江南可采莲,莲叶何田田。鱼戏莲叶间。鱼戏莲叶东,鱼戏莲叶西,鱼戏莲叶南,鱼戏莲叶北。 — 两汉·汉乐府《江南》

这篇博客我们将会讲解一些习题,习题是有关于数组和指针的,数组方面的习题也能帮助我们更好的理解sizeof和strlen,指针的习题也全方位锻炼我们对指针的理解。

目录
- 一维数组🍀
- 字符数组🐽
- 二维数组🦑
- 指针试题(共8道)
- 一二题
- 三四题
- 五六题
- 七八题
- 总结😈
一维数组🍀
//一维数组
int a[] = {1,2,3,4};
printf("%d\n",sizeof(a));
printf("%d\n",sizeof(a+0));
printf("%d\n",sizeof(*a));
printf("%d\n",sizeof(a+1));
printf("%d\n",sizeof(a[1]));
printf("%d\n",sizeof(&a));
printf("%d\n",sizeof(*&a));
printf("%d\n",sizeof(&a+1));
printf("%d\n",sizeof(&a[0]));
printf("%d\n",sizeof(&a[0]+1));
解析
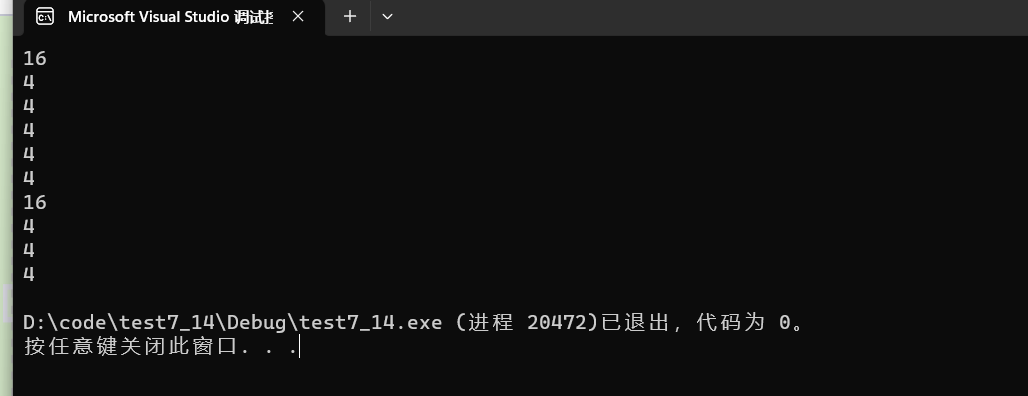
- sizeof(a):sizeof中如果放的是数组名,则为求整个数组的大小,所以应该是
16 - sizeof(a+0):sizeof()中放的是a+0,也就是首数组名+0,数组名+0得到数组首元素的地址,所以这里是求地址的大小,
在32位下是4,在64位下是8。 - sizeof(*a):*a代表着,a地址的元素,这个元素的类型是int,所以大小为
4。 - sizeof(a+1):与第二个差不多,a+1得到第二个元素的地址,
求地址的大小在32位下是4,在64位下是8。 - sizeof(a[1]):a[1]就是第二个元素,第二个元素的类型是int,所以结果是
4 - sizeof(&a):&a的地址实际上就是取出整个数组的地址,但是也还是地址,所以在
32位下是4,在64位下是8。 - sizeof(*&a):上面一题我们知道&a是取出整个数组的地址,但是这里又多了一个 *,就相当于先取地址然后再解引用,两个相互抵消了。还有一种理解就是数组整个地址的解引用就相当于是整个数组(sizeof(a)),所以是
16 - sizeof(&a+1):这里其实是也有一个知识点就是,&(取地址)操作符是比+号(不是正号)这个操作符的优先级要高的,所以就相当于拿到整个数组的地址再+1,就跳过一个数组的长度。但还是地址,大小在
32位下是4,在64位下是8。 - sizeof(&a[0]):我们知道[]的优先级是高于&的,就是相当于取出第一个元素的地址然后&,但是也还是地址,是地址的话大小在
32位下是4,在64位下是8。 - sizeof(&a[0]+1):跟上面可以说是一个的就只是地址加了1,是地址的话大小在
32位下是4,在64位下是8。
字符数组🐽
接下来是字符数组
int main()
{//字符数组char arr[] = { 'a','b','c','d','e','f' };printf("%d\n", sizeof(arr));printf("%d\n", sizeof(arr + 0));printf("%d\n", sizeof(*arr));printf("%d\n", sizeof(arr[1]));printf("%d\n", sizeof(&arr));printf("%d\n", sizeof(&arr + 1));printf("%d\n", sizeof(&arr[0] + 1));
}
解析
- sizeof(arr):还是老规矩,sizeof内放数组名求的是数组整个的大小,数组里放的是全是字符而不是字符串,所以一共6个字符,一共字符大小为1字节最终结果就是
6。 - sizeof(arr + 0):这里放的就不是一个单纯的数组名了,而是一个首地址+0,还是首地址,是地址那么在
32位下就是4,64位下就是8。 - sizeof(*arr):这个也不是单纯的一个数组名,数组名代表的是首元素地址,首元素地址解引用得到的就是首元素,首元素的类型是char,那么大小就为
1。 - sizeof(arr[1]):arr[1]就代表第二个元素,那么大小就是
1。 - sizeof(&arr)):&取出的还是地址,是地址那么在
32位下就是4,64位下就是8。 - sizeof(&arr + 1):依然还是地址,是地址那么在
32位下就是4,64位下就是8。 - sizeof(&arr[0] + 1):&arr[0],就是取出第一个元素的地址,第一个元素的地址+1,也是地址,是地址那么在
32位下就是4,64位下就是8。
来看看strlen
int main()
{
char arr[] = {'a','b','c','d','e','f'};
printf("%d\n", strlen(arr));
printf("%d\n", strlen(arr+0));
printf("%d\n", strlen(*arr));
printf("%d\n", strlen(arr[1]));
printf("%d\n", strlen(&arr));
printf("%d\n", strlen(&arr+1));
printf("%d\n", strlen(&arr[0]+1));
}
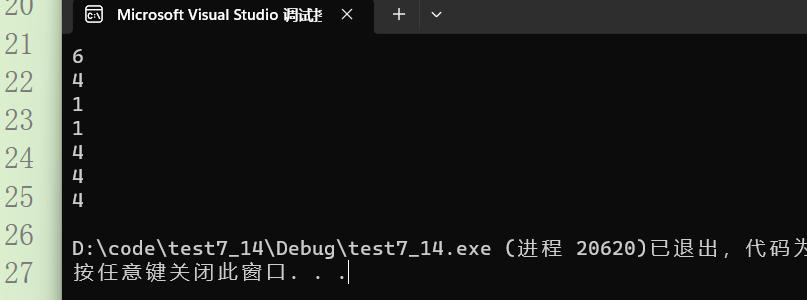
- strlen(arr):我们知道strlen是求字符串长度的,返回从参数的地址到\0之间的字符个数,但是我们的
数组里面放的是字符并不是字符串,那怎么办呢?其实\0的ASCII码值就是0(字符'0'的是48),也就是说strlen会从数组首元素地址开始从内存中找0,但我们是不知道什么时候能找到的,所以是一个随机值。 - strlen(arr+0):与上面的是一致的都是首元素地址。是一个
随机值。 - strlen(*arr):这里就有得一说了,我们知道strlen里一般放的都是字符数组的地址,而这里*arr就相当于arr[0],而’a’代表的ASCII码是97,这里又是什么意思呢?也就说strlen是要从地址97开始往后找0,但是我们的操作系统有一个规定:在大多数操作系统中,0到某个特定值之间的地址被保留给内核使用,称为内核地址空间。这个特定值可以因操作系统和硬件架构而异,但通常是一个较低的地址。所以这里就会出现野指针,这是一行错误代码。
