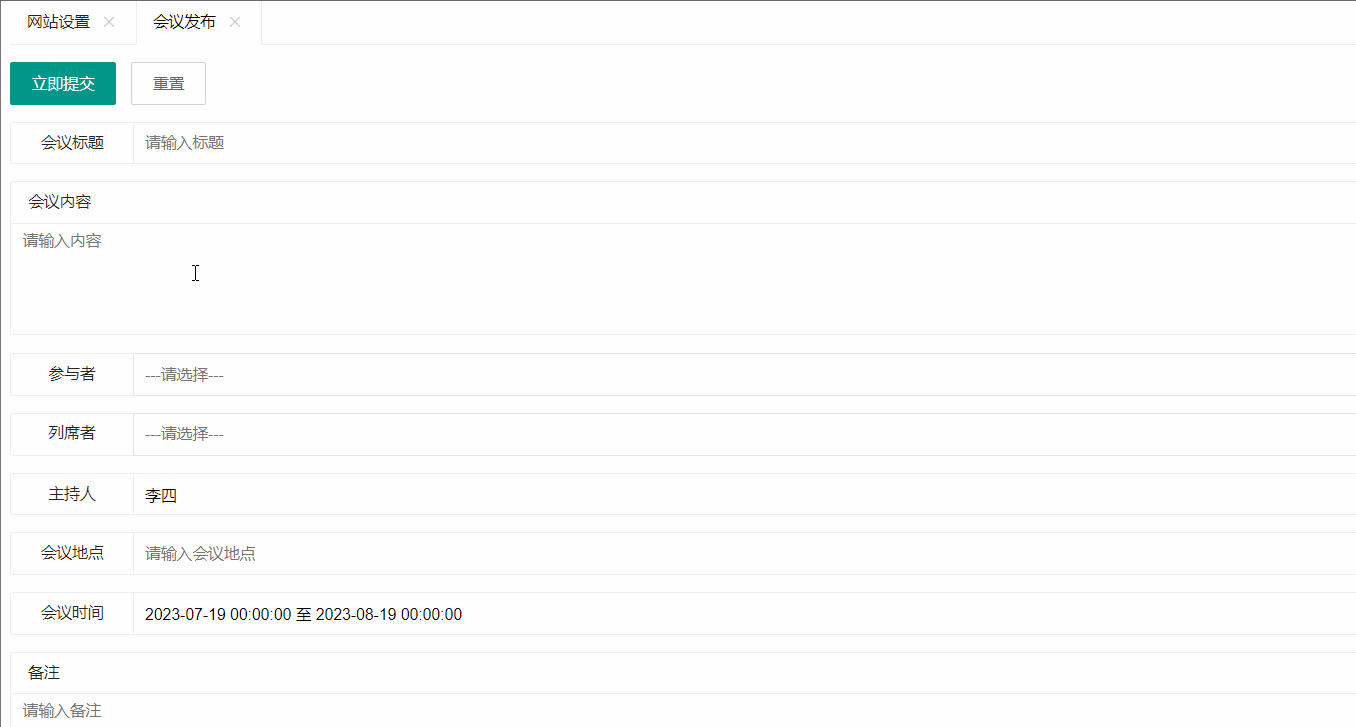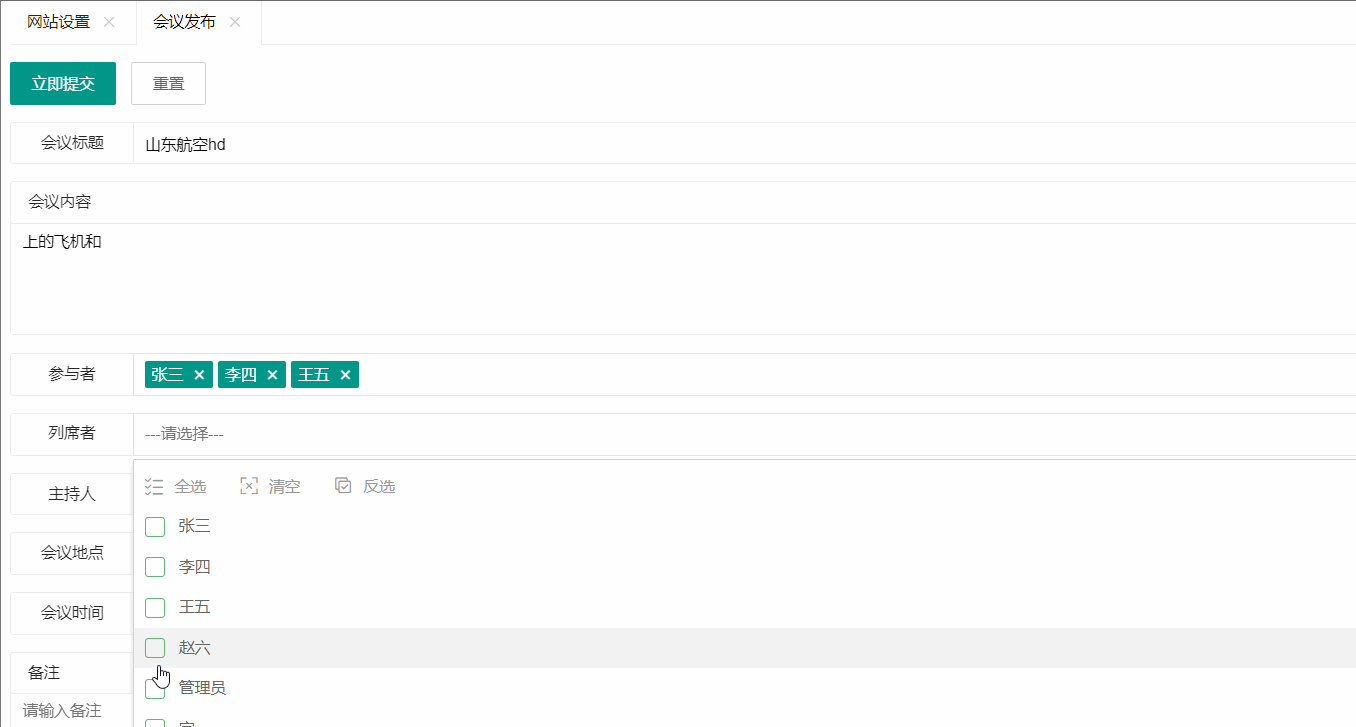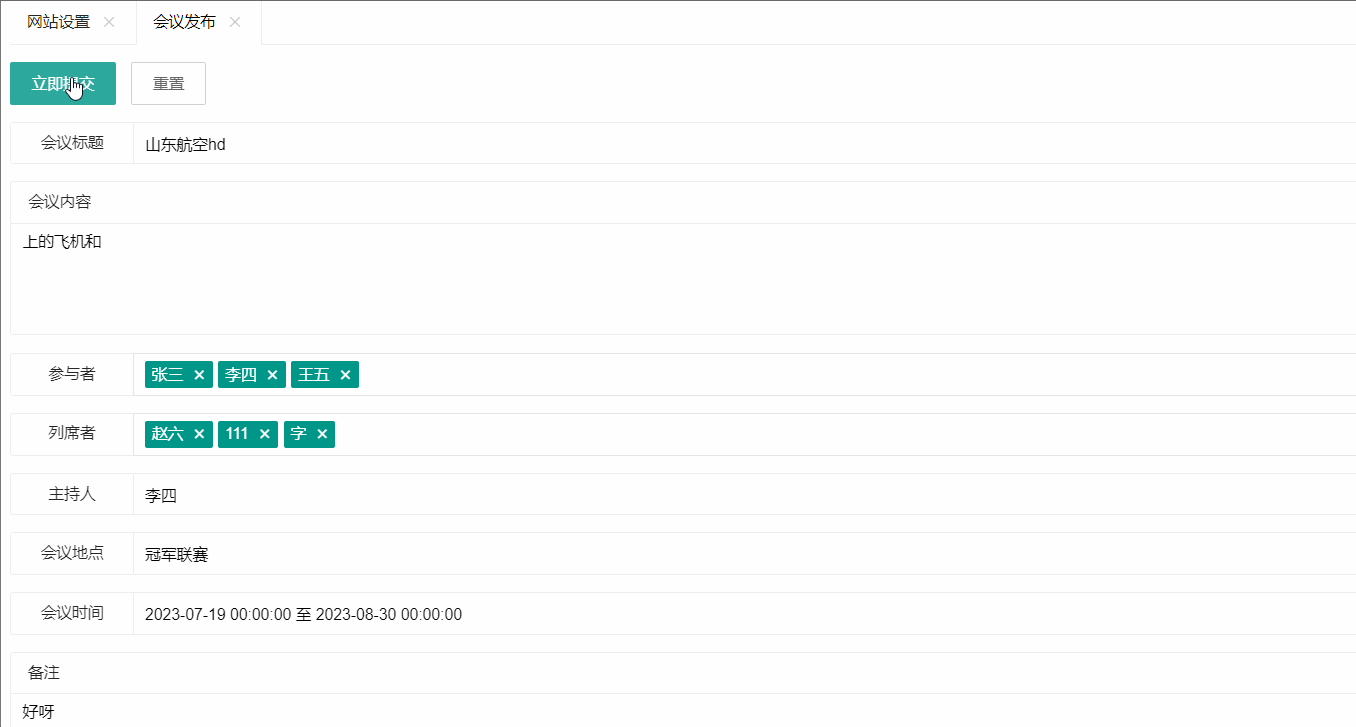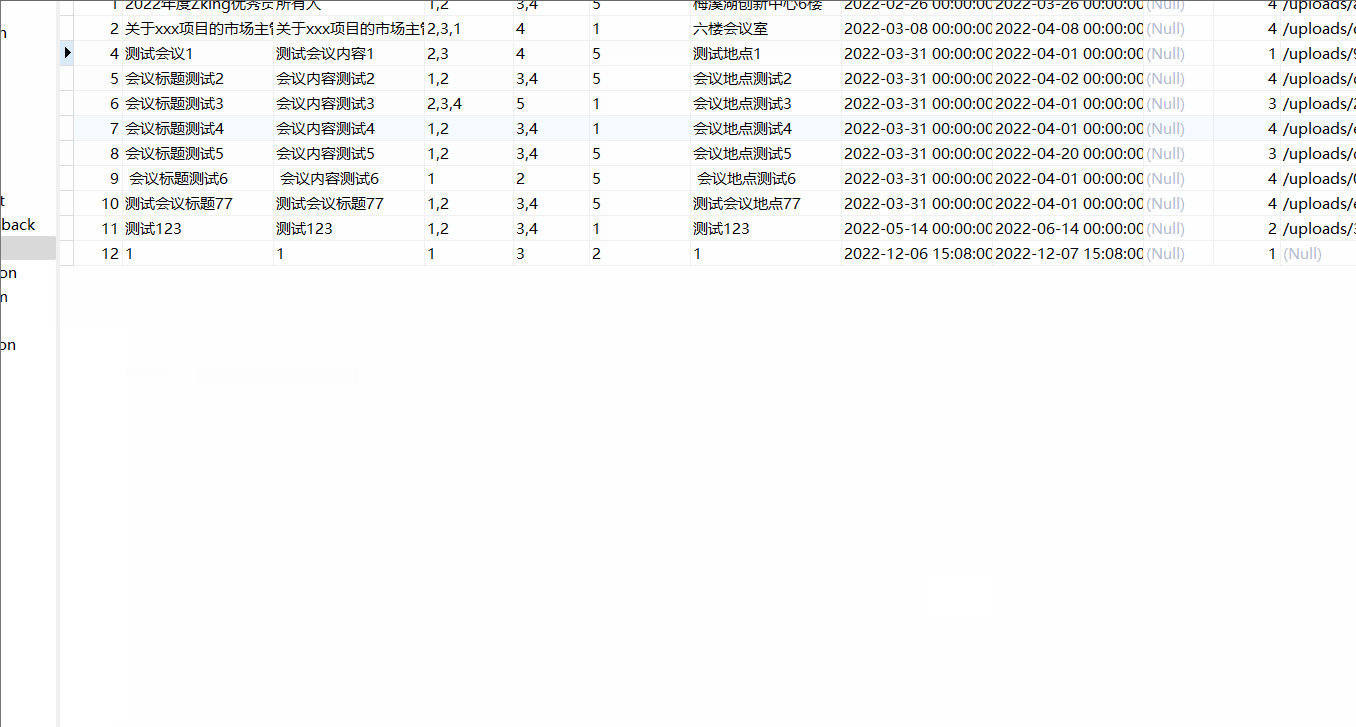
相同个人id下所有字段按时间顺序补位,取首个不为空值

--数据建表
drop table if exists db.tb_name;
create table if not exists db.tb_name
( id string,name string,tele string,email string,`date` string
)
;
insert overwrite table db.tb_name
values
("32001","张三","23456789",null,"2023-07-18")
,("32001",null,null,"23456789@163.com","2023-07-19")
