文章目录
- 知识点梳理:
- 1. mysql 中 in 和 exists 区别
- 2. varchar 与 char 的区别
- 查看表结构:
- 获取当前时间:
- 查看建表语句:
- 修改用户密码:
- 查看所有用户:
- grant命令:
- 判断当前数据库有多少连接数:
- 分组之前进行排序:
- 查询媒体名称为"小强日报"的数据量:
- 内连接:
- 去重:
- Cast(字符串转数字):
- 分割函数:
- 1. MySQL8 split
- 2. substring_index
- group by 1, 2:
- replace into:
- ON DUPLICATE key update:
- DATEDIFF() 函数返回两个日期之间的时间:
- 四舍五入:
- 1. 函数ROUND(x)
- 2. 函数ROUND(x,y)
- 3. 函数TRUNCATE(x,y)
- 简单的增删改:
- beauty_article_view视图:
- 创建库和表:
- create、insert 和 select 相结合:
- 查询数据库中所有表名或者表的所有字段名:
- 索引:
- 日期和字符相互转换:
- \g 和 \G:
- 开窗函数:
- if函数:
- 经纬度转换:
- 需要注意的点:
- 查询数据库中的存储过程和函数:
- INTERVAL关键字和INTERVAL()函数:
- 1. INTERVAL关键字
- 2. INTERVAL() 函数
- 创建日期维度表:
- 从库binlog报错:
- json:

知识点梳理:
来自:mysql delete exists用法_2020年最新版MySQL面试题(四)
1. mysql 中 in 和 exists 区别
mysql 中的 in 语句是把外表和内表作 hash 连接,而 exists 语句是对外表作 loop 循环,每次 loop 循环再对内表进行查询。一直大家都认为 exists 比 in 语句的效率要高,这种说法其实是不准确的。这个是要区分环境的。
- 如果查询的两个表大小相当,那么用 in 和 exists 差别不大。
- 如果两个表中一个较小,一个是大表,则子查询表大的用 exists,子查询表小的用 in。
- not in 和 not exists:如果查询语句使用了 not in,那么内外表都进行全表扫描,没有用到索引;而 not extsts 的子查询依然能用到表上的索引。所以无论那个表大,用 not exists 都比 not in 要快。
2. varchar 与 char 的区别
char 的特点:
- char 表示定长字符串,长度是固定的;
- 如果插入数据的长度小于 char 的固定长度时,则用空格填充;
- 因为长度固定,所以存取速度要比 varchar 快很多,甚至能快50%,但正因为其长度固定,所以会占据多余的空间,是空间换时间的做法;
- 对于 char 来说,最多能存放的字符个数为255,和编码无关
varchar的特点:
- varchar 表示可变长字符串,长度是可变的;
- 插入的数据是多长,就按照多长来存储;
- varchar 在存取方面与 char 相反,它存取慢,因为长度不固定,但正因如此,不占据多余的空间,是时间换空间的做法;
- 对于 varchar 来说,最多能存放的字符个数为 65532
总之,结合性能角度(char更快)和节省磁盘空间角度(varchar更小),具体情况还需具体来设计数据库才是妥当的做法。
查看表结构:
desc tabl_name;
获取当前时间:
SELECT CURRENT_TIMESTAMP;
# 输出结果为:2021-06-11 16:14:45SELECT CURRENT_TIME;
# 输出结果为:16:14:45SELECT CURRENT_DATE;
# 输出结果为:2021-06-11SELECT NOW();
# 输出结果为:2021-06-11 16:14:45SELECT CURDATE();
# 输出结果为:2021-06-11SELECT CURTIME();
# 输出结果为:16:14:45
来自:mysql如何获取当前时间
查看建表语句:
mysql> show create table t1;
+-------+------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+------------------------------------------------------------------------------------------------------------------------+
| t1 | CREATE TABLE `t1` (`a` int(11) DEFAULT NULL,`b` varchar(50) DEFAULT NULL,`last_update_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '该条信息的更新时间'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 |
+-------+------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
注意:当 update 的值和表里现有的值一样时 last_update_time 字段是不更新的。
修改用户密码:
-- 创建用户及密码
create user 'huiq'@'%' identified by 'huiq%123';-- 修改用户密码
mysql>set password for 'huiq'@'%' = password('huiq%123456');-- 删除用户
mysql>delete from mysql.user where user='huiq' and host='%';
-- 删除账户及权限(想删除用户的话一般用这种方式)
mysql>drop user 用户名@'%';mysql>flush privileges;
注:删除mysql的users_MySQL两种删除用户语句的区别(delete user和drop user)
查看所有用户:
mysql> select user,host from mysql.user;
+---------------+-----------------------+
| user | host |
+---------------+-----------------------+
| TBPM | % |
| root | 192.168.1.12 |
| mysql.session | localhost |
| mysql.sys | localhost |
| root | localhost |
+---------------+-----------------------+
5 rows in set (0.01 sec)
grant命令:
# 例1:增加一个test1用户,密码为123456,可以在任何主机上登录,并对所有数据库有查询,增加,修改和删除的功能。需要在mysql的root用户下进行
mysql>grant select,insert,update,delete on *.* to test1@"%" identified by "123456";
mysql>flush privileges;# 例2:增加一个test2用户,密码为123456,只能在192.168.2.12上登录,并对数据库student有查询,增加,修改和删除的功能。需要在mysql的root用户下进行
mysql>grant select,insert,update,delete on student.* to test2@192.168.2.12 identified by "123456";
mysql>flush privileges;# 例3:授权用户test3拥有数据库student的所有权限
