spark基础入门
- 环境搭建
- local
- standlone
- spark ha
- spark code
- spark core
- spark sql
- spark streaming
环境搭建
准备工作
创建安装目录
mkdir /opt/soft
cd /opt/soft
下载scala
wget https://downloads.lightbend.com/scala/2.13.12/scala-2.13.12.tgz -P /opt/soft
解压scala
tar -zxvf scala-2.13.12.tgz
修改scala目录名称
mv scala-2.13.12 scala-2
下载spark
wget https://dlcdn.apache.org/spark/spark-3.5.0/spark-3.5.0-bin-hadoop3-scala2.13.tgz -P /opt/soft
解压spark
tar -zxvf spark-3.5.0-bin-hadoop3-scala2.13.tgz
修改目录名称
mv spark-3.5.0-bin-hadoop3-scala2.13 spark-3
修改环境遍历
vim /etc/profile.d/my_env.sh
export JAVA_HOME=/opt/soft/jdk-8export ZOOKEEPER_HOME=/opt/soft/zookeeper-3export HDFS_NAMENODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_ZKFC_USER=root
export HDFS_JOURNALNODE_USER=root
export HADOOP_SHELL_EXECNAME=rootexport YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=rootexport HADOOP_HOME=/opt/soft/hadoop-3
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoopexport HBASE_HOME=/opt/soft/hbase-2export PHOENIX_HOME=/opt/soft/phoenixexport HIVE_HOME=/opt/soft/hive-3
export HCATALOG_HOME=/opt/soft/hive-3/hcatalogexport HCAT_HOME=/opt/soft/hive-3/hcatalog
export SQOOP_HOME=/opt/soft/sqoop-1export FLUME_HOME=/opt/soft/flumeexport SCALA_HOME=/opt/soft/scala-2export SPARK_HOME=/opt/soft/spark-3
export SPARKPYTHON=/opt/soft/spark-3/pythonexport PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin:$PHOENIX_HOME/bin:$HIVE_HOME/bin:$HCATALOG_HOME/bin:$HCATALOG_HOME/sbin:$HCAT_HOME/bin:$SQOOP_HOME/bin:$FLUME_HOME/bin:$SCALA_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin:$SPARKPYTHON
source /etc/profile
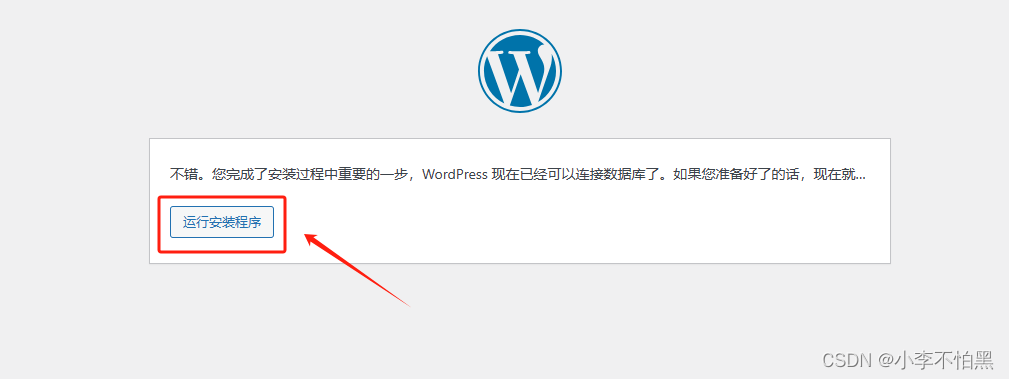
Local模式
scala java
启动
spark-shell

页面地址:http://spark01:4040

退出
:quit

pyspark
启动
pyspark

页面地址:http://spark01:4040
退出
quit() or Ctrl-D

本地模式提交应用
在spark目录下执行
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[4] \
./examples/jars/spark-examples_2.13-3.5.0.jar \
10
- –class表示要执行程序的主类,此处可以更换为咱们自己写的应用程序
- –master local[2] 部署模式,默认为本地模式,数字表示分配的虚拟CPU核数量
- spark-examples_2.13-3.5.0.jar 运行的应用类所在的jar包,实际使用时,可以设定为咱们自己打的jar包
- 数字10表示程序的入口参数,用于设定当前应用的任务数量
Standalone模式
编写核心配置文件
cont目录下
cd /opt/soft/spark-3/conf
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
export JAVA_HOME=/opt/soft/jdk-8
export HADOOP_HOME=/opt/soft/hadoop-3
export HADOOP_CONF_DIR=/opt/soft/hadoop-3/etc/hadoop
export JAVA_LIBRAY_PATH=/opt/soft/hadoop-3/lib/native
export SPARK_DIST_CLASSPATH=$(/opt/soft/hadoop-3/bin/hadoop classpath)export SPARK_MASTER_HOST=spark01
export SPARK_MASTER_PORT=7077export SPARK_WORKER_MEMORY=4g
export SPARK_WORKER_CORES=4
export SPARK_MASTER_WEBUI_PORT=6633编辑slaves
cp workers.template workers
vim workers
spark01
spark02
spark03配置历史日志
cp spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://lihaozhe/spark-log
hdfs dfs -mkdir /spark-log
vim spark-env.sh
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.retainedApplications=30
-Dspark.history.fs.logDirectory=hdfs://lihaozhe/spark-log"
修改启动文件名称
mv sbin/start-all.sh sbin/start-spark.sh
mv sbin/stop-all.sh sbin/stop-spark.sh
分发搭配其他节点
scp -r /opt/soft/spark-3 root@spark02:/opt/soft
scp -r /opt/soft/spark-3 root@spark03:/opt/soft
scp /etc/profile.d/my_env.sh root@spark02:/etc/profile.d
scp /etc/profile.d/my_env.sh root@spark03:/etc/profile.d
在其它节点刷新环境遍历
source /etc/profile
启动
start-spark.sh
start-history-server.sh
webui
http://spark01:6633

http://spark01:18080

提交作业到集群
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://spark01:7077 \
./examples/jars/spark-examples_2.13-3.5.0.jar \
10
提交作业到Yarn
spark-submit \
--master yarn \
--class org.apache.spark.examples.SparkPi \
./examples/jars/spark-examples_2.13-3.5.0.jar \
10
HA模式
编写核心配置文件
cont目录下
cd /opt/soft/spark-3/conf
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
export JAVA_HOME=/opt/soft/jdk-8
export HADOOP_HOME=/opt/soft/hadoop-3
export HADOOP_CONF_DIR=/opt/soft/hadoop-3/etc/hadoop
export JAVA_LIBRAY_PATH=/opt/soft/hadoop-3/lib/native
export SPARK_DIST_CLASSPATH=$(/opt/soft/hadoop-3/bin/hadoop classpath)SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=spark01:2181,spark02:2181,spark03:2181
-Dspark.deploy.zookeeper.dir=/spark"export SPARK_WORKER_MEMORY=8g
export SPARK_WORKER_CORES=8
export SPARK_MASTER_WEBUI_PORT=6633编辑slaves
cp workers.template workers
vim workers
spark01
spark02
spark03配置历史日志
cp spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://lihaozhe/spark-log
hdfs dfs -mkdir /spark-log
vim spark-env.sh
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.retainedApplications=30
-Dspark.history.fs.logDirectory=hdfs://lihaozhe/spark-log"
修改启动文件名称
mv sbin/start-all.sh sbin/start-spark.sh
mv sbin/stop-all.sh sbin/stop-spark.sh
分发搭配其他节点
scp -r /opt/soft/spark-3 root@spark02:/opt/soft
scp -r /opt/soft/spark-3 root@spark03:/opt/soft
scp /etc/profile.d/my_env.sh root@spark02:/etc/profile.d
scp /etc/profile.d/my_env.sh root@spark03:/etc/profile.d
在其它节点刷新环境遍历
source /etc/profile
启动
start-spark.sh
start-history-server.sh
webui
http://spark01:6633

http://spark01:18080

提交作业到集群
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://spark01:7077 \
./examples/jars/spark-examples_2.13-3.5.0.jar \
10
提交作业到Yarn
spark-submit --master yarn \
--class org.apache.spark.examples.SparkPi \
./examples/jars/spark-examples_2.13-3.5.0.jar 10
spark-code
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.lihaozhe</groupId><artifactId>spark-code</artifactId><version>1.0.0</version><properties><jdk.version>1.8</jdk.version><scala.version>2.13.12</scala.version><spark.version>3.5.0</spark.version><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><commons-io.version>2.14.0</commons-io.version><commons-lang3.version>3.12.0</commons-lang3.version><commons-pool2.version>2.11.1</commons-pool2.version><hadoop.version>3.3.6</hadoop.version><hive.version>3.1.3</hive.version><java-testdata-generator.version>1.1.2</java-testdata-generator.version><junit.version>5.10.1</junit.version><lombok.version>1.18.30</lombok.version><mysql.version>8.2.0</mysql.version></properties><dependencies><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>${scala.version}</version></dependency><dependency><groupId>org.scala-lang</groupId><artifactId>scala-compiler</artifactId><version>${scala.version}</version></dependency><dependency><groupId>com.github.binarywang</groupId><artifactId>java-testdata-generator</artifactId><version>${java-testdata-generator.version}</version></dependency><!-- spark-core --><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.13</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.13</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.13</artifactId><version>${spark.version}</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.13</artifactId><version>${spark.version}</version></dependency><!-- junit-jupiter-api --><dependency><groupId>org.junit.jupiter</groupId><artifactId>junit-jupiter-api</artifactId><version>${junit.version}</version><scope>test</scope></dependency><!-- junit-jupiter-engine --><dependency><groupId>org.junit.jupiter</groupId><artifactId>junit-jupiter-engine</artifactId><version>${junit.version}</version><scope>test</scope></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>${lombok.version}</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-slf4j2-impl</artifactId><version>2.21.1</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-core</artifactId><version>2.21.1</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>1.7.25</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version></dependency><!-- commons-pool2 --><dependency><groupId>org.apache.commons</groupId><artifactId>commons-pool2</artifactId><version>${commons-pool2.version}</version></dependency><dependency><groupId>org.apache.hive</groupId><artifactId>hive-jdbc</artifactId><version>${hive.version}</version></dependency><!-- commons-lang3 --><dependency><groupId>org.apache.commons</groupId><artifactId>commons-lang3</artifactId><version>${commons-lang3.version}</version></dependency><dependency><groupId>commons-io</groupId><artifactId>commons-io</artifactId><version>${commons-io.version}</version></dependency><dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId><version>${mysql.version}</version></dependency></dependencies><build><finalName>${project.artifactId}</finalName><!--<outputDirectory>../package</outputDirectory>--><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.11.0</version><configuration><!-- 设置编译字符编码 --><encoding>UTF-8</encoding><!-- 设置编译jdk版本 --><source>${jdk.version}</source><target>${jdk.version}</target></configuration></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-clean-plugin</artifactId><version>3.3.2</version></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-resources-plugin</artifactId><version>3.3.1</version></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-war-plugin</artifactId><version>3.3.2</version></plugin><!-- 编译级别 --><!-- 打包的时候跳过测试junit begin --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-surefire-plugin</artifactId><version>3.2.2</version><configuration><skip>true</skip></configuration></plugin><!-- 该插件用于将Scala代码编译成class文件 --><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>4.8.1</version><configuration><scalaCompatVersion>${scala.version}</scalaCompatVersion><scalaVersion>${scala.version}</scalaVersion></configuration><executions><execution><goals><goal>testCompile</goal></goals></execution><execution><id>compile-scala</id><phase>compile</phase><goals><goal>add-source</goal><goal>compile</goal></goals></execution><execution><id>test-compile-scala</id><phase>test-compile</phase><goals><goal>add-source</goal><goal>testCompile</goal></goals></execution></executions></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.6.0</version><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build>
