由浅入深全面解析ThreadLocal
@TOC
简介
线程并发:在多线程并发的场景下使用
传递数据:我们可以通过ThreadLocal在同一线程,不同组件中传递公共变量
线程隔离:每个线程的变量都是独立的,不会相互影响
基本使用
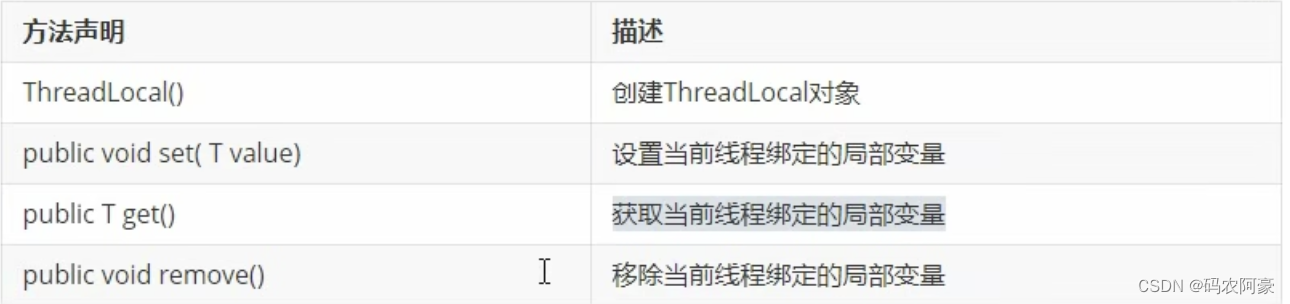
常用方法
代码案例实现 (1) 不使用ThreadLocal时模拟多线程存取数据
public class ThreadLocalDemo1 {private String content;public String getContent() {return content;}public void setContent(String content) {this.content = content;}public static void main(String[] args) {ThreadLocalDemo1 threadLocalDemo = new ThreadLocalDemo1();for (int i = 0; i < 5; i++) {Thread thread = new Thread(new Runnable() {@Overridepublic void run() {/*** 每一个线程存一个变量,过一会取出这个变量*/threadLocalDemo.setContent(Thread.currentThread().getName() + "的数据");System.out.println("------------------------");System.out.println(Thread.currentThread().getName() + "----->" + threadLocalDemo.getContent());}});thread.setName("线程" + i);thread.start();}}
}结果:
------------------------
线程0----->线程4的数据
------------------------
线程4----->线程4的数据
------------------------
线程2----->线程4的数据
------------------------
线程3----->线程4的数据
------------------------
线程1----->线程4的数据(2) 使用ThreadLocal对多线程进行数据隔离,把数据绑定到ThreadLocal (传统解决方案首先想到的就是加锁,确实可以实现,但是却牺牲了效率,需要等待上一个线程之行结束才可以往下之行)
public class ThreadLocalDemo2 {ThreadLocal<String> threadLocal = new ThreadLocal<>();private String content;public String getContent() {return threadLocal.get();}public void setContent(String content) {threadLocal.set(content);}public static void main(String[] args) {ThreadLocalDemo2 threadLocalDemo2 = new ThreadLocalDemo2();for (int i = 0; i < 5; i++) {Thread thread = new Thread(new Runnable() {@Overridepublic void run() {/*** 