相关文章:
Django实现接口自动化平台(十二)自定义函数模块DebugTalks 序列化器及视图【持续更新中】_做测试的喵酱的博客-CSDN博客
本章是项目的一个分解,查看本章内容时,要结合整体项目代码来看:
python django vue httprunner 实现接口自动化平台(最终版)_python+vue自动化测试平台_做测试的喵酱的博客-CSDN博客
一、Interfaces背景及相关接口
| 请求方式 | URI | 对应action | 实现功能 |
| GET | /Interfaces/ | .list() | 查询Interface列表 |
| POST | /Interfaces/ | .create() | 创建一条数据 |
| GET | /Interfaces/{id}/ | .retrieve() | 检索一条Interface的详细数据 |
| PUT | /Interfaces/{id}/ | update() | 更新一条数据中的全部字段 |
| PATCH | /Interfaces/{id}/ | .partial_update() | 更新一条数据中的部分字段 |
| DELETE | /Interfaces/{id}/ | .destroy() | 删除一条数据 |
| GET | /Interfaces/{id}/configs/ | 查询某个接口的配置信息 | |
| POST | /Interfaces/{id}/run/ | 运行某个接口下的所有case | |
| GET | /Interfaces/{id}/testcases/ | 查询Interface下的case列表 |
一个项目下,会有多个接口。
一个接口,会有多个case。
1.1 查询Interface列表
| GET | /Interfaces/ | .list() | 查询Interface列表 |
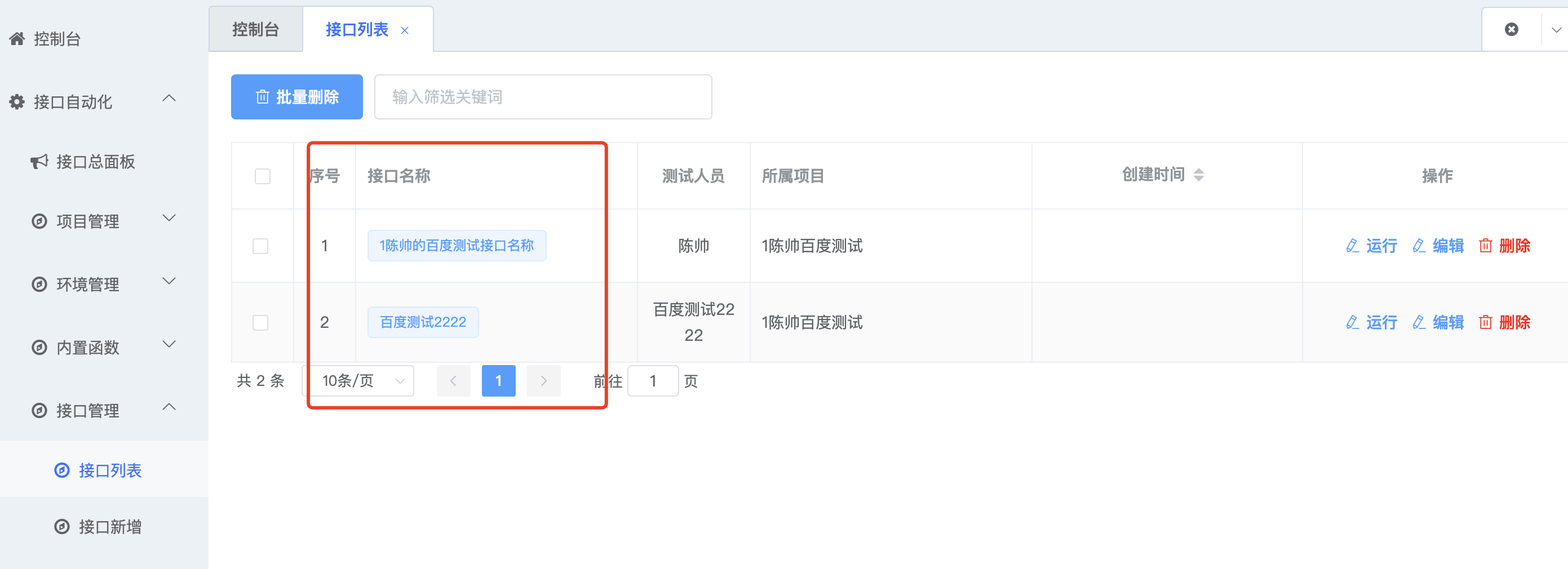 接口列表,所有项目的接口都在这个列表里。
接口列表,所有项目的接口都在这个列表里。
1.2 创建接口 Interface
| POST | /Interfaces/ | .create() | 创建一条数据 |

1.3 编辑更新接口 Interface
| PUT | /Interfaces/{id}/ | update() | 更新一条数据中的全部字段 |


二、模型类model
models.py
from django.db import modelsfrom utils.base_models import BaseModelclass Interfaces(BaseModel):id = models.AutoField(verbose_name='id主键', primary_key=True, help_text='id主键')name = models.CharField('接口名称', max_length=200, unique=True, help_text='接口名称')project = models.ForeignKey('projects.Projects', on_delete=models.CASCADE,related_name='interfaces', help_text='所属项目')tester = models.CharField('测试人员', max_length=50, help_text='测试人员')desc = models.CharField('简要描述', max_length=200, null=True, blank=True, help_text='简要描述')class Meta:db_table = 'tb_interfaces'verbose_name = '接口信息'verbose_name_plural = verbose_nameordering = ('id',)def __str__(self):return self.name这段代码是一个名为 Interfaces 的 Django 模型类,表示接口信息。
该模型类继承了 BaseModel,并定义了以下字段:
- id:自动生成的自增主键。
- name:接口名称,是一个字符型字段,最大长度为 200,且必须唯一。
- project:外键字段,关联到另一个名为 Projects 的模型类,使用级联删除。
