#国科大#
#复习#
#nlp#

第七章 只1~2个有常识性的问题,基本不考 ;第九章不考 ;第十章 只考 第一节 问答系统 (机器阅读理解 和 智能对话 不考)
一道计算 两道设计
大题预测
综合题(计算题+模型结构分析题+模型设计题,3题)
- 维比特、前向、后向计算题
- 写出各种模型的输入输出。比如CBOW输入(x1x2x4x5)输出x3
- 设计题:设计一个带有Attention机制的神经网络序列生成模型,要求可完成机器翻译任务也可完成自动文摘任务。画出模型结构,写出输入,输出,函数关系,解释模型原理,介绍模型如何训练,说明加入attention有哪些好处。(要同时完成生成任务和选择任务)

- 模型结构分析题
- 模型设计题
1)维特比算法(10分)
123三个状态,ABC三种观测,计算量不大,都是一位小数。每个状态只能转换到自身与后面的状态,一个状态只对应两个观测。比如1状态只能转换到1和2,产生A或B观测。

(2)语言模型
假设输入是 (x1, x2, x3, x4, x5) 的一个序列,写出下列LM的输入与目标输出:
- DNN
- RNN
- CBOW
- SkipGram
- GPT
- BERT

(3)设计题
设计一个能够处理翻译与摘要任务的model,且含有Attention机制
- 画图,描述输入输出与函数关系;
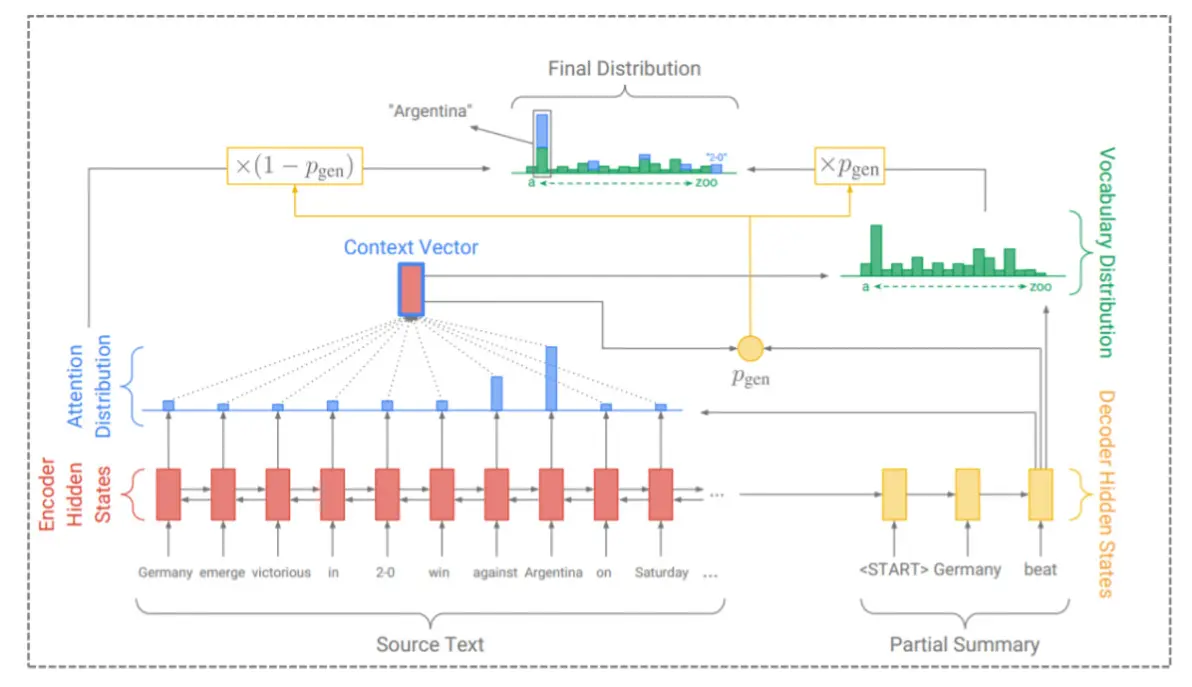
- 训练方法,损失函数是什么损失函数是对数损失。初始化随机权重和偏差,把输入传入网络,正向传播,得到输出值。计算预测值和真实值之间的误差。然后BPTT,对每一个产生误差的神经元,改变相应的(权重)值以减小误差。迭代更新,直到找到最佳权重。
- 工作原理是什么将编码-解码+注意力模型和指针网结合,生成既可产生也可选择的输出。
https://www.bilibili.com/opus/748005190865518612
https://blog.csdn.net/AAArwei/article/details/128649938#t15
一 | NLP各范式概念 机器学习基本概念
-
人工智能:
建立可智能化处理事物的系统。让机器能够像人类一样完成智能任务(如学习、推理、规划、决策等等)。
-
人工智能起源:
图灵测试
-
人工智能层次:
-
弱人工智能
完成特定任务的人工智能;
表现像是有智能的样子;
不具有自我意识;
不会威胁到人类生存;
目前,已经实现了越来越多的弱人工智能 -
强人工智能
通用人工智能;
机器具有真正的推理和解决问题的能力,与人类一样拥有进行所有工作的可能;
不具有自我意识;
可能威胁到人类生存; -
超级人工智能
超级人工智能是指具有 自我意识,包括独立自 主的价值观、世界观等;
在几乎所有领域都比最聪明的人类大脑聪明很多,包括科学创新、通识和社交技能等
-
-
认知能力(cognitive abilities,cognitive ability):
是通过大量信息的输入,然后在大脑的思维模式中经过处理,最后输判断的一种能力。
-
自然语言处理:
是人工智能的一个分支,用于分析、理解和生成自然语言,
以方便人和计算机设备以及人与人之间的交流是利用计算机为工具,对人类特有的书面形式和口头形式的自然语言的信息进行各种类型处理和加工的技术。
-
自然语言:
自然语言指人类社会发展过程中自然产生是约定俗成的人类语言
语言是人类交际的工具,是人类思维的载体
-
自然语言处理的主要任务
-
命名实体识别:识别文本中的特定实体(如人名、地名等)。
-
关系抽取:从文本中提取实体之间的关系。
-
情感分析:判断文本的情感倾向(正向或负向)。
-
机器翻译:将一种语言自动翻译成另一种语言。
-
问答系统:根据用户提出的问题提供答案。
-
信息抽取:从文本中提取结构化信息,如实体识别、关系抽取、事件抽取等。
-
文本分类:将文本归类到预定义的类别中,如垃圾邮件过滤、新闻分类等。
-
机器阅读理解:根据给定的文章回答相关问题。
-
智能对话:通过多轮对话与用户交互,完成任务或提供信息。
-
自动文摘:从长文本中提取主要内容生成摘要。
-
-
NLP的发展历史与学派
- 理性主义:强调人类生成语句的能力是天生的,代表人物如乔姆斯基。
- 经验主义:认为语言能力来源于学习,代表人物如斯金纳。
- 深度学习法:近年来主流的方法,通过神经网络模型自动提取特征,简化问题解决过程。
-
NLP的范式变迁
-
第一范式:概率统计方法 | 非神经网络时代的完全监督学习--特征工程
- 特点:人工定义特征,使用概率模型进行学习。
- 模型:概率模型,如 贝叶斯,隐马尔可夫,最大熵,条件随机场CRF等。
- 优点:可解释性强。
- 缺点:特征工程复杂,解决问题方法复杂。
-
第二范式:基于神经网络的完全监督学习 | 基于神经网络的完全监督学习--架构工程
- 特点:模型自动提取特征,端到端解决方案。
- 模型:CNN、RNN、Transformer、GNN等。
- 优点:简化问题解决方法。
- 缺点:需要大量标注数据,可解释性差。
-
第三范式:预训练,精调范式 | 目标工程 (Pre-train, Fine-tune)
- 特点:通过自监督学习从大规模数据中获得预训练模型,然后微调以适配下游任务。
- 模型:BERT、GPT等。
- 优点:利用大规模无标注数据,提高下游任务性能。
- 缺点:需要领域数据进行微调。
-
第四范式:预训练,提示,预测范式 | Prompt挖掘工程 (Pre-train, Prompt, Predict)
- 特点:通过改变任务形式,利用预训练模型完成任务,不需要对模型进行大量改动。
- 方法:使用prompt技术,将任务转换为完形填空问题。
- 优点:适用于小样本学习或零样本学习。
- 缺点:需要设计合适的prompt。
-
第五范式:大模型(ChatGPT等)
- 特点:通用预训练语言模型,将下游任务统一为生成式任务,通过提示学习等方式完成任务。
- 优点:强大的语言生成和理解能力,适用于多种任务。
- 缺点:模型庞大,计算资源需求高.