每一个线程存一个变量,过一会取出这个变量*/threadLocalDemo2.setContent(Thread.currentThread().getName()+"的数据");System.out.println("------------------------");System.out.println(Thread.currentThread().getName() + "----->" + threadLocalDemo2.getContent());}});thread.setName("线程" + i);thread.start();}}
}结果:
------------------------
------------------------
------------------------
线程3----->线程3的数据
------------------------
线程2----->线程2的数据
线程1----->线程1的数据
线程0----->线程0的数据
------------------------
线程4----->线程4的数据ThreadLocal与synchronized的区别
二者都是用来处理多线程并发访问的问题,但是二者的原理和侧重点不一样,简要说就是,ThreadLocal牺牲了空间,而synchronized是牺牲了时间来保证线程安全(隔离)。  总结:在上述的案例当中,使用ThreadLocal更为合理,这样保证了程序拥有了更高的并发性。
总结:在上述的案例当中,使用ThreadLocal更为合理,这样保证了程序拥有了更高的并发性。
ThreadLocal现在的设计(JDK1.8)
- 简介 每一个Thread维护一个ThreadLocalMap,这个Map的key为ThreadLocal实例本身,而value则为实际存储的值。
- 具体过程 (1)每一个Thread内部都有一个Map(ThreadLocalMap) (2)Map里面存储的ThreadLocal对象(key)和线程的变量副本(value) (3)Thread的Map是由ThreadLocal来维护的,由ThreadLocal负责向Map获取和设置线程的变量值。 (4)对于线程获取值,每一个副本只能获取当前线程本地的副本值,别的线程无法访问到,互不干扰,实现了线程隔离。
- 对比与1.8之前的设计(相当于Thread与ThreadLocal的角色互换了)
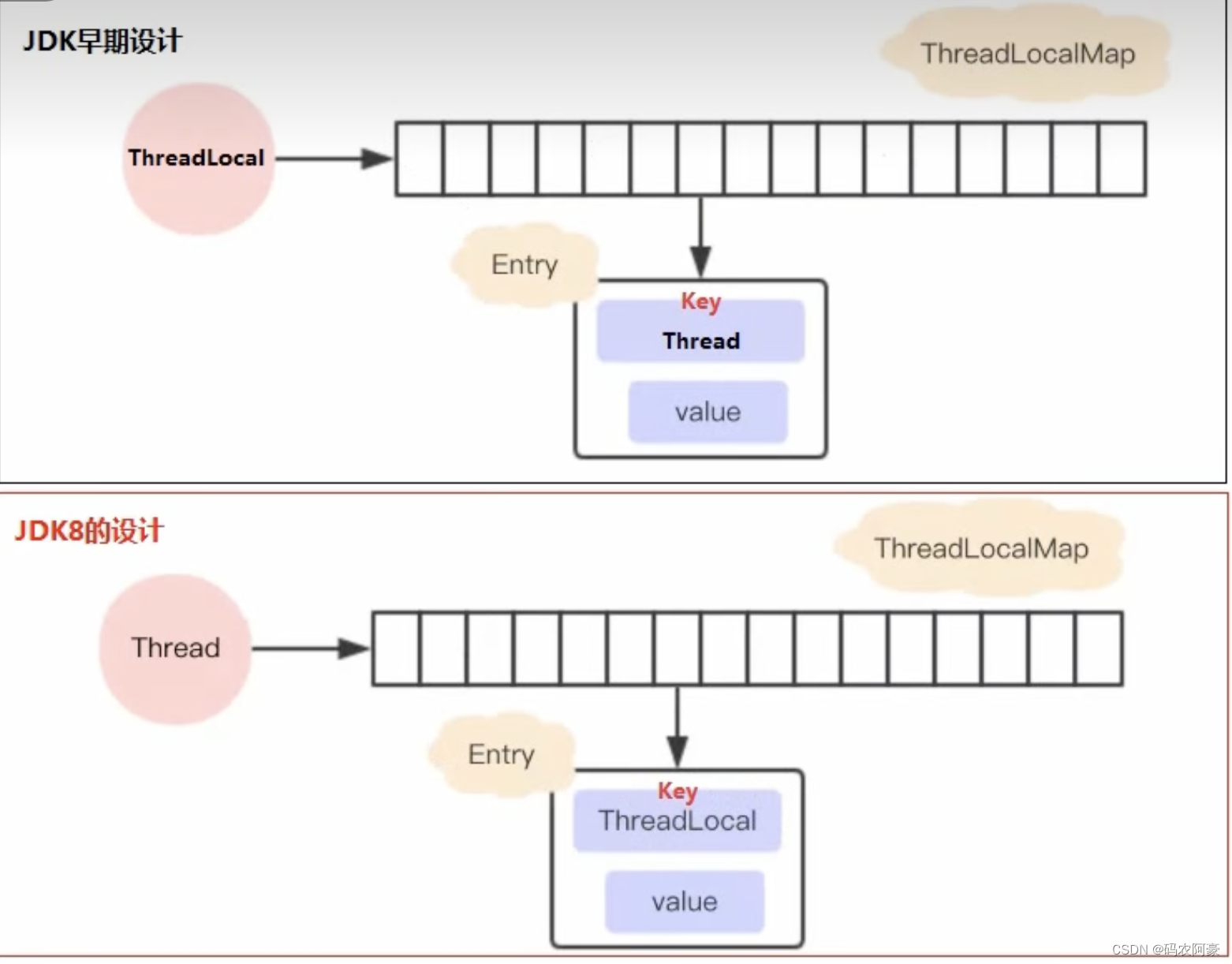
- 1.8设计的好处 (1)每个Map存储的Entry数量变少了(因为实际状况下Thread比ThreadLocal多) (2)当Thread销毁时,ThreadLocalMap也会随之销毁,避免内存的浪费
ThreadLocal核心方法源码分析
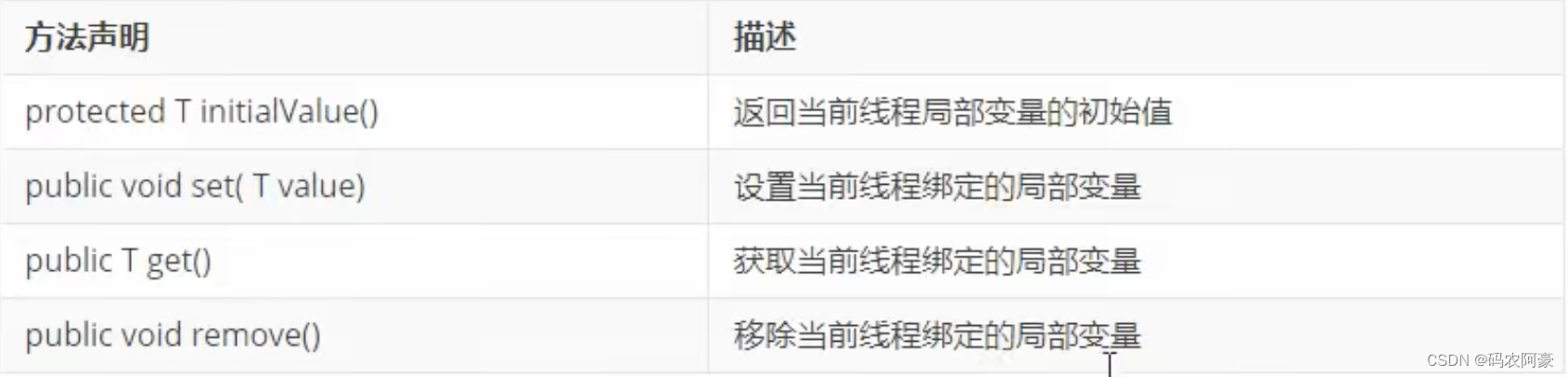
- get方法源码
public T get() {// 获取当前线程Thread t = Thread.currentThread();// 获取ThreadLocalMapThreadLocalMap map = getMap(t);// map不为空时,获取里面的Entryif (map != null) {ThreadLocalMap.Entry e = map.getEntry(this);if (e != null) {@SuppressWarnings("unchecked")T result = (T)e.value;// 返回结果return result;}}// 没有则赋值初始值null并返回return setInitialValue();}- set方法源码
