大家好,这里是七七,这个专栏是用代码实例来学习的,不是去介绍很多知识的。
话不多说,开始今天的内容
目录
代码1
代码2
代码3
代码4
代码5
学习1的总代码
代码1
grouped=df.groupby('单品编码')
result={}grouped=df.groupby('单品编码')是对名为df的数据框按照列名为’单品编码’进行分组操作。这将返回一个GroupBy对象,该对象可以用于按照分组对数据进行聚合操作。
然后,result={}是创建一个空字典对象。
代码2
for name, group in groupedunique_months=group['月份'].unique()total_months=len(unique_months)season=[]season_list=[0]*4if 3 in unique_months or 4 in unique_months or 5 in unique_months:season.append("春季")season_list[0]=1if 6 in unique_months or 7 in unique_months or 8 in unique_months:season.append("夏季")season_list[1] = 1if 9 in unique_months or 10 in unique_months or 11 in unique_months:season.append("秋季")season_list[2] = 1if 12 in unique_months or 1 in unique_months or 2 in unique_months:season.append("冬季")season_list[3] = 1result[name]={'出现的月份':unique_months,'总共出现的月份数':total_months,'出现的季节':season,"季节数":len(season),"季节列表":season_list}这段代码是对`GroupBy`对象进行迭代,并针对每个分组进行操作,最终生成一个结果字典`result`,记录了每个分组的统计信息。
对于每个分组,首先通过`group['月份'].unique()`获取该分组下的"月份"列中的唯一值,并将其存储在`unique_months`中。接着,使用`len()`函数计算`unique_months`的长度,即该分组出现的不同月份总数,并将其存储在`total_months`中。
为了确定该分组出现的季节信息,定义了一个空的列表`season`和一个包含4个零元素的列表`season_list`。然后,通过判断`unique_months`中是否包含特定月份,来确定季节的出现情况。如果`unique_months`中出现了3、4或5月份,则将"春季"添加到`season`列表中,并将`season_list[0]`置为1。同样,对其他月份进行判断,分别将"夏季"、"秋季"和"冬季"添加到`season`列表中,并将相应的`season_list`元素置为1。
最后,将该分组的名称作为`result`字典的键,对应的结果作为值存储起来。结果字典的值包括:'出现的月份'、'总共出现的月份数'、'出现的季节'、'季节数'以及'季节列表'。这样,在每次迭代结束后,`result`字典就会记录了每个分组的统计信息。
通过这段代码,您可以获取每个分组出现的月份、总共出现的月份数以及该分组所处的季节信息,并将这些统计信息存储在结果字典中,以便后续分析和使用。
当对一个`GroupBy`对象进行迭代时,会返回一个由元组`(name, group)`组成的迭代器。其中,`name`表示分组的名称,`group`表示相应的分组数据。
具体迭代的过程如下:
1. 首先,根据指定的列对数据进行分组,生成`GroupBy`对象 `grouped`。
2. 使用`for name, group in grouped`语法,开始对`grouped`进行迭代。在每次迭代中,会将一个分组的名称赋值给`name`,将该分组的数据赋值给`group`。