error - strlen(arr[1]):与上一个一致是
error。 - strlen(&arr):&arr和arr在地址的值上都是一样的所以也是随机值。并且这两个
随机值是相当的。 - strlen(&arr+1):还是地址,但是+1了,应该是随机值
-1。吗?,注意这里是&arr,我们知道&arr的类型数组指针,也就是要跳过一个数组,所以这里一个是随机值-6 - strlen(&arr[0]+1):仍然是首元素地址+1,由于这里是取出元素的地址,所以+1是跳过一个字节,还是随机值
-1。
最后两个的细节要注意,不要只知道无法运行。

接下来就是字符串了。
int main()
{char arr[] = "abcdef";printf("%d\n", sizeof(arr));printf("%d\n", sizeof(arr + 0));printf("%d\n", sizeof(*arr));printf("%d\n", sizeof(arr[1]));printf("%d\n", sizeof(&arr));printf("%d\n", sizeof(&arr + 1));printf("%d\n", sizeof(&arr[0] + 1));printf("%d\n", strlen(arr));printf("%d\n", strlen(arr + 0));printf("%d\n", strlen(*arr));printf("%d\n", strlen(arr[1]));printf("%d\n", strlen(&arr));printf("%d\n", strlen(&arr + 1));printf("%d\n", strlen(&arr[0] + 1));
}
- sizeof(arr):我们知道字符串末尾其实有一个’\0’,它也是要占一个字节的。所以这个数组的总大小就是
7。 - sizeof(arr + 0):现在不是只有数组名了,而arr+0就代表着首元素地址,是地址
32位下是4,64位下是8。 - sizeof(*arr):首元素地址解引用得到首元素,首元素类型为char,所以大小为
1。 - sizeof(arr[1]):第二个元素的地址解引用得到的是第二个元素,同上大小为
1。 - sizeof(&arr):取出arr整个数组的地址,但是在数值上就是首元素地址,是地址
32位下是4,64位下是8。 - sizeof(&arr + 1):&arr+1,就是地址跳过一个数组大小,还是地址,是地址
32位下是4,64位下是8。 - sizeof(&arr[0] + 1):注意这里是+1的类型与上面不同这里是&arr[0],也就是说+1加一个元素。是地址
32位下是4,64位下是8。
char arr[] = "abcdef";printf("%d\n", strlen(arr));printf("%d\n", strlen(arr + 0));printf("%d\n", strlen(*arr));printf("%d\n", strlen(arr[1]));printf("%d\n", strlen(&arr));printf("%d\n", strlen(&arr + 1));printf("%d\n", strlen(&arr[0] + 1));
然后是剩下的strlen的。
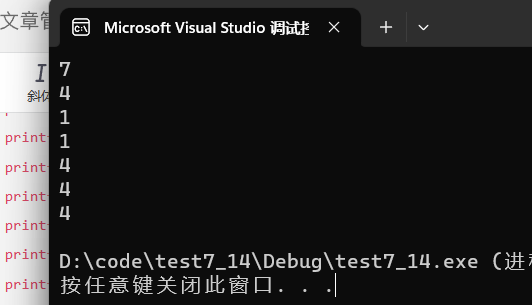
- strlen(arr):是标准的用法,这里属于是字符串而不是字符,从首元素到\0之前的元素是abcdef,一共6个,也就是说字符串长度为
6。 - strlen(arr + 0):同上一样是首元素地址,没有太大区别。
6。 - strlen(arr)):这里arr就相当于arr[0],而’a’代表的ASCII码是97,这里又是什么意思呢?也就说strlen是要从地址97开始往后找0,但是我们的操作系统有一个规定**:在大多数操作系统中,0到某个特定值之间的地址被保留给内核使用,称为内核地址空间。这个特定值可以因操作系统和硬件架构而异,但通常是一个较低的地址。所以这里就会出现野指针,这是一行错误代码。
error - strlen(arr[1]):是’b’同上。
error。 - strlen(&arr):取地址数组名,就是首元素地址,从首元素地址到\0,长度是
6个字节。
-strlen(&arr + 1):这个就有点不一样了,&arr就是取出整个数组的地址,整个数组地址的类型是数组指针,数组指针+1一个跳过一个数组大小,所以这个是随机值。
strlen(&arr[0] + 1):还是老生常谈的问题,&arr[0]就是首元素地址,首元素地址可以看出类型就是char *类型,char *类型+1也只是跳过一个字节。所以跳过了’a’,剩下的长度就是5。
然后来看看指针与字符串结合。
char *p = "abcdef";
printf("%d\n", sizeof(p));
printf("%d\n", sizeof(p+1));
printf("%d\n", sizeof(*p));
printf("%d\n", sizeof(p[0]));
printf("%d\n", sizeof(&p));
printf("%d\n", sizeof(&p+1));
printf("%d\n", sizeof(&p[0]+1));printf("%d\n", strlen(p));
printf("%d\n", strlen(p+1));
printf("%d\n", strlen(*p));
printf("%d\n", strlen(p[0]));
printf("%d\n", strlen(&p));
printf("%d\n", strlen(&p+1));
printf("%d\n", strlen(&p[0]+1));
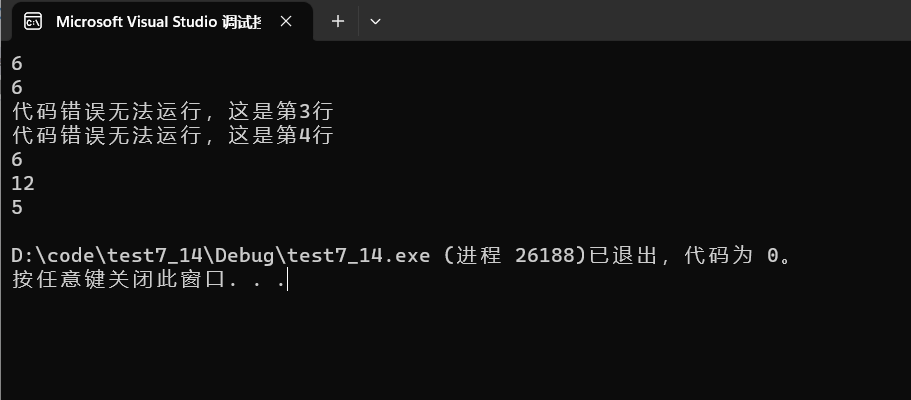
- sizeof ( p):注意这里并不是数组了,而是指针指向内存中存储的一个字符串,p存储字符串的首字符地址,是地址那么在
32位下是4,64位下是8。 - sizeof(p+1):这里与上面基本一致,不过是第二个字符的地址,是地址那么在
32位下是4,64位下是8。 - sizeof(*p):p是字符串首字符地址,然后 * p就是拿到首字符,首字符的类型是char,故大小为
1。 - sizeof(p[0]):和上面一样都是首字符,首字符的类型是char,故大小为
1。 - sizeof(&p):取出p变量的地址,还是地址,是地址那么在
32位下是4,64位下是8。 - sizeof(&p+1):取出p的地址再+1,由于p的类型是char *,+1也只是+1字节,但是归根到底还是地址,是地址那么在
32位下是4,64位下是8。 - sizeof(&p[0]+1):任然是地址,是地址那么在
32位下是4,64位下是8。
char *p = "abcdef";
printf("%d\n", strlen(p));
printf("%d\n", strlen(p+1));
printf("%d\n", strlen(*p));
printf("%d\n", strlen(p[0]));
printf("%d\n", strlen(&p));
printf("%d\n", strlen(&p+1));
printf("%d\n", strlen(&p[0]+1));
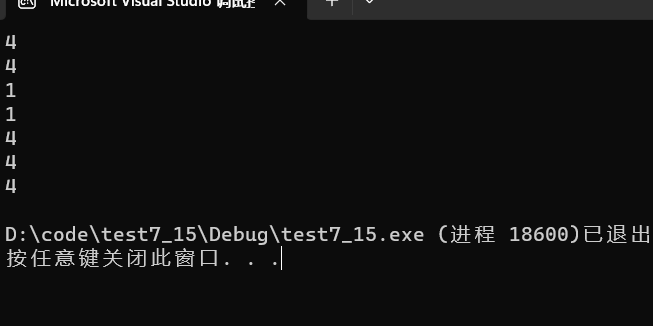
- strlen( p):p中存储的是这个字符串的首字符地址,那么从首字符到\0之前有6个字符,字符串长度为
6。 - strlen(p+1):p+1,变成是第二个字符的地址,从第二个字符到\0之前有5个字符,长度为
5。 - strlen(p): * p就是拿到’a’的ASCII码97,也就说strlen是要从地址97开始往后找0,但是我们的操作系统有一个规定*:在大多数操作系统中,0到某个特定值之间的地址被保留给内核使用,称为内核地址空间。这个特定值可以因操作系统和硬件架构而异,但通常是一个较低的地址。所以这里就会出现野指针,这是一行错误代码。
error - strlen(p[0]):与上面一致,都是访问低地址而出现野指针
error。 - strlen(&p):注意这里是取出p的地址,并不是p中存储的地址,是有很大区别的,p中的地址是字符串首字符的,p的地址是p在内存中存储的。所以这里是
随机值。 - strlen(&p+1):与上面基本一致,这里是&p+1,这里&p可以看成是整个字符串,+1就是跳过整个字符串。这里也
肯定会出现随机值,但是不一样就会与上面这个题的随机值一样。 - strlen(&p[0]+1):我们知道*(p+0) = p[0],而p变量存储的地址是字符串首字符的,相当于拿到首字符了已经,再取地址就是首字符地址,再+1也就跳过首字符,从第二个字符到\0之前有5个字符,长度为
5。
二维数组🦑
这就是数组的最后一道题。需要仔细的讲讲
int main()
{int a[3][4] = { 0 };printf("%d\n", sizeof(a));printf("%d\n", sizeof(a[0][0]));printf("%d\n", sizeof(a[0]));printf("%d\n", sizeof(a[0] + 1));printf("%d\n", sizeof(*(a[0] + 1)));printf("%d\n", sizeof(a + 1));printf("%d\n", sizeof(*(a + 1)));printf("%d\n", sizeof(&a[0] + 1));printf("%d\n", sizeof(*(&a[0] + 1)));printf("%d\n", sizeof(*a));printf("%d\n", sizeof(a[3]));return 0;
}
-
sizeof(a):这里是sizeof中出现数组名的情况,求的是整个数组的大小,数组3*4的个数是12个元素,类型都为int,12 *4 =
48 。 -
sizeof(a[0][0]):这是就是二维数组中第一个元素的写法,第一个元素类型为int,大小就是
4。 -
sizeof(a[0]):这个就不一样了,我们说
a[0]其实也可以写成这样*(a+0),a为数组名,数组名代表首元素地址,但是在二维数组中数组名代表第一行的地址,也就是说这个地址+1的话会跳过一行,而不是一个元素。但是这里只是+0就还是不变,我们知道a代表第一行的地址(把第一行看成是一维数组),和我们的一维数组的&arr是一样的。都是拿到整个一维数组的地址。那么其实a+0可以看成就是&arr,为什么呢?因为都是拿到整个数组的地址,并且都是一维数组。那么*(a+0),就可以看成是 * (&arr),而*又可以与&抵消就得到arr,这个arr我们就直接看成是第一行的数组名****就行。那么这道题的意思就是求第一行的总大小,是[4]*4=16。
其实你也可以这样记忆,sizeof(a[0])代表求第一行的所有元素大小。
那么a[0]就可以看成是第一行的数组名,并且是第一行的地址。 -
sizeof(a[0] + 1):a[0]作为第一行的数组名,并没有单独放在sizeof内部,也没有被取地址,按上面的分析方法a[0]代表第一行的数组名也是第一行的地址,所以a[0]就是数组首元素的地址,就是第一行第一个元素的地址,a[0]+1就是第一行第二个元素的地址,是地址那么在
32位下是4,64位下是8。 -
sizeof(*(a[0] + 1)):a[0]+1就是第一行第二个元素的地址,解引用得到第二行第一个元素,大小为
4。 -
sizeof(a + 1):a代表第一行地址,+1跳过第一行,但是还是地址,是地址那么在
32位下是4,64位下是8。 -
sizeof(*(a + 1)):对第二行的地址解引用得到第二行,也可以写成这样:a[1],根据我所理解的,a[1]看成是第二行的数组名,并且是第二行的地址。解引用就得到第二行。大小为
16。 -
sizeof(&a[0] + 1):a[0]我们知道是第一行的数组名对数组名取地址相当于拿到整个数组,然后+1跳过一行,但也还是地址,是地址那么在
32位下是4,64位下是8。 -
sizeof(*(&a[0] + 1)):与多加了一个 *,代表对第二行的地址解引用,拿到第二行,对第二行求大小得
16。 -
sizeof(*a):a代表二维数组数组名,也是第一行的地址,对第一行的地址解引用得到第一行。第一行大小为
16。 -
sizeof(a[3]):最后是这个,我们看到我们行数最大也为2,为什么这里写3呢?
