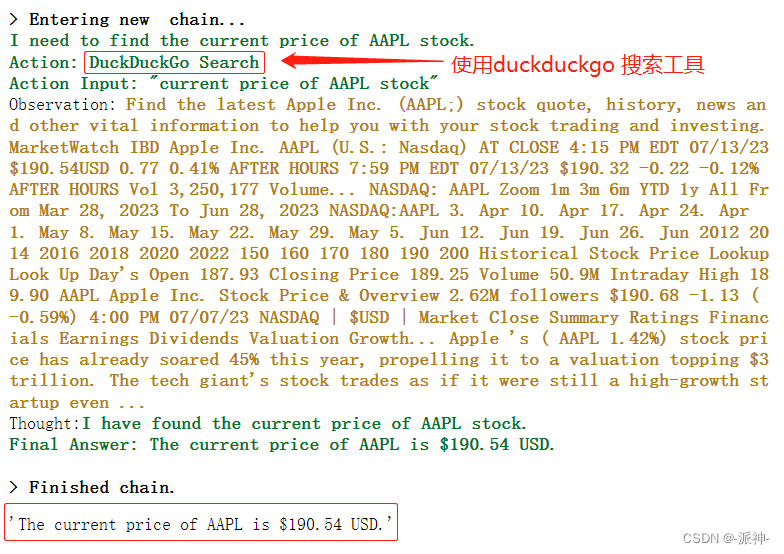
Es客户端
语言无关

java最常用的客户端是Java Client、Java Rest Client、Java Transport Client
Java Client
从es7.17开始,官方推出Java Client,并且将Java Rest Client标为Deprecated(过期)
要求jdk至少要jdk8
具体用法再看===》
Java Rest Client
Java Rest Client分为:
Java Low level Rest Client
Java High level Rest Client
在es7.15的时候过期的
RestClient 是线程安全的,RestClient使用 Elasticsearch 的 HTTP 服务,默认为9200端口,这一点和transport client不同。
Java Low level Rest Client
之所以称为低级客户端,是因为它几乎没有帮助 Java 用户构建请求或解析响应。它处理请求的路径和查询字符串构造,但它将 JSON 请求和响应主体视为必须由用户处理的不透明字节数组。
特点
与任何 Elasticsearch 版本兼容
ES 5.0.0只是发布第一个
Java Low-level REST client时的ES版本(2016年),不代表其向前只兼容到5.0,Java Low-level REST client基于Apache HTTP 客户端,它允许使用 HTTP 与任何版本的 Elasticsearch 集群进行通信。最小化依赖
跨所有可用节点的负载平衡
在节点故障和特定响应代码的情况下进行故障转移
连接失败惩罚(是否重试失败的节点取决于它连续失败的次数;失败的尝试越多,客户端在再次尝试同一节点之前等待的时间就越长)
持久连接
请求和响应的跟踪记录
可选的集群节点自动发现(也称为嗅探)
Java High Level REST Client
Java 高级 REST 客户端在 Java 低级 REST 客户端之上运行。
它的主要目标是公开 API 特定的方法,接受请求对象作为参数并返回响应对象,以便请求编组和响应解组由客户端本身处理。
要求Elasticsearch版本为2.0或者更高。
maven
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-client</artifactId><version>7.12.0</version>
</dependency>初始化
// 初始化
RestClient restClient = RestClient.builder(new HttpHost("localhost1", 9200, "http"),new HttpHost("localhost2", 9200, "http")).build();// 资源释放
restClient.close();简单用法
@Test@SneakyThrowspublic void createIndex() {//region 创建客户端对象RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));//endregion//region Request对象CreateIndexRequest request = new CreateIndexRequest("product2");//endregion//region 组装数据//region settingrequest.settings(Settings.builder().put("index.number_of_shards", 3).put("index.number_of_replicas", 0));//endregion//region mapping
// request.mapping(
// "{\n" +
// " \"properties\": {\n" +
// " \"message\": {\n" +
// " \"type\": \"text\"\n" +
// " }\n" +
// " }\n" +
// "}",
// XContentType.JSON);//region 还可以使用Map构建
// Map<String, Object> message = new HashMap<>();
// message.put("type", "text");
// Map<String, Object> properties = new HashMap<>();
// properties.put("message", message);
// Map<String, Object> mapping = new HashMap<>();
// mapping.put("properties", properties);
// request.mapping(mapping);//endregion//region 使用XContentBuilder构建
// XContentBuilder builder = XContentFactory.jsonBuilder();
// builder.startObject();
// {
// builder.startObject("properties");
// {
// builder.startObject("message");
// {
// builder.field("type", "text");
// }
// builder.endObject();
// }
// builder.endObject();
// }
// builder.endObject();
// request.mapping(builder);//endregion//endregion//region 别名request.alias(new Alias("product_alias").filter(QueryBuilders.termQuery("name", "xiaomi")));//endregionrequest.timeout(TimeValue.timeValueMillis(2));//endregion// 同步CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);// 异步client.indices().createAsync(request, RequestOptions.DEFAULT, new ActionListener<CreateIndexResponse>() {@Overridepublic void onResponse(CreateIndexResponse createIndexResponse) {}@Overridepublic void onFailure(Exception e) {}});// 是否所有节点都已确认请求createIndexResponse.isAcknowledged();// 在超时之前是否为索引中的每个碎片启动所需数量的碎片副本createIndexResponse.isShardsAcknowledged();client.close();}@Test@SneakyThrowspublic void getIndex() {RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));GetIndexRequest request = new GetIndexRequest("product*");GetIndexResponse response = client.indices().get(request, RequestOptions.DEFAULT);String[] indices = response.getIndices();for (String indexName : indices) {System.out.println("index name:" + indexName);}client.close();}@Test@SneakyThrowspublic void delIndex() {RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));DeleteIndexRequest request = new DeleteIndexRequest("product2");AcknowledgedResponse response = client.indices().delete(request, RequestOptions.DEFAULT);if (response.isAcknowledged()) {System.out.println("删除index成功!");} else {System.out.println("删除index失败!");}client.close();}@Test@SneakyThrowspublic void insertData() {//region 创建连接RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));//endregion//region 准备数据List<Product> list = service.list();//endregion//region 创建Request对象//插入数据,index不存在则自动根据匹配到的template创建。index没必要每天创建一个,如果是为了灵活管理,最低建议每月一个 yyyyMM。IndexRequest request = new IndexRequest("test_index");//endregion//region 组装数据Product product = list.get(0);Gson gson = new Gson();//最好不要自定义id 会影响插入速度。request.id(product.getId().toString());request.source(gson.toJson(product), XContentType.JSON);//endregion//region 执行Index操作IndexResponse response = client.index(request, RequestOptions.DEFAULT);//endregionSystem.out.println(response);client.close();}@Test@SneakyThrowspublic void batchInsertData() {//region 创建连接RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));//endregion//region 创建Request对象//批量插入数据,更新和删除同理BulkRequest request = new BulkRequest("test_index");//endregion//region 组装数据Gson gson = new Gson();Product product = new Product();product.setPrice(3999.00);product.setDesc("xioami");for (int i = 0; i < 10; i++) {product.setName("name" + i);request.add(new IndexRequest().id(Integer.toString(i)).source(gson.toJson(product), XContentType.JSON));}//endregionBulkResponse response = client.bulk(request, RequestOptions.DEFAULT);System.out.println("数量:" + response.getItems().length);client.close();}@Test@SneakyThrowspublic void getById() {//region 创建连接RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));//endregion//region 创建Request对象//注意 这里查询使用的是别名。GetRequest request = new GetRequest("test_index", "6");//endregion//region 组装数据String[] includes = {"name", "price"};String[] excludes = {"desc"};FetchSourceContext fetchSourceContext = new FetchSourceContext(true, includes, excludes);//只查询特定字段。如果需要查询所有字段则不设置该项。