public void set(T value) {// 获取当前线程Thread t = Thread.currentThread();// 获取ThreadLocalMapThreadLocalMap map = getMap(t);if (map != null) {// 不为空直接setmap.set(this, value);} else {// map为空则创建并setcreateMap(t, value);}}- initialValue方法返回初始值(protected修饰为了让子类覆盖设计的)需要自定义初始值可以重写该方法
protected T initialValue() {return null;}- remove方法
public void remove() {// 获取当前线程的ThreadLocalMapThreadLocalMap m = getMap(Thread.currentThread());if (m != null) {// 移除ThreadLocalMapm.remove(this);}}- setInitialValue方法
private T setInitialValue() {// 得到初始化值nullT value = initialValue();// 获取当前线程Thread t = Thread.currentThread();// 获取线程中ThreadLocalMapThreadLocalMap map = getMap(t);// map存在的话把null设置进去,不存在则创建一个并将null设置进去if (map != null) {map.set(this, value);} else {createMap(t, value);}// 如果当前ThreadLocal属于TerminatingThreadLocal(关闭的ThreadLocal)则register(注册)到TerminatingThreadLocalif (this instanceof TerminatingThreadLocal) {TerminatingThreadLocal.register((TerminatingThreadLocal<?>) this);}return value;}ThreadLocalMap源码分析
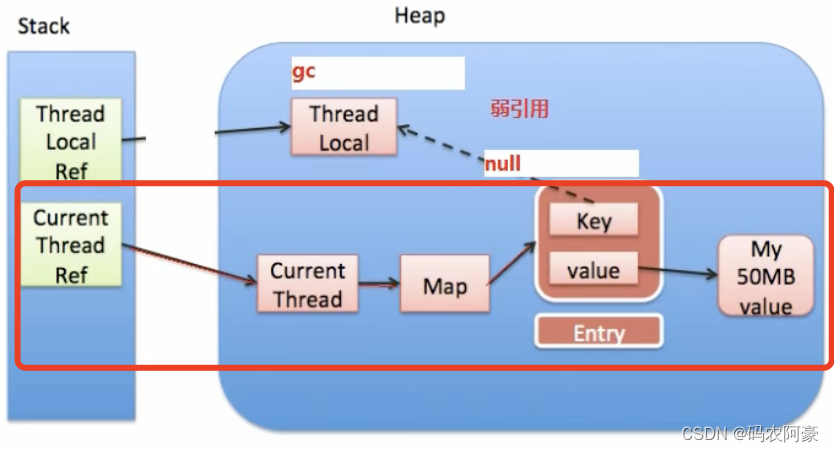
- 简介 ThreadLocalMap是ThreadLocal的内部类,没有实现Map接口,是独自设计实现Map功能,内部的Entry也是独立的。
- 结构图解
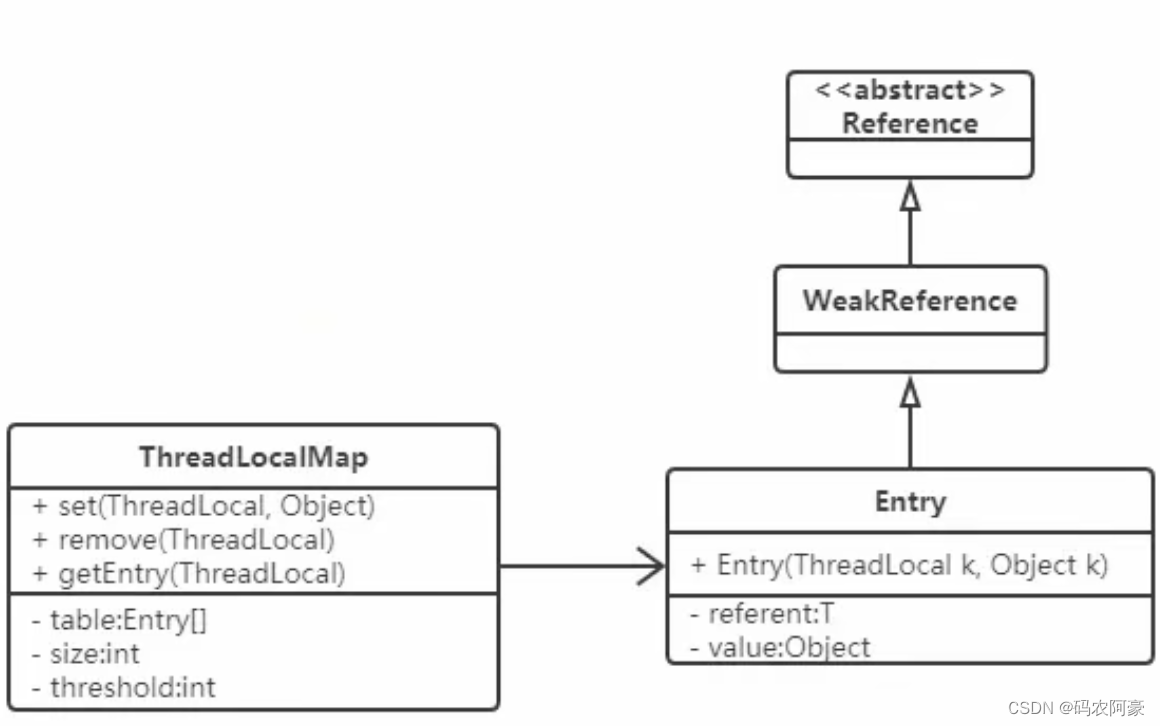
- 成员变量
// Entry类,继承弱应用,为了和Thread的生命周期解绑static class Entry extends WeakReference<ThreadLocal<?>> {/** The value associated with this ThreadLocal. */Object value;Entry(ThreadLocal<?> k, Object v) {super(k);value = v;}}/*** The initial capacity -- MUST be a power of two.* 初始容量,必须是二的幂*/private static final int INITIAL_CAPACITY = 16;/*** The table, resized as necessary.