- tester:测试人员,是一个字符型字段,最大长度为 50。
- desc:简要描述,是一个可选的字符型字段,最大长度为 200,允许为空。
在模型类的 Meta 内部类中,定义了一些元数据:
- db_table:指定数据库表的名称为 'tb_interfaces'。
- verbose_name:模型类的可读名称为 '接口信息',用于在管理界面显示。
- verbose_name_plural:模型类的复数形式可读名称与 verbose_name 相同。
- ordering:定义默认的排序方式为按照 id 升序排序。
最后,模型类定义了一个 __str__() 方法,返回接口的名称(name 字段值)作为实例的字符串表示,方便在调试和查看对象时使用。
这个模型类表示一个接口信息,包含了接口的名称、所属项目、测试人员和简要描述等字段。
三、序列化器
from rest_framework import serializersfrom .models import Interfaces
from projects.models import Projectsclass InterfaceModelSerilizer(serializers.ModelSerializer):project = serializers.StringRelatedField(label='所属项目名称', help_text='所属项目名称')project_id = serializers.PrimaryKeyRelatedField(label='所属项目id', help_text='所属项目id',queryset=Projects.objects.all())class Meta:model = Interfacesexclude = ('update_datetime',)extra_kwargs = {"create_datetime": {"read_only": True,"format": "%Y年%m月%d日 %H:%M:%S"}}def to_internal_value(self, data):result = super().to_internal_value(data)result['project'] = result.pop('project_id')return result
这是一个名为 InterfaceModelSerializer 的 Django REST Framework 序列化器,用于序列化和反序列化接口信息。
该序列化器继承自 ModelSerializer,并定义了以下字段和元数据:
- project:通过 serializers.StringRelatedField 将关联的项目对象序列化为字符串表示,标签为 "所属项目名称"。
- project_id:通过 serializers.PrimaryKeyRelatedField 将关联的项目对象序列化为其主键 ID,标签为 "所属项目id",查询集为 Projects.objects.all()。
在模型类中,没有project_id 字段,只有project字段。project字段,获取的值,也不是用户传入的,而是根据表信息查询出来的。所以我们要在序列化器中,手动加入project字段的对应的值。
在 Meta 内部类中,定义了以下属性:
- model:指定序列化器对应的模型为 Interfaces。
- exclude:排除不需要被序列化和反序列化的字段,这里排除了 update_datetime 字段。
- extra_kwargs:用于定义附加的字段参数,这里将 create_datetime 字段设置为只读,并指定日期时间格式为 "%Y年%m月%d日 %H:%M:%S"。
此外,序列化器还重写了 to_internal_value() 方法,通过调用父类的方法获取反序列化后的数据,并将 project_id 字段值赋给 project 字段,以匹配模型类中的命名。
该序列化器实现了序列化和反序列化接口信息,并提供了一些额外的字段参数、数据转换等功能。
这里为什么要重写 to_internal_value()方法:
result['project'] = result.pop('project_id')因为在模型类中,没有project_id 字段,只有project字段。