这个代码是错误的吗?
int a[3][4] = { 0 };
其实不是,我们要知道一个知识点, sizeof在进行计算类型的大小时,它不会去看你括号里写的东西存不存在而是直接根据类型推得大小,a[3]就是第三行的数组名,即使没有第三行也会计算,数组名放在sizeof里得到第三行的大小,也是16。
小总结
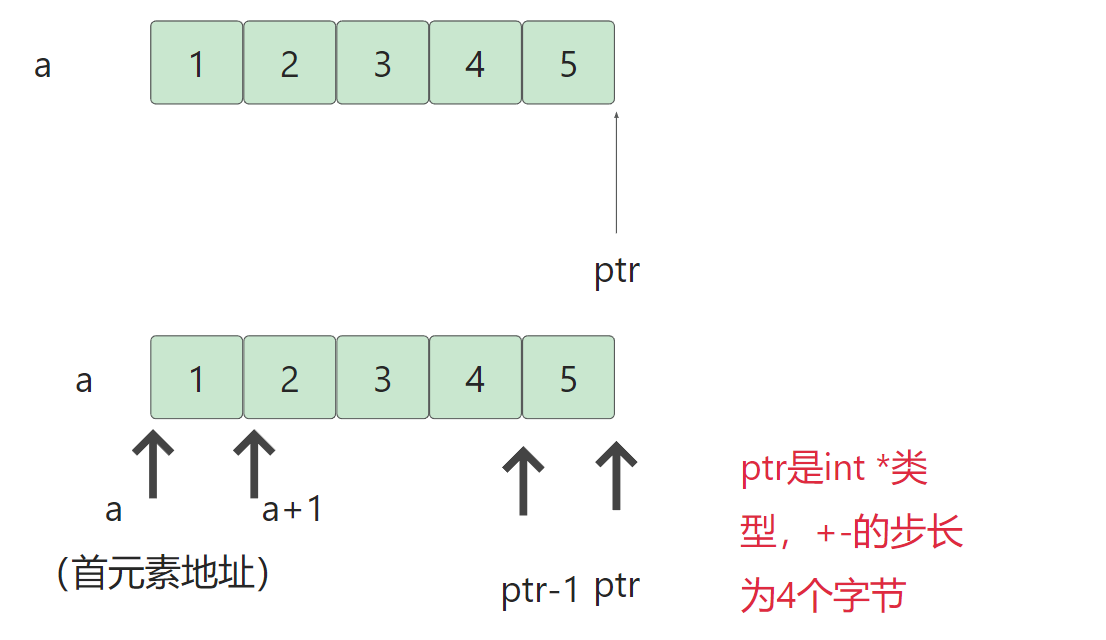
二维数组中 :
a +1的+1是要跳过一行。(a是第一行的地址+1跳过一行,并且a是相对于二维数组而言)
a[0] +1的+1是要跳过一个元素。(a[0]是第一行的数组名,一维数组的数组名+1就跳过一个元素)
&a[0]+1的+1是要跳过一行。(&是拿到整个一维数组的地址再+1,肯定就跳过一行了)。
指针试题(共8道)
一二题
一 :
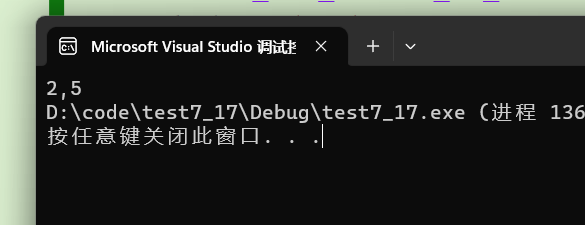
int main()
{int a[5] = { 1, 2, 3, 4, 5 };int *ptr = (int *)(&a + 1);printf( "%d,%d", *(a + 1), *(ptr - 1));return 0;
}程序的结果是什么?
分析
- a是整型数组5个元素,
- int *ptr = (int *)(&a + 1);我们先说&a+1,我们知道&a得到的是整个数组的地址,那么+1就相当于跳过一个数组,为什么还要强制转换(int *)呢?因为&a相当于数组指针,与int *ptr 的类型不一样,所以要强制类型转换。现在已经分析完了,输出部分请看图。
答案:
二 :
//结构体的大小是20个字节
struct Test
{int Num;char *pcName;short sDate;char cha[2];short sBa[4];
}*p;
//假设p 的值为0x100000。 如下表表达式的值分别为多少?
//已知,结构体Test类型的变量大小是20个字节
int main()
{printf("%p\n", p + 0x1);printf("%p\n", (unsigned long)p + 0x1);printf("%p\n", (unsigned int*)p + 0x1);return 0;
}
输出的结果是什么?
分析
我们知道p的值是0x100000,p+0x1呢? (unsigned long)p + 0x1); (unsigned int*)p + 0x1)又是多少?
- 我们不要被吓到了,0x1其实就是1,而p是一个结构体指针变量,所以这个指针应该是这样的,
struct Test *p;。
我们知道指针的类型决定指针的步长,那么现在结构体大小为20个字节,所以结构体指针+1就应该+20的地址。
相当于0x100000+20。20用十进制表示就14。
最后结果就是0x100014。 (unsigned long)p + 0x1);这里就改变的p的类型,之前是结构体指针现在强转为u long了,而u long咱们就把p不再看作一个指针变量了,就是一个普通的变量,相当于 int i = 0; i + 1。- 所以结果就是
0x100001。 (unsigned int*)p + 0x1),与上面一样,都是改变了指针的类型,u int *的大小也是 4个字节(32位),那么+1也是跳过4个字节。也相当于0x100000+0x4。
结果就为0x100004。
三四题
int main()
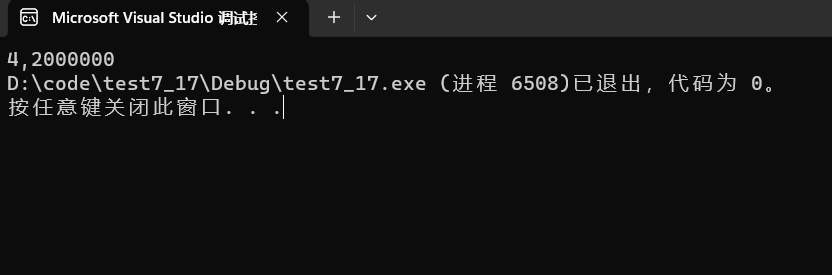
{int a[4] = { 1, 2, 3, 4 };int *ptr1 = (int *)(&a + 1);int *ptr2 = (int *)((int)a + 1);printf( "%x,%x", ptr1[-1], *ptr2);return 0;
}
输出的结果是什么?
分析:
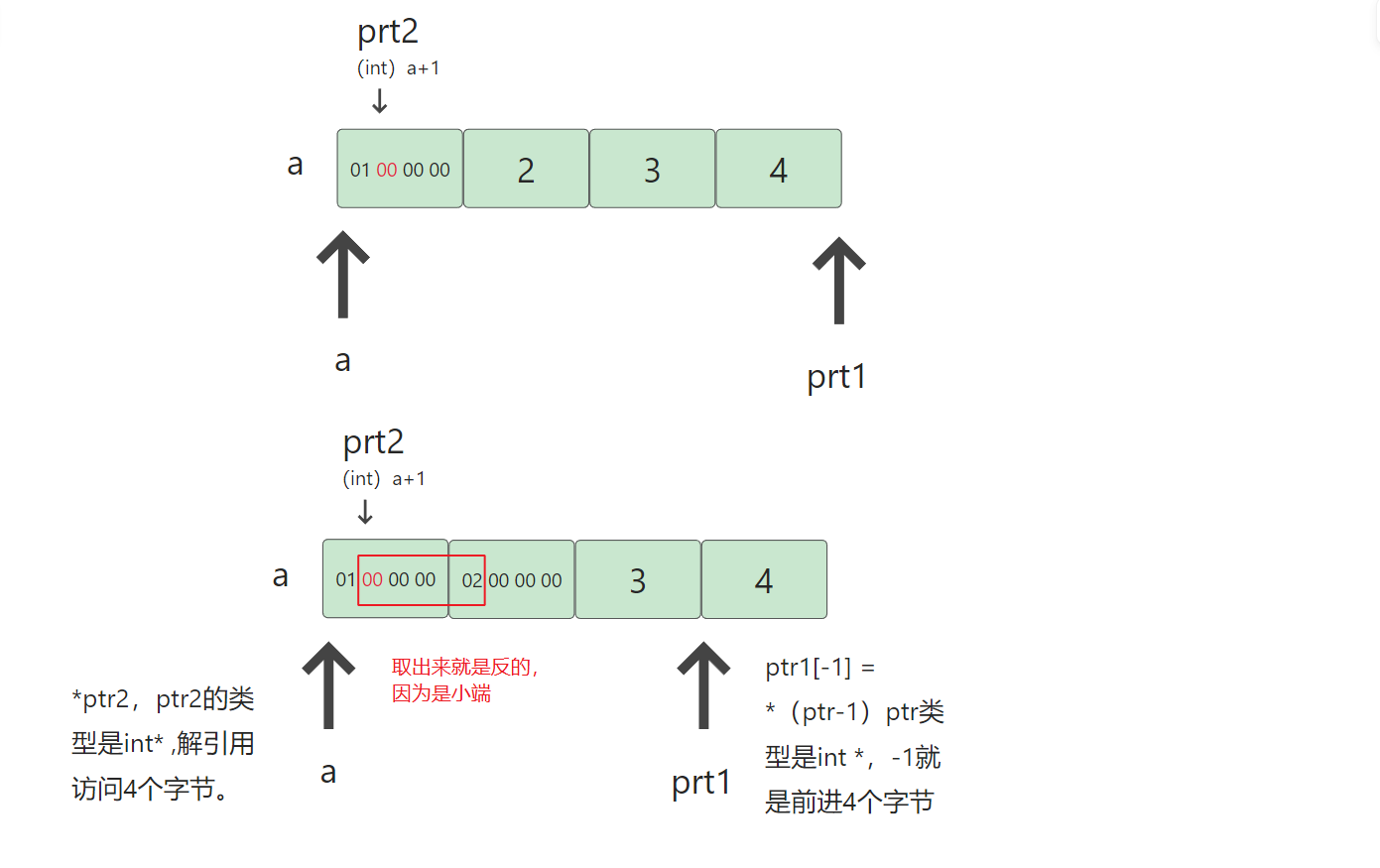
-
我们a是4个元素的整型数组, ptr1指向的是
&a+1的地址处,就是跳过一个数组,这里强转是因为&a的类型相当于int (*)[4],最后将数组指针转为int *。 -
ptr2就不一样的了,a是数组名也是首元素地址,也可看作是一个
int *类型,但是这里强转了,转为int 就相当于变成普通的变量加减,而int *+1跳过4个字节,int 类型+1,只跳过一个字节,最后再把类型转为int*就行了。 -
图
四
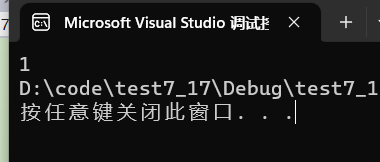
int main()
{int a[3][2] = { (0, 1), (2, 3), (4, 5) };int *p;p = a[0];printf( "%d", p[0]);return 0;
}
输出的结果是什么?
分析:
这个就比上面的简单一些了,考察二维数组的知识点,
首先这个题目有个坑,在二维数组初始化的时候,用(),就相当于逗号表达式,实际上应该是这样的, int a[3][2] = { 1, 3, 5};
我们知道a[0]就是代表第一行的数组名,数组名也是首元素地址,p[0]就相当于*(p +0),对p 解引用得到1。
五六题
五
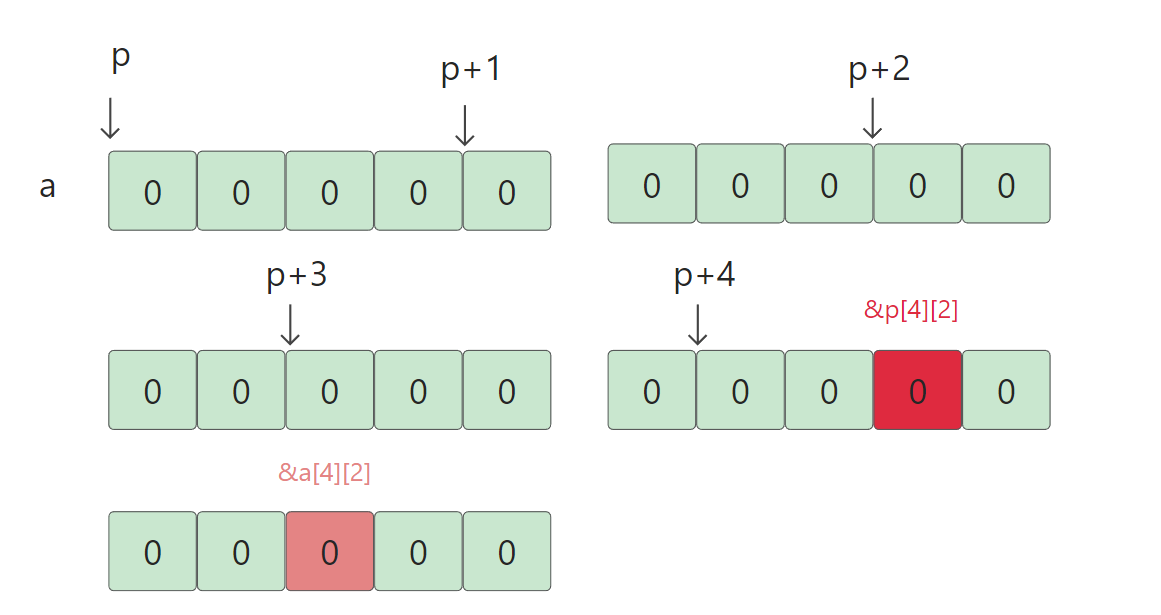
int main()
{int a[5][5];int(*p)[4];p = a;printf( "%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);return 0;
}
输出的结果是什么?