mysql>grant all privileges on student.* to test3@localhost identified by '123456';
mysql>flush privileges;
# 注:如果已经有相应用户,identified by可不加;其中,关键字 “privileges” 可以省略。# 查看当前用户(自己)权限:
show grants;# 查看其他 MySQL 用户权限:
show grants for root@192.168.10.1;grant all on *.* to root@192.168.10.1;
# show grants for root@192.168.10.1;显示GRANT ALL PRIVILEGES ON *.* TO 'root'@'192.168.10.1'# 撤销已经赋予给 MySQL 用户权限的权限。revoke 跟 grant 的语法差不多,只需要把关键字 “to” 换成 “from” 即可:
revoke all on *.* from root@192.168.10.1;
# show grants for root@192.168.10.1;显示GRANT USAGE ON *.* TO 'root'@'192.168.10.1'
# 注:usage 特殊的“无权限”权限# 如果想在mysql.user表中不想存在该账户还得进行“删除账户及权限”
drop user root@192.168.10.1;
参考:mysql 创建用户,指定数据库,表的读写权限常用命令
判断当前数据库有多少连接数:
show full processlist;
问题:com.mysql.jdbc.exceptions.jdbc4.MySQLNonTransientConnectionException: Data source rejected establishment of connection, message from server: "Too many connections"
原因:数据库超过最大连接数了,查询当前最大连接数。(后来排查代码根本原因是创建的mysql连接并没有关闭。。。)
select VARIABLE_VALUE from performance_schema.global_variables where VARIABLE_NAME='MAX_CONNECTIONS';
+----------------+
| VARIABLE_VALUE |
+----------------+
| 800 |
+----------------+
1 row in set (0.00 sec)解决方案:
set global max_connections = 3600;
或者,要彻底解决问题还是要修改my.cnf配置文件,在“[mysqld]”下面添加“max_connections=1000”,执行:service mysql restart 重新启动MySQL服务
分组之前进行排序:
SELECT * FROM(SELECT * FROM biz_messageboard ORDER BY CREATETIME DESC) a GROUP BY a.USERID;
select * from goonie_article_view where id%2=1 and id < 3094578 ORDER BY id DESC limit 50
查询媒体名称为"小强日报"的数据量:
SELECT COUNT(*) FROM goonie_article_view WHERE SUBSTRING_INDEX(`goonie_article_view`.`mediaNameZh`,'-',1) = "小强日报";
SELECT * FROM beauty_article_view WHERE SUBSTRING_INDEX(`beauty_article_view`.`mediaNameZh`,'-',-1) = "旅游";SELECT * FROM goonie_article_view WHERE author LIKE "张%";SELECT COUNT(*) FROM goonie_article_view WHERE pubdate > "2018-05-09 18:00:00";SELECT * FROM beauty_article_view WHERE codename='礼仪' AND id BETWEEN 1216 AND 1318;
SELECT * FROM beauty_article_view WHERE codename='语录' OR codename='礼仪' AND id < 24658 ORDER BY id DESC LIMIT 50;
内连接:
SELECT COUNT(*) FROM goonie_article_view w INNER JOIN gooniewechat_key t ON w.`creator`=t.`weixin_name` WHERE w.`gather_time`>="2019-01-29";
去重:
SELECT COUNT(DISTINCT(codename)) FROM beauty_article_view;
SELECT DISTINCT(codename) FROM beauty_article_view;
Cast(字符串转数字):
一开始以为这样用就Ok,结果报错:

后来折腾了半天这样写才好使:select cast('12' as SIGNED);
参考:MySQL CAST函数
分割函数:
1. MySQL8 split
参考:mysql8 split函数
在 MySQL8 中,新增了一个非常实用的函数 split,它可以帮助我们将字符串按照指定的分隔符拆分成多个部分。语法如下:
split(str, delimiter, position)
- str:要拆分的字符串。
- delimiter:分隔符。
- position:可选参数,表示要返回的部分的索引,默认为1。
2. substring_index
但我的 Mysql 版本没有那么高不支持 split 函数,只能选择另一种方式了。
select version();
-- 5.7.36-log
参考:mysql 函数 substring_index 的用法
用法规则:
substring_index(“待截取有用部分的字符串”,“截取数据依据的字符”,截取字符的位置 N)
实例:
SELECT SUBSTRING_INDEX ('15,151,152,16',',',1);
==> 得到结果为: 15SELECT SUBSTRING_INDEX ('15,151,152,16',',',-1);
==> 得到结果为: 16SELECT SUBSTRING_INDEX (SUBSTRING_INDEX ('15,151,152,16',',',2),',',-1);
==> 得到结果为: 151SELECT SUBSTRING_INDEX (SUBSTRING_INDEX ('15,151,152,16',',',-2),',',1);
==> 得到结果为: 152
group by 1, 2:
select name,age,gender from person_inf where amout < 10000 group by 1,2
# 等于
select name,age,gender from person_inf where amout < 10000 group by name,age
group by 1,2的意思是根据select参数的第1、第2列进行分组
replace into:
replace into 主要作用类似 insert 插入操作。主要的区别是 replace 会根据主键或者唯一索引检查数据是否存在,如果存在就先删除再更新,不存在则直接新增记录。三种形式:
1. replace into tbl_name(col_name, ...) values(...)