class Interfaces(BaseModel):id = models.AutoField(verbose_name='id主键', primary_key=True, help_text='id主键')name = models.CharField('接口名称', max_length=200, unique=True, help_text='接口名称')project = models.ForeignKey('projects.Projects', on_delete=models.CASCADE,related_name='interfaces', help_text='所属项目')tester = models.CharField('测试人员', max_length=50, help_text='测试人员')desc = models.CharField('简要描述', max_length=200, null=True, blank=True, help_text='简要描述')project_id 字段来自
3.1 扩展:重写 to_internal_value() 方法
3.1.1、ModelSerializer 类介绍:
五、DRF 模型序列化器ModelSerializer_做测试的喵酱的博客-CSDN博客
3.1.2 to_internal_value() 原始方法
继承关系: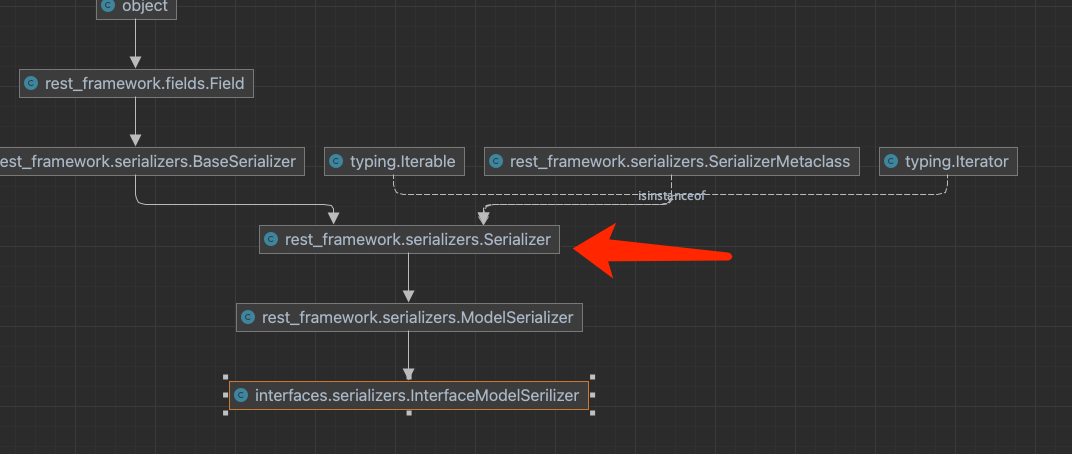
重写to_internal_value() 方法,to_internal_value() 是继承自Serializer 类。
源码:
def to_internal_value(self, data):"""Dict of native values <- Dict of primitive datatypes."""if not isinstance(data, Mapping):message = self.error_messages['invalid'].format(datatype=type(data).__name__)raise ValidationError({api_settings.NON_FIELD_ERRORS_KEY: [message]}, code='invalid')ret = OrderedDict()errors = OrderedDict()fields = self._writable_fieldsfor field in fields:validate_method = getattr(self, 'validate_' + field.field_name, None)primitive_value = field.get_value(data)try:validated_value = field.run_validation(primitive_value)if validate_method is not None:validated_value = validate_method(validated_value)except ValidationError as exc:errors[field.field_name] = exc.detailexcept DjangoValidationError as exc:errors[field.field_name] = get_error_detail(exc)except SkipField:passelse:set_value(ret, field.source_attrs, validated_value)if errors:raise ValidationError(errors)return retto_internal_value 方法用于将传入的原始数据data转换为内部值,即将外部数data据映射到模型的属性上。
传入的原始数据data:
- 传入的原始数据可以是一个字典类型(Mapping),即一个键值对组成的数据结构。在这段代码中,通过判断数据类型是否为 Mapping 来确定是否满足传入的要求。如果不是字典类型,就会抛出一个验证错误。字典类型的数据可以是类似 {'key': 'value'} 的形式,其中键和值可以是任意合法的 Python 数据类型。
1、在该方法中,首先判断传入的数据是否是一个字典类型(Mapping)。如果不是字典类型,则抛出一个验证错误,并返回错误信息。然后,创建一个有序字典 ret 用于存储转换后的内部值,以及一个有序字典 errors 用于存储验证过程中的错误信息。
