Set 集合类体系如下:
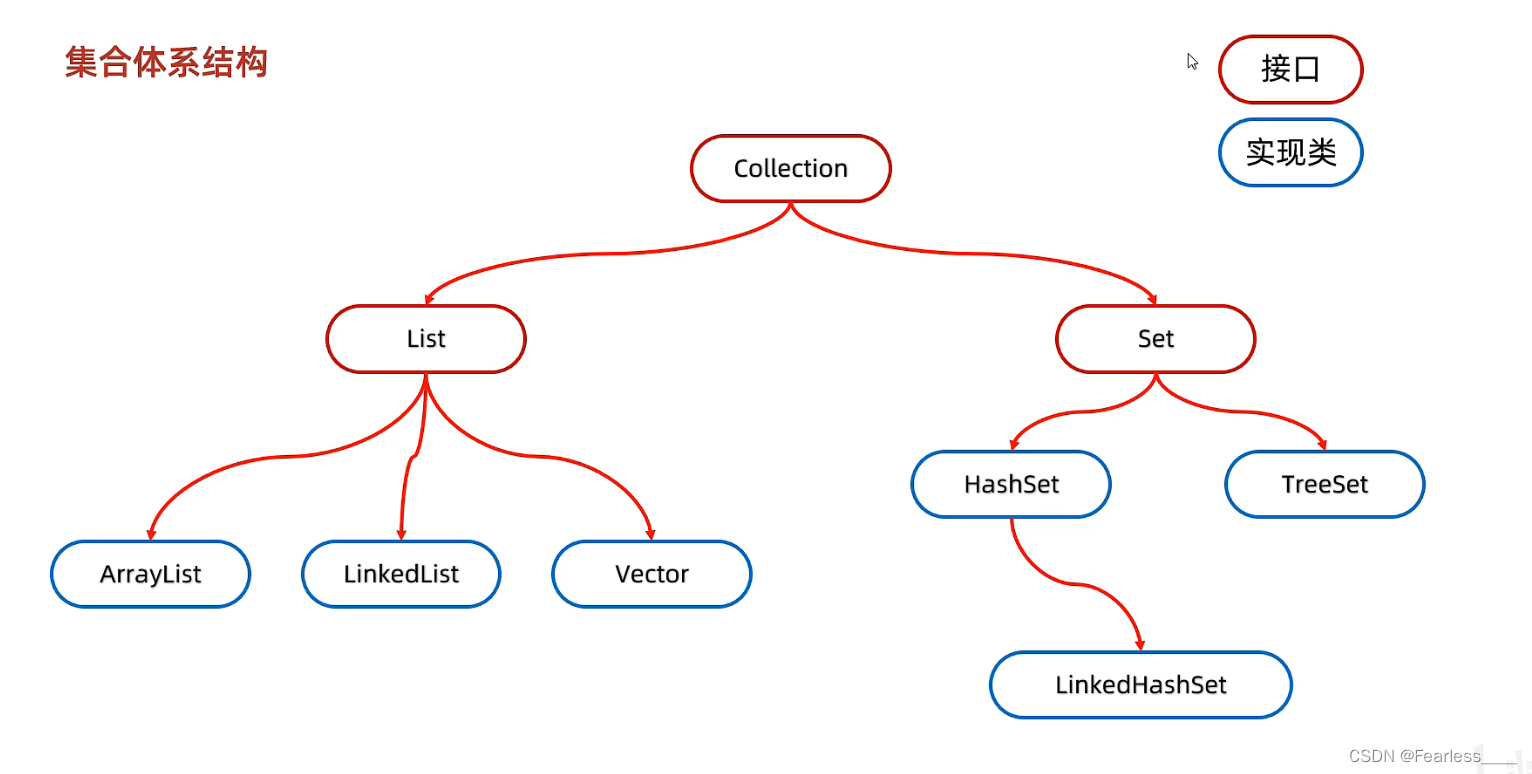
HashSet -- 无序、不重复、无索引
LinkedHashSet -- 有序、不重复、无索引
TreeSet -- 可排序、不重复、无索引
HashSet
HashSet 底层采用 哈希表 存储数据
哈希表组成
JDK8 之前 -- 数组 + 链表
JDK8 之后 -- 数组 + 链表 +红黑树
一开始会把元素存储在数组中,但是哈希表会出现同一个索引位置要存储多个元素的情况,因此要将同一个索引位置的多个对象用链表或红黑树进行存储
哈希表的核心 -- 哈希值
哈希值我们可以理解为对象的整数形式
因为在哈希表存储的时候,不是从索引零开始按序存储的,而是根据公式
int index = (数组长度 - 1 )& 哈希值
index就是对象存储的位置
