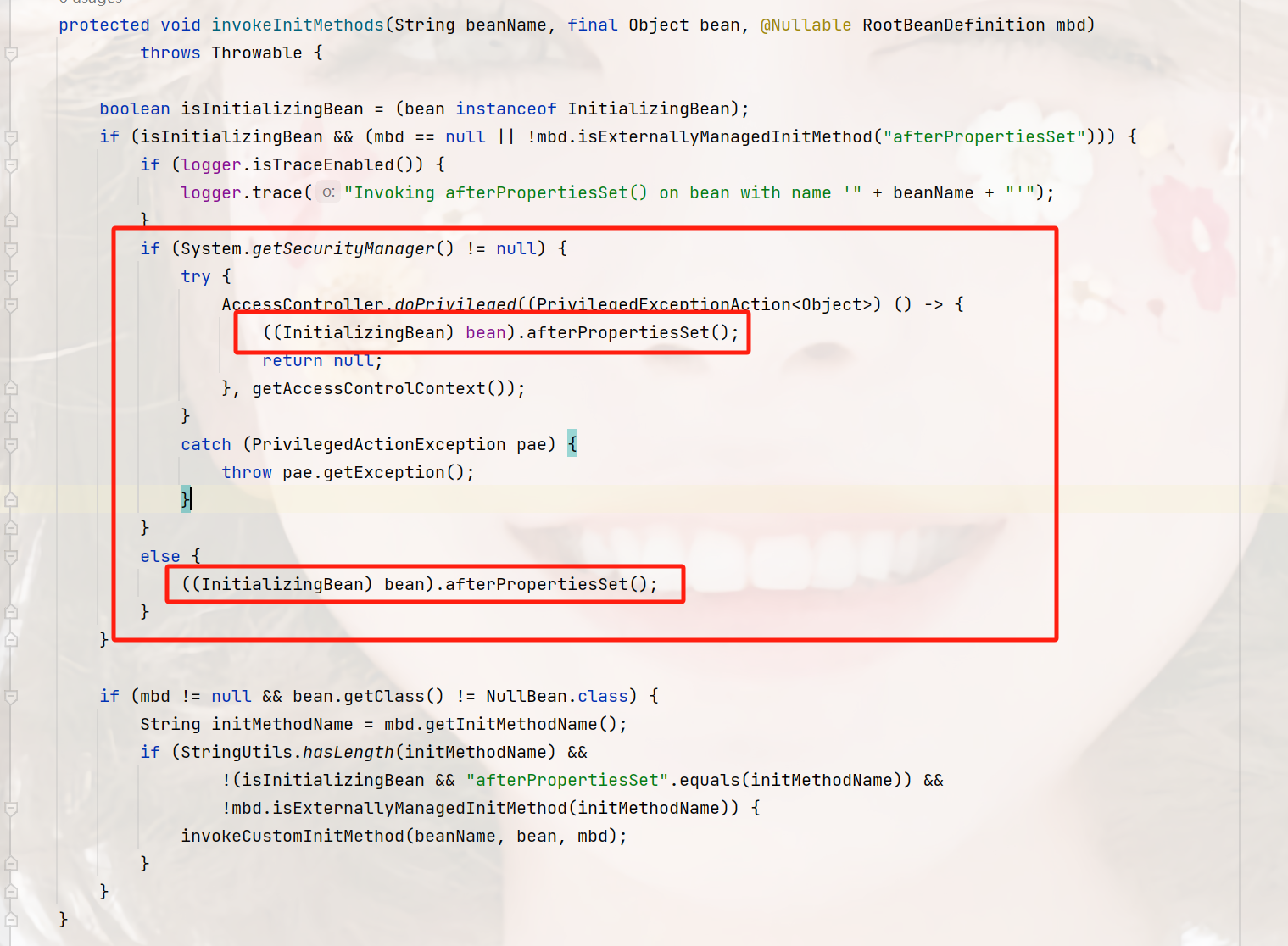
- AE 是将数据映直接映射为数值code(确定的数值),主要用于图像压缩与还原
- VAE是先将数据映射为分布,再从分布中采样得到数值code,主要用于图像生成。
- AQ-VAE是在原始VAE基础上多了一步
Vector Quantization矢量量化操作,完成对 latents 的进一步压缩,主要用于图像生成。
AE
因为AE学的只是将具体的图像X压缩为latent Z,然后解码回X‘,计算重建loss,而并不是学习一个概率分布。
AutoEncoder训练后会有严重的过拟合:当我们想从latent space中随机采样一个random vector z,然后用decoder解码为一张图像时,我们发现并不是所有的vector都可以解码为一张人脸的,而是一个具体的vector一张具体的训练集的图像存在一一对应关系。这个latent space中的vector和训练集图像严重过拟合了,无法在两个vector之间进行插值生成相似的图像。因此我们无法使用AE的Decoder生成训练集中没有见过的图像。

假设我们训练好的AE将“新月”图片encode成code=1(这里假设code只有1维),将其decode能得到“新月”的图片;将“满月”encode成code=10,同样将其decode能得到“满月”图片。这时候如果我们给AE一个code=5,我们希望是能得到“半月”的图片,但由于之前训练时并没有将“半月”的图片编码,或者将一张非月亮的图片编码为5,那么我们就不太可能得到“半月”的图片。因此AE多用于数据的压缩和恢复,用于数据生成时效果并不理想。

VAE
VAE相较于AE开始学习概率分布:encoder将原图像的概率分布转化为latent sapce中的概率分布,然后decoder将latent sapce中的概率分布转化为图像的概率分布。当我们学习到了 p ( x ∣ z ) p(x|z) p(x∣z)以后,我们就可以从latent sapce p ( z ∣ x ) p(z|x) p(z∣x)中随机采样一个random vector z使用decoder解码为一张图像。

不将图片映射成“数值编码”,而将其映射成“分布”。还是刚刚的例子,我们将“新月”图片映射成μ=1的正态分布,那么就相当于在1附近加了噪声,此时不仅1表示“新月”,1附近的数值也表示“新月”,只是1的时候最像“新月”。将"满月"映射成μ=10的正态分布,10的附近也都表示“满月”。那么code=5时,就同时拥有了“新月”和“满月”的特点,那么这时候decode出来的大概率就是“半月”了。

代码层面:
Encoder、Decoder是正常的CNN或Transformer架构混用都可以。


在 输入图像 x 用 encoder 编码为latents h后,先进行一个卷积quant_conv将其映射为2部分:均值mena和方差logvar,然后使用均值和方差,在中进行采样
从技术角度来说,训练时,VAE 的工作原理如下:
(1)编码器encoder将输入样本 input img x 编码为latents h后,进行一个卷积quant_conv将其映射为2部分:均值mena和方差logvar,其中标准差 s t d = e l o g v a r = e l o g s t d std=e^{\sqrt{logvar}}=e^{logstd} std=elogvar=elogstd
(2)我们假定潜在后验分布Posterior(正态分布 x ~ P(mean, std^2) -> x = mean + std * epsilon)能够生成输入图像,并从这个分布中随机采样一个点 z : z= mena + std * epsilon,其中 epsilon 是取值很小的随机张量(下面代码中是sample)。
(3)解码器decoder将latent space的这个点z映射回原始输入图像x’
因为训练时 epsilon 是随机的,所以可以确保:与 input_img 编码的latent space中(即 mean)靠近的每个点都能被解码为与 input_img 类似的图像,从而迫使latent space能够连续。


前面说我们假设了后验分布Posterior是正态分布,那我们如何约束呢?在训练的loss中可以找到答案,VAE的loss函数不仅包含图像的重建loss,还包含了我们的Posterior分布和标准正态分布的KL散度loss。

对于训练好的模型,我们可以在latent space中随机采样一些vector,然后用decoder解码为图像:

VQ-VAE
和VAE的区别是,他的Posterior分布是一个离散概率分布:在原始VAE基础上多了一步Vector Quantization矢量量化操作,完成对 latents 的进一步压缩。

具体来说,VQ-VAE维护了一个code book矩阵(是一个Learnable 的 Embedding Layer),通过计算encoder输出的latent与code book中每个向量的距离,然后从code book中拿出距离最近的向量组成新的latent传入decoder,进行重建。

代码层面:
encoder和decoder和VAE一样:

构建一个learnable的embedding作为code book,对于编码后的latent z进行变形,然后与code book中每个向量计算距离。

找到距离 latent 最近的向量 组成新的latent z_q,与原始的latent z 相加。

VQ-VAE的loss包含2部分,一个是图像重建的rec_loss,一个是学习embedding code book的quant_loss.







![3.[BUUCTF HCTF 2018]WarmUp1](https://img-blog.csdnimg.cn/direct/1c0a84bea02d4cb99c2fb86cf56b1f81.png)