分析:首先定义了一个二维数组a,有定义了一个数组指针要十分的注意这个数组指针指向的数组看作是4个元素的。p这个指针变量存放的a,a又代表着二维数组数组第一行的地址。
- &p[4][2]:&* ( *(p+4)+2),p的类型是数组指针+4只能跳过4个元素的数组,这里一行是5个元素所以跳不完,+4最后在倒数第二行停下,再+2,得到这一行第四个元素的地址,再解引用,由于二维数组没有初始化就得到0。再取出这个元素的地址。
- &a[4][2]:就是取出最后一行第三个元素的地址。
&p[4][2] - &a[4][2]:是小地址减去大地址,因为数组随下标的增长地址有低变高。地址相减就相当于指针相减,因为地址就是指针,所以根据指针相减得到的是指针之间的元素个数得到最后结果是4。
图:
六
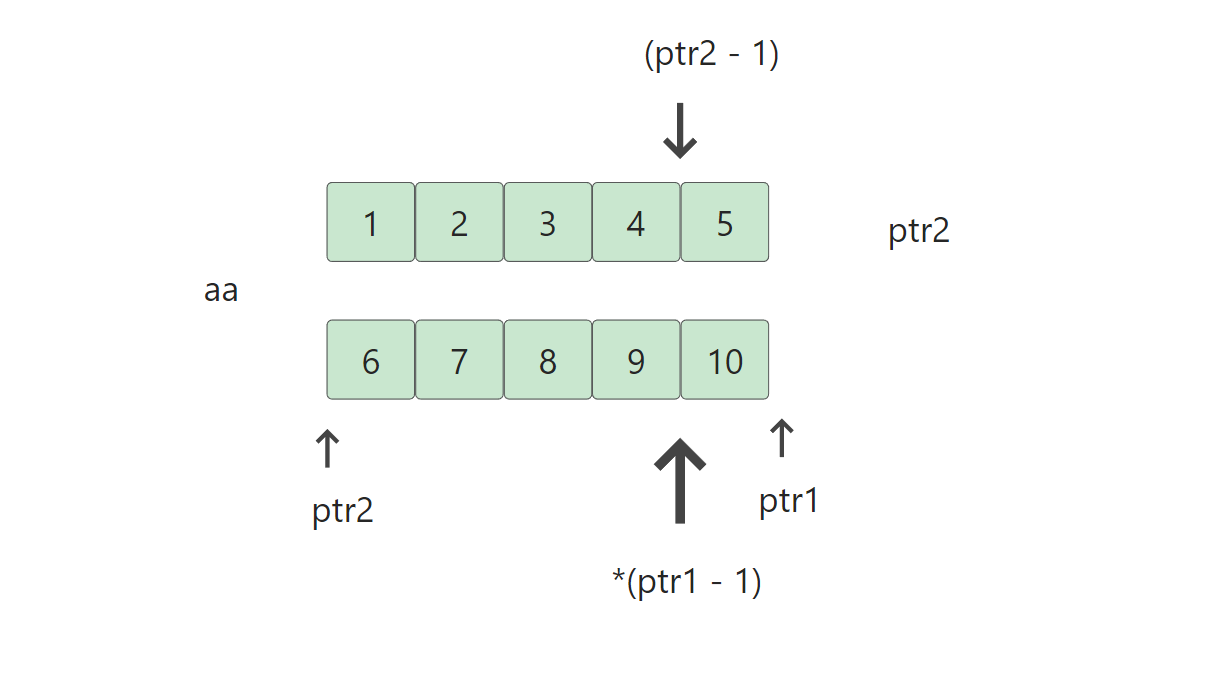
int main()
{int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };int *ptr1 = (int *)(&aa + 1);int *ptr2 = (int *)(*(aa + 1));printf( "%d,%d", *(ptr1 - 1), *(ptr2 - 1));return 0;
}
输出的结果是什么?
分析:aa是个二维数组的两行一共十个元素。
&aa + 1:aa是二维数组数组名对二维数组的数组名取地址就是拿到整个数组的地址,整个数组的地址+1,就跳过整个二维数组。
*(aa + 1):可以写成这样aa[1],相当于第一行的地址+1再解引用得到第二行的地址,aa[1]也就相当于数组名。
图

七八题
七
int main()
{char* a[] = { "work","at","alibaba" };char** pa = a;pa++;printf("%s\n", *pa);return 0;
}
输出的结果是什么?
