问题
使用GPT这样的LLM去处理游戏中的NPC和玩家的对话是个很好的点子,那么如何处理记忆化的问题呢。
因为LLM的输入tokens是有限制的,所以伴随着问题的记忆context是有窗口大小限制的,将所有的记忆输入LLM并不现实。
所以这里看到了stanford的一项研究,利用ChatGPT做的生成智能群体。
方法
Generative Agents: Interactive Simulacra of Human Behavior ----Stanford
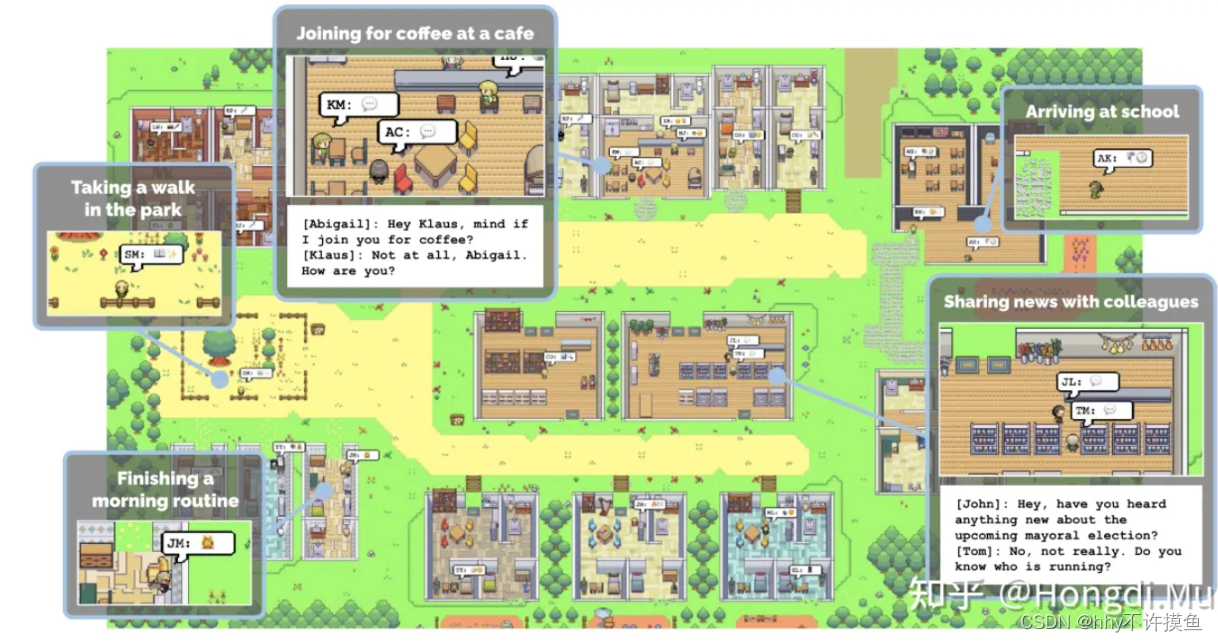
Introduction
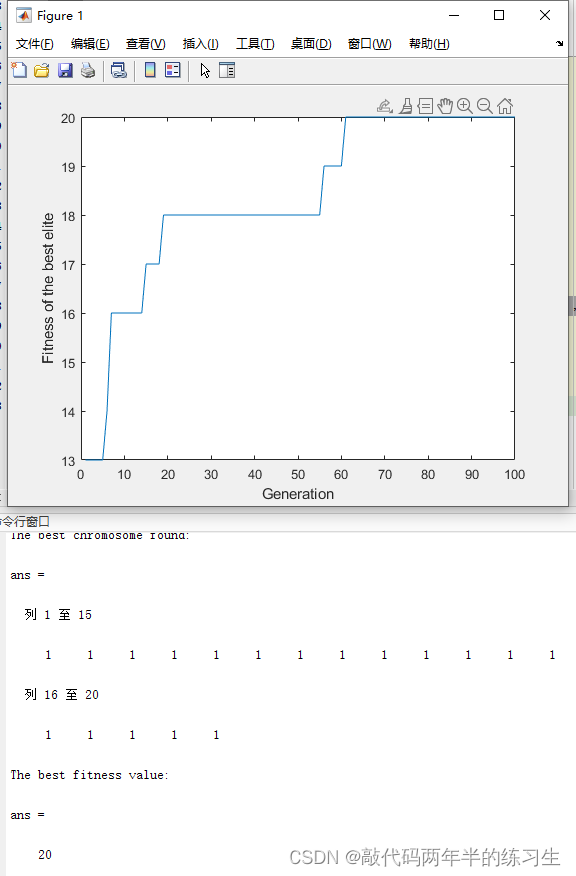
生成代理为交互式应用程序创建可信的人类行为模拟。在这项工作中,我们通过填充沙盒环境来演示生成代理,让人想起模拟人生,其中有 25 个代理,每个代理通过一段话进行初始化。 用户可以作为代理人,他们会观察和干预他们计划自己的日子、分享新闻、建立关系和协调小组活动。
生成型智能体的核心技术是基于深度学习的生成模型。生成模型是一种可以从数据中学习出潜在规律,并根据这些规律生成新数据的机器学习方法。
生成式智能体接受当前环境和过去经验作为输入,并将行为生成为输出。这种行为的基础是一种新颖的智能体架构,它将一个大型语言模型与合成和检索相关信息的机制相结合,以在语言模型的输出上进行条件控制。
主要包括三个组成部分:
(1)memory stream
(2)reflection
它将记忆合成为高层次的推理,使智能体能够在时间上得出关于自己和他人的结论,以更好地指导其行为
(3)schedule
将这些结论和当前环境转化为高层次的行动计划,然后递归地转化为详细的行动和反应行为。这些反思和计划被反馈到记忆流中,以影响智能体未来的行为
Memory and Retrieval
challenge: 创建可以模拟人类行为的生成代理需要对一组远远大于提示中描述的经验进行推理,因为完整的内存流可以分散模型,甚至目前不适合有限的上下文窗口。
memory stream: a list of memory objects. 每个memory object包含:自然语言描述、创建时间戳和最近的访问时间戳。包括agent本身的行为或者代理感知到其他代理的行为。
主要做法:
我们的体系结构实现了一个检索功能,该功能将代理的当前情况作为输入,并返回内存流的一个子集以传递给语言模型。

Recency: 指数衰减函数。我们的衰减因子是0.99。
Importance:重要性来区分普通记忆和核心记忆。给agents认为比较重要的记忆对象分配更高的分数。(在创建memory objects的时候就得到了重要性评分)
Ex:房间里吃早饭这样的事件重要性得分很低,与另一半分手重要性得分很高。
另外直接让LM输出对应的得分也是很有效的。
prompt:
On the scale of 1 to 10, where 1 is purely mundane (e.g., brushing teeth, making bed) and 10 is extremely poignant (e.g., a break up, college acceptance), rate the likely poignancy of the following piece of memory. Memory: buying groceries at The Willows Market and Pharmacy Rating: <fill in>
Relavance:与当前的情况相似度更高的memory object分配更高的分数。使用语言模型生成每个memory object的embeeding vector。然后计算memory object与query之间的余弦相似度。
最后将得分归一化到0-1之间。将三者的得分进行一个求和。然后取top ranked memory object作为prompt输入语言模型中。
Reflection
当只有原始的观察记忆时,生成式智能体很难进行泛化或推理。考虑这样一种情况,用户问Klaus Mueller:“如果你必须选择一个你认识的人与之共度一小时,你会选择谁?”只有观察性记忆的智能体只会选择和Klaus互动最频繁的人:他的大学宿舍邻居Wolfgang。不幸的是,Wolfgang和Klaus只是偶尔擦肩而过,没有深入的交流。更理想的回答需要智能体从Klaus在研究项目上花费的时间的记忆中进行泛化,生成一个更高层次的反思,即Klaus对研究充满热情,同时也能够认识到Maria在自己的研究中付出了努力(尽管在不同的领域),从而产生一个反思,即他们有共同的兴趣爱好。通过以下方法,当问及Klaus要和谁共度时光时,Klaus选择Maria而不是Wolfgang
使用一个reflection tree。当智能体感知到的最新事件的重要性分数之和超过一定阈值时,我们就会生成反思。在实践中,我们的智能体大约每天反思两到三次。
反思的第一步是让智能体确定要反思什么,通过识别基于最近经验可以提出的问题。我们使用智能体记忆流中最近的100个记录(例如,“Klaus Mueller正在阅读一本关于社区变迁的书”,“Klaus Mueller正在与图书馆员谈论他的研究项目”,“图书馆的桌子目前没有人占用”)向大型语言模型提出查询,提示语言模型:“只考虑上述信息,我们可以回答哪些关于主题的最重要的高层次问题?”。模型的响应生成候选问题,例如,“Klaus Mueller对哪个主题充满热情?”和“Klaus Mueller和Maria Lopez之间的关系是什么?”。我们使用这些生成的问题作为检索的查询,并收集与每个问题相关的记忆(包括其他反思)。然后,我们提示语言模型提取见解,并引用作为见解证据的特定记录
我们解析并将该语句作为反思存储在记忆流中,包括指向被引用的记忆对象的指针。
递归操作。
记忆保存
记忆来源:NPC通过设定、和虚拟世界进行对话和互动从而获得记忆。
记忆权重:NPC对获得的记忆进行评分,从而区分平凡记忆和深刻记忆。
记忆反思:NPC不断地回顾和提炼自己的记忆,从而形成核心记忆。
记忆检索
在需要的时候,NPC通过内部的表征向量检索到所需要的记忆信息,然后根据重要性和访问时间进行排序。
一定程度上提高了NPC的性能。