前言
句子向量表示一直作为很多自然语言处理任务的基石,一直是NLP领域的热门话题,BERT-Flow以及BERT-whitenning其实像是后处理,将bert的输出进行一定的处理来解决各向异性的问题。
而SimCSE《Simple Contrastive Learning of Sentence Embeddings》,即「简单的对比句向量表征框架」,通过一种简单的对比学习去做句子嵌入。而且在可以不要监督数据的情况下,生成质量较好的句子向量。文章被收录在EMNLP2021。
paper地址:https://aclanthology.org/2021.emnlp-main.552.pdf
code地址:https://github.com/princeton-nlp/SimCSE
1.对比学习
对比学习的定义:以拉近相似数据,推开不相似数据为目标,有效地学习数据表征。对比学习的流程如下:
(1)将一只猫的图X,数据增强的方式生成另一张猫的图片作为正例X+,构建正例样本对,选择一只狗作为负例X-。
(2)将这个正负例样本组(X,X+,X-)同时输入到一个模型中进行特征抽取。
(3)优化对比损失,将X和X+的在特征空间里面的距离拉近,同时将X和X-在特征空间中的距离拉远。
通过对比学习方式,可以达到下面两个目的:
(1)相似图片早特征空间靠的很近,这就实现了相似图片,它们的特征也比较相近
(2)而不相似的图片在特征空间中距离会非常大,导致这些具有差异性得图片会比较分散的分布在特征空间中,从另一个角度上来思考,就是特征空间的信息会尽可能的多。
从对比学习的整个流程来看,我们可以发现在没有标注数据的时候,只需要做一下数据增强构建正例样本对,就可以很方便的使用对比学习抽取出比较有用的特征向量。
2.SimCSE
SimSCE 就是一个采用对比学习框架进行句子嵌入的方法,SimCES提出了有监督和无监督这两种对比学习方式来进行句子嵌入。
2.1 无监督方法
无监督方法中,采用dropout技术,对原始文本进行数据增强,从而构造出正样本,用于后续对比学习训练。
2.1.1 流程实现
无监督方法如下图所示,过程如下。
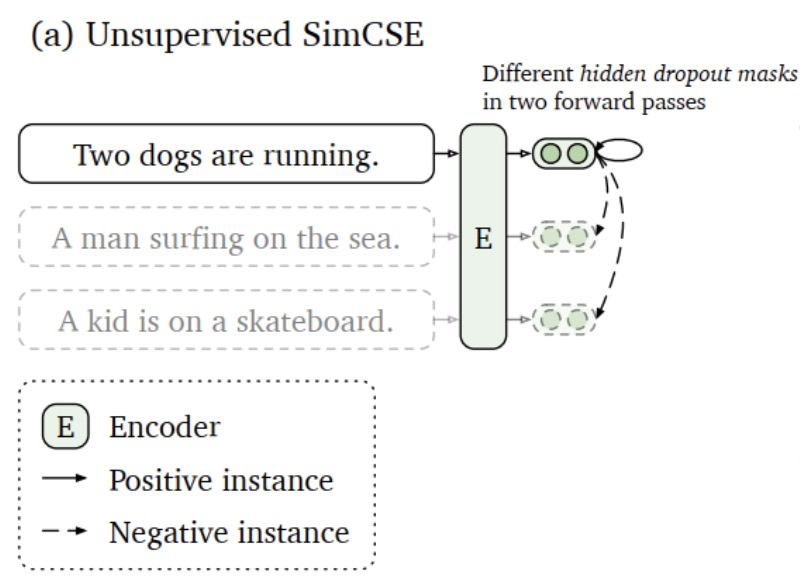
(1) 将同一个句子输入到模型两次,采用dropout技术,得到两个不同的特征向量。由于模型中存在dropout 层,神经元随机失活会导致同一个句子在训练阶段输入到模型中得到的输出都会不一样。
(2) 在一个batch中,将同一个句子在模型中的两次输出当作正例,将其他句子的输出全部当作负例。
(3) 优化对比损失,增加正例之间的相似度,减小负例之间的相似度。
2.1.2 Loss 实现与详解
这里假设每个batch 输入给模型的样本 格式如下 :
(1) [0,1,2,3,4,5] 代表一个batch中含有六个样本
(2)其中0,1表示同一个句子,其中2,3是同一个句子,其中4,5是同一个句子
那么模型的输出 y_pred 就是[X0,X1,X2,X3,X4,X5] 这六个句子的向量表示。对比Loss 的详解 如下。
def compute_loss(y_pred, lamda=0.05):idxs = torch.arange(0, y_pred.shape[0]) # [0,1,2,3,4,5] #这里[(0,1),(2,3),(4,5)]代表三组样本,#其中0,1是同一个句子,输入模型两次#其中2,3是同一个句子,输入模型两次#其中4,5是同一个句子,输入模型两次y_true = idxs + 1 - idxs % 2 * 2 # 生成真实的label = [1,0,3,2,5,4] # 计算各句子之间的相似度,形成下方similarities 矩阵,其中xij 表示第i句子和第j个句子的相似度#[[ x00,x01,x02,x03,x04 ,x05 ]# [ x10,x11,x12,x13,x14 ,x15 ]# [ x20,x21,x22,x23,x24 ,x25 ]# [ x30,x31,x32,x33,x34 ,x35 ]# [ x40,x41,x42,x43,x44 ,x45 ]# [ x50,x51,x52,x53,x54 ,x55 ]]similarities = F.cosine_similarity(y_pred.unsqueeze(1), y_pred.unsqueeze(0), dim=2)# similarities屏蔽对角矩阵即自身相等的loss#[[ -nan,x01,x02,x03,x04 ,x05 ] # [ x10, -nan,x12,x13,x14 ,x15 ]# [ x20,x21, -nan,x23,x24 ,x25 ]# [ x30,x31,x32, -nan,x34 ,x35 ]# [ x40,x41,x42,x43, -nan,x45 ]# [ x50,x51,x52,x53,x54 , -nan ]]similarities = similarities - torch.eye(y_pred.shape[0]) * 1e12# 论文中除以 temperature 超参similarities = similarities / lamda#下面这一行计算的是相似矩阵每一行和y_true = [1,0,3,2,5,4] 的交叉熵损失#[[ -nan,x01,x02,x03,x04 ,x05 ] label = 1 含义:第0个句子应该和第1个句子的相似度最高,即x01越接近1越好# [ x10, -nan,x12,x13,x14,x15 ] label = 0 含义:第1个句子应该和第0个句子的相似度最高,即x10越接近1越好# [ x20,x21, -nan,x23,x24,x25 ] label = 3 含义:第2个句子应该和第3个句子的相似度最高,即x23越接近1越好# [ x30,x31,x32, -nan,x34,x35 ] label = 2 含义:第3个句子应该和第2个句子的相似度最高,即x32越接近1越好# [ x40,x41,x42,x43, -nan,x45 ] label = 5 含义:第4个句子应该和第5个句子的相似度最高,即x45越接近1越好# [ x50,x51,x52,x53,x54 , -nan ]] label = 4 含义:第5个句子应该和第4个句子的相似度最高,即x54越接近1越好#这行代码就是simsce的核心部分,就是一个句子被dropout 两次得到的向量相似度应该越大 #越好,且和其他句子向量的相似度越小越好loss = F.cross_entropy(similarities, y_true) return torch.mean(loss)2.2 监督学习方法
2.2.1 流程实现
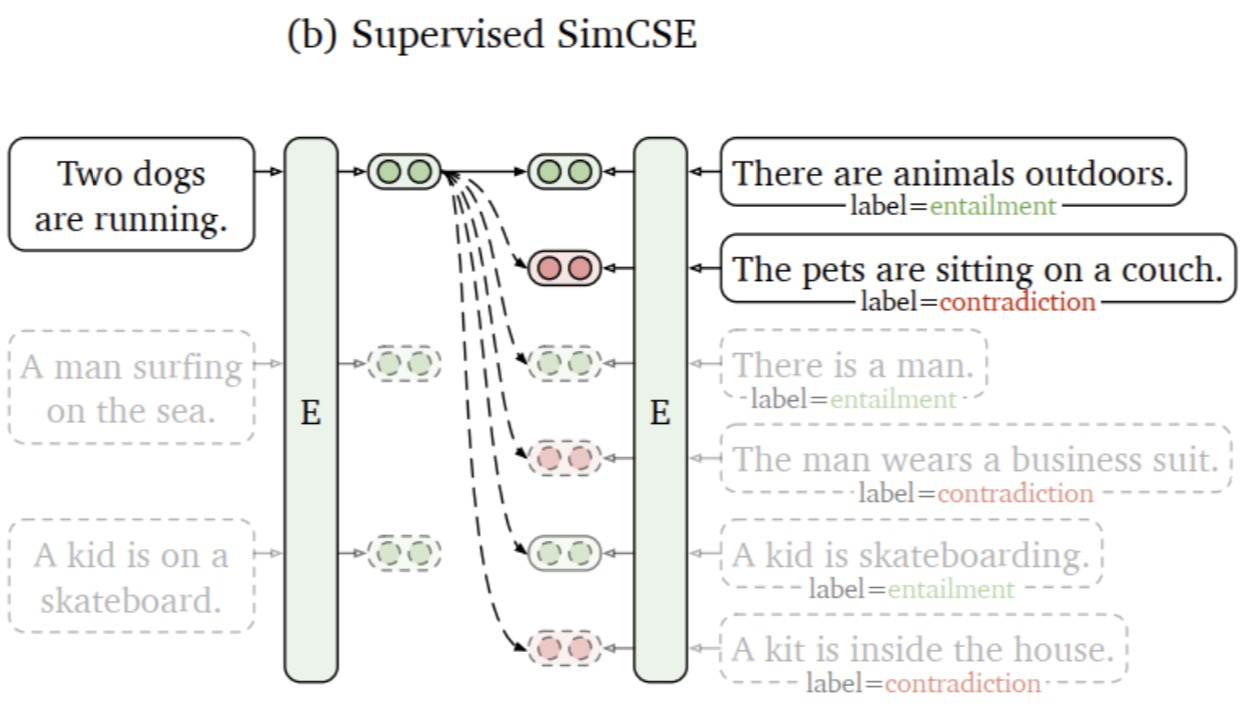
监督学习方法中,借助于文本蕴含(自然语言推理)数据集,将蕴涵-pair作为正例,矛盾-pair作为难负例,用于后续对比学习训练。并且通过对比学习解决了预训练Embedding的各向异性问题,使其空间分布更均匀,当有监督数据可用时,可以使正样本直接更紧密。模型结构如下图所示:
2.2.2 Loss 实现与详解
这里假设每个batch 输入给模型的样本 格式如下 :
(1) [0,1,2,3,4,5] 代表一个batch中含有六个样本。
(2)[(0,1,2),(3,4,5)]代表二组样本,其中0,1是相似句子代表正例,0,2是不相似的句子代表负例;其中3,4是相似句子代表正例,3,5是不相似的句子代表负例。模型的输出 y_pred 就是[X0,X1,X2,X3,X4,X5] 这六个句子的向量表示。对比Loss 的详解 如下。
def compute_loss(y_pred,lamda=0.05):row = torch.arange(0,y_pred.shape[0],3,device='cuda') # [0,3]col = torch.arange(y_pred.shape[0], device='cuda') # [0,1,2,3,4,5]#这里[(0,1,2),(3,4,5)]代表二组样本,#其中0,1是相似句子,0,2是不相似的句子#其中3,4是相似句子,3,5是不相似的句子col = torch.where(col % 3 != 0)[0].cuda() # [1,2,4,5]y_true = torch.arange(0,len(col),2,device='cuda') # 生成真实的label = [0,2]#计算各句子之间的相似度,形成下方similarities 矩阵,其中xij 表示第i句子和第j个句子的相似度#[[ x00,x01,x02,x03,x04 ,x05 ]# [ x10,x11,x12,x13,x14 ,x15 ]# [ x20,x21,x22,x23,x24 ,x25 ]# [ x30,x31,x32,x33,x34 ,x35 ]# [ x40,x41,x42,x43,x44 ,x45 ]# [ x50,x51,x52,x53,x54 ,x55 ]]similarities = F.cosine_similarity(y_pred.unsqueeze(1), y_pred.unsqueeze(0), dim=2)#这里将similarities 做切片处理,形成下方矩阵#[[ x01,x02,x04 ,x05 ] # [x31,x32,x34 ,x35 ]]similarities = torch.index_select(similarities,0,row)similarities = torch.index_select(similarities,1,col)#论文中除以 temperature 超参 similarities = similarities / lamda#下面这一行计算的是相似矩阵每一行和y_true = [0, 2] 的交叉熵损失#[[ x01,x02,x04 ,x05 ] label = 0 含义:第0个句子应该和第1个句子的相似度最高, 即x01越接近1越好# [x31,x32,x34 ,x35 ]] label = 2 含义:第3个句子应该和第4个句子的相似度最高 即x34越接近1越好#这行代码就是simsce的核心部分,和正例句子向量相似度应该越大 #越好,和负例句子之间向量的相似度越小越好loss = F.cross_entropy(similarities,y_true)return torch.mean(loss)其实除了通过dropout 两次来构造对比学习的正例样本,其实还有很多的方式构造正例,比如可以采用文本处理里面经常用到的同义词替换,回译等方式去进行正例构造,但SimCSE的作者想到用dropout这么简单的方式来构建对比学习的正例样本对,并且在很多数据集上表现不俗。
3.代码调用
# Import our models. The package will take care of downloading the models automatically
tokenizer = AutoTokenizer.from_pretrained("princeton-nlp/sup-simcse-bert-base-uncased")
model = AutoModel.from_pretrained("princeton-nlp/sup-simcse-bert-base-uncased")
# Tokenize input texts
texts = ["马云说本周六要来京和高文欣会面","马云计划周六在北京会见高文欣","马云周六没空"
]
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt")
# Get the embeddings
with torch.no_grad():embeddings = model(**inputs, output_hidden_states=True, return_dict=True).pooler_output# Calculate cosine similarities
# Cosine similarities are in [-1, 1]. Higher means more similar
cosine_sim_0_1 = 1 - cosine(embeddings[0], embeddings[1])
cosine_sim_0_2 = 1 - cosine(embeddings[0], embeddings[2])print("Cosine similarity between \"%s\" and \"%s\" is: %.3f" % (texts[0], texts[1], cosine_sim_0_1))
print("Cosine similarity between \"%s\" and \"%s\" is: %.3f" % (texts[0], texts[2], cosine_sim_0_2))

Reference:
1.https://www.jianshu.com/p/d73e499ec859