd out osd.0
marked out osd.0.
- 使用综合步骤,删除配置文件中针对坏掉的 osd 的配置
[root@admin opt]# ceph osd purge osd.0 --yes-i-really-mean-it
purged osd.0
3、把原来坏掉的 osd 修复后重新加入集群
- 在 osd 节点创建 osd,无需指定名,会按序号自动生成
[root@node01 ~]# cd /etc/ceph
[root@node01 ceph]# ceph osd create
0
- 创建账户
[root@node01 ceph]# ceph-authtool --create-keyring /etc/ceph/ceph.osd.0.keyring --gen-key -n osd.0 --cap mon 'allow profile osd' --cap mgr 'allow profile osd' --cap osd 'allow *'
creating /etc/ceph/ceph.osd.0.keyring
- 导入新的账户秘钥
[root@node01 ceph]# ceph-authtool --create-keyring /etc/ceph/ceph.osd.0.keyring --gen-key -n osd.0 --cap mon 'allow profile osd' --cap mgr 'allow profile osd' --cap osd 'allow *'
creating /etc/ceph/ceph.osd.0.keyring
[root@node01 ceph]# ceph auth import -i /etc/ceph/ceph.osd.0.keyring
imported keyring
[root@node01 ceph]# ceph auth list
mds.node01key: AQBL47RkRQYCMRAA+D7Nou0EwJo9kqEoQoyeRQ==caps: [mds] allowcaps: [mon] allow profile mdscaps: [osd] allow rwx......
- 更新对应的 osd 文件夹中的密钥环文件
[root@node01 ceph]# ceph auth get-or-create osd.0 -o /var/lib/ceph/osd/ceph-0/keyring
- 加入 crushmap
[root@node01 ceph]# ceph osd crush add osd.0 1.000 host=node01
add item id 0 name 'osd.0' weight 1 at location {host=node01} to crush map
- 加入集群
[root@node01 ceph]# ceph osd in osd.0
marked in osd.0.
[root@node01 ceph]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 1.13640 root default