-
-
机器学习基本概念
-
监督学习:
- 定义:利用带标签的数据训练模型,预测新数据的标签。
- 常见算法:决策树、SVM、神经网络、随机森林。
-
无监督学习:
- 定义:处理无标签数据,发现数据内在结构。
- 常见算法:聚类(K-means)、降维(PCA)、自编码器。
-
强化学习:
- 定义:通过与环境互动,学习最优策略以最大化累积奖励。
- 常见算法:Q-learning、策略梯度、深度强化学习。
-
常用概念:
- 过拟合:模型在训练数据上表现好,但在测试数据上表现差。
- 欠拟合:模型未能充分学习训练数据的模式。
- 交叉验证:评估模型泛化能力的技术,常见有K折交叉验证。
-
深度学习:
- 基础:神经网络,尤其是多层感知机(MLP)。
- 关键技术:卷积神经网络(CNN)、循环神经网络(RNN)、Transformer。
- 优点:强大的表征学习能力,适用于大规模数据。
-
-
重要模型与技术
-
BERT (Bidirectional Encoder Representations from Transformers) :
- 特点:双向训练,预训练-微调范式。
- 应用:广泛用于各种NLP任务,如文本分类、NER、问答。
-
GPT (Generative Pre-trained Transformer) :
- 特点:单向训练,生成式预训练。
- 应用:文本生成、对话系统、代码生成。
-
Transformer:
- 特点:基于自注意力机制,处理长距离依赖。
- 应用:机器翻译、文本生成、时间序列分析。
-
大语言模型 (如 GPT-4, ChatGPT) :
- 特点:参数量巨大,强大的上下文理解能力。
- 应用:通用问答、内容生成、代码辅助。
-
-
机器学习模型评估
- 准确率(Accuracy) :分类正确的样本占总样本的比例。
- 精确率(Precision) :预测为正类的样本中实际为正类的比例。
- 召回率(Recall) :实际为正类的样本中被正确预测为正类的比例。
- F1分数(F1 Score) :精确率和召回率的调和平均数。
-
机器学习中的特征工程
- 特征选择:从原始数据中选择最相关的特征。
- 特征提取:通过变换或组合原始特征生成新的特征。
- 特征缩放:将特征值缩放到相同的范围,如归一化或标准化。
-
深度学习
- 神经网络:由多个神经元层组成的模型,能够自动提取特征并进行复杂的非线性映射。
- 卷积神经网络(CNN) :主要用于图像处理,通过卷积层提取局部特征。
- 循环神经网络(RNN) :主要用于序列数据处理,能够处理时间序列或文本数据。
- Transformer:基于自注意力机制的模型,广泛应用于自然语言处理任务。
-
预训练与微调
- 预训练:在大规模无标注数据上训练模型,学习通用的语言表示。
- 微调:在特定任务的有标注数据上对预训练模型进行进一步训练,使其适应特定任务。
三章
神经网络
卷积网络
循环网络
图卷积网络
的基本概念
全连接前馈神经网络DNN
深度学习:机器学习的一个分支
人工神经网络:模仿人脑网络构建不同的深度学习模型
人脑结构:可视作为1000多亿神经元组成的神经网络

-
人工神经元模型:
- 生物神经元:具有兴奋和抑制两种状态。
- 人工神经元:输入通过权重和偏置加权求和后,经过激活函数输出。
- 激活函数:常用的有Sigmoid、Tanh、ReLU、LeakyReLU、ELU等,用于引入非线性。
-
人工神经网络:由多个神经元组成的具有并行分布结构的神经网络模型
-
前馈神经网络结构:
- 输入层、隐藏层和输出层。
- 信息传播:输入通过各层依次传递,无反馈连接。
- 模型表示:$y = f(x, \theta) = \sigma(W^{L}\ldots \sigma(W{2}\sigma(Wx + b^{1}) + b^{2} ) \ldots + b^{L})$
-
训练方法:
- 梯度下降法:通过迭代调整参数使损失函数最小化。
- 反向传播算法(BP) :用于计算各层参数的梯度,通过链式法则反向传播误差。
- 梯度消失问题:深层网络中梯度可能在传播过程中消失,影响训练效果。
-
激活函数的性质
- 连续并可导(允许少数点上不可导)的非线性函数
- 可导的激活函数可以直接利用数值优化的方法来学习网络参数
-
激活函数及其导函数要尽可能的简单
- 有利于提高网络计算效率
-
激活函数的导函数的值域要在一个合适的区间内
- 不能太大也不能太小,否则会影响训练的效率和稳定性
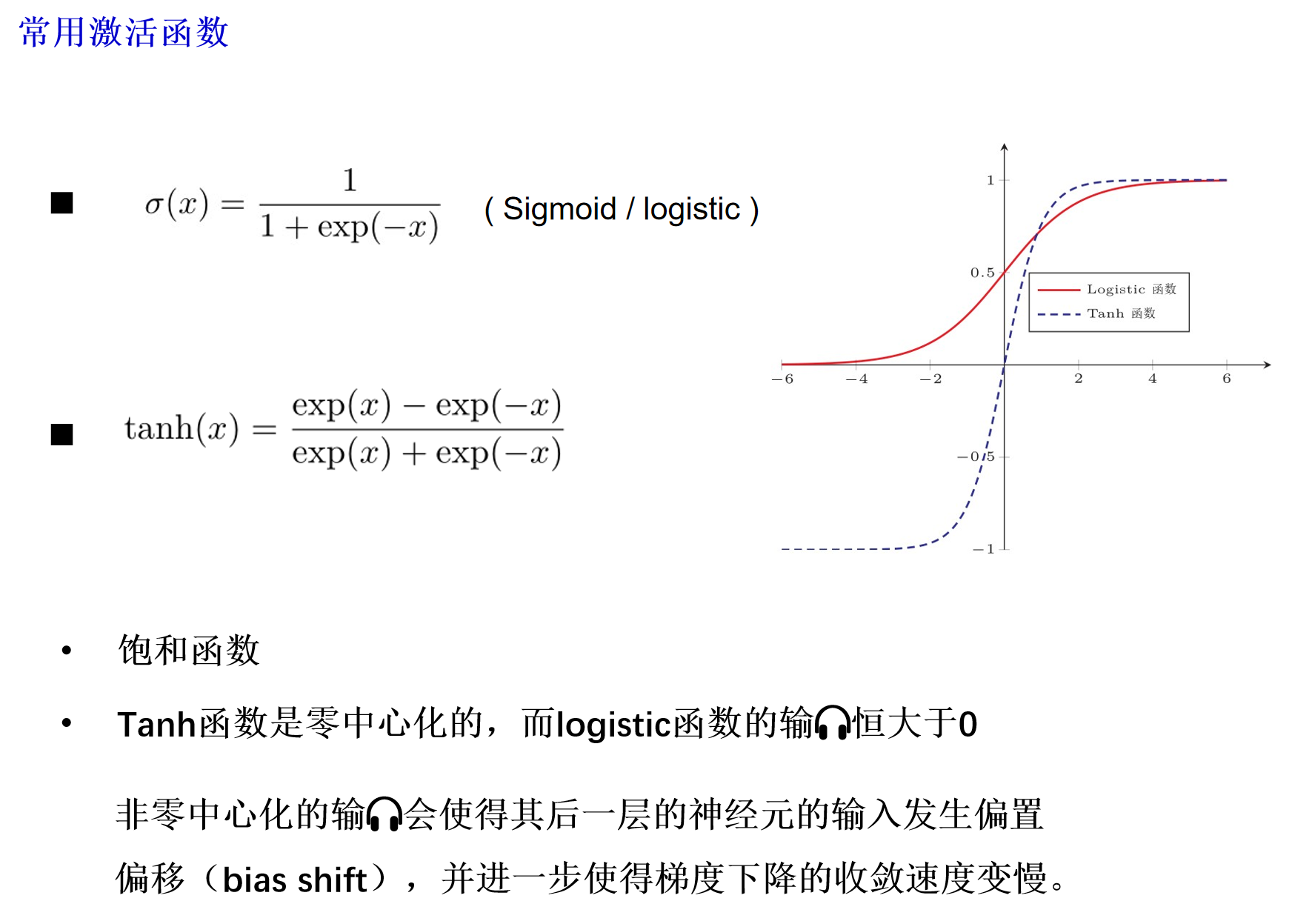


relu是非饱和式的激活函数
激活函数的作用:
- 计算上更加高效
- 生物学合理性
- 单侧抑制、宽兴奋边界
- 在一定程度上缓解梯度消失问题
- 增加网络的表达能力,给网络增加非线性因素
-
前馈神经网络的训练过程可以分为以下三步:
- 先前馈计算每一层的状态和激活值,直到最后一层
- 反向传播计算每一层的误差
- 计算每一层参数的偏导数,并更新参数
-
解决梯度消失问题方法
- 选择合适的激活函数
- 用复杂的门结构代替激活函数(门的参数分割也可以解决权重冲突)
- 残差结构
-
解决过拟合问题方法
- 选择合适的正则方法
- drop out?
模型设计题参考流程
卷积神经网络 CNN
-
概述:
- CNN 通过卷积层和池化层来减少参数数量,适合处理图像数据。
- 卷积层通过卷积核在输入数据上滑动,提取局部特征。
- 池化层通过降采样减少特征图的尺寸,降低计算量。
-
结构:
- 卷积网络是由卷积层、子采样层、全连接层交叉堆叠而成
- 卷积层: 使用卷积核进行卷积操作,提取特征。
- 池化层: 通过最大池化或平均池化减少特征图尺寸。
- 全连接层: 将池化层输出展平后输入全连接层进行分类。
-
优点:
- 局部连接: 只与局部区域连接,减少参数数量。
- 权重共享: 卷积核在所有位置共享权重。
- 平移不变性: 对平移具有一定的鲁棒性。
-
结构特性:
- 局部连接
- 权重共享
- 空间或时间上的次采样
- 这些特性使得卷积神经网络具有一定程度上的平移、缩放和扭曲不变性
图卷积神经网络
-
基于谱域的图卷积神经网络
- 在谱域中定义卷积,卷积是通过图傅立叶变换和卷积定理定义的
- 挑战:卷积滤波器在谱域中定义(而不是在顶点域中)
-
基于空间的图卷积神经网络
- 定义顶点域中的卷积,卷积定义为目标顶点的邻域中所有顶点的加权平均函数
- 挑战:不同节点的邻域大小差异很大
输入:原始网络
输出:Node representation set;每个表示带有原图的特征信息
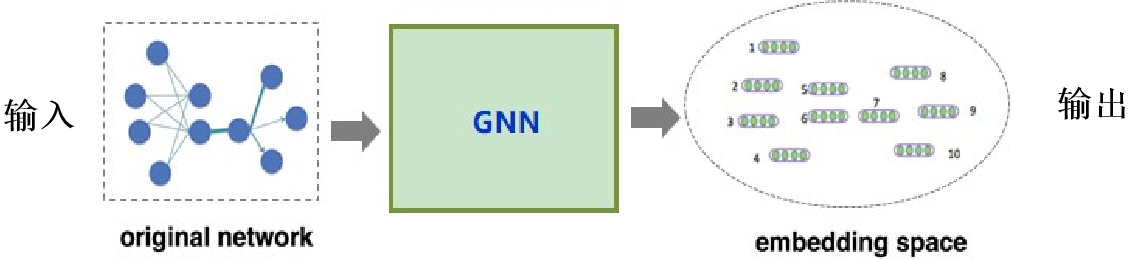
图中的池化:
-
SumPooling
顾名思义,将邻居Embedding的每一维求和:
-
AvgPooling
将邻居Embedding的每一维求均值:
-
MaxPooling
将邻居Embedding的按每一维取最大值:
........
应用于节点分类、图分类、链接预测等。
循环神经网络
- DNN、CNN 输入、输出定长;处理输入、输出变长问题效率不高。
而自然语言处理中的语句通常其长度不固定。 - 单一 DNN、CNN 无法处理时序相关序列问题
将处理问题在时序上分解为一系列相同的“单元”,单元的神经网络可以在时序上展开,且能将上一时刻的结果传递给下一时刻,整个网络按时间轴展开。即可变长。
-
概述:
- RNN 适合处理序列数据,通过循环结构保持之前的信息。
- 适用于自然语言处理中的序列生成、机器翻译等任务。
-
结构:
- RNN 单元: 包含隐藏层和输出层,隐藏层与上一时刻的隐藏层相连。
- 展开: RNN 可以在时间轴上展开,形成一个深层网络。
-
问题:
- 梯度消失/爆炸: 长序列训练时,梯度可能消失或爆炸。
- 长期依赖: 难以捕捉长距离依赖关系。
-
变体:
- LSTM: 通过门控机制解决梯度消失问题。
- GRU: 简化 LSTM,同样适用于序列数据处理。
训练方法 | 参数学习方法
-
有监督训练
-
梯度下降法学习参数
-
BPTT
- 反向传播算法的一种扩展
- 随时间反向传播,Back-Propagation Through Time,BPTT
- 求解每个时间步的梯度是该算法的核心操作
-
会出现和深度前馈神经网络类似的梯度消失问题。
-
在训练循环神经网络时,更经常出现的是梯度消失问题,训练较难
长期依赖问题
距当前节点越远的节点对当前节点处理影响越小,无法建模长时间的依赖
长短时记忆神经网络:LSTM(long short-term memory):
- 建立一个机制保留前面远处结点信息在长距离传播中不会被丢失
- 分割参数矩阵解决权重共享
- 门控结构解决梯度消失问题
-