2. replace into tbl_name(col_name, ...) select ...
3. replace into tbl_name set col_name=value, ...
mysql 中常用的三种插入数据的语句:
insert into表示插入数据,数据库会检查主键,如果出现重复会报错;replace into表示插入替换数据,需求表中有 PrimaryKey,或者 unique 索引,如果数据库已经存在数据, 则用新数据替换,如果没有数据效果则和insert into一样;insert ignore表示,如果中已经存在相同的记录,则忽略当前新数据;
来自:mysql中replace与replace into的用法
注意1:unique 索引一定要设置合理,在工作中使用 replace into 就遇到了本来想根据三个字段去插入数据,结果 unique 索引只设置了两个字段,这就导致本来想插入两个字段值一样另一个字段值不一样的五条数据,但不一样的那个字段没设置为 unique 索引,这就导致只插入了一条循环后的最后一条数据。
注意2:尽量使用下面的 ON DUPLICATE key update,工作中发现 replace into 会覆盖不指定字段的值,比如我更新字段1和2之前字段3的值为5,字段3设置的默认值为0,则 replace into 字段1, 字段2 后,字段3会变为0,下面的 ON DUPLICATE key update 就没有这个问题。
ON DUPLICATE key update:
有时候由于业务需求,可能需要先去根据某一字段值查询数据库中是否有记录,有且值不一样则更新,没有则插入。这个时候就可以用到 ON DUPLICATE key update 这个 sql 语句了。
insert into user (username,userpwd,num) values ("testName2","testPwd3",10)
ON DUPLICATE KEY UPDATE
username = VALUES(username),
userpwd = VALUES(userpwd)
参考:ON DUPLICATE key update的介绍与使用
扩展:MYSQL on duplicate key update和replace into 详解
DATEDIFF() 函数返回两个日期之间的时间:
SELECT DATEDIFF('2008-12-30','2008-12-28') AS DiffDate;
结果:2SELECT TIMESTAMPDIFF(DAY, '2022-01-05', '2022-01-01') AS date_diff;
结果:-4# 使用DATEDIFF和CASE语句计算两个日期的差值,可以灵活处理日期顺序
SELECT CASEWHEN '2022-01-01' > '2022-01-05' THEN DATEDIFF('2022-01-01', '2022-01-05')ELSE DATEDIFF('2022-01-05', '2022-01-01')END AS date_diff;# 使用TIMESTAMPDIFF和ABS函数计算两个日期的差值,无论日期的先后顺序
SELECT ABS(TIMESTAMPDIFF(DAY, '2022-01-01', '2022-01-05')) AS date_diff;
四舍五入:
参考:MySQL四舍五入
1. 函数ROUND(x)
ROUND(x) 函数返回最接近于参数 x 的整数,对 x 值进行四舍五入。
SELECT ROUND(-2.34),ROUND(-4.56),ROUND(2.34),ROUND(4.56);
结果:-2 -5 2 5
2. 函数ROUND(x,y)
ROUND(x,y) 函数返回最接近于参数 x 的数,其值保留到小数点后面 y 位,若 y 为负值,则将保留 x 值到小数点左边 y 位。
SELECT ROUND(3.45,1),ROUND(3.45,0),ROUND(123.45,-1),ROUND(167.8,-2);
结果:3.5 3 120 200实例:
update table set c_total_hour = round(hour,2) where length(hour) >8;
3. 函数TRUNCATE(x,y)
TRUNCATE(x,y) 函数返回被舍去至小数点后 y 位的数字 x。若y的值为0,则结果不带有小数点或不带有小数部分。若 y 设为负数,则截去(归零)x 小数点左起第 y 位开始后面所有低位的值。
SELECT TRUNCATE(2.34,1),TRUNCATE(4.56,1),TRUNCATE(4.56,0),TRUNCATE(56.78,-1);
结果:2.3 4.5 4 50
简单的增删改:
UPDATE afacebooktoken SET token='EAACEdEose0' where id=1;
DELETE FROM afacebooktoken WHERE id=1;
INSERT INTO afacebooktoken VALUES(1,'EAAL7AMi5Z');
beauty_article_view视图:
CREATE ALGORITHM=UNDEFINED DEFINER=`woman`@`%` SQL SECURITY DEFINER VIEW `beauty1_article_view` AS
select`a`.`id` AS `id`,`a`.`creator` AS `author`,`a`.`publish_time` AS `pubdate`,`a`.`site_code` AS `media_level`,`a`.`source` AS `trans_from_m`,`a`.`title` AS `titleZh`,`a`.`depth` AS `depth`,`a`.`location` AS `page_place_src`,`a`.`url` AS `url`,`a`.`content_finger` AS `finger`,`a`.`url_hash` AS `url_hash`,`d`.`content` AS `textZh`,`d`.`summary` AS `abstractZh`,`d`.`keywords` AS `keywordsZh`,`e`.`description` AS `codename`,`a`.`detriment` AS `detriment`,#`c`.`name` AS `mediaNameZh`,`a`.`gather_time` AS `gather_time`
from ((`gooniearticle` `a`join `gooniearticledetailed` `d`)join `goonienewssort` `e`)
where (`a`.`id` = `d`.`pid`)and (`d`.`infoid` = `e`.`id`)
order by `a`.`id`
创建库和表:
-- 创建库
CREATE DATABASE `active_modle` DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;-- 删除库
drop database active_modle;-- 创建表
CREATE TABLE `biz_reply` (`id` BIGINT(64) NOT NULL AUTO_INCREMENT,`userid` VARCHAR(255) DEFAULT NULL COMMENT '用户id',`shopid` VARCHAR(200) DEFAULT '' COMMENT '商家id',`recontent` VARCHAR(1000) DEFAULT '' COMMENT '留言内容',`createId` VARCHAR(32) DEFAULT NULL COMMENT '创建人',`createTime` DATETIME DEFAULT NULL COMMENT '创建时间',PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8;
-- CHARSET=utf8mb4能存储Emoji表情-- 增加字段
ALTER table mysql_into_hbase add execute_sql text COMMENT 'ods层到dwd层的执行语句';
-- 删除字段
alter table mysql_into_hbase drop execute_sql;-- 表名称的修改
alter table mysql_into_hbase rename oracle_into_hbase;-- 删除表
drop table biz_reply;
增删字段可参考:入门必看!mysql数据表添加字段的方法!