2、接下来,获取可写字段(_writable_fields)列表,并遍历其中的每个字段。对于每个字段,首先尝试获取该字段验证方法(validate_method),然后通过字段的 get_value(data) 方法获取原始数据的值。
3、接着,对原始值进行验证和转换操作,使用字段的 run_validation 方法进行验证,将原始值转换为验证后的值。如果字段定义了验证方法(validate_method),则调用该方法对验证后的值进行进一步处理。
在验证过程中,可能会抛出 ValidationError 或 DjangoValidationError 异常,这表示验证失败。此时,将错误信息保存到 errors 字典中,字段名作为键,错误详情作为值。
如果在验证过程中出现 SkipField 异常,表示跳过该字段的验证操作,直接进入下一个字段。
最后,如果 errors 字典中含有错误信息,则抛出 ValidationError 异常,其中包含了所有字段的验证错误信息。如果没有错误,则返回转换后的内部值 ret。
总结来说,to_internal_value 方法是 Django REST Framework 中用于将外部传入的数据转换为内部值的核心方法,它通过验证和转换操作,将外部数据映射到模型的属性上,并处理了验证过程中可能出现的错误。
to_internal_value() 方法的返回值:
"""Dict of native values <- Dict of primitive datatypes.""""Dict of primitive datatypes" 指的是一个字典,其中的值是原始数据类型(primitive datatypes)的数据。常见的原始数据类型包括整数(int)、浮点数(float)、字符串(string)、布尔值(boolean)等。
"Dict of native values" 意味着一个字典,其中的值是原生(native)数据类型的值。在 Python 中,这些原生数据类型与内置数据类型是一致的,如int、float、str、bool等。
因此,"Dict of native values <- Dict of primitive datatypes" 表示将一个字典中的原始数据类型的值转换为对应的原生数据类型的值。这个转换的过程可以通过 Python 的内置功能来完成,例如使用 int()、float()、str()、bool() 等方法来将值转换为相应的原生数据类型。最终的结果将是一个具有相同键但值为原生数据类型的字典。
to_internal_value 方法的返回值通常是一个字典类型(Mapping),表示经过转换后的内部值。在代码中,result 变量就是一个字典,它存储了经过处理后的数据。
3.1.3 重写to_internal_value() 方法
def to_internal_value(self, data):result = super().to_internal_value(data)result['project'] = result.pop('project_id')return result在这段代码中,to_internal_value 方法首先调用了父类的 to_internal_value 方法,传入了参数 data。这个方法是继承自父类的,默认的实现会将传入的数据转换为内部值。
然后,result['project'] = result.pop('project_id') 这一行代码将字典中键为 'project_id' 的值取出,并以 'project' 作为键添加到 result 字典中。同时,result.pop('project_id') 会将原字典中键为 'project_id' 的键值对删除。
最后,返回经过处理后的 result 字典。
这段代码的作用是将传入的数据中的 'project_id' 键值对提取出来,并将其改名为 'project',然后返回处理后的字典。这样可以实现对数据的字段重命名操作。
四、视图
class InterfaceViewSet(RunMixin, viewsets.ModelViewSet):queryset = Interfaces.objects.all()serializer_class = serializers.InterfaceModelSerilizerpermission_classes = [permissions.IsAuthenticated]