目录
一、排序概述
二、插入排序
2.1直接插入排序
2.2折半插入排序
2.3二路插入排序
2.4表插入排序
2.5希尔排序
三、交换排序
3.1冒泡排序
3.2快速排序
四、选择排序
4.1简单选择排序
4.2锦标赛排序
4.3堆排序
五、归并排序
六、基数排序
七、总结
一、排序概述
定义:将一组存放在数据表中的无序数据按照一定的顺序排列起来
目的:便于查找
排序算法衡量指标:
- 时间效率——排序速度
- 空间效率——占内存辅助空间大小
- 稳定性——若两个记录A和B的关键字值相等,且排序后A、B的先后次序保持不变,则称这种排序算法是稳定的
内部排序:待排序记录都在内存中
外部排序:数据量过大,将数据分批调入内存进行排序,还要将结果及时放入外存
待排序记录在内存中的存储和处理:
- 顺序排序:排序时直接移动记录
- 链表排序:排序时只移动指针
- 地址排序:排序时先移动地址,最后再移动记录
内部排序算法分类:
- 插入排序
- 交换排序
- 选择排序
- 归并排序
- 基数排序
列表结构及建立:
typedef struct {int array[MAXSIZE + 1];int length;
}list;void initlist(list& l)
{printf("number?");scanf_s("%d", &l.length);for (int i = 1; i <= l.length; i++){printf("data:");scanf_s("%d", &l.array[i]);}
}
二、插入排序
基本思想:每步将一个待排序的对象,按其关键码大小,插入到前面已经排好序的一组对象的适当位置上,直到对象全部插入为止。简言之,边插入边排序,保证子序列中随时都是排好序的。
2.1直接插入排序
对于每一个元素,在已形成的有序线性表中从后向前找插入位置,原位置元素向后移,新元素插入。是最简单的排序法。
| 时间效率 | 最好:O(n),数据本就有序,比较n-1次 最差:O(n^2),数据逆序,从第二个元素开始,每个元素都要与有序部分全比较一遍,比较1+2+...n-1次 |
| 空间效率 | O(1),占用一个缓冲单元 |
| 稳定性 | 稳定 |
代码:
#include<stdio.h>
#include<stdlib.h>#define MAXSIZE 20typedef struct {int array[MAXSIZE + 1];int length;
}list;void initlist(list& l)
{printf("number?");scanf_s("%d", &l.length);for (int i = 1; i <= l.length; i++){printf("data:");scanf_s("%d", &l.array[i]);}
}void sort(list& l)
{int i, j;for (i = 2; i <= l.length; i++) //0号为缓冲位,1号默认为有序,所以从2号开始遍历{if (l.array[i - 1] > l.array[i]) //新元素大于等于有序部分最后一位(即前一个元素)时无需操作,小于时进行操作{l.array[0] = l.array[i]; //新元素值复制到缓冲区j = i-1;while (l.array[j] > l.array[0]) //将有序部分大于新元素的部分后移{l.array[j + 1] = l.array[j];j--;}l.array[j + 1] = l.array[0]; //新元素插入}}for (i = 1; i <= l.length; i++)printf("%d ", l.array[i]);
}int main() {list l;initlist(l);sort(l);
}2.2折半插入排序
子表有序且为顺序存储结构,则插入时采用折半查找定可加速定位。与直接插入排序相比,元素间的比较次数减少
| 优点 | 比较次数大大减少,全部元素比较次数仅为O( |
| 时间效率 | 移动次数并未减少, 所以排序效率仍为O(n^2) |