create、insert 和 select 相结合:
create table `heheda_tmp` as select * from heheda limit 10;
insert into `heheda_tmp`(message_id,project,file_date,create_time) select message_id,project,file_date,create_time from heheda limit 10;
查询数据库中所有表名或者表的所有字段名:
-- 查询数据库中所有表名
select table_name from information_schema.tables where table_schema='data_warehouse' and table_type='base table';-- 查询指定数据库中指定表的所有字段名column_name
select column_name from information_schema.columns where table_schema='data_warehouse' and table_name='dw_4029_manage';
索引:
-- 创建普通索引:
CREATE INDEX t_grhx_grbq_index ON t_grhx_grbq(sfzhm);-- 查看索引:
show index from t_grhx_grbq;
日期和字符相互转换:
date_format(date,'%Y-%m-%d') -------------->oracle中的to_char();str_to_date(date,'%Y-%m-%d') -------------->oracle中的to_date();%Y:代表4位的年份%y:代表2为的年份%m:代表月, 格式为(01……12)%c:代表月, 格式为(1……12)%d:代表月份中的天数,格式为(00……31)%e:代表月份中的天数, 格式为(0……31)%H:代表小时,格式为(00……23)%k:代表 小时,格式为(0……23)%h: 代表小时,格式为(01……12)%I: 代表小时,格式为(01……12)%l :代表小时,格式为(1……12)%i: 代表分钟, 格式为(00……59)%r:代表 时间,格式为12 小时(hh:mm:ss [AP]M)%T:代表 时间,格式为24 小时(hh:mm:ss)%S:代表 秒,格式为(00……59)%s:代表 秒,格式为(00……59)SELECT DATE_FORMAT(20130111191640,'%Y-%m-%d %H:%i:%s')DATE_FORMAT(20130111191640,'%Y-%m-%d %H:%i:%s')
\g 和 \G:
\g等价于;,如下实例:
mysql> select * from t3\g
+------+----------+----------+-------+------------+---------------------+
| id | username | password | money | birthday | cztime |
+------+----------+----------+-------+------------+---------------------+
| 1 | 用户1 | 12346 | 500 | 1995-05-20 | 2018-07-30 09:40:30 |
+------+----------+----------+-------+------------+---------------------+
1 rows in set (0.00 sec)mysql> select * from t3;
+------+----------+----------+-------+------------+---------------------+
| id | username | password | money | birthday | cztime |
+------+----------+----------+-------+------------+---------------------+
| 1 | 用户1 | 12346 | 500 | 1995-05-20 | 2018-07-30 09:40:30 |
+------+----------+----------+-------+------------+---------------------+
1 rows in set (0.00 sec)
\G将查询到的横向表格纵向输出,方便阅读:
如下实例:
mysql> show create table t4;
+——-+————————————————————————————————————————————————————-+
| Table | Create Table |
+——-+————————————————————————————————————————————————————-+
| t4 | CREATE TABLE t4 (
id int(11) DEFAULT NULL,
username varchar(20) DEFAULT NULL,
money int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
+——-+————————————————————————————————————————————————————-+
1 row in set (0.00 sec)mysql> show create table t4\G
***************** 1. row *****************
Table: t4
Create Table: CREATE TABLE t4 (
id int(11) DEFAULT NULL,
username varchar(20) DEFAULT NULL,
money int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)ERROR:
No query specified
开窗函数:
说明:开窗函数与聚合函数一样,也是对行集组进行聚合计算,但是它不像普通聚合函数那样每组只返回一个值,开窗函数可以为每组返回多个值,因为开窗函数所执行聚合计算的行集组是窗口。
语法:
主要是over( PARTITION BY (根据某条件分组,形成一个小组)….ORDER BY(再组内进行排序) …. )
常用函数:
参考:https://www.bbsmax.com/A/q4zVkPLxJK/
1、row_number() over(partition by … order by …)
2、rank() over(partition by … order by …)
3、dense_rank() over(partition by … order by …)
rank(): 跳跃排序,如果有两个第一级时,接下来就是第三级。
