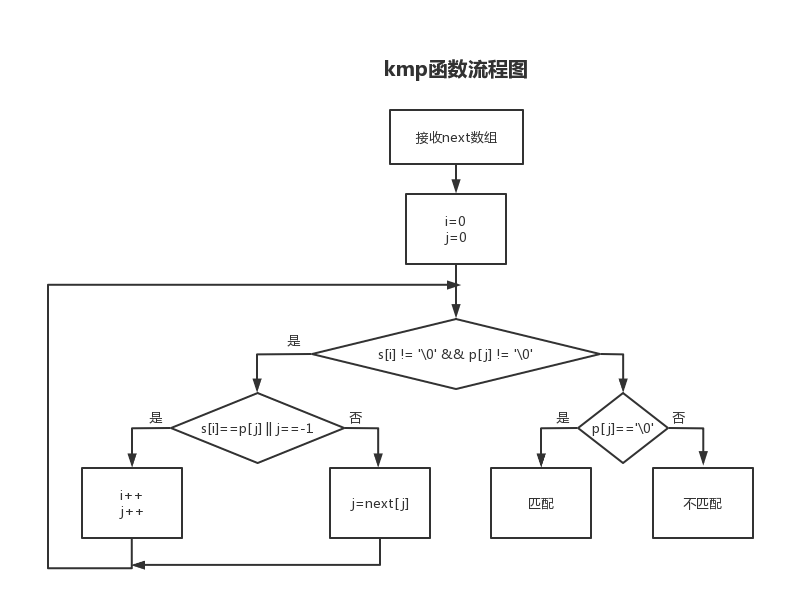
📚引言
🙋♂️作者简介:生鱼同学,大数据科学与技术专业硕士在读👨🎓,曾获得华为杯数学建模国家二等奖🏆,MathorCup 数学建模竞赛国家二等奖🏅,亚太数学建模国家二等奖🏅。
✍️研究方向:复杂网络科学
🏆兴趣方向:利用python进行数据分析与机器学习,数学建模竞赛经验交流,网络爬虫等。
泰坦尼克号的沉没是历史上最惨痛的沉船事件之一。
1912年4月15日,泰坦尼克号在其处女航中与冰山相撞后沉没,2224名乘客和船员中的1502人死亡。
在这个数据分析项目中,我们需要完成对什么样的人有可能幸存的分析。
特别是,我们需要你应用机器学习的工具来预测哪些乘客在悲剧中幸存下来。
在本文中,我们就从数据的角度出发对泰坦尼克幸存者进行分析与预测,话不多说我们开始吧。
📖数据获取
本项目数据基于Kaggle中泰坦尼克数据,需要的小伙伴可以自行登录Kaggle中进行下载,或者私信我索要链接。
kaggle的链接如下:
KAGGLE竞赛链接
当我们成功注册账号后,可以在竞赛链接中找到泰坦尼克沉船存活的竞赛链接,如下图所示:
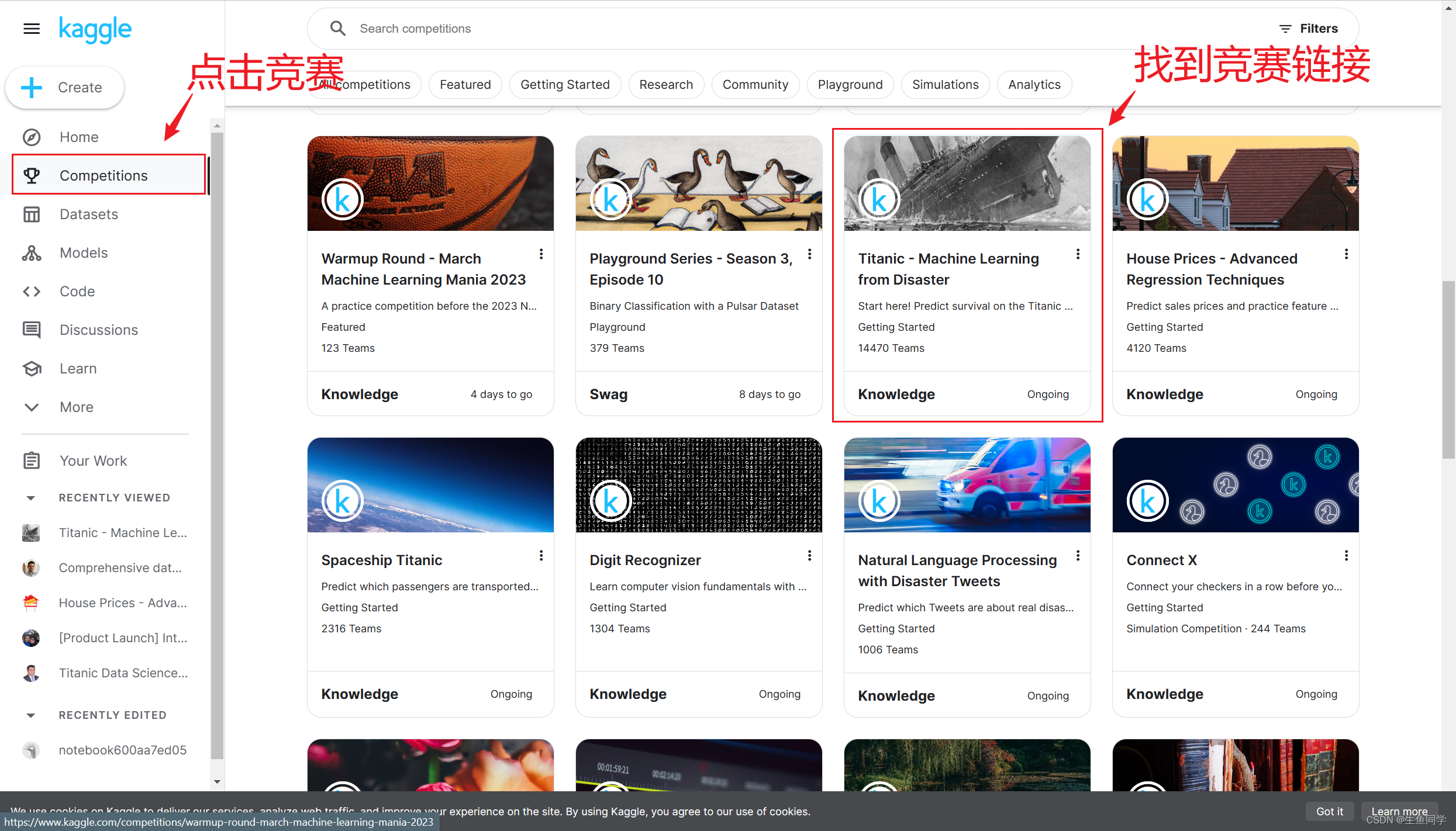
进入竞赛页面后,可以看到关于竞赛的简单介绍以及其他人的代码等内容,在这里我们点击Data。

注意下面的数据介绍,这里的数据介绍将会帮助我们了解数据的基本情况以及其代表的内容。
我们获取到数据之后,打开编译环境准备开始进行数据分析,在本文中我使用的是jupyter进行数据分析,当然可以选择自己习惯的编译环境进行后续的工作。
拿到数据之后,我们首先编写代码将其读取进编译环境中,代码如下:
# 导入pandas
import pandas as pd
# 将训练集数据导入
data = pd.read_csv('train.csv')
导入数据后的结果如下:

📖数据初步观察与处理
📃数据观察
🔖数据清理4C原则