| 空间效率 | O(1) |
| 稳定性 | 稳定 |
2.3二路插入排序
增加一个元素数和待排数组相同的循环数组d
先将list第一个元素赋给d第一个元素,然后以此元素为基准,把list中其他元素插入到基准的前面或后面,最终从头指针到尾指针即为有序数组
2.4表插入排序
在顺序存储结构中,给每个记录增开一个指针分量,在排序过程中不移动元素,只修改指针,最终得到一个有序链表
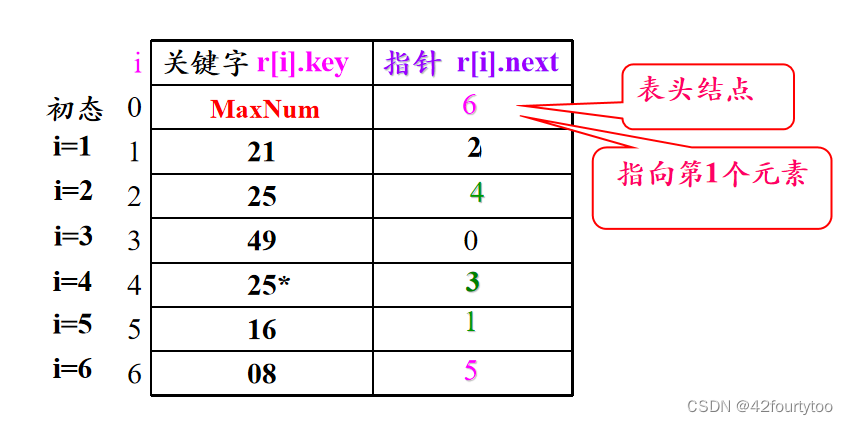
| 时间效率 | 无需移动记录,只需修改2n次指针值。但由于比较次数没有减少,故时间效率仍为O(n^2) |
| 空间效率 | 低,因为增开了指针分量。但在运算过程中没有用到更多的辅助单元 |
| 稳定性 | 稳定 |
2.5希尔排序
先将整个待排序列分割为若干子序列,子序列中分别插入排序,再扩大子序列范围,插入排序,至整个序列有序
子序列的选择:将相隔一定距离的元素划分为一个序列,间隔逐渐缩短
| 时间效率 | O(n^1.25)~O(1.6n^1.25) 由经验公式得到 |
| 空间效率 | O(1) |
| 稳定性 | 不稳定 |
代码:
#include <stdio.h>
#include <malloc.h>void shellsort(int* a, int len)
{int i, j, k, tmp, gap; // gap 为步长for (gap = len / 2; gap > 0; gap /= 2) // 步长初始化为数组长度的一半,每次遍历后步长减半{ for (i = 0; i < gap; ++i) // 变量 i 为每次分组的第一个元素下标;间隔数也是组数{ for (j = i + gap; j < len; j += gap) //对每组元素进行插入排序;在每组中第一个默认为有序,从第二个开始遍历{ tmp = a[j]; // 备份a[j]的值k = j - gap; // k初始化为j的前一个元素while (k >= 0 && a[k] > tmp) // 把一组中有序部分比tmp的值大的元素向后移动{a[k + gap] = a[k]; k -= gap;}a[k + gap] = tmp; // 把tmp插入}}}
}int main(void)
{int i, len, * a;printf("请输入要排的数的个数:");scanf_s("%d", &len);a = (int*)malloc(len * sizeof(int)); // 动态定义数组if (!a) return NULL;printf("请输入要排的数:\n");for (i = 0; i < len; i++) // 数组值的输入scanf_s("%d", &a[i]);shellsort(a, len); // 调用希尔排序函数printf("希尔升序排列后结果为:\n");for (i = 0; i < len; i++) // 排序后的结果的输出printf("%d\t", a[i]);printf("\n");
}用希尔排序方法对一个数据序列进行排序时,若第1趟排序结果为9,1,4,13,7,8,20,23,15,则该趟排序采用的增量(间隔)可能是( )
- A. 2
- B. 3
- C. 4
- D. 5
答案:B 依次对选项进行假设,当组内都有序时假设成立
三、交换排序
两两比较关键码,如果逆序,则进行交换
3.1冒泡排序
每趟不断将相邻两记录两两比较,并按“前小后大”(或“前大后小”)规则交换。每趟结束时,能挤出一个最大值到最后面
| 优点 | 每一趟整理元素时,不仅可以完全确定表尾一个元素的位置,还可以对前面的元素作一些整理,所以比一般的排序要快 |
| 时间效率 | 最好情况:初始排列有序,只执行一趟冒泡,做 n-1 次比较,不移动对象; 最坏情形:初始排列逆序,执行n-1趟冒泡,第i趟(1<=i<=n) 做了n - i 次比较,执行了 n - i 次交换.此时比较总次数:n(n-1)/2 记录移动总次数:3/2n(n-1) 最坏情况O(n^2) |
