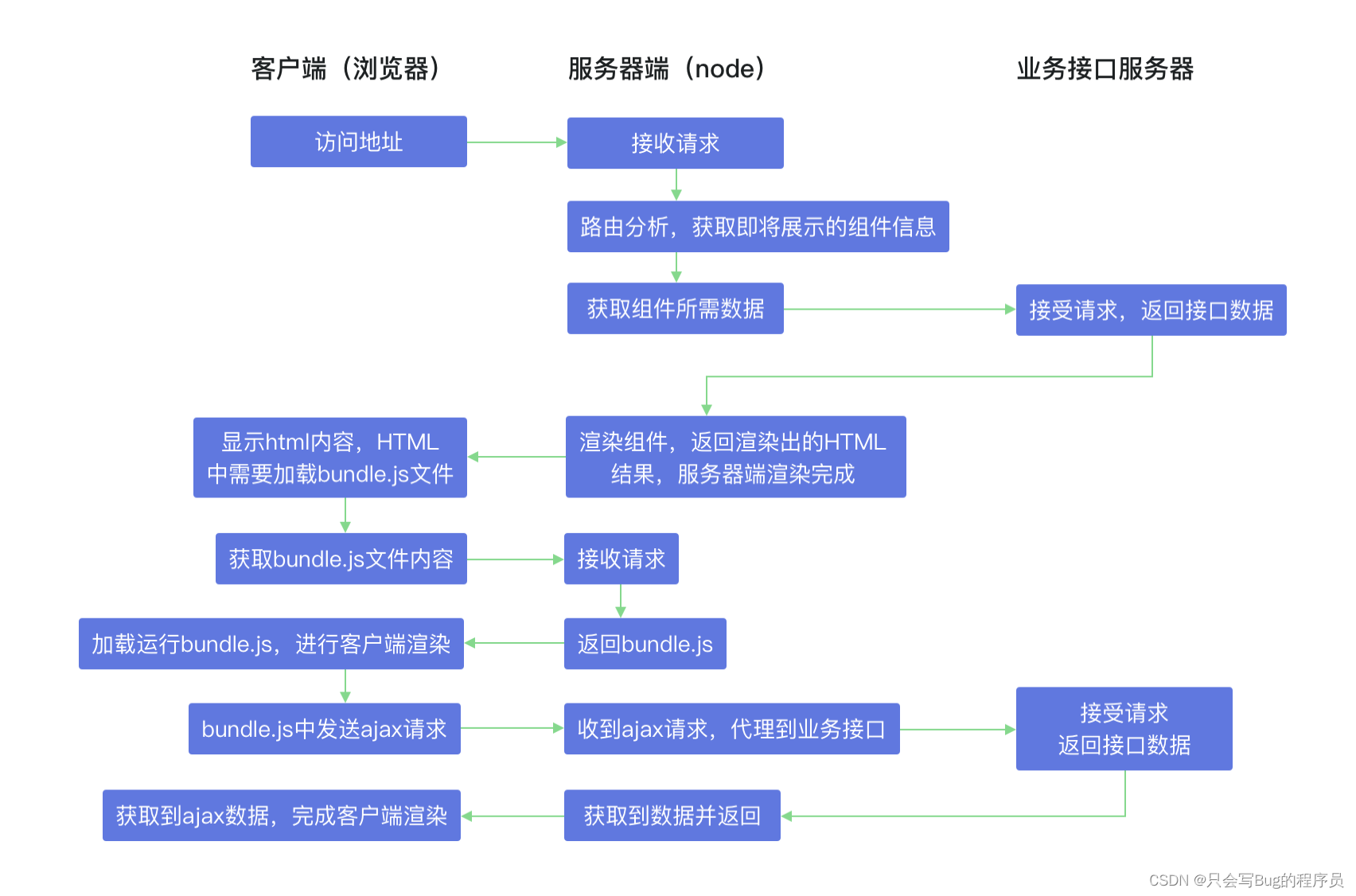
报错:
Could not load library libcudnn_cnn_infer.so.8. Error: /home/qc/miniconda3/envs/DNAqc/lib/python3.10/site-packages/torch/lib/libcudnn_cnn_infer.so.8: cannot read file data
Please make sure libcudnn_cnn_infer.so.8 is in your library path!
Aborted (core dumped)

原因:libcudnn_cnn_infer.so.8这个文件有问题,找别人要一份
致谢:网上搜索,报错内容都是:Could not load library libcudnn_cnn_infer.so.8. Error: libcuda.so: cannot open shared object file: No such file or directory。试了删掉pytorch重装,试了新建一个不同python版本的虚拟环境,不对不对,全都不对,后来去搜“cannot read file data”,众多回答中看到这句话,当时心想这库是从官网下的,别人都没事,我的肯定也没问题,但是到最后各种搜索和尝试都无果,决定尝试,终于成了!感谢这位大哥,也感谢传我能用文件的朋友!
还有一位,成功之后去翻历史记录,没找到他的网站。他给了一段简单的代码,验证cuda和cudnn是否能用,现在把这段代码发在这里。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.backends.cudnn as cudnn
from torchvision import datasets, transformsclass Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(1, 10, kernel_size=5)self.conv2 = nn.Conv2d(10, 20, kernel_size=5)self.conv2_drop = nn.Dropout2d()self.fc1 = nn.Linear(320, 50)self.fc2 = nn.Linear(50, 10)def forward(self, x):x = F.relu(F.max_pool2d(self.conv1(x), 2))x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))x = x.view(-1, 320)x = F.relu(self.fc1(x))x = F.dropout(x, training=self.training)x = self.fc2(x)return F.log_softmax(x, dim=1)def train(model, device, train_loader, optimizer, epoch):model.train()for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = F.nll_loss(output, target)loss.backward()optimizer.step()if batch_idx % 10 == 0:print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, batch_idx * len(data), len(train_loader.dataset),100. * batch_idx / len(train_loader), loss.item()))def main():cudnn.benchmark = Truetorch.manual_seed(1)device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")print("Using device: {}".format(device))kwargs = {'num_workers': 1, 'pin_memory': True}train_loader = torch.utils.data.DataLoader(datasets.MNIST('./data', train=True, download=True,transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])),batch_size=64, shuffle=True, **kwargs)model = Net().to(device)optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)for epoch in range(1, 11):train(model, device, train_loader, optimizer, epoch)if __name__ == '__main__':main()
感谢!