request.fetchSourceContext(fetchSourceContext);//endregion//region 响应数据GetResponse response = client.get(request, RequestOptions.DEFAULT);//endregionSystem.out.println(response);client.close();}@Testpublic void delById() throws IOException {//region DescriptionRestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));//endregionDeleteRequest request = new DeleteRequest("test_index", "1");DeleteResponse response = client.delete(request, RequestOptions.DEFAULT);System.out.println(response);client.close();}@Testpublic void multiGetById() throws IOException {//region DescriptionRestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));//endregion//region Description//根据多个id查询MultiGetRequest request = new MultiGetRequest();//endregion//region Descriptionrequest.add("test_index", "6");//两种写法request.add(new MultiGetRequest.Item("test_index","7"));//endregion//region DescriptionMultiGetResponse response = client.mget(request, RequestOptions.DEFAULT);//endregionfor (MultiGetItemResponse itemResponse : response) {System.out.println(itemResponse.getResponse().getSourceAsString());}client.close();}@Testpublic void updateByQuery() throws IOException {//region 连接RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));//endregion//region 请求对象UpdateByQueryRequest request = new UpdateByQueryRequest("test_index");//endregion//region 组装数据//默认情况下,版本冲突会中止 UpdateByQueryRequest 进程,但是你可以用以下命令来代替//设置版本冲突继续
// request.setConflicts("proceed");//设置更新条件request.setQuery(QueryBuilders.termQuery("name", "name2"));
// //限制更新条数
// request.setMaxDocs(10);request.setScript(new Script(ScriptType.INLINE, "painless", "ctx._source.desc+='#';", Collections.emptyMap()));//endregionBulkByScrollResponse response = client.updateByQuery(request, RequestOptions.DEFAULT);System.out.println(response);client.close();}
优缺点
优点
安全:REST API使用单一的集群入口点,可以通过 HTTPS 保障数据安全性,传输层只用于内部节点到节点的通信。
易用:客户端只通过 REST 层而不是通过传输层调用服务,可以大大简化代码编写缺点
性能略逊于Java API,但是差距不大
Low level Client
优点:
轻依赖:Apache HTTP 异步客户端及其传递依赖项(Apache HTTP 客户端、Apache HTTP Core、Apache HTTP Core NIO、Apache Commons Codec 和 Apache Commons Logging)
兼容性强:兼容所有ES版本
缺点:
功能少:显而易见,轻量化带来的必然后果High level Client
优点:
功能强大:支持所有ES的API调用。
松耦合:客户端和ES核心服务完全独立,无共同依赖。
接口稳定:REST API 比与 Elasticsearch 版本完全匹配的`Transport Client`接口稳定得多。
缺点:
兼容性中等:基于Low Level Client,只向后兼容ES的大版本,比如6.0的客户端兼容6.x(即6.0之后的版本),但是6.1的客户端未必支持所有6.0ES的API,但是这并不是什么大问题,咱们使用相同版本的客户端和服务端即可,而且不会带来其他问题。
Java Transport Client
使用的客户端名称叫TransportClient
从7.0.0开始,官方已经不建议使用TransportClient作为ES的Java客户端了,并且从8.0会被彻底删除
TransportClient 使用transport模块(9300端口)远程连接到 Elasticsearch 集群,客户端并不加入集群,而是通过获取单个或者多个transport地址来以轮询的方式与他们通信。
TransportClient使用transport协议与Elasticsearch节点通信,如果客户端的版本和与其通信的ES实例的版本不同,就会出现兼容性问题。而low-level REST使用的是HTTP协议,可以与任意版本ES集群通信。high-level REST是基于low-level REST的。
es整合java时,es的版本和java中的版本要保证大版本一致,比如,7.x
es的版本和springboot版本兼容性关系

依赖
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>transport</artifactId><version>7.12.1</version>
</dependency>连接
// 创建客户端连接
TransportClient client = new PreBuiltTransportClient(Settings.EMPTY).addTransportAddress(new TransportAddress(InetAddress.getByName("host1"), 9300)).addTransportAddress(new TransportAddress(InetAddress.getByName("host2"), 9300));// 关闭客户端
client.close();简单使用
@SneakyThrowsprivate void create(TransportClient client) {List<Product> list = service.list();for (Product item : list) {System.out.println(item.getDate().toLocalDateTime().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")));IndexResponse response = client.prepareIndex("product", "_doc", item.getId().toString()).setSource(XContentFactory.jsonBuilder().startObject().field("name", item.getName()).field("desc", item.getDesc()).field("price", item.getPrice()).field("date", item.getDate().toLocalDateTime().format(DateTimeFormatter.ofPattern("yyyy-MM-dd"))).field("tags", item.getTags().replace("\"", "").split(",")).endObject()).get();System.out.println(response.getResult());}}@SneakyThrowsprivate void get(TransportClient client) {GetResponse response = client.prepareGet("product", "_doc", "1").get();String index = response.getIndex();//获取索引名称String type = response.getType();//获取索引类型String id = response.getId();//获取索引idSystem.out.println("index:" + index);System.out.println("type:" + type);System.out.println("id:" + id);System.out.println(response.getSourceAsString());}private void getAll(TransportClient client) {SearchResponse response = client.prepareSearch("product").get();SearchHits searchHits = response.getHits();SearchHit[] hits = searchHits.getHits();for (SearchHit hit : hits) {String res = hit.getSourceAsString();System.out.println("res" + res);}}@SneakyThrowsprivate void update(TransportClient client) {UpdateResponse response = client.prepareUpdate("product", "_doc", "2").setDoc(XContentFactory.jsonBuilder().startObject().field("name", "update name").endObject()).get();System.out.println(response.getResult());}@SneakyThrowsprivate void delete(TransportClient client) {DeleteResponse response = client.prepareDelete("product", "_doc", "2").get();System.out.println(response.getResult());}kibana中操作的是Rest api
dsl转成代码
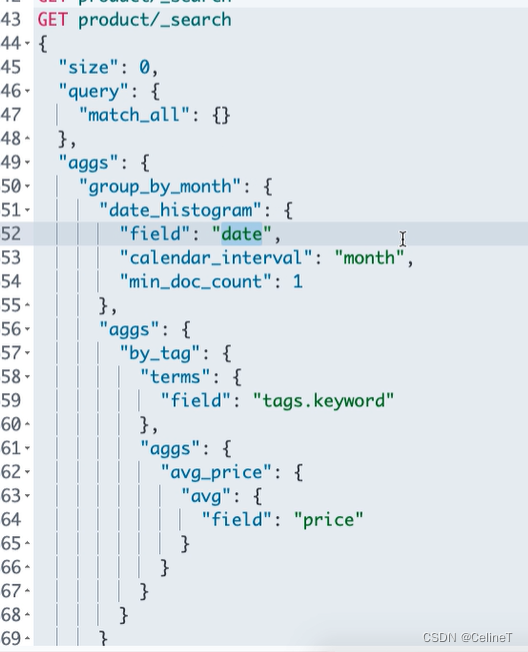
void aggSearch() {//region 1->创建客户端连接TransportClient client = new PreBuiltTransportClient(Settings.EMPTY).addTransportAddress(new TransportAddress(InetAddress.getByName("localhost"), 9300));//endregion//region 2->计算并返回聚合分析response对象SearchResponse response = client.prepareSearch("product").setSize(0).setQuery(QueryBuilders.matchAllQuery()).addAggregation(AggregationBuilders.dateHistogram("group_by_month").field("date").calendarInterval(DateHistogramInterval.MONTH).minDocCount(1).subAggregation(AggregationBuilders.terms("by_tag").field("tags.keyword").subAggregation(AggregationBuilders.avg("avg_price").field("price")))).execute().actionGet();//endregion//region 3->输出结果信息SearchHit[] hits = response.getHits().getHits();Map<String, Aggregation> map = response.getAggregations().asMap();Aggregation group_by_month = map.get("group_by_month");Histogram dates = (Histogram) group_by_month;Iterator<Histogram.Bucket> buckets = (Iterator<Histogram.Bucket>) dates.getBuckets().iterator();while (buckets.hasNext()) {Histogram.Bucket dateBucket = buckets.next();System.out.println("\n月份:" + dateBucket.getKeyAsString() + "\n计数:" + dateBucket.getDocCount());Aggregation by_tag = dateBucket.getAggregations().asMap().get("by_tag");StringTerms terms = (StringTerms) by_tag;Iterator<StringTerms.Bucket> tags = terms.getBuckets().iterator();while (tags.hasNext()) {StringTerms.Bucket tag = tags.next();System.out.println("\t标签名称:" + tag.getKey() + "\n\t数量:" + tag.getDocCount());Aggregation avg_price = tag.getAggregations().get("avg_price");Avg avg = (Avg) avg_price;System.out.println("\t平均价格:" + avg.getValue());}}//endregionclient.close();}
嗅探器sniffer
允许从正在运行的 Elasticsearch 集群中自动发现节点并将它们设置为现有 RestClient 实例的最小库(在集群中,根据一个节点找到其他节点)
依赖
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-client-sniffer</artifactId><version>7.12.1</version>
</dependency>// 默认每五分钟发现一次
RestClient restClient = RestClient.builder(new HttpHost("localhost", 9200, "http")).build();
Sniffer sniffer = Sniffer.builder(restClient).build();// 设置嗅探间隔
RestClient restClient = RestClient.builder(new HttpHost("localhost", 9200, "http")).build();
// 设置嗅探间隔为60000毫秒
Sniffer sniffer = Sniffer.builder(restClient).setSniffIntervalMillis(60000).build();// 失败时重启嗅探
SniffOnFailureListener sniffOnFailureListener =new SniffOnFailureListener();
RestClient restClient = RestClient.builder(new HttpHost("localhost", 9200)).setFailureListener(sniffOnFailureListener) //将失败侦听器设置为 RestClient 实例 .build();
Sniffer sniffer = Sniffer.builder(restClient).setSniffAfterFailureDelayMillis(30000) //在嗅探失败时,不仅节点在每次失败后都会更新,而且还会比平常更早安排额外的嗅探轮次,默认情况下是在失败后一分钟,假设事情会恢复正常并且我们想要检测尽快地。可以在 Sniffer 创建时通过 setSniffAfterFailureDelayMillis 方法自定义所述间隔。请注意,如果如上所述未启用故障嗅探,则最后一个配置参数无效。.build();
sniffOnFailureListener.setSniffer(sniffer); //将 Sniffer 实例设置为失败侦听器// 资源释放
// Sniffer 对象应该与RestClient 具有相同的生命周期,并在客户端之前关闭。
sniffer.close();
restClient.close();Spring Data Elasticsearch
Spring Data 的目的是用统一的接口,适配所有不同的存储类型。
Spring Data Elasticsearch是Spring Data的一个子项目,该项目旨在为新数据存储提供熟悉且一致的基于 Spring 的编程模型,同时保留特定于存储的功能和功能。Spring Data Elasticsearch是一个以 POJO 为中心的模型,用于与 Elastichsearch 文档交互并轻松编写 Repository 风格的数据访问层
特点
Spring 配置支持使用基于 Java 的
@Configuration类或用于 ES 客户端实例的 XML 命名空间。
ElasticsearchTemplate提高执行常见 ES 操作的生产力的助手类。包括文档和 POJO 之间的集成对象映射。功能丰富的对象映射与 Spring 的转换服务集成
基于注释的映射元数据但可扩展以支持其他元数据格式
Repository接口的自动实现,包括对自定义查找器方法的支持。对存储库的 CDI 支持
依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>注解
@Document:在类级别应用,以指示该类是映射到数据库的候选类。最重要的属性包括:
indexName:用于存储此实体的索引的名称。它可以包含类似于“日志-#{T(java.time.LocalDate).now().toString()}”
type :映射类型。如果未设置,则使用该类的小写简单名称。(自4.0版起已弃用)
createIndex:标记是否在存储库引导时创建索引。默认值为true。请参阅自动创建带有相应映射的索引
versionType:版本管理的配置。默认值为外部 .
@Id:在字段级别应用,以标记用于标识的字段。
@Transient:默认情况下,存储或检索文档时,所有字段都映射到文档,此批注不包括该字段。
@PersistenceConstructor:标记在从数据库实例化对象时要使用的给定构造函数(甚至是包受保护的构造函数)。构造函数参数按名称映射到检索文档中的键值。
@Field:应用于字段级别并定义字段的属性,大多数属性映射到相应的Elasticsearch映射定义(以下列表不完整,请查看注释Javadoc以获取完整的参考):
name:将在Elasticsearch文档中表示的字段的名称,如果未设置,则使用Java字段名称。
type:字段类型,可以是Text,关键字,Long,Integer,Short,Byte,Double,Float,Half_Float,Scaled_Float,日期,日期Nanos,Boolean,Binary,Integer_Range,Float_Range,Long_Range,DoubleˉRange,DateˉRange,Object,Nested,Ip,TokenCount,percollator,flatten,搜索。请参阅Elasticsearch映射类型
format:一个或多个内置日期格式,请参阅下一节格式数据映射 .