在我们拿到数据后,我们需要对数据进行初步的观察以及数据清洗。这里介绍Kaggle大佬提出的数据清理4C原则,其分别是:
-
Correcting(纠正):顾名思义,纠正数据就是对数据进行异常值的处理。例如年龄如果存在100+的数据,那么这一定是不正常的值。我们将对不同的数据进行异常值的检查以确保其是正常有效的。但是,当我们从原始的数据中修改数据的时候一定要谨慎行事,因为建立一个准确的模型的基石就是数据,数据决定了模型的好坏
-
Completing(补充):补充缺失值以及被我们所发现的异常值是必须的。虽然在某些模型中,可以自动的帮助我们处理缺失值儿不需要处理(例如决策树)。在这部分中,我们通常会选择缺失占比小的缺失值进行删除,儿占比较大或者占比非常大的缺失值,我们会考虑在原有的数据中探寻某种规律将其进行填充。
-
Creating(创建):特征工程中需要我们对原有的特征进行理解并决定是否提取新的特征。例如,在本题中我们可以考虑对年龄进行分段作为一个新的特征考虑在内。当然这里的前提是,我们对问题有一个深刻的了解,探寻我们提取的特征是否真的能够对最后的模型构建有帮助。这就需要我们反复验证,思考进行提取特征,找寻到真正对不同问题有帮助的特征。
-
Converting(转换):在针对某些特定的数据格式的时候,可能还需要我们进行数据转换。这当然是非常重要的,例如某些字符串类型的数据,需要我们转换为数值的形式来表示。
在这一步中,我们将调用pandas中的基本函数对数据进行初步的观察。我们首先调用info()查看数据的类型以及基本情况,代码如下:
data.info()
结果如下:

当我们调用该函数后,可以看到所有数据的类型以及基本情况。
这里需要注意我标注的数据,我们发现Age数据与其它数据相比数量少了很多,也就是我们说的缺失值。与此同时,可以看到Cabin以及Embarked也存在缺失的情况。
这些都需要我们关注,并在后续进行一些处理。
随后,我们调用describe()函数进一步观察数据的分布情况,该函数可以帮助我们计算每列数据的分布以及平均值等内容。代码如下:
data.describe()
结果如下:
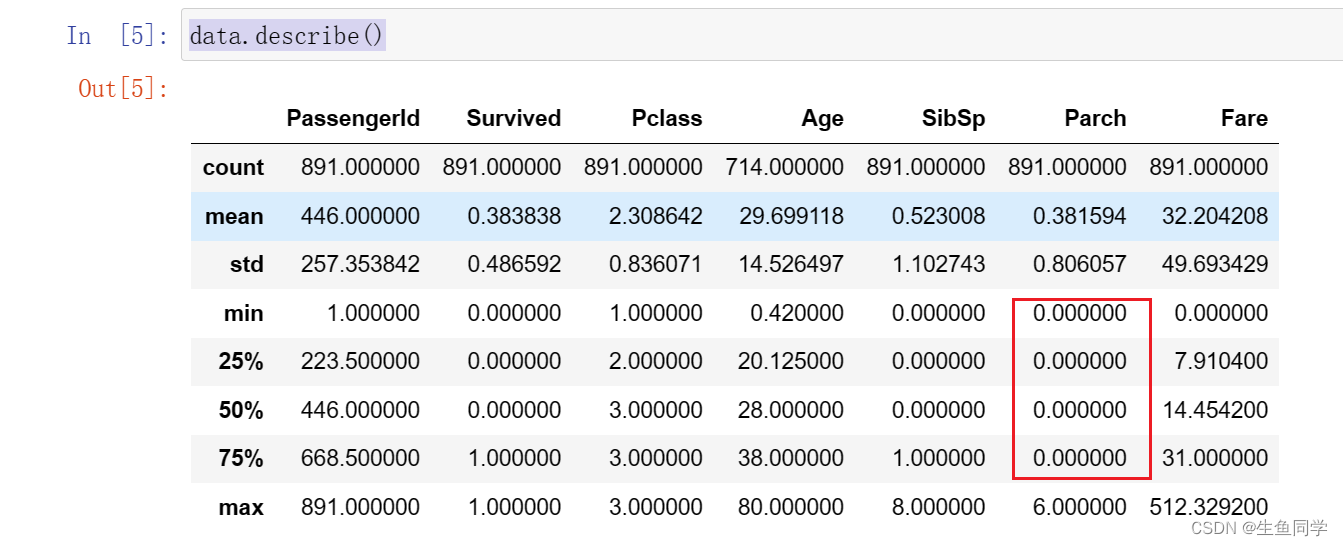
这里我们发现Parch数据的75%都是0,存在明显的分布不均匀的情况,后续可能需要处理。
📃缺失值处理(Completing)
在上节中,我们发现数据存在一定的缺失情况,我们首先对其进行可视化,这能够使得我们对数据的观察更直观。
在这里我们用到了missingno库进行缺失数据的可视化,其对缺失数据的可视化更加直观。
使用之前,请确保自己已经安装该库。
使用该库进行可视化的代码如下:
# 在数据中抽样100个单位
data_sample = data.sample(100)
msno.matrix(data_sample)
结果如下:
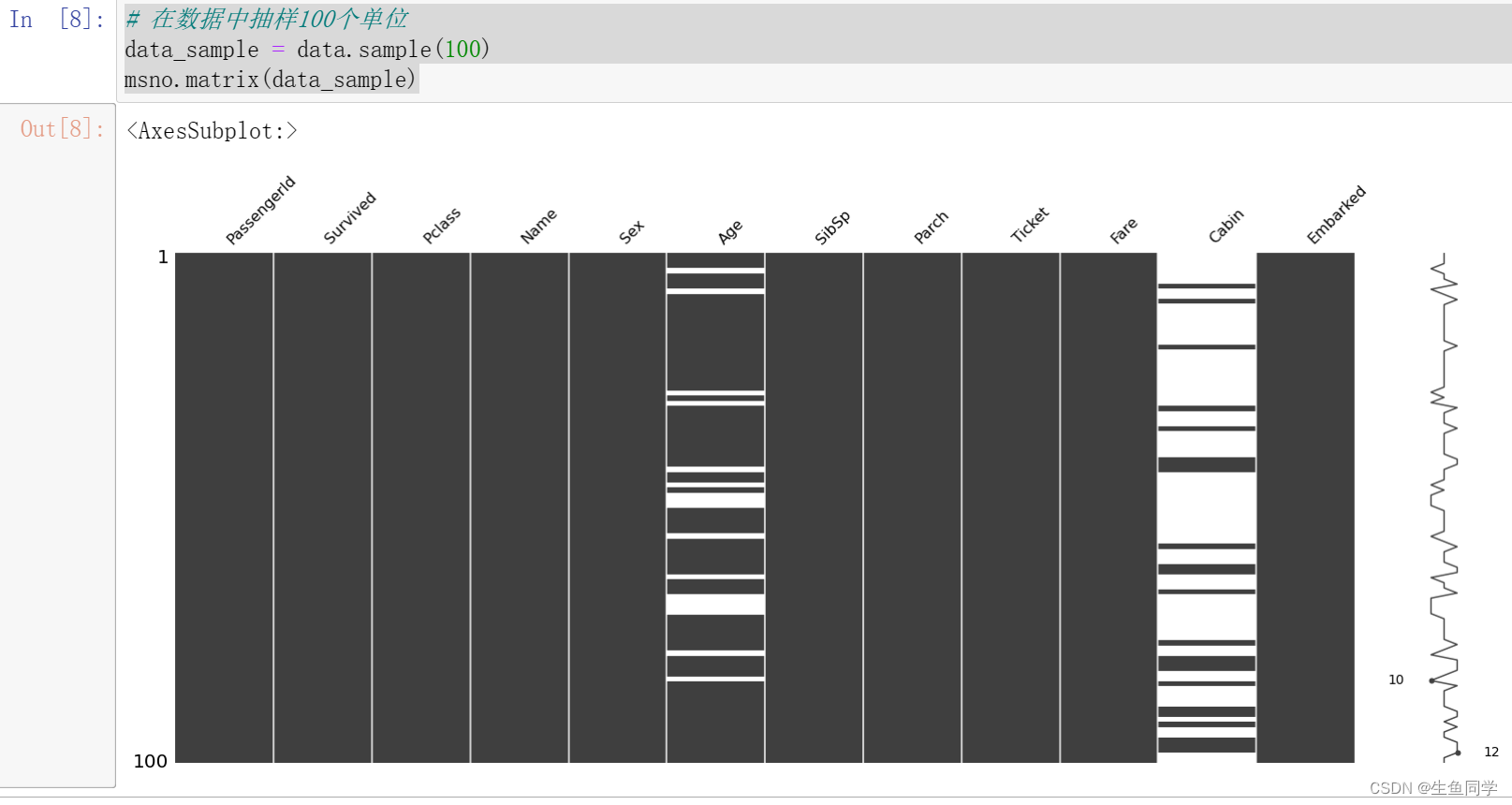
可以发现,Cabin的缺失值较为明显,Age也存在一些缺失值。
因为数据中每列代表的情况不尽相同,所以我们将针对数据进行不同的处理方法。
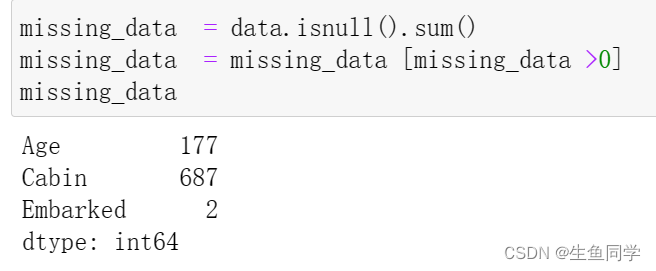
我们再通过代码来观察一下缺失的数据情况,代码与结果如下:
missing_data = data.isnull().sum()
missing_data = missing_data [missing_data >0]
missing_data
🔖Embarked的处理
我们首先处理Embarked列,在上边的数据观察中发现其拥有两个缺失值,因为相对于全部的一千条数据来说其量级较小,所以我们在这里直接选择该列缺失的两条数据进行删除处理,代码如下:
# 在data中寻找Embarked的缺失值 找到后在原表中将其行删除
data.dropna(axis=0, how='any',subset=['Embarked'], inplace=True)
dropna 参数介绍:
axis: default 0指行,1为列
how: {‘any’, ‘all’}, default ‘any’指带缺失值的所有行;'all’指清除全是缺失值的
thresh: int,保留含有int个非空值的行
subset: 对特定的列进行缺失值删除处理
inplace: 这个很常见,True表示直接在原数据上更改
🔖Age的处理
在上述观察中,我们发现Age存在一定的缺失情况,接下来我们对其进行处理。
我们由Kaggle中的数据介绍中了解到,其表示乘客的年龄,且缺失值相对来说较多,不能够直接采用删除的方式。
我们首先观察Age的分布情况,绘制年龄的直方图,代码如下:
data.hist(column='Age')
结果如下:
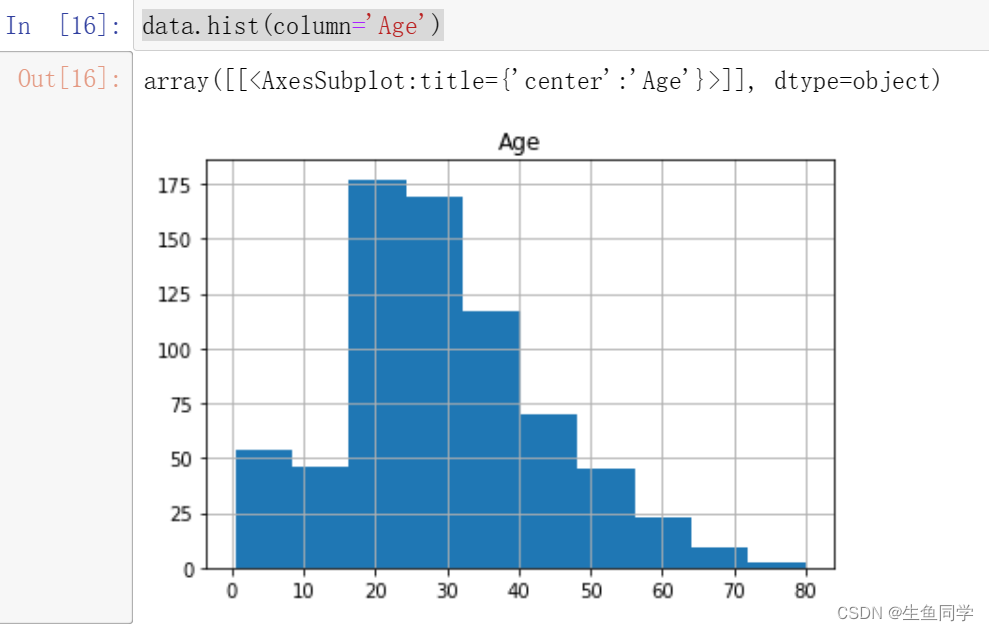
我们注意到,年龄的分布存在一定的偏态,这时候更适合采用中位数进行填充。
注意:偏态分布的大部分值都聚集在变量分布的一侧,中位数可以很好的表示中心趋势。
所以,我们对年龄的缺失值进行中位数的填充。代码如下:
data['Age'].fillna(data['Age'].median(), inplace=True)
至此,我们对于年龄的缺失值处理完毕。
🔖Cabin的处理
我们首先看一下Cabin的数据解释:Cabin number(机舱号码)
对于该特征来说,仿佛对于最终的数据帮助不大。即使其对于最后的数据是非常重要的,由于其缺失值过多且不容易探寻其中的规律,我们还是选择对其做删除的处理。
代码如下:
# 这里我直接删除了该列
del data['Cabin']
至此,所有数据的缺失值处理完毕。
📃异常值的检测与处理(Correcting)
在本例中,我们能够进行检测并处理的主要是Age特征,因为我们预先知道其大概的范围。在这里我们绘制箱线图观察其数据的异常情况决定是否需要进行处理,代码如下:
data['Age'].plot.box()
结果如下:
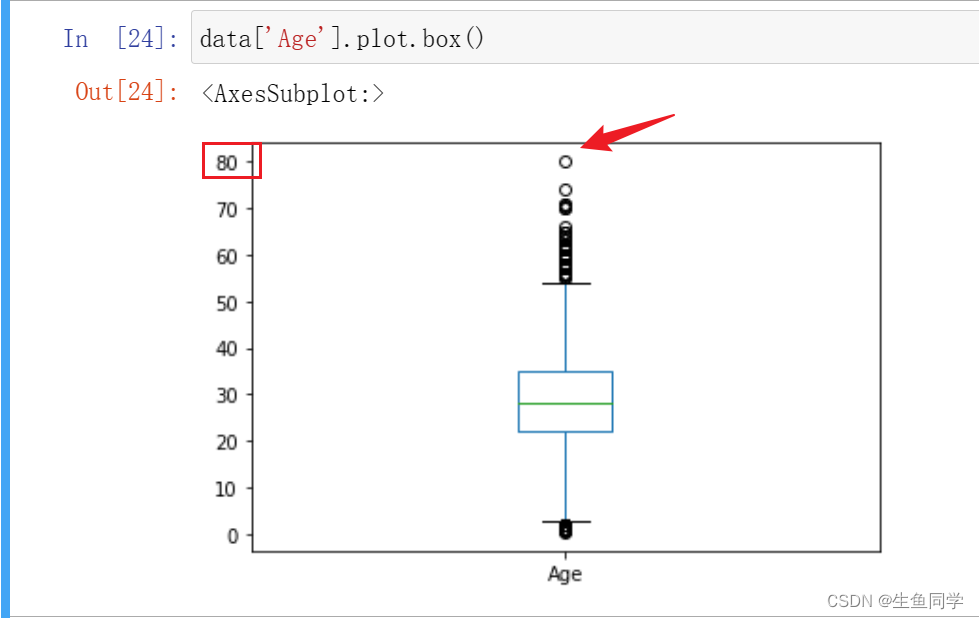
在这里,我们可以看到该数据的最高点在80,符合我们对于数据的预先认知,遂不进行处理。
📃特征构建(Create)
在这部分中,要求我们对不同的特征有一定的了解以及认识,在这里我列出所有的特征含义。
| 特征名称 | 含义 |
|---|---|
| survival | 是否存活,1表示存活,0表示没有 |
| pclass | 表示票的种类,分别为1,2,3等 |
| sex | 性别 |
| Age | 年龄 |
| sibsp | 在泰坦尼克号上的兄弟姐妹/配偶的数量 |
| parch | 在泰坦尼克号上的父母/子女人数 |
| ticket | 票号 |
| fare | 乘客票价 |
| cabin | 机舱号 |
| embarked | 上岸港口 ,C = Cherbourg, Q = Queenstown, S = Southampton |
在这里,我们提取两个特征,分别是乘客家庭规模,是否独自一人,并对票价以及年龄进行分段构造两个新的特征。
注意:针对不同的项目采取的特征提取工作并不相同,因为这需要根据具体的业务进行分析并提取。
我们首先针对家庭规模以及是否独自一人创建新的两个特征,代码如下:
data['FamilySize'] = data['SibSp'] + data['Parch'] + 1data['IsAlone'] = 1
data['IsAlone'].loc[data['FamilySize'] > 1] = 0
然后,我们对年龄和票价进行分段,代码如下:
data['FareBin'] = pd.qcut(data['Fare'], 4)
data['AgeBin'] = pd.cut(data['Age'].astype(int), 5)
这里简单介绍一下上述两个函数的区别与作用
qcut:根据传入的数值进行等频分箱,即每个箱子中含有的数的数量是相同的。
cut:根据传入的数值进行等距离分箱,即每个箱子的间距都是相同的。
特别的,在本节中特征工程的过程要根据实际业务进行不同的特征提取,这个过程需要我们对业务有足够的理解程度。几个好的特征对后续的模型精确程度有很大的积极影响。
📃数据格式转换(Convert)
某些特定的格式在很多模型中其实是不适用的,在本例中经过上述处理后的数据如下所示:
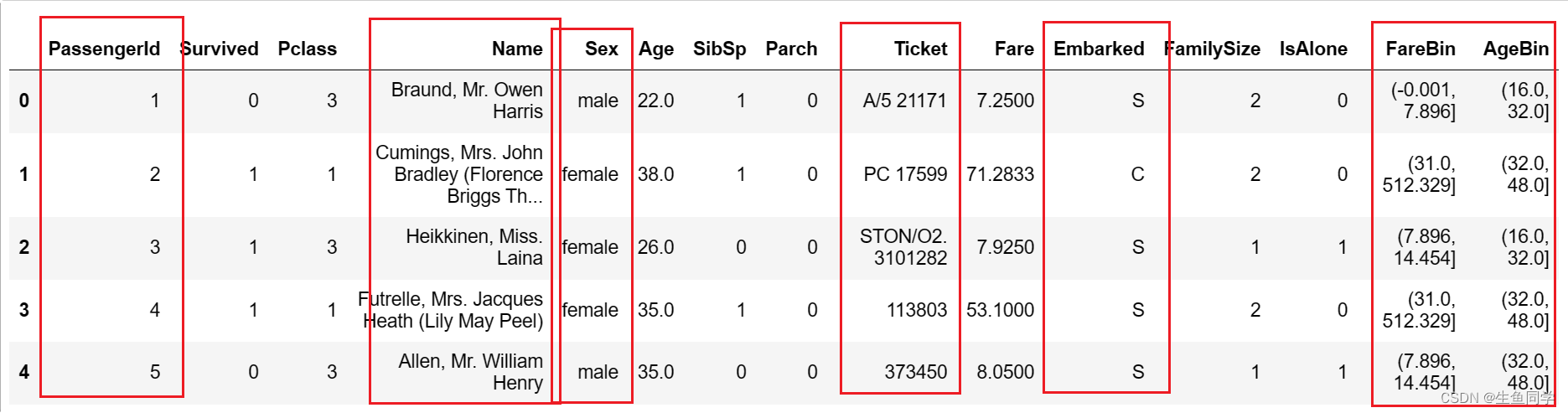
图中的性别等内容都为字符类型,这显然在模型中存在一定的不兼容情况,这就需要我们进行一定程度的格式转换。
在本部分中,我们要处理的有以下几个部分:
- PassengerId:用户id的部分对后面的预测仿佛用处不大,我们对其进行删除。
- Name:这里的名字中有MR.MISS等信息,这可能对后续的模型有帮助,我们对其进行处理保留。
- Sex:需要进行编码使用,因为它是字符串类型。
- Ticket:仿佛用处不大,这里我们选择删除。
- Embarked:需要进行编码使用,因为它是字符串类型。
- FareBin:需要进行编码使用,因为它是一个范围。
- AgeBin:需要进行编码使用,因为它是一个范围。
我们首先对需要删除的两列进行删除的操作,代码如下:
del data['PassengerId']
del data['Ticket']
然后我们对Name进行处理,将其中的身份信息提取出来,代码如下:
data['Title'] = data['Name'].str.split(", ", expand=True)[1].str.split(".", expand=True)[0]
结果如下:

最后,我们对需要编码的数据进行编码:
from sklearn.preprocessing import OneHotEncoder, LabelEncoder
label = LabelEncoder()data['Sex_Code'] = label.fit_transform(data['Sex'])
data['Embarked_Code'] = label.fit_transform(data['Embarked'])
data['Title_Code'] = label.fit_transform(data['Title'])
data['AgeBin_Code'] = label.fit_transform(data['AgeBin'])
data['FareBin_Code'] = label.fit_transform(data['FareBin'])
编码后的结果如下:
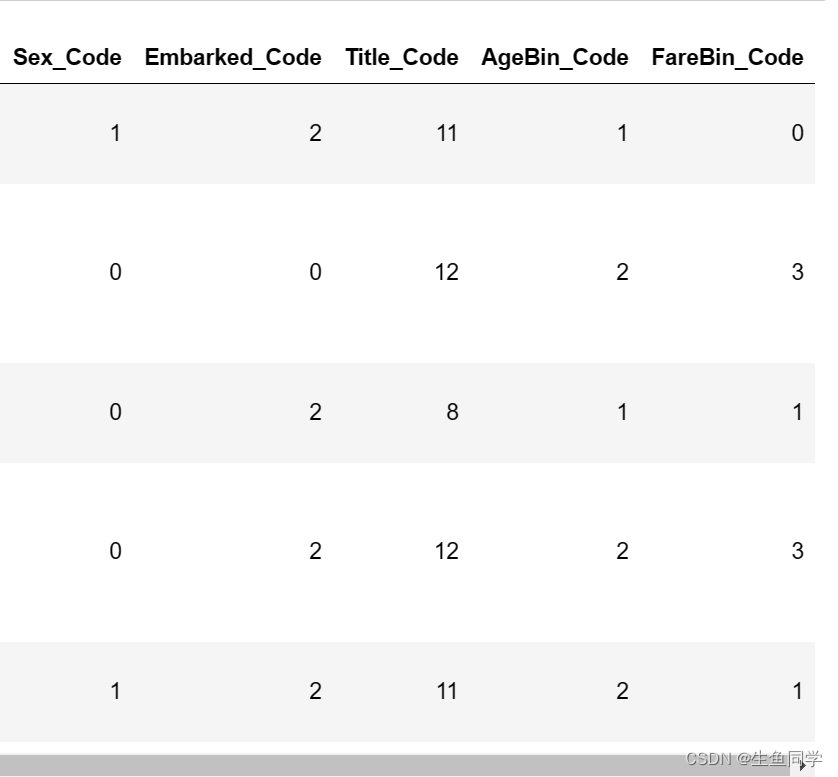
至此,数据格式转换已经完毕。
📖模型构建与评价
在本节中,我们将基于上述数据进行模型的构建,并且通过不同的评价指标进行构建。
📃模型构建
在这里我将会使用基础的分类模型进行模型的构建,并挑选出初步表现最好的模型进行参数调节。代码如下:
# 处理不需要的数据列
data_x = data.copy()
del data_x['Survived']
del data_x['Name']
del data_x['Sex']
del data_x['FareBin']
del data_x['AgeBin']
del data_x['Title']
del data_x['Embarked']
# 构建y
data_y = data['Survived']
# 导入包
from sklearn import svm, tree, linear_model, neighbors, naive_bayes, ensemble, discriminant_analysis, gaussian_process
from sklearn.model_selection import cross_val_score
# 定义常用的几种分类模型
MLA = {#随机森林'随机森林':ensemble.RandomForestClassifier(),#逻辑回归'逻辑回归':linear_model.LogisticRegressionCV(max_iter=3000),#SVM'SVM':svm.SVC(probability=True),#树模型'树模型':tree.DecisionTreeClassifier(),}