dense_rank(): 连续排序,如果有两个第一级时,接下来仍然是第二级。
4、count() over(partition by … order by …)
5、max() over(partition by … order by …)
6、min() over(partition by … order by …)
7、sum() over(partition by … order by …)
8、avg() over(partition by … order by …)
9、first_value() over(partition by … order by …)
10、last_value() over(partition by … order by …)
11、lag() over(partition by … order by …)
12、lead() over(partition by … order by …)
lag 和lead 可以 获取结果集中,按一定排序所排列的当前行的上下相邻若干offset 的某个行的某个列(不用结果集的自关联);
lag ,lead 分别是向前,向后;
lag 和lead 有三个参数,第一个参数是列名,第二个参数是偏移的offset,第三个参数是 超出记录窗口时的默认值)
但是:mysql 8.0版本以下并不支持,只能通过变通的方法实现相同的功能
(1)实现自增:
SELECT@num := @num+1 score_ranking,id
FROM`user`, (SELECT @num := 0) t1
ORDER BYid DESC;
(2)实现rank():
参考:https://blog.csdn.net/justry_deng/article/details/80597916
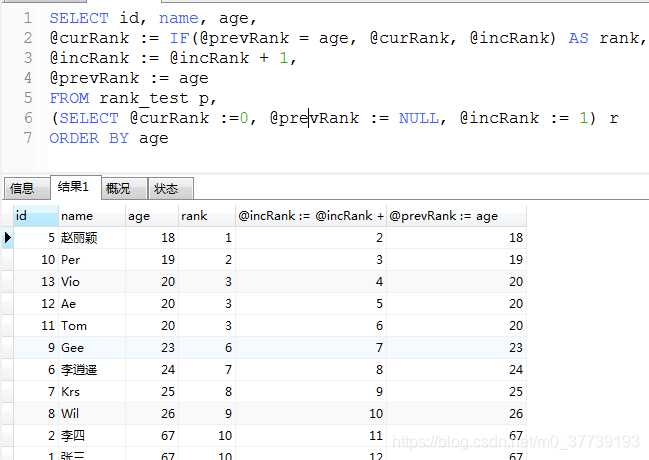
(3)8.0版本以上实现rank():rank()、row_number()、dense_rank()
参考:https://blog.csdn.net/sqsltr/article/details/94408487
create table students(id int(4) auto_increment primary key,name varchar(50) not null, score int(4) not null);insert into students(name,score) values('curry', 100),('klay', 99),('KD', 100), ('green', 90), ('James', 99), ('AD', 96);select id, name, rank() over(order by score desc) as r from students;
select id, name, DENSE_RANK() OVER(order by score desc) as dense_r from students;
select id, name, row_number() OVER(order by score desc) as row_r from students;
if函数:
语法: if(boolean testCondition, T valueTrue, T valueFalseOrNull)
说明: 当条件testCondition为TRUE时,返回valueTrue;否则返回valueFalseOrNullmysql和hive都适用
实例1:
select if(hehe='小强',1,2) as flag from t_xiaoqiang;实例2:
select if(haha is not null,'hehe',123) from t_xiaoqiang;
经纬度转换:
度分秒转经纬度:
- 度分秒:120°13’52"
- 整数部分:120直接读取
- 小数部分:13/60=0.21666666666666667,52/3600=0.01444444,0.216666+0.0144=0.231111
- 结果:120.231111
经纬度转度分秒:
- 度数:113.211
- 度:113直接读取
- 分:0.211*60=12.66,读取12
- 秒:0.66*60=39.6
- 结果:113°12’39.6"
相关sql:
SELECT 22+FORMAT(35/60+34.62/3600,6) JD;
# 结果为:22.59295
注意:在 Doris 中 FORMAT 函数不存在,所以只能用 round 函数,结果和上面相同,不会显示末尾的0,但是 mysql 使用 round 函数末尾会显示0。
-- mysql
SELECT 22+ROUND(35/60+34.62/3600,6) JD;
# 结果为:22.592950-- doris
SELECT 22+ROUND(35/60+34.62/3600,6) JD;
# 结果为:22.59295
需要注意的点:
1.在做多表查询,或者查询的时候产生新的表的时候会出现这个错误:Every derived table must have its own alias(每一个派生出来的表都必须有一个自己的别名,同样适用于SqlServer)。
2.同级生成的别名字段不可以使用,只能嵌套使用(这样感觉增加了语句量,在Gauss是可以做到的)
mysql:
SELECTa.hehe heheda,heheda*12
FROMhaha a;-- 报错:Unknown column 'heheda' in 'field list'
Gauss:
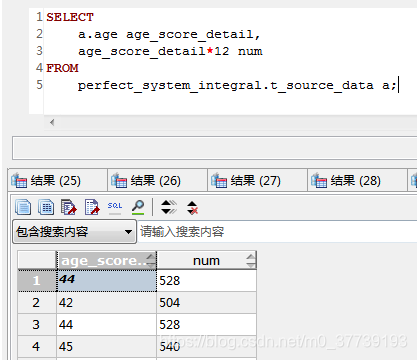
查询数据库中的存储过程和函数:
select `name` from mysql.proc where db = 'test_schema1' and `type` = 'PROCEDURE'; //存储过程
select `name` from mysql.proc where db = 'test_schema1' and `type` = 'FUNCTION'; //函数
INTERVAL关键字和INTERVAL()函数:
来自:一文速学-玩转MySQL中INTERVAL关键字和INTERVAL()函数用法讲解
1. INTERVAL关键字
语法:
interval [+/-]<数值> <时间单位># 例如
interval 3 dayselect (create_time-INTERVAL 3 day) as time from value_test;
# 等于
select (create_time+INTERVAL -3 day) as time from value_test;
时间单位表为:
| 时间单位 | 描述 |
|---|---|
| year | 年 |
| quarter | 季度 |
| month | 月 |
| week | 周 |
| day | 天 |
| hour | 小时 |
| minute | 分钟 |
| second | 秒 |