</project>hdfs-conf
在 resources 目录下存放 hdfs 核心配置文件 core-site.xml 和hdfs-site.xml
被引入的hdfs配置文件为测试集群配置文件
由于生产环境与测试环境不同,项目打包的时候排除hdfs配置文件
rdd
相同点:
都是分布式数据集
DataFrame底层是RDD,但是DataSet不是,不过他们最后都是转换成RDD运行
DataSet和DataFrame的相同点都是有数据特征、数据类型的分布式数据集(schema)
不同点:
schema信息:
RDD中的数据是没有数据类型的
DataFrame中的数据是弱数据类型,不会做数据类型检查 虽然有schema规定了数据类型,但是编译时是不会报错的,运行时才会报错
DataSet中的数据类型是强数据类型
序列化机制:
RDD和DataFrame默认的序列化机制是java的序列化,可以修改为Kyro的机制
DataSet使用自定义的数据编码器进行序列化和反序列化
数据集方式构建RDD
package cn.lihaozhe.chap01;import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;import java.util.Arrays;
import java.util.List;/*** 数据集构建RDD* RDD代表弹性分布式数据集。它是记录的只读分区集合。 RDD是Spark的基本数据结构。它允许程序员以容错方式在大型集群上执行内存计算。** @author 李昊哲* @version 1.0*/
public class JavaDemo01 {public static void main(String[] args) {// SparkConf conf = new SparkConf().setAppName("RDD").setMaster("local");// spark基础配置SparkConf conf = new SparkConf().setAppName("RDD");// 本地运行conf.setMaster("local");try (JavaSparkContext sparkContext = new JavaSparkContext(conf)) {// 数据集List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);// 从集合中创建 RDDJavaRDD<Integer> javaRDD = sparkContext.parallelize(list);// 将 spark RDD 转为 java 对象List<Integer> collect = javaRDD.collect();// lambda 表达式collect.forEach(System.out::println);}}
}package cn.lihaozhe.chap01import org.apache.spark.{SparkConf, SparkContext}/*** 数据集构建RDD* RDD代表弹性分布式数据集。它是记录的只读分区集合。 RDD是Spark的基本数据结构。它允许程序员以容错方式在大型集群上执行内存计算。** @author 李昊哲* @version 1.0*/
object ScalaDemo01 {def main(args: Array[String]): Unit = {// val conf = new SparkConf().setAppName("RDD").setMaster("local")// spark基础配置val conf = new SparkConf().setAppName("RDD")// 本地运行conf.setMaster("local")val sparkContext = new SparkContext(conf)// 数据集val data = Array(1, 2, 3, 4, 5)// 从集合中创建 RDD// ParallelCollectionRDDval rdd = sparkContext.parallelize(data)rdd.foreach(println(_))}
}本地文件构建RDD
words.txt
linux shell
java mysql jdbc
hadoop hdfs mapreduce
hive presto
flume kafka
hbase phoenix
scala spark
sqoop flink
linux shell
java mysql jdbc
hadoop hdfs mapreduce
hive presto
flume kafka
hbase phoenix
scala spark
sqoop flink
base phoenix
scala spark
sqoop flink
linux shell
java mysql jdbc
hadoop hdfs mapreduce
java mysql jdbc
hadoop hdfs mapreduce
hive presto
flume kafka
hbase phoenix
scala spark
java mysql jdbc
hadoop hdfs mapreduce
java mysql jdbc
hadoop hdfs mapreduce
hive prestopackage cn.lihaozhe.chap01;import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;import java.util.List;/*** 借助外部文件 External Datasets 构建 RDD** @author 李昊哲* @version 1.0*/
public class JavaDemo02 {public static void main(String[] args) {// SparkConf conf = new SparkConf().setAppName("RDD").setMaster("local");// spark基础配置SparkConf conf = new SparkConf().setAppName("RDD");// 本地运行conf.setMaster("local");try (JavaSparkContext sparkContext = new JavaSparkContext(conf)) {// 使用本地文件系统构建数据集JavaRDD<String> javaRDD = sparkContext.textFile("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/word.txt");// 将 spark RDD 转为 java 对象List<String> collect = javaRDD.collect();// lambda 表达式collect.forEach(System.out::println);}}
}
package cn.lihaozhe.chap01import org.apache.spark.{SparkConf, SparkContext}/*** 借助外部文件 External Datasets 构建 RDD** @author 李昊哲* @version 1.0*/
object ScalaDemo02 {def main(args: Array[String]): Unit = {// val conf = new SparkConf().setAppName("RDD").setMaster("local")// spark基础配置val conf = new SparkConf().setAppName("RDD")// 本地运行conf.setMaster("local")val sparkContext = new SparkContext(conf)// 使用本地文件系统构建数据集val data = sparkContext.textFile("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/word.txt")data.foreach(println(_))}
}HDFS文件构建RDD
package cn.lihaozhe.chap01;import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;import java.util.List;/*** 借助外部文件 External Datasets 构建 RDD** @author 李昊哲* @version 1.0*/
public class JavaDemo03 {public static void main(String[] args) {System.setProperty("HADOOP_USER_NAME", "root");// SparkConf conf = new SparkConf().setAppName("RDD").setMaster("local");// spark基础配置SparkConf conf = new SparkConf().setAppName("RDD");// 本地运行conf.setMaster("local");try (JavaSparkContext sparkContext = new JavaSparkContext(conf)) {// 使用本地文件系统构建数据集// JavaRDD<String> javaRDD = sparkContext.textFile("hdfs://spark01:8020/data/word.txt");JavaRDD<String> javaRDD = sparkContext.textFile("/data/word.txt");// 将 spark RDD 转为 java 对象List<String> collect = javaRDD.collect();// lambda 表达式collect.forEach(System.out::println);}}
}
package cn.lihaozhe.chap01import org.apache.spark.{SparkConf, SparkContext}/*** 借助外部文件 External Datasets 构建 RDD** @author 李昊哲* @version 1.0*/
object ScalaDemo03 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")// val conf = new SparkConf().setAppName("RDD").setMaster("local")// spark基础配置val conf = new SparkConf().setAppName("RDD")// 本地运行conf.setMaster("local")val sparkContext = new SparkContext(conf)// 使用本地文件系统构建数据集val data = sparkContext.textFile("/data/word.txt")data.foreach(println(_))}
}
算子
count
javacode
package cn.lihaozhe.chap02;import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;import java.util.Arrays;
import java.util.List;/*** count 算子** @author 李昊哲* @version 1.0*/
public class JavaDemo01 {public static void main(String[] args) {String appName = "count";// SparkConf conf = new SparkConf().setAppName(appName).setMaster("local");// spark基础配置SparkConf conf = new SparkConf().setAppName(appName);// 本地运行conf.setMaster("local");try (JavaSparkContext sparkContext = new JavaSparkContext(conf)) {// 数据集List<Integer> data = Arrays.asList(0, 1, 2, 3, 4, 5, 6, 7, 8, 9);// 从集合中创建RDDJavaRDD<Integer> javaRDD = sparkContext.parallelize(data);long count = javaRDD.count();System.out.println("count = " + count);}}
}scalacode
package cn.lihaozhe.chap02import org.apache.spark.{SparkConf, SparkContext}/*** count 算子** @author 李昊哲* @version 1.0*/
object ScalaDemo01 {def main(args: Array[String]): Unit = {val appName = "count"// spark基础配置// val conf = new SparkConf().setAppName(appName).setMaster("local")val conf = new SparkConf().setAppName(appName)// 本地运行conf.setMaster("local")// 构建 SparkContext spark 上下文val sparkContext = new SparkContext(conf)// 数据集val data = Array(0, 1, 2, 3, 4, 5, 6, 7, 8, 9)val rdd = sparkContext.parallelize(data)val count = rdd.count()println(s"count = $count")}
}运行结果:
count = 10
take
javacode
package cn.lihaozhe.chap02;import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;import java.util.Arrays;
import java.util.List;/*** take 算子** @author 李昊哲* @version 1.0*/
public class JavaDemo02 {public static void main(String[] args) {String appName = "take";// SparkConf conf = new SparkConf().setAppName(appName).setMaster("local");// spark基础配置SparkConf conf = new SparkConf().setAppName(appName);// 本地运行conf.setMaster("local");try (JavaSparkContext sparkContext = new JavaSparkContext(conf)) {// 数据集List<Integer> data = Arrays.asList(0, 1, 2, 3, 4, 5, 6, 7, 8, 9);// 从集合中创建RDDJavaRDD<Integer> javaRDD = sparkContext.parallelize(data);List<Integer> topList = javaRDD.take(3);topList.forEach(System.out::println);}}
}scalacode
package cn.lihaozhe.chap02import org.apache.spark.{SparkConf, SparkContext}/*** take 算子** @author 李昊哲* @version 1.0*/
object ScalaDemo02 {def main(args: Array[String]): Unit = {val appName = "take"// spark基础配置// val conf = new SparkConf().setAppName(appName).setMaster("local")val conf = new SparkConf().setAppName(appName)// 本地运行conf.setMaster("local")// 构建 SparkContext spark 上下文val sparkContext = new SparkContext(conf)// 数据集val data = Array(0, 1, 2, 3, 4, 5, 6, 7, 8, 9)val rdd = sparkContext.parallelize(data)val top = rdd.take(3)top.foreach(println(_))}
}运行结果:
0
1
2distinct
javacode
package cn.lihaozhe.chap02;import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;import java.util.Arrays;
import java.util.List;/*** distinct 算子** @author 李昊哲* @version 1.0*/
