触发器
触发器是由事件来触发某个操作(也包含INSERT、UPDATE、DELECT事件),如果定义了触发程序,当数据库执行这些语句时,就相当于事件发生了,就会自动激发触发器执行相应的操作。
当对数据表中的数据执行 插入、更新和删除操作,需要自动执行一些数据库逻辑时,就可以使用触发器来实现。
触发器的创建:
格式:


例:创建触发器before_insert,向表一插入数据之前,向表二中插入日志信息。
DELIMITER $CREATE TRIGGER before_insert_triBEFORE INSERT ON test_firstFOR EACH ROWBEGININSERT INTO test_second(t_log)VALUES('before insert ……');END $DELIMITER ;创建触发器after_insert,向表一插入数据之后,向表二中插入日志信息。
DELIMITER $CREATE TRIGGER after_insert_triAFTER INSERT ON test_firstFOR EACH ROWBEGININSERT INTO test_second(t_log)VALUES('after insert ……');END $DELIMITER ;例:在添加员工信息时,判断员工信息是否大于他领导的薪资,如果大于,则报'HY000'的错误,使得添加失败。
-- 创建触发器DELIMITER $CREATE TRIGGER sal_check_tri2BEFORE INSERT ON emp_test_triFOR EACH ROWBEGINDECLARE mgr_sal DECIMAL(7,2);SELECT sal INTO mgr_sal FROM emp_test_triWHERE empno = NEW.mgr;IF NEW.sal > mgr_salTHEN SIGNAL SQLSTATE 'HY000' SET MESSAGE_TEXT = '薪资不能比领导高';END IF;END $DELIMITER ;-- 插入数据INSERT INTO emp_test_tri(empno,ename,mgr,sal)VALUES(8000,'Tom', 7788,2500);INSERT INTO emp_test_tri(empno,ename,mgr,sal)VALUES(8001,'Tom', 8000,3200);注:触发器中的NEW表示当前正在添加的记录。OLD表示删除前、更新前的记录。
查看触发器:
查看当前数据库的所有触发器的定义:
SHOW TRIGGERS;
查看当前数据库中某个数据库的定义:
SHOW CREATE TRIGGER 触发器名;
从系统库information_schema的TRIGGERS表中查询触发器的信息:
SELECT * FROM information_schema.TRIGGERS;
删除触发器
DROP TRIGGER 触发器名;
窗口函数
窗口函数的作用类似于在查询中对数据进行分组。与分组操作不同的是,分组操作会把分组的结果聚合成一条记录,而窗口函数是将结果置于每一条数据记录中。