分析:有一个字符指针数组,里面有三个元素,又有一个二级指针存储a的首元素的地址,因为a的首元素是char *类型存储的是字符串的首字符地址。pa++就意味着pa中存储的地址+1,就到了数组的下一个元素,下一个元素是’‘at’'的首字符地址,故输出的是at。

八
这一题也是最难的一题
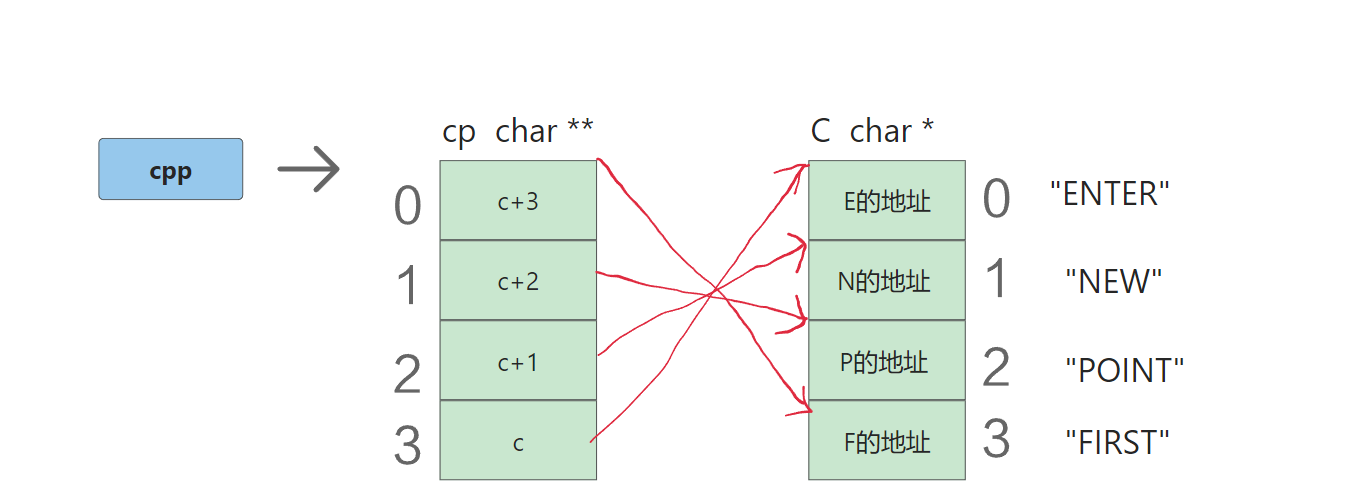
int main()
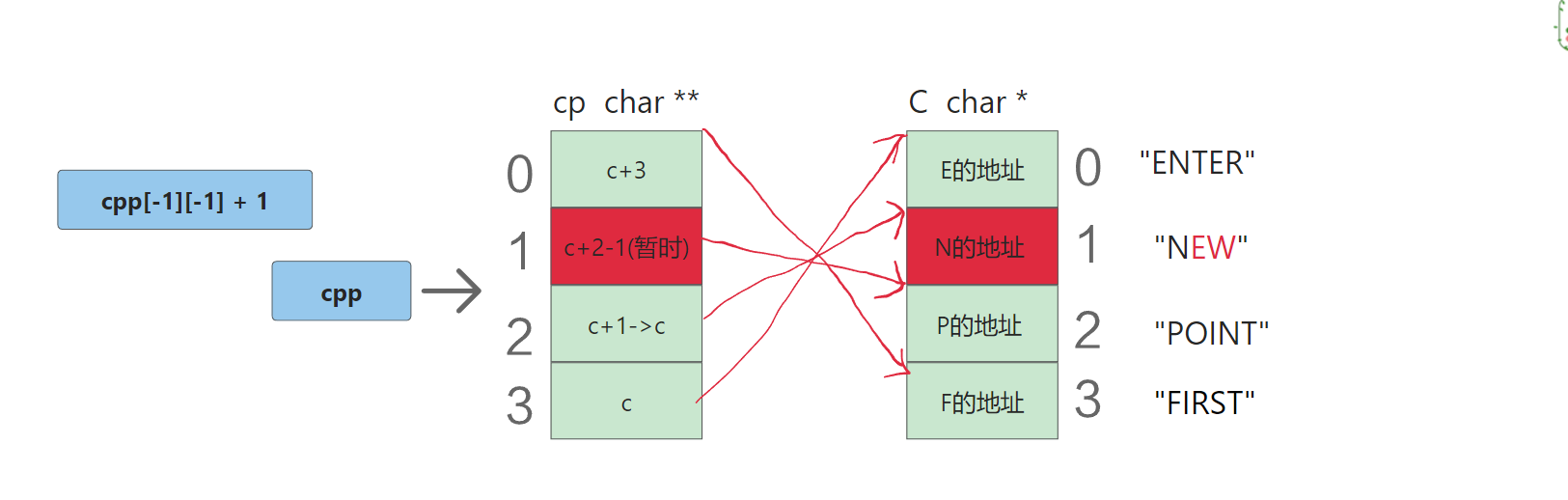
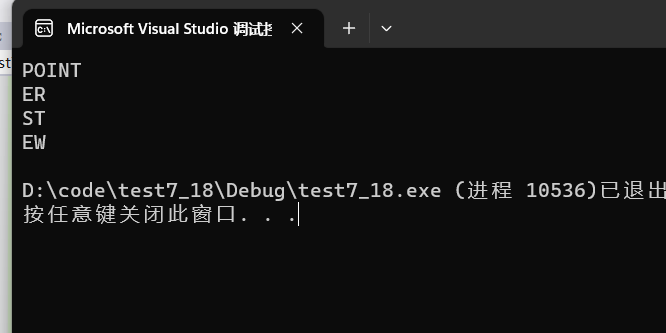
{char* c[] = { "ENTER","NEW","POINT","FIRST" };char** cp[] = { c + 3,c + 2,c + 1,c };char*** cpp = cp;printf("%s\n", **++cpp);printf("%s\n", *-- * ++cpp + 3);printf("%s\n", *cpp[-2] + 3);printf("%s\n", cpp[-1][-1] + 1);return 0;
}输出的结果是什么?
分析:有一个字符指针数组。数组的每个元素是相应字符串的首字符地址。
而cp这个二级指针数组存放的是char *类型的地址,刚好c数组的每个元素是char *,最后cpp这个三级指针指向的是二级指针数组的首元素地址。
- 图
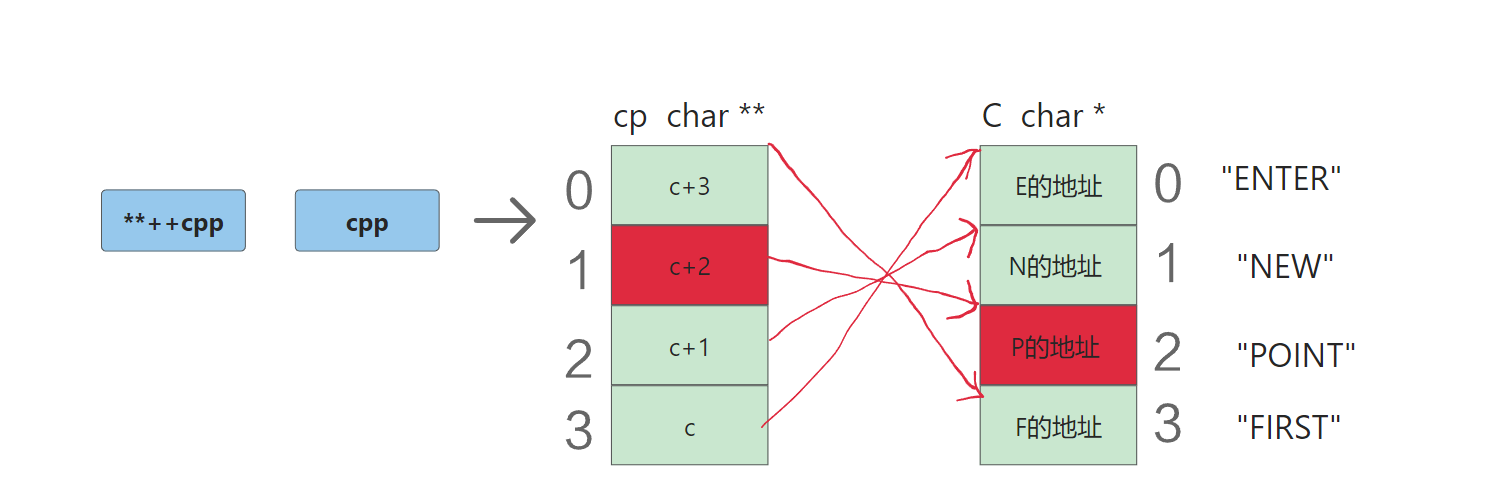