public class JavaDemo03 {public static void main(String[] args) {String appName = "distinct";// SparkConf conf = new SparkConf().setAppName(appName).setMaster("local");// spark基础配置SparkConf conf = new SparkConf().setAppName(appName);// 本地运行conf.setMaster("local");try (JavaSparkContext sparkContext = new JavaSparkContext(conf)) {// 数据集List<Integer> data = Arrays.asList(0, 1, 5, 6, 7, 8, 9, 3, 4, 2, 4, 3);// 从集合中创建RDDJavaRDD<Integer> javaRDD = sparkContext.parallelize(data);JavaRDD<Integer> uniqueRDD = javaRDD.distinct();List<Integer> uniqueList = uniqueRDD.collect();uniqueList.forEach(System.out::println);}}
}scalacode
package cn.lihaozhe.chap02import org.apache.spark.{SparkConf, SparkContext}/*** distinct 算子** @author 李昊哲* @version 1.0*/
object ScalaDemo03 {def main(args: Array[String]): Unit = {val appName = "distinct"// spark基础配置// val conf = new SparkConf().setAppName(appName).setMaster("local")val conf = new SparkConf().setAppName(appName)// 本地运行conf.setMaster("local")// 构建 SparkContext spark 上下文val sparkContext = new SparkContext(conf)// 数据集val data = Array(0, 1, 5, 6, 7, 8, 9, 3, 4, 2, 4, 3)val rdd = sparkContext.parallelize(data)val uniqueRdd = rdd.distinct()uniqueRdd.foreach(println(_))}
}运行结果:
4
0
1
6
3
7
9
8
5
2map
javacode
package cn.lihaozhe.chap02;import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;import java.util.Arrays;
import java.util.List;/*** map 算子** @author 李昊哲* @version 1.0*/
public class JavaDemo04 {public static void main(String[] args) {String appName = "map";// SparkConf conf = new SparkConf().setAppName(appName).setMaster("local");// spark基础配置SparkConf conf = new SparkConf().setAppName(appName);// 本地运行conf.setMaster("local");try (JavaSparkContext sparkContext = new JavaSparkContext(conf)) {// 数据集List<Integer> data = Arrays.asList(1, 2, 3, 4, 5);// 从集合中创建RDDJavaRDD<Integer> javaRDD = sparkContext.parallelize(data);JavaRDD<Integer> rs = javaRDD.map(num -> num * 2);List<Integer> list = rs.collect();list.forEach(System.out::println);}}
}scalacode
package cn.lihaozhe.chap02import org.apache.spark.{SparkConf, SparkContext}/*** map 算子** @author 李昊哲* @version 1.0*/
object ScalaDemo04 {def main(args: Array[String]): Unit = {val appName = "map"// spark基础配置// val conf = new SparkConf().setAppName(appName).setMaster("local")val conf = new SparkConf().setAppName(appName)// 本地运行conf.setMaster("local")// 构建 SparkContext spark 上下文val sparkContext = new SparkContext(conf)// 数据集val data = Array(1, 2, 3, 4, 5)val rdd = sparkContext.parallelize(data)val rs = rdd.map(_ * 2)rs.foreach(println(_))}
}运行结果:
2
4
6
8
10flatMap
javacode
package cn.lihaozhe.chap02;import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;import java.util.Arrays;
import java.util.Iterator;
import java.util.List;/*** flatMap 算子** @author 李昊哲* @version 1.0*/
public class JavaDemo05 {public static void main(String[] args) {String appName = "flatMap";// SparkConf conf = new SparkConf().setAppName(appName).setMaster("local");// spark基础配置SparkConf conf = new SparkConf().setAppName(appName);// 本地运行conf.setMaster("local");try (JavaSparkContext sparkContext = new JavaSparkContext(conf)) {// 数据集List<String> data = Arrays.asList("hadoop hive presto", "hbase phoenix", "spark flink");// 从集合中创建RDDJavaRDD<String> javaRDD = sparkContext.parallelize(data);// ["hadoop hive presto hbase phoenix spark flink"]// JavaRDD<String> wordsRdd = javaRDD.flatMap(new FlatMapFunction<String, String>() {// @Override// public Iterator<String> call(String s) throws Exception {// String[] words = s.split(" ");// return Arrays.asList(words).iterator();// }// });JavaRDD<String> wordsRdd = javaRDD.flatMap((FlatMapFunction<String, String>) line -> Arrays.asList(line.split(" ")).listIterator());List<String> words = wordsRdd.collect();words.forEach(System.out::println);}}
}scalacode
package cn.lihaozhe.chap02import org.apache.spark.{SparkConf, SparkContext}/*** flatMap 算子** @author 李昊哲* @version 1.0*/
object ScalaDemo05 {def main(args: Array[String]): Unit = {val appName = "flatMap"// spark基础配置// val conf = new SparkConf().setAppName(appName).setMaster("local")val conf = new SparkConf().setAppName(appName)// 本地运行conf.setMaster("local")// 构建 SparkContext spark 上下文val sparkContext = new SparkContext(conf)// 数据集val data = Array("hadoop hive presto", "hbase phoenix", "spark flink")// ("hadoop","hive","presto","hbase","phoenix","spark","flink")val rs = data.flatMap(_.split(" "))rs.foreach(println(_))}
}运行结果:
hadoop
hive
presto
hbase
phoenix
spark
flinkfilter
javacode
package cn.lihaozhe.chap02;import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;import java.util.Arrays;
import java.util.List;/*** filter 算子** @author 李昊哲* @version 1.0*/
public class JavaDemo06 {public static void main(String[] args) {String appName = "filter";// SparkConf conf = new SparkConf().setAppName(appName).setMaster("local");// spark基础配置SparkConf conf = new SparkConf().setAppName(appName);// 本地运行conf.setMaster("local");try (JavaSparkContext sparkContext = new JavaSparkContext(conf)) {// 数据集List<Integer> data = Arrays.asList(0, 1, 2, 3, 4, 5, 6, 7, 8, 9);// 从集合中创建RDDJavaRDD<Integer> javaRDD = sparkContext.parallelize(data);JavaRDD<Integer> evenRDD = javaRDD.filter(num -> num % 2 == 0);List<Integer> evenList = evenRDD.collect();evenList.forEach(System.out::println);}}
}scalacode
package cn.lihaozhe.chap02import org.apache.spark.{SparkConf, SparkContext}/*** filter 算子** @author 李昊哲* @version 1.0*/
object ScalaDemo06 {def main(args: Array[String]): Unit = {val appName = "filter"// spark基础配置// val conf = new SparkConf().setAppName(appName).setMaster("local")val conf = new SparkConf().setAppName(appName)// 本地运行conf.setMaster("local")// 构建 SparkContext spark 上下文val sparkContext = new SparkContext(conf)// 数据集val data = Array(0, 1, 2, 3, 4, 5, 6, 7, 8, 9)val rdd = sparkContext.parallelize(data)val evenRdd = rdd.filter(_ % 2 == 0)evenRdd.foreach(println(_))}
}运行结果:
0
2
4
6
8groupByKey
javacode
package cn.lihaozhe.chap02;import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;import java.util.List;/*** groupByKey 算子** @author 李昊哲* @version 1.0*/
public class JavaDemo07 {public static void main(String[] args) {// SparkConf conf = new SparkConf().setAppName("RDD").setMaster("local");// spark基础配置SparkConf conf = new SparkConf().setAppName("groupByKey");// 本地运行conf.setMaster("local");try (JavaSparkContext sparkContext = new JavaSparkContext(conf)) {// 使用本地文件系统构建数据集JavaRDD<String> javaRDD = sparkContext.textFile("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/data.csv");// javaRDD.mapToPair(new PairFunction<String, String, Integer>() {// @Override// public Tuple2<String, Integer> call(String s) throws Exception {// String[] words = s.split(",");// return new Tuple2<String, Integer>(words[0], Integer.parseInt(words[1]));// }//});JavaPairRDD<String, Integer> javaPairRDD = javaRDD.mapToPair((PairFunction<String, String, Integer>) word -> {// [person3,137]String[] words = word.split(",");return new Tuple2<String, Integer>(words[0], Integer.parseInt(words[1]));});JavaPairRDD<String, Iterable<Integer>> groupRDD = javaPairRDD.groupByKey();List<Tuple2<String, Iterable<Integer>>> collect = groupRDD.collect();collect.forEach(tup -> {// 获取keySystem.out.print(tup._1 + " >>> (");// 获取valuetup._2.forEach(num -> System.out.print(num + ","));System.out.println("\b)");});}}
}
scalacode
package cn.lihaozhe.chap02import org.apache.spark.{SparkConf, SparkContext}/*** groupByKey 算子** @author 李昊哲* @version 1.0*/
object ScalaDemo07 {def main(args: Array[String]): Unit = {// val conf = new SparkConf().setAppName("RDD").setMaster("local")// spark基础配置val conf = new SparkConf().setAppName("groupByKey")// 本地运行conf.setMaster("local")val sparkContext = new SparkContext(conf)// 使用本地文件系统构建数据集val data = sparkContext.textFile("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/data.csv")val tupleData = data.map(line => (line.split(",")(0), line.split(",")(1)))// (person1,Seq(197, 38, 12, 114, 91, 182, 29, 2, 100, 99, 137, 56))val groupData = tupleData.groupByKey()groupData.foreach(println(_))}
}reduceByKey
javacode
package cn.lihaozhe.chap02;import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Function;
import scala.Tuple2;import java.util.List;/*** reduceByKey 算子** @author 李昊哲* @version 1.0*/
public class JavaDemo08 {public static void main(String[] args) {// SparkConf conf = new SparkConf().setAppName("RDD").setMaster("local");// spark基础配置SparkConf conf = new SparkConf().setAppName("reduceByKey");// 本地运行conf.setMaster("local");try (JavaSparkContext sparkContext = new JavaSparkContext(conf)) {// 使用本地文件系统构建数据集JavaRDD<String> javaRDD = sparkContext.textFile("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/data.csv");// javaRDD.mapToPair(new PairFunction<String, String, Integer>() {// @Override// public Tuple2<String, Integer> call(String s) throws Exception {// String[] words = s.split(",");// return new Tuple2<String, Integer>(words[0], Integer.parseInt(words[1]));// }//});JavaPairRDD<String, Integer> javaPairRDD = javaRDD.mapToPair((PairFunction<String, String, Integer>) word -> {// [person3,137]String[] words = word.split(",");return new Tuple2<String, Integer>(words[0], Integer.parseInt(words[1]));});JavaPairRDD<String, Integer> reduceRDD = javaPairRDD.reduceByKey((Function2<Integer, Integer, Integer>) Integer::sum);List<Tuple2<String, Integer>> collect = reduceRDD.collect();collect.forEach(tup -> System.out.println(tup._1 + " >>> " + tup._2));}}