对象可以根据 hashCode 方法计算出哈希值,该方法定义在Object类中,因此所有对象都可调用,默认使用地址值进行计算,但是一般情况下用对象的地址值计算哈希值的意义不大,因此一般情况下会重写 hashCode 方法,利用对象内部属性计算哈希值
关于 hashCode 方法 重写,最重要的是 hashCode 方法和 equals 方法的联系,可以参考以下博客
(8条消息) 为什么重写 equals 方法就必须重写 hashCode 方法?_Fearless____的博客-CSDN博客![]() https://blog.csdn.net/Fearless____/article/details/131786820
https://blog.csdn.net/Fearless____/article/details/131786820
我们对 对象相等 的定义是:当两个对象 equals 返回 true 时,则两个对象就是相同的
但是当两个对象不相等时,可能会得到相同的哈希值
哈希表存储的原理:
- 通过哈希值计算出存储的位置,如果该位置为null,则直接存入;
- 如果不为null,则调用equals方法(不为null说明多个对象的哈希值相等,但是哈希值相等不代表元素相等,元素是否相等的标准由equals判断),如果该位置存在equals为true的元素,则不存储,如果没有则存储(以链表或红黑树的形式存储)
所以从上面看出,哈希值具有两个作用,一是计算出存储位置,二是初步判断哈希表中是否存在相同元素
正是因为哈希表具有不存储相同对象的特点,HashSet才能做到不重复
又因为哈希表是数组+链表+红黑树,并且不是从索引0开始按序存储,所以HashSet是无序的、无索引的
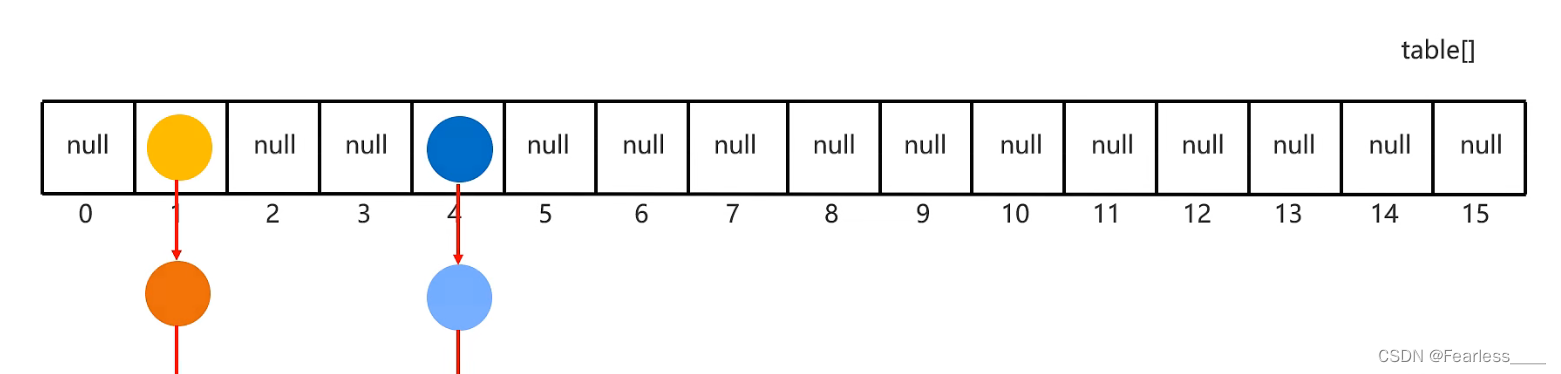
如下图,在遍历的时候,会先查看0索引位置,没有元素,那么查看1索引位置,遍历该链表,继续查看2索引位置... 以此类推,因此遍历的结果是 黄 -> 橙 -> .. -> 深蓝 -> 浅蓝 ,而我们存储的顺序可能是 橙 -> 浅蓝 -> ... -> 蓝->黄
