计算机视觉 CV
Perception
如自动驾驶领域。
只要是从所谓的图像当中去抽取信息的过程,我们都叫做Perception。
- 视觉检测可以涵盖二维检测,如车辆、人和信号灯的检测。
- 另外,还可以控制三维信息,直接在三维空间中操作数据。

SLAM
SLAM 全称 Simultaneous Localization and Mapping。
- 计算机视觉领域不仅包括检测,还可以进行分割、车道线检测等任务。
- SLAM(同时定位和地图构建)是一个重要的概念,用于定位和制图。
- SLAM技术在VR和AR中的应用需要解决同时定位和制图的问题。

视差和深度信息
- 视差是深度信息的一种表示,与深度信息本质相同。
- 生成深度信息对于改变场景视角非常重要,比如为VR和AR创建不同视角。
- 生成深度信息通常需要复杂的数学和算法。
三维建模和修复
- 三维建模允许将现实世界的对象小型化,如无人机。
- 图像修复工作包括通过周围信息自动填充被删除的内容。
- 逆过程也可能是可行的,例如从图像中删除不想看到的对象。
计算机视觉是一个广泛的领域,包括了众多任务和应用,从二维检测到三维建模和修复。这个领域需要深厚的数学和算法知识,但也为许多领域的科学和技术进步提供了新的可能性。

人脸和图像修复
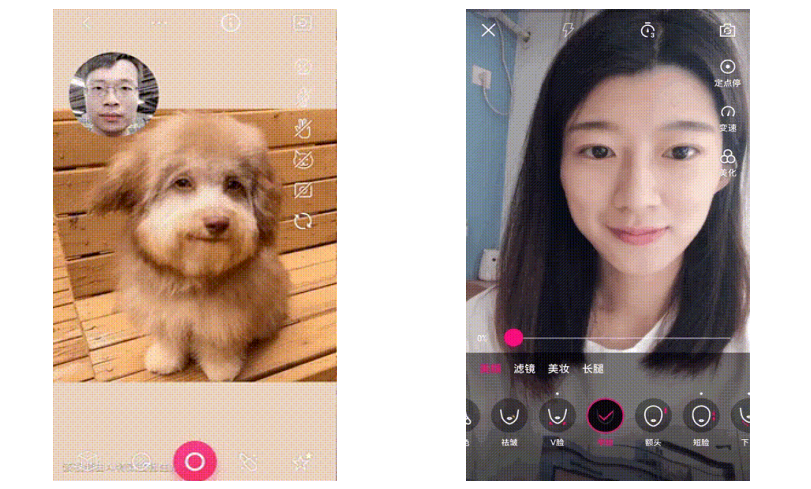
- 人脸驱动和美化: 你可以使用CV技术来实现人脸驱动,例如将一张人脸的表情应用到另一张脸上。此外,你还可以使用CV技术进行美颜处理,例如瘦脸。
- 图像修复: CV技术可以帮助修复图像中的缺陷或损坏,例如自动填充图像中缺失的部分,根据周围的信息进行补全。
- 对象移除: 你可以使用CV技术从图像中删除不需要的对象或元素,使图像更清晰或美观。

总结一下什么是CV
CV就是从图像、视频或者其他媒介中提取信息
• Extract Info from Image / Video / Other types of data: depth map / IR image / disparity map / point clouds / …
-
Image

-
Video

-
Other types of data
-
深度图 (depth map): 深度图是一种图像,但它不使用颜色来表示图像中的内容,而是使用灰度值。这些灰度值实际上表示物体距离相机的距离,而不是颜色信息。较暗的区域通常表示距离较远,而较亮的区域表示距离较近。
-
红外图像 (IR image): 红外图像是使用红外相机捕获的图像,它具有不同的信息呈现方式。这种图像在某些应用中很有用,例如夜视设备。
-
视差图 (disparity map): 视差图是计算机视觉中的一个关键概念,它表示左右相机看同一点时的距离差异。这些差异可用于计算深度信息,就像深度图一样。
-
点云 (point clouds): 点云是一组三维点的集合,通常用于表示物体的表面或场景的三维结构。它在无人车等领域中广泛应用,用于建立场景的三维模型。