}
scalacode
package cn.lihaozhe.chap02import org.apache.spark.{SparkConf, SparkContext}/*** reduceByKey 算子** @author 李昊哲* @version 1.0*/
object ScalaDemo08 {def main(args: Array[String]): Unit = {// val conf = new SparkConf().setAppName("RDD").setMaster("local")// spark基础配置val conf = new SparkConf().setAppName("reduceByKey")// 本地运行conf.setMaster("local")val sparkContext = new SparkContext(conf)// 使用本地文件系统构建数据集val data = sparkContext.textFile("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/data.csv")val tupleData = data.map(line => (line.split(",")(0), line.split(",")(1).toInt))// (person1,Seq(197, 38, 12, 114, 91, 182, 29, 2, 100, 99, 137, 56))val groupData = tupleData.reduceByKey(_ + _)groupData.foreach(println(_))}
}mapValues
javacode
package cn.lihaozhe.chap02;import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;import java.util.*;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.stream.Collectors;/*** mapValues 算子* 引入数据文件 data.csv 第一列为姓名 第二列为每次消费的订单金额 析客单价** @author 李昊哲* @version 1.0*/
public class JavaDemo09 {public static void main(String[] args) {// SparkConf conf = new SparkConf().setAppName("RDD").setMaster("local");// spark基础配置SparkConf conf = new SparkConf().setAppName("mapValues");// 本地运行conf.setMaster("local");try (JavaSparkContext sparkContext = new JavaSparkContext(conf)) {// 使用本地文件系统构建数据集JavaRDD<String> javaRDD = sparkContext.textFile("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/data.csv");// javaRDD.mapToPair(new PairFunction<String, String, Integer>() {// @Override// public Tuple2<String, Integer> call(String s) throws Exception {// String[] words = s.split(",");// return new Tuple2<String, Integer>(words[0], Integer.parseInt(words[1]));// }//});JavaPairRDD<String, Integer> javaPairRDD = javaRDD.mapToPair((PairFunction<String, String, Integer>) word -> {// [person3,137]String[] words = word.split(",");return new Tuple2<String, Integer>(words[0], Integer.parseInt(words[1]));});JavaPairRDD<String, Iterable<Integer>> groupRDD = javaPairRDD.groupByKey();JavaPairRDD<String, Double> avgRDD = groupRDD.mapValues(v -> {int sum = 0;Iterator<Integer> it = v.iterator();AtomicInteger atomicInteger = new AtomicInteger();while (it.hasNext()) {Integer amount = it.next();sum += amount;atomicInteger.incrementAndGet();}return (double) sum / atomicInteger.get();});List<Tuple2<String, Double>> collect = avgRDD.collect();collect.forEach(tup -> System.out.println(tup._1 + " >>> " + (double) Math.round(tup._2 * 100) / 100));
// Map<String, List<Tuple2<String, Integer>>> listMap = javaPairRDD.collect().stream().collect(Collectors.groupingBy(tup -> tup._1));
// Set<Map.Entry<String, List<Tuple2<String, Integer>>>> entries = listMap.entrySet();
// Iterator<Map.Entry<String, List<Tuple2<String, Integer>>>> it = entries.iterator();
// Map<String, Double> map = new HashMap<>();
// while (it.hasNext()) {
// Map.Entry<String, List<Tuple2<String, Integer>>> entry = it.next();
// Integer sum = entry.getValue().stream().map(tup -> tup._2).reduce(Integer::sum).orElse(0);
// long count = entry.getValue().stream().map(tup -> tup._2).count();
//
// map.put(entry.getKey(), Double.valueOf(sum) / count);
// }
// map.forEach((name, amount) -> System.out.println(name + " >>> " + amount));}}
}
scalacode
package cn.lihaozhe.chap02import org.apache.spark.{SparkConf, SparkContext}/*** groupByKey 算子** @author 李昊哲* @version 1.0*/
object ScalaDemo09 {def main(args: Array[String]): Unit = {// val conf = new SparkConf().setAppName("RDD").setMaster("local")// spark基础配置val conf = new SparkConf().setAppName("mapValues")// 本地运行conf.setMaster("local")val sparkContext = new SparkContext(conf)// 使用本地文件系统构建数据集val data = sparkContext.textFile("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/data.csv")val tupleData = data.map(line => (line.split(",")(0), line.split(",")(1).toInt))// (person1,Seq(197, 38, 12, 114, 91, 182, 29, 2, 100, 99, 137, 56))val groupData = tupleData.groupByKey()// groupData.foreach(println(_))val avgData = groupData.mapValues(v => (v.sum.toDouble / v.size).formatted("%.2f"))avgData.foreach(println(_))}
}
sortByKey
javacode
package cn.lihaozhe.chap02;import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;import java.util.List;/*** sortByKey reduceByKey 算子* 引入数据文件 data.csv 第一列为姓名 第二列为每次消费的订单金额 分析每个人消费的金额数据汇总** @author 李昊哲* @version 1.0*/
public class JavaDemo10 {public static void main(String[] args) {// SparkConf conf = new SparkConf().setAppName("RDD").setMaster("local");// spark基础配置SparkConf conf = new SparkConf().setAppName("sortByKey");// 本地运行conf.setMaster("local");try (JavaSparkContext sparkContext = new JavaSparkContext(conf)) {// 使用本地文件系统构建数据集JavaRDD<String> javaRDD = sparkContext.textFile("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/data.csv");// javaRDD.mapToPair(new PairFunction<String, String, Integer>() {// @Override// public Tuple2<String, Integer> call(String s) throws Exception {// String[] words = s.split(",");// return new Tuple2<String, Integer>(words[0], Integer.parseInt(words[1]));// }//});JavaPairRDD<String, Integer> javaPairRDD = javaRDD.mapToPair((PairFunction<String, String, Integer>) word -> {// [person3,137]String[] words = word.split(",");return new Tuple2<String, Integer>(words[0], Integer.parseInt(words[1]));});JavaPairRDD<String, Integer> reduceRDD = javaPairRDD.reduceByKey((Function2<Integer, Integer, Integer>) Integer::sum);// 参数 true为升序 false为降序 默认为升序JavaPairRDD<String, Integer> sortedRDD = reduceRDD.sortByKey(false);List<Tuple2<String, Integer>> collect = sortedRDD.collect();collect.forEach(tup -> System.out.println(tup._1 + " >>> " + tup._2));}}
}
scalacode
package cn.lihaozhe.chap02import org.apache.spark.{SparkConf, SparkContext}/*** sortByKey reduceByKey 算子* 引入数据文件 data.csv 第一列为姓名 第二列为每次消费的订单金额 分析客总金额** @author 李昊哲* @version 1.0*/
object ScalaDemo10 {def main(args: Array[String]): Unit = {// val conf = new SparkConf().setAppName("RDD").setMaster("local")// spark基础配置val conf = new SparkConf().setAppName("sortByKey")// 本地运行conf.setMaster("local")val sparkContext = new SparkContext(conf)// 使用本地文件系统构建数据集val data = sparkContext.textFile("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/data.csv")val tupleData = data.map(line => (line.split(",")(0), line.split(",")(1).toInt))// (person1,Seq(197, 38, 12, 114, 91, 182, 29, 2, 100, 99, 137, 56))val groupData = tupleData.reduceByKey(_ + _)val swapData = groupData.map(_.swap)// 参数 true为升序 false为降序 默认为升序val sortData = swapData.sortByKey(ascending = false)val result = sortData.map(_.swap)result.foreach(println(_))}
}
sortBy
package cn.lihaozhe.chap02import org.apache.spark.{SparkConf, SparkContext}/*** sortBy reduceByKey 算子* 引入数据文件 data.csv 第一列为姓名 第二列为每次消费的订单金额 分析客总金额** @author 李昊哲* @version 1.0*/
object ScalaDemo11 {def main(args: Array[String]): Unit = {// val conf = new SparkConf().setAppName("RDD").setMaster("local")// spark基础配置val conf = new SparkConf().setAppName("sortBy")// 本地运行conf.setMaster("local")val sparkContext = new SparkContext(conf)// 使用本地文件系统构建数据集val data = sparkContext.textFile("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/data.csv")val tupleData = data.map(line => (line.split(",")(0), line.split(",")(1).toInt))// (person1,1057)val groupData = tupleData.reduceByKey(_ + _)// 参数 true为升序 false为降序 默认为升序val sortedData = groupData.sortBy(_._2, ascending = false)sortedData.foreach(println(_))}
}join
package cn.lihaozhe.chap02import org.apache.spark.{SparkConf, SparkContext}/*** join 算子** @author 李昊哲* @version 1.0*/
object ScalaDemo12 {def main(args: Array[String]): Unit = {// val conf = new SparkConf().setAppName("RDD").setMaster("local")// spark基础配置val conf = new SparkConf().setAppName("join")// 本地运行conf.setMaster("local")val sparkContext = new SparkContext(conf)// 使用本地文件系统构建数据集val data = sparkContext.textFile("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/data.csv")val tupleData = data.map(line => (line.split(",")(0), line.split(",")(1).toInt))val groupData = tupleData.groupByKey()// 姓名 评价消费金额val avgData = groupData.mapValues(v => (v.sum.toDouble / v.size).formatted("%.2f"))// 姓名 消费总金额val sumData = tupleData.reduceByKey(_ + _)// 相当于表连接val rsData = sumData.join(avgData)rsData.foreach(println(_))}
}运行结果:
(person1,(1057,88.08))
(person9,(2722,113.42))
(person6,(2634,105.36))
(person0,(1824,101.33))
(person2,(1296,99.69))
(person3,(2277,91.08))
(person7,(2488,99.52))
(person4,(2271,113.55))
(person5,(2409,114.71))
(person8,(1481,87.12))