3. 在每个迭代中,你可以通过`name`获取当前分组的唯一标识,可以通过`group`来进行该分组内的其他操作和处理。
4. 继续迭代,直到遍历完所有的分组。
总的来说,这个迭代过程允许您逐个访问每个分组,并对每个分组进行操作和分析,比如计算统计量、应用函数等。您可以根据实际需求在每次迭代中进行适当的处理。
输出结果:
代码3
count_all=0
count_all_list = []
for key, value in result.items():if value['季节数']==4:count_all+=1count_all_list.append(key)print(count_all)print(count_all_list)
result.items()返回一个字典中的所有键值对。这个方法把字典中的每一个键值对都转化为(键, 值)的元组,然后把这些元组放到一个迭代器中。
这段代码是在result字典中针对每个键值对进行操作,并统计符合条件的键值对的数量。
首先,定义了一个变量count_all和一个列表count_all_list。count_all记录包含4个季节的所有分组的数量,count_all_list记录符合条件的分组的名称。
然后,使用for key, value in result.items()语法,开始从result字典中逐个取出键和值,进行循环操作。在循环中,使用if value['季节数']==4的语法来判断当前字典的季节数是否为4,如果是,就将该分组的名称添加到count_all_list中,并将count_all自增1。
最后,通过print(count_all)和print(count_all_list)语句,将符合条件的分组数量和分组名称输出。
输出如下:
代码4
df['年份']=df['日期'].dt.year
result=df.groupby(['单品编码','年份']).agg({'日期':'nunique'}).reset_index()
result.rename(columns={'日期':'天数'},inplace=True)第一行就不介绍了,在python学习1-CSDN博客中已经介绍过
接下来,使用 `df.groupby(['单品编码','年份'])` 对数据框 `df` 进行分组操作,按照 '单品编码' 和 '年份' 进行分组。然后,通过 `.agg({'日期':'nunique'})` 对分组后的每个组进行聚合操作,对 '日期' 列应用 `nunique()` 函数,计算每个组中独特日期值的数量。这样,结果数据框 `result` 将包含 '单品编码'、'年份' 和 '日期'(记为 '天数')三个列。
最后,通过 `.reset_index()` 重置 `result` 数据框的索引,将多级索引还原为默认的整数索引。然后使用 `.rename(columns={'日期':'天数'}, inplace=True)` 的方式,将 '日期' 列的名称改为 '天数'。这样,`result` 数据框就得到了最终的结果。
通过以上的操作,您可以得到按照 '单品编码' 和 '年份' 进行分组的数据框 `result`,其中记录了每个组中独特日期值的数量。这个结果可以帮助您进行进一步的数据分析和处理。
.agg()是 pandas 库用于分组数据计算的方法,其可以用于对 DF 或者 Series 数据进行一些分组操作,并对分组后的数据进行需要的一些聚合处理。其中,{'日期':'nunique'}这个参数是.agg()中最重要的一部分。
{'日期':'nunique'}表示对于 ‘日期’ 这一列的数据,应用nunique()函数进行聚合,具体含义是,分组后统计每个组(例如每个商品以及每个年份)中独特日期值的数量,即去重后的独特日期值的数量。
nunique()函数用于计算一列数据中除去重复值之外的独特(唯一)值的数量,其语法格式为:Series.nunique(dropna=True),其中:
Series为要统计独特值的数据列;dropna表示是否排除空值,默认为 True,即排除空值。在上面的代码中,由于分组使用了 ‘单品编码’ 和 ‘年份’ 两个列,所以会对所有在同一年份中的同一种商品进行分组,统计该商品在该年份内销售的天数,最终将结果存储在 ‘天数’ 列中。
代码5
max_days=result.groupby('单品编码')['天数'].max().reset_index()
#print(max_days)
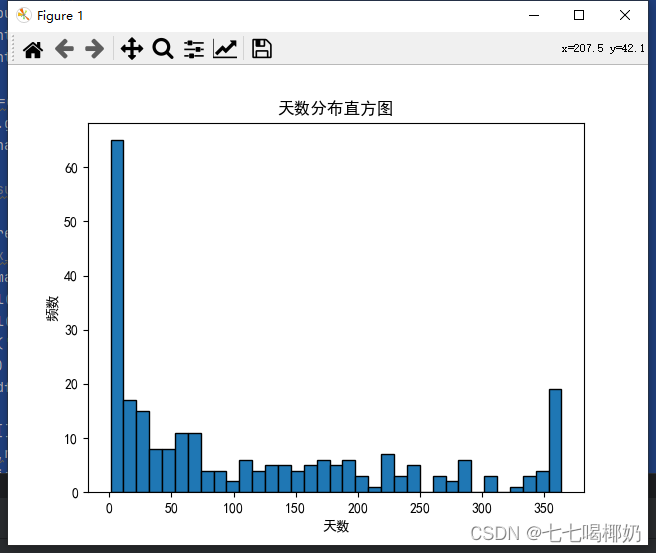
plt.hist(max_days['天数'],bins=35,edgecolor='k')
plt.xlabel('天数')
plt.ylabel('频数')
plt.title('天数分布直方图')
plt.show()
filtered_df=max_days[max_days['天数']<=15]
cnt=0
cnt_list=[]
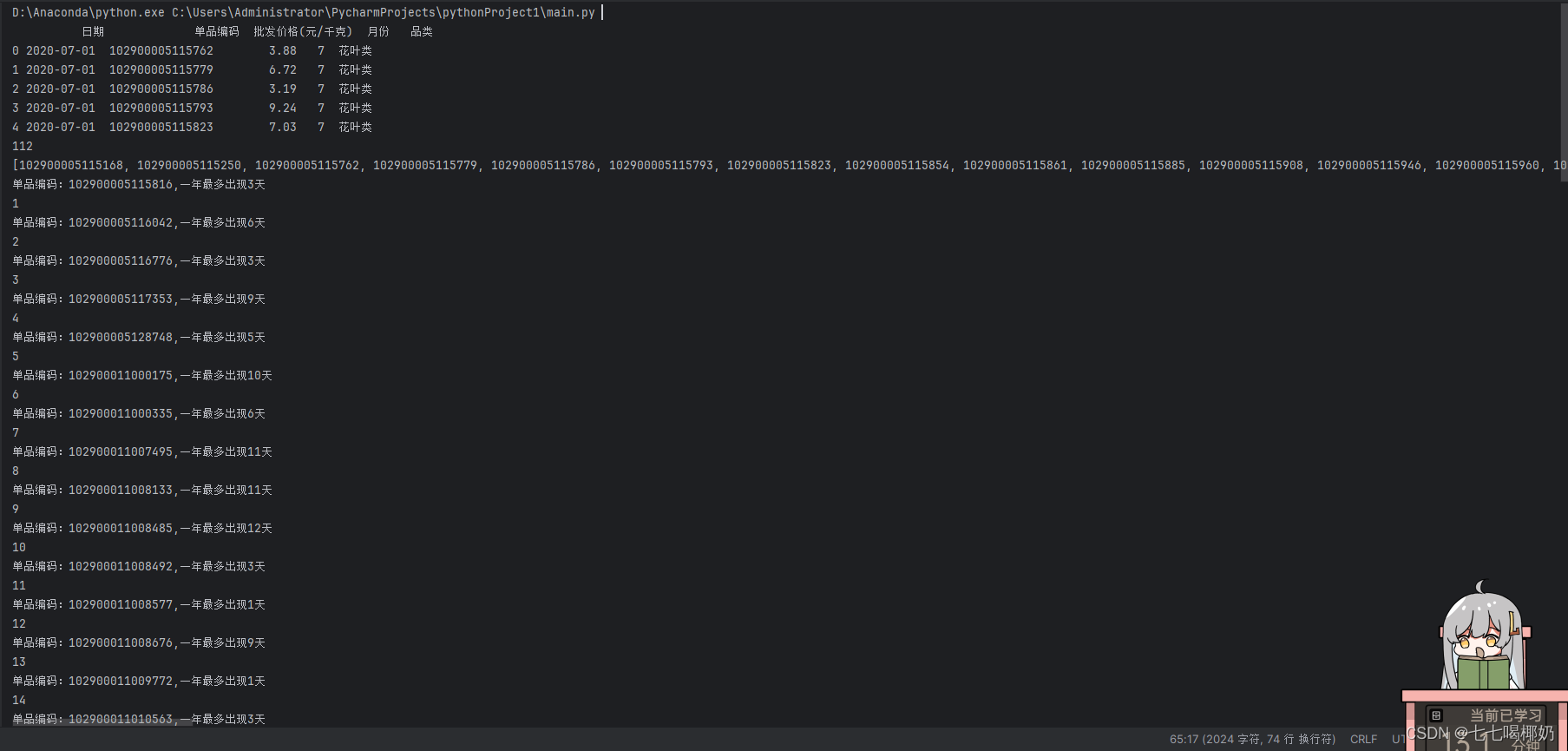
for index,row in filtered_df.iterrows():cnt_list.append(row['单品编码'])print(f"单品编码:{row['单品编码']},一年最多出现{row['天数']}天")cnt+=1print(cnt)这段代码的作用是,首先通过 `result` 数据框中的 '单品编码' 列和 '天数' 列计算出每个单品在最多的一年内销售的天数,并将结果保存在 `max_days` 数据框中;然后,绘制 `max_days` 数据框中 '天数' 列的频数分布直方图,以便进行天数分布的可视化;最后把最多销售天数小于等于 15 天的单品筛选出来,输出它们在其销售最多一年内的销售天数,并统计筛选出的单品数量。
具体解释如下:
`max_days=result.groupby('单品编码')['天数'].max().reset_index()`: 通过对 `result` 数据框按照 '单品编码' 列进行分组,对每组中的 '天数' 列求出最大值,表示该单品在最多的一年内销售的天数,从而得到结果数据框 `max_days`。
`plt.hist(max_days['天数'],bins=35,edgecolor='k')`: 使用 `plt.hist()` 可视化库,绘制直方图,并将 `max_days` 数据框中的 '天数' 列作为参数传入,以便绘制该列的分布图。`bins=35` 表示直方图的数量为 35,`edgecolor='k'` 表示直方图的边界颜色为黑色。
`plt.xlabel('天数')` 和 `plt.ylabel('频数')`: 分别指定直方图的横轴和纵轴的标签。
`plt.title('天数分布直方图')`: 指定直方图的标题。
`plt.show()`: 显示绘制出来的直方图。
`filtered_df=max_days[max_days['天数']<=15]`: 从 `max_days` 数据框中筛选出在最多销售天数小于等于 15 天的单品,将结果存储在 `filtered_df` 数据框中。
`cnt=0` 和 `cnt_list=[]`: 分别初始化计数器和空列表。
`for index,row in filtered_df.iterrows():`: 对 `filtered_df` 数据框进行遍历,依次读取每一行数据。
- `cnt_list.append(row['单品编码'])`:将当前行数据中的 '单品编码' 列的值加入到列表 `cnt_list` 中。
- `print(f"单品编码:{row['单品编码']},一年最多出现{row['天数']}天")`:输出当前行数据中的 '单品编码'和 '天数'列的值。
- `cnt+=1` 和 `print(cnt)`:对计数器进行累加操作,并输出当前筛选出的单品数量。
通过以上操作,可以将所有在其销售最多一年内销售天数小于等于15天的单品筛选出来,并将它们在最多销售天数的那一年内的销售天数打印出来,方便进行进一步的数据分析和处理。同时,直方图也可以让我们更加直观的了解不同单品销售天数的分布情况。
学习1的总代码