# 进行5折交叉验证并选择f1作为评价指标
for model_name in MLA:scores = cross_val_score(MLA[model_name], X=data_x, y=data_y, verbose=0, cv = 5, scoring='f1')print(f'{model_name}:',scores.mean())
结果如下:

我们可以看到,目前随机森林的效果最好,所以我们选择随机森林进行参数调节。
📃参数调节
在这里我们选择使用网格调参的方式进行参数调节,代码如下:
from sklearn.model_selection import GridSearchCVn_estimators = [3,5,10,15,20,40, 55]
max_depth = [10,100,1000]parameters = { 'n_estimators': n_estimators, 'max_depth': max_depth}model = ensemble.RandomForestClassifier()
clf = GridSearchCV(model, parameters, cv=5)
clf = clf.fit(data_x, data_y)
clf.best_estimator_
结果如下:

在这里,我们选择了几个简单的参数进行调节,可以根据自己的实际情况对不同的参数进行调节。我们再进行一次交叉验证求平均值看一下效果,结果如下:

可以看到与刚才的效果相比有一些提升。
📍总结
至此,我们的基于python对泰坦尼克幸存者进行分析与预测已经完全结束。
当然,这只是对整个数据分析的过程的简单介绍,大家可以根据实际的情况进行不同程度的更改。
在数据分析的过程中还需要进行可视化等不同的内容,大家可以根据自己的需要进行编码或分析。
最后,验证集的数据清洗以及处理的相关工作大同小异,感兴趣的朋友们可以自己按照上述步骤进行操作,或在评论区与我讨论。
需要源码的朋友可以私信我进行索取,我们下次再见。