-
生成模型 Generative Model
生成模型的定义: 生成模型是一种能够生成新数据,尤其是与现有数据相关的数据的模型。这些模型可以创建新的图像、文本、声音等内容。

-
人脸转换: 使用生成模型,可以实现人脸的转换。例如,将一个侧脸的照片转化为正面的照片,这在过去是难以想象的。
-
照片上色: 生成模型可用于给黑白照片上色,提高图像的质量,使图像更生动。
-
去除反光: 生成模型也可以用于去除图像中的反光,改善照片质量。
-
文本描述生成图像: 这个模型的另一个重要应用是从文本描述生成图像。用户可以提供文本描述,生成模型会生成符合描述的图像。
-
多模态生成: 最新的生成模型可以处理多种不同类型的数据,如图像、文本、音频等。这使得可以在不同模态之间进行转化,例如,生成带有文本描述的图像和音频。
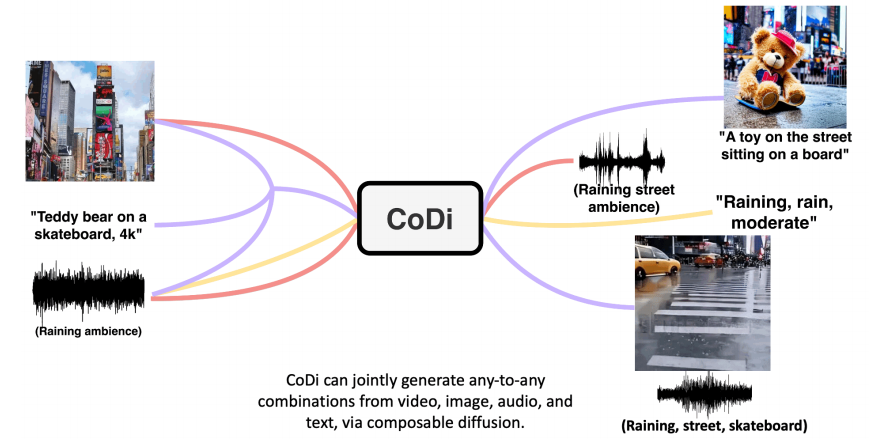
-
商业应用: 生成模型还具有商业潜力,如影视业中,它可以用于实现电影角色的语言切换,使角色的表情、口型保持不变,只是语言切换为不同语种,从而扩大电影的受众。
CV范式 Paradigm of CV
我们可以从低层次(low level)、中层次(mid level)和高层次(high level)的角度总结计算机视觉(CV)的发展:
-
低层次(Low Level):
- 低层次计算机视觉主要关注从原始图像中提取基础信息,如角点和边缘。
- 角点是图像中的突出点,通常位于物体的角部分,而边缘是具有不同亮度或颜色的地方。
- 基础信息提取的过程需要进行数学建模,例如计算图像的梯度,以获得变化信息。
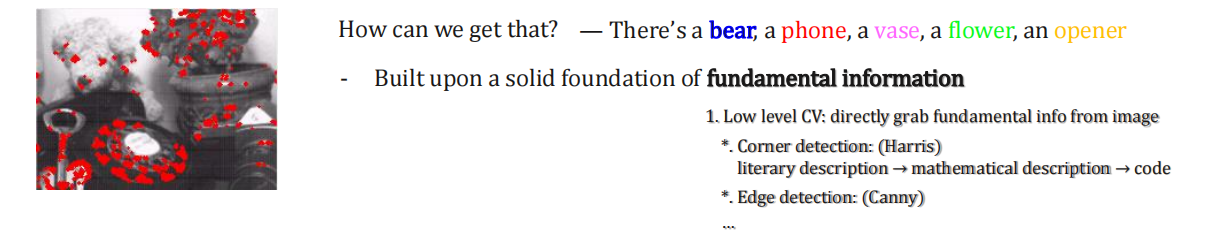
-
中层次(Mid Level):
- 中层次计算机视觉涉及从基础信息中提炼出更具语义的特征。
- 特征工程是一个常见的任务,它涉及到描述字(特征点/特征向量)的生成。
- 这些描述字通常包含关于物体方向、周围区域的信息以及其他特征,例如尺度和旋转不变性 (放缩或旋转后仍然是角点)。

-
高层次(High Level):
- 在高层次计算机视觉中,利用从基础信息和特征中提取的信息进行语义任务。
- 这包括利用经典工具(如SVM)或神经网络(如CNN)来执行任务,如物体识别或图像分类。
- 语义任务可以涵盖更高级的概念,例如对象检测、人脸识别、图像分割等。
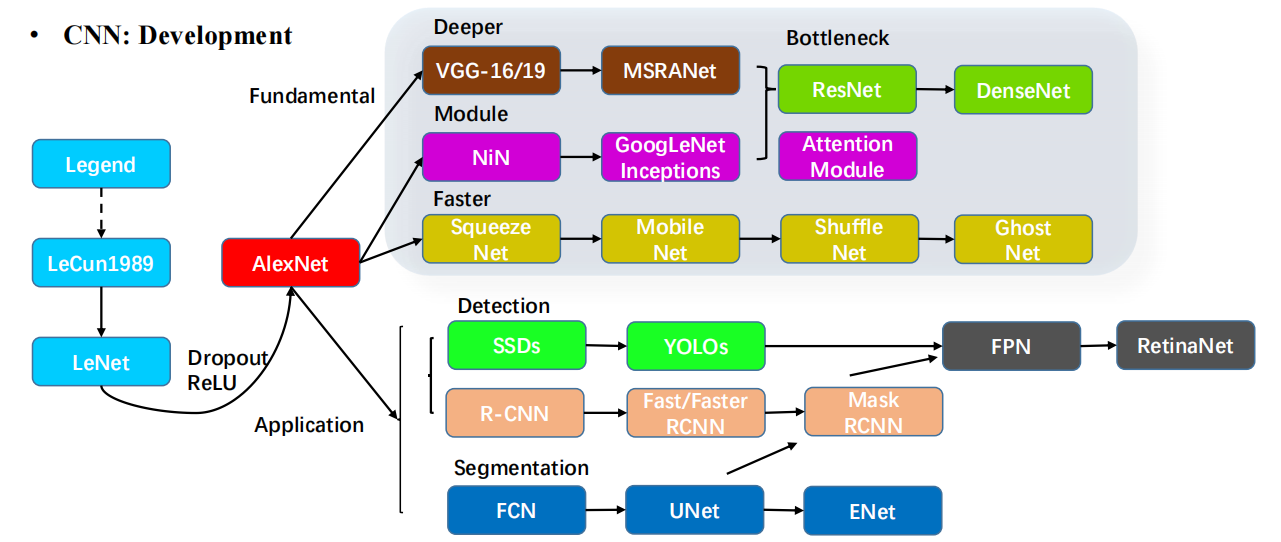
CNN
-
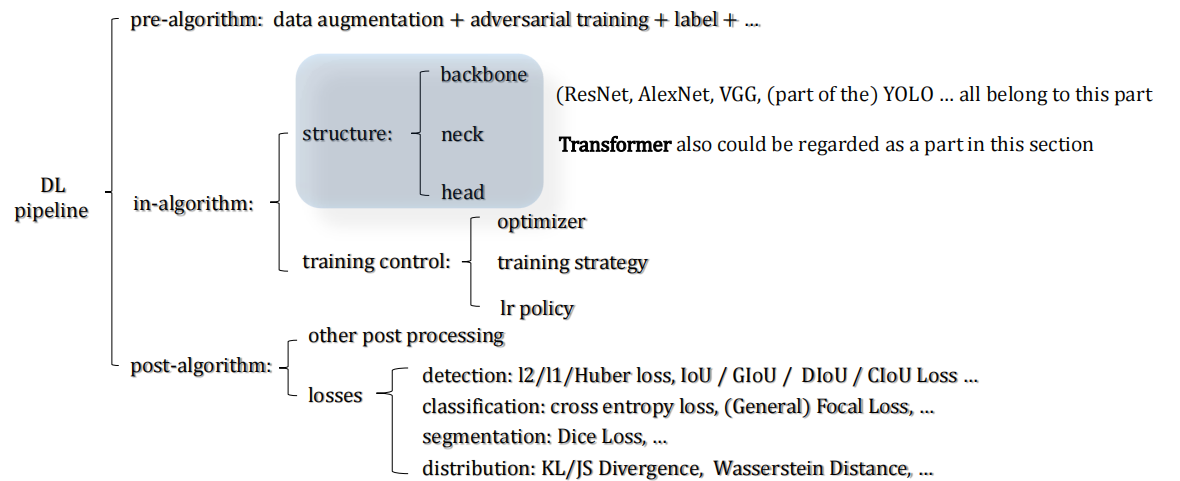
pre-algorithm
- 数据预处理和增广:这个阶段涉及数据的准备,包括对图像或数据进行预处理,如翻转、遮挡、添加噪音等,以增加数据的多样性。还包括对标签(label)的操作,如标注错误以改进模型的泛化能力。
-
in-algorithm
- 网络结构(Backbone):这个阶段涉及网络的结构设计,如卷积神经网络(CNN)的骨干结构(Backbone)。这是模型的基本框架,可以包括各种类型的神经网络结构,如Transformer、U-Net等。
- 网络连接和结构调整(Neck):这个阶段是连接Backbone和Head之间的过渡,通常包括一些网络连接和结构调整,以适应特定的任务。
- (Head):Headnetwork,有些用于做分割、有些用于做分类…
- 训练策略(Training Control):在这个阶段,确定如何训练模型,包括学习策略、训练策略、优化器的选择等。这是模型训练的关键部分。
-
post-algorithm
5. 后处理和损失函数(Loss Functions):最后一个阶段涉及模型输出的后处理,以及损失函数的选择。损失函数的选择取决于任务的不同,如目标检测、分割等。
-
CNN层级结构:
- Layer:CNN层级结构的基本组成单元。它包括卷积层(Convolutional Layer)、池化层(Pooling Layer)、批归一化层(Batch Normalization Layer)、全连接层(Fully Connected Layer)和丢弃层(Dropout Layer)。卷积层用于提取特征,池化层用于降低空间维度,批归一化层有助于加速训练,全连接层用于输出预测,丢弃层用于防止过拟合。
- Module:模块是由多个层级组合而成的结构,用于构建更复杂的CNN模型。例如,残差块(ResBlock)是一种常见的模块,它包含跳跃连接,有助于解决梯度消失问题。其他模块包括CBAM(Convolutional Block Attention Module)和SE-Net(Squeeze-and-Excitation Network),它们用于增强模型的特征学习能力。
- Network:网络是由多个模块组合而成的CNN结构。常见的CNN网络结构包括VGG、ResNet、UNet、MobileNet等。它们在不同的任务中表现出色,如图像分类、目标检测、分割等。