WordCount
JavaWordCount
package cn.lihaozhe.chap03;import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;import java.util.Arrays;/*** @author 李昊哲* @version 1.0* @create 2023-12-12*/
public class JavaWordCount {public static void main(String[] args) {System.setProperty("HADOOP_USER_NAME", "root");String appName = "JavaWordCount";SparkConf conf = new SparkConf().setAppName(appName);try (JavaSparkContext sparkContext = new JavaSparkContext(conf)) {JavaRDD<String> javaRDD = sparkContext.textFile("/data/word.txt");JavaRDD<String> wordRdd = javaRDD.flatMap((FlatMapFunction<String, String>) line -> Arrays.asList(line.split(" ")).listIterator());JavaPairRDD<String, Integer> javaPairRDD = wordRdd.mapToPair((PairFunction<String, String, Integer>) word -> new Tuple2<>(word, 1));JavaPairRDD<String, Integer> rs = javaPairRDD.reduceByKey((Function2<Integer, Integer, Integer>) Integer::sum);rs.saveAsTextFile("/data/result");}}
}ScalaWordCount
package cn.lihaozhe.chap03import org.apache.spark.{SparkConf, SparkContext}/*** @author 李昊哲* @version 1.0*/
object ScalaWordCount01 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val conf = new SparkConf().setAppName("ScalaWordCount01")val sparkContext = new SparkContext(conf)val content = sparkContext.textFile("/data/word.txt")val words = content.flatMap(_.split(" "))val wordGroup = words.groupBy(word => word)val wordCount = wordGroup.mapValues(_.size)wordCount.saveAsTextFile("/data/result")}
}package cn.lihaozhe.chap03import org.apache.spark.{SparkConf, SparkContext}/*** @author 李昊哲* @version 1.0*/
object ScalaWordCount02 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val conf = new SparkConf().setAppName("ScalaWordCount02")val sparkContext = new SparkContext(conf)val content = sparkContext.textFile("/data/word.txt")val words = content.flatMap(_.split(" "))val wordMap = words.map((_, 1))val wordGroup = wordMap.reduceByKey(_ + _)wordGroup.saveAsTextFile("/data/result")}
}项目打包发布
mvn package
上传jar文件到集群
在集群上提交
spark-submit --master yarn --class cn.lihaozhe.chap02.JavaWordCount spark-code.jar
spark-submit --master yarn --class cn.lihaozhe.chap03.ScalaWordCount01 spark-code.jar
spark-submit --master yarn --class cn.lihaozhe.chap03.ScalaWordCount02 spark-code.jar
SparkSQL
在SparkCore中需要创建上下文环境SparkContext
SparkSql对SparkCore的封装, 不仅仅是功能上的封装,上下文件环境也封装了老版本中称为 SQLContext 用于Spark自己的查询 和 HiveContext 用于Hive连接的查询新版本中称为 SparkSession 是 SQLContext 和 HiveContext的组成 , 所以他们的API是通用的同时 SparkSession也可以直接获取到SparkContext对象
DataFrame
是一种基于RDD的分布式数据集, 与RDD的区别在于DataFrame中有数据的原信息,
可以理解为传统数据库中的一张二维表格,每一列都有列名和类型
DataSet
是分布式数据集,对DataFrame的一个扩展,相当于传统JDBC中的ResultSet
RDD 数据
DataFrame 数据+结构
DataSet 数据+结构+数据类型
DataFrame
构建 DataFrame
package cn.lihaozhe.chap04import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession/*** 构建 dataFrame** @author 李昊哲* @version 1.0*/
object ScalaDemo01 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf()if (!sparkConf.contains("spark.master")) {sparkConf.setMaster("local")}val sparkSession = SparkSession.builder().appName("Spark SQL basic example").config(sparkConf).getOrCreate()// 隐式转换import sparkSession.implicits._// 读取 csv 文件获取 dataFrameval df = sparkSession.read.csv("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/data.csv")// root// |-- _c0: string (nullable = true)// |-- _c1: string (nullable = true)df.printSchema()sparkSession.stop()}
}运行结果:
root|-- _c0: string (nullable = true)|-- _c1: string (nullable = true)
show
package cn.lihaozhe.chap04import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession/*** show** @author 李昊哲* @version 1.0*/
object ScalaDemo02 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf()if (!sparkConf.contains("spark.master")) {sparkConf.setMaster("local")}val sparkSession = SparkSession.builder().appName("Spark SQL basic example").config(sparkConf).getOrCreate()// 隐式转换import sparkSession.implicits._// 读取 csv 文件获取 dataFrameval df = sparkSession.read.csv("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/data.csv")df.printSchema()df.show(5, truncate = false)sparkSession.stop()}
}运行结果:
root|-- _c0: string (nullable = true)|-- _c1: string (nullable = true)+-------+---+
|_c0 |_c1|
+-------+---+
|person3|137|
|person7|193|
|person7|78 |
|person0|170|
|person5|145|
+-------+---+
option
package cn.lihaozhe.chap04import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession/*** option 是否将第一行作为字段名 header 默认值为 false** @author 李昊哲* @version 1.0*/
object ScalaDemo03 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf()if (!sparkConf.contains("spark.master")) {sparkConf.setMaster("local")}val sparkSession = SparkSession.builder().appName("Spark SQL basic example").config(sparkConf).getOrCreate()// 隐式转换import sparkSession.implicits._// 读取 csv 文件获取 dataFrameval df = sparkSession.read.option("header", "true").csv("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/info.csv")// root// |-- name: string (nullable = true)// |-- amount: string (nullable = true)df.printSchema()df.show(5)sparkSession.stop()}
}运行结果:
root|-- name: string (nullable = true)|-- amount: string (nullable = true)+-------+------+
| name|amount|
+-------+------+
|person3| 137|
|person7| 193|
|person7| 78|
|person0| 170|
|person5| 145|
+-------+------+
select
package cn.lihaozhe.chap04import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession/*** select** @author 李昊哲* @version 1.0*/
object ScalaDemo04 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf()if (!sparkConf.contains("spark.master")) {sparkConf.setMaster("local")}val sparkSession = SparkSession.builder().appName("Spark SQL basic example").config(sparkConf).getOrCreate()// 隐式转换import sparkSession.implicits._// 读取 csv 文件获取 dataFrameval df = sparkSession.read.csv("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/data.csv")df.printSchema()val rs = df.select("_c0", "_c1")rs.show(5, truncate = false)sparkSession.stop()}
}运行结果:
root|-- _c0: string (nullable = true)|-- _c1: string (nullable = true)+-------+---+
|_c0 |_c1|
+-------+---+
|person3|137|
|person7|193|
|person7|78 |
|person0|170|
|person5|145|
+-------+---+
withColumnRenamed
package cn.lihaozhe.chap04import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession/*** withColumnRenamed** @author 李昊哲* @version 1.0*/
object ScalaDemo05 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf()if (!sparkConf.contains("spark.master")) {sparkConf.setMaster("local")}val sparkSession = SparkSession.builder().appName("Spark SQL basic example").config(sparkConf).getOrCreate()// 隐式转换import sparkSession.implicits._// 读取 csv 文件获取 dataFrameval df = sparkSession.read.csv("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/data.csv")val table = df.withColumnRenamed("_c0", "name").withColumnRenamed("_c1", "amount")table.printSchema()val rs = table.select("name", "amount")rs.show(5,truncate = false)sparkSession.stop()}
}运行结果:
root|-- name: string (nullable = true)|-- amount: string (nullable = true)+-------+------+
|name |amount|
+-------+------+
|person3|137 |
|person7|193 |
|person7|78 |
|person0|170 |
|person5|145 |
+-------+------+
cast
package cn.lihaozhe.chap04import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.col
import org.apache.spark.sql.types.{IntegerType, StringType}/*** cast** @author 李昊哲* @version 1.0*/
object ScalaDemo06 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf()if (!sparkConf.contains("spark.master")) {sparkConf.setMaster("local")}val sparkSession = SparkSession.builder().appName("Spark SQL basic example").config(sparkConf).getOrCreate()// 隐式转换import sparkSession.implicits._// 读取 csv 文件获取 dataFrameval df = sparkSession.read.csv("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/data.csv")val table = df.select(col("_c0").cast(StringType).as("name"),col("_c1").cast(IntegerType).as("amount"),)table.printSchema()val rs = table.select("name", "amount")rs.show(5, truncate = false)sparkSession.stop()}
}运行结果:
root|-- name: string (nullable = true)|-- amount: integer (nullable = true)+-------+------+
| name|amount|
+-------+------+
|person3| 137|
|person7| 193|
|person7| 78|
|person0| 170|
|person5| 145|
+-------+------+
show first foreach head take tail
package cn.lihaozhe.chap04import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession/*** show first foreach head take tail** @author 李昊哲* @version 1.0*/
object ScalaDemo07 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf()if (!sparkConf.contains("spark.master")) {sparkConf.setMaster("local")}val sparkSession = SparkSession.builder().appName("Spark SQL basic example").config(sparkConf).getOrCreate()// 隐式转换import sparkSession.implicits._// 读取 csv 文件获取 dataFrameval df = sparkSession.read.option("header", "true").csv("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/info.csv")df.printSchema()// df.show(5, truncate = false)// df.foreach(println)// [name: string, amount: string]// println(df)// [person3,137]// println(df.first())// df.head(3).foreach(println)// df.take(3).foreach(println)df.tail(3).foreach(println)sparkSession.stop()}