,("32002","李四",null,"23456876@qq.com","2023-07-18")
,("32003","王二",null,null,"2023-07-18")
,("32003",null,"9876789",null,"2023-06-18")
,("32003",null,null,"9876789@gmail.com","2023-07-18")
,("32004","刘五","987456798",null,"2023-07-18")
,("32004","刘七","1987456798",null,"2023-07-20")
;
--distribute by 分区排序:类似MR中partition,进行分区,结合sort by使用drop table if exists db.tb_name_new;
create table if not exists db.tb_name_new as
select id ,collect_list(`name`)[0] as `name`,collect_list(`tele`)[0] as `tele`,collect_list(`email`)[0] as `email`,collect_list(`date`)[0] as `date`
from
(
select id,name,tele,email,`date`
from
db.tb_name
distribute by id
sort by id,`date` desc
) t
group by id
;
*注意:此处是取的首个不为空(即不为null)的字段,所以在实际使用过程中应提前将空字符串转为null值。
--剔除字符串中的不可见字符,若该字段中均为不可见字符或该字段为空字符串,则转为空
case when length(regexp_replace(col_name,'[\\x00-\\x08\\x0B-\\x0C\\x0E-\\x1F]+|\\s+',''))>0 then regexp_replace(col_name,'[\\x00-\\x08\\x0B-\\x0C\\x0E-\\x1F]+|\\s+','')else null end as new_col_name