门控结构的关键在于它们能够有选择地让信息通过,这主要是通过不同的“门”来实现的。例如,LSTM 包含输入门、遗忘门和输出门,这些门控机制控制着信息的存储和遗忘,从而维持长期依赖关系。
具体来说,LSTM 的细胞状态提供了一条“高速公路”,允许梯度在反向传播时直接传递,而不会被过多的非线性变换(如 sigmoid 或 tanh 函数)所削弱。这些门的激活函数在某些区域(如 sigmoid 在 0.5 附近)有较大的导数,这有助于梯度在反向传播时保持相对稳定,避免梯度消失。
GRU门控网络:
LSTM 简化: 输入门和遗忘门合并为更新门(更新门决定隐状态保留放弃部分)
LSTM:
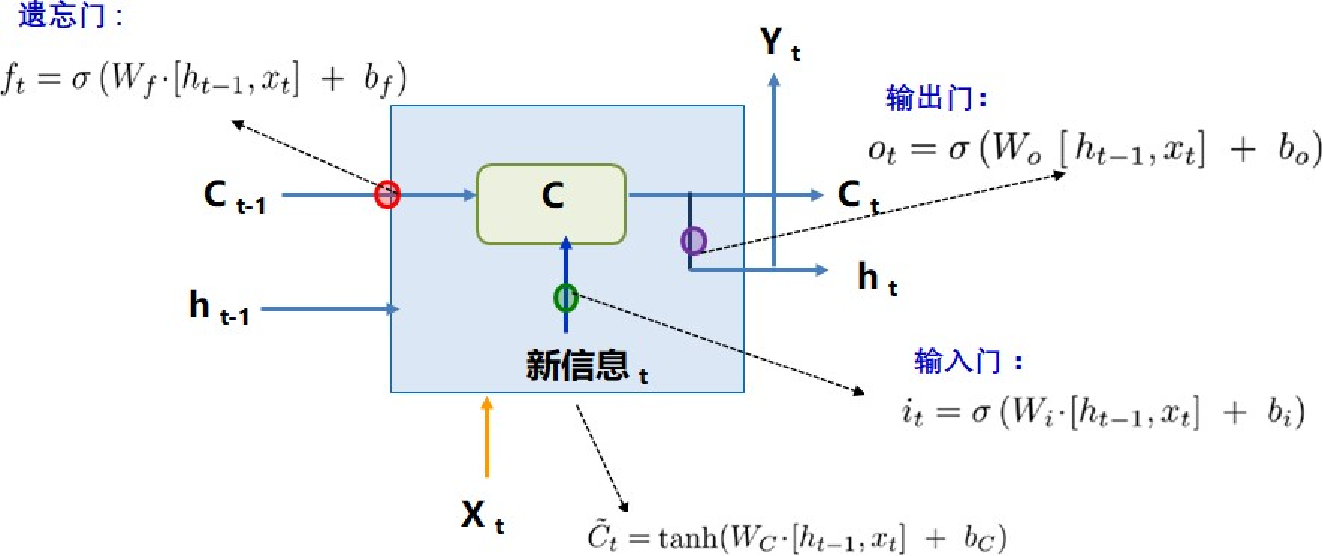
GRU简化:(重置门、更新门)
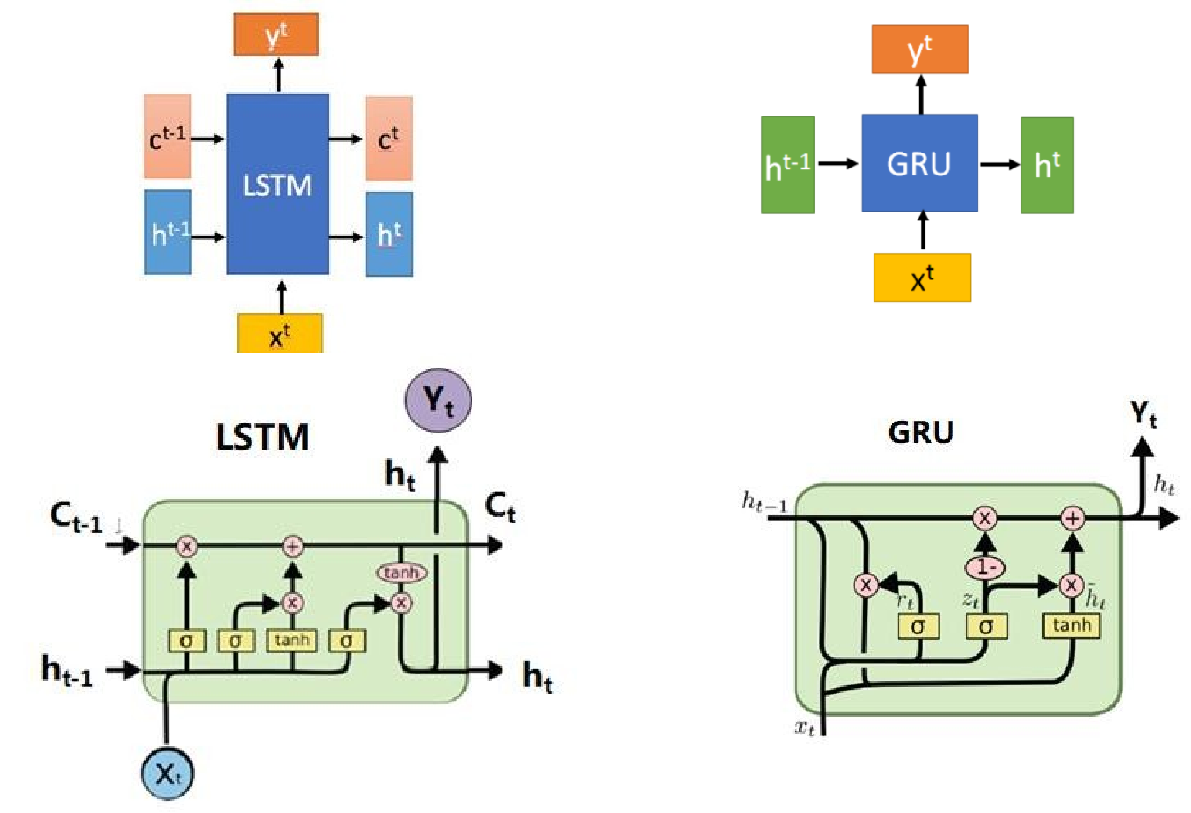
RNN/LSTM 建模的序列问题
- 图像分类
- 图文标注
- 情感分类
- 机器翻译
- 序列标注
四章 语言模型+词向量
统计语言模型特点
神经网络语言模型特点
词向量及特点
典型词向量训练算法
1. 统计语言模型特点
规则法:判断是否合乎语法、语义(语言学定性分析)
统计法: 通过可能性(概率)的大小来判断(数学定量计算)
-
基本概念:
- 语言模型用于计算句子概率 $p(S)$,判断句子的合理性。
- 通过概率大小判断句子的合理性,替代传统的规则法(语法、语义分析)。
- 语言模型的基本思想是用句子 $S = w_1, w_2, \dots, w_n$ 的概率 $p(S)$ 来刻画句子的合理性。
-
参数估计:
- 使用最大似然估计(MLE)方法估计语言模型参数。
- 通过语料统计词的条件概率 $p(w_i | w_1, \dots, w_{i-1})$。
- 数据稀疏问题:由于语料有限,某些词组合可能未出现,导致零概率问题。
-
数据平滑:
- 数据平滑的基本思想是调整最大似然估计的概率值,消除零概率问题。
- 常见平滑方法:加1法(Additive Smoothing)、减值法(Discounting)、Good-Turing、Back-off、绝对减值、线性减值等。
-
模型评价:
- 通过困惑度(Perplexity)评价语言模型性能,困惑度越低,模型越好。
- 困惑度定义为 $PP_p(T) = 2^{H_p(T)}$,其中 $H_p(T)$是模型对测试语料的交叉熵。
-
应用:
- 计算句子概率,决定哪个词序列更合理。
- 预测下一个词,用于语音识别、机器翻译等任务。
重点:什么是语言模型?语言模型存在的问题?
-
什么是语言模型?
- 语言模型:用数学的方法描述语言规律。用句子 $S = w_1, w_2, \dots, w_n$ 的概率 $p(S)$ 刻画句子的合理性(统计自然语言处理的基础模型)。语言模型记载的是序列信息。
-
语言模型存在的问题:
- 由于参数数量过多问题需要进行词 $i$ 的历史简化(n-gram)。
- 由于数据匮乏引起的0概率问题需要进行数据平滑。
2. 神经网络语言模型特点
-
基本概念:
- 神经网络语言模型(NNLM)通过神经网络学习语言模型参数 p(wi∣w1,…,wi−1)p(wi∣w1,…,wi−1)。
- 与统计语言模型相比,神经网络语言模型不需要简化历史为n-gram,且不需要数据平滑。
-
DNN语言模型(NNLM) :
- 使用前馈神经网络(DNN)学习语言模型参数。
- 输入为n-1个词的词向量,输出为下一个词的概率分布。
- 通过最大化语料的似然函数来训练模型。
-
RNN语言模型(RNNLM) :
- 使用循环神经网络(RNN)学习语言模型参数。
- RNN能够保留每个词的全部历史信息,不需要简化为n-gram。
- 通过BPTT(Backpropagation Through Time)算法进行训练。
-
优点:
- 不需要数据平滑,泛化能力强。
- 能够捕捉更长的上下文信息,模型效果更好。
重点:什么是神经网络语言模型?有哪几种?每种的特点是什么?哪种更好,优点是 什么?
-
什么是神经网络语言模型?
- 神经网络语言模型:用神经网络来学习语言模型的参数。
-
神经网络语言模型分类及特点:
-
NNLM(Neural Network Language Model)
- 特点:用DNN(深度神经网络)学习语言模型,使用BP(反向传播)算法进行参数训练。
-
RNNLM(Recurrent Neural Network Language Model)
- 特点:用RNN(循环神经网络)学习语言模型,使用BPTT(随时间反向传播)算法进行参数训练。
- RNN语言模型还有一些变形,如正向、反向、双向语言模型等。
-
-
RNNLM模型更好
- 原因:RNN适合处理序列数据,在NLP任务中一般使用RNNLM。随着模型逐个读入语料中的词,隐藏层不断更新,通过这种迭代推进方式,每个隐藏层实际上包含了此前所有上文的信息。相比NNLM只能采用上文n元短语作为近似,RNNLM包含了更丰富的上文信息,也有潜力达到更好的效果。
-
RNNLM优点
- RNNLM模型可以保留每个词的全部历史信息,不需简化为n-gram。
- 当语言模型训练好后,模型网络参数固定,这时给任意的 $w_{i-1}$,$p(w_i)$ 都不会为0。
- 在神经网络中,一般使用RNN语言模型。
重点:神经网络语言模型输入、输出、要预测哪些参数、参数学习方法要掌握
-
神经网络语言模型的输入、输出、参数预测及学习方法:
-
NNLM
- 输入:$w_{i-1}$
- 输出:$p(w_i)$
- 参数学习方法:BP(反向传播)
- 在训练语言模型的同时也训练了词向量——预测的参数包括各模型参数和词向量。
-
RNNLM
- 输入:$w_{i-1}$
- 输出:$p(w_i)$
- 参数学习方法:BPTT(随时间反向传播)
- 在训练语言模型的同时也训练了词向量——预测的参数包括各模型参数和词向量。
-
3. 词向量及特点
-
词表示概述:
- 词向量是将词表示为低维稠密向量的方法,解决了传统one-hot表示的高维稀疏问题。
- 分布式假设:在相同上下文中出现的词倾向于具有相同的含义。
-
词向量特点:
- 语义相似性:语义相似的词在向量空间中距离更近。
- 线性关系:词向量之间的线性关系可以反映词之间的语义关系(如“国王-女王”与“男人-女人”)。
- 降维:将高维稀疏的one-hot表示降维为低维稠密向量,消除词汇鸿沟。
-
应用:
- 同义词检测、单词类比、语义相似度计算等。
- 作为静态特征输入到其他NLP任务中,如文本分类、命名实体识别等。
- 作为动态初值输入到神经网络中,提升模型效果。
4. 重点 典型词向量训练算法
-
NNLM模型词向量:
- NNLM(Neural Network Language Model)在训练语言模型的同时训练词向量。
- 输入为n-1个词的词向量,输出为下一个词的概率分布。
- 通过最大化语料的似然函数来训练词向量。
-
RNNLM模型词向量:
- RNNLM(Recurrent Neural Network Language Model)通过RNN学习词向量。
- RNN能够保留每个词的全部历史信息,不需要简化为n-gram。
- 通过BPTT算法进行训练。
-
C&W模型词向量:
- C&W模型(Collobert & Weston模型)通过直接对n元短语打分来训练词向量。
- 目标函数是求目标词与其上下文的联合打分,而不是预测下一个词。
- 通过pairwise方式对文本片段进行优化,训练词向量。
-
CBOW模型:
- CBOW(Continuous Bag-of-Words)模型通过上下文词预测目标词。
- 输入为上下文词向量的平均值,输出为目标词的概率分布。
- 通过最大化目标词的似然函数来训练词向量。
-
Skip-gram模型:
- Skip-gram模型通过目标词预测上下文词。
- 输入为目标词的词向量,输出为上下文词的概率分布。
- 通过最大化上下文词的似然函数来训练词向量。
-
Word2vec:
- Word2vec是Google开源的词向量工具,包含CBOW和Skip-gram两种模型。
- 通过高效的训练方法生成词向量,广泛应用于机器翻译、相似词查找等任务。
五章 nlp中的注意力机制
注意力机制基本概念
注意力结构
注意力构成
Transformer
注意力机制概述
-
注意力机制的定义:注意力机制是一种加权求和机制/模块。其基本思想是,对于输入信息中的不同部分,根据其对当前任务的重要性赋予不同的权重,然后进行加权求和,从而聚焦于对任务最有帮助的信息。例如,在处理一个序列时,注意力机制可以为序列中的每个元素计算一个权重,然后根据这些权重对元素进行加权求和,得到一个综合表示.
-
注意力机制的作用:
- 等权求和 → 加权求和:传统的处理方式往往对输入信息中的所有部分赋予相同的权重,即等权求和。而注意力机制通过计算权重,实现了加权求和,使得模型能够更加关注对任务更重要的信息,从而提高处理效果.
- 任意节点间建立关联关系:在图结构等场景中,注意力机制可以为任意两个节点之间建立关联关系,而不仅仅局限于相邻节点。这种灵活性使得模型能够更好地捕捉节点间的复杂关系,提升对图结构的理解和处理能力.
传统注意力机制
-
注意力模块结构:
-
输入与输出:注意力模块的输入通常包括查询(Q)和键(K)集合,输出为加权求和后的值(Att-V)。查询(Q)可以是当前任务的目标信息,如目标语言的单词;键(K)集合则是需要关注的信息集合,如源语言句子中的单词表示.
-
如何求K对Q的权重:
- 计算注意力打分函数:通过一个打分函数S=f(Q,Ki)来计算查询Q与每个键Ki之间的匹配程度,得到一个分数.这个打分函数可以是点积、余弦相似度等.
- 使用softmax函数计算权重:将得到的分数经过softmax函数处理,得到每个键Ki对查询Q的权重.softmax函数的作用是将分数转换为概率分布,使得权重之和为1,从而实现对不同键的加权求和.
-
如何计算最后值:
- 普通模式:Att-V = a1×K1 + a2×K2 + ... + an×Kn,即根据计算得到的权重对键集合中的元素进行加权求和,得到最终的输出值.
- 键值对模式:Att-V = a1×V1 + a2×V2 + ... + an×Vn,在这种模式下,每个键Ki对应一个值Vi,最终输出是根据权重对值集合进行加权求和.
-
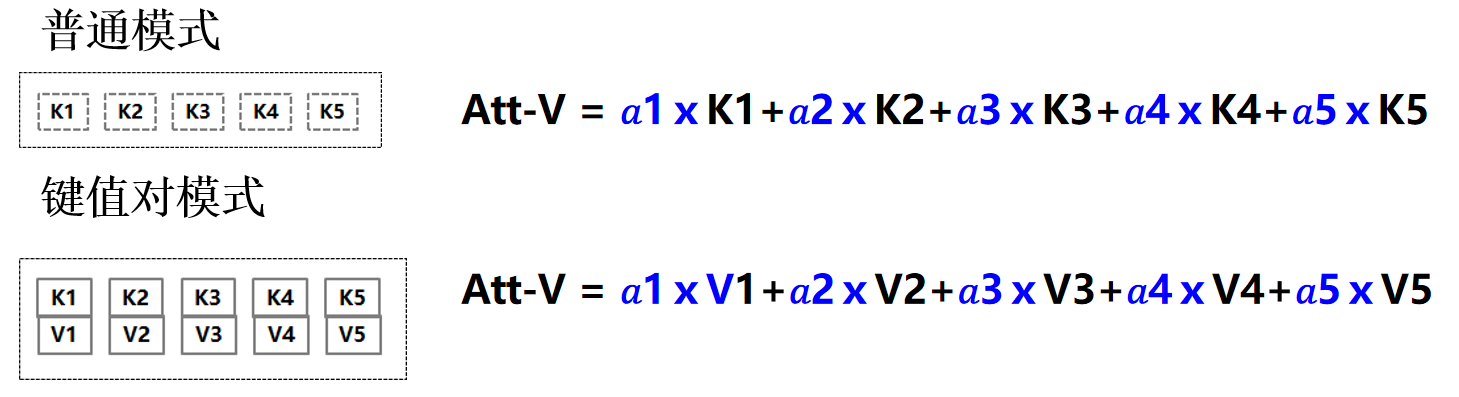
-
注意力模块训练与评价:
- 训练:将注意力模块嵌入到整体模型中进行训练,不需要额外的训练数据.模块中的参数可以通过模型的训练过程自动学习到合适的权重分配方式.
- 评价:通过将注意力模块应用于不同的任务中,检验其对任务性能的提升效果.如果任务指标(如准确率、F1分数等)有所提高,则说明注意力模块发挥了积极作用.
注意力模块的应用:
- 机器翻译:在机器翻译任务中,注意力机制可以帮助模型更好地对齐源语言和目标语言之间的信息,使得翻译结果更加准确和流畅.例如,在翻译“杰瑞”时,模型会根据注意力权重确定源语言句子中哪些单词对“杰瑞”的影响更大,从而生成更准确的翻译.
- 图卷积网络:在图卷积网络中,注意力机制可以用于节点的聚集过程,从等权聚集转变为加权聚集,使得模型能够更加关注对当前节点更重要的邻居节点,提高图结构的处理能力.
- 异质图卷积:在异质图中,存在不同类型的节点和边,注意力机制可以实现针对不同类别和类别中节点的双重注意力机制聚集,分别计算类型级和结点级的注意力权重,从而更好地处理异构图数据.
- 图片标题生成:在图片标题生成任务中,注意力机制可以帮助模型关注图片中对生成标题更重要的区域或对象,生成与图片内容更匹配的标题.
注意力机制的类型:
-
软注意力(Soft Attention) :在求注意力分配概率分布时,对于输入信息中的每个部分都给出一个概率,形成一个概率分布.这种方式可以同时考虑所有部分的信息,但可能导致模型对某些重要信息的关注度不够集中.
就是:考虑所有的输入
-
硬注意力(Hard Attention) :直接从输入信息中选择某个特定的部分,然后将其与目标信息对齐,而其他部分的对齐概率为0.这种方式可以更加集中地关注重要信息,但存在一定的随机性和不稳定性.
就是:将最大的可能性的权重设置为1,其他为0
-
全局注意力(Global Attention) :在解码端进行注意力计算时,会考虑编码器端序列中所有的信息,从而实现对整个输入序列的全局关注.全局注意力模型通常属于软注意力模型的一种.
就是:Decode端Attention计算时要考虑输Ecoder端序列中所有的词(所有时间步的隐层输出都考虑)
-
局部注意力(Local Attention) :本质上是软注意力和硬注意力的混合或折衷.通常会先预估一个对齐位置,然后在该位置左右一定范围的窗口内进行类似于软注意力的概率分布计算,从而在关注局部信息的同时,也保留了一定的全局视野.
就是:decoder运行时关注的encoder时间步的隐层具有一个窗口大小,根据decoder时间步的进行在encoder的隐层输出上滑动计算上下文向量(context vector)。
注意力机制优势
- 让任务处理系统找到与当前任务相关显著的输入信息,并按重要性进行处理,从而提高输出的质量。
- 不需要监督信号,可推理多种不同模态数据之间的难以解释、隐蔽性强、复杂映射关系,对于先验认知少的问题,极为有效。
- 解决长距离依赖问题,提升任务性能。
注意力编码机制
-
编码的定义:编码是将神经网络中分散的信息聚集为某种隐层表示的过程,形成信息量更丰富的表示,以便后续的处理和使用.编码的对象可以是词、句子等不同的处理单元.
-
注意力机制作为编码机制的类型:
-
编码为单一向量:
- 句编码:将整个句子编码为一个句向量,这个向量能够捕捉句子的整体语义信息.例如,对于句子“这个餐厅的服务真不错”,通过注意力机制可以将句子中的每个词进行加权求和,得到一个能够代表整个句子语义的向量.
- 词编码:将序列中的词进行编码,使得编码后的词向量带有句子中各词的权重信息,从而能够更好地表示词在句子中的上下文关系.例如,在句子“The animal didn’t cross the street because it was too tired”中,编码“it”时,会根据上下文信息判断“it”指代的是“animal”还是“street”,并赋予相应的权重.
-
编码为一个序列:
- 不同序列融合编码:将两个不同的序列编码成一个融合的表示序列,常用于匹配任务和阅读理解任务中的融合层表示.例如,在处理两个句子的匹配问题时,可以将两个句子分别编码为序列,然后通过注意力机制将它们融合成一个表示两个句子关系的序列.
- 相同序列自注意力编码:利用多头自注意力编码对一个句子进行编码,可以起到类似句法分析器的作用,捕捉句子内部的结构和依赖关系.例如,在Transformer模型的编码端,就是通过自注意力机制对输入序列进行编码,生成能够表示序列内部复杂关系的编码序列.
-
自注意力机制:
定义:
自注意力机制实际上是Attention(X, X, X)的形式,其中X为输入序列.其含义是在序列内部进行Attention计算,寻找序列内部词与词之间的关联关系,从而更好地理解序列的结构
可以并行计算
RNN+attention 模型设计
- 加入attention后,在长句子上的翻译表现提升至正常水平
- 代价是m*t的复杂度消耗(m是encoder时间步,t是decoder时间步)
- encoder中各个时间步的隐层输出为key,decoder中上一次输出s为query,计算一次c,s,c,xi决定这一时间步的输出
- 对RNN可能存在注意力偏执问题,过度关注某些时间步或某些特征
https://www.youtube.com/watch?v=XhWdv7ghmQQ
问题
重点:什么是 Attention 机制?有几种?什么应用?优势?
-
什么是 Attention 机制?
-
定义:注意力机制是一个加权求和模块,对于输入 $Q$ 和 $K$($K$ 是一个集合),需要回答的问题是:对于 $Q$ 而言,每一个 $K_i$ 有多重要,重要性由 $V$ 描述。
-
Attention 机制结构:
- 输入:$Q$,$K$(集合)
- 输出:$\text{Att-V}$
-
Attention 机制的三个阶段:
- 计算 $f(Q, K_i)$(注意力打分函数)
- $a_i = \text{softmax}(f(Q, K_i))$
- 加权求和:输出 $\text{Att-V}= a_{i} * K_{i}$(普通模式)或 $\text{Att-V} = a_i * V_i$(键值对模式)
- 普通模式:$\text{key} = \text{value}$,softmax 函数输出的 $a_i$ 直接与 $K_i$ 相乘得到输出 $\text{Att-V}$
- 键值对模式:$\text{key}\neq \text{value}$,softmax 函数输出的 $a_i$ 与 $K_i$ 对应的 $V_i$ 相乘得到输出 $\text{Att-V}$
-
-
注意力机制种类
- 软注意力(Soft Attention) :在求注意力分配概率分布的时候,对于输入句子 X 中任意一个单词都给出一个概率,是一个概率分布。
- 硬注意力(Hard Attention) :直接从输入句子里面找到某个特定的单词,然后把目标句子单词和这个单词对齐,而其它输入句子中的单词硬性地认为对齐概率为 0。
- 全局注意力(Global Attention) :Decode 端 Attention 计算时要考虑 Encoder 端序列中所有的词。Global Attention Model 是 Soft Attention Model。
- 局部注意力(Local Attention) :Local Attention Model 本质上是 Soft AM 和 Hard AM 的一个混合或折衷。一般首先预估一个对齐位置 $P_t$,然后在 $P_t$ 左右大小为 $D$ 的窗口范围来取类似于 Soft AM 的概率分布。
-
应用
- 网络中有“求和”的地方都可以用,如图卷积、机器翻译等。
-
重点:优势
- 让任务处理系统找到与当前任务相关显著的输入信息,并按照重要性进行处理。
- 不需要监督信号,可推导多种不同模态数据之间的难以解释、隐蔽性强、复杂映射关系,对于先验知识少的问题极为有效。
- 可以解决长距离依赖问题,提升任务性能。
-
存在问题
- 对 RNN 有注意力偏置问题。
-
解决方法
- Coverage 机制:可以缓解注意力偏置问题。为了使得模型不过多地关注已经关注过的区域,所以将 coverage 向量作为下一步的注意力构成部分,这样下一步生成的注意力分布就会有意识地减少已经关注过的区域的概率。
重点:注意力编码机制
-
注意力编码机制
-
对不同序列的不同编码方式:
- 单一向量编码:将输入序列编码成单一向量表示(句表示、篇章表示、词的上下文表示)。
- 不同序列间编码:将 2 个序列编码成二者融合的向量表示(匹配任务、阅读理解的混合层表示)。
- 同一序列自编码:(相同序列自注意力编码)使用多头注意力编码对一个句子编码,起到句法分析器的作用。
-
不同编码方式的计算方式:
- 单一向量编码:句子各元素 $K$ 序列与 $Q$ 的关联关系。
- 不同序列间编码:对 $K$ 序列和 $Q$ 序列编码。
- 同一序列自编码:采用多头注意力机制,每头的 $Q = K = V$ 且参数不共享,最后把各头的结果拼接。
-
六章重点 NLP基础技术
事件抽取、文本匹配基本概念及建模方法;序列标注:维特比算法,RNN+CRF 模型基本概念;序列生成:基本概念,解码方法,词元化算法,评价指标,存在问题,Transformer(模型及训练)指针网络基本概念
事件抽取
文本匹配基本概念及建模方法
序列标注:维特比算法
RNN+CRF 模型基本概念
序列生成:基本概念
解码方法
词元化算法
评价指标
存在问题
Transformer(模型及训练)
指针网络基本概念
事件抽取任务
任务涉及模型:标注+分类
-
触发词检测:(标注+分类)
- 实体标注 lstm+crf
- 文本分类 embedding+conv/rnn/...+dnn
- 触发词:出生
触发词类别:life / Be-Born
-
触发词类别 life / Be-Born 类模板:
Person: Time: Place:
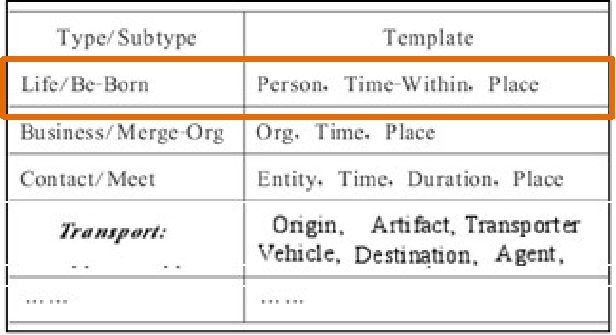
-
按模板抽取角色:(标注)
事件:
Trigger: 出生
Type: Life, Subtype: Be-Born
Person: name Time: 1893年 Place: 湖南湘潭 -
任务涉及模型:标注+分类
文本分类
-
分类任务概述:利用计算机对大量文档按分类标准自动归类,输入为文本序列,输出为类别标签.
-
分类方法:
- 概率统计时代:特征工程+算法(如Naive Bayes、SVM、LR、KNN等).
- 深度学习时代:自动获取特征(表示学习),端到端分类.
-
神经网络分类方法:
- 基于词袋的文本分类
- 基于卷积神经网络文本分类
- 基于循环神经网络文本分类
- 基于attention机制文本分类
- 基于图卷积神经网络文本分类
-
序列结构文本分类(关系抽取) :
- 神经词袋模型
- FastText
- 卷积神经网络模型(CNN)
- 循环神经网络(RNN)
- 循环+卷积神经网络模型
- LSTM/CNN-GRU(篇章级-混合模型)
- HAN(篇章级- Attention 模型)
-
图结构文本分类:
- 图卷积神经网络文本分类步骤:Graph 构建、文本Graph节点特征表示、图卷积算法.
文本匹配
-
文本匹配任务概述:广义的将研究两段文本间关系的问题定义为“文本匹配”问题,匹配含义根据任务的不同有不同的定义。很多自然语言处理的任务都会涉及文本匹配问题
-
复述识别(paraphrase identification)(释义识别)
两个句子“感冒了是否要吃药”和“感冒了要吃什么药”问:两个句 子是否表达同样的意思?
-
文本蕴含识别(Textual Entailment)
两个句子“我正在上海旅游”和“我正在八达岭长城”
问:这两句话是什么关系? -
一般可建模为 “分类” 和 “排位” 问题
-
-
与文本匹配相关的NLP任务:问答(QA)、对话(Conversation)、信息检索(IR)等.
复述识别(paraphrase identification)
又称释义识别,是判断两段文本是不是表达了同样的语义,这一类场景一般
建模成分类问题。
如:两个句子“感冒了是否要吃药”和“感冒了要吃什么药” 问:两个句子是否表达同样的意思?
解决方法:该问题的句子匹配是计算二个句子相似度,可建模为二分类问题
文本蕴含识别(Textual Entailment)
给定一个前提文本(text),根据这个前提去推断假说文本(hypothesis)与 文本的关系,关系有:
蕴含关系(entailment),矛盾关系(contradiction)。
这一类场景一般建模成多分类问题。
如:两个句子“我正在上海旅游”和“我正在八达岭长城” 问:这两句话是什么关系?
解决方法:该问题的句子匹配是计算二个句子之间的关系,可建模为多分类问题
其他任务——看问答系统
问答(QA)
根据Question在段落或文档中查找Answer,这类场景常常会被建模成分类问题;还有一类是根据Question从若干候选中找出正确答案,这类场景常常会被建模成排位( ranking )问题。
对话(Conversation)
与QA 类似,但是比QA更复杂,由于引入了历史轮对话,需要考虑在历史轮的限制下回复是否合理。一般建模为分类或排位问题。
信息检索(IR)
信息检索是一个更为复杂的任务,往往会有Query—Tittle,Query—Document的形 式(Query可能是一个Document)检索需要计算相似度和排序一般建模为排位问题。
建模方法
-
统计方法:特征工程+算法(如PRanking、margin、SVM、LR等).
-
深度学习方法:表示学习抽取有用特征,交互聚合,孪生网络.
-
基于单语义文档表达的深度学习模型(基于表示-孪生网络)
- 主要思路:首先将单个文本先表达成一个稠密向量(分布式表达),然后直接计算两个向量间的相似度作为文本间的匹配度。
- ARC-I (基于CNN)
- ★ CDNN (基于CNN)
