1.实验目的
1.会用Python提供的方法对数据进行预处理
2.会用python实现adaboost算法
2.设备与环境
Jupyter notebook
3.实验原理


4.实验内容
AdaBoost先初始化样本权值分布,并从初始训练集训练出一个基学习器,再根据这个基学习器的分类结果对训练样本的权值分布进行调整,再生成新的基学习器,依次进行下去,直到满足要求。其流程如下:
(1)初始化样本权值分布
(2)生成基本分类器G1
(3)计算分类器系数α \alphaα
(4)更新训练数据的权值分布
(5)生成新的分类器G2
(6)循环(2-5)
(7)将所有的分类器线性相加。
5.实验结果分析
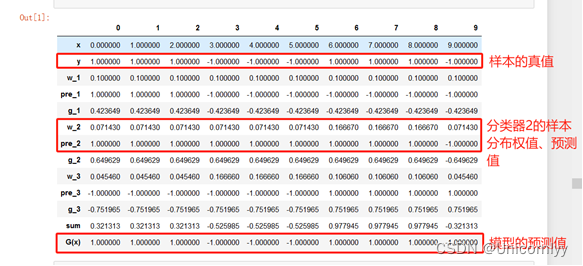
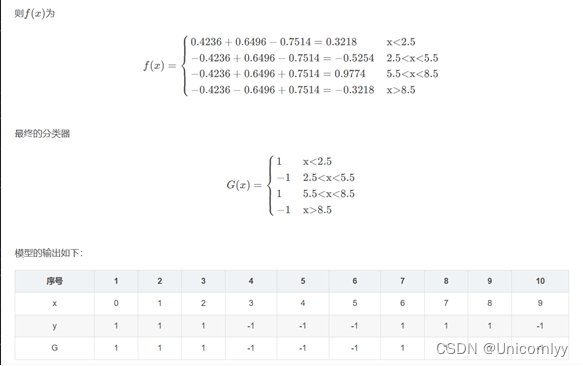
由上图可以发现模型预测的正确率达100%
6.附录(代码)
#导入相关的库
import math
import pandas as pd
import numpy as np#输入原始数据
x=[0,1,2,3,4,5,6,7,8,9]
y=[1,1,1,-1,-1,-1,1,1,1,-1]
T=3 #设置分类器个数#初始化样本权值分布函数
def func_w_1(x):w_1=[]for i in range(len(x)):w_1.append(0.1)return w_1
#生成阈值函数
def func_threshs(x):threshs =[i-0.5 for i in x]threshs.append(x[len(x)-1]+0.5)return threshs
#根据阈值生成22种分类器的输出
def func_cut(threshs):y_pres_all={}y_last_all={}for thresh in threshs:y_pres=[]y_last=[]for i in range(len(x)):if x[i]<thresh:y_pres.append(1)y_last.append(-1)else:y_pres.append(-1)y_last.append(1)y_pres_all[thresh]=y_pres #前向分类器y_last_all[thresh]=y_last #后向分类器return y_pres_all,y_last_all#求一个分类器误差率e
def sub_func_e(y,w_n,y_pres_all,thresh):e=0for i in range(len(y)):if y_pres_all[thresh][i]!=y[i]:e+=w_n[i];return e#求一类分类器误差率
def sub_func_e_s(y,w_n,y_pres_all,threshs):e_s={}e_min=1n=0for thresh in threshs:e=sub_func_e(y,w_n,y_pres_all,thresh)e_s[thresh]=round(e,6)if e<e_min:e_min=round(e,6)n=threshreturn e_s,e_min,n#求两类分类器误差率
def sub_func_e_all(y,w_n,y_pres_all,y_last_all,threshs):e_s1,e_min1,n1=sub_func_e_s(y,w_n,y_pres_all,threshs)e_s2,e_min2,n2=sub_func_e_s(y,w_n,y_last_all,threshs)if e_min1<=e_min2:return e_s1,e_min1,n1,y_pres_allelse:return e_s2,e_min2,n2,y_last_all
#输出最佳分类器
def func_pre_n(y_all,n):pre_n=y_all[n]return pre_n#求最佳分类器的误差率
def func_a_n(e_min):a_n=round(0.5*math.log((1-e_min)/e_min),6)return a_n
#求临时分布权值
def func_w_n_tmp(x,pre_n,w_n,a_n):w_n_tmp=[]for i in range(len(x)):w_new=round(w_n[i]*math.exp(-1*a_n*y[i]*pre_n[i]),6)w_n_tmp.append(w_new)return w_n_tmp
#求Z
def func_z_n(w_n_tmp):z_n=sum(w_n_tmp)return z_n
#求更新后的样本分布权值
def func_w_n(w_n_tmp,z_n):w_n=[round(i/z_n,5) for i in w_n_tmp]return w_n#求f(x)
def func_g_n(x,pre_n,a_n):g_n=[]for i in range(len(x)):g_n_single=a_n*pre_n[i]g_n.append(g_n_single)return g_n
#各子函数封装
def func_AdaBoost(x,y,T):a_n_s=[] #保存分类器系数w_n_s=[] #保存样本分布权值pre_n_s=[] #保存各个基分类器的输出e_n_s=[] #保存误差率g_n_s=[] #保存子分类器n_s=[] #保存阈值w_1=func_w_1(x) #初始化权值,都为0.1w_n_s.append(w_1)threshs=func_threshs(x)for i in range(T):w_n=w_n_s[i]y_pres_all,y_last_all=func_cut(threshs)e_s,e_min,n,y_all=sub_func_e_all(y,w_n,y_pres_all,y_last_all,threshs)pre_n=func_pre_n(y_all,n)a_n=func_a_n(e_min)w_n_tmp=func_w_n_tmp(x,pre_n,w_n,a_n)z_n=func_z_n(w_n_tmp)w_n=func_w_n(w_n_tmp,z_n)g_n=func_g_n(x,pre_n,a_n)a_n_s.append(a_n)w_n_s.append(w_n)pre_n_s.append(pre_n)g_n_s.append(g_n)n_s.append(n)e_n_s.append(e_min)return a_n_s,w_n_s,pre_n_s,g_n_s,n_s,e_n_s#主程序
a_n_s,w_n_s,pre_n_s,g_n_s,n_s,e_n_s=func_AdaBoost(x,y,T)
#列表、显示结果
data={'x':x,'y':y,'w_1':w_n_s[0],'pre_1':pre_n_s[0],'g_1':g_n_s[0],'w_2':w_n_s[1],'pre_2':pre_n_s[1],'g_2':g_n_s[1],'w_3':w_n_s[2],'pre_3':pre_n_s[2],'g_3':g_n_s[2]}
df=pd.DataFrame(data)
df['sum']=df['g_1']+df['g_2']+df['g_3']
#输出预测值
df['G(x)']=np.sign(df['sum'])
df.T