| 空间效率 | O(1) |
| 稳定性 | 稳定 |
代码:
#include<stdio.h>
#include<stdlib.h>void sort(int* list, int len)
{for (int i = 0; i < len - 1; i++) //进行len-1次排序{for (int j = 1; j < len - i; j++) //每次从第2个元素遍历到len-i号元素{if (list[j - 1] > list[j]){int t = list[j];list[j] = list[j - 1];list[j - 1] = t;}}}
}int main() {int i, len, * a;printf("请输入要排的数的个数:");scanf_s("%d", &len);a = (int*)malloc(len * sizeof(int)); // 动态定义数组if (!a) return NULL;printf("请输入要排的数:\n");for (i = 0; i < len; i++) // 数组值的输入scanf_s("%d", &a[i]);sort(a, len);for (i = 0; i < len; i++)printf("%d ", a[i]);
}对一组数据(2,12,16,88,5,10)进行排序,若前三趟排序结果如下( )
第一趟:2,12,16,5,10,88
第二趟:2,12,5,10,16,88
第三趟:2,5,10,12,16,88
则采用的排序方法可能是:
- A. 快速排序
- B. 冒泡排序
- C. 基数排序
- D. 希尔排序
答案:B 每次排序都有最大值挤到最后
3.2快速排序
思路:以首元素为基准,首元素此时为“空闲位”。先从后向前找比首元素小的,复制到空闲位,自身变为新的空闲位;再从前往后找比基准大的,复制到空闲位,自身成为新的空闲位。当前后指针相遇时把基准插入。此时列表基准左边都比它小,右边都比它大,向左右递归继续排序。
| 时间效率 | |
| 空间效率 | |
| 稳定性 | 不稳定 |
代码:
//快速排序:以首位数为基准,用两指针从两侧逼近,把小于基准的都放到基准左侧,大于基准的都放到基准右侧,再缩小范围,递归。
void quicksort(int*& list, int l, int r) { //传入数组,开始和结束的编号if (l < r) {int p1 = l;int p2 = r; //两指针指向两侧int target = list[l]; //首元素为基准while (p1 < p2) { //以下操作都需要当两指针未重合时才能执行while (p1 < p2 && list[p2] > target) //从后向前找到不大于target的值p2--;if (p1 < p2)list[p1++] = list[p2]; //把这个值赋给p1,p1后移while (p1 < p2 && list[p1] < target) //从前向后找到不小于target的值p1++;if (p1 < p2)list[p2--] = list[p1]; //把这个值赋给p2,p2前移}list[p1] = target; //把重合之处赋为target//递归调用quicksort(list, l, p1 - 1);quicksort(list, p1 + 1, r);}
}下列序列中,( )是执行第一趟快速排序后所得的序列。(下划线表示已找到位置的元素)
- A. [68,11,18,69]_[23,93,73]
- B. [68,11,69,23]_[18,93,73]
- C. [93,73]_[68,11,69,23,18]
- D. [73,11,69,23,18]_[93,68]
答案:D 只有D能找到一个数,使左边数组都小于它,右边数组大于它
四、选择排序
选择排序的基本思想:每一趟(第i趟)在后面n - i + 1个待排记录中选取关键字最小的记录作为有序序列中的第 i 个记录。
4.1简单选择排序
| 时间效率 | O(n^2) 走 n - 1 趟,每趟遍历 n - i 个元素 |