}where
package cn.lihaozhe.chap04import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.col
import org.apache.spark.sql.types.{IntegerType, StringType}/*** where 按条件查询** @author 李昊哲* @version 1.0*/
object ScalaDemo08 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf()if (!sparkConf.contains("spark.master")) {sparkConf.setMaster("local")}val sparkSession = SparkSession.builder().appName("Spark SQL basic example").config(sparkConf).getOrCreate()// 隐式转换import sparkSession.implicits._// 读取 csv 文件获取 dataFrameval df = sparkSession.read.csv("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/data.csv")val table = df.select(col("_c0").cast(StringType).as("name"),col("_c1").cast(IntegerType).as("amount"),).where("amount > 100")table.foreach(println)sparkSession.stop()}
}package cn.lihaozhe.chap04import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.col
import org.apache.spark.sql.types.{IntegerType, StringType}/*** where 按条件查询** @author 李昊哲* @version 1.0*/
object ScalaDemo09 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf()if (!sparkConf.contains("spark.master")) {sparkConf.setMaster("local")}val sparkSession = SparkSession.builder().appName("Spark SQL basic example").config(sparkConf).getOrCreate()// 隐式转换import sparkSession.implicits._// 读取 csv 文件获取 dataFrameval df = sparkSession.read.csv("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/data.csv")val table = df.select(col("_c0").cast(StringType).as("name"),col("_c1").cast(IntegerType).as("amount"),).where(col("amount") > 100)table.foreach(println)sparkSession.stop()}
}filter
package cn.lihaozhe.chap04import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.col
import org.apache.spark.sql.types.{IntegerType, StringType}/*** filter 按条件查询** @author 李昊哲* @version 1.0*/
object ScalaDemo10 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf()if (!sparkConf.contains("spark.master")) {sparkConf.setMaster("local")}val sparkSession = SparkSession.builder().appName("Spark SQL basic example").config(sparkConf).getOrCreate()// 隐式转换import sparkSession.implicits._// 读取 csv 文件获取 dataFrameval df = sparkSession.read.csv("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/data.csv")val table = df.select(col("_c0").cast(StringType).as("name"),col("_c1").cast(IntegerType).as("amount"),).filter("amount > 100")table.foreach(println)sparkSession.stop()}
}package cn.lihaozhe.chap04import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.col
import org.apache.spark.sql.types.{IntegerType, StringType}/*** filter 按条件查询** @author 李昊哲* @version 1.0*/
object ScalaDemo11 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf()if (!sparkConf.contains("spark.master")) {sparkConf.setMaster("local")}val sparkSession = SparkSession.builder().appName("Spark SQL basic example").config(sparkConf).getOrCreate()// 隐式转换import sparkSession.implicits._// 读取 csv 文件获取 dataFrameval df = sparkSession.read.csv("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/data.csv")val table = df.select(col("_c0").cast(StringType).as("name"),col("_c1").cast(IntegerType).as("amount"),).filter(col("amount") > 100)table.foreach(println)sparkSession.stop()}
}groupBy
package cn.lihaozhe.chap04import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.col
import org.apache.spark.sql.types.{IntegerType, StringType}/*** group by** @author 李昊哲* @version 1.0*/
object ScalaDemo12 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf()if (!sparkConf.contains("spark.master")) {sparkConf.setMaster("local")}val sparkSession = SparkSession.builder().appName("Spark SQL basic example").config(sparkConf).getOrCreate()// 隐式转换import sparkSession.implicits._// 读取 csv 文件获取 dataFrameval df = sparkSession.read.csv("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/data.csv")val rs = df.select(col("_c0").cast(StringType).as("name"),col("_c1").cast(IntegerType).as("amount"),).groupBy("name").count().where("count > 20")rs.printSchema()rs.foreach(println)sparkSession.stop()}
}orderBy
package cn.lihaozhe.chap04import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.col
import org.apache.spark.sql.types.{IntegerType, StringType}/*** order by** @author 李昊哲* @version 1.0*/
object ScalaDemo13 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf()if (!sparkConf.contains("spark.master")) {sparkConf.setMaster("local")}val sparkSession = SparkSession.builder().appName("Spark SQL basic example").config(sparkConf).getOrCreate()// 隐式转换import sparkSession.implicits._// 读取 csv 文件获取 dataFrameval df = sparkSession.read.csv("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/data.csv")val rs = df.select(col("_c0").cast(StringType).as("name"),col("_c1").cast(IntegerType).as("amount"),).groupBy("name").count().where("count > 20").orderBy(col("count"), col("name"))rs.printSchema()rs.foreach(println)sparkSession.stop()}
}SQL
package cn.lihaozhe.chap04import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession/*** SQL** @author 李昊哲* @version 1.0*/
object ScalaDemo14 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf()if (!sparkConf.contains("spark.master")) {sparkConf.setMaster("local")}val sparkSession = SparkSession.builder().appName("Spark SQL basic example").config(sparkConf).getOrCreate()// 隐式转换import sparkSession.implicits._// 读取 csv 文件获取 dataFrameval df = sparkSession.read.csv("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/data.csv")// 使用 DataFrame 生成一张临时表df.createOrReplaceTempView("order_info")// 获取 SQLContext 对象// val sqlContext = sparkSession.sqlContext// val rs = sqlContext.sql("select _c0 as name,_c1 as amount from order_info where _c1 > 100")// 获取sql查询结果 dataFrameval rs = sparkSession.sql("select _c0 as name ,_c1 as mount from order_info where _c1 > 100")rs.foreach(println)sparkSession.stop()}
}DataSet
dataframe dataset
package cn.lihaozhe.chap05import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession/*** RDD DataFrame DataSet** @author 李昊哲* @version 1.0*/
object ScalaDemo01 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf()if (!sparkConf.contains("spark.master")) {sparkConf.setMaster("local")}val sparkSession = SparkSession.builder().appName("Spark SQL basic example").config(sparkConf).getOrCreate()// 隐式转换import sparkSession.implicits._// 读取 csv 文件获取 dataFrameval df = sparkSession.read.option("header", "true").csv("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/info.csv")// 将 dataFrame 转换成 dataSetval ds = df.as[OrderInfo]// ds.printSchema()// ds.foreach(println)// val rdd = df.rddval rdd = ds.map(orderInfo => (orderInfo.name, orderInfo.amount.toInt)).rddrdd.foreach(println)sparkSession.stop()}
}case class OrderInfo(name: String, amount: String)读取文件构建DataSet
package cn.lihaozhe.chap05import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession/*** DataFrame DataSet** @author 李昊哲* @version 1.0*/
object ScalaDemo02 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf()if (!sparkConf.contains("spark.master")) {sparkConf.setMaster("local")}val sparkSession = SparkSession.builder().appName("Spark SQL basic example").config(sparkConf).getOrCreate()// 隐式转换import sparkSession.implicits._// 读取 csv 文件获取 dataFrameval df = sparkSession.read.text("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/info.csv")// 读取 csv 文件获取 dataSetval ds = sparkSession.read.textFile("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/info.csv")sparkSession.stop()}
}RDD schema
package cn.lihaozhe.chap05import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession/*** 在字段较少的情况下 使用 反射 推导 出 RDD schema 信息** @author 李昊哲* @version 1.0*/
object ScalaDemo03 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf()if (!sparkConf.contains("spark.master")) {sparkConf.setMaster("local")}val sparkSession = SparkSession.builder().appName("Spark SQL basic example").config(sparkConf).getOrCreate()// 隐式转换import sparkSession.implicits._val ds = sparkSession.sparkContext.textFile("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/data.csv").map(_.split(",")).map(attributes => OrderSchema(attributes(0),attributes(1).toInt)).toDS()ds.printSchema()ds.foreach(println)sparkSession.stop()}
}case class OrderSchema(name: String, amount: Integer)StructType
package cn.lihaozhe.chap05import org.apache.spark.SparkConf
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SparkSession}/*** StructField** @author 李昊哲* @version 1.0*/