* table.length MUST always be a power of two.* 根据需要调整大小。长度必须是2的幂。*/private Entry[] table;/*** The number of entries in the table.* table中的entrie数量*/private int size = 0;/*** The next size value at which to resize.* 要调整大小的下一个大小值*/private int threshold; // Default to 0/*** Set the resize threshold to maintain at worst a 2/3 load factor.* 设置调整大小阈值以维持最坏的2/3负载因子*/private void setThreshold(int len) {threshold = len * 2 / 3;}/*** Increment i modulo len.* 增量一*/private static int nextIndex(int i, int len) {return ((i + 1 < len) ? i + 1 : 0);}/*** Decrement i modulo len.* 减量一*/private static int prevIndex(int i, int len) {return ((i - 1 >= 0) ? i - 1 : len - 1);}弱引用与内存泄露(内存泄漏和弱引用没有直接关系)
- 内存泄漏/溢出概念 (1)Memory overflow:内存溢出,没有足够的空间提供给申请者使用 (2)Memory leak:内存泄漏,系统中已动态分配的堆内存由于某种原因无法释放或者没有释放,导致系统内存堆积,影响系统运行,甚至导致系统崩溃。内存泄漏终将导致内存溢出。
- 强/弱引用概念 (1)Strong Referce:强引用,我们常见的对象引用,只要有一个强引用指向对象,也就表明还“活着”,这种状况下垃圾回收机制(GC)是不会回收的。 (2)Weak Referce:弱引用,继承了WeakReferce的对象,垃圾回收器发现了只具有弱引用的对象,不管当前系统的内存是否充足,都会回收他的内存。
- 如果key,即Entry使用强引用,也无法避免内存泄漏 因为Entry是在Thread当前线程中,生命周期和Thread一样,没有手动删除Entry时Entry就会内存泄漏。
- 也就是说,只要在调用完ThreadLocal后及时使用remove方法,才能避免内存泄漏

ThreadLocal核心源码(Hash冲突解决)
- 从构造方法入手
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {// 初始化tabletable = new Entry[INITIAL_CAPACITY];// 计算索引在数组中的位置(核心代码)int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);// 设置值table[i] = new Entry(firstKey, firstValue);size = 1;// 设置阈值(INITIAL_CAPACITY的三分之二)setThreshold(INITIAL_CAPACITY);}- 重点分析int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