| 空间效率 | O(1) |
| 稳定性 | 不稳定 |
代码:
void simple_section_sort(int* list, int len)
{int min, x;for (int i = 0; i < len - 1; i++) // 要对前n-1个位置进行选择,插入{min = 65535;x = i;for (int j = i; j < len; j++) //选择出i到末尾的最小值{if (list[j] < min){min = list[j];x = j;}} int tmp = list[x]; //将最小值与第i个元素交换list[x] = list[i];list[i] = tmp;}
}对一组数据(84,47,25,15,21)排序,数据的排列次序在排序的过程中的变化为
(1) 84 47 25 15 21 (2) 15 47 25 84 21 (3) 15 21 25 84 47 (4) 15 21 25 47 84
则采用的排序是 ( )
- A. 选择
- B. 冒泡
- C. 快速
- D. 插入
答案:A 最小值不断增加
4.2锦标赛排序
思路:把待排元素当作一棵完全二叉树的叶子节点,叶子不足的补齐;从下向上建立二叉树,父节点为子节点中较小值;此时根节点为排序的第一个结果;然后把树中的这个值变为无穷,更新父节点,得到新的根节点为排序的第二个结果;直到所有叶节点都遍历。
| 时间效率 | |
| 空间效率 | O(n) 胜者树附加节点n-1个 |
| 稳定性 | 稳定 当遇到两个数值相同时,认为左边较小 |
代码:
不写了,知道过程就行 :)
4.3堆排序
准备知识:
1.堆的结构是完全二叉树。构造堆的时候从上往下,从左往右依次添加节点
2.一般用数组来表示堆,用下标的计算关系来指明父子关系
3.下标为 i 的结点的父结点下标为 (i-1)/2;其左右子结点分别为 (2i + 1)、(2i + 2)
4.大根堆:父节点值大于两子节点 小根堆:父节点值小于两子节点
建堆:
例:关键字序列T= (21,25,49,25,16,08),建大根堆
1.将原始序列画成完全二叉树的形式(准备知识1)
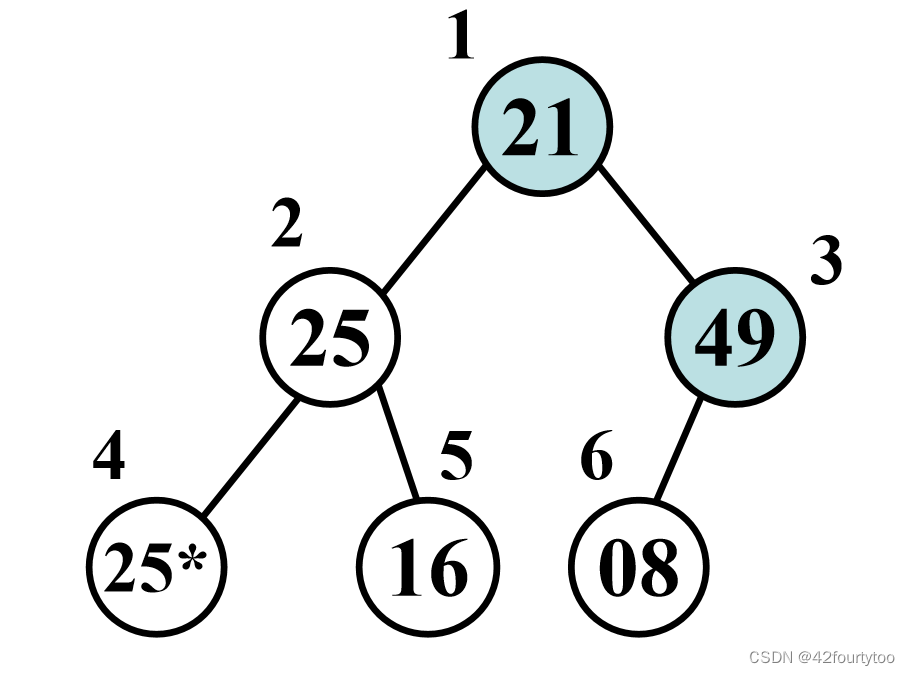
初始堆 2.从完全二叉树的最后一个非终端节点(编号为 [n/2])开始调整,图中为49
3.该节点(49)与它的两个子节点(08)进行比较,把较大值放到父节点的位置(49>8,不动)
4.对倒数第二个非终端节点进行此操作(25>25*,25>16,不动 ),一直遍历到根节点
5.另外,被换下来的节点要继续向下比较(如根节点21,21<25<49,21与49交换,交换后21要与子节点(08)继续比较,判断是否还要交换)
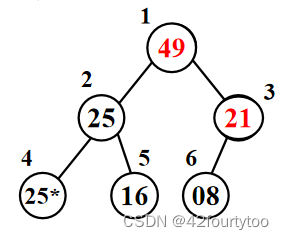
大根堆
此时根节点为最大值,开始排序
排序:
1)最大值在根节点,也就是数组第一位。把第一位与最后一位第n位交换,把最大值放到最后
2)数组从1到n-1重新建堆。最大值又上浮到第一位
3)再对调第一位和第n-1位,如此重复,得到有序序列
算法流程:
void HeapSort (HeapType &H ) //对顺序表H进行堆排序
{for (i = H.length / 2; i >0; --i)HeapAdjust(H, i, H.length); //倒序遍历非叶子节点,建立初始堆for (i = H.length; i > 1; --i) { H.r[1] ←→ H.r[i]; //最大值和尾部交换HeapAdjust(H, 1, i-1); //把刚换上去的头节点进行调整,重建最大堆}
}//HeapAdjust是针对结点 i 的堆调整函数,其含义是:从结点i开始到堆尾为止
//从上向下比较,如果子女的值大于双亲结点的值,则互相交换,即把局部调整为大根堆| 时间效率 | |
| 空间效率 | O(1) 仅在首尾交换时用到一个临时变量temp |
| 稳定性 | 不稳定 |
练习:
已知关键序列5,8,12,19,28,20,15,22是小根堆(最小堆),插入关键字3,调整后得到的小根堆是?
答案:3,5,12,8,28,20,15,22,19
五、归并排序
思路:把一个长度为n的无序序列看成是n个长度为 1 的有序子序列。将数组的每一个元素划分为一个有序表。两两合并,组内分别排序;再两两合并,组内排序;最终得到有序序列。

| 时间效率 | |
| 空间效率 | O(n) 在合并两子序列时,需要一个长度为n的辅助序列 |
| 稳定性 | 稳定 |
代码:
#include<stdio.h>
#include<stdlib.h>void merge(int* list, int low, int mid, int high)
{int p;int* a = (int*)malloc(sizeof(int) * (high - low + 1));if (!a) return;for (p = low; p <= high; p++)a[p] = list[p];int i, j, k;for (i = low, j = mid + 1, k = low; i <= mid && j <= high; k++){if (list[i] > list[j])a[k] = list[j++];elsea[k] = list[i++];}while (i <= mid)a[k++] = list[i++];while (j <= high)a[k++] = list[j++];for (p = low; p <= high; p++)list[p] = a[p];
}void mergesort(int* list, int low, int high) //归并排序
{if (low < high) {int mid = (low + high) / 2;mergesort(list, low, mid); //对前半部分归并排序mergesort(list, mid + 1, high); //对后半部分归并排序merge(list, low, mid, high); //把排序完的部分合并}
}int main(void)
{int i, len, * list;printf("请输入要排的数的个数:");scanf_s("%d", &len);list = (int*)malloc(len * sizeof(int)); // 动态定义数组if (!list) return NULL;printf("请输入要排的数:\n");for (i = 0; i < len; i++) // 数组值的输入scanf_s("%d", &list[i]);mergesort(list, 0, len - 1);for (i = 0; i < len; i++)printf("%d ", list[i]);}六、基数排序
基本思想:从多维度对元素进行排序,比如对扑克牌进行排序,可以先按花色分类,再按数字大小分类;也可以先按数字大小分类,再按花色分类。这也叫多关键字排序。
多关键字排序的实现通常有两种实现方法:
- 最高位优先法MSD (Most Significant Digit first)
- 最低位优先法LSD (Least Significant Digit first)
若规定花色为第一关键字(高位),面值为第二关键字(低位),则上文第一种方法为MSD,第二种为LSD。
数值排序思路:
把数字的每一位看作一个维度。最多有几位,就要经过几趟排序。先从数字最低位开始比较。
建立编号0~9的十个队列
遍历数组中的数字,按照个位数字将它们放入对应的队列(分配)
遍历完后,按照从上到下,从左到右的顺序把数字从队列中取出得到第一遍整理后的数组(收集)
再按照十位数字入队列,再取出...直到最高位

例:
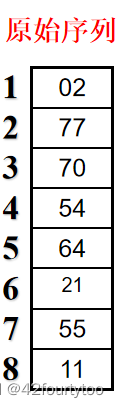


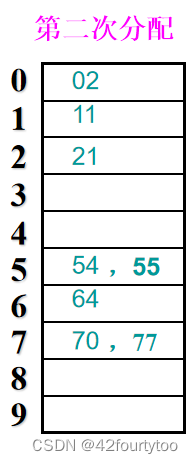
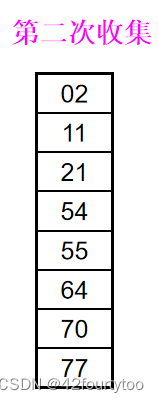
为什么从最低位开始比较?