例:查询员工信息,按部门分类,在每个员工前显示其所在部门的平均工资。
SELECT empno,ename,deptno,SUM(sal) OVER(PARTITION BY deptno) '部门平均工资'FROM emp;
可以发现,查询中确实对数据进行了分组,但是只是将每个组并列在了一起,然后在每个员工的后面显示其部门平均工资
窗口函数的语法格式:
函数 OVER (PARTITION BY 字段名 ORDER BY 字段名 ASC/DESC)
或者是
函数 OVER 窗口名 …… WINDOW 窗口名 AS (PARTITION BY 字段名 ORDER BY 字段名 ASC/DESC)
窗口的使用:
OVER括号中的分组排序规则的内容可以以一个窗口代替,最后在使用窗口的多个函数声明完后,用WINDOW 窗口名 AS (PARTITION BY 字段名 ORDER BY 字段名 ASC/DESC)指明窗口的具体规则的内容。
PARTITION BY子句:
指定窗口函数按照哪些字段分组,分组后,窗口函数在每个分组中分别执行。
ORDER BY:
指定窗口函数按照那些字段进行排序,也是在组内排序。
函数的分类:

序号函数:
ROW_NUMBER( )函数
ROW_NUMBER( )能够对数据中的序号进行顺序显示。按分组分别显示序号。
例:查看员工信息,以员工部门分组,在每个员工前显示其在部门的序号。每个部门中按员工工资排序。
SELECT ROW_NUMBER() OVER(PARTITION BY deptno ORDER BY sal) 序号,empno,ename,deptnoFROM emp;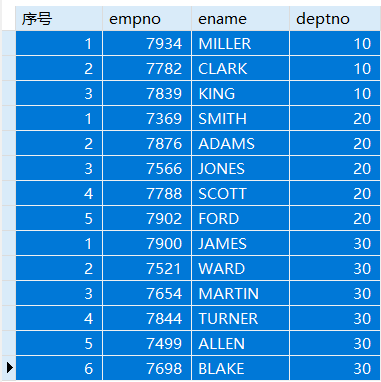
也可以利用新生成的序号,在后面加上WHERE 序号 < 3,求出每个部门工资排名前三的员工信息。
RANK( )函数
使用RANK( )函数能够对序号进行并列排序,并且会跳过重复的序号(比如序号为1,1,3……)
例:查看员工信息,以员工部门分组,每个部门中按员工工资排序,并显示其在工资的排名(跳过重复的排名序号)。
SELECT empno,ename,deptno,RANK() OVER(PARTITION BY deptno ORDER BY sal) '部门工资排名'FROM emp;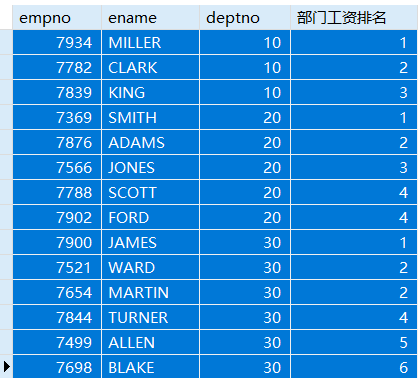
与前面的ROW_NUMBER( )函数不同的是,当遇到相同的值比较时,会判为相同值的记录排序序号一样,并跳过重复的排序再计数。
DENSE_RANK( )函数
DENSE_RANK( )函数对序号进行并列排序,并且不会跳过重复的序号(比如序号为1,1,2……)
例:查看员工信息,以员工部门分组,每个部门中按员工工资排序,并显示其在工资的排名(不跳过重复的排名序号)。
SELECT empno,ename,deptno,DENSE_RANK() OVER(PARTITION BY deptno ORDER BY sal) '部门工资排名'FROM emp;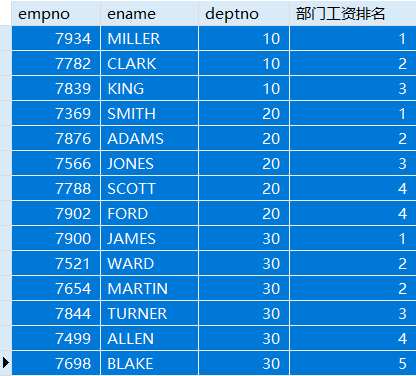