object ScalaDemo04 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf()if (!sparkConf.contains("spark.master")) {sparkConf.setMaster("local")}val sparkSession = SparkSession.builder().appName("Spark SQL basic example").config(sparkConf).getOrCreate()// 隐式转换import sparkSession.implicits._// 1、从原RDD的行中创建一个RDD;val rowRDD = sparkSession.sparkContext.textFile("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/data.csv").map(_.split(",")).map(attributes => Row(attributes(0), attributes(1).toInt))// 2、创建由 StructType 表示的模式,该模式与步骤1中创建的RDD中的Rows结构匹配。val structType = StructType(Array(StructField(name = "name", dataType = StringType, nullable = false),StructField(name = "amount", dataType = IntegerType, nullable = false)))// 3、通过 SparkSession 提供的 createDataFrame 方法将 schema 应用到 RDD 的行。val df = sparkSession.createDataFrame(rowRDD, structType)df.printSchema()df.foreach(println)sparkSession.stop()}
}package cn.lihaozhe.chap05import org.apache.spark.SparkConf
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SparkSession}/*** StructField** @author 李昊哲* @version 1.0*/
object ScalaDemo05 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf()if (!sparkConf.contains("spark.master")) {sparkConf.setMaster("local")}val sparkSession = SparkSession.builder().appName("Spark SQL basic example").config(sparkConf).getOrCreate()// 隐式转换import sparkSession.implicits._// 1、从原RDD的行中创建一个RDD;val rowRDD = sparkSession.sparkContext.textFile("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/data.csv").map(_.split(",")).map(attributes => Row(attributes(0), attributes(1)))// 2、创建由 StructType 表示的模式,该模式与步骤1中创建的RDD中的Rows结构匹配。// val schemaString = "name amount"// val fields = schemaString.split(" ").map(fieldName => StructField(name = fieldName, dataType = StringType, nullable = true))// val structType = StructType(fields)val structType = StructType("name amount".split(" ").map(fieldName => StructField(name = fieldName, dataType = StringType)))// 3、通过 SparkSession 提供的 createDataFrame 方法将 schema 应用到 RDD 的行。val df = sparkSession.createDataFrame(rowRDD, structType)df.printSchema()df.foreach(println)sparkSession.stop()}
}json
package cn.lihaozhe.chap05import org.apache.spark.SparkConf
import org.apache.spark.sql.{Encoders, SparkSession}/*** kryo** @author 李昊哲* @version 1.0*/
object ScalaDemo06 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf()if (!sparkConf.contains("spark.master")) {sparkConf.setMaster("local")}val sparkSession = SparkSession.builder().appName("Spark SQL basic example").config(sparkConf).getOrCreate()// 隐式转换import sparkSession.implicits._val ds = sparkSession.sparkContext.textFile("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/data.csv").map(_.split(",")).map(attributes => TbOrder(attributes(0), attributes(1).toInt)).toDS()// 创建临时表 order_infods.createOrReplaceTempView("order_info")// SQL查询后的结果集 dataFrameval df = sparkSession.sql("select name,amount from order_info where amount between 100 and 150")// df.foreach(println)// 通过下标方式取值df.map(temp => "{\"name\":" + temp(0) + ",\"amount\": " + temp(1) + "}").show(3, truncate = false)// 通过属性方式取值df.map(temp => "{\"name\":" + temp.getAs[String]("name") + ",\"amount\": " + temp.getAs[Int]("amount") + "}").show(3, truncate = false)// 将数据转为json格式字符串df.toJSON.show(3, truncate = false)// 一次读取一行数据并将数据封装到Map中implicit val mapEncoder = Encoders.kryo[Map[String, Any]]val array = df.map(teenager => teenager.getValuesMap[Any](List("name", "amount"))).collect()array.foreach(println)sparkSession.stop()}
}case class TbOrder(name: String, amount: Integer)格式转换
parquet
package cn.lihaozhe.chap06import org.apache.spark.SparkConf
import org.apache.spark.sql.{SaveMode, SparkSession}/*** parquet** @author 李昊哲* @version 1.0* @create 2023-12-12 */
object ScalaDemo01 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf()if (!sparkConf.contains("spark.master")) {sparkConf.setMaster("local")}val sparkSession = SparkSession.builder().appName("Spark SQL basic example").config(sparkConf).getOrCreate()// 隐式转换import sparkSession.implicits._// 读取 csv 文件获取 dataFrameval df = sparkSession.read.option("header", "true").format("csv").load("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/info.csv")df.select("name", "amount").write.mode(SaveMode.Overwrite).format("parquet").save("/data/spark/parquet")sparkSession.stop()}
}case class OrderInfo(name: String, amount: String)json
package cn.lihaozhe.chap06import org.apache.spark.SparkConf
import org.apache.spark.sql.{SaveMode, SparkSession}/*** json** @author 李昊哲* @version 1.0*/
object ScalaDemo02 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf()if (!sparkConf.contains("spark.master")) {sparkConf.setMaster("local")}val sparkSession = SparkSession.builder().appName("Spark SQL basic example").config(sparkConf).getOrCreate()// 隐式转换import sparkSession.implicits._// 读取 csv 文件获取 dataFrameval df = sparkSession.read.format("parquet").load("/data/spark/parquet")println(df.count())df.select("name", "amount").write.mode(SaveMode.Overwrite).format("json").save("/data/spark/json")sparkSession.stop()}
}JDBC
package cn.lihaozhe.chap07import org.apache.spark.SparkConf
import org.apache.spark.sql.{SaveMode, SparkSession}/*** jdbc** @author 李昊哲* @version 1.0*/
object ScalaDemo01 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf()if (!sparkConf.contains("spark.master")) {sparkConf.setMaster("local")}val sparkSession = SparkSession.builder().appName("Spark SQL JDBC example").config(sparkConf).getOrCreate()// 隐式转换import sparkSession.implicits._// 读取 csv 文件获取 dataFrameval df = sparkSession.read.format("jdbc").option("url", "jdbc:mysql://spark03").option("dbtable","knowledge.dujitang").option("user", "root").option("password", "Lihaozhe!!@@1122").load()println(df.count())sparkSession.stop()}
}
package cn.lihaozhe.chap07import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSessionimport java.util.Properties/*** jdbc** @author 李昊哲* @version 1.0*/
object ScalaDemo02 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf()if (!sparkConf.contains("spark.master")) {sparkConf.setMaster("local")}val sparkSession = SparkSession.builder().appName("Spark SQL JDBC example").config(sparkConf).getOrCreate()// 隐式转换import sparkSession.implicits._val url = "jdbc:mysql://spark03"val tableName = "knowledge.dujitang"val connectionProperties = new Properties()connectionProperties.put("user", "root")connectionProperties.put("password", "Lihaozhe!!@@1122")connectionProperties.put("customSchema", "id int,text string")// 读取 csv 文件获取 dataFrameval df = sparkSession.read.jdbc(url, tableName, connectionProperties)df.printSchema()println(df.count())sparkSession.stop()}
}package cn.lihaozhe.chap07import org.apache.spark.SparkConf
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SaveMode, SparkSession}import java.util.Properties/*** jdbc** @author 李昊哲* @version 1.0*/
object ScalaDemo04 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf()if (!sparkConf.contains("spark.master")) {sparkConf.setMaster("local")}val sparkSession = SparkSession.builder().appName("Spark SQL JDBC example").config(sparkConf).getOrCreate()// 隐式转换// 1、从原RDD的行中创建一个RDD;val rowRDD = sparkSession.sparkContext.textFile("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/data.csv").map(_.split(",")).map(attributes => Row(attributes(0), attributes(1).toInt))// 2、创建由 StructType 表示的模式,该模式与步骤1中创建的RDD中的Rows结构匹配。val structType = StructType(Array(StructField(name = "name", dataType = StringType, nullable = true),StructField(name = "amount", dataType = IntegerType, nullable = true)))// 3、通过 SparkSession 提供的 createDataFrame 方法将 schema 应用到 RDD 的行。val df = sparkSession.createDataFrame(rowRDD, structType)val url = "jdbc:mysql://spark03"val tableName = "lihaozhe.data"val connectionProperties = new Properties()connectionProperties.put("user", "root")connectionProperties.put("password", "Lihaozhe!!@@1122")df.write.mode(SaveMode.Overwrite).jdbc(url, tableName, connectionProperties)sparkSession.stop()}
}package cn.lihaozhe.chap07import org.apache.spark.SparkConf
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SaveMode, SparkSession}import java.util.Properties/*** jdbc** @author 李昊哲* @version 1.0*/
object ScalaDemo05 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf()if (!sparkConf.contains("spark.master")) {sparkConf.setMaster("local")}val sparkSession = SparkSession.builder().appName("Spark SQL JDBC example").config(sparkConf).getOrCreate()// 隐式转换// 1、从原RDD的行中创建一个RDD;val rowRDD = sparkSession.sparkContext.textFile("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/data.csv").map(_.split(",")).map(attributes => Row(attributes(0), attributes(1).toInt))// 2、创建由 StructType 表示的模式,该模式与步骤1中创建的RDD中的Rows结构匹配。val structType = StructType(Array(StructField(name = "name", dataType = StringType, nullable = true),StructField(name = "amount", dataType = IntegerType, nullable = true)))// 3、通过 SparkSession 提供的 createDataFrame 方法将 schema 应用到 RDD 的行。val df = sparkSession.createDataFrame(rowRDD, structType)val url = "jdbc:mysql://spark03"val tableName = "lihaozhe.data"val connectionProperties = new Properties()connectionProperties.put("user", "root")connectionProperties.put("password", "Lihaozhe!!@@1122")connectionProperties.put("createTableColumnTypes", "name varchar(50)")df.write.mode(SaveMode.Overwrite).jdbc(url, tableName, connectionProperties)sparkSession.stop()}