- ★ InferSent (基于RNN)
-
基于多语义文档表达的深度学习模型(基于交互-交互聚合)
-
主要思路:需要建立多语义表达,更早地让两段文本进行交互,然后挖掘文本交互后的模式特征,综合得到文本间的匹配度。
-
★ ESIM (基于RNN 和 Attention )
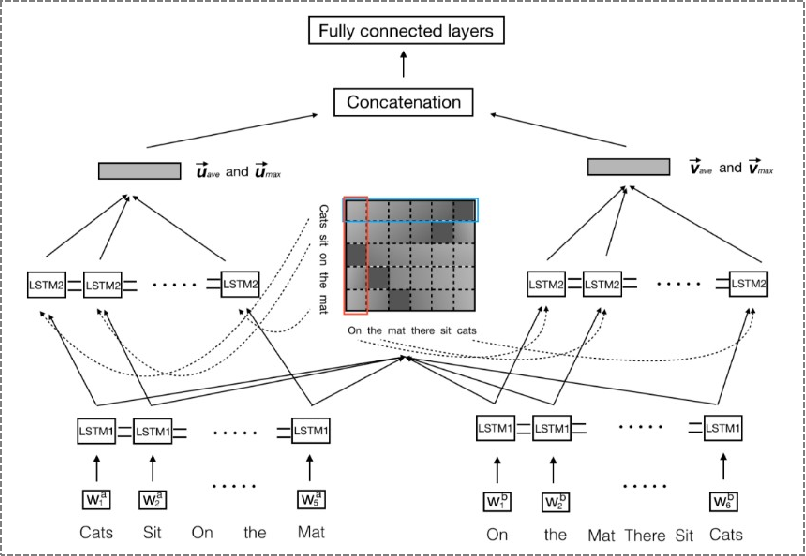
-
★ BiMPM(基于RNN)
-
-
复杂问题建模中常用交互耦合方法
- 应用:在复杂问题建模中,常用交互耦合方法进行序列间的耦合表示,为后继挖掘交互表示模式特征提供信息。例如,选择式阅读理解等任务中常使用这种方法。
-
序列标注:维特比算法
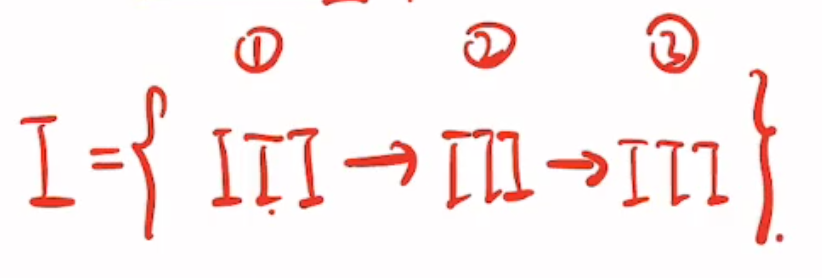
维特比算法求解篱笆网络(逐层推进,有向)中的最短路径问题

π 是初始状态概率,用向量表示:
$\pi = (\pi_i)_N \quad where \quad \pi=P(i_1=q_i)$
即,πi 是在时刻 t=1 时处于隐藏状态 qi 的概率;
A 是隐藏状态转移概率分布,通常用矩阵表示,称为状态转移矩阵:
B 是观察状态发射概率分布,通常用矩阵表示,称为混淆矩阵或发射矩阵:
1 初始状态
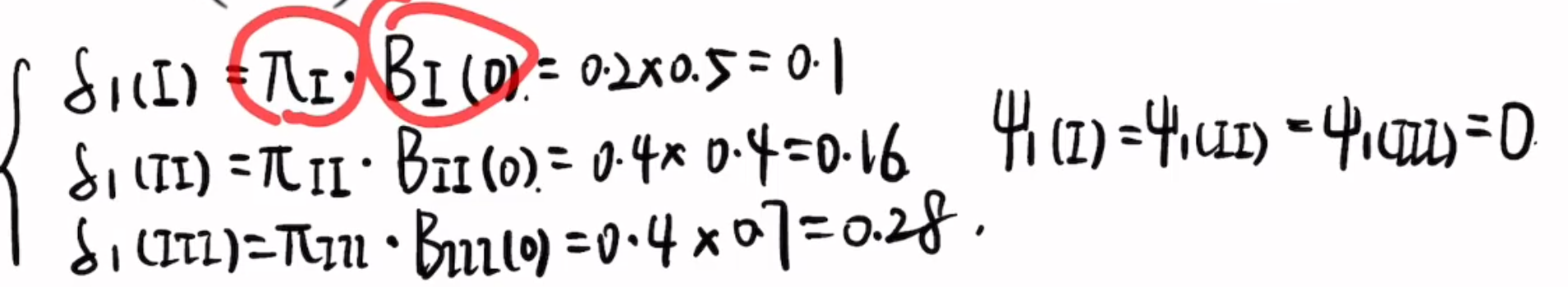
$$
\delta_{1}(Ⅰ)代表从0时刻的null状态转移到Ⅰ状态的概率
$$
$\psi_{1}(Ⅰ)$代表在1时刻取得状态Ⅰ时,上一时刻(时刻0)最可能的状态是什么
这里都是0状态(null状态/初始状态)
2 第二时刻
此时要考虑前一时刻的状态
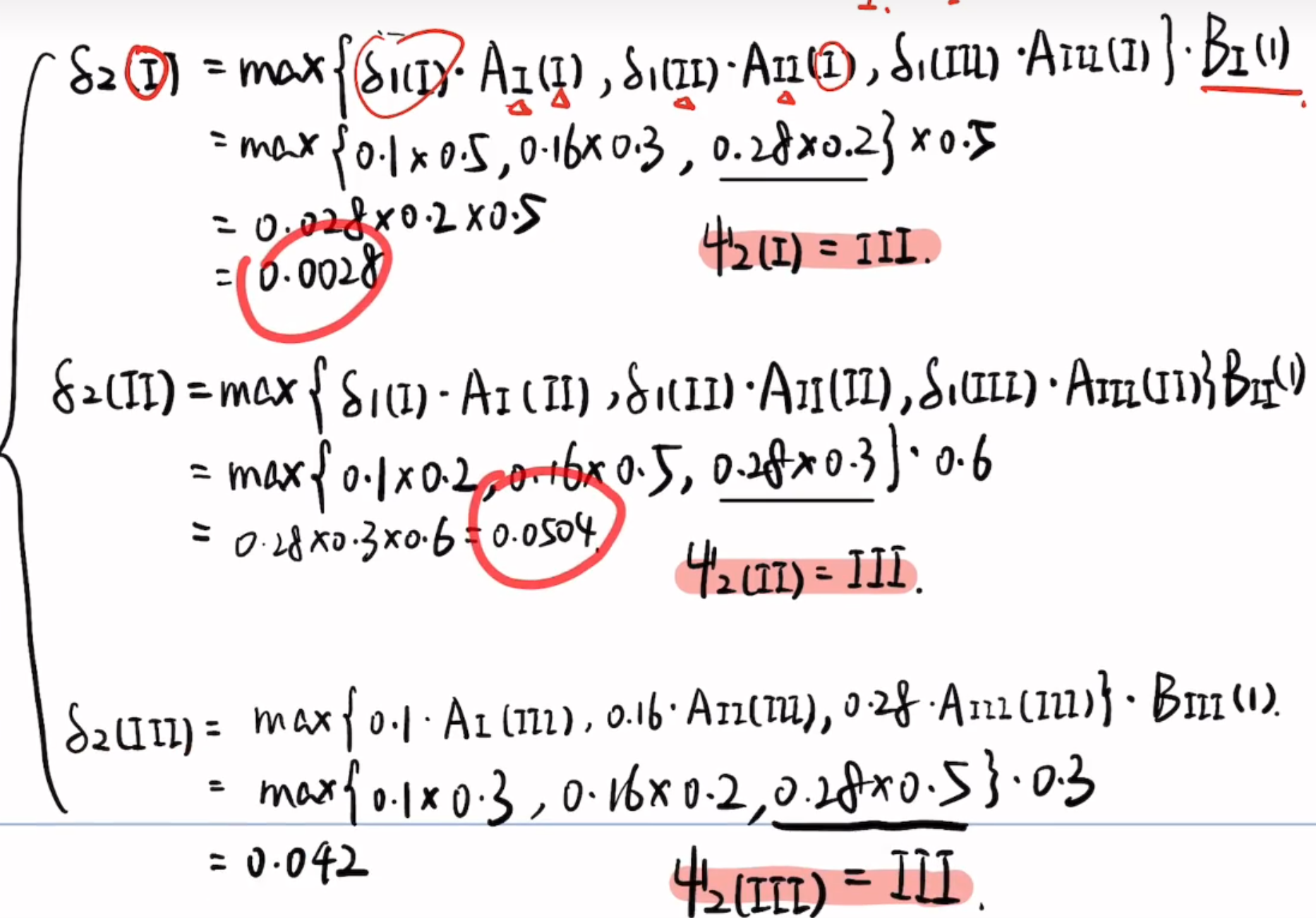
3 第三时刻
这里乘的就是$B_Ⅲ(0)$了,这和观测序列B有关,上一状态概率本次转移概率观测概率
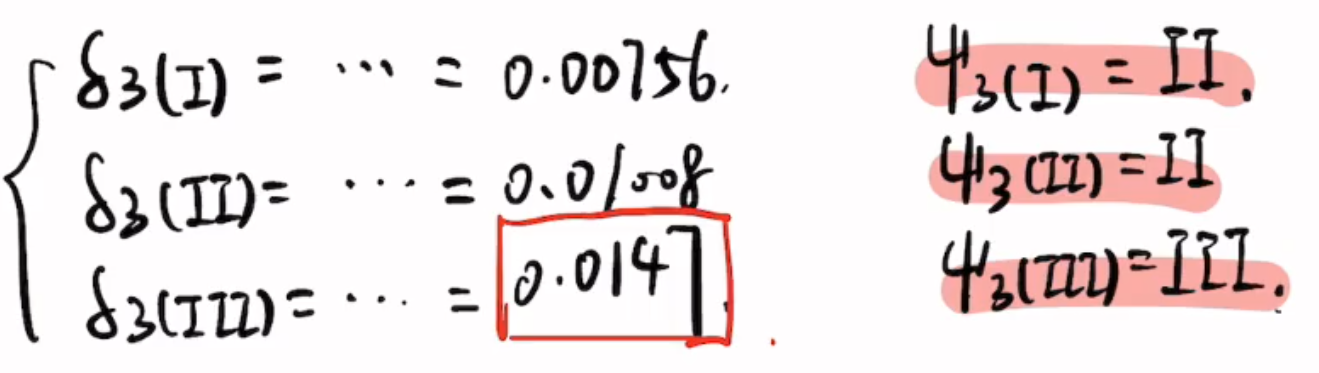
4 反推,解码隐藏状态
已知$\delta_3(Ⅲ)$最大,所以最后一个状态选择Ⅲ
后面根据$\psi()$选择前面的状态。
https://www.bilibili.com/video/BV18LigeFEPj/
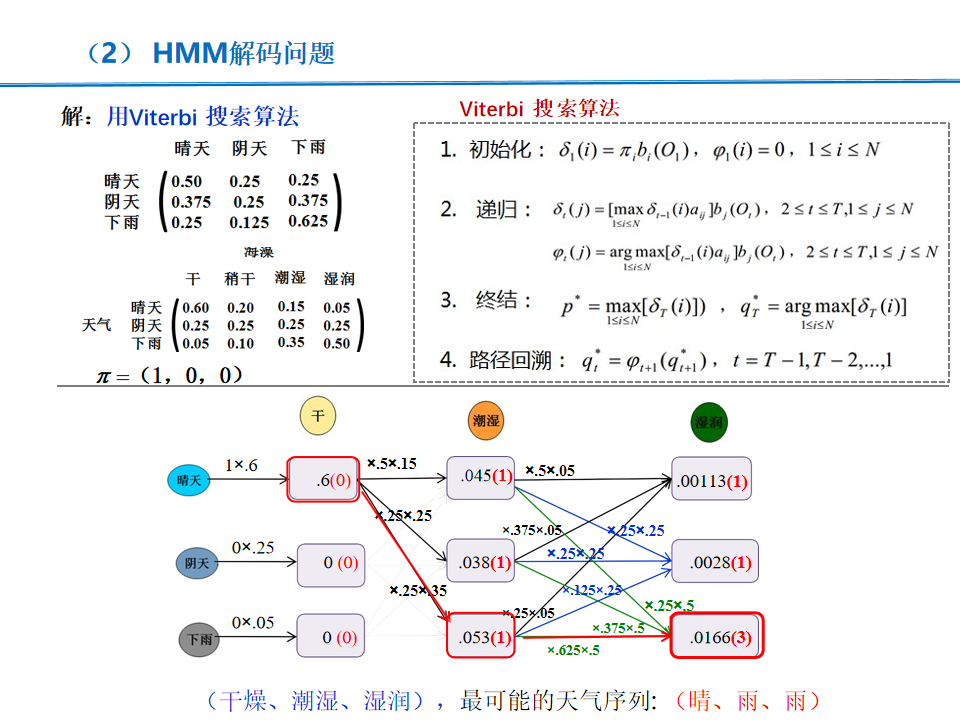
RNN+CRF 模型基本概念
实际上,这也适用于所有的循环网络模型
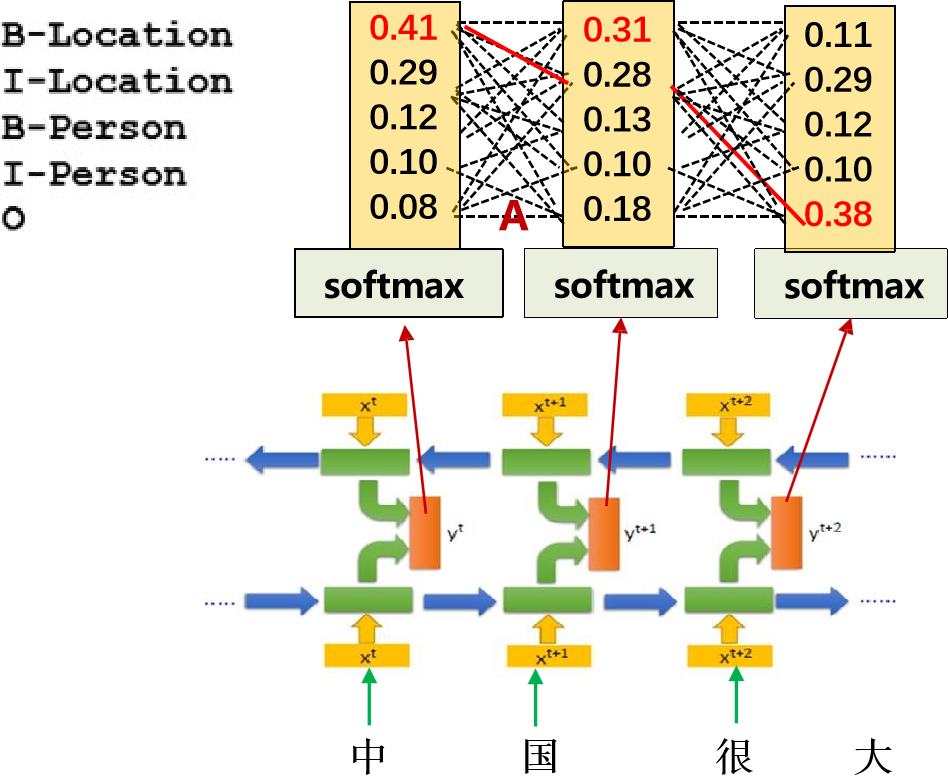
可以看到,每个时间步都有对应的类别概率
根据rnn的输出,我们有:
1 状态转移分布(分类-时间步)
2 观测序列
3 分类-vocabsize 的发射矩阵
根据样本中的观测序列,学习出一个最优的状态转移矩阵A(分类-分类) 这就是学习目标
-
有监督学习
-
损失函数 : 交叉熵损失
-
优化目标:
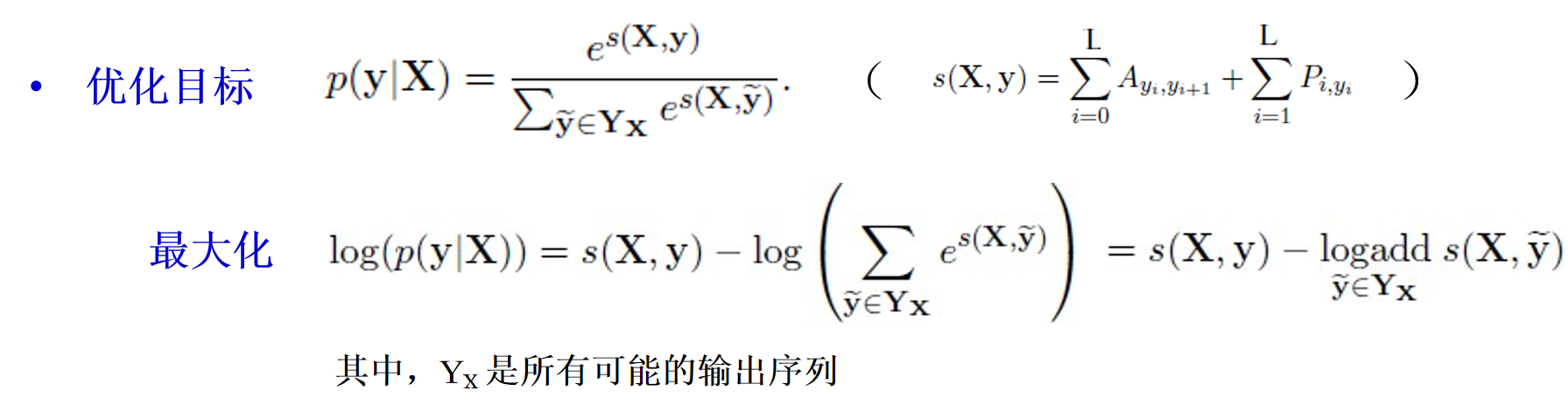
-
用BPTT算法训练参数
-
模型预测:
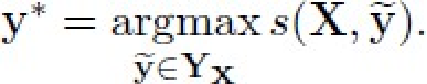
序列生成:基本概念
-
序列生成问题是NLP中常见和重要的研究内容,应用非常广泛,例如机器翻译‚自动文摘、机器阅读理解、对话生成 、自动生成字幕等多项任务。
-
NLP中的常见任务,如机器翻译、自动文摘、对话生成等,其核心是将输入序列X映射到输出序列Y,Y可以是任意长序列,序列生成分为自回归序列生成和条件序列生成,前者用历史序列信息预测下一个值,后者根据输入内容生成特定序列.
-
可控序列生成:在条件序列生成的基础上,增加对生成序列的属性C的控制,如关键实体、情感极性等,以满足实际需求.
-
Seq2Seq模型:基于Encoder-Decoder框架实现序列生成,分为纯生成式、选择式和选择-生成式模型,分别对应不同的解码方式.
解码方法
- 贪心解码:每一步选择概率最高的单词,简单高效但可能导致错误级联.
- 随机采样:按概率分布随机选择单词,增加多样性但可能生成不连贯文本.
- Beam Search:维护k个候选序列,每步从每个候选序列的概率分布中选择概率最高的k个单词,然后保留总概率最高的k个候选序列,平衡质量和多样性.
- top-k采样:每步只从概率最高的k个单词中随机采样,有助于提高生成质量但可能不符合常识.
- top-p采样(nucleus sampling) :每步只从累积概率超过阈值p的最小单词集合中随机采样,关注概率分布核心部分,避免不合适单词.
词元化算法
-
BPE(Byte Pair Encoding) :通过不断合并字符或子词生成子词词表,简化词表规模,处理罕见OOV(Out-of-Vocabulary)词,提高模型处理效率和效果.
-
算法步骤:
- Normalization和Pre-tokenization:统计语料中字符频率,将单词拆分为单个字符并加结束符</w>,加入词汇表.
- 计算Pre-token表中相连字符/片段的共现频率,将共现频率最高的合并,加入词汇表,并更新Pre-token表记录.
- 重复步骤2,直至得到期望大小的词汇表.
-
-
Wordpiece Model(子词方法) :将单词拆分为更小的单元sub-word,如“older”划分为“old”和“er”,有效缓解OOV问题和缩减词表规模.
评价指标
- BLEU(Bilingual Evaluation Understudy) :衡量生成序列与参考序列之间的N元词组重合度,计算不同长度的N元组合的精度,并进行几何加权平均,引入长度惩罚因子防止生成过短句子.
- ROUGE(Recall-Oriented Understudy for Gisting Evaluation) :计算召回率,从候选序列中提取N元组集合,与参考序列比较,衡量生成序列的完整性.
存在问题
-
曝光偏差问题(Exposure Bias) :自回归生成模型训练时使用真实数据作为前缀,而预测时使用模型生成的前缀,导致模型生成的分布与真实数据分布不一致,错误传播.
-
曝光误差(exposure bias)简单来讲是因为文本生成在训练和推断时的不一致造成的。
-
不一致体现在推断和训练时使用的输入不同,在训练时每一个词输入都来自真实样本(GroudTruth),但是在推断时当前输入用的却是上一个词的输出。
-
解决方法:Scheduled Sampling,在训练过程中混合使用真实数据和模型生成数据,逐渐减少真实数据的使用比例.
-
-
训练-评价目标不一致问题:训练时使用最大似然估计,而评价时使用BLEU、ROUGE等指标,导致训练目标和评价方法不一致.
- 解决方法:采用强化学习策略进行模型训练,将序列生成看作马尔可夫决策过程,优化期望回报以融入评价指标.
Transformer模型及训练
-
模型结构:
- 编码端(Encoder) :由6层Attention堆叠,包含Multi-head attention和Feed Forward Network两个子层,输入序列经过编码得到表示.
- 解码端(Decoder) :由6层Attention堆叠,包含Multi-head attention、cross-attention和Feed Forward Network三个子层,解码端的每一层与编码端的最后输出层做cross-attention,生成输出序列.
- 自注意力编码模块:对输入序列进行自注意力编码,计算Query、Key、Value,通过softmax计算注意力权重,得到编码表示.
- 多头自注意力编码模块:将自注意力编码过程分为多个头进行,每个头使用不同的参数,然后将结果拼接或平均,增强模型的表达能力.
-
训练:
-
训练语料:并行语料对(x, y),如机器翻译中的源语言句子和目标语言句子.
-
损失函数:交叉熵损失,计算模型输出与真实标签之间的差异.
-
训练策略:Teacher Forcing,训练时解码端可并行训练,利用真实数据作为前缀,提高训练效率.
-
掩码技术:
- Padding Mask:处理非定长序列问题,使不定长序列可以按定长序列统一并行操作,在Attention计算中对padding部分的值加上一个非常大的负数,使得这些位置的权重接近0.
- Sequence Mask:防止标签泄露,在Decoder的Self-Attention中使用,对解码端的输入进行掩码,确保解码时只能看到之前的输出,不能看到未来的输出.
-
-
预测:
- 输入源句子到编码端进行并行编码,得到编码表示.
- 解码端从起始符<Go>开始,逐步生成输出序列,每一步根据已生成的序列和编码表示进行解码,直至生成结束符号<Eos>.
指针网络的基本概念
- 定义:指针网络是一种特殊的序列生成模型,其核心思想是通过“指针”直接从输入序列中选择输出元素,而不是从固定的输出词表中生成新的元素。这种机制特别适合于输出序列中的元素是输入序列的子集的任务,如文本摘要、机器阅读理解等。
- 适用场景:指针网络适用于那些输出序列中的元素必须是输入序列中的元素的任务。例如,在机器阅读理解中,答案通常是文章中的某个片段,而不是完全生成的新内容。
- 优势:相比于传统的生成模型,指针网络能够有效地处理输出序列中的OOV(Out-of-Vocabulary)问题,即输出序列中可能出现不在固定词表中的词。通过直接从输入中选择,指针网络可以生成更准确和自然的结果.
指针网络的模型结构
- 编码器-解码器架构:指针网络通常采用编码器-解码器架构。编码器对输入序列进行编码,生成每个输入元素的表示;解码器则根据编码器的输出和当前的解码状态来选择下一个输出元素。
- 注意力机制:指针网络中的解码器通常会使用注意力机制来计算对输入序列中各个元素的关注程度。注意力权重决定了每个输入元素被选为下一个输出元素的概率.
- 选择过程:在每一步解码过程中,解码器会根据当前的解码状态和注意力权重,从输入序列中选择一个元素作为输出。选择过程通常通过计算一个概率分布来实现,该分布反映了每个输入元素被选中的概率.
指针网络的应用
- 文本摘要:在自动文本摘要任务中,指针网络可以用于生成摘要,通过从原文中选择关键句子或片段来构建摘要.
- 机器阅读理解:在机器阅读理解任务中,指针网络可以用于生成答案,通过从文章中选择相关的片段来回答问题.
- 其他选择任务:指针网络还可以应用于其他需要从输入序列中选择输出元素的任务,如序列排序、路径选择等.
指针网络的优缺点
-
优点:
- 处理OOV问题:能够有效地处理输出序列中的OOV问题,生成更准确的结果.
- 灵活性:适用于多种需要从输入序列中选择输出元素的任务.
-
缺点:
- 生成能力有限:由于输出元素必须是输入序列中的元素,因此在需要生成新内容的任务中可能不适用.
- 复杂性:模型结构相对复杂,训练和实现难度较高.
指针网络的扩展
- 结合生成能力:为了弥补指针网络在生成新内容方面的不足,可以将其与传统的生成模型相结合,形成“选择-生成”模型。这种模型既可以从输入中选择元素,也可以生成新的元素,从而在处理复杂任务时具有更强的灵活性和适应性.
- 多任务学习:指针网络还可以与其他任务结合进行多任务学习,以提高模型的泛化能力和性能
八章 属性级情感分析
概念定义
-
属性级情感分析(ABSA) :这是一种细粒度的情感分析任务,旨在识别文本中提到的实体及其属性,并判断这些属性的情感倾向。它不仅关注整体情感,还关注具体属性的情感态度。
-
实体和属性:
- 实体(Entity) :如产品、人物等。
- 属性(Aspect) :实体的特定特征或方面,如手机的屏幕、电池等。
-
观点结构:通常用五元组表示一个观点:(实体, 属性, 情感, 观点持有者, 时间)。
任务定义
-
属性抽取(Aspect Extraction, AE) :从文本中识别出所有提到的属性。
-
观点抽取(Opinion Extraction, OE) :识别与属性相关联的观点词或短语。
-
情感分类(Sentiment Classification, SC) :判断每个属性的情感倾向(正面、负面、中立等)。
-
联合任务:
- 属性观点联合抽取(Pair Extraction) :同时识别属性和观点,并将它们配对。
- 属性抽取+观点抽取+情感分类(AESC) :在一个任务中同时完成属性抽取、观点抽取和情感分类.
建模方法
-
基于传统机器学习的方法:
- 使用特征工程提取与属性和情感相关的特征,如词性标注、情感词典等。
- 应用分类算法(如SVM、随机森林)进行情感分类.
-
基于深度学习的方法:
-
序列标注模型:
- BiLSTM-CRF:使用双向长短期记忆网络(BiLSTM)捕捉文本的上下文信息,然后通过条件随机场(CRF)进行序列标注,实现属性抽取.
- BERT:利用预训练语言模型BERT的上下文表示能力,进行属性和观点的抽取.
-
注意力机制模型:
- AT-LSTM:基于注意力的LSTM模型,通过注意力机制关注与属性相关的情感信息,实现属性级情感分类.
- ATAE-LSTM:在AT-LSTM的基础上,改进属性向量的拼接方式,提高模型的性能.
-
图神经网络(GNN) :
- 利用图结构表示实体和属性之间的关系,通过图卷积网络捕捉复杂的关系信息,进行属性级情感分析.
-
联合学习框架:
- Span-based extract-then-classify framework:先抽取属性和观点的span,然后进行情感分类,使用BERT等预训练模型作为基础.
- Joint training dual-MRC framework:将属性抽取、观点抽取和情感分类联合训练,使用BERT作为骨干网络,通过多任务学习提高模型的整体性能.
- A Unified Generative Framework:将所有的ABSA任务统一到一个生成框架中,使用BART等生成模型进行端到端的建模.
-
未来研究方向
- 复杂的属性多元组抽取:研究如何抽取包含多个属性和观点的复杂结构.
- 联合学习抽取和分类:进一步探索属性抽取和情感分类的联合学习方法,提高模型的效率和准确性.
- 引入外部知识:结合语义知识库、情感词典等外部知识,增强模型的理解能力.
- 表示学习:研究更先进的表示学习方法,如Transformer、GNN等,以更好地捕捉文本中的复杂语义信息.
序列生成
- 情感弧生成:在故事生成任务中,根据给定的情感弧(如开始、主体和结束的情感序列),生成符合情感变化的故事.
- 情感对话生成:在对话系统中,考虑情绪因素,生成具有情感连贯性和共情能力的对话回复,如使用内部和外部情绪记忆机制.
- 共情聊天机器人:除了识别情绪类别,还需了解情绪背后的原因,生成共情回复,如通过检测情绪原因和指导用户进行自我披露.
十章 问答系统
问答系统的基本概念与分类
-
基本概念:问答系统是人与计算机交互的过程,通过自然语言查询从资源中检索相关信息并生成答案.
-
分类:
- 专家系统:限定领域,依赖结构化知识库,将问题转化为SQL查询.
- 检索式问答系统:基于非结构化Web数据,通过检索相关文档和段落来抽取答案.
- 社区问答系统:利用社区中的用户生成内容,找到与问题相应的答案.
- 知识库问答系统:利用知识图谱等结构化知识进行查询和推理,得出答案.
问答系统方法设计思想
- 问题理解:分析问题的句子成分、类别和潜在答案类型,为后续的资源检索和答案生成提供依据.
- 资源分析:根据问题分析结果,确定可能含有答案的数据集或知识库,为检索和答案生成提供数据支持.