与前面的RANK( )函数不同的是,不跳过重复的排序再计数。
分布函数:
PERCENT_RANK( )函数
PERCENT_RANK( )函数是等级值百分比函数。
计算方式:(rank - 1) / (rows - 1)
其中,rank的值是使用RANK( )函数产生的序号,rows的值为当前窗口的总记录数。
例:查看员工信息,以员工部门分组,每个部门中按员工工资排序,并显示其在工资的排名(跳过重复的排名序号),并显示其序号的等级值百分比。
SELECT empno,ename,deptno,RANK() OVER(PARTITION BY deptno ORDER BY sal) '部门工资排名',PERCENT_RANK() OVER(PARTITION BY deptno ORDER BY sal) '排名比例'FROM emp;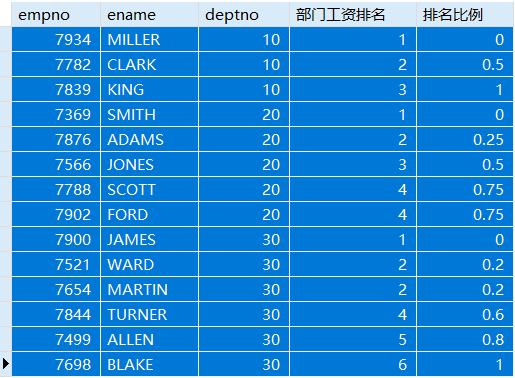
使用窗口的格式:
SELECT empno,ename,deptno,RANK() OVER w '部门工资排名',PERCENT_RANK() OVER w '排名比例'FROM emp WINDOW w AS (PARTITION BY deptno ORDER BY sal);CUME_DIST( )函数
CUME_DIST( )函数主要用于查询小于或等于本记录的某个值的组内的记录的比例。
例:查询工资小于或等于当前员工的薪资的员工的比例
SELECT empno,ename,sal,deptno,CUME_DIST() OVER(PARTITION BY deptno ORDER BY sal ASC) '比例'FROM emp;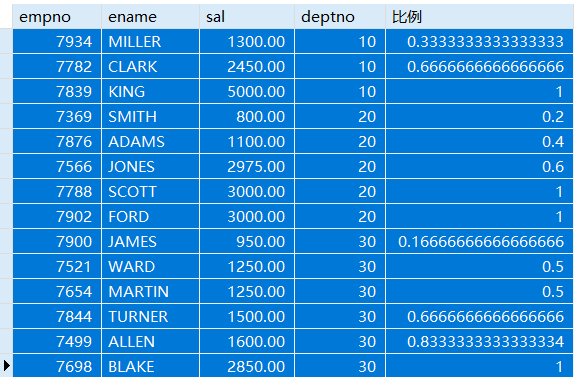
以MILLER为例,在10号部门中员工工资小于或等于1300的员工比例为0.3333……
以CLARK为例,在10号部门中员工工资小于或等于2450的员工比例为0.6666……
前后函数
LAG(expr,n)函数
LAG(expr,n)函数返回当前行的第前n行记录的expr的值。
例:查询上一个员工与当前员工的薪资的差值。
SELECT empno,ename,deptno,sal,pre_sal,sal - pre_sal diff_salFROM(SELECT empno,ename,deptno,sal,LAG(sal,1) OVER w pre_salFROM empWINDOW w AS (PARTITION BY deptno ORDER BY sal)) t;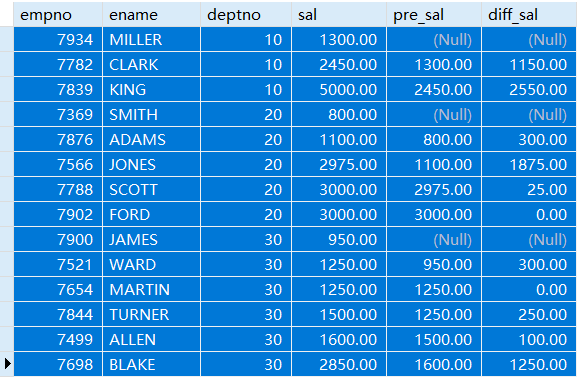
子查询中的pre_sal即为上一个记录的薪资。将1改为2即为上两个记录的工资,找不到相应的记录结果为NULL。
首尾函数
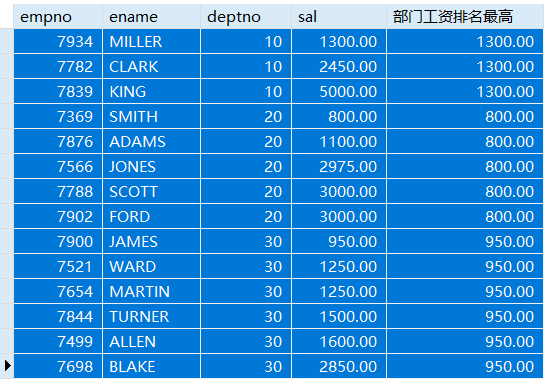
FIRST_VALUES(expr)函数