private final int threadLocalHashCode = nextHashCode();private static int nextHashCode() {return nextHashCode.getAndAdd(HASH_INCREMENT);}private static AtomicInteger nextHashCode = new AtomicInteger();private static final int HASH_INCREMENT = 0x61c88647;public final int getAndAdd(int delta) {return unsafe.getAndAddInt(this, valueOffset, delta);}(1)这里定义了一个AtomicInteger,每次获取并加上HASH_INCREMENT(0x61c88647,这个值与斐波那契数(黄金分割)有关),是为了让哈希码能够均匀的分布在2的n次方的数组(Entry[])里面,也就尽可能避免了哈希冲突。 (2)hashcode & (INITIAL_CAPACITY - 1) 相当于hashcode % (INITIAL_CAPACITY - 1) 的高效写法,所以size必须为2的次幂,这样最大程度避免了哈希冲突。
- set方法源码分析
private void set(ThreadLocal<?> key, Object value) {Entry[] tab = table;int len = tab.length;// 计算索引int i = key.threadLocalHashCode & (len-1);/**** 使用线性探测法查找元素* */for (Entry e = tab[i];e != null;// 使用线性探测法查找元素e = tab[i = nextIndex(i, len)]) {// 获取到该Entry对应的ThreadLocalThreadLocal<?> k = e.get();if (k == key) {// key存在则覆盖valuee.value = value;return;}// key为null但是值不为null,这说明了之前使用过,但是ThreadLocal被垃圾回收了,当前的Entry是一个陈旧的(Stale)元素if (k == null) {// key(ThreadLocal)不存在,则新Entry替换旧的Entry,此方法做了不少垃圾清理的动作,避免了内存泄漏。replaceStaleEntry(key, value, i);return;}}// ThreadLocal中未找到key也没有陈旧的元素,此时则在这个位置新创建一个Entrytab[i] = new Entry(key, value);int sz = ++size;// cleanSomeSlots用于清理e.get()为null的key,如果大于阈值(2/3容量)则rehash(执行一次全表扫描清理工作)if (!cleanSomeSlots(i, sz) && sz >= threshold)rehash();}/*** 线性探测法查找元素,到最后一个时重定位到第一个*/private static int nextIndex(int i, int len) {return ((i + 1 < len) ? i + 1 : 0);}(详细视频可前往B站黑马程序员)
本文由博客一文多发平台 OpenWrite 发布!






![使用教程之【SkyWant.[2304]】路由器操作系统,破解移动【Netkeeper】校园网【小白篇】](https://img-blog.csdnimg.cn/direct/01663f3794ff4cea9462ccd0000b3c0e.png)