| microsecond | 微秒 |
| second_microsecond | 秒_微秒 |
| minute_microsecond | 分_微秒 |
| minute_second | 分_秒 |
| hour_microsecond | 时_微秒 |
| hour_second | 时_秒 |
| hour_minute | 时_分 |
| day_microsecond | 天_微秒 |
| day_second | 天_秒 |
| day_minute | 天_分钟 |
| day_hour | 天_小时 |
| year_month | 年_月 |
如果我们想要在原基础上加上1小时10分钟10秒:
select (create_time+INTERVAL '1:10:10' hour_second) as time from value_test;# 这里要注意一下指定的时间单位向下兼容性,当我们选择的是hour_second小时到秒时,输入的数值仅为两个数值(会自动识别为10分10秒),例如:
select (create_time+INTERVAL '10:10' hour_second) as time from value_test;
# 其他的连续时间段表示单位也都一样(识别成了10小时10分10秒),例如:
select (create_time+INTERVAL '10:10:10' day_second) as time from value_test;
interval 一般使用场景都在场景筛选中使用,比如 where 的条件判断,或者是筛选、去一段指定的时间片段。如取近七日的时间段的数据:
and time between cast(date_sub(date_format(curdate(),'%Y%m%d')
, interval 7 day) as DECIMAL)
and cast(date_sub(date_format(curdate(),'%Y%m%d') , interval 1 day)
as DECIMAL)# 或者(file_date为date格式,如2023-12-08)
where bb.file_date between DATE_SUB(aa.max_file_date, INTERVAL 7 DAY) and aa.max_file_date
2. INTERVAL() 函数
在 MySQL 输入 interval() 函数就会显示相应的语法格式:
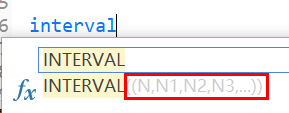
INTERVAL() 函数为分区函数,其中,N是要判断的数值,N1,N2,N3,... 是分段的间隔。
这个函数的返回值是段的位置:
- 如果N<N1,则返回0,
- 如果N1<=N<N2,则返回1,
- 如果N2<=N<N3,则返回2。
- 区间是左闭右开的。
我们想要把 time 列的时间归类为 20220601-20220610 为一个区域,20220611-20220620 为一个区域,20220621-20220630 为一个区域,每隔10天为一个分区。
select INTERVAL(time,20220611,20220621,20220631) as time from value_test
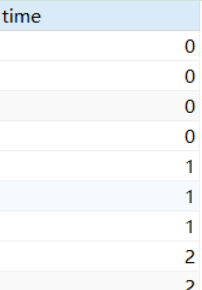
分完区之后一般进行统计,就可以得到对应区间的个数了:
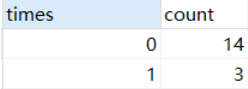
select INTERVAL(time,20220611,20220621,20220631) as times ,count(*) as count
from value_test
GROUP BY times
创建日期维度表:
参考:hive数仓里建立日期维表、MySQL 如何生成日期表
先创建表:
CREATE TABLE `dim_date` (`date_id` bigint(8) DEFAULT NULL,`date` date DEFAULT NULL,`date_cn` varchar(20) DEFAULT NULL,`WEEK_CN` varchar(20) DEFAULT NULL,`WEEK_OF_YEAR_CN` varchar(20) DEFAULT NULL,`MONTH` varchar(20) DEFAULT NULL,`MONTH_CN` varchar(20) DEFAULT NULL,`QUARTER` varchar(20) DEFAULT NULL,`QUARTER_CN` varchar(20) DEFAULT NULL,`YEAR_CN` varchar(20) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
创建存储过程并执行:
delimiter $$ #将语句的结束符号从分号;临时改为两个$$(可以是自定义)
create procedure p_dim_date(in start_date VARCHAR(20),in date_count int)
begindeclare i int;set i=0;DELETE from dim_date;while i<date_count doINSERT into dim_date(date_id,date,date_cn,WEEK_CN,WEEK_OF_YEAR_CN,MONTH,MONTH_CN,QUARTER,QUARTER_CN,YEAR_CN)SELECT REPLACE(start_date,'-','') date_id,DATE_FORMAT(STR_TO_DATE(start_date,'%Y-%m-%d %H:%i:%s'),'%Y-%m-%d') date,DATE_FORMAT(STR_TO_DATE(start_date,'%Y-%m-%d %H:%i:%s'),'%Y年%m月%d日') date_cn,case dayofweek(STR_TO_DATE(start_date,'%Y-%m-%d %H:%i:%s')) when 1 then '星期日' when 2 then '星期一' when 3 then '星期二' when 4 then '星期三' when 5 then '星期四' when 6 then '星期五' when 7 then '星期六' end WEEK_CN,DATE_FORMAT(STR_TO_DATE(start_date,'%Y-%m-%d %H:%i:%s'),'%Y年第%u周') WEEK_OF_YEAR_CN,DATE_FORMAT(STR_TO_DATE(start_date,'%Y-%m-%d %H:%i:%s'),'%Y-%m') MONTH,DATE_FORMAT(STR_TO_DATE(start_date,'%Y-%m-%d %H:%i:%s'),'%Y年第%m月') MONTH_CN,CONCAT(DATE_FORMAT(STR_TO_DATE(start_date,'%Y-%m-%d %H:%i:%s'),'%Y'),'Q',quarter(STR_TO_DATE( start_date,'%Y-%m-%d %H:%i:%s'))) QUARTER,CONCAT(DATE_FORMAT(STR_TO_DATE(start_date,'%Y-%m-%d %H:%i:%s'),'%Y'),'年第',quarter(STR_TO_DATE(start_date,'%Y-%m-%d %H:%i:%s')),'季度') QUARTER_CN,DATE_FORMAT(STR_TO_DATE(start_date,'%Y-%m-%d %H:%i:%s'),'%Y年') YEAR_CNfrom dual;set i=i+1;set start_date = DATE_FORMAT(date_add(STR_TO_DATE(start_date,'%Y-%m-%d %H:%i:%s'),interval 1 day),'%Y-%m-%d');end while;