}spark on hive
“Spark on Hive” 和 “Hive on Spark” 是两个不同的概念,它们分别描述了 Spark 和 Hive 之间的集成方式。
- Spark on Hive: “Spark on Hive” 指的是在 Spark 应用程序中使用 Hive 的元数据存储和查询引擎。在这种集成方式下,Spark 可以直接访问和操作 Hive 中的数据表,而不需要将数据复制到 Spark 的内存中。这种集成方式可以通过 Spark SQL 来实现,用户可以在 Spark 应用程序中使用 SQL 或 DataFrame API 来查询和操作 Hive 中的数据。
- Hive on Spark: “Hive on Spark” 指的是在 Hive 查询引擎中使用 Spark 作为计算引擎。在传统的 Hive 中,计算任务是由 MapReduce 来执行的,但是在一些情况下,用户希望使用 Spark 来代替 MapReduce 来执行 Hive 查询,以获得更好的性能和资源利用率。通过将 Spark 作为 Hive 的计算引擎,可以让用户在执行 Hive 查询时利用 Spark 的内存计算能力,从而提高查询性能。
总的来说,“Spark on Hive” 主要是指在 Spark 应用程序中使用 Hive 数据,而 “Hive on Spark” 主要是指在 Hive 查询引擎中使用 Spark 作为计算引擎。这两种集成方式都可以让用户更好地利用 Spark 和 Hive 的优势,根据具体的需求选择适合的集成方式。
package cn.lihaozhe.chap08import org.apache.spark.SparkConf
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SaveMode, SparkSession}import java.util.Properties/*** hive** @author 李昊哲* @version 1.0*/
object ScalaDemo01 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf()if (!sparkConf.contains("spark.master")) {sparkConf.setMaster("local")}val sparkSession = SparkSession.builder().appName("Spark SQL JDBC example").config(sparkConf).enableHiveSupport().getOrCreate()// 隐式转换import sparkSession.implicits._// 1、从原RDD的行中创建一个RDD;val rowRDD = sparkSession.sparkContext.textFile("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/data.csv").map(_.split(",")).map(attributes => Row(attributes(0), attributes(1).toInt))// 2、创建由 StructType 表示的模式,该模式与步骤1中创建的RDD中的Rows结构匹配。val structType = StructType(Array(StructField(name = "name", dataType = StringType, nullable = true),StructField(name = "amount", dataType = IntegerType, nullable = true)))// 3、通过 SparkSession 提供的 createDataFrame 方法将 schema 应用到 RDD 的行。val df = sparkSession.createDataFrame(rowRDD, structType)df.write.mode(SaveMode.Overwrite).saveAsTable("lihaozhe.order_info");sparkSession.stop()}
}package cn.lihaozhe.chap08import org.apache.spark.SparkConf
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SaveMode, SparkSession}/*** hive** @author 李昊哲* @version 1.0*/
object ScalaDemo02 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf()if (!sparkConf.contains("spark.master")) {sparkConf.setMaster("local")}val sparkSession = SparkSession.builder().appName("Spark SQL JDBC example").config(sparkConf).enableHiveSupport().getOrCreate()// 隐式转换// val orderDF = sparkSession.sql("select * from lihaozhe.order_info");import sparkSession.sqlval orderDF = sql("select * from lihaozhe.order_info");orderDF.foreach(info => println(info(0) + "\t" + info(1)))sparkSession.stop()}
}streaming
sparkstreaming
structedstreaming
结构化流处理是 Apache Spark 中用于处理实时数据流的一种方式,它具有许多优点和一些缺点,下面我将列举一些主要的优缺点:
优点:
-
高度集成:结构化流处理与 Spark 的其他组件(如 Spark SQL、DataFrame 等)高度集成,使得处理实时数据流变得更加简单和灵活。
-
容错性:结构化流处理具有容错性,能够在发生故障时自动恢复,保证数据处理的可靠性。
-
高性能:结构化流处理基于 Spark 引擎,具有优秀的性能和扩展性,能够处理大规模的实时数据流。
-
支持多种数据源:结构化流处理支持从多种数据源(如 Kafka、HDFS、文件系统等)读取数据,并且能够将处理结果写入到多种目标(如 Kafka、HDFS、文件系统、数据库等)。
-
SQL友好:结构化流处理提供了类似 SQL 的 API,使得处理实时数据流变得更加直观和易于理解。
缺点:
-
学习曲线:对于初学者来说,结构化流处理可能需要一定的学习成本,特别是对于理解流处理的概念和调优性能方面。
-
实时性限制:尽管结构化流处理能够处理实时数据流,但是由于批处理的特性,其实时性可能无法满足某些对实时性要求非常高的场景。
-
资源消耗:由于结构化流处理是基于 Spark 引擎的,因此可能需要大量的计算资源和内存资源来处理实时数据流。
总的来说,结构化流处理在处理实时数据流方面具有许多优点,但也需要根据具体的业务需求和场景来权衡其优缺点。
来代替 MapReduce 来执行 Hive 查询,以获得更好的性能和资源利用率。通过将 Spark 作为 Hive 的计算引擎,可以让用户在执行 Hive 查询时利用 Spark 的内存计算能力,从而提高查询性能。
总的来说,“Spark on Hive” 主要是指在 Spark 应用程序中使用 Hive 数据,而 “Hive on Spark” 主要是指在 Hive 查询引擎中使用 Spark 作为计算引擎。这两种集成方式都可以让用户更好地利用 Spark 和 Hive 的优势,根据具体的需求选择适合的集成方式。
package cn.lihaozhe.chap08import org.apache.spark.SparkConf
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SaveMode, SparkSession}import java.util.Properties/*** hive** @author 李昊哲* @version 1.0*/
object ScalaDemo01 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf()if (!sparkConf.contains("spark.master")) {sparkConf.setMaster("local")}val sparkSession = SparkSession.builder().appName("Spark SQL JDBC example").config(sparkConf).enableHiveSupport().getOrCreate()// 隐式转换import sparkSession.implicits._// 1、从原RDD的行中创建一个RDD;val rowRDD = sparkSession.sparkContext.textFile("file:///D:/work/河南师范大学/2023/bigdata2023/spark/code/spark-code/data.csv").map(_.split(",")).map(attributes => Row(attributes(0), attributes(1).toInt))// 2、创建由 StructType 表示的模式,该模式与步骤1中创建的RDD中的Rows结构匹配。val structType = StructType(Array(StructField(name = "name", dataType = StringType, nullable = true),StructField(name = "amount", dataType = IntegerType, nullable = true)))// 3、通过 SparkSession 提供的 createDataFrame 方法将 schema 应用到 RDD 的行。val df = sparkSession.createDataFrame(rowRDD, structType)df.write.mode(SaveMode.Overwrite).saveAsTable("lihaozhe.order_info");sparkSession.stop()}
}package cn.lihaozhe.chap08import org.apache.spark.SparkConf
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SaveMode, SparkSession}/*** hive** @author 李昊哲* @version 1.0*/
object ScalaDemo02 {def main(args: Array[String]): Unit = {System.setProperty("HADOOP_USER_NAME", "root")val sparkConf = new SparkConf()if (!sparkConf.contains("spark.master")) {sparkConf.setMaster("local")}val sparkSession = SparkSession.builder().appName("Spark SQL JDBC example").config(sparkConf).enableHiveSupport().getOrCreate()// 隐式转换// val orderDF = sparkSession.sql("select * from lihaozhe.order_info");import sparkSession.sqlval orderDF = sql("select * from lihaozhe.order_info");orderDF.foreach(info => println(info(0) + "\t" + info(1)))sparkSession.stop()}
}streaming
sparkstreaming
structedstreaming
结构化流处理是 Apache Spark 中用于处理实时数据流的一种方式,它具有许多优点和一些缺点,下面我将列举一些主要的优缺点:
优点:
-
高度集成:结构化流处理与 Spark 的其他组件(如 Spark SQL、DataFrame 等)高度集成,使得处理实时数据流变得更加简单和灵活。
-
容错性:结构化流处理具有容错性,能够在发生故障时自动恢复,保证数据处理的可靠性。
-
高性能:结构化流处理基于 Spark 引擎,具有优秀的性能和扩展性,能够处理大规模的实时数据流。
-
支持多种数据源:结构化流处理支持从多种数据源(如 Kafka、HDFS、文件系统等)读取数据,并且能够将处理结果写入到多种目标(如 Kafka、HDFS、文件系统、数据库等)。
-
SQL友好:结构化流处理提供了类似 SQL 的 API,使得处理实时数据流变得更加直观和易于理解。
缺点:
-
学习曲线:对于初学者来说,结构化流处理可能需要一定的学习成本,特别是对于理解流处理的概念和调优性能方面。
-
实时性限制:尽管结构化流处理能够处理实时数据流,但是由于批处理的特性,其实时性可能无法满足某些对实时性要求非常高的场景。
-
资源消耗:由于结构化流处理是基于 Spark 引擎的,因此可能需要大量的计算资源和内存资源来处理实时数据流。
总的来说,结构化流处理在处理实时数据流方面具有许多优点,但也需要根据具体的业务需求和场景来权衡其优缺点。
sparkstreaming
package cn.lihaozhe.chap09import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.{Seconds, StreamingContext}/*** spark streaming** @author 李昊哲* @version 1.0*/
object SparkStreamingExample {def main(args: Array[String]): Unit = {//1. 生成一个Dstreamval sparkConf: SparkConf = new SparkConf().setMaster("local[2]").setAppName("SparkStreamingExample")val streamingContext = new StreamingContext(sparkConf, Seconds(4))val dStream: ReceiverInputDStream[String] = streamingContext.socketTextStream("spark03", 9999)//2. 计算(wordcount)dStream.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).print()//3. 运行流程序streamingContext.start()streamingContext.awaitTermination()}
}structedstreaming
kafka
log4j.properties
log4j.rootLogger=error, stdout,R
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%5L) : %m%nlog4j.appender.R=org.apache.log4j.RollingFileAppender
log4j.appender.R.File=../log/agent.log
log4j.appender.R.MaxFileSize=1024KB
log4j.appender.R.MaxBackupIndex=1log4j.appender.R.layout=org.apache.log4j.PatternLayout
log4j.appender.R.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%6L) : %m%nKafkaConsumer
package cn.lihaozhe.chap10import java.util.Properties
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.kafka.common.serialization.StringSerializerobject SparkKafkaProducer {def main(args: Array[String]): Unit = {// 0 配置信息val properties = new Properties()properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"spark01:9092,spark02:9092,spark03:9092")properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,classOf[StringSerializer])properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,classOf[StringSerializer])// 1 创建一个生产者val producer = new KafkaProducer[String, String](properties)// 2 发送数据for (i <- 1 to 5) {producer.send(new ProducerRecord[String,String]("lihaozhe","lihaozhe"+i))}// 3 关闭资源producer.close()}}KafkaConsumer
package cn.lihaozhe.chap10import org.apache.spark.SparkConf
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}object SparkKafkaConsumer {def main(args: Array[String]): Unit = {// 1 初始化上下文环境val conf = new SparkConf().setMaster("local[*]").setAppName("spark-kafka")val ssc = new StreamingContext(conf, Seconds(3))// 2 消费数据val kafkapara = Map[String,Object](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG->"spark01:9092,spark02:9092,spark03:9092",ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG->classOf[StringDeserializer],ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG->classOf[StringDeserializer],ConsumerConfig.GROUP_ID_CONFIG->"test")val KafkaDSteam = KafkaUtils.createDirectStream(ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](Set("lihaozhe"), kafkapara))// key "" value "lihaozhe"val valueDStream = KafkaDSteam.map(record => record.value())valueDStream.print()// 3 执行代码 并阻塞ssc.start()ssc.awaitTermination()}}