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=[u'simHei']
plt.rcParams['axes.unicode_minus']=Falsexlsx_file = 'data/附件1.xlsx'
df_1 = pd.read_excel(xlsx_file)xlsx_file = 'data/附件3.xlsx'
df = pd.read_excel(xlsx_file)df['日期']=pd.to_datetime(df['日期'])
df['月份']=df['日期'].dt.monthmapping_dict=df_1.set_index('单品编码')['分类名称'].to_dict()
df['品类']=df['单品编码'].map(mapping_dict)
print(df.head(5))grouped=df.groupby('单品编码')
result={}for name, group in grouped:unique_months=group['月份'].unique()total_months=len(unique_months)season=[]season_list=[0]*4if 3 in unique_months or 4 in unique_months or 5 in unique_months:season.append("春季")season_list[0]=1if 6 in unique_months or 7 in unique_months or 8 in unique_months:season.append("夏季")season_list[1] = 1if 9 in unique_months or 10 in unique_months or 11 in unique_months:season.append("秋季")season_list[2] = 1if 12 in unique_months or 1 in unique_months or 2 in unique_months:season.append("冬季")season_list[3] = 1result[name]={'出现的月份':unique_months,'总共出现的月份数':total_months,'出现的季节':season,"季节数":len(season),"季节列表":season_list}
count_all=0
count_all_list = []
for key, value in result.items():if value['季节数']==4:count_all+=1count_all_list.append(key)
print(count_all)
print(count_all_list)df['年份']=df['日期'].dt.year
result=df.groupby(['单品编码','年份']).agg({'日期':'nunique'}).reset_index()
result.rename(columns={'日期':'天数'},inplace=True)#print(result)max_days=result.groupby('单品编码')['天数'].max().reset_index()
#print(max_days)
plt.hist(max_days['天数'],bins=35,edgecolor='k')
plt.xlabel('天数')
plt.ylabel('频数')
plt.title('天数分布直方图')
plt.show()
filtered_df=max_days[max_days['天数']<=15]
cnt=0
cnt_list=[]
for index,row in filtered_df.iterrows():cnt_list.append(row['单品编码'])print(f"单品编码:{row['单品编码']},一年最多出现{row['天数']}天")cnt+=1print(cnt)这段代码只是将两个表格中的数据进行一系列的预处理,按照时间分类
总输出如下: