神经网络可以计算任何函数的可视化证明
对于神经网络,一个显著的事实就是它可以计算任何函数。
如下:不管该函数如何,总有神经网络能够对任何可能的输入x,输出值f(x)
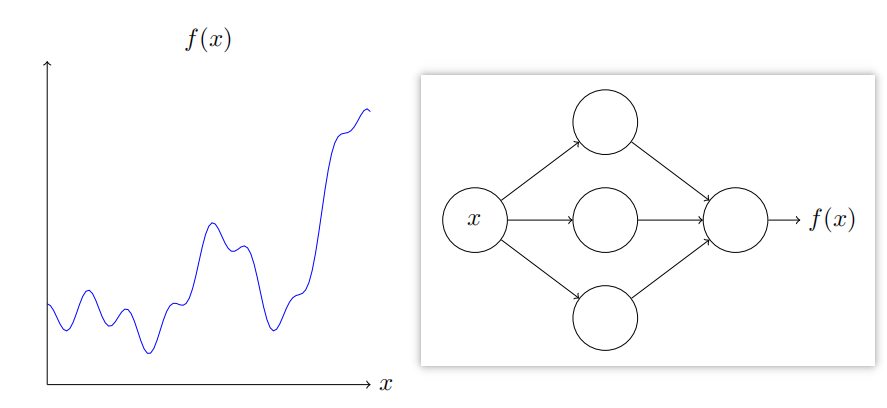
即使函数有很多输入和输出, f = f ( x 1 , ⋯ , x m ) f=f(x_1,\cdots,x_m) f=f(x1,⋯,xm),结果也是成立的。
结果表明神经网络具有一种普遍性,无论我们想计算什么函数,都能用神经网络实现。
普遍性定理在计算机科学领域中特别常见,我们几乎可以将生活中的任何过程看作函数的计算,例如基于一段音乐识别曲目,其实也能将其视为计算一个函数,或者将中文翻译成英文”,又或者根据一个mp4视频文件生成对电影情节的描述并讨论表演水平。
普遍性指神经网络可以做各种事情。本质上就是通过一定的规律由a变b的性质。
两个预先声明
在解释为什么普遍性成立之前,需要给“神经网络可以计算任意函数”两个预先声明。
第一点,这句话不是说神经网络可用于准确计算任何函数,而是说可以获得不错的近似。可以通过增加隐藏神经元的数量来提升近似的准确度。
例如一个网络中含有五个隐藏神经元的话肯定比含有3个隐藏神经元更好得近似结果。
第二点,可以按照上述方式近似的函数其实是连续函数。如果函数不是连续的,即会有突然的“跳跃”,那么通常无法使用一个神经网络进行近似。
这并不意外,因为神经网络计算的是输人的连续函数。然而,即使那些需要计算的函数是不连续的,连续的近似一般也足够好了。这样的话,就可以用神经网络来近似了。实践中,这通常不是一个严重的限制。
总结一下,关于普遍性定理,更加准确的表述是:包含隐藏层的神经网络可按照任意给定的准确度来近似任何连续函数。
一个输入和一个输出的普遍性
为了理解如何构造一个神经网络来计算了,先从只包含一个隐藏层的神经网络开始,它有两个隐藏神经元,以及由单个输出神经元形成的输出层。
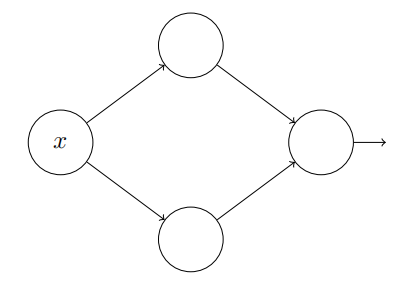
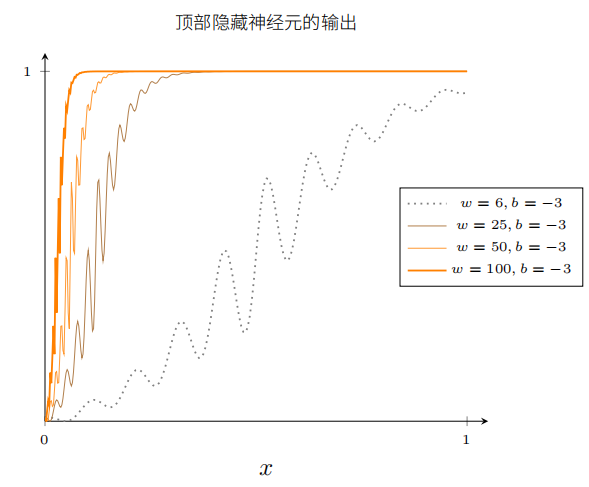
为了理解神经网络组件的工作机制,下面着重研究顶部的隐藏神经元。了解顶部隐藏神经元的权重w、偏置b和输出曲线的关系。思考如何通过顶部隐藏神经元的变化计算函数。
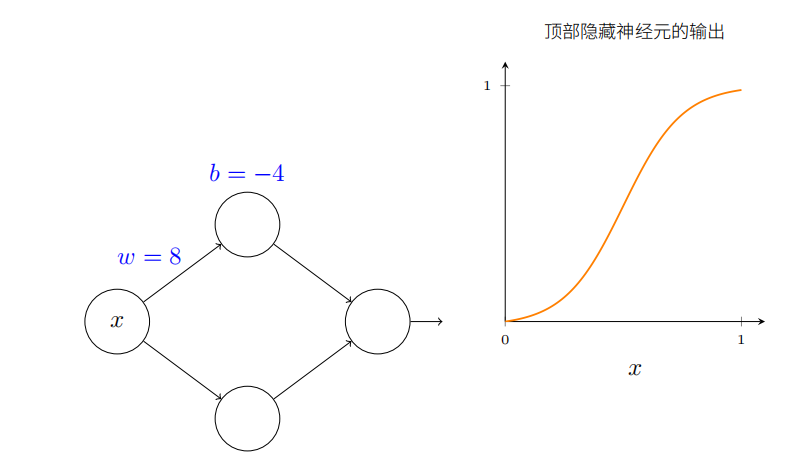
如前所述,隐藏神经元计算的是 σ ( w x + b ) \sigma(wx+b) σ(wx+b),其中 σ ( z ) ≡ 1 / ( 1 + e − z ) \sigma(z)\equiv1/(1+\mathrm{e}^{-z}) σ(z)≡1/(1+e−z)是sigmoid函数。前面频繁使用这个代数形式,这里为了证明普遍性会完全忽略其代数性质,而会在图像中调整并观察形状来获得更多认识。
一开始增大偏置b的值。当偏置增加时,图形向左移动,但是形状保持不变。
接着减小偏置。当偏置减小时,图形向右移动,但形状仍没有变化。
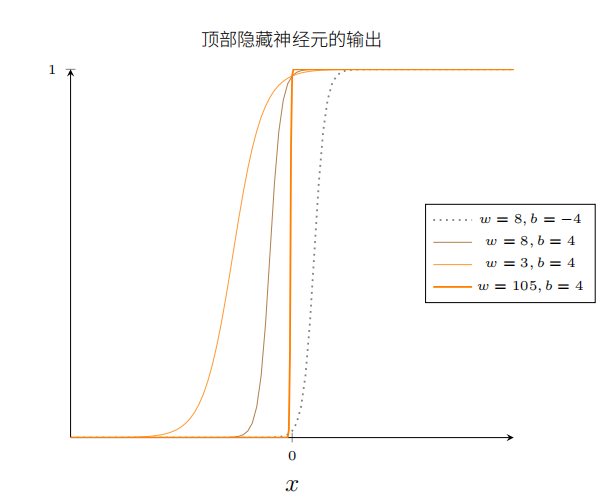
然后将权重减小到大约2或3.当权重减小时,曲线向两边拉宽了。可以通过改变偏置让曲线保持在框内。
最后,把权重增加到超过100.这会使得曲线变得越来越陡,最终看上去像阶跃函数。尝试调整偏置,使得阶跃位置靠近x=0.3.
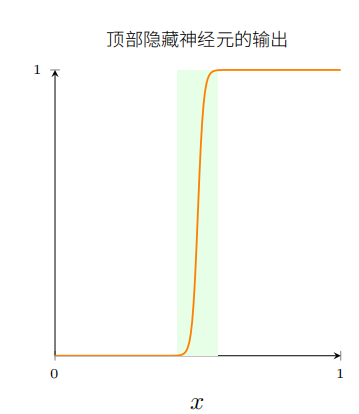
你能给权重增加很⼤的值来简化我们的分析,使得输出实际上是个⾮常接近的阶跃函数。下⾯我画出了当权重为 w = 999 时从顶部隐藏神经元的输出。
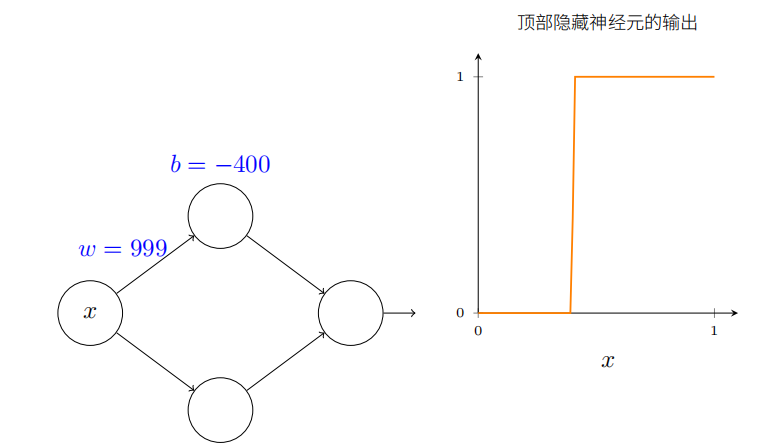
实际上处理阶跃函数⽐⼀般的 S 型函数更加容易。很显然相比于思考把⼀串 S 形状的曲线加起来是什么,我们只考虑在输出层我们把所有隐藏神经元的贡献值加在⼀起,分析⼀串阶跃函数的和是很容易的。
所以假设我们的隐藏神经元输出阶跃函数会使事情更容易。更具体些,我们把权重 w 固定在⼀个⼤的值,然后通过修改偏置设置阶跃函数的位置。
当然,把输出作为⼀个阶跃函数处理只是⼀个近似,但是它是⼀个⾮常好的近似,现在我们把它看作是精确的。
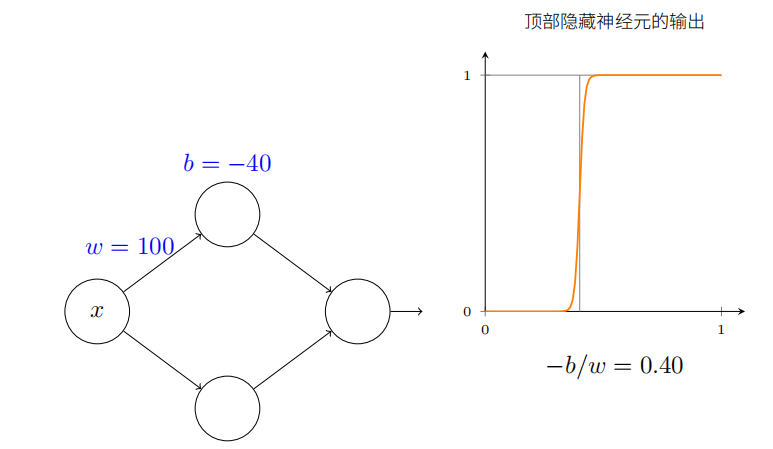
x 取何值时阶跃会发⽣呢?换种⽅式,阶跃的位置如何取决于权重和偏置?
得出的结论是:阶跃的位置和 b 成正⽐,和 w 成反⽐。
实际上,阶跃发⽣在$ s = −b/w $的位置,正如图中通过修改权重和偏置看到的:
这将⽤仅仅⼀个参数 s 来极⼤简化我们描述隐藏神经元的⽅式,这就是阶跃位置, s = − b / w s = −b/w s=−b/w
试着修改下图中的 s: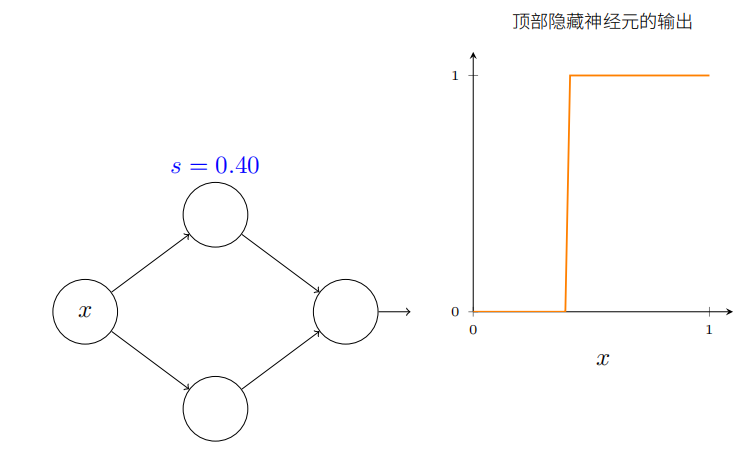
正如上⾯注意到的,我们隐式地设置输⼊上的权重 w 为⼀些⼤的值 —— ⼤到阶跃函数能够很好地近似。通过选择偏置 b = − w s b = -ws b=−ws,我们能很容易地将⼀个以这种⽅式参数化的神经元转换回常⽤的模型。
我们假设隐藏神经元在计算以阶跃点$ s_1 (顶部神经元)和 (顶部神经元)和 (顶部神经元)和 s_2 $(底部神经元)参数化的节约函数。它们各⾃有输出权重 $w_1 和 和 和w_2$。是这样的⽹络:
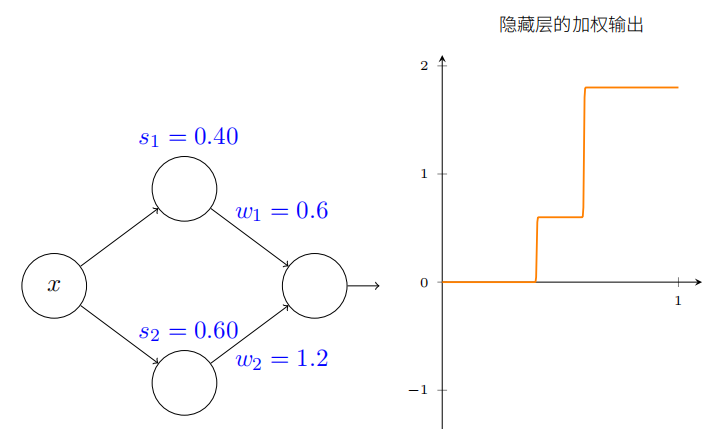
右边的绘图是隐藏层的加权输出 w 1 a 1 + w 2 a 2 . w_{1}a_{1}+w_{2}a_{2}. w1a1+w2a2.。(注意:整个网络输出是 σ ( w 1 a 1 + w 2 a 2 + b ) \sigma(w_{1}a_{1}+w_{2}a_{2}+b) σ(w1a1+w2a2+b))这⾥ a1 和 a2 各⾃是顶部和底部神经元的输出。这些输出由 a 表⽰,是因为它们通常被称为神经元的激活值(activations)。
试着增加和减⼩顶部隐藏神经元的阶跃点 s1。感受下这如何改变隐藏层的加权输出。尤其值得去理解当 s1 经过 s2 时发⽣了什么。你会看到这时图形发⽣了变化,因为我们从顶部隐藏神经元先被激活的情况变成了底部隐藏神经元先被激活的情况。
类似地,试着操作底部隐藏神经元的阶跃点 s2,感受下这如何改变隐藏神经元混合后的输出。
尝试增加和减少每⼀个输出权重。注意,这如何调整从各⾃的隐藏神经元的贡献值。当⼀个权重是 0 时会发⽣什么?
最后,试着设置 w1 为 0*.8,w2 为 −0.8。你得到⼀个“凸起”的函数,它从点 s1 开始,到点s2 结束,⾼为 0.*8。例如,加权后的输出可能看起来像这样:
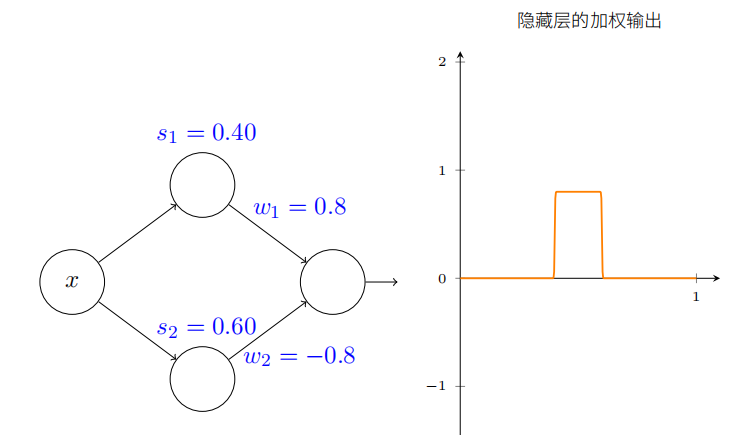
当然,我们可以调整为任意的凸起⾼度。让我们⽤⼀个参数,h,来表⽰⾼度。为了减少混乱我也会移除“s1 = . . .”和“w1 = . . .”的标记。
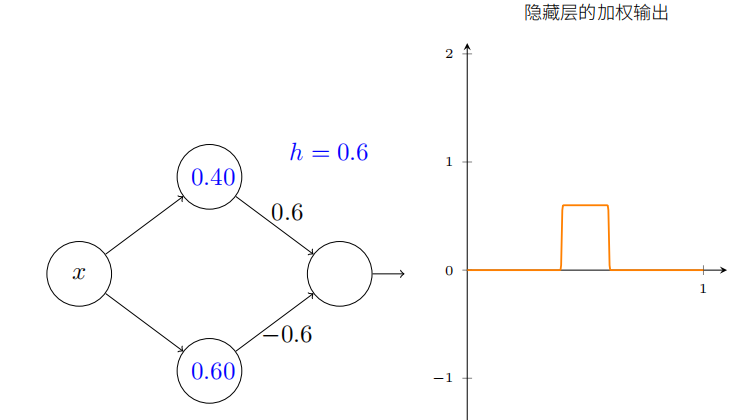
试着将 h 值改⼤或改⼩,看看凸起的⾼度如何改变。试着把⾼度值改为负数,观察发⽣了什么。并且试着改变阶跃点来看看如何改变凸起的形状。
顺便提⼀下,你会注意到,我们⽤神经元的⽅式,可以认为不只是在图形的⻆度,⽽且是更传统的编程形式,作为 if-then-else 的⼀种声明,即:
if input >= step point:add 1 to the weighted output
else:add 0 to the weighted output
对于⼤部分内容,我将坚持以图形的考虑⻆度。但在接下来的内容中,你有时可能会发现交换考虑⻆度是有帮助的,并且考虑 if-then-else 的形式。
我们可以⽤凸起制作的技巧来得到两个凸起,通过把两对隐藏神经元⼀起填充进同⼀个⽹络:
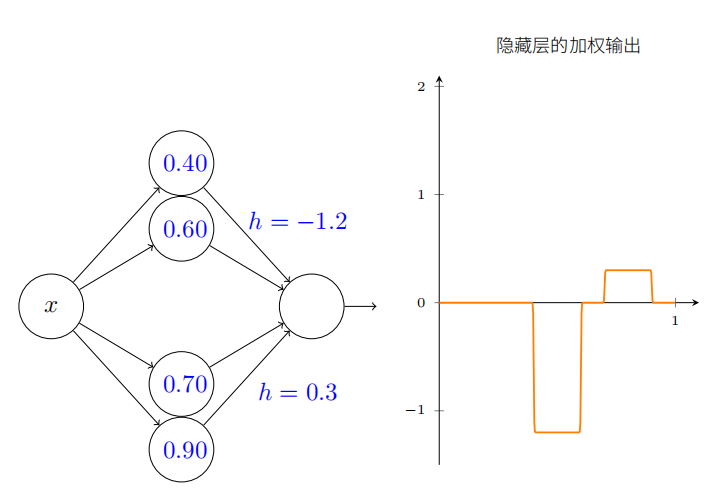
这⾥我抑制了权重,只是简单地在每对隐藏神经元上写了 h 的值。
更普遍地,我们可以利⽤这个思想来取得我们想要的任何⾼度的峰值。尤其,我们可以把间隔 [0*,* 1] 分成⼤量的⼦区间,⽤ N 表⽰,并利⽤ N 对隐藏神经元来设置任意期望⾼度的峰值。让我们看看 N = 5 这如何⼯作。
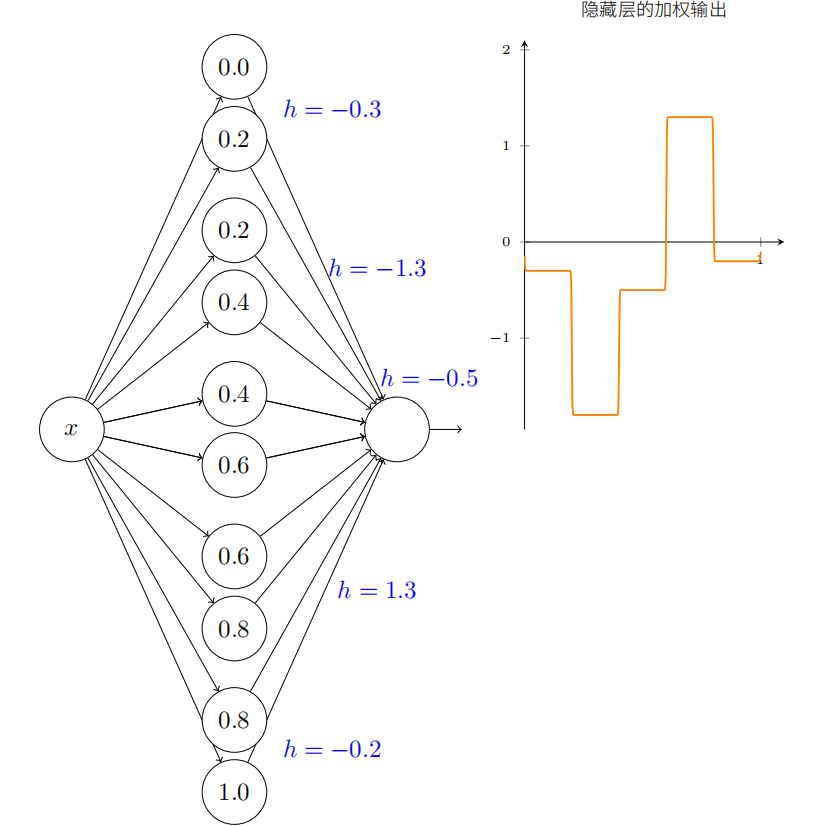
让我们回想在最开始绘制出的函数:
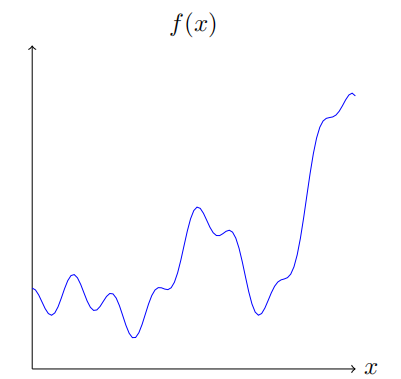
这个函数其实是:
f ( x ) = 0.2 + 0.4 x 2 + 0.3 x sin ( 15 x ) + 0.05 cos ( 50 x ) f(x)=0.2+0.4x^2+0.3x\sin(15x)+0.05\cos(50x) f(x)=0.2+0.4x2+0.3xsin(15x)+0.05cos(50x)
x 取值范围从 0 到 1,y 轴取值为 0 到 1。
我们再试着用神经网络的方法去估计它。
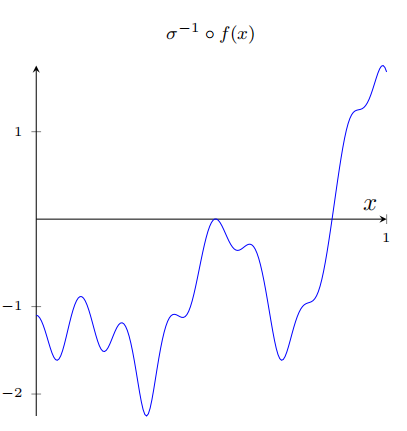
在我们上⾯的⽹络中,我们已经分析了隐藏神经元输出的加权组合 ∑ j w j a j \sum_jw_ja_j ∑jwjaj。我们现在知道如何在这个量上获得⼤量的控制。但是,正如我前⾯所指出的,这个量不是⽹络的输出。⽹络输出的是 σ ( ∑ j w j a j + b ) \sigma(\sum_{j}w_{j}a_{j}+b) σ(∑jwjaj+b),其中 b 是在输出神经元的偏置。有什么办法可以实现对⽹络的实际输出控制吗?
解决⽅案是设计⼀个神经⽹络,它的隐藏层有⼀个加权输出 σ − 1 ∘ f ( x ) \sigma^{-1}\circ f(x) σ−1∘f(x),其中 σ − 1 \sigma^{-1} σ−1 是 σ \sigma σ 函数的倒数。也就是说,我们希望从隐藏层的加权输出是:
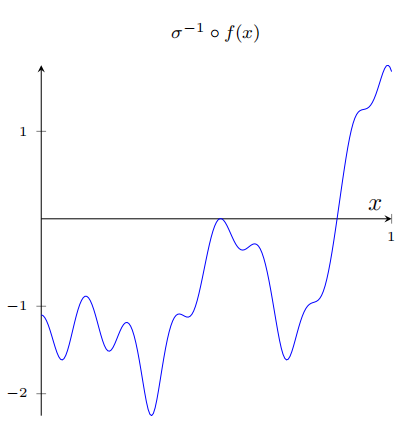
根据图形的需求我们大概可以调整到如下地步: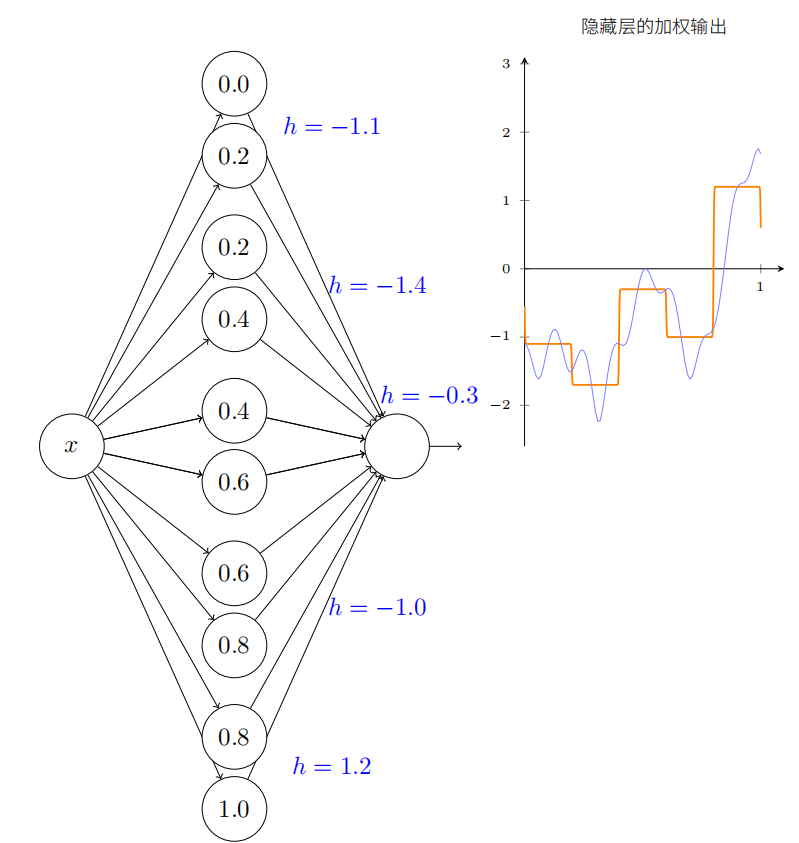
在已经解决了所有⽹络的必要元素来近似计算函数 f(x)!这只是⼀个粗略的近似,但我们可以很容易地做得更好,仅仅通过增加隐藏神经元对的数量,分配更多的凹凸形状。
于此我们已经理解了如何通过提⾼隐层神经元的数⽬来提⾼近似的质量。
多个输入变量
我们从考虑当⼀个神经元有两个输⼊会发⽣什么开始:
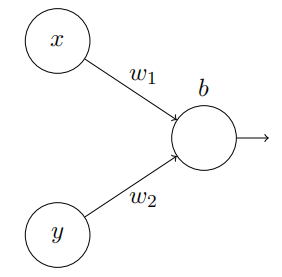
这⾥,我们有输⼊ x 和 y,分别对应于权重 w1 和 w2,以及⼀个神经元上的偏置 b。让我们把权重 w2 设置为 0,然后反复琢磨第⼀个权重 w1 和偏置 b,看看他们如何影响神经元的输出:
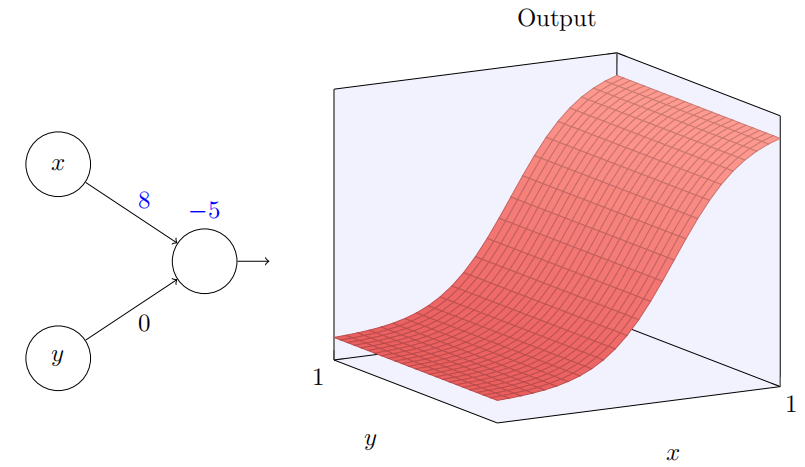
为当我们增加权重 w1 到 w1 = 100,同时 w2 保持 0 不变时会发⽣什么?
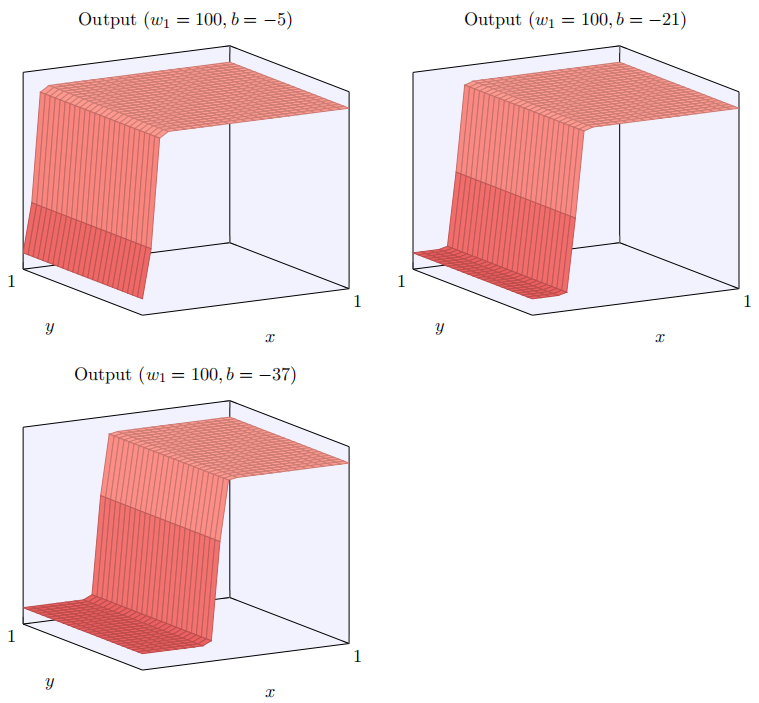
正如我们前⾯讨论的那样,随着输⼊权重变⼤,输出接近⼀个阶跃函数。不同的是,现在的阶跃函数是在三个维度。也如以前⼀样,我们可以通过改变偏置的位置来移动阶跃点的位置。阶跃点的实际位置是 s x ≡ − b / w 1 s_x\equiv-b/w_1 sx≡−b/w1。
让我们⽤阶跃点位置作为参数重绘上⾯的阶跃函数:

当然,通过使得 y 输⼊上的权重取⼀个⾮常⼤的值(例如,w2 = 1000),x 上的权重等于 0,即 w1 = 0,来得到⼀个 y
轴⽅向的阶跃函数也是可⾏的,
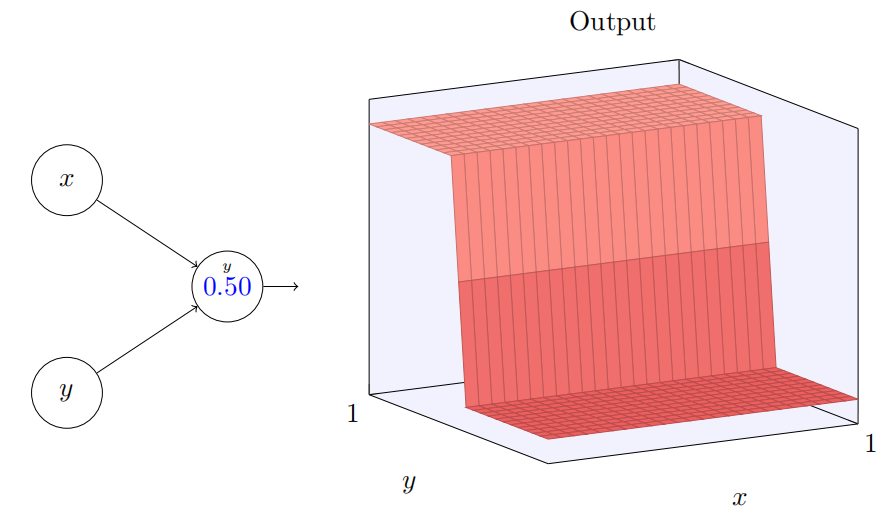
再⼀次,神经元上的数字是阶跃点,在这个情况下数字上的⼩ y 提醒我们阶跃是在 y 轴⽅向。我本来可以明确把权重标记在 x 和 y 输⼊上,但是决定不这么做,因为这会把图⽰弄得有些杂乱。但是记住⼩ y 标记含蓄地告诉我们 y 权重是个⼤的值,x 权重为 0。
我们可以⽤我们刚刚构造的阶跃函数来计算⼀个三维的凹凸函数。为此,我们使⽤两个神经元,每个计算⼀个 x ⽅向的阶跃函数。然后我们⽤相应的权重 h 和 −h 将这两个阶跃函数混合,这⾥ h 是凸起的期望⾼度。所有这些在下⾯图⽰中说明:
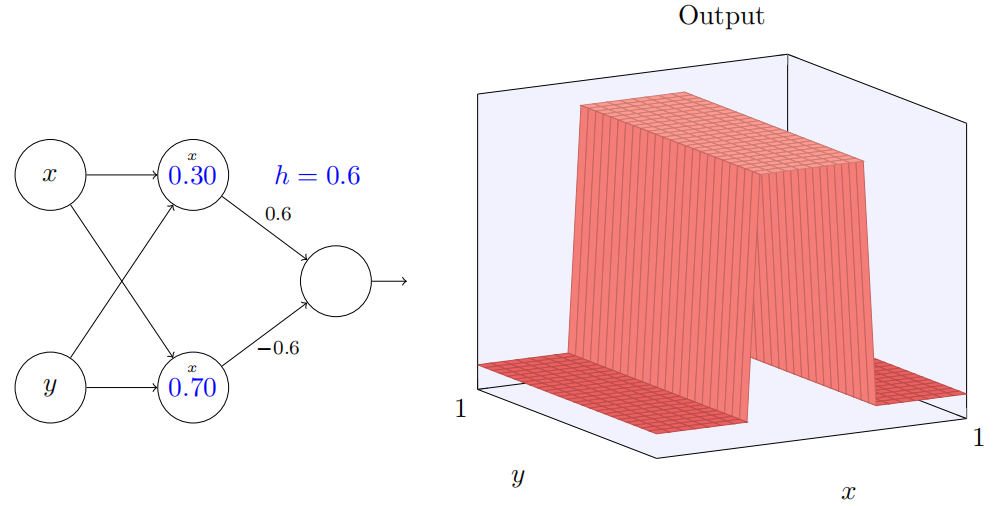
同理,使用y方向实现结果如下: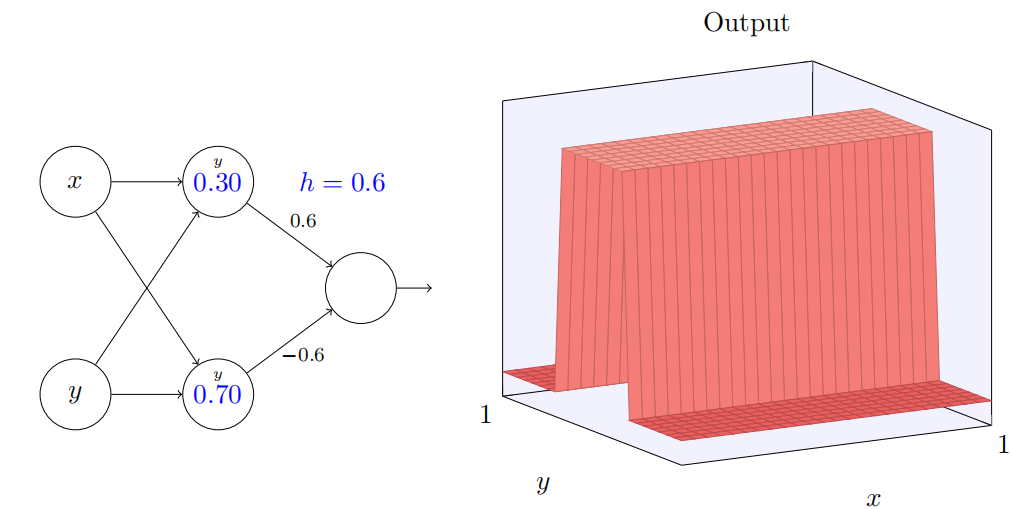
让我们考虑当我们叠加两个凹凸函数时会发⽣什么,⼀个沿 x ⽅向,另⼀个沿 y ⽅向,两者都有⾼度 h:
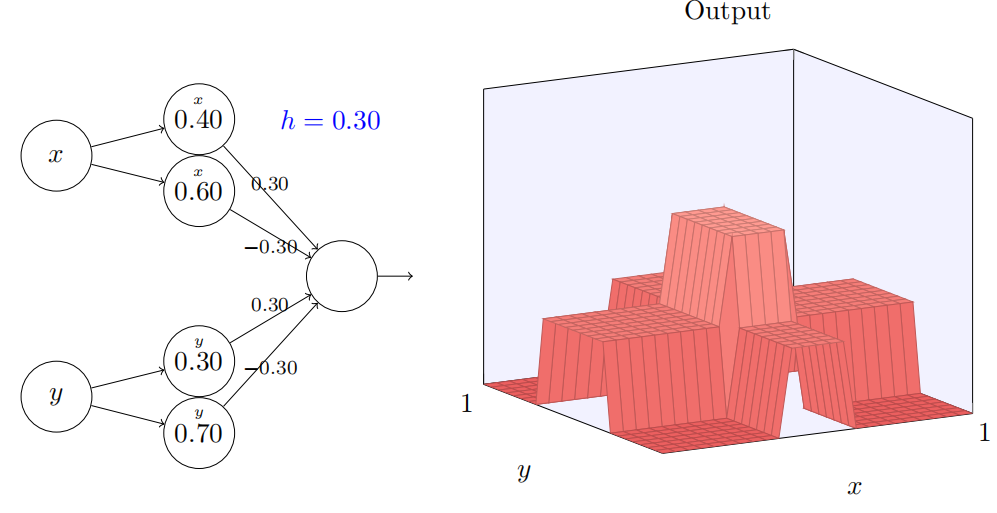
试着改变参数 h。正如你能看到,这引起输出权重的变化,以及 x 和 y 上凹凸函数的⾼度。
我们构建的有点像是⼀个塔型函数: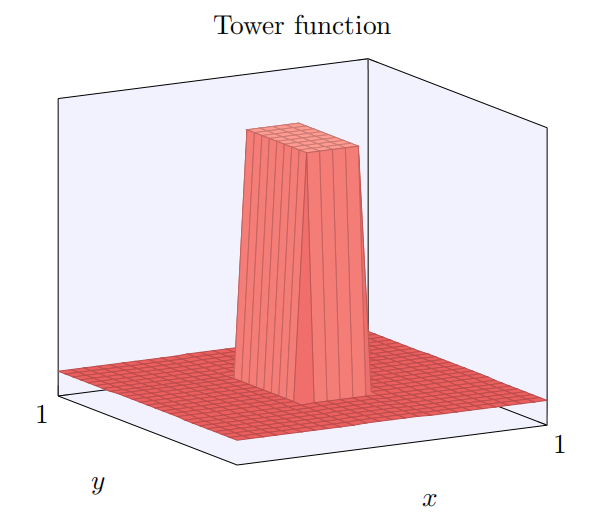
如果我们能构建这样的塔型函数,那么我们能使⽤它们来近似任意的函数,仅仅通过在不同位置累加许多不同⾼度的塔:
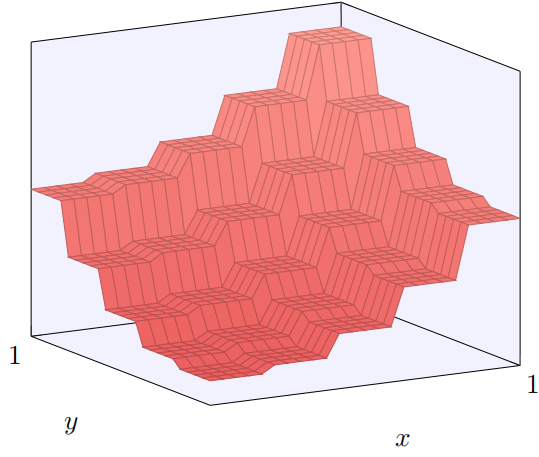
当然,我们还没有解决如何构建⼀个塔型函数。我们已经构建的看起来像⼀个中⼼塔,⾼度为 2h,周围由⾼原包围,⾼度为 h。
但是我们能制造⼀个塔型函数。记得前⾯我们看到神经元能被⽤来实现⼀个 if-then-else 的声明:
if input >= threshold:output 1
else:output 0
这是⼀个只有单个输⼊的神经元。我们想要的是将⼀个类似的想法应⽤到隐藏神经元的组合输出:
if combined output from hidden neurons >= threshold:output 1
else:output 0
如果我们选择适当的阈值 —— ⽐如,3h/2,这是⾼原的⾼度和中央塔的⾼度中间的值——我们可以把⾼原下降到零,并且依旧矗⽴着塔。
请注意,我们现在正在绘制整个⽹络的输出,⽽不是只从隐藏层的加权输出。这意味着我们增加了⼀个偏置项到隐藏层的加权输出,并应⽤ S 型函数。
你能找到 h 和 b 的值,能产⽣⼀个塔型吗?这有点难,所以如果你想了⼀会⼉还是困住,这是有两个提⽰:
(1)为了让输出神经元显⽰正确的 if-then-else ⾏为,我们需要输⼊的权重(所有 h 或 −h)变得很⼤;
(2)b 的值决定了 if-then-else 阈值的⼤⼩。
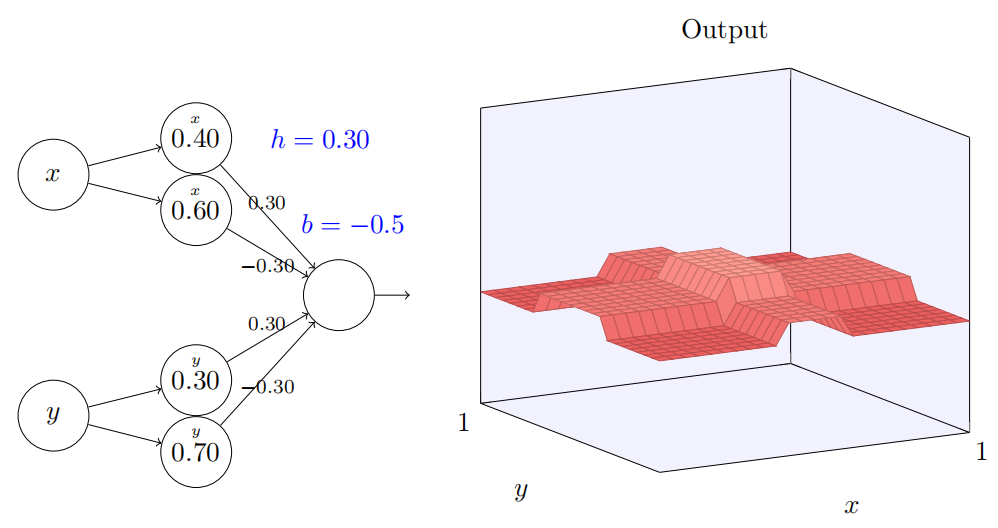
在初始参数时,输出看起来像⼀个前⾯图形在它的塔型和⾼原上的平坦的版本。为了得到期望的⾏为,我们增加参数 h 直到它变得很⼤。这就给出了 if-then-else 做阈值的⾏为。其次,为了得到正确的阈值,我们选择 b ≈ −3h/2。尝试⼀下,看看它是如何⼯作的!这是它看起来的样⼦,我们使⽤ h = 10:
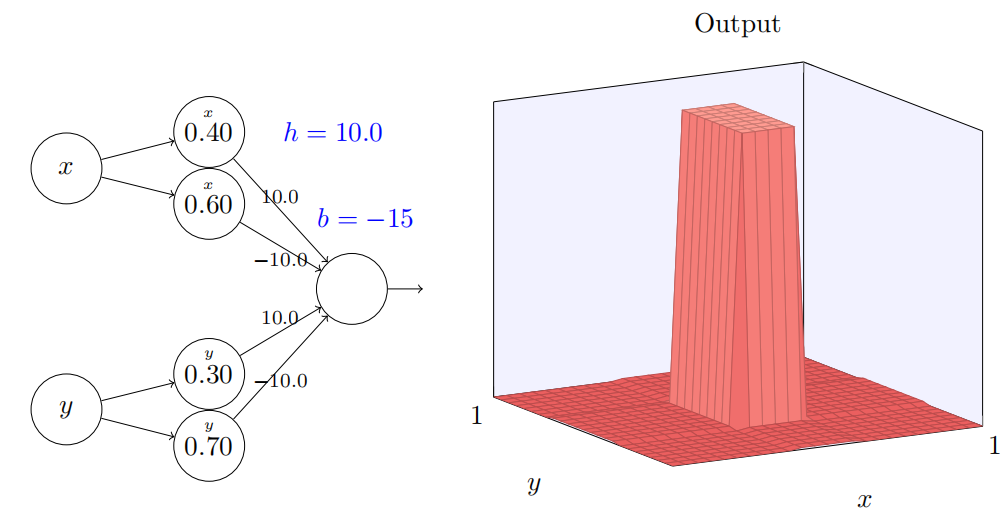
甚⾄对于这个相对适中的 h 值,我们得到了⼀个相当好的塔型函数。当然,我们可以通过更进⼀步增加 h 并保持偏置 b = −3h/2 来使它如我们所希望的那样。
让我们尝试将两个这样的⽹络组合在⼀起,来计算两个不同的塔型函数。为了使这两个⼦⽹络更清楚,我把它们放在如下所⽰的分开的⽅形区域:每个⽅块计算⼀个塔型函数,使⽤上⾯描述的技术。右边的图上显⽰了第⼆个隐藏层的加权输出,即,它是⼀个加权组合的塔型函数。
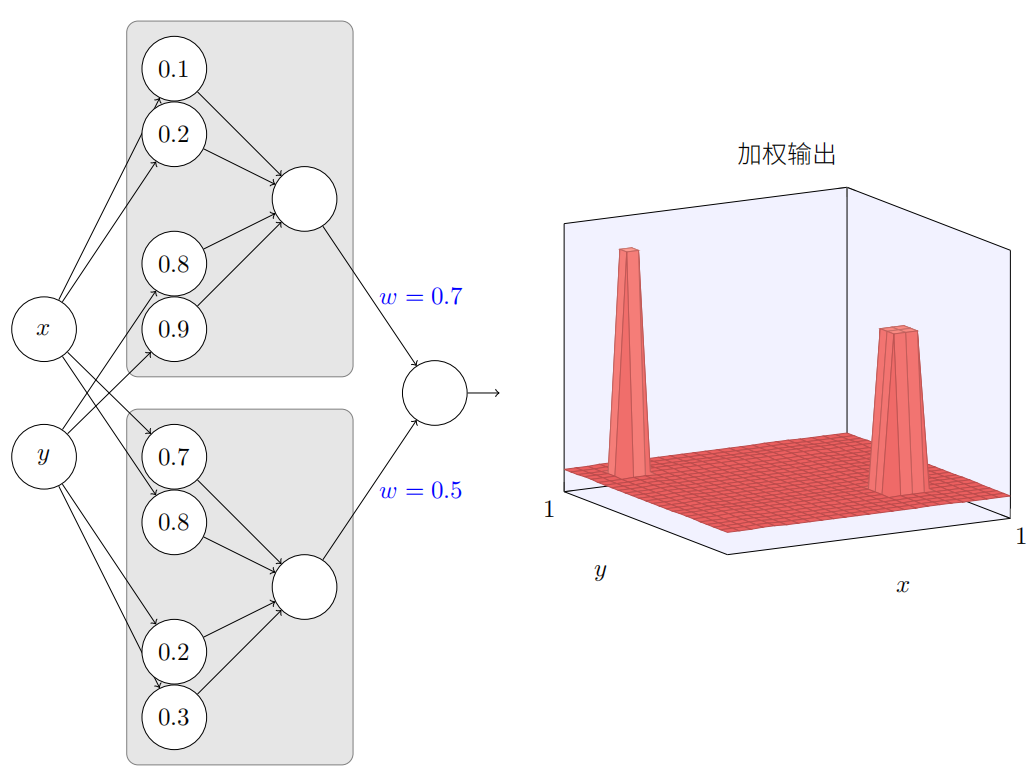
尤其你能看到通过修改最终层的权重能改变输出塔型的⾼度。
同样的想法可以⽤在计算我们想要的任意多的塔型。我们也可以让它们变得任意细,任意⾼。结果,我们可以确保第⼆个隐藏层的加权输出近似与任意期望的⼆元函数: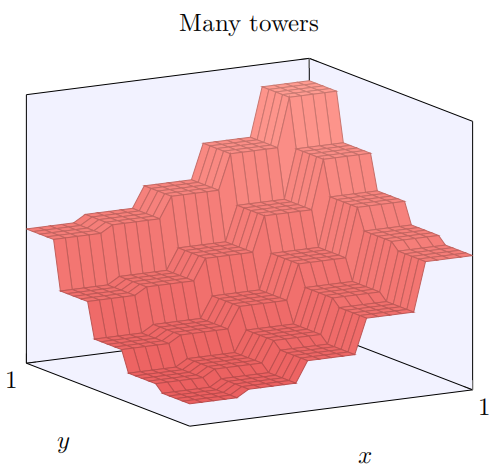
尤其通过使第⼆个隐藏层的加权输出为 σ − 1 ∘ f \sigma^{-1}\circ f σ−1∘f 的近似,我们可以确保⽹络的输出可以是任意期望函数 f 的近似。
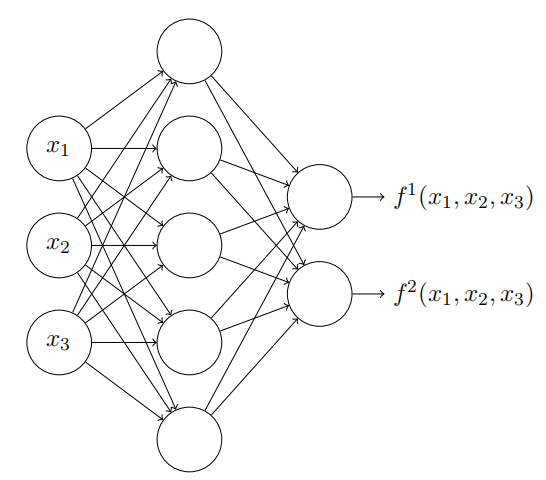
超过两个变量的函数会怎样?让我们试试三个变量 x1, x2*, x3。下⾯的⽹络可以⽤来计算⼀个四维的塔型函数:
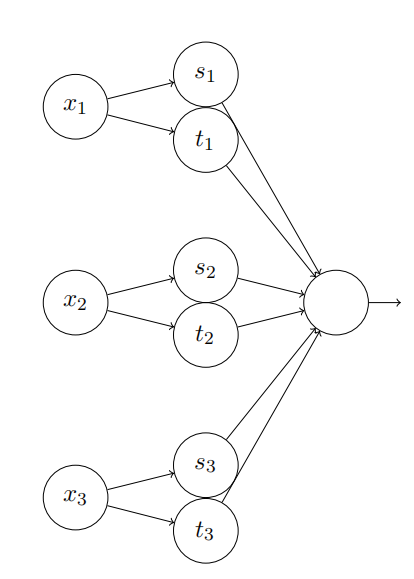
这⾥,x1, x2*, x3 表⽰⽹络的输⼊。s1, t1 等等是神经元的阶跃点 —— 即,第⼀层中所有的权重是很⼤的,⽽偏置被设置为给出阶跃点 s1, t1, s2, . . .。第⼆层中的权重交替设置为 +h, −h,其中 h 是⼀个⾮常⼤的数。输出偏置为 −5h/2。
这个⽹络计算这样⼀个函数,当三个条件满⾜时:x1 在 s1 和 t1 之间;x2 在 s2 和 t2 之间;x3 在 s3 和 t3 之间,输出为 1。其它情况⽹络输出为 0。即,这个塔型在输⼊空间的⼀个⼩的区域输出为 1,其它情况输出 0。
通过组合许多个这样的⽹络我们能得到任意多的塔型,如此可近似⼀个任意的三元函数。对于 m 维可⽤完全相同的思想。唯⼀需要改变的是将输出偏置设为 (−m + 1/2)h,为了得到正确的夹在中间的⾏为来弄平⾼原。
好了,所以现在我们知道如何⽤神经⽹络来近似⼀个多元的实值函数。对于 f ( x 1 , … , x m ) ∈ R n f(x_{1},\ldots,x_{m}) \in R^n f(x1,…,xm)∈Rn 的向量函数怎么样?当然,这样⼀个函数可以被视为 n 个单独的实值函数:, f 1 ( x 1 , … , x m ) \begin{aligned}f^1(x_1,\ldots,x_m)\end{aligned} f1(x1,…,xm), f 2 ( x 1 , … , x m ) f^2(x_1,\ldots,x_m) f2(x1,…,xm) 等等。所以我们创建⼀个⽹络来近似 f 1 f^1 f1,另⼀个来近似 f 2 f^2 f2 ,如此等等。然后简单地把这些⽹络都组合起来。所以这也很容易应付。
S 型神经元的延伸
我们已经证明了由 S 型神经元构成的⽹络可以计算任何函数。回想下在⼀个 S 型神经元中,输⼊ x1, x2, . . .导致输出 σ ( ∑ j w j x j + b ) \sigma(\sum_jw_jx_j+b) σ(∑jwjxj+b),这⾥ W j W_j Wj是权重,b 是偏置,⽽ σ 是 S 型函数:
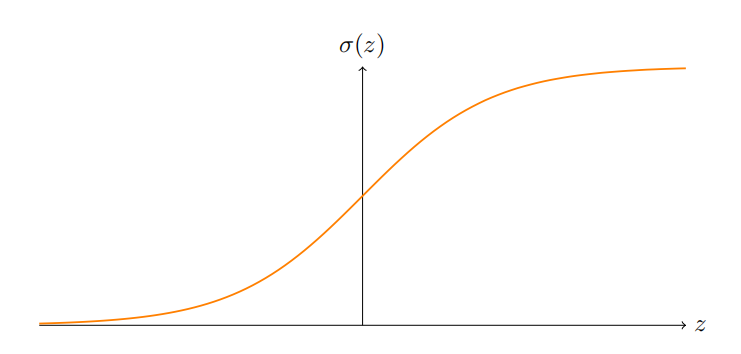
如果我们考虑⼀个不同类型的神经元,它使⽤其它激活函数,⽐如如下的 s(z),会怎样?