- 答案形成:在候选答案集中采用各种技术抽取或生成答案,并返回给用户,是问答系统的核心环节.
典型模型与方法
-
检索式问答系统:
-
流水线方式:
- Document Retriever:通过TF-IDF等方法检索与问题相关的文档,如DrQA系统.
- Document Reader:将答案抽取转化为抽取式阅读理解问题,从文档中抽取答案片段.
- 答案重排序:结合多个证据对答案进行重排序,如strength-based re-ranker和coverage-based re-ranker.
-
端到端方式:
- Retriever-Reader联合学习:如ORQA模型,将Retriever和Reader都设计为可学习的神经网络模型,并通过Inverse Cloze Task等预训练任务提升检索和阅读理解能力.
- Retriever-Free方法:利用大规模预训练语言模型(如GPT-2、T5等)直接从模型参数中检索答案,无需显式检索外部文档.
-
-
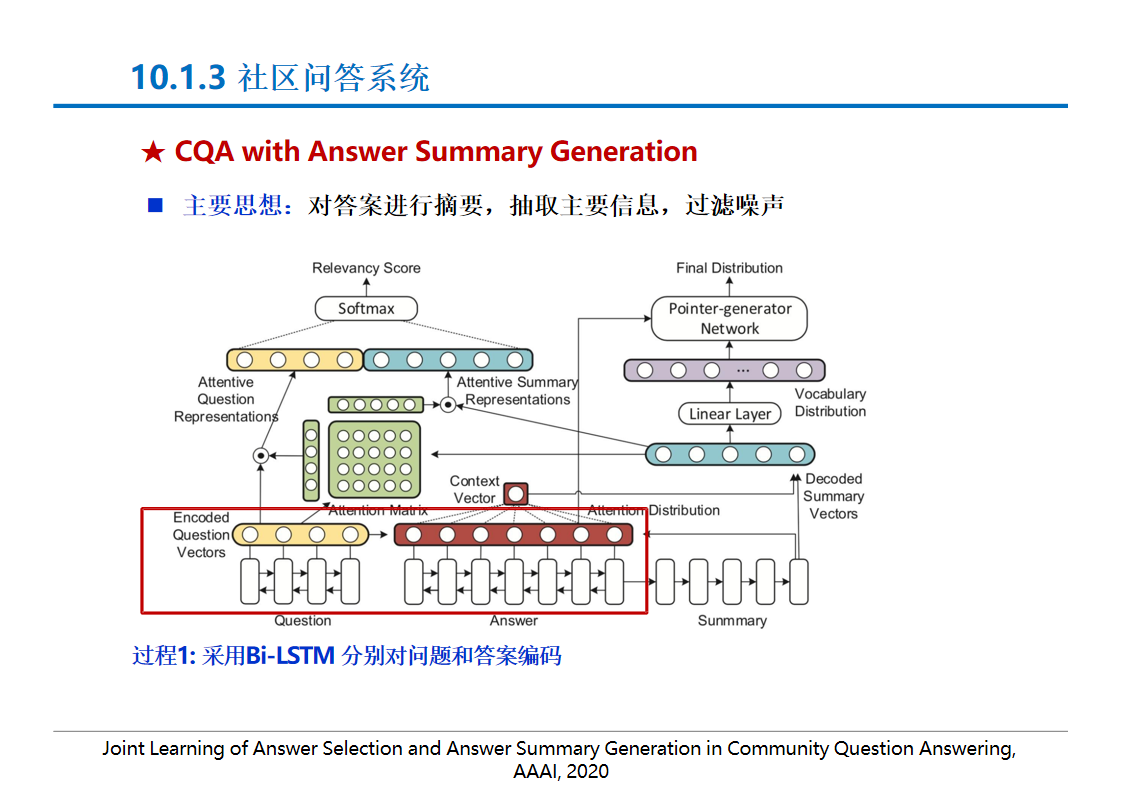
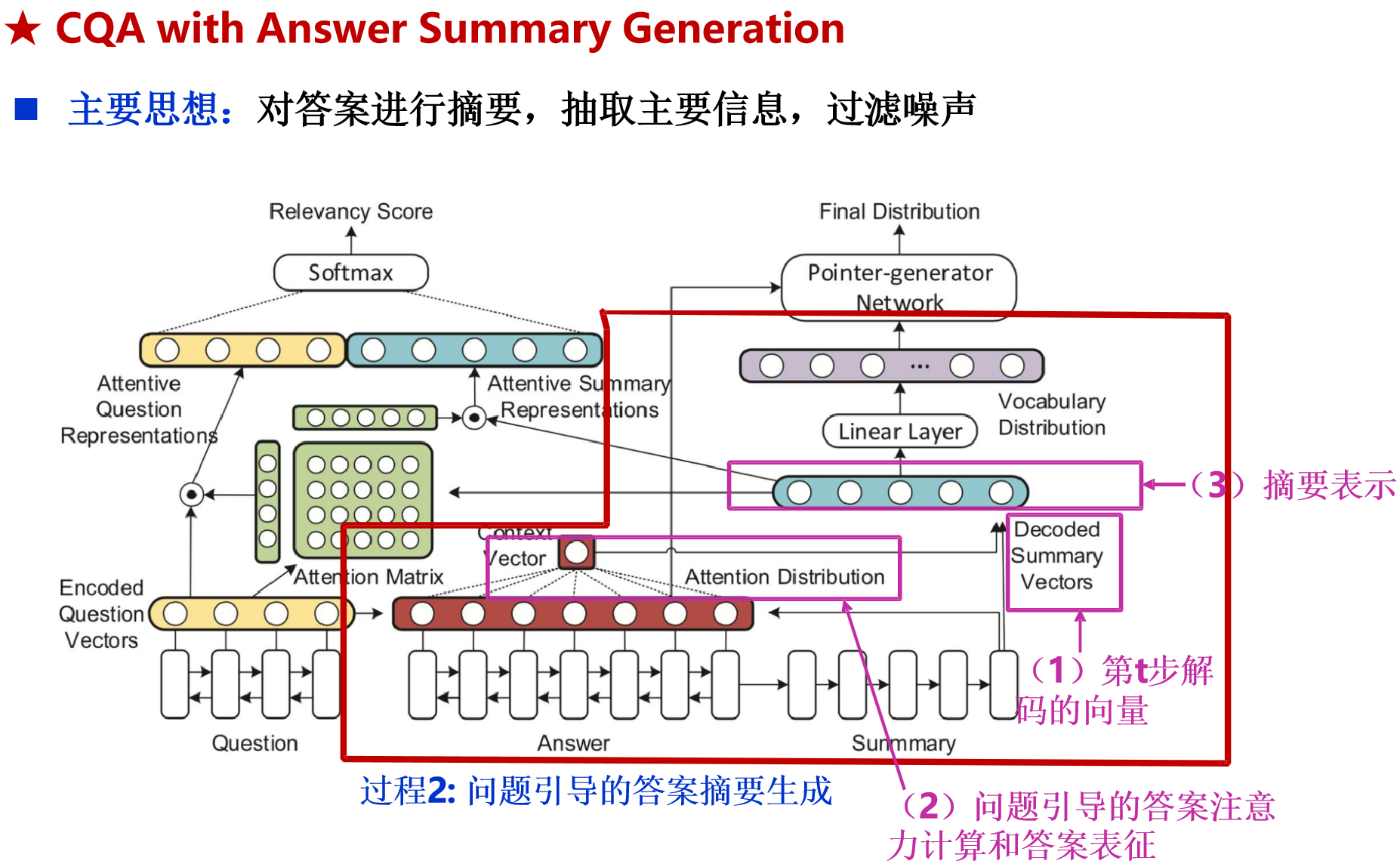
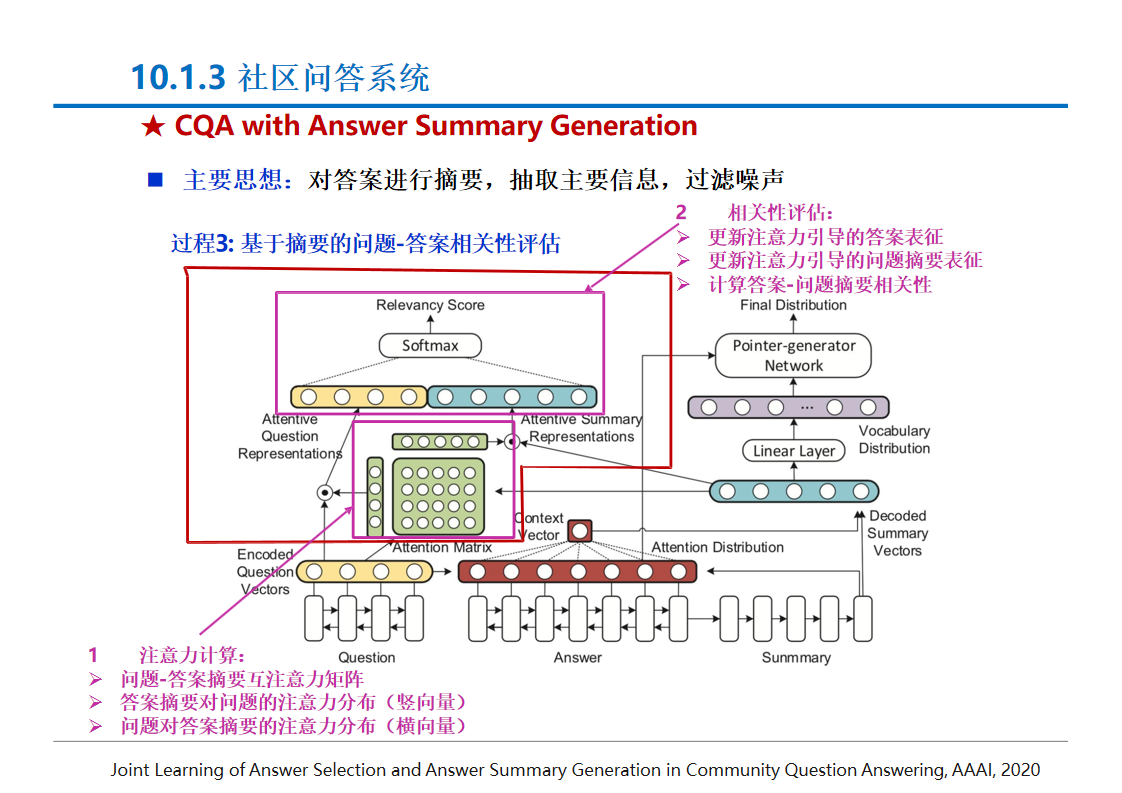
社区问答系统:
- 问题对检索模型:通过信息检索找到与问题相似的问题,然后返回答案或相似问题列表.
- 答案质量评估:判断答案的质量,如通过用户信息、答案摘要生成等方法提升答案质量评估的准确性.
-
知识库问答系统:
- 语义解析:将自然语言问题转化为逻辑形式,通过查询语句在知识库中检索答案.
- 信息抽取:提取问题中的实体,在知识库中查询相关子图,通过分类器筛选候选答案.
- 向量建模:对问题和候选答案进行编码表示,通过向量相似度计算筛选答案.
- 融合文本和知识图谱:如GRAFT-Net等模型,通过构建异构图并进行信息传播更新,融合文本和知识图谱的知识进行问答.
- 知识增强的大模型问答:将知识图谱中的知识以三元组或子图特征的形式注入到大语言模型的prompt中,提升问答的准确性和知识性.
考点总结
- 问答系统的基本概念与分类:理解问答系统的定义、分类及其适用场景.
- 方法设计思想:掌握问题理解、资源分析和答案形成的基本思路和方法.
- 典型模型与方法:熟悉各种问答系统类型中的典型模型和方法,如检索式问答的流水线方式和端到端方式、社区问答的问题对检索和答案质量评估、知识库问答的语义解析和信息抽取等.
- 模型的优缺点与适用场景:分析不同模型在问答任务中的优缺点,以及它们在不同场景下的适用性,如检索式问答在开放域问答中的优势和局限性、知识库问答在准确性方面的优势等.
社区问答系统