end$$call p_dim_date('2018-01-01',365)

注:执行存储过程的时候得加delimiter $$,参考:MySQL 存储过程,否则报错

从库binlog报错:
问题:我在程序中先truncate t2再insert into t2 select * from t1主库的一张表后报错:Duplicate entry '1' for key 'PRIMARY', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log mysql-bin.000059, end_log_pos 183416832

解决:把程序里的truncate table换成了delete from table就可以了。相应的表结构(t1和t2表结构一样):
CREATE TABLE `t2` (`id` bigint(18) NOT NULL,`ch_name` varchar(64) NOT NULL,`remark` varchar(255) DEFAULT NULL COMMENT '备注',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
json:
参考:https://blog.csdn.net/lianghecai52171314/article/details/121742377
MySQL 里的 json 分为 json array 和 json object。
| 分类 | 函数 | 描述 |
|---|---|---|
| 创建json | json_array | 创建json数组 |
| json_object | 创建json对象 | |
| json quote | 将json转成json字符串类型 | |
| 查询json | json_contains | 判断是否包含某个json值 |
| json_contains_path | 判断某个路径下是否包含json值 | |
| json_extract | 提取json值 | |
| column->path | json_extract的简洁写法,Mysql 5.7.9开始支持 | |
| column->>path | json_unquote(column -> path)的简洁写法 | |
| json_keys | 提取json中的键值为json数组 | |
| json_search | 按给定字符串关键字搜索json,返回匹配的路径 |
示例:
SELECT json_extract('{"id":1,"nickName":"小强"}','$.nickName');
# 返回结果:"小强"SELECT json_object("name","xiaoyu","old",12,"height","165.1");
# 返回结果:{"old": 12, "name": "xiaoyu", "height": "165.1"}
创建测试表和数据:
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;-- ----------------------------
-- Table structure for tb_emp
-- ----------------------------
DROP TABLE IF EXISTS `tb_emp`;
CREATE TABLE `tb_emp` (`id` int(0) NOT NULL AUTO_INCREMENT COMMENT '员工编号',`ename` varchar(12) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '员工姓名',`info` json NULL COMMENT '员工信息',PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;-- ----------------------------
-- Records of tb_emp
-- ----------------------------
INSERT INTO `tb_emp` VALUES (1, 'SMITH', '{\"job\": \"CLERK\", \"mgr\": 7902, \"sal\": 800.0, \"comm\": null, \"empno\": 7369, \"ename\": \"SMITH\", \"deptno\": 20, \"hiredate\": 345830400000}');
INSERT INTO `tb_emp` VALUES (2, 'ALLEN', '{\"job\": \"SALESMAN\", \"mgr\": 7698, \"sal\": 1600.0, \"comm\": 300.0, \"empno\": 7499, \"ename\": \"ALLEN\", \"deptno\": 30, \"hiredate\": 351446400000}');
INSERT INTO `tb_emp` VALUES (3, 'WARD', '{\"job\": \"SALESMAN\", \"mgr\": 7698, \"sal\": 1250.0, \"comm\": 500.0, \"empno\": 7521, \"ename\": \"WARD\", \"deptno\": 30, \"hiredate\": 351619200000}');
INSERT INTO `tb_emp` VALUES (4, 'JONES', '{\"job\": \"MANAGER\", \"mgr\": 7839, \"sal\": 2975.0, \"comm\": null, \"empno\": 7566, \"ename\": \"JONES\", \"deptno\": 20, \"hiredate\": 354988800000}');