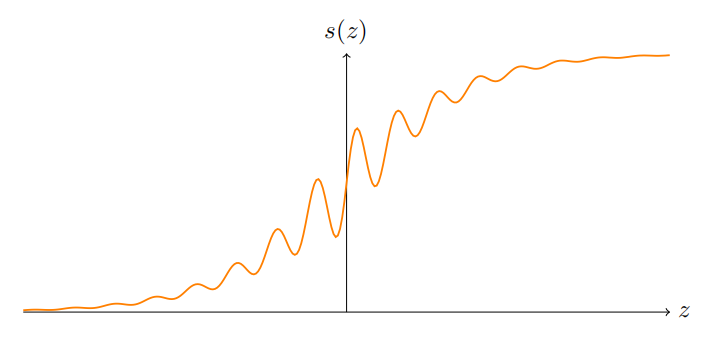
更确切地说,我们假定如果神经元有输⼊ x1, x2, . . .,权重 w1, w2, . . . 和偏置 b,那么输出 s ( ∑ j w j x j + b ) s(\sum_jw_jx_j+b) s(∑jwjxj+b)。我们可以使⽤这个激活函数来得到⼀个阶跃函数,正如⽤ S 型函数做过的⼀样。
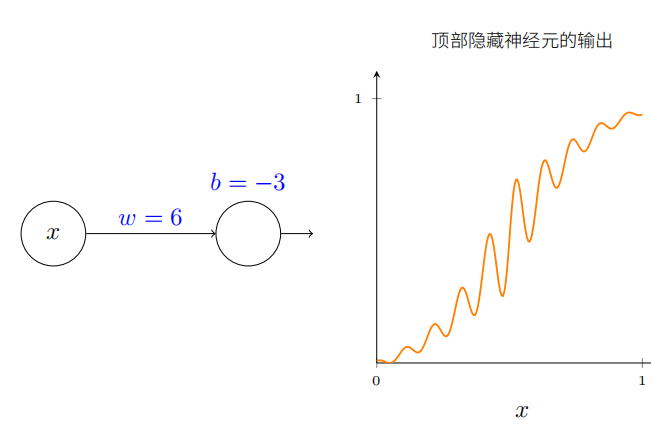
试着加⼤上图中的权重,⽐如 w = 100,你将得到:
正如使⽤ S 型函数的时候,这导致激活函数收缩,并最终变成⼀个阶跃函数的很好的近似。试着改变偏置,然后你能看到我们可以设置我们想要的阶跃位置。所以我们能使⽤所有和前⾯相同的技巧来计算任何期望的函数。
s(z) 需要什么样的性质来满⾜这样的结果呢?我们确实需要假定 s(z) 在 s ( z ) 在 z → − ∞ 和 z → ∞ s(z)\text{ 在 }z\to-\infty\text{ 和 }z\to\infty s(z) 在 z→−∞ 和 z→∞ 时是定义明确的。这两个界限是在我们的阶跃函数上取的两个值。我们也需要假定这两个界限彼此不同。如果它们不是这样,就没有阶跃,只是⼀个简单的平坦图形!但是如果激活函数 s(z)满⾜这些性质,基于这样⼀个激活函数的神经元可普遍⽤于计算。
修补阶跃函数
⽬前为⽌,我们假定神经元可以准确⽣成阶跃函数。这是⼀个⾮常好的近似,但也仅仅是近似。实际上,会有⼀个很窄的故障窗⼝,如下图说明,在这⾥函数会表现得和阶跃函数⾮常不同。
在这些故障窗⼝中我给出的普遍性的解释会失败。
现在,它不是⼀个很严重的故障。通过使得输⼊到神经元的权重为⼀个⾜够⼤的值,我们能把这些故障窗⼝变得任意⼩。当然,我们可以把故障窗⼝窄过我在上⾯显⽰的 —— 窄得我们的眼睛都看不到。所以也许我们可以不⽤过于担⼼这个问题。
尽管如此,有⼀些⽅法解决问题是很好的。
实际上,这个问题很容易解决。让我们看看只有⼀个输⼊和⼀个输出的神经⽹络如何修补其计算函数。同样的想法也可以解决有更多输⼊和输出的问题。
特别地,假设我们想要我们的⽹络计算函数 f。和以前⼀样,我们试着设计我们的⽹络,使得隐藏神经元的加权输出是 σ − 1 ∘ f ( x ) \sigma^{-1}\circ f(x) σ−1∘f(x):
如果我们要使⽤前⾯描述的技术做到这⼀点,我们会使⽤隐藏神经元产⽣⼀系列的凹凸函数:
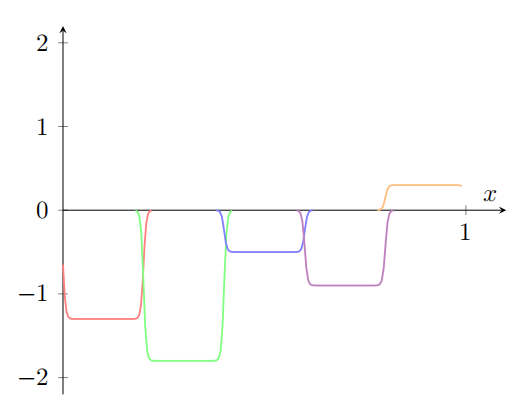
再说⼀下,我夸⼤了图上的故障窗⼝⼤⼩,好让它们更容易看到。很明显如果我们把所有这些凹凸函数加起来,我们最终会得到⼀个合理的 σ − 1 ∘ f ( x ) \sigma^{-1}\circ f(x) σ−1∘f(x)的近似,除了那些故障窗⼝。
假设我们使⽤⼀系列隐藏神经元来计算我们最初的⽬标函数的⼀半,即 σ − 1 ∘ f ( x ) / 2 \sigma^{-1}\circ f(x) /2 σ−1∘f(x)/2,⽽不是使⽤刚刚描述的近似。当然,这看上去就像上⼀个图像的缩⼩的版本: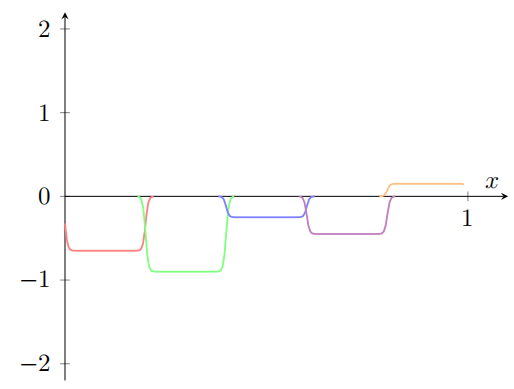
并且假设我们使⽤另⼀系列隐藏神经元来计算⼀个 σ − 1 ∘ f ( x ) / 2 \sigma^{-1}\circ f(x) /2 σ−1∘f(x)/2 的近似,但是⽤将凹凸图形偏移⼀半宽度:
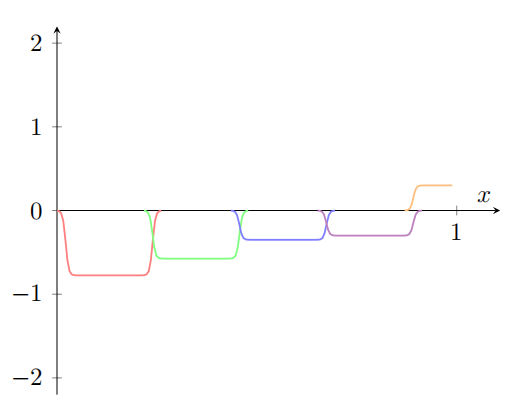
现在我们有两个不同的 σ − 1 ∘ f ( x ) / 2 \sigma^{-1}\circ f(x) /2 σ−1∘f(x)/2 的近似。如果我们把这两个近似图形加起来,我们会得到⼀个 σ − 1 ∘ f ( x ) \sigma^{-1}\circ f(x) σ−1∘f(x) 的整体近似。这个整体的近似仍然在⼀些⼩窗⼝的地⽅有故障。但是问题⽐以前要⼩很多。原因是在⼀个近似中的故障窗⼝的点,不会在另⼀个的故障窗⼝中。所以在这些窗⼝中,近似会有 2 倍的因素更好。
我们甚⾄能通过加⼊⼤量的,⽤ M 表⽰,重叠的近似 σ − 1 ∘ f ( x ) / M \sigma^{-1}\circ f(x) /M σ−1∘f(x)/M 来做得更好。假设故障窗⼝已经⾜够窄了,其中的点只会在⼀个故障窗⼝中。并且假设我们使⽤⼀个 M ⾜够⼤的重叠近似,结果会是⼀个⾮常好的整体近似。