-
CNN应用:
- 目标检测(Detection):目标检测是在图像中识别和定位物体的任务。常见的检测算法包括Faster R-CNN、YOLO(各个版本如YOLOv2、YOLOv3、YOLOv4、YOLOv7、YOLOv8)、RetinaNet、FPN(Feature Pyramid Network)、CenterNet等。这些算法结合了卷积神经网络和目标框回归方法,实现了高效的目标检测。
- 生成对抗网络(GAN):GAN是一种生成模型,由生成器和判别器组成,用于生成与真实数据相似的数据。常见的GAN算法包括原始GAN、Wasserstein GAN(WGAN)、条件GAN、Pix2Pix、Cycle-GAN等。GAN用于图像生成、风格迁移、图像超分辨率等任务。
- 关键点检测(Keypoint Detection):关键点检测是在图像中定位关键点的任务,例如人体关节的位置。Hourglass网络是一种常用于关键点检测的CNN结构,它具有逐级降采样和上采样层,用于生成关键点热图。
- 三维相关(3D Related):3D视觉任务涵盖了立体匹配、点云分析、物体姿态估计等。一些重要的算法包括GANet、LEAStereo、PointNet、Voxelnet、MiDas、PoseCNN、SSD-6D等,它们用于从多视图或点云数据中重建三维信息。
- 图像分割(Segmentation):图像分割任务涉及将图像中的不同区域分配给不同的类别。常用的分割网络包括UNet、ENet、PANet等,它们具有编码-解码结构,有助于精确的语义分割。
- 模型加速(Acceleration):模型加速方法用于减少深度学习模型的复杂度,以便在资源受限的设备上进行推断。这些方法包括网络剪枝(Network Slimming)、知识蒸馏(Knowledge Distillation)以及使用轻量级模型如MobileNet、ShuffleNet、GhostNet等。
- 神经架构搜索(NAS):神经架构搜索是一种自动化的深度学习模型设计方法,其目标是找到最佳的网络结构。EfficientNet是一个成功的NAS例子,它通过均衡了模型宽度、深度和分辨率,实现了高性能的图像分类。
VGG
后续补充
残差网络 ResNet
后续补充
UNet
Unet最初由Olaf Ronneberger、Philipp Fischer和Thomas Brox于2015年提出,用于图像分割任务。Unet的设计灵感来自生物医学图像处理领域,特别是用于细胞分割的应用。该网络架构在医学图像分割、计算机视觉和许多其他领域的图像分析任务中非常成功。
Unet的关键特点是其编码器-解码器结构,其中编码器用于捕获图像的上下文信息,而解码器用于还原分割结果的空间分辨率。以下是Unet架构的主要组成部分:
-
编码器(Encoder):编码器部分由卷积层和池化层组成,用于逐渐降低输入图像的空间分辨率并提取特征。每一层都会增加特征的抽象性,从边缘和纹理信息到更高级别的语义信息。
-
解码器(Decoder):解码器部分由反卷积层和/或上采样层组成,用于逐步增加特征图的分辨率,并将上下文信息与高分辨率特征图相结合,以生成分割结果。解码器的每一层都通过跳跃连接(skip connections)与相应编码器层相连接,以帮助细节保留和避免信息丢失。
-
损失函数:通常使用像素级别的损失函数,如交叉熵损失或Dice损失,来衡量模型的输出与实际分割掩码之间的差异。
Unet的主要优点包括:
-
良好的上下文信息捕获:由于编码器部分逐渐减小图像尺寸,可以捕获更广泛的上下文信息,有助于准确的分割任务。
-
跳跃连接:跳跃连接有助于维护高分辨率特征的信息,从而提高分割的细节和准确性。
-
相对较少的参数:相对于一些其他深度学习模型,Unet通常具有相对较少的参数,这有助于减少训练和推理的计算成本。
Transpose Convolution & Upsampling
Transpose Convolution(转置卷积,也称为反卷积或分数步长卷积)和上采样都是用于增加图像或特征图的空间分辨率的技术,通常用于深度学习中的图像处理任务,如图像分割或生成任务。
-
转置卷积(Transpose Convolution):
- 转置卷积是一种卷积运算的逆操作,它用于将特征图的空间分辨率扩展,从而使特征图变得更大。
- 在标准卷积操作中,卷积核滑动并执行池化操作,将输入特征图的空间分辨率降低。转置卷积的操作与之相反,可以将特征图的分辨率增加。
- 转置卷积的卷积核通常包含零填充,以扩大特征图的大小。它还具有可学习的权重参数,可以在训练中调整,以适应特定任务。
- 转置卷积通常用于解码器部分,用于从编码器获得的低分辨率特征图生成高分辨率分割结果。
-
上采样(Upsampling):
- 上采样是一种简单的操作,它通过插值技术将低分辨率图像或特征图的大小增加到所需的分辨率。
- 常见的上采样方法包括最邻近插值、双线性插值和双三次插值等。这些方法可以根据需要平滑地增加图像的大小。
- 上采样通常用于从编码器到解码器传递信息,以便在分割任务中恢复特征图的分辨率。例如,它可以用于跳跃连接中,以将低分辨率特征图上采样到与解码器特征图相匹配的分辨率,并将它们相结合以生成分割结果。
虽然转置卷积和上采样都可以用于增加特征图的分辨率,但它们之间存在一些差异。转置卷积通常包含可学习的参数,可以更好地适应特定任务,而上采样是一种简单的插值技术,通常不包含可学习的参数。在实际应用中,根据任务和性能要求,可以选择使用其中一种或两种技术来进行上采样操作。