printf("%s\n", **++cpp);,首先cpp先永久+1,也就是移动char ***个步长也就是1,得到指向c+2地址处,再解引用得到c+2,而c+2是c这个数组中的地址,再解引用得到"POINT"。
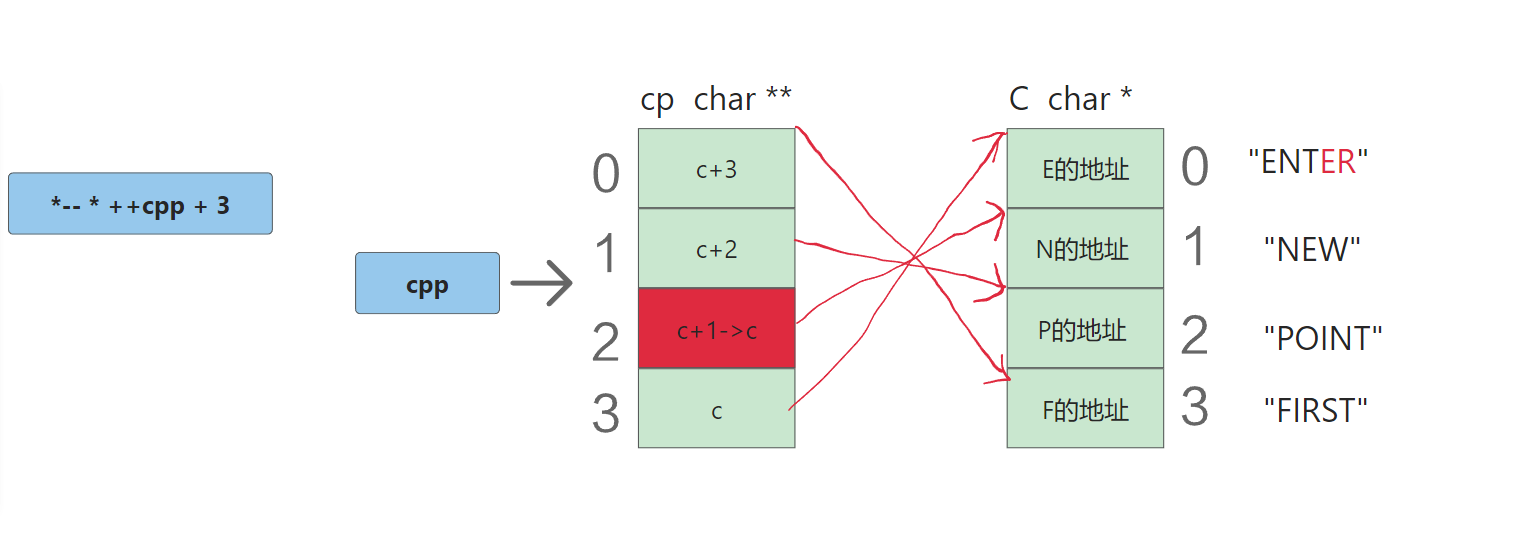
-*-- * ++cpp + 3:首先我们还是要明确理解的顺序,先cpp永久+1,再解引用,得到c+1,而c+1是c数组中的地址,然后再–,所以改变了c+1的值变成了c,然后再解引用得到"E"的地址,然后再加3,这时候就代表着"ENTER"这个字符串加3,ENTER我们可以理解成就是E的地址再+3,结果就得到"ER"。
就相当于:
int main()
{printf("%s", "abcde" + 3);}

- 图
*cpp[-2] + 3:首先我们拆解一下,* (*(cpp-2))+3,首先cpp-2,但是不是永久的,然后再解引用,上面我们cpp指向的是下标为2的位置,现在应该指向0,解引用得到c+3,再解引用得到F的地址,F的地址+3得到"ST";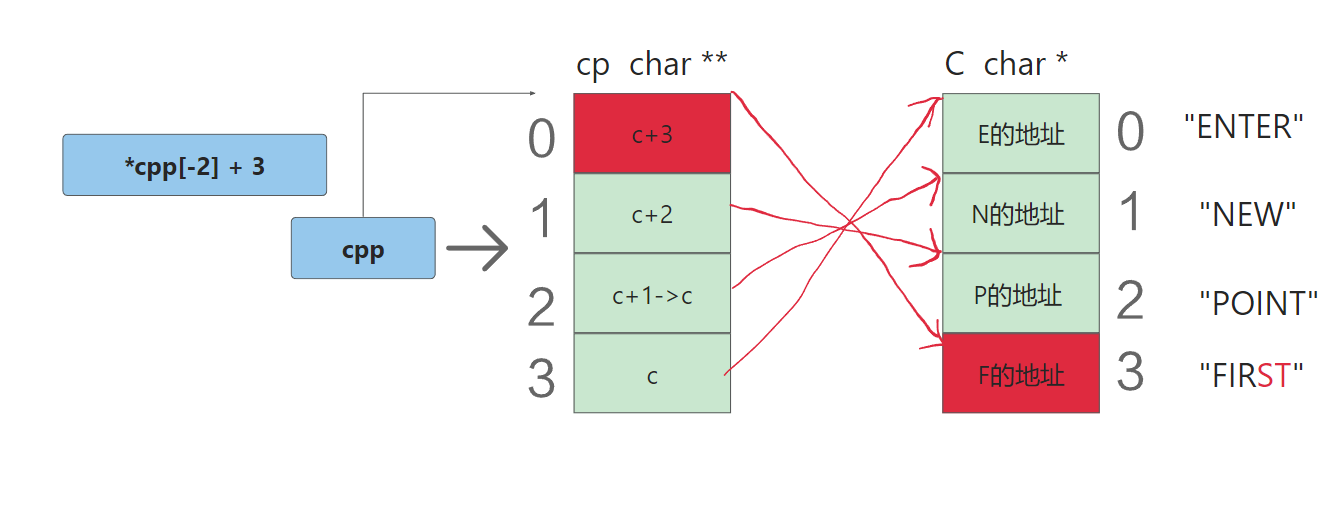
cpp[-1][-1] + 1:首先还是拆解一下,* (*(cpp-1)-1)+1,cpp-1指向c+2,解引用得到c+2,c+2然后要-1得到c+1,c+1解引用得到"NEW",再+1输出"EW"。
总结😈
这篇博客篇幅较长是因为先要深入的理解数组与地址与指针的关系是不太容易的,所以我们需要题目来练习,在数组方面我们让大家理解了数组名±或者&的一些差异,也包括一些类型的不同,指针方面也比较全面是各种类型的杂糅为的就是锻炼自己的理解能力。 完(๑′ᴗ‵๑)