-3 1.03897 host node010 1.00000 osd.0 down 1.00000 1.000003 hdd 0.01949 osd.3 up 1.00000 1.000006 hdd 0.01949 osd.6 up 1.00000 1.00000
-5 0.05846 host node021 hdd 0.01949 osd.1 up 1.00000 1.000004 hdd 0.01949 osd.4 up 1.00000 1.000007 hdd 0.01949 osd.7 up 1.00000 1.00000
-7 0.03897 host node032 hdd 0.01949 osd.2 up 1.00000 1.000005 hdd 0.01949 osd.5 up 1.00000 1.00000
- 重启 osd 守护进程
[root@node01 ceph]# systemctl restart ceph-osd@0
[root@node01 ceph]# ceph osd tree #稍等片刻后 osd 状态为 up ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 1.13640 root default
-3 1.03897 host node010 hdd 1.00000 osd.0 up 1.00000 1.000003 hdd 0.01949 osd.3 up 1.00000 1.000006 hdd 0.01949 osd.6 up 1.00000 1.00000
-5 0.05846 host node021 hdd 0.01949 osd.1 up 1.00000 1.000004 hdd 0.01949 osd.4 up 1.00000 1.000007 hdd 0.01949 osd.7 up 1.00000 1.00000
-7 0.03897 host node032 hdd 0.01949 osd.2 up 1.00000 1.000005 hdd 0.01949 osd.5 up 1.00000 1.00000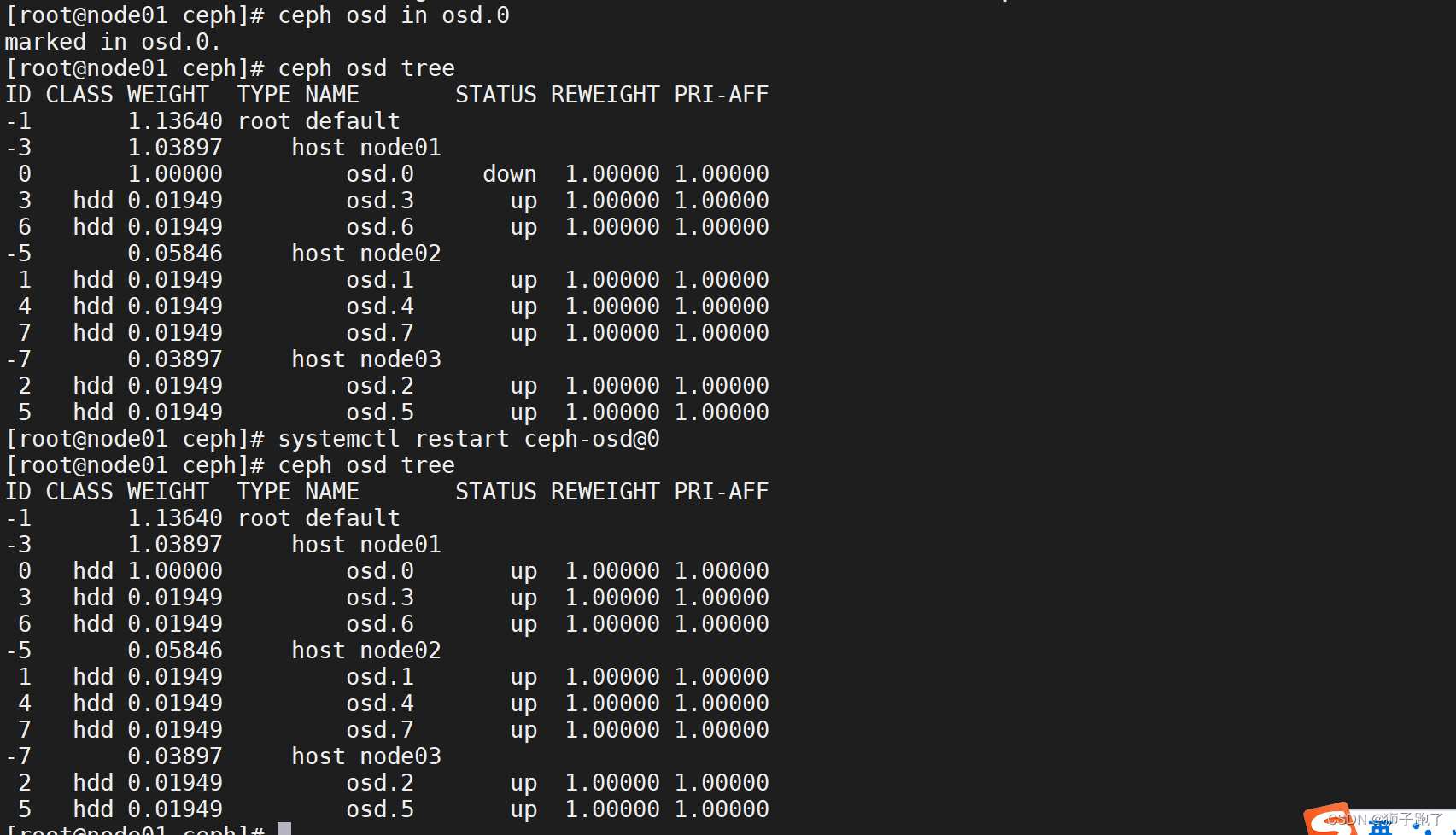
4、如果重启失败
- 报错
Job for ceph-osd@0.service failed because start of the service was attempted too often. See "systemctl status ceph-osd@0.service" and "journalctl -xe" for details.
To force a start use "systemctl reset-failed ceph-osd@0.service" followed by "systemctl start ceph-osd@0.service" again.
- 运行
systemctl reset-failed ceph-osd@0.service && systemctl restart ceph-osd@0.service