LinkedHashSet
本质上跟 HashSet 相同,只不过多了个双链表的机制记录储存的顺序
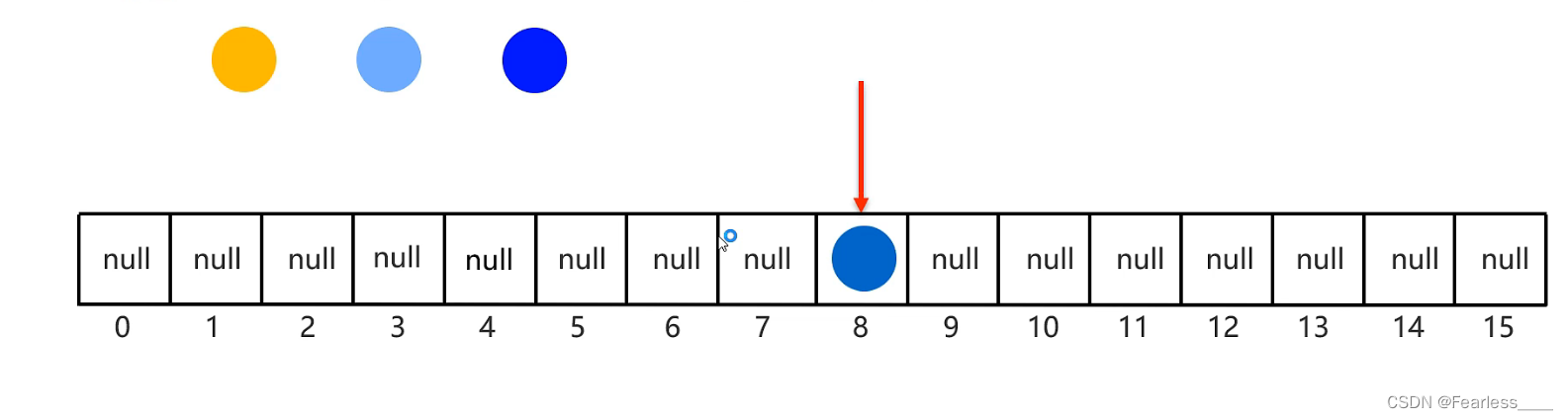
现在我们要将这四个元素存入哈希表中

现在存入第一个元素,此时还有一条双向链表,双向链表的头结点指向该元素
存入第二个元素,此时,第一个元素会记录下第二个元素的地址值,第二个元素也会记录第一个元素的地址值,这就形成了一个双向链表

存入第三个元素,第三个元素和第四个元素间同样会相互记录地址值
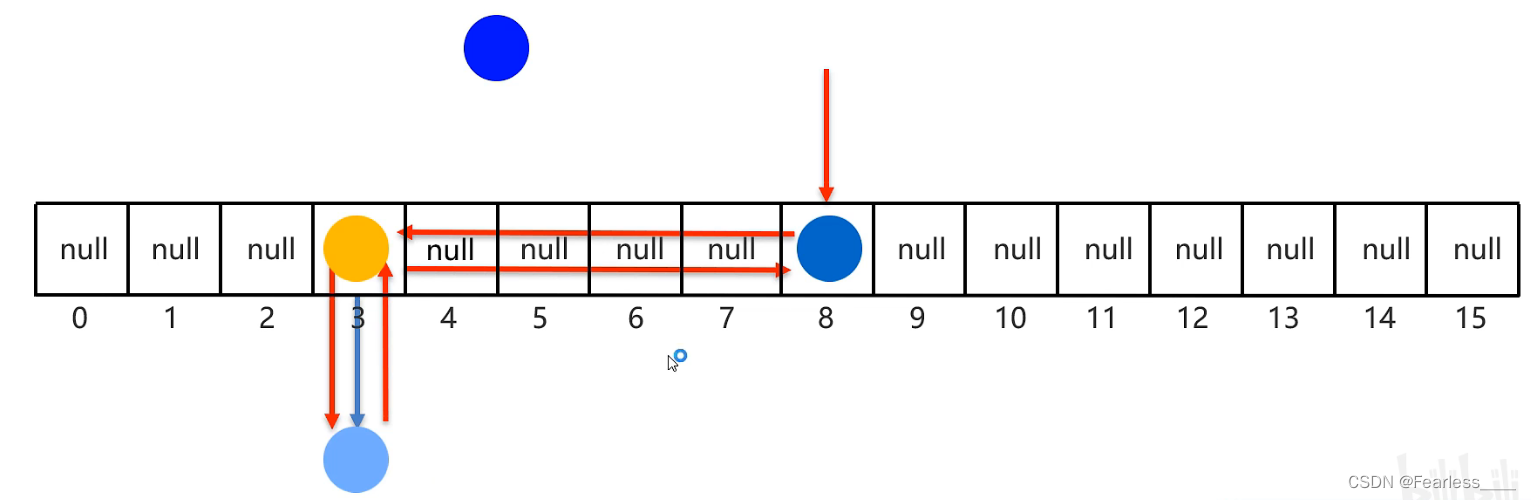
存入第四个元素
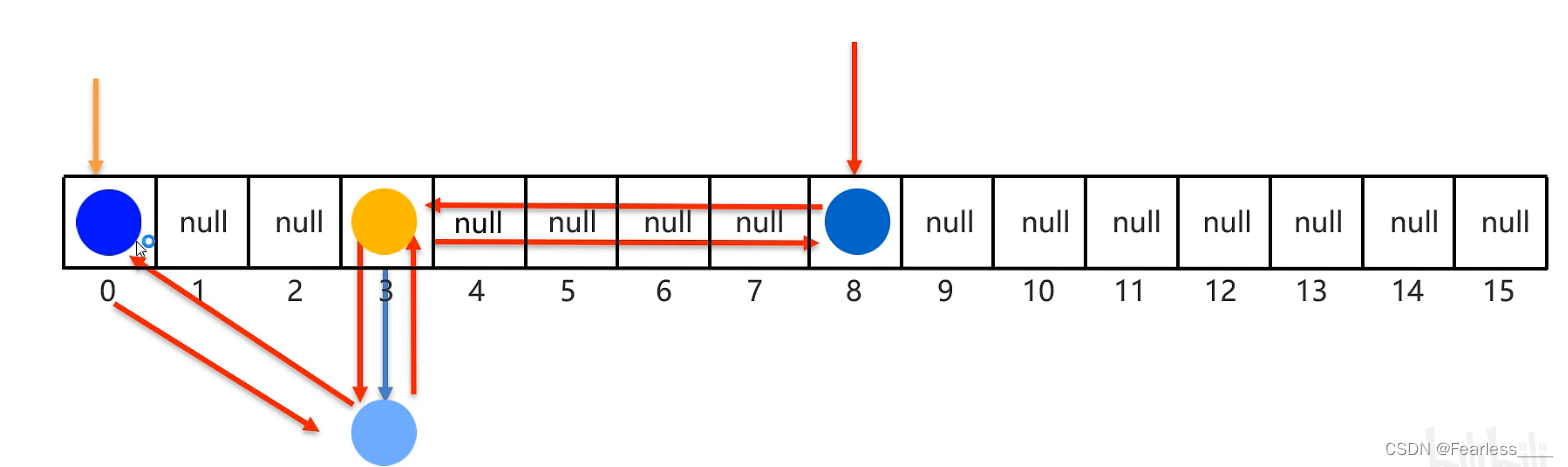
接下来要遍历的时候,不再和HashSet相同,而是直接从头节点开始遍历该双向链表,最后得到的结果就是有序的