INSERT INTO `tb_emp` VALUES (5, 'MARTIN', '{\"job\": \"SALESMAN\", \"mgr\": 7698, \"sal\": 1250.0, \"comm\": 1400.0, \"empno\": 7654, \"ename\": \"MARTIN\", \"deptno\": 30, \"hiredate\": 370454400000}');
INSERT INTO `tb_emp` VALUES (6, 'BLAKE', '{\"job\": \"MANAGER\", \"mgr\": 7839, \"sal\": 2850.0, \"comm\": null, \"empno\": 7698, \"ename\": \"BLAKE\", \"deptno\": 30, \"hiredate\": 357494400000}');
INSERT INTO `tb_emp` VALUES (7, 'CLARK', '{\"job\": \"MANAGER\", \"mgr\": 7839, \"sal\": 2450.0, \"comm\": null, \"empno\": 7782, \"ename\": \"CLARK\", \"deptno\": 10, \"hiredate\": 360864000000}');
INSERT INTO `tb_emp` VALUES (8, 'SCOTT', '{\"job\": \"ANALYST\", \"mgr\": 7566, \"sal\": 3000.0, \"comm\": null, \"empno\": 7788, \"ename\": \"SCOTT\", \"deptno\": 20, \"hiredate\": 545756400000}');
INSERT INTO `tb_emp` VALUES (9, 'KING', '{\"job\": \"PRESIDENT\", \"mgr\": null, \"sal\": 5000.0, \"comm\": null, \"empno\": 7839, \"ename\": \"KING\", \"deptno\": 10, \"hiredate\": 374774400000}');
INSERT INTO `tb_emp` VALUES (10, 'TURNER', '{\"job\": \"SALESMAN\", \"mgr\": 7698, \"sal\": 1500.0, \"comm\": 0.0, \"empno\": 7844, \"ename\": \"TURNER\", \"deptno\": 30, \"hiredate\": 368726400000}');
INSERT INTO `tb_emp` VALUES (11, 'ADAMS', '{\"job\": \"CLERK\", \"mgr\": 7788, \"sal\": 1100.0, \"comm\": null, \"empno\": 7876, \"ename\": \"ADAMS\", \"deptno\": 20, \"hiredate\": 548694000000}');
INSERT INTO `tb_emp` VALUES (12, 'JAMES', '{\"job\": \"CLERK\", \"mgr\": 7698, \"sal\": 950.0, \"comm\": null, \"empno\": 7900, \"ename\": \"JAMES\", \"deptno\": 30, \"hiredate\": 376156800000}');
INSERT INTO `tb_emp` VALUES (13, 'FORD', '{\"job\": \"ANALYST\", \"mgr\": 7566, \"sal\": 3000.0, \"comm\": null, \"empno\": 7902, \"ename\": \"FORD\", \"deptno\": 20, \"hiredate\": 376156800000}');
INSERT INTO `tb_emp` VALUES (14, 'MILLER', '{\"job\": \"CLERK\", \"mgr\": 7782, \"sal\": 1300.0, \"comm\": null, \"empno\": 7934, \"ename\": \"MILLER\", \"deptno\": 10, \"hiredate\": 380563200000}');SET FOREIGN_KEY_CHECKS = 1;
# 查看所有员工的编号、名称、工作、薪水
SELECT id,ename,info->'$.job',info->'$.sal' from tb_emp;
SELECT id,ename,JSON_EXTRACT(info,'$.job'),JSON_EXTRACT(info,'$.sal') from tb_emp;
SELECT id,ename,JSON_EXTRACT(info,'$.job','$.sal') from tb_emp;# 查询id值为7788的员工的名称是否为SCOTT
SELECT JSON_CONTAINS(info,'{"ename":"SCOTT"}')
from tb_emp
WHERE id= 8# 查询指定字段中是否包含ename和dno中的任何一个
SELECT JSON_CONTAINS_PATH(info, 'one','$.ename','$.dno')
from tb_emp
WHERE id= 8# 查询指定字段中是否同时包含ename和dno
SELECT JSON_CONTAINS_PATH(info, 'all','$.ename','$.dno')
from tb_emp
WHERE id= 8# 查询部门编号为10的员工的详细信息
select * from tb_emp where info->'$.deptno'=10;# 查询部门编号为10且mgr为null的员工的详细信息
select * from tb_emp where info->'$.deptno'=10 and info->'$.ename'='CLARK';# 查询部门编号为10且id为7的员工的详细信息
select * from tb_emp where info->'$.deptno'=10 and id =7;# 查询薪水大于3000的员工的信息
select * from tb_emp where JSON_EXTRACT(info, '$.sal')>3000;# 查询薪水等于5000的员工的信息
select * from tb_emp where JSON_CONTAINS(info, JSON_OBJECT('sal',5000));# 查询JSON字段中所有的键
select JSON_KEYS(info) FROM tb_emp;
注:在 Mysql 8.0(Mysql 5.7.22) 增加了两个聚合函数:json_arrayagg() 和 json_objectagg()