FIRST_VALUES(expr)函数返回第一个记录的expr的值(分组内的第一个),会在每一行都显示第一个记录的expr的值。
例:
SELECT empno,ename,deptno,sal,FIRST_VALUE(sal) OVER(PARTITION BY deptno ORDER BY sal) '部门工资排名最高'
FROM emp;
LAST_VALUES(expr)函数
LAST_VALUES(expr)函数返回最后一个记录的expr的值。
其他函数
NTH_VALUES(expr,n)函数
NTH_VALUES(expr,n)函数返回第n个记录的expr的值。
NTILE(n)函数
NTILE(n)函数将分区中的有序数据分为n个桶,记录桶编号。
例:将员工按薪资分为三组。
SELECT NTILE(3) OVER w 桶编号,empno,deptno,ename,salFROM emp WINDOW w AS (PARTITION BY deptno ORDER BY sal);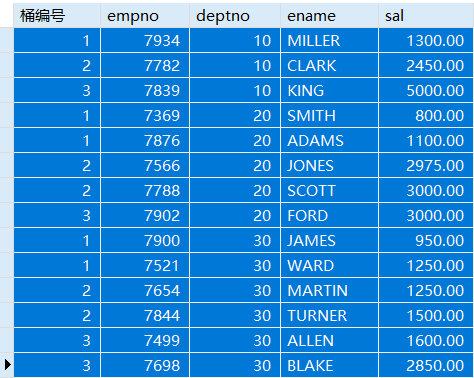
即自动按薪资再分一个等级,按照要分的组数来均分等级。
公用表表达式
公用表表达式(或通用表表达式)简称为CTE(Common Table Expressions)。CTE是一个命名的临时结果集,作用范围是当前语句。CTE可以理解为一个可以复用的子查询。
公用表表达式分为普通公用表表达式和递归公用表表达式。
普通公用表表达式:
例:
WITH test_cteAS (SELECT DISTINCT deptno FROM emp)SELECT *FROM dept dJOIN test_cte eON d.deptno = e.deptno;将查询结果放在WITH CTE名 AS ( )的括号中,就可以在下面的查询语句中将CTE当作一个表使用。可以有多个CTE,CTE可以引用其他CTE。
递归公用表表达式:
在WITH和CTE名中间插入RECURSIVE
例:
WITH RECURSIVE cteAS(-- 若UNION ALL前面的查询语句为A部分SELECT empno,ename,mgr,1 AS 第几代 FROM emp WHERE empno = 7839 -- 种子查询,设置第一代领导UNION ALL-- 若UNION ALL后面的查询语句为B部分SELECT a.empno,a.ename,a.mgr,第几代+1 FROM emp AS a JOIN cteON (a.mgr = cte.empno) -- 递归查询,找出以递归公用表表达式的人为领导的人,即找出A部分的下一代-- 执行完后,B部分变为新的A部分,继续找新的B部分,直到找不到任何记录为止。)SELECT empno,ename,第几代 FROM cte;-- 可以在此处加上WHERE子句,查询指定的第几代数。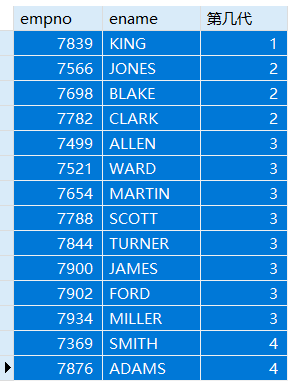
A部分先设置查询的第一代,B部分再设置下一代的查询方法,当A、B执行完后,B会成为新的A部分,查找新的B部分,以此类推,直到找不到下一代记录为止。A、B部分用UNION ALL连接。