虽然最高位最能决定数字大小,但先排高位后排低位会把总体的趋势打乱;先排低位,虽然高位相同的数字是分散的,但如果单独取出来看,会发现高位相同的数字间正变得有序。最后排高位,确定总体趋势,得到有序数组。
| 时间效率 | O(d(n+radix)) 假设有 n 个记录,每个记录关键字有 d 位,每个关键字的取值有radix个,则每趟分配需要的时间为O(n),每趟收集需要的时间为O(radix),合计每趟总时间为O(n+radix)。全部排序需要重复进行d 趟“分配”与“收集”。 |
| 空间效率 | O(n+radix) 基数排序需要增加n+2radix个附加链接指针。存储数据的静态链表需要额外n个指针,每个静态队列需要头尾两个指针。 |
| 稳定性 | 稳定 |
代码:
#include<stdio.h>
#include<stdlib.h>typedef struct { //队列类型int head;int tail;int* base;
}array; void radix_sort(int* list, int len)
{ int i, j, k; //代表三层循环变量int high = 0; //找最大值来计算元素的最高位数highint max = list[0];for (i = 0; i < len; i++)if (list[i] > max)max = list[i];while (max){max /= 10;high++;}array* ten_arr = (array*)malloc(10 * sizeof(array)); //10个列表if (!ten_arr) return;for (i = 0; i < 10; i++) //列表初始化{ten_arr[i].head = ten_arr[i].tail = 0;ten_arr[i].base = (int*)malloc(sizeof(int) * 10); //每个列表能放10个元素if (!ten_arr[i].base) return;}int b = 1; //b用于计算,表明当前取的是哪一位for (i = 0; i < high; i++) {for (j = 0; j < len; j++) //遍历数组元素{int number = (list[j] / b) % 10; //取指定位数字ten_arr[number].base[ten_arr[number].tail++] = list[j]; //把元素放进对应队列} b *= 10; //b倍增,下次循环取下一位k = 0;for (j = 0; j < 10; j++) //把队列中的数据收集起来放回列表中{while (ten_arr[j].head != ten_arr[j].tail) {list[k++] = ten_arr[j].base[ten_arr[j].head++];} ten_arr[j].head = ten_arr[j].tail = 0; //队列清空,这玩意不要放到while里面:(}}
}int main(void)
{int i, len, * list;printf("数的个数:");scanf_s("%d", &len);list = (int*)malloc(len * sizeof(int)); if (!list) return NULL;printf("输入数:\n");for (i = 0; i < len; i++) scanf_s("%d", &list[i]);radix_sort(list, len);for (i = 0; i < len; i++)printf("%d ", list[i]);}七、总结
稳定的排序算法:鸡毛插龟壳(基数、冒泡、插入、归并)




![【C++入门到精通】互斥锁 (Mutex) C++11 [ C++入门 ]](https://img-blog.csdnimg.cn/direct/2b8dd8add78842b5aadcc661e9255f47.png#pic_center)