pattern:一个或多个自定义日期格式,请参阅下一节格式数据映射 .
store:标志是否应将原始字段值存储在Elasticsearch中,默认值为假 .
analyzer ,搜索分析器 ,normalizer用于指定自定义分析器和规格化器。
@GeoPoint:将字段标记为地理点如果字段是GeoPoint班级
简单使用
public class EsUtil {// 生成批量处理对象private static BulkRequest bulkRequest = new BulkRequest();/*** 添加数据到es* @param indexName* @param typeName* @param indexId* @param json*/public static void add(RestHighLevelClient restHighLevelClient, String indexName, String typeName, String indexId, Map<String, Object> json) throws IOException {IndexRequest indexRequest = new IndexRequest(indexName, typeName,indexId);
// Gson gson = new Gson();indexRequest.source(new JSONObject(json).toString(), XContentType.JSON);try {restHighLevelClient.index(indexRequest,RequestOptions.DEFAULT);} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}/*** 判断索引名是否存在* @param indexName* @return*/public static boolean existsIndex(RestHighLevelClient restHighLevelClient,String indexName) {try{GetIndexRequest request = new GetIndexRequest(indexName);boolean exists = restHighLevelClient.indices().exists(request, RequestOptions.DEFAULT);return exists;}catch (Exception e){System.out.println("Exception");}return false;}/*** @param : client* @description : 判断文档是否存在*/public static boolean isExist(RestHighLevelClient restHighLevelClient, String indexName, String typeName, String indexId) throws IOException{GetRequest request = new GetRequest(indexName, typeName, indexId);//1.同步判断boolean exists = restHighLevelClient.exists(request, RequestOptions.DEFAULT);//2.异步判断ActionListener<Boolean> listener = new ActionListener<Boolean>() {@Overridepublic void onResponse(Boolean exists) {if (exists){System.out.println("文档存在");}else {System.out.println("文档不存在");}}@Overridepublic void onFailure(Exception e) {}};//client.existsAsync(request, RequestOptions.DEFAULT, listener);return exists;}/*** @param : client* @description : 删除文档*/public static void deleteDocument(RestHighLevelClient restHighLevelClient, String indexName, String typeName, String indexId) throws IOException{DeleteRequest request = new DeleteRequest(indexName,typeName,indexId);//设置请求超时时间:2分钟request.timeout(TimeValue.timeValueMinutes(2));//request.timeout("2m");//同步删除DeleteResponse deleteResponse = restHighLevelClient.delete(request, RequestOptions.DEFAULT);//异步删除ActionListener<DeleteResponse> listener = new ActionListener<DeleteResponse>() {@Overridepublic void onResponse(DeleteResponse deleteResponse) {System.out.println("删除后操作");}@Overridepublic void onFailure(Exception e) {System.out.println("删除失败");}};}/*** 批量增加数据的方法* @param restHighLevelClient* @param indexname* @param typename* @param row_key* @param map* @throws Exception*/public void bulkadd(RestHighLevelClient restHighLevelClient, String indexname, String typename, String row_key, Map<String,Object> map) throws Exception {try {// 生成批量处理对象//BulkRequest bulkRequest = new BulkRequest();// 得到某一行的数据,并封装成索引对象IndexRequest indexRequest = new IndexRequest(indexname, typename,row_key);indexRequest.source(new JSONObject(map).toString(), XContentType.JSON);//判断是否执行加载if (bulkRequest.numberOfActions() != 0 && (bulkRequest.numberOfActions() > 100)) {try {bulkRequest(restHighLevelClient);} catch (Exception e) {e.printStackTrace();}}// 装填数据bulkRequest.add(indexRequest);} catch (Exception e) {e.printStackTrace();}finally {bulkRequest(restHighLevelClient);}}/*** 批量具体执行方法* execute bulk process* @throws Exception*/private void bulkRequest(RestHighLevelClient restHighLevelClient) throws Exception {// 加载数据BulkResponse bulkResponse = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);// 判断加载情况if(bulkResponse.hasFailures()){System.out.println("失败");}else{System.out.println("成功");// 重新定义